个人学习的积累
- CPU_Memory_Monitoring.py 实时监控CUP和内存的使用率
- CPU_Memory_Flush.py print输出刷新
- CPU_Memory_Flush2.py print输出刷新,定位输出刷新
- weatherAndPM.py 命令行版
- weatherAndPM_GUI.py GUI版
- redayexcel.py 读取Excel文件内容
- MySQL2Excel.py 从MySQL中读取表内容,写入Excel
- excelToDatabase.py 从Excel读取内容,写入MySQL
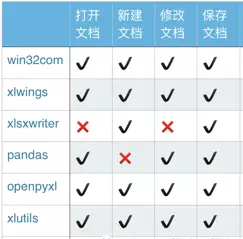
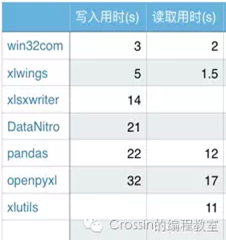
- xlwings:简单强大,可替代VBA
- openpyxl:简单易用,功能广泛;(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易
- pandas:使用需要结合其他库,数据处理是pandas立身之本
- win32com:不仅仅是excel,可以处理office;不过它相当于是 windows COM 的封装,新手使用起来略有些痛苦。
- Xlsxwriter:丰富多样的特性,缺点是不能打开/修改已有文件,意味着使用 xlsxwriter 需要从零开始。
- DataNitro:作为插件内嵌到excel中,可替代VBA,在excel中优雅的使用python
- xlutils:结合xlrd/xlwt,老牌python包,需要注意的是你必须同时安装这三个库
- NULL空值:对应于python中的None,表示这个cell里面没有数据。
- numberic: 数字型,统一按照浮点数来进行处理。对应于python中的float。
- string: 字符串型,对应于python中的unicode。
- workbook: 工作簿,一个excel文件包含多个sheet。
- sheet:工作表,一个workbook有多个,表名识别,如“sheet1”,“sheet2”等。
- cell: 单元格,存储数据对象
1.创建一个workbook(工作簿)
wb = Workbook() # 一个工作簿(workbook)在创建的时候同时至少也新建了一张工作表(worksheet)。
2.打开一个已有的workbook:
wb = load_workbook('file_name.xlsx')
3.打开sheet:
通过名字ws = wb["frequency"] 或ws2 = wb.get_sheet_by_name('frequency')
不知道名字用index
sheet_names = wb.get_sheet_names() #方法得到工作簿的所有工作表
ws = wb.get_sheet_by_name(sheet_names[index])# index为0为第一张表
或者(调用得到正在运行的工作表)
ws =wb.active或ws = wb.get_active_sheet() #通过_active_sheet_index设定读取的表,默认0读第一个表
活动表表名wb.get_active_sheet().title
4.新建sheet(工作表)
ws1 = wb.create_sheet() #默认插在最后
ws2 = wb.create_sheet(0) #插在开头,在创建工作表的时候系统自动命名,依次为Sheet, Sheet1, Sheet2 ...
ws.title = "New Title" #修改表名称
简化 ws2 = wb.create_sheet(title="Pi")
5.读写单元格
当一个工作表被创建时,其中是不包含单元格。只有当单元格被获取时才被创建。这种方式下,我们不会创建我们使用不到的单元格,从而减少了内存消耗。
可以直接根据单元格的索引直接获得
c = ws['A4'] #读取单元格,如果不存在将在A4新建一个
可以通过cell()方法获取单元格(行号列号从1开始)
d = ws.cell(row = 4, column = 2) #通过行列读
d = ws.cell('A4')
写入单元格(cell)值
ws['A4'] = 4 #写单元格
ws.cell(row = 4, column = 2).value = 'test')
ws.cell(row = 4, column = 2, value = 'test')
6.访问多个单元格
cell_range = ws['A1':'C2'] #使用切片获取多个单元格
get_cell_collection() #读所有单元格数据
7.按行、按列操作 逐行读
ws.iter_rows(range_string=None, row_offset=0, column_offset=0) #返回一个生成器,
获得多个单元格
- portScanner1.py 简单的端口扫描例子
- portScanner2.py 使用线程的端口扫描例子
- portScanner3.py 使用argparse获取参数
- portScanner4.py 对给定的参数进行多线程端口扫描
- portScanner5.py 优化:获取参数IP和port进行扫描
TCP端口扫描一般分为以下几种类型:
TCP connect扫描:也称为全连接扫描,这种方式直接连接到目标端口,完成了TCP三次握手的过程,这种方式扫描结果比较准确,但速度比较慢而且可轻易被目标系统检测到。
TCP SYN扫描:也称为半开放扫描,这种方式将发送一个SYN包,启动一个TCP会话,并等待目标响应数据包。如果收到的是一个RST包,则表明端口是关闭的,而如果收到的是一个SYN/ACK包,则表示相应的端口是打开的。
Tcp FIN扫描:这种方式发送一个表示拆除一个活动的TCP连接的FIN包,让对方关闭连接。如果收到了一个RST包,则表明相应的端口是关闭的。
TCP XMAS扫描:这种方式通过发送PSH、FIN、URG、和TCP标志位被设为1的数据包。如果收到了一个RST包,则表明相应的端口是关闭的。
- 文件夹分类工具.py 用于文件夹分类,批量操作
- directory_tree_count.py
- typeName.py 对于存储数据为json格式的txt或log文件进行处理,筛选类型和数量
- 本项目仅用于学习和交流
欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远 Thanks for all