记录Stanford大学CS143编译原理的学习过程:blue_book:
Cool语法的学习笔记没做笔记,对应PA实现在assignments/PA1/stack.cl
在词法分析阶段,我们编写词法分析器的 flex 脚本。通过 flex 工具,可以将脚本转换为对应的 C++ 源码,进一步编译即可得到可执行的词法分析器(lexer)。
词法分析器的核心任务是: 读取源码中的字符流,识别出有意义的单词(token)并分类输出。
在 flex 脚本中,我们主要编写正则表达式匹配规则,用于识别源码中的关键词、标识符、常量、运算符等。这些匹配规则最终都会转化为对应的自动机状态跳转表,用于实际运行时识别 token。
lexer 通过正则语法将源码文本转化为一系列 token,并在过程中完成基本的语法过滤和错误检测。
- 字符串或注释未闭合(如缺失引号或
*/) - 非法字符(如 ASCII < 32 的控制符号)
- 非法转义字符(如字符串外的
\\) - 字符串过长
- 其他可通过字符流直接识别的简单语法错误
/* 定义词法单元的正则表达式 */
DIGIT [0-9]
LETTER [a-zA-Z]
ID ({LETTER}|{DIGIT}|_)
TYPEID [A-Z]{ID}*
/* 规则与动作 */
{TYPEID} {
/* 将识别到的 TYPEID 添加到符号表中 */
cool_yylval.symbol = idtable.add_string(yytext);
/* 返回对应的 token 类型 */
return TYPEID;
}该规则表示:匹配以大写字母开头、后跟若干字母/数字/下划线的类型名,并将其存入符号表。
正则表达式规则虽然简单易写,但它们本身无法直接用于解析字符串。因此需要引入一种可以转化为程序模型的形式 —— 有限自动机(Finite Automaton, FA)。
正则表达式对应的是形式语言中的”正则语言“,表达能力有限,例如匹配括号,无法写出一个正则表达式来匹配任意数量和深度的嵌套括号序列。并且缺乏结构化理解,正则表达式擅长识别扁平的、线性的模式(即一个字符序列)。它们可以告诉你“这里有一个数字”、“那里有一个标识符”、“这里是一个关键字”,但它们无法告诉你这些识别出来的部分之间有什么结构关系,例如无法做到优先级的划分。还有就是无法处理上下文,对于有多义的字符无法来根据上下文进行区分。
有限自动机由以下部分组成:
- 状态集合(有限)
- 初始状态
- 接受状态(一个或多个)
- 状态转移函数(基于输入字符,从当前状态跳转到下一个状态)
可以把有限自动机看作一个有向图,状态是节点,转移是边。
- 从初始状态开始
- 读取输入字符串的每个字符,查找当前状态下的匹配边进行状态转移
- 如果输入处理完毕后正好落在某个接受状态,则该字符串被接受(匹配成功)
-
确定性有限自动机(DFA) 每个状态对每个输入字符最多只有一个转移路径
-
非确定性有限自动机(NFA) 允许一个状态对相同字符有多条转移路径,甚至有 ε(空)转移
DFA 与 NFA 在表达能力上是等价的,NFA 可以通过子集构造法转化为等价的 DFA。
flex 工具的核心原理就是将正则表达式转换为 NFA,再转为 DFA,最后生成状态跳转表。
生成的代码(lex.yy.cc)大致流程如下:
- 初始化状态与内存
- 读取输入字符(按字节)
- 通过
yy_nxt状态表 和yy_current_state查找转移 - 直到无法继续转移为止,确定匹配到的 token
- 在
yy_accept表中查找对应的操作yy_act并执行
其中
yy_nxt、yy_accept等状态表是词法分析中由自动机制生成的重要数据结构。
词法分析是编译器的第一阶段,通过正则表达式 + 自动机构建出的 lexer 可以:
- 快速识别和分类源代码中的基本单元(token)
- 过滤明显语法错误
- 为后续语法分析阶段(parser)提供基础数据
flex 作为一种工具,简化了构建词法分析器的复杂度,使我们只需专注于正则规则的编写,而不必手写自动机代码。
所谓 parser,一般是指把某种格式的文本(字符串)转换成某种数据结构的过程。最常见的 parser,是把程序文本转换成编译器内部的一种叫做“抽象语法树”(AST)的数据结构。也有简单一些的 parser,用于处理 CSV,JSON,XML 之类的格式。
词法分析关心单词是否拼写正确,而语法分析关心这些单词组合在一起是否符合语法规则。
在编译器的语法分析阶段,主要通过上下文无关文法(CFG)来描述程序设计语言的语法结构。
语法分析器(Parser)的任务就是根据给定的上下文无关文法规则,来检查由词法分析器输出的记号(token)序列是否构成一个合法的程序,并通常会构建一个语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree)来表示程序的结构。
上下文无关文法之所以适合用于语法分析,是因为它能够很好地描述程序语言中常见的层次结构和嵌套关系,例如:
- 表达式的结构 (如
$a+b×c$ ) - 语句的结构 (如
$if-then-else$ 语句的嵌套) - 函数调用、括号匹配等
虽然有些语言的语法特性(如变量必须先声明后使用)不能完全由纯粹的上下文无关文法描述,需要在后续的语义分析阶段进行检查,但程序的骨架和主要的结构规则确实是使用上下文无关文法来定义的。因此,可以说 CFG 是语法分析阶段的核心工具。
一个 CFG 通常由四个部分组成:
- 终结符 (Terminals): 构成语言句子的基本、不可再分的符号(如编程语言中的关键字、运算符、标识符等)。
- 非终结符 (Non-terminals): 代表语言中的语法概念或结构,可以被进一步展开或替换的符号(如“表达式”、“语句”等)。
- 产生式 (Productions): 一组替换规则,形式为
$A→β$ ,其中 A 是一个非终结符,β 是由终结符和非终结符组成的序列。这意味着非终结符 A 可以被 β 替换。 - 开始符号 (Start Symbol): 一个特殊的非终结符,代表了要生成的最顶层的语法结构。
CFG 用于定义一个语言中哪些字符串是合法的,以及它们的语法结构。
用 grammar 和 input 构建一个 parse tree。
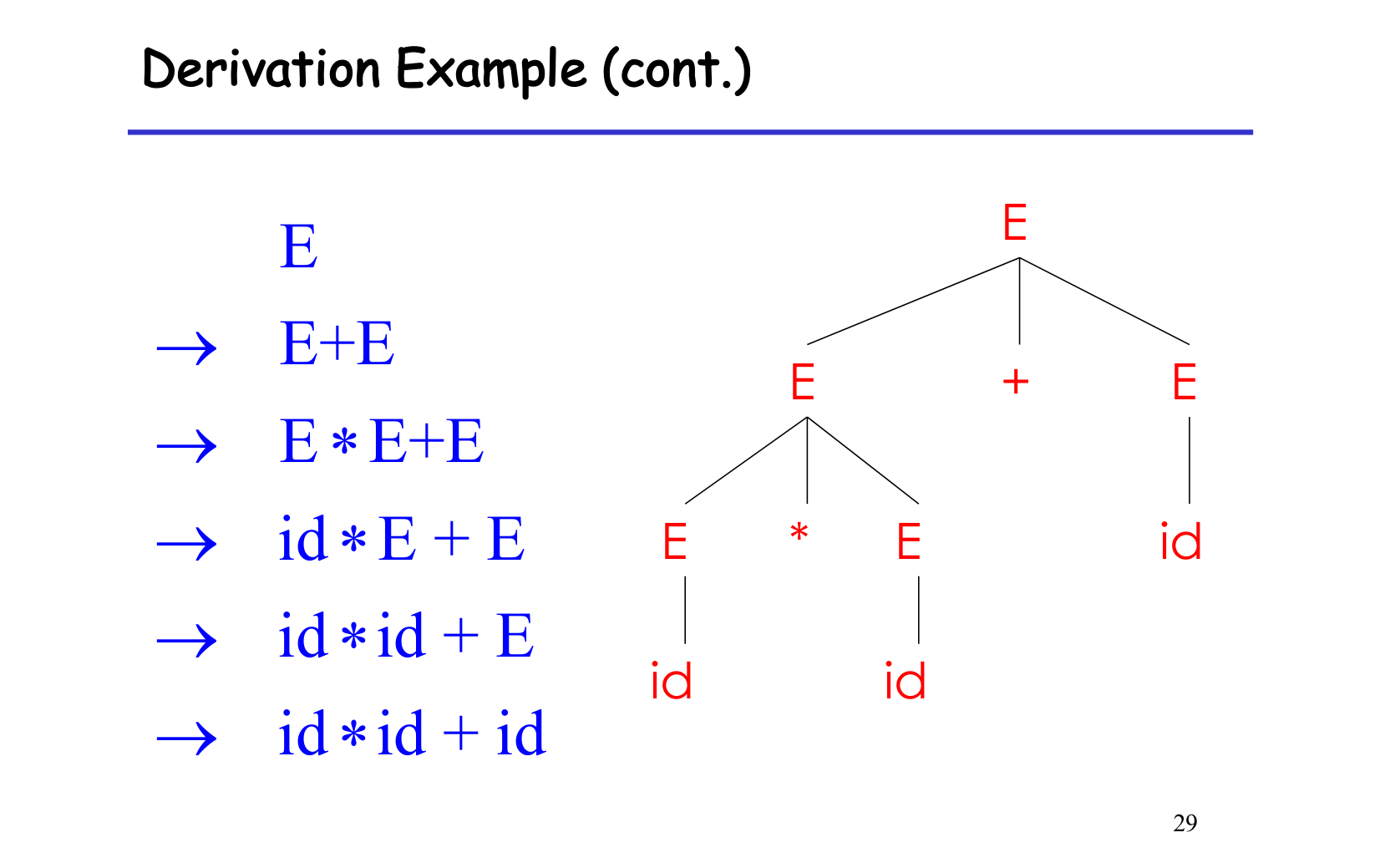
Parse tree 的性质
- Terminals 是叶节点。
- Non-terminals 是中间节点。
- 中序遍历(in-order traversal)叶节点,得到 original input。
- 展示了 operations 之间的关联关系。
derivation 可以有很多种推导顺序,但得到的 parse tree 都是一样的(对于非二义性语句,上面图片展示的就是二义性语句,需要解决优先级问题)。
常用的是:left-most 和 right-most。
当然,也可以 random 选先展开 tree 的哪一个 node。只要 parse tree 一样,结果不变。
消除二义性
消除二义性的基本思路是:修改产生式规则,强制文法只生成符合我们期望结构(即非二义性结构)的语法分析树。
1. 消除运算符优先级和结合性的二义性
问题:像 E→E+E∣E×E∣id 这样的文法,对于表达式 a+b×c,既可以解释为 (a+b)×c,也可以解释为 a+(b×c),造成二义性。这是因为它没有体现乘法优先于加法,以及运算符的结合性(比如加法和乘法通常是左结合的)。
方法:引入多个非终结符,代表不同的优先级层次。通常从最低优先级的运算符开始分层。
- 分层:
- 最低优先级(如加减 +,−):由一个非终结符(通常是
Expr或 表达式)处理。 - 较高优先级(如乘除 ×,/):由另一个非终结符(通常是
Term或 项)处理。 - 最高优先级(如括号、变量):由再一个非终结符(通常是
Factor或 因子)处理。
- 最低优先级(如加减 +,−):由一个非终结符(通常是
- 使用左递归(Left Recursion)处理左结合性: 对于左结合的运算符(如 +,−,×,/),规则写成左递归形式,如 A→A op B∣B,这会强制从左往右组合。
改写示例:
假设我们要实现乘除优先于加减,且都是左结合。
Expr -> Expr + Term | Expr - Term | Term
Term -> Term * Factor | Term / Factor | Factor
Factor -> ( Expr ) | id
解释:
Expr处理最低优先级的 +,−。Expr -> Expr + Term意味着一个表达式可以是一个表达式加上一个“项”。这确保了在处理 a+b×c 时,b×c 会被先看作一个Term,然后和a组成的Expr进行加法运算。Term处理较高优先级的 ×,/。Term -> Term * Factor类似地确保乘除的结合。Factor是最高优先级,它可以是一个带括号的表达式(强制括号内先计算)或一个基本的id(变量或常量)。
通过这种分层和左递归,文法强制了先分析出 Factor,再组合成 Term,最后组合成 Expr,从而体现了正确的优先级和结合性,消除了二义性。
2. 消除 if...else 语句的“悬空else”(Dangling Else)二义性
问题:在嵌套的 if 语句中,一个 else 子句可能既可以匹配到离它最近的内部 if,也可以匹配到外部的 if。例如:if E1 then if E2 then S1 else S2 中的 else S2 可以匹配 if E2 或 if E1,造成二义性。通常期望 else 匹配最近的 if。
文法规则示例(有二义性):
Stmt -> if Expr then Stmt else Stmt
| if Expr then Stmt
| OtherStmt方法:将语句分为两类非终结符:匹配语句 (Matched Stmt) 和 不匹配语句 (Unmatched Stmt)。
- 匹配语句: 指的是每个
if都有对应的else的语句,或者不是if语句。 - 不匹配语句: 指的是以一个没有
else的if结尾的语句。
然后,修改规则以强制 else 必须与其最近的、未匹配的 then 匹配。
改写示例:
Stmt -> MatchedStmt | UnmatchedStmt
MatchedStmt -> if Expr then MatchedStmt else MatchedStmt // 完整的 if-then-else
| OtherStmt // 其他非 if 语句
UnmatchedStmt -> if Expr then Stmt // then 后面可以是任何语句 (可能是未匹配的 if)
| if Expr then MatchedStmt else UnmatchedStmt // else 后面必须是匹配语句,然后自身是不匹配语句解释:
- 关键在于
UnmatchedStmt的规则if Expr then MatchedStmt else UnmatchedStmt。它要求在一个if...then...else...结构中,如果整个结构是一个不匹配语句(意味着外部还有一个未匹配的then需要找else),那么else后面的子语句 (MatchedStmt) 必须是“完整匹配”的,不能包含悬空的then来“抢”外部的else。而不匹配的if(if Expr then Stmt) 只能出现在最外层或者在then分支中。 - 通过这种区分,强制任何
else都只能跟随在一个MatchedStmt之后出现,而在UnmatchedStmt中,else子句必须是MatchedStmt。这确保了else总是与离它最近的那个尚未被else匹配的then关联
消除while语句二义性同理
语法分析阶段的错误处理(Error Handling)是编译器设计中至关重要的一环。当输入的源代码(通常是词法单元流)不符合编程语言的语法规则时,语法分析器必须能够:
- 报告错误 (Report errors): 清晰、准确地向用户指出错误的位置和性质。
- 从错误中恢复 (Recover from errors): 尽可能地继续分析剩余的输入,以便在一次编译中检测出多个错误,而不是在遇到第一个错误时就停止。
- 避免产生“雪崩式”错误 (Avoid spurious errors): 错误恢复机制不应导致对正确代码部分产生连锁性的虚假错误报告。
- 不显著降低正确程序的编译速度 (Not slow down correct programs): 错误处理机制不应给合法的程序带来过大的性能开销。
3 种 error handling 方法:
- Panic mode。skip 一些 input 然后尝试继续 parse 剩下的,一次 compile 检查更多的 error。
- error productions。兼容了常见 mistake 用法,但,增加了语法的复杂度,例如把5x解析为$5 * x$。
- Automatic local or global correction。理论研究用的多,工程上,现在很少用了,主要是上世纪编译代码很慢,能够自动修复有一定的合理性。
Note
parse tree对于后续的编译器阶段(如语义分析、代码生成)来说,过于冗余和复杂了。AST 是对分析树进行提炼和简化后的结果,更适合后续处理。例如分号等冗余的符号在AST中被去掉
精简了 parse tree 的一些信息。比如,括号、单个的父节点。
可以把分析树看作是语法分析器“思考过程”的完整记录,它证明了输入是如何符合语言语法的。而抽象语法树则是这个思考过程的“精华总结”,它提取了程序的核心结构和意义,为后续的编译步骤提供了一个更干净、更高效的数据结构。
-
基本原理:
- 解析器从文法的开始符号对应的函数开始执行。
- 每个非终结符 A 对应一个函数,例如 parse_A()。
- parse_A() 的任务是根据 A 的产生式规则,识别输入流中能够由 A 推导出的那部分词法单元序列。
- 如果 A 的产生式是 A -> X Y Z,那么 parse_A() 会依次调用 parse_X() (如果X是非终结符) 或匹配终结符 X (如果X是终结符),然后是 Y,再然后是 Z。
- 这种调用关系自然地形成了递归,因为一个非终结符的产生式中可能包含其他非终结符,甚至它自身(间接或直接,但直接左递归需要消除)。
-
工作流程示例: 假设有文法规则:
statement -> 'if' '(' expression ')' statement | other_statement expression -> term '+' term | term term -> 'id' | 'number'
-
当解析器需要解析一个 statement 时,它会调用 parse_statement()。
-
parse_statement() 会查看当前的输入词法单元:
- 如果是 if,它会消耗 if,然后消耗 (,然后调用 parse_expression(),然后消耗 ),最后递归调用 parse_statement() 来解析 if 语句体。
- 如果不是 if,它会尝试匹配 other_statement 的规则(调用 parse_other_statement())。
-
parse_expression() 类似地会查看输入,决定是解析 term + term 结构还是单个 term 结构,并调用 parse_term()。
-
关键要求和考虑:
- 消除左递归 (Left Recursion Elimination): 直接左递归(如 A -> A α)会导致 parse_A() 无限调用自身而不消耗任何输入,必须将其改写为右递归或使用循环。
- 左因子提取 (Left Factoring): 如果一个非终结符有多个产生式以相同的符号开头(如 A -> α β | α γ),解析器需要向前看(lookahead)更多的词法单元才能决定使用哪个产生式。左因子提取可以简化这个决策过程,通常目标是使文法成为 LL(1) 文法(只需向前看1个词法单元即可确定产生式)。
- 预测性 (Predictive Parsing): 经过适当改造(消除左递归、提取左因子)的文法,可以使得递归下降解析器在每一步都能通过查看下一个(或几个)输入词法单元来唯一确定使用哪个产生式,这种解析器称为预测性解析器。这避免了回溯(backtracking)。
-
优点:
- 直观易懂: 解析器的结构直接对应文法规则,易于理解和手动编写。
- 易于实现: 实现相对简单,不需要复杂的解析表生成工具(如 Yacc/Bison 的 LALR 表)。
- 良好的错误报告: 由于是手动编写,可以方便地在代码中加入详细和有针对性的错误诊断信息。
- 易于集成语义动作: 可以在解析函数中直接嵌入构建抽象语法树(AST)或执行其他语义动作的代码。
-
缺点:
- 文法限制: 对文法有要求,必须消除左递归,且最好能进行左因子提取以实现预测性解析。不是所有文法都适合。
- 性能(如果存在回溯): 如果文法没有很好地处理,导致需要回溯(即尝试一条路径失败后退回尝试另一条),性能会显著下降。预测性递归下降解析器则没有这个问题。
- 手动编写工作量: 对于非常大的文法,手动编写所有解析函数可能比较繁琐。
需要额外设计backtrack
解决左递归是构建自顶向下解析器(如递归下降解析器)的关键步骤,因为直接左递归会导致解析函数无限递归调用自身而不消耗任何输入。
主要有两种左递归:
-
直接左递归 (Direct Left Recursion): 形如
A -> A α | βA是一个非终结符。α和β是终结符和/或非终结符的序列。β不能以A开头。- 这种规则表示
A可以是一个β,或者是一个A后面跟着一个α(即β α,β α α,β α α α, ...)。
消除方法: 将其改写为等价的右递归形式:
A -> β A'A' -> α A' | ε(其中ε表示空串,A'是一个新的非终结符)
解释:
A -> β A':任何A的推导都必须以β开头。A' -> α A' | ε:A'代表零个或多个α序列。如果选择ε,则A就是β;如果选择α A',则A就是β α,然后A'再次决定是再加一个α还是结束。
示例: 原始文法(算术表达式,左结合):
expr -> expr + term | term消除左递归后:
expr -> term expr'expr' -> + term expr' | ε -
间接左递归 (Indirect Left Recursion): 形如
A -> B α,B -> A β,或者更长的推导链。 消除方法:- 代换: 首先将一个非终结符的产生式代入另一个,直到暴露出直接左递归。
- 消除直接左递归: 然后使用上述方法消除直接左递归。
- 这个过程可能比较复杂,需要系统地进行替换。
示例:
S -> A a | bA -> S c | d将
S的产生式代入A:A -> (A a | b) c | dA -> A a c | b c | d现在A具有直接左递归A -> A (a c) | (b c | d)。 令α = a c,β = b c | d。 消除后:S -> A a | b(不变)A -> (b c | d) A'A' -> a c A' | ε
语义动作是在语法分析过程中,当某个产生式被识别(归约)时执行的代码片段。它们通常用于构建抽象语法树 (AST)、进行类型检查、生成中间代码等。
当消除左递归时,语法树的结构会发生变化。原始的左递归结构自然地对应左结合的操作(如 a+b+c 会被解析为 ((a+b)+c))。消除左递归后,新的右递归结构会自然地对应右结合的操作(a+(b+c))。如果我们需要保持原始的左结合语义(这在算术表达式中很常见),就需要仔细设计语义动作。
示例:构建 AST 并保持左结合
考虑原始文法和其期望的语义动作 (使用类似 Yacc/Bison 的伪代码):
expr -> expr1 + term { $$ = new_node('+', $1, $3); } // expr -> term { $$ = $1; }
消除左递归后的文法:
expr -> term expr' { /* 如何组合 term 和 expr' 的结果? */ }
expr' -> + term expr1' { /* 如何组合? */ } | ε { /* 如何处理? */ }
通过参数传递(继承属性)和返回值(综合属性)来处理:
当我们将左递归转换为右递归时,expr' 的函数需要一种方式来“接收”左边的操作数(即 term 的结果),然后将它与 + term 组合,并将新的部分结果传递给下一次 expr' 的递归调用,或者在 ε 产生式时返回最终结果。
让我们用递归下降函数的思路来模拟:
// 原始左递归 (概念上)
// Node parse_expr() {
// Node left = parse_expr(); // 问题点!
// if (currentToken == '+') {
// consume('+');
// Node right = parse_term();
// return new_node('+', left, right);
// } else {
// // 假设这里有产生式 expr -> term
// return parse_term(); // 这是不完整的,简化说明
// }
// }
// 消除左递归后
Node parse_expr() {
Node term_node = parse_term(); // 对应 expr -> term expr' 中的 term
return parse_expr_prime(term_node); // 将 term_node 作为 "左操作数" 传给 expr'
}
// expr' -> + term expr1' | ε
// parse_expr_prime 接收一个 "继承的" 左操作数 (inherited_left_operand)
Node parse_expr_prime(Node inherited_left_operand) {
if (currentToken == '+') {
consume('+');
Node term_node = parse_term();
Node new_left_operand = new_node('+', inherited_left_operand, term_node); // 构建 ((a+b) ...)
return parse_expr_prime(new_left_operand); // 递归,将新的部分结果作为左操作数传递
} else {
// ε 产生式:没有更多的 '+ term' 了,返回目前为止构建的左操作数
return inherited_left_operand;
}
}
Node parse_term() {
// ... 解析 term (例如,一个标识符或数字)
// return new_leaf_node(currentTokenValue);
}解释:
parse_expr()首先解析一个term,这个term成为表达式最左边的部分。- 它将这个
term的 AST 节点作为参数(inherited_left_operand)传递给parse_expr_prime()。 parse_expr_prime()检查是否有一个+。- 如果是,它消耗
+,解析接下来的term,然后用inherited_left_operand和新解析的term_node创建一个新的 AST 节点(例如new_node('+', inherited_left_operand, term_node))。这个新节点代表了到目前为止的左结合结果(如(a+b))。然后,它递归调用parse_expr_prime(),并将这个新创建的节点作为新的inherited_left_operand传递下去,以处理可能的后续+ term(如((a+b)+c))。 - 如果不是
+(即遇到ε产生式),意味着没有更多的+ term部分了,此时inherited_left_operand就是整个左结合表达式的最终 AST,直接返回它。
- 如果是,它消耗
通过这种方式,即使文法被改写成了右递归的形式,我们仍然可以通过精心设计的参数传递(继承属性)和返回值(综合属性)来构建出代表左结合语义的 AST。
总结来说,消除左递归是语法转换,而正确处理语义动作则确保了这种转换在保留程序原始含义(如操作符结合性)的同时,能够正确地构建出所需的数据结构(如 AST)。
也是 top-down 算法。
核心是不用 backtrack 了,写 parsing 时的关键 feature。
方法是,通过 lookahead 来 predict 该选哪个 production。
简单理解
- Recursive descent 类似深度优先
- Predictive parsing 类似广度优先
Predict parser 接受 LL(k) grammar。缩写来源:
- Left-to-right
- Left-most derivations
- K tokens lookahead
一般来说使用LL(1)即可,提取production公共前缀
构造预测表:
- 使用FIRST集(产生式首符号集)和FOLLOW集(非终结符后符号集)。
- 对于文法产生式 A → α,在预测表 [A, t] 中记录 α,其中 t 是 FIRST(α) 中的终结符,或 FOLLOW(A) 中的终结符(若 α 可推空)。
- If S is start symbol then $$ \in FOLLOW(S)$。
解析过程:
- 维护一个栈,初始包含开始符号。
- 根据栈顶符号和当前输入符号,查预测表:
- 若栈顶是终结符,匹配输入并弹出。
- 若栈顶是非终结符,选择表中对应产生式,推导并压栈。
- 若表为空或无法匹配,报错。
- 重复直到栈空且输入耗尽。
- 简单高效,适合小型文法。
- 易于实现语义动作,生成语法树或执行计算。
- 解析时间线性(O(n),n为输入长度)。
- 要求文法无左递归、无二义性,且满足LL(1)条件。
- 不适合复杂的文法,可能需改写(如消除左递归)。
特点:
- 更 general & preferred
- 不用 left-factored grammar。可以 natural grammar。
3 个重要 fact
- A bottom-up parser 是 rightmost derivation 的 reverse。
- handle 只出现在 top of the stack,never inside。
- For any grammar,the set of viable prefixes is a regular language。
核心思想是:
- 从输入符号串开始。
- 不断地将输入符号(或已经形成的语法结构)移入 (Shift) 到一个分析栈中。
- 当栈顶的符号序列形成某个产生式的右部 (handle) 时,就将这个序列归约 (Reduce) 为该产生式的左部非终结符。
- 这个过程持续进行,直到所有输入都被消耗,并且栈中只剩下文法的开始符号,此时解析成功。如果无法进行下去,则说明输入串有语法错误。
关键概念:
- 分析栈 (Parse Stack): 用于存储终结符和非终结符,代表当前已识别的语法结构片段。栈底通常有一个特殊标记(如 $)。
- 输入缓冲区 (Input Buffer): 存放剩余未处理的词法单元(终结符)。末尾通常也有一个特殊标记(如 $)。
- 句柄 (Handle): 栈顶的一个符号串,它与某个产生式的右部匹配,并且将其归约为该产生式的左部非终结符是迈向完成整个推导(反向的)正确的一步。简单来说,就是当前可以被归约的子串。
-
动作 (Actions):
- 移入 (Shift): 将输入缓冲区的第一个符号移到分析栈的栈顶。
- 归约 (Reduce): 当栈顶形成一个句柄 α(即存在产生式 A -> α),将 α 从栈中弹出,然后将 A 压入栈中。这个动作通常伴随着语义动作的执行(如构建AST节点)。
- 接受 (Accept): 当输入缓冲区为空,且栈中只剩下开始符号时,解析成功。
- 错误 (Error): 当无法执行上述任何一个合法动作时,报告语法错误。
工作流程示例:
假设有文法:
- E -> E + T
- E -> T
- T -> id
输入串:id + id $ ( $ 是结束标记)
| 栈 (Stack) | 输入 (Input) | 动作 (Action) |
|---|---|---|
| $ | id + id $ | Shift |
| $ id | + id $ | Reduce by T -> id |
| $ T | + id $ | Reduce by E -> T (选择这个还是等待?这是冲突点) 假设选择Reduce |
| $ E | + id $ | Shift |
| $ E + | id $ | Shift |
| $ E + id | $ | Reduce by T -> id |
| $ E + T | $ | Reduce by E -> E + T |
| $ E | $ | Accept |
核心挑战:
移入-归约解析的主要挑战在于决定何时移入以及何时归约,特别是当栈顶的符号串可以有多种归约方式,或者既可以移入也可以归约时,就会产生冲突 (Conflicts):
- 移入-归约冲突 (Shift-Reduce Conflict): 解析器既可以选择移入下一个输入符号,也可以选择将栈顶的句柄归约。例如,在C语言中解析
if (expr) if (expr) s1; else s2;时的 "dangling else" 问题。 - 归约-归约冲突 (Reduce-Reduce Conflict): 栈顶的符号串可以匹配多个产生式的右部,解析器不知道应该使用哪个产生式进行归约。
| 冲突类型 | 原因 | 解决方法 |
|---|---|---|
| 移入-规约 | 既可移入又可规约 | 1. 定义优先级和结合性 2. 默认移入 3. 修改文法 |
| 规约-规约 | 多个产生式可规约 | 1. 合并或调整文法 2. 用 %prec 指定优先级 3. 使用 LALR(1) 或 GLR |
常见的移入-归约解析算法:
- LR(k) 解析器:
- L: 从左到右扫描输入 (Left-to-right scan of input)。
- R: 构建最右推导的逆过程 (Rightmost derivation in reverse)。
- k: 向前看 k 个输入符号来做决策。
- 常见的 LR 解析器类型包括:
- LR(0): 最简单,但能力有限,很多实用文法无法处理。
- SLR(1) (Simple LR): 比 LR(0) 强大,但仍有一些限制。
- LALR(1) (Look-Ahead LR): 介于 SLR(1) 和 Canonical LR(1) 之间,解析表大小适中,能力较强,是 Yacc/Bison 等工具的默认选择。
- Canonical LR(1) (CLR(1)): 最强大,但解析表可能非常大。
这些算法通过预先构建一个解析表 (Parse Table) 来指导移入或归约的决策。解析表根据当前栈顶状态和下一个(或 k 个)输入符号来确定要执行的动作。
优点:
- 能力强大: 可以处理比 LL 解析器更大范围的文法(特别是 LR(1) 及其变种)。
- 高效: 对于无二义性文法,LR 解析器通常非常高效。
- 自动生成: 有成熟的工具(如 Yacc, Bison, ANTLR 的部分模式)可以从文法自动生成 LR 解析器。
缺点:
- 手动构造困难: 手动构造 LR 解析表非常复杂且容易出错。
- 错误定位: 相较于递归下降,LR 解析器在发生错误时,定位错误原因可能不那么直观,因为它是在找到一个完整句柄后才报错,可能已经移入了很多符号。
- 文法要求: 虽然比 LL 宽松,但仍要求文法是无二义性的,并且能够解决所有移入-归约和归约-归约冲突(通常通过文法改写或指定优先级/结合性规则)。
SLR(1) 解析(Simple LR(1) Parsing)是自底向上(Bottom-Up)语法分析方法中的一种,属于 LR 解析器家族的变体。它在 LR(0) 解析器的基础上引入了向前看(Lookahead)符号来改进归约决策,从而能够处理比 LR(0) 更广泛的文法。
核心概念:
-
基于 LR(0) 项集: SLR(1) 的状态(解析器在某个时刻的配置)是基于 LR(0) 项集(Set of LR(0) Items)构建的。LR(0) 项表示一个产生式和一个圆点
., 表示在解析该产生式的右部时,已经匹配到圆点的位置。 例如:A -> α . β表示我们正在尝试匹配产生式A -> αβ,并且已经成功匹配了α。 -
向前看符号 (Lookahead): SLR(1) 使用一个 (1) 向前看符号。这意味着解析器在做决策时,不仅看栈顶的状态,还会看输入流中的下一个词法单元。
-
归约决策的改进: 这是 SLR(1) 和 LR(0) 的主要区别。
- 在 LR(0) 中,如果一个状态包含一个圆点在末尾的项(例如
A -> α .),它就 立即 尝试归约使用产生式A -> α,无论下一个输入符号是什么。这导致许多冲突。 - 在 SLR(1) 中,如果一个状态包含一个项
A -> α .,解析器并不会立即归约。它会查看下一个输入符号(向前看符号)。只有当这个向前看符号属于非终结符A的 FOLLOW 集合 (FOLLOW(A)) 时,解析器才会执行归约A -> α。 - FOLLOW(A) 集合包含所有可能紧跟在非终结符
A后面的终结符。
- 在 LR(0) 中,如果一个状态包含一个圆点在末尾的项(例如
-
解析表 (Parse Table): 像所有 LR 解析器一样,SLR(1) 依赖一个由工具自动生成的解析表来指导其行为。解析表有两个部分:
- ACTION 表:
ACTION[状态][终结符]决定了在当前状态下,如果下一个输入符号是某个终结符时,是执行移入 (Shift)、归约 (Reduce)、接受 (Accept) 还是报告错误 (Error)。 - GOTO 表:
GOTO[状态][非终结符]决定了在当前状态下,如果将栈顶的一串符号归约成某个非终结符后,解析器应该转移到哪个新状态。
- ACTION 表:
工作流程:
- 解析器维护一个栈,栈中存放状态和文法符号。
- 初始时,栈中只有起始状态。
- 解析器查看栈顶状态和当前输入符号(向前看符号)。
- 根据解析表中的
ACTION[当前状态][当前输入符号]入口执行操作:- Shift s: 将当前输入符号压栈,然后将状态
s压栈,并移动输入指针到下一个符号。 - Reduce A -> α: 假定 α 的长度是 |α|,从栈中弹出 |α| 个符号及对应的状态。查看栈顶的新状态
s',根据GOTO[s'][A]找到新状态s''。将非终结符A压栈,然后将状态s''压栈。执行与产生式A -> α相关的语义动作。 - Accept: 解析成功。
- Error: 报告错误并进入错误恢复流程。
- Shift s: 将当前输入符号压栈,然后将状态
SLR(1) 的特点:
- 能力: 比 LR(0) 强大,能够解析更多的文法,但不如 LALR(1) 或 LR(1) 强大。
- 简单性: 相比 LR(1),SLR(1) 的解析表构建相对简单,因为它只需要计算非终结符的全局
FOLLOW集合,而不是为每个项计算上下文相关的向前看集合。 - 冲突: 如果在构建解析表时,某个
ACTION[状态][终结符]入口既包含移入动作又包含归约动作(移入-归约冲突),或者包含多个归约动作(归约-归约冲突),则该文法不是 SLR(1) 文法。SLR(1) 通过使用FOLLOW集合解决了 LR(0) 的一些冲突,但并不能解决所有冲突。特别是在不同状态下,同一个产生式A -> α可能有效,但它在某些状态下的FOLLOW符号集合是不同的,SLR(1) 无法区分这种情况,因为它是用全局FOLLOW(A)来检查的。
在 SLR(1) 中,冲突的判断基于当前状态(由 LR(0) 项集表示)和下一个输入符号(向前看符号),并且归约操作的合法性还需要检查向前看符号是否在待归约非终结符的 FOLLOW 集合中。
定义: 在某个解析状态下,对于下一个输入符号 a,解析器既可以执行移入 a 的动作,也可以执行某个产生式 A -> α 的归约动作,且 a 属于 FOLLOW(A)。
示例文法:
- S -> A 'b'
- A -> 'a'
- C -> 'a' 'b'
输入串: 'a' 'b' $ ( $表示输入结束)
冲突发生过程:
- 移入 'a': 栈: $ 输入: 'a' 'b' $ -> 栈: $ 'a' 输入: 'b' $
- 现在解析器处于一个状态,这个状态是通过看到符号 'a' 达到的。这个状态对应的 LR(0) 项集可能包含:
- A -> 'a' . (我们看到了一个 'a',这可能是一个完整的 A)
- C -> 'a' . 'b' (我们看到了一个 'a',这可能是产生式 C -> 'a' 'b' 的开头部分)
- 下一个输入符号是 'b'。
-
判断动作:
- 移入? 状态中包含项 C -> 'a' . 'b'。点 . 后面是终结符 'b',这与下一个输入符号 'b' 匹配。所以,解析器可以选择 移入 'b'。
-
归约? 状态中包含项 A -> 'a' .。这是一个待归约项(点在末尾)。需要检查下一个输入符号 'b' 是否在 FOLLOW(A) 集合中。
- 根据规则 S -> A 'b',非终结符 A 后面直接跟着终结符 'b'。所以,'b' 属于 FOLLOW(A)。
- 因为 'b' 在 FOLLOW(A) 中,所以解析器也可以选择用产生式 A -> 'a' 进行 归约。
结论: 在栈为 $ 'a',下一个输入符号为 'b' 时,解析器面临选择:是移入 'b' (匹配 C -> 'a' 'b') 还是归约 'a' 为 A (匹配 S -> A 'b')?由于 'b' 既是 C -> 'a' . 'b' 后面的符号,又在 FOLLOW(A) 中,所以这是一个移入-归约冲突。SLR(1) 解析器无法决定,这个文法不是 SLR(1) 文法。
定义: 在某个解析状态下,对于下一个输入符号 a,解析器可以执行产生式 A -> α 的归约动作,也可以执行另一个产生式 B -> β 的归约动作,且 a 同时属于 FOLLOW(A) 和 FOLLOW(B)。
示例文法:
- S -> A 'a'
- S -> B 'a'
- A -> 'b'
- B -> 'b'
输入串: 'b' 'a' $
冲突发生过程:
- 移入 'b': 栈: $ 输入: 'b' 'a' $ -> 栈: $ 'b' 输入: 'a' $
- 现在解析器处于一个状态,这个状态是通过看到符号 'b' 达到的。这个状态对应的 LR(0) 项集可能包含:
- A -> 'b' . (我们看到了一个 'b',这可能是一个完整的 A)
- B -> 'b' . (我们看到了一个 'b',这可能是一个完整的 B)
- 下一个输入符号是 'a'。
-
判断动作:
-
归约 1? 状态中包含项 A -> 'b' .。需要检查下一个输入符号 'a' 是否在 FOLLOW(A) 中。
- 根据规则 S -> A 'a',非终结符 A 后面直接跟着终结符 'a'。所以,'a' 属于 FOLLOW(A)。
- 因为 'a' 在 FOLLOW(A) 中,解析器可以选择用产生式 A -> 'b' 进行 归约。
-
归约 2? 状态中包含项 B -> 'b' .。需要检查下一个输入符号 'a' 是否在 FOLLOW(B) 中。
- 根据规则 S -> B 'a',非终结符 B 后面直接跟着终结符 'a'。所以,'a' 属于 FOLLOW(B)。
- 因为 'a' 在 FOLLOW(B) 中,解析器也可以选择用产生式 B -> 'b' 进行 归约。
-
归约 1? 状态中包含项 A -> 'b' .。需要检查下一个输入符号 'a' 是否在 FOLLOW(A) 中。
结论: 在栈为 $ 'b',下一个输入符号为 'a' 时,解析器面临选择:是归约 'b' 为 A (匹配 S -> A 'a') 还是归约 'b' 为 B (匹配 S -> B 'a')?由于 'a' 同时在 FOLLOW(A) 和 FOLLOW(B) 中,所以这是一个归约-归约冲突。SLR(1) 解析器无法决定,这个文法不是 SLR(1) 文法。
All identifiers are declared 树状结构+堆栈解决+符号表管理
Types 能够进行什么操作 ;类型信息分动态和静态 逻辑推理规则