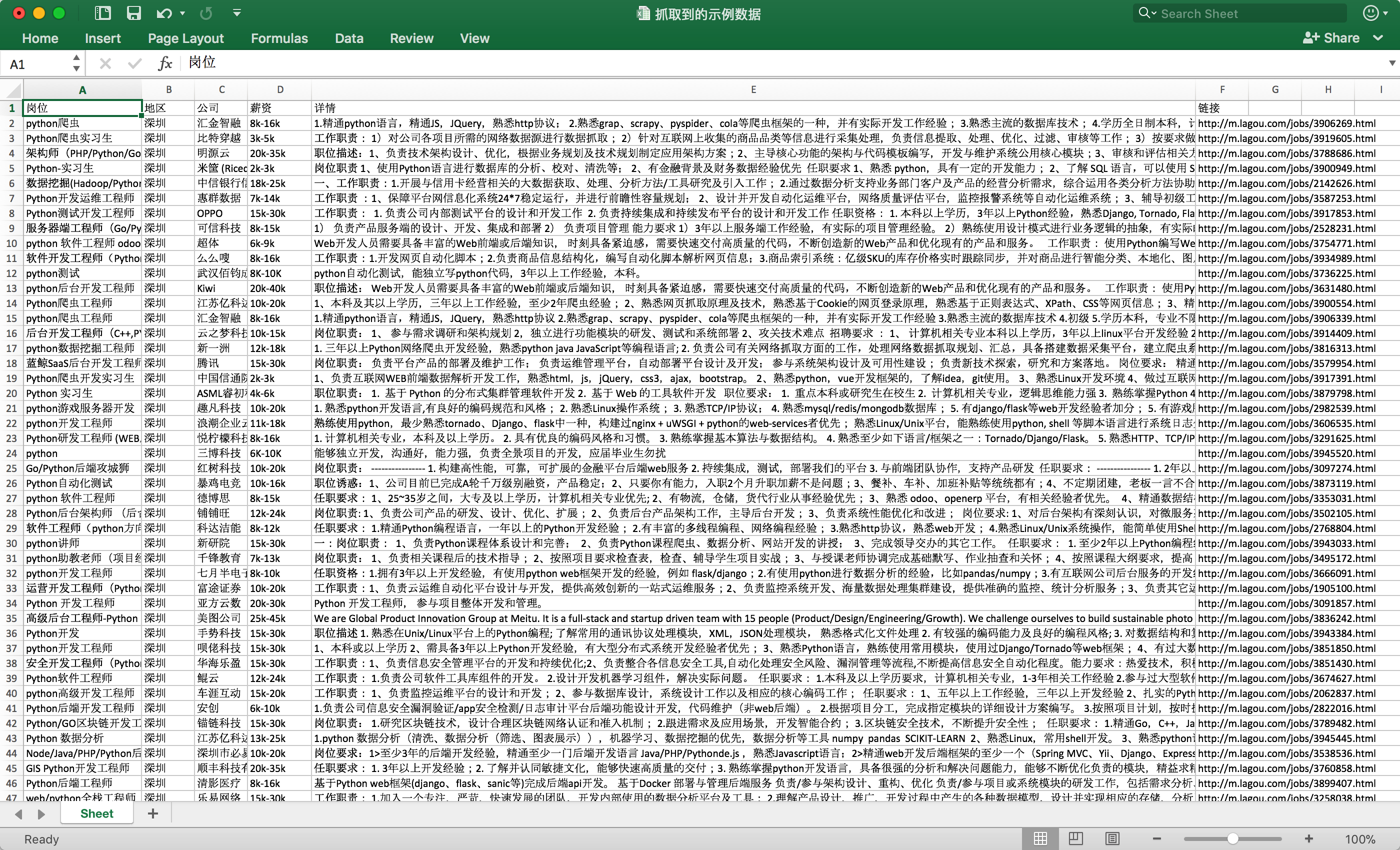
先使用单线程爬虫抓取岗位之后,之后又使用了Scrapy框架编写抓取拉勾岗位信息的爬虫,抓取数万条岗位数据。
单线程版本v1需求(100%完成):
- 拉勾网定向爬虫
- 实现关键字岗位的抓取,例如抓取广州的所有Python岗位,全国的所有产品经理岗位等。
- 单线程爬虫,不采用代理,采用timesleep方式抓取多个
scrapy版本v1需求(100%实现):
- 拉勾网定向爬虫
- 实现关键字岗位的抓取,例如抓取广州的所有Python岗位,全国的所有产品经理岗位等。
- 支持Request请求的user-agent轮转设置(编写下载器中间件)
- 支持IP代理,为此特地写了一个自动获取实时可用代理IP池的库 https://github.com/defland/FreeIPAgentPool.py (其实就是爬虫,爬多个免费代理IP网站,抓取可用代理IP和验证之后返回可用list) ,实现方式为编写下载器中间件
- 支持保存到Excel
- 支持保存到Mongodb数据库
Catspider version (计划中)
- catspider是为了熟悉爬虫,自己仿造scrapy类似自己做url队列管理、下载器管理、分析器管理、持久化存储的微信通用爬虫工具包。
- https://github.com/defland/CatSpider
- 使用catspider mvp version重构此爬虫