- 大数据是一门以Hadoop为代表的大数据平台框架上进行各种数据分析的技术
- 大数据平台基础框架包括了Hadoop和Spark为代表的基础大数据框架
- 各种数据分析技术包括实事数据处理技术、离线处理技术;数据分析、数据挖掘和用机器算法进行预测分析等技术
- Hadoop是一个开源的大数据框架
- Hadoop是一个分布式计算的解决方案
- Hadoop = HDFS(分布式文件系统) + MapReduce(分布式计算)

1.数据块:存储在HDFS上的文件是按块存储的
数据块是抽象块而非整个文件作为存储单元
默认大小是64MB,一般设置为128M,备份X3
2.NameNode:管理文件系统的命名空间,存放文件元数据
维护文件系统所有文件和目录,文件与数据块之间的映射
记录每个文件中各个数据块所在的数据节点信息
(文件与数据库的映射表、数据库与数据节点的映射表)
3.DataNode:存储并检索数据库
向NameNode更新所存储的列表
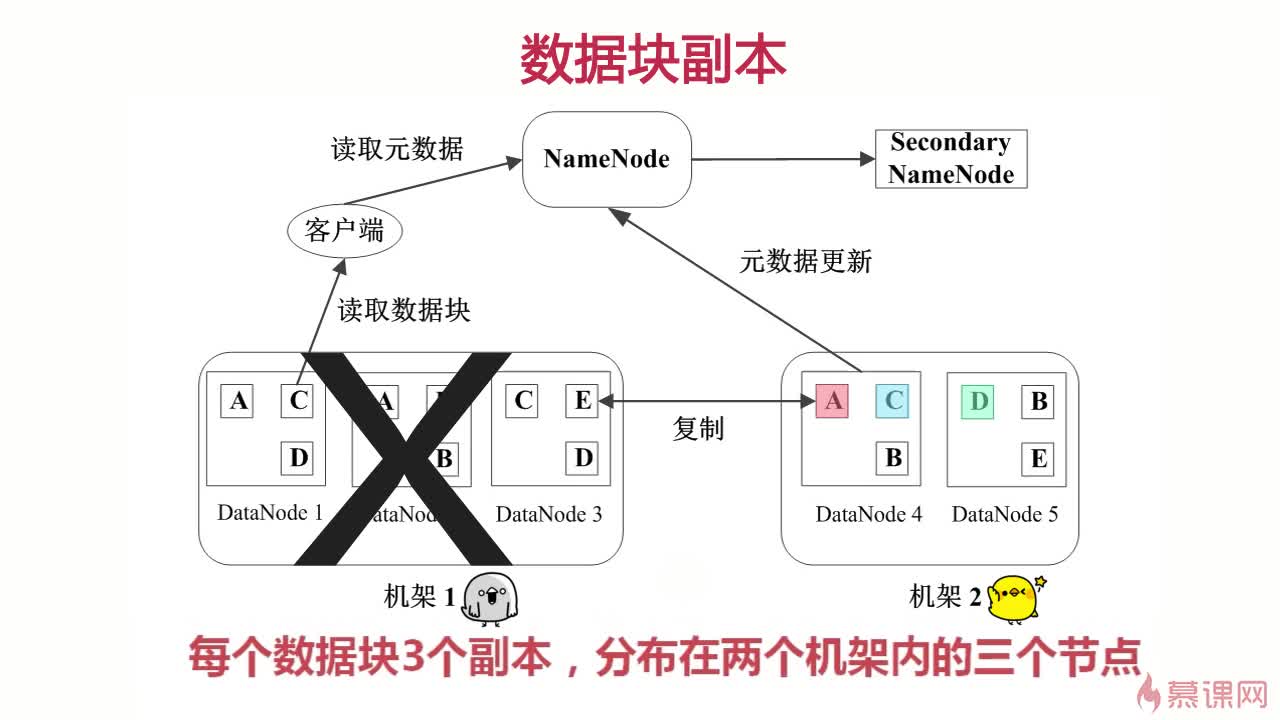
1. 多副本,保证高可用
2. 心跳检测,实时监控
3. 二级NameNode,保证元数据高可用


1.适合大文件存储,支持TB、PB级的数据存储,并有副本策略
2.可以构建在廉价的机器上,并有一定的容错和恢复机制
3.支持流式数据访问,一次写入,多次读取最高效
1.不适合大量小文件存储
2.不适合并发写入,不支持文件随机修改
3.不支持随机读等低延时的访问方式

- 客户端向NameNode发起写数据请求
- 分块写入DataNode节点,DataNode自动完成副本备份
- DataNode向NameNode汇报存储完成,NameNode通知客户端
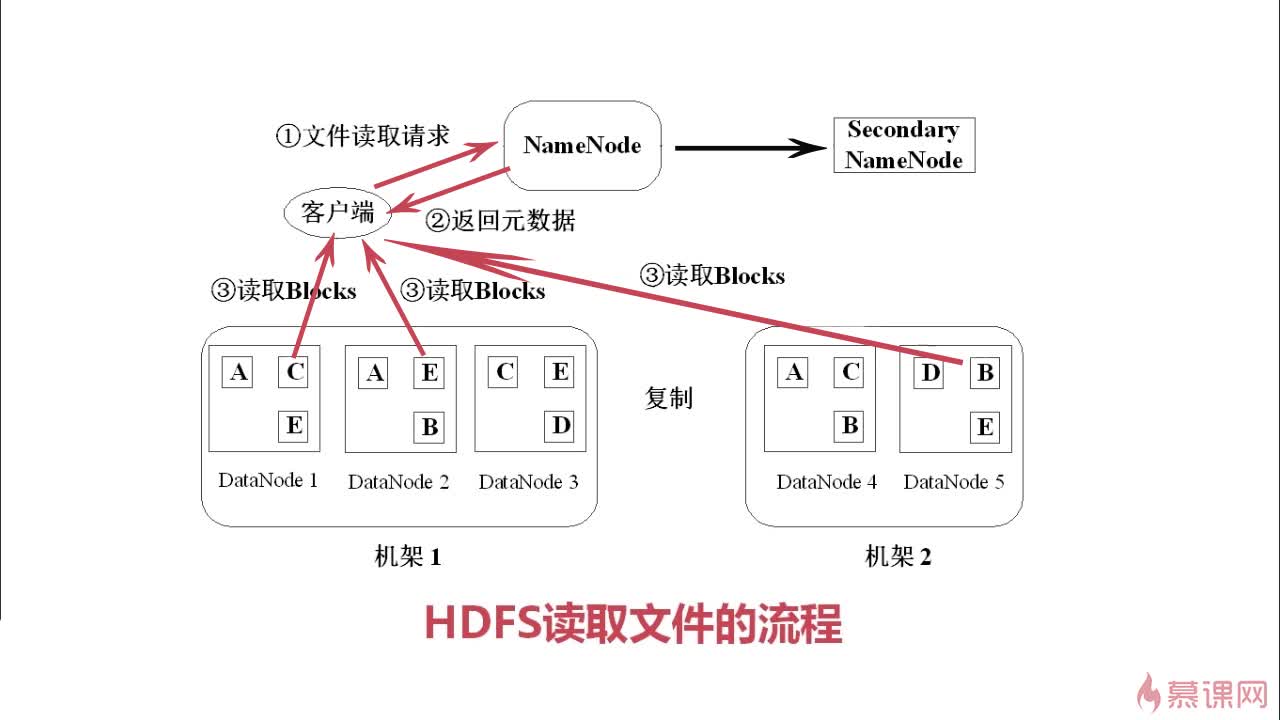
- 客户端向NameNode发起读数据请求
- NameNode找出距离最近的DataNode节点信息
- 客户端从DataNode分块下载文件
类Linux系统: ls、cat、mkdir、rm、chmod、chown等
HDFS文件交互: copyFromLocal 从本地向hdfs文件系统拷贝
copyToLocal hdfs文件系统向本地拷贝
get 下载文件
put 上传文件
hadoop存放文件命令 hadoop fs -put hadoop-env.sh /input
hadoop获取文件命令 hadoop fs -get
hadoop删除文件命令 hadoop fs -rm
hadoop创建目录命令 hadoop fs -mkdir
hadoop 格式化操作 hadoop namenode -formet
hadoop查看存储信息 hadoop dfsadmin -report
mapReduce:分而治之的原理,既将大的任务分解成各个小的任务,既所谓的map,然后将各个小任务的处理结果进行合并,合并汇总称之为 reduce.
1、mapreduce是一个并行计算的框架
2、map将任务分解成多个子任务,reduce将子任务并行执行后合并结果
3、mapreduce的过程:input split->shuffle->output

基本概念:
Job & Task
JobTracker
TaskTracker
一个 Job(任务、作业) 被切分为多个 Task,Task 又分为 MapTask 和 ReduceTask




1. 重复执行
默认重复执行 4 次,若还是失败,则放弃执行
2. 推测执行
个别节点执行过慢的话,会重启一个同样的任务,只要其中一个执行完,其他就被终止掉。可以保证任务不会因为某1-2个机器错误 或故障而导致整体效率下降