一个统计文本中单词有多少个的小脚本
更新了新的功能 - 计算每个单词一共出现多少次(并没有完全做对比,单词太多了。)
gcc -o count count.c
./count a.txt
通讯录功能。
gcc -o contacts contacts.c
./contacts
- 输入用户 name & phone number
- 打印刚刚所有插入的用户
- delete 所输入的 用户
- search 用户
- save 用户至自定义文件
- load 加载文件并读取里面的用户信息
基础的多线程编程,分别尝试使用了
互斥锁 mutex
自旋锁 spinlock
原子操作 _asm_ volatile()
gcc -o lock lock.c -lpthread
./lock
线程池的创建
注意mutex & pthread_cond_wait() pthread_cond_broadcast() 等关键函数的调用
消化好本项目过程中接口之间的传递,线程之间的转换过程的写法和原理。
了解好 gdb 调试,学会如何使用 gdb
gcc -o pthreadpool pthreadpool.c -lpthread -g
./pthreadpool
gdb 调试gcc -o pthreadpool pthreadpool.c -lpthread -g gdb ./pthreadpool b xxx(行) (breakpoint) b 124 r (runing) c (continue)
创建数据库
使用数据库
创建表格
gcc -o Mysql Mysql.c -I /user/include/mysql/ -lmysqlclient -I 系统头文件 -lmysqlclient: 引入我们编译中使用的库
#include <mysql.h>
可能找不到
如果确实存在 /user/include/mysql/mysql.h
就改成
#include <mysql/mysql.h>
如果在上面的目录没有找到mysql.h文件,需要安装mysql-devel但是注意在ubuntu下安装mysql-devel命令:sudo apt-get install libmysqld-dev
如果你不想将#include<mysql.h>改成#include <mysql/mysql>的话,而且你是用的gcc编译的话,那么可以这样
gcc -I/user/include/mysql
# DELETE FROM TBL_USER WHERE U_NAME='Mayc'; # 提醒不安全,因为可能会同时有多条数据被删除
-- SET SQL_SAFE_UPDATES=0; # 设置成安全模式, 三条语句同时做
-- DELETE FROM TBL_USER WHERE U_NAME='Mayc';
-- SET SQL_SAFE_UPDATES=1;
sql -->
# 更好的方式
DELIMITER $$
CREATE PROCEDURE PROC_DELETE_USER(IN UNAME VARCHAR(32))
BEGIN
SET SQL_SAFE_UPDATES=0; # 设置成安全模式, 三条语句同时做
DELETE FROM TBL_USER WHERE U_NAME=UNAME;
SET SQL_SAFE_UPDATES=1;
END$$
CALL PROC_DELETE_USER('qiuxiang')
主要的思路还是根据之前的pthread_pool来进行改写。
需要注意的地方是,既然是多连接池,那么就肯定会应用到多线程。技术能力不够,在这里就没有再去做一个线程池配合,单纯的就是为每一个数据库连接配了一个线程
threadid。我将整个过程分为如下几个部分:
- 数据库连接结构体的创建
- 用于管理数据库的相当于管理员的结构体,用来管理创建的数据库连接
- 创建定量的数据库连接 --- 并且用链表连接管理,配合
管理员结构体- 配合多线程进行并发处理,要注意临界资源的锁控制。
- 将之前的
mysql的一些操作函数封装在struct tast结构体中,并作为任务分配给每一个数据库连接, 每有一个新的task需要唤醒一个数据库连接(等同于唤醒一个线程),或者说是从数据库连接池中取出一个空闲的连接。完成task之后要释放,也就是将一个数据库连接回收到连接池

查询名:
长度不固定,且不使用填充字节,一般该字段表示的就是需要查询的域名(如果是反向查询,则为IP,反向查询即由IP地址反查域名),一般的格式如下图所示

0voice.com; name:60voice3com
www.0voice.com; name:3www60voice3com
在网络中,就是将 dns_head 和 dns_question 两个结构体内的信息发送给dns服务器

在C/C++写网络程序的时候,往往会遇到字节的网络l顺序和主机顺序的问题。这是就可能用到htonl(), ntohl(), ntohs(),htons()这4个函数。 网络字节顺序与本地字节顺序之间的转换函数:
htonl()--"Host to Network Long" ntohl()--"Network to Host Long" htons()--"Host to Network Short" ntohs()--"Network to Host Short"
字符串切分 strtok(string, delim) -- strtok(www.0voice.com, ".");
- string -- 需要切分的字符串,
- delim -- 规则
在后续接着切分的时候变成 strtok(nullptr, delim), 由此可发现,该函数是一个线程非安全函数
strncpy(qname, token, len + 1)
和 strcpy() 不同,strncpy() 需要指定长度
dns客户端比较固定的写法
int dns_client_commit(const char* domain){
int sockfd = socket(AF_INET, SOCK_DGRAM, 0);
if(sockfd < 0) return -1;
struct sockaddr_in servaddr = { 0 };
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(DNS_SERVER_PORT);
servaddr.sin_addr._addr = inet_addr(DNS_SERVER_IP);
struct dns_header header = { 0 };
dns_create_header(&header);
struct dns_question question = { 0 };
dns_create_question(question, domain);
char request[1024] = { 0 };
int length = dns_build_requestion(&header, question, request);
//request
sendto(fd, request, length, 0, servaddr, addr_len);
}dns_build_requestion(struct dns_header* header, struct dns_question* question, char* request, int rlen)
将header和question的数据打包并返回包长度
int dns_build_requestion(struct dns_header* header, struct dns_question* question, char* request, int rlen){
if(header == nullptr || dns_question == nullptr || request == nullptr) return -1;
memset(request, 0, rlen);
// header --> request
memcpy(request, header, sizeof(struct dns_header));
int offset = sizeof(struct dns_header);
// question --> request
memcpy(request+offset, question->qname, question->length);
offset += question->length;
memcpy(requestion+offset, question->qtype, sizeof(question->qtype));
offset += sizeof(question->qtype);
memcpy(requestion+offset, question->qclass, sizeof(question->qclass));
offset += sizeof(question->qclass);
return offset;
}send() 和 recvfrom() 是一个流程的操作,属于同步操作,在recvfrom()和sendto()之间自动加锁,完成接收才结束
- UDP传输速度快 (下载)
- UDP相应速度快 (游戏)
引入epoll,以下是 epoll 的接口介绍
-
int epoll_create(int size);创建一个
epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。(这里我就遇到了相反的麻烦,提前把epoll给关闭了) -
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,第二个参数表示动作,用三个宏来表示:-
EPOLL_CTL_ADD:注册新的fd到epfd中;
-
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
-
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的
fd,第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:
-
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
- EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
- EPOLLOUT:表示对应的文件描述符可以写;
- EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
- EPOLLERR:表示对应的文件描述符发生错误;
- EPOLLHUP:表示对应的文件描述符被挂断;
- EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
-
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);epoll的事件注册函数,epoll_ctl向epoll对象中添加、修改或者删除感兴趣的事件,返回0表示成功,否则返回–1,此时需要根据errno错误码判断错误类型。等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0 会立即返回,-1 将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
- 第1个参数 epfd是 epoll的描述符。
- 第2个参数 events则是分配好的 epoll_event结构体数组,==epoll将会把发生的事件复制到 events数组中(events不可以是空指针,内核只负责把数据复制到这个 events数组中,不会去帮助我们在用户态中分配内存。内核这种做法效率很高)==。
- 第3个参数 maxevents表示本次可以返回的最大事件数目,通常 maxevents参数与预分配的events数组的大小是相等的。
- 第4个参数 timeout表示在没有检测到事件发生时最多等待的时间(单位为毫秒),如果 timeout为0,则表示 epoll_wait在 rdllist链表中为空,立刻返回,不会等待。
fcntl() 用来操作文件描述符(进程的文件描述符, 相关细节在 《UNIX环境高级编程》p392 中可以查询)的一些特性。
cmd 是 F_GETLK、F_SETLK 或 F_SETLKW。
为文件的本次打开操作和后续的 I/O 操作设置非阻塞方式。
和百度的服务器连接
- 建立TCP连接
- 在TCP连接,socket的基础上,向百度服务器发送http协议请求
- 服务器在TCP连接socket,返回http协议 -- response

GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3
OpenSSL/0.9.1l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi- www.baidu.com --> 翻译为 ip 地址。 DNS
- TCP 连接这个 ip 地址: 端口
- 发送 http 协议
API -- gethostbyname()定义:返回对应于给定主机名的包含主机名字和地址信息的
hostent结构的指定指针。struct hostent{ char *h_name; char ** h_aliases; short h_addrtype; short h_length; char ** h_addr_list; } struct hostent* gethostbyname(const char* name){ err_t err; ip_addr_t addr; /* buffer variables for lwip_gethostbyname */ HOSTENT_STORAGE struct hostent s_hostent; HOSTENT_STORAGE char *s_aliases; HOSTENT_STORAGE ip_addr_t s_hostent_addr; HOSTENT_STORAGE ip_addr_t *s_phostent_addr[2]; /* query host IP address */ err = netconn_gethostbyname(name, &addr); if (err != ERR_OK) { LWIP_DEBUGF(DNS_DEBUG, ("lwip_gethostbyname(%s) failed, err=%d\n", name, err)); h_errno = HOST_NOT_FOUND; } return NULL; }
inet_ntoa()将unsigned int --> char*
http_create_socket(char* ip)创建socket用于连接相应的服务器,ip来自于gethostbyname()创建
socket和sockadd_in结构体连接 connect(sockfd, (struct sockaddr*)&sin, sizeof(struct sockaddr_in))
设置非阻塞I/O
fcntl(sockfd, F_SETFL, O_NONBLOCK);
int http_send_request(const char* hostname, const char* resource)hostname: github.com resource: /artintel
通过函数获取ip地址
host_to_ip(const char* hostname);建立连接
http_create_socket()发送
socketsend(sockfd, buffer, strlen(buffer), 0);接收
response
select检测,监听, 网络io里是否有可读的数据
select(maxfd + 1, &rset, &wset, &eset, NULL);
maxfd:可监听的最大sockfd数量rset:哪些 I/O 可读wset:哪些 I/O 可写eset:哪些 I/O 出错NULL:多长时间轮询一次
$ gcc -o http_request http_request.c -lpthread
$ ./http_request www.baidu.com /- 并发服务器
- 一请求一线程 (已不被推崇)
- IO 多路复用, epoll
- TCP服务器百万级连接

申请一个 int sockfd = socket(AF_INET, SOCK_STREAM, 0);
初始化一个实例 sockaddr_in
struct sockaddr_in addr;
memset(&addr, 0, sizeof(struct sockaddr_in));
add.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = INADDR_ANY;
bind();
将一本地地址与一套接字捆绑。本函数适用于未连接的数据报或流类套接字,在
connect()或listen()调用前使用。当用socket()创建套接字后,它便存在于一个名字空间(地址族)中,但并未赋名。bind()函数通过给一个未命名套接字分配一个本地名字来为套接字建立本地捆绑(主机地址/端口号)。
bind(sockfd, (struct sockaddr*)&addr, sizeof(struct sockaddr_in))
listen();
创建一个套接字并监听申请的连接
#include <sys/socket.h> int listen(int sockfd, int backlog); // sockfd: 用于标识一个已捆包未连接套接字的文件描述符 // backlog: 等待连接队列的最大长度
accept();
accept()接收一个套接字中已建立的连接,来自客户端的连接。accept()是c语言中网络编程的重要的函数,本函数从s的等待连接队列中抽取第一个连接,创建一个与s同类的新的套接字并返回句柄。提取出所监听套接字的等待连接队列中第一个连接请求,创建一个新的套接字,并返回指向该套接字的文件描述符。
新建立的套接字不再监听状态,原来所监听的套接字也不受该系统调用的影响。
新建立的套接字准备发送
send()和接收数据recv()。SOCKET accept( SOCKET s, struct sockaddr FAR *addr, int FAR *addrlen );
addr用于存放客户端的地址,addrlen在调用函数时被设置为addr指向区域的长度,在函数调用结束后被设置为实际地址信息的长度。本函数会阻塞等待知道有客户端请求到达。返回值是一个新的套接字描述符,它代表的是和客户端的新的连接,可以把它理解成是一个客户端的
socket,这个socket包含的是客户端的ip和port信息 。(当然这个new_socket会从sockfd中继承服务器的ip和port信息),而参数中的SOCKET s包含的是服务器的ip和port信息 。
单纯的 sockfd 无法解决多个客户端连接时,如何分辨的问题
可通过应用层协议来解决
-
int epoll_create(int size);创建一个
epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。 -
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,第二个参数表示动作,用三个宏来表示:-
EPOLL_CTL_ADD:注册新的fd到epfd中;
-
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
-
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的
fd,第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:
-
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
- EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
- EPOLLOUT:表示对应的文件描述符可以写;
- EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
- EPOLLERR:表示对应的文件描述符发生错误;
- EPOLLHUP:表示对应的文件描述符被挂断;
- ==EPOLLET==: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
epoll事件有两种模型,边沿触发:edge-triggered (ET), 水平触发:level-triggered (LT)
socket接收缓冲区不为空 有数据可读 读事件一直触发 socket发送缓冲区不满 可以继续写入数据 写事件一直触发 边沿触发(edge-triggered)
socket的接收缓冲区状态变化时触发读事件,即空的接收缓冲区刚接收到数据时触发读事件 socket的发送缓冲区状态变化时触发写事件,即满的缓冲区刚空出空间时触发读事件 边沿触发仅触发一次,水平触发会一直触发。
-
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);epoll的事件注册函数,epoll_ctl向epoll对象中添加、修改或者删除感兴趣的事件,返回0表示成功,否则返回–1,此时需要根据errno错误码判断错误类型。等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0 会立即返回,-1 将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
- 第1个参数 epfd是 epoll的描述符。
- 第2个参数 events则是分配好的 epoll_event结构体数组,==epoll将会把发生的事件复制到 events数组中(events不可以是空指针,内核只负责把数据复制到这个 events数组中,不会去帮助我们在用户态中分配内存。内核这种做法效率很高)==。
- 第3个参数 maxevents表示本次可以返回的最大事件数目,通常 maxevents参数与预分配的events数组的大小是相等的。
- 第4个参数 timeout表示在没有检测到事件发生时最多等待的时间(单位为毫秒),如果 timeout为0,则表示 epoll_wait在 rdllist链表中为空,立刻返回,不会等待。
$ gcc -o tcp_server tcp_server.c
$ ./tcp_server 8888- 并发服务器
- 一请求一线程 (已不被推崇)
- IO 多路复用, epoll
- TCP服务器百万级连接
申请一个 int sockfd = socket(AF_INET, SOCK_STREAM, 0);
初始化一个实例 sockaddr_in
struct sockaddr_in addr;
memset(&addr, 0, sizeof(struct sockaddr_in));
add.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = INADDR_ANY;
bind();
将一本地地址与一套接字捆绑。本函数适用于未连接的数据报或流类套接字,在
connect()或listen()调用前使用。当用socket()创建套接字后,它便存在于一个名字空间(地址族)中,但并未赋名。bind()函数通过给一个未命名套接字分配一个本地名字来为套接字建立本地捆绑(主机地址/端口号)。
bind(sockfd, (struct sockaddr*)&addr, sizeof(struct sockaddr_in))
listen();
创建一个套接字并监听申请的连接
#include <sys/socket.h> int listen(int sockfd, int backlog); // sockfd: 用于标识一个已捆包未连接套接字的文件描述符 // backlog: 等待连接队列的最大长度
accept();
accept()接收一个套接字中已建立的连接,来自客户端的连接。accept()是c语言中网络编程的重要的函数,本函数从s的等待连接队列中抽取第一个连接,创建一个与s同类的新的套接字并返回句柄。提取出所监听套接字的等待连接队列中第一个连接请求,创建一个新的套接字,并返回指向该套接字的文件描述符。
新建立的套接字不再监听状态,原来所监听的套接字也不受该系统调用的影响。
新建立的套接字准备发送
send()和接收数据recv()。SOCKET accept( SOCKET s, struct sockaddr FAR *addr, int FAR *addrlen );
addr用于存放客户端的地址,addrlen在调用函数时被设置为addr指向区域的长度,在函数调用结束后被设置为实际地址信息的长度。本函数会阻塞等待知道有客户端请求到达。返回值是一个新的套接字描述符,它代表的是和客户端的新的连接,可以把它理解成是一个客户端的
socket,这个socket包含的是客户端的ip和port信息 。(当然这个new_socket会从sockfd中继承服务器的ip和port信息),而参数中的SOCKET s包含的是服务器的ip和port信息 。
单纯的 sockfd 无法解决多个客户端连接时,如何分辨的问题
可通过应用层协议来解决
-
int epoll_create(int size);创建一个
epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。 -
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,第二个参数表示动作,用三个宏来表示:-
EPOLL_CTL_ADD:注册新的fd到epfd中;
-
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
-
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的
fd,第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:
-
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
- EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
- EPOLLOUT:表示对应的文件描述符可以写;
- EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
- EPOLLERR:表示对应的文件描述符发生错误;
- EPOLLHUP:表示对应的文件描述符被挂断;
- ==EPOLLET==: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
epoll事件有两种模型,边沿触发:edge-triggered (ET), 水平触发:level-triggered (LT)
socket接收缓冲区不为空 有数据可读 读事件一直触发 socket发送缓冲区不满 可以继续写入数据 写事件一直触发 边沿触发(edge-triggered)
socket的接收缓冲区状态变化时触发读事件,即空的接收缓冲区刚接收到数据时触发读事件 socket的发送缓冲区状态变化时触发写事件,即满的缓冲区刚空出空间时触发读事件 边沿触发仅触发一次,水平触发会一直触发。
-
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);epoll的事件注册函数,epoll_ctl向epoll对象中添加、修改或者删除感兴趣的事件,返回0表示成功,否则返回–1,此时需要根据errno错误码判断错误类型。等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0 会立即返回,-1 将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
- 第1个参数
epfd是epoll的描述符。 - 第2个参数
events则是分配好的epoll_event结构体数组,==epoll将会把发生的事件复制到 events数组中(events不可以是空指针,内核只负责把数据复制到这个 events数组中,不会去帮助我们在用户态中分配内存。内核这种做法效率很高)==。 - 第3个参数
maxevents表示本次可以返回的最大事件数目,通常maxevents参数与预分配的events数组的大小是相等的。 - 第4个参数
timeout表示在没有检测到事件发生时最多等待的时间(单位为毫秒),如果timeout为0,则表示epoll_wait在rdllist链表中为空,立刻返回,不会等待。
可能遇到的问题记录:
-
connection refused服务器不允许连接在服务器机如下设置
文件系统会默认每个进程的
fd个数为1024 修改:
/etc/security/limits.conf 命令:
ulimit -a
ulimit -n 1048576(sudo su) (临时修改)
sudo vim /etc/security/limits.conf 在最后一行之前添加
* hard nofile 1048576
* soft nofile 1048576 -
Cannot assign requested address端口个数可能不够
sockfd 与网络地址之间的关系 --> sockfd 与 ip 地址有什么关系
sockfd --> (远程ip, 远程端口, 本机ip, 本机端口, proto)
多开辟几个端口以供使用
-
Connection timed outfd 个数与 fd 的最大值影响
在客户端机如下设置:
cat /proc/sys/fs/file-max fs.file-max = 1048576cat /proc/sys/net/netfilter/nf_conntrack_max nf_conntrack_max = 1048576如果
nf_conntrack_max不显示 按照以下方式设置:# 若提示 sysctl: cannot stat /proc/sys/net/nf_conntrack_max: No such file or directory 执行如下: sudo su modprobe ip_conntrack lsmod |grep conntrack $ sudo sysctl -p ... fs.file-max = 1048576 net.nf_conntrack_max = 1048576
设置方法:
sudo vim /etc/sysctl.conf 在 #net.ipv4.conf.all.log_martians = 1 之下输入 fs.file-max = 1048576 net.nf_conntrack_max = 1048576 -
Cannot open /proc/meminfo: Too many open files in system在服务器端执行第3步骤
-
内存回收 大数量的TCP连接请求,很可能导致服务器内存的使用过载
所以引入TCP的协议栈
在刚刚的文件添加位置之下再添加
net.ipv4.tcp_mem = 252114 524288 786432 net.ipv4.tcp_wmem = 1024 1024 2048 net.ipv4.tcp_rmem = 1024 1024 2048**tcp_mem **(3个
INTEGER变量):low, pressure, highlow:当TCP使用了低于该值的内存页面数时,TCP不会考虑释放内存。(理想情况下,这个值应与指定给tcp_wmem的第 2 个值相匹配 - 这第 2 个值表明,最大页面大小乘以最大并发请求数除以页大小(131072 * 300 / 4096)。 pressure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。(理想情况下这个值应该是 TCP 可以使用的总缓冲区大小的最大值(204800 * 300 / 4096)。 high:允许所有tcp sockets用于排队缓冲数据报的页面量。(如果超过这个值,TCP连接将被拒绝,这就是为什么不要令其过于保守(512000 * 300 / 4096)的原因了。 在这种情况下,提供的价值很大,它能处理很多连接,是所预期的 2.5 倍;或者使现有连接能够传输 2.5 倍的数据.tcp_wmem(3个INTEGER变量):
min, default, maxmin:为TCP socket预留用于发送缓冲的内存最小值。每个tcp socket创建后都可以使用它。默认值为4096(4K)。 default:为TCP socket预留用于发送缓冲buffer的内存数量,默认情况下该值会影响其它协议使用的net.core.wmem_default值,一般要低于net.core.wmem_default的值。默认值为16384(16K)。 max: 用于TCP socket发送缓冲的内存最大值。该值不会影响net.core.wmem_max,"静态"选择参数SO_SNDBUF则不受该值影响。默认值为131072(128K)。(对于服务器而言,增加这个参数的值对于发送数据很有帮助)tcp_rmem() 同理 tcp_wmem()
/etc/sysctl.conf是一个允许你改变正在运行中的 Linux系统的接口。它包含一些TCP/IP堆栈和虚拟内存系统的高级选项,可用来控制 Linux 网络配置,由于/proc/sys/net目录内容的临时性,建议把TCP/IP参数的修改添加到/etc/sysctl.conf文件, 然后保存文件,使用命令sudo sysctl –p使之立即生效。
# 服务器端
$ gcc -o tcp_server tcp_server.c
./tcp_server 8888
# 客户端 (可准备多个客户端机的虚拟机)
$ gcc -o tcp_client tcp_client.c
./tcp_client (ip of server) 8888刚开始学习设计模式,写一些自己的浅见留在此处,便于以后自己查询或者更正
设计模式应该是,大佬们通过不断地代码迭代过程总结出的一系列的标准。之前看李建忠李老师的视频时因基础不好(现在仍还不足)仍有很多不理解的地方。但是一直记着一句话,设计模式不是“标准”,不能死学,死套,根据场景的不同,根据情况不同选择不同的设计模式。最高要做到 -- “心中无设计模式”
-
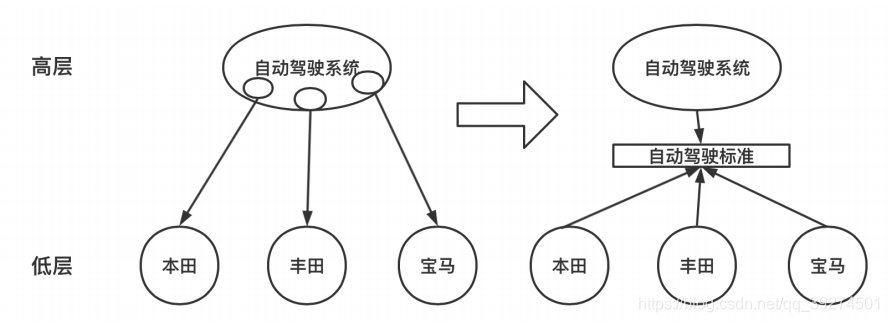
依赖倒置原则
- 高层模块不应该依赖底层模块,二者都应该依赖抽象
- 抽象不应该依赖具体实现,具体实现应该依赖于抽象
-
开放封闭原则
- 一个类应该对扩展开放,对修改关闭
-
面向接口编程
- 不将变量类型声明为某个特定的类,而是声明为某个接口
- 客户程序无需获知对象的具体类型,只需要知道对象所具有的接口
- 减少系统中各部分的依赖关系,从而实现“高内聚、松耦合”的类型设计方案
-
封装变化点
- 将稳定点和变化点分离,扩展修改变化点;让稳定点与变化点的实现层次分离
-
单一职责原则
- 一个类应该仅有一个引起它变化的原因
-
里氏替换原则
- 子类型必须能够替换掉它的父类型;主要出现在子类覆盖父类实现,原来使用父类型的程序可能出现错误;覆盖了父类方法却没有实现父类方法的职责;
-
接口隔离原则
- 不应该强迫客户依赖于它们不用的方法
- 一般用于处理一个类拥有比较多的接口,而这些接口涉及到很多职责
-
对象组合优于类继承
- 继承耦合度高,组合耦合度低
设计模式的使用,需要我们对当前任务,系统具有相当的熟悉程度时,并且明确发现了可以优化的地方时,我们可以使用设计模式。而这个可以优化的地方包括找到:
- 系统的关键依赖点
- 明确的变化点
- 明确找到复用方向
- 对需求的变化方向熟悉
如果我们获得对代码重构的权利,我们便应该在重构的过程中找到合适的设计模式,而重构时我们需要注意的便是:
- 静态转变为动态
- 早绑定转变为晚绑定
- 继承转变为组合
- 编译时依赖转变为运行时依赖
class Base{...} class Son : public Base{...} Base* subject = new Son();
- 紧耦合转变为松耦合
以下是对常用设计模式 -- 单例模式的笔记记录和资料查询汇总
- 定义 保证一个类仅有一个实例,并提供一个该实例的全局访问点 -- 《设计模式》GOF
此处将通过六个不同的单例模式代码写法来逐步理清单例模式
- 版本1
class Singleton { public: static Singleton * GetInstance() { if (_instance == nullptr) { _instance = new Singleton(); } return _instance; } private: Singleton(){}//构造 Singleton(const Singleton &clone){} //拷⻉构造 Singleton& operator=(const Singleton&) {} static Singleton * _instance; } Singleton* Singleton::_instance = nullptr;//静态成员需要初始化
这是最容易写出来的单例模式代码。我们通过类内静态方法 GetInstance() 来达到了一个类仅有一个实例的要求。但该代码可能存在如
- 堆区开辟的内存空间并没有被释放的问题
- 多线程的线程安全问题
对于第一个问题:
对于在堆区new出的对象,_instance 在版本一中,何时释放,由谁来释放并没有得到解决,如果对象没有被释放,在运行期间可能会存在内存泄露问题。
因此我们可以通过比如 atexit() 函数,内部类或者智能指针来解决,由此我们获得版本 2
- 版本 2
atexit()内部类class Singleton { public: static Singleton* GetInstance(){ if( _instance == nullptr ){ _instance = new Singleton(); atexit(Destructor); } return _instance; } ~Singleton () {} private: static void Destructor() { // Destructor() 静态是因为 静态成员只能访问静态成员函数 if( nullptr != _instance ){ delete _instance; _instance = nullptr; } } Singleton();//构造 Singleton( const Singleton& cpy );//拷贝构造 static Singleton* _instance; } Singleton* Singleton::_instance = nullptr;//静态成员需要初始化;还可以使用内部类,只能指针来解决;
这段代码之所以能做到自动内存释放,是因为使用了一个技巧,上面用内部类定义的class Singleton { public: static Singleton* GetInstance(){ if( _instance == nullptr ){ _instance = new Singleton(); } return _instance; } ~Singleton () { } private: class AutoRelease { public: ~AutoRelease(){ if(Singleton::_instance != nullptr){ delete Singleton::_instance; Singleton::_instance = nullptr; } } }; Singleton(){}//构造 Singleton( const Singleton& cpy ){}//拷贝构造 static Singleton* _instance; static AutoRelease _auto; } Singleton* Singleton::_instance = nullptr;//静态成员需要初始化;还可以使用内部类,只能指针来解决; Singleton::AutoRelease Singleton::_auto;
_auto是一个静态变量,而静态变量的生成和释放都是操作系统负责调用的,这样在_auto销毁的时候,会自动进入_auto的析构函数,即AutoRelease类的析构函数,我们在这个函数里进行释放单例对象的操作,这样就可以做到自动释放了
即便如此,我们依然会有多线程的线程安全问题,即多个线程在 _instance == nullptr 这个条件满足的时候一起进入了 _instance = new Singleton();,便会出现线程安全问题,那么一般的解决办法便是通过锁来进行操作,如此便有了版本三
-
版本 3
#include <mutex> class Singleton { // 懒汉模式 lazy load public: static Singleton * GetInstance() { //std::lock_guard<std::mutex> lock(_mutex); // 3.1 切换线程 if (_instance == nullptr) { std::lock_guard<std::mutex> lock(_mutex); // 3.2 if (_instance == nullptr) { _instance = new Singleton(); atexit(Destructor); } } return _instance; } private: static void Destructor() { if (nullptr != _instance) { delete _instance; _instance = nullptr; } } Singleton(){} //构造 Singleton(const Singleton &cpy){} //拷⻉构造 static Singleton * _instance; static std::mutex _mutex; } Singleton* Singleton::_instance = nullptr;//静态成员需要初始化 std::mutex Singleton::_mutex; //互斥锁初始化
在这个版本中,加锁的方法分别有如 3.1 和 3.2, 一般来说不选择 3.1 的原因在于,锁的粒度太大,线程切换的代价过大过于无意义。所以选择 3.2 的方法。 而 3.2 方法仍存在一个巨大的隐患:CPU 指令重排。 对于
_instance = new Singleton();CPU的指令顺序是:- 分配内存 malloc
- 调用构造器构造函数
- 指针赋值
单线程环境下,3.2的写法应该是没有问题的,但在多线程环境下,由于CPU命令的重拍特性,很可能会出现 1 3 2 的执行顺序方式,即分配内存,指针复制,调用构造函数。而单例模式下,当某个线程线性进入了
_instance = new Singleton();,而其他函数在这个线程产生了唯一的实例,并解开锁之后,进行if(_instance == nullptr)并判断为假后退出。结果是没有经历调用构造函数这一个阶段,却获得了内存地址,导致_instance指向了随机的内存地址,便出现了大家所知道的线程安全问题。由此,便有了版本四,内存屏障 -
版本 4
#include <mutex> #include <atomic> class Singleton { // C++ Java public: static Singleton * GetInstance() { Singleton* tmp = _instance.load(std::memory_order_relaxed); std::atomic_thread_fence(std::memory_order_acquire);//获取内存屏障 if (tmp == nullptr) { std::lock_guard<std::mutex> lock(_mutex); tmp = _instance.load(std::memory_order_relaxed); if (tmp == nullptr) { tmp = new Singleton; std::atomic_thread_fence(std::memory_order_release);//释放内存屏障 _instance.store(tmp, std::memory_order_relaxed); atexit(Destructor); } } return tmp; } private: static void Destructor() { Singleton* tmp = _instance.load(std::memory_order_relaxed); if (nullptr != tmp) { delete tmp; } } Singleton(){} Singleton(const Singleton&) {} Singleton& operator=(const Singleton&) {} static std::atomic<Singleton*> _instance; static std::mutex _mutex; }; std::atomic<Singleton*> Singleton::_instance;//静态成员需要初始化 std::mutex Singleton::_mutex; //互斥锁初始化 // g++ Singleton.cpp -o singleton -std=c++11
版本 4 的问题,对于我来说,就是过于复杂了,还没学懂。。所以有了版本 5
-
版本 5
// c++11 magic static 特性:如果当变量在初始化的时候,并发同时进⼊声明语句,并发 // 线程将会阻塞等待初始化结束。 class Singleton { public: ~Singleton(){} static Singleton& GetInstance() { static Singleton instance; return instance; } private: // protected Singleton(){} Singleton(const Singleton&) {} Singleton& operator=(const Singleton&) {} }; // 继承 Singleton // g++ Singleton.cpp -o singleton -std=c++11
注意:静态局部变量 懒汉模式 -- 系统自动释放 C++11 static 自带线程安全
注意: 无法继承,因为子类无法继承父类的构造函数
可以通过
friend关键字获取private,但是扩展性不好,可以改为protected继承就方便了。
由此,基本单例模式的版本 5 是我所知最好用最好理解的写法,那么我们也可以利用版本 5 写出模板方式的模板 6
-
模板 6
template<typename T> class Singleton { public: static T& GetInstance() { static T instance; // 这⾥要初始化DesignPattern, // 需要调⽤DesignPattern 构造函数,同时会调⽤⽗类的构造函数。 return instance; } virtual ~Singleton() {} Singleton(const Singleton&) {} Singleton& operator =(const Singleton&) {} protected: Singleton() {} // protected修饰构造函数,才能让别⼈继承 }; class DesignPattern : public Singleton<DesignPattern> { friend class Singleton<DesignPattern>; // friend 能让 Singleton<T> 访 // 问到 DesignPattern构造函数 private: DesignPattern(){} DesignPattern(const DesignPattern&) {} DesignPattern& operator=(const DesignPattern&) {} }

接下来就是简单一些的笔记记录了
-
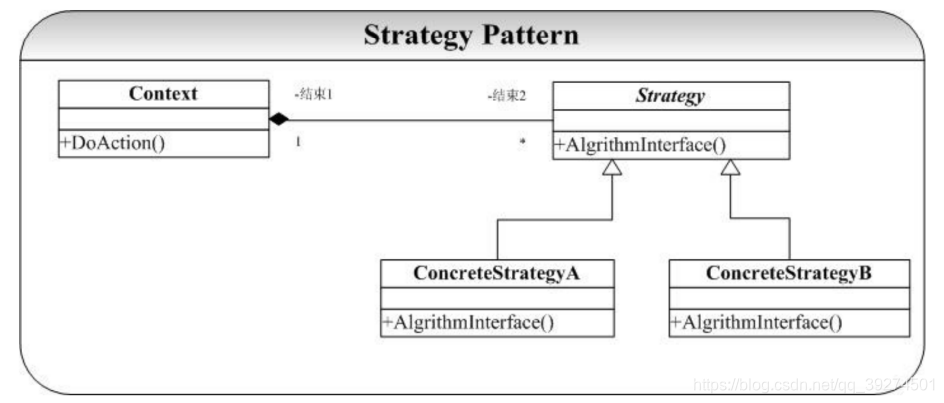
定义 定义⼀系列算法,把它们⼀个个封装起来,并且使它们可互相替换。该模式使得算法可独⽴于使⽤它的客户程序⽽变化。 ——《设计模式》 GoF
-
代码
-
要点
- 策略模式提供了⼀系列可重⽤的算法,从⽽可以使得类型在运⾏时⽅便地根据需要在各个算法之间进⾏切换;
- 策略模式消除了条件判断语句;就是在解耦合;
- 充分体现了开闭原则;单⼀职责;
-
本质
- 分离算法,选择实现
-
结构图
-
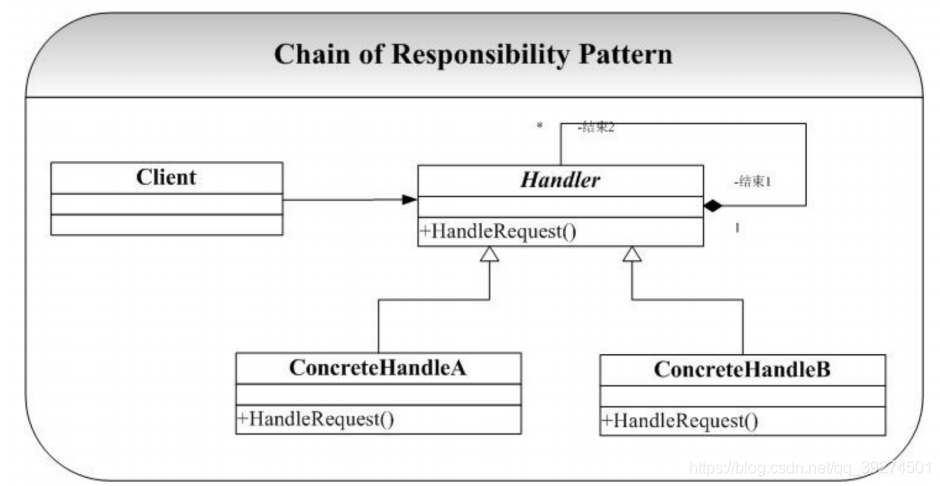
定义 使多个对象都有机会处理请求,从⽽避免请求的发送者和接收者之间的耦合关系。将这些对象连成⼀条链,并沿着这条链传递请求,直到有⼀个对象处理它为⽌。 ——《设计模式》GoF
-
代码
- nginx 阶段处理
// 严格意义说是功能链 // ngx_http_init_phase_handlers 初始化责任链 cmcf->phase_engine.handlers // ngx_http_core_run_phases 调⽤责任链
- nginx 阶段处理
-
要点
- 解耦请求⽅和处理⽅,请求⽅不知道请求是如何被处理,处理⽅的组成是由相互独⽴的⼦处理构成,⼦处理流程通过链表的⽅式连接,⼦处理请求可以按任意顺序组合;
- 责任链请求强调请求最终由⼀个⼦处理流程处理;通过了各个⼦处理条件判断;
- 责任链扩展就是功能链,功能链强调的是,⼀个请求依次经由功能链中的⼦处理流程处理;
- 充分体现了单⼀职责原则;将职责以及职责顺序运⾏进⾏抽象,那么职责变化可以任意扩展,同时职责顺序也可以任意扩展;
-
本质
-
分离职责,动态组合
-
结构图
-
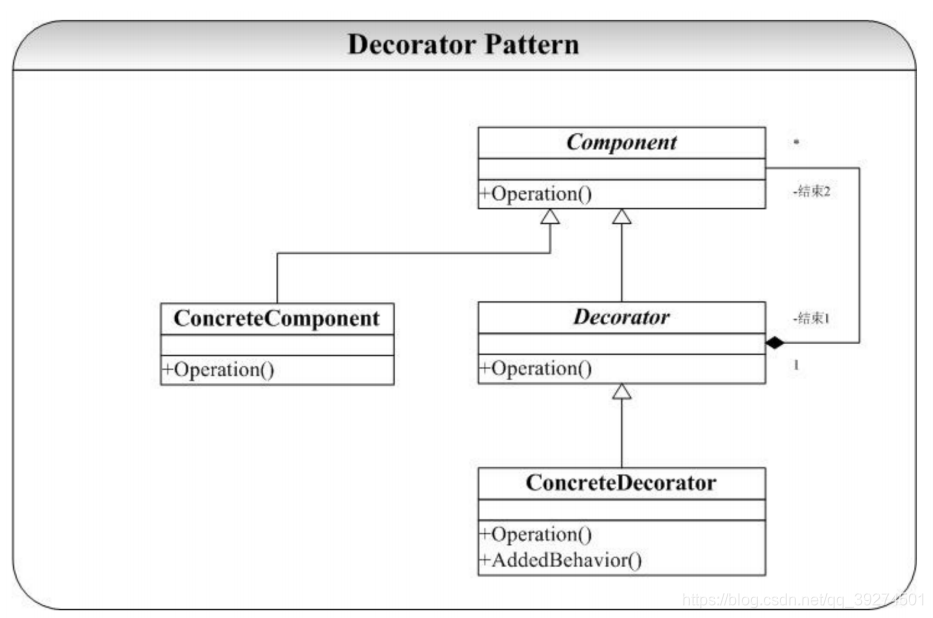
定义 动态地给⼀个对象增加⼀些额外的职责。就增加功能⽽⾔,装饰器模式⽐⽣成⼦类更为灵活。 ——《设计模式》GoF
-
背景 普通员⼯有销售奖⾦,累计奖⾦,部⻔经理除此之外还有团队奖⾦;后⾯可能会添加环⽐增⻓奖⾦,同时可能针对不同的职位产⽣不同的奖⾦组合;
-
代码
-
要点
- 通过采⽤组合⽽⾮继承的⼿法, 装饰器模式实现了在运⾏时动态扩展对象功能的能⼒,⽽且可以根据需要扩展多个功能。 避免了使⽤继承带来的“灵活性差”和“多⼦类衍⽣问题”。
- 不是解决“多⼦类衍⽣的多继承”问题,⽽是解决“⽗类在==多个⽅向上的扩展功能==”问题;
- 装饰器模式把⼀系列复杂的功能分散到每个装饰器当中,⼀般⼀个装饰器只实现⼀个功能,实现复⽤装饰器的功能;
-
本质
- 动态组合
-
结构图

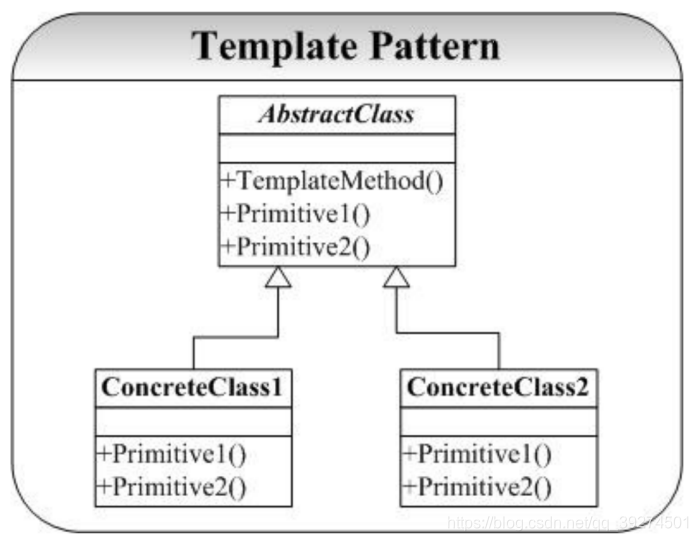
- 定义 定义⼀个操作中的算法的⻣架 ,⽽将⼀些步骤延迟到⼦类中。 Template Method使得⼦类可以不改变⼀个算法的结构即可重定义该算法的某些特定步骤。 ——《 设计模式》 GoF
- 背景 某个品牌动物园,有⼀套固定的表演流程,但是其中有若⼲个表演⼦流程受欢迎程度⽐较低,希望将这⼏个表演流程创新,以尝试迭代更新表演流程;
- 代码
- 要点
- 非常常用的设计模式,子类可以复写父类的子流程,使父类的大流程更丰富;(注意使用纯虚函数需要注意的点,比如,虚析构函数,子类必须复写,纯虚函数不能实例化,纯虚类里的非纯虚函数可以有实现,纯虚函数不能实现)
- 反向控制流程的典型应用
- 父类
protected保护子类需要复写的子流程;这样子类的子流程只能父类来调用 - 充分体现了依赖倒置原则
- 本质
- 通过固定算法骨架来约束子类行为
- 结构图
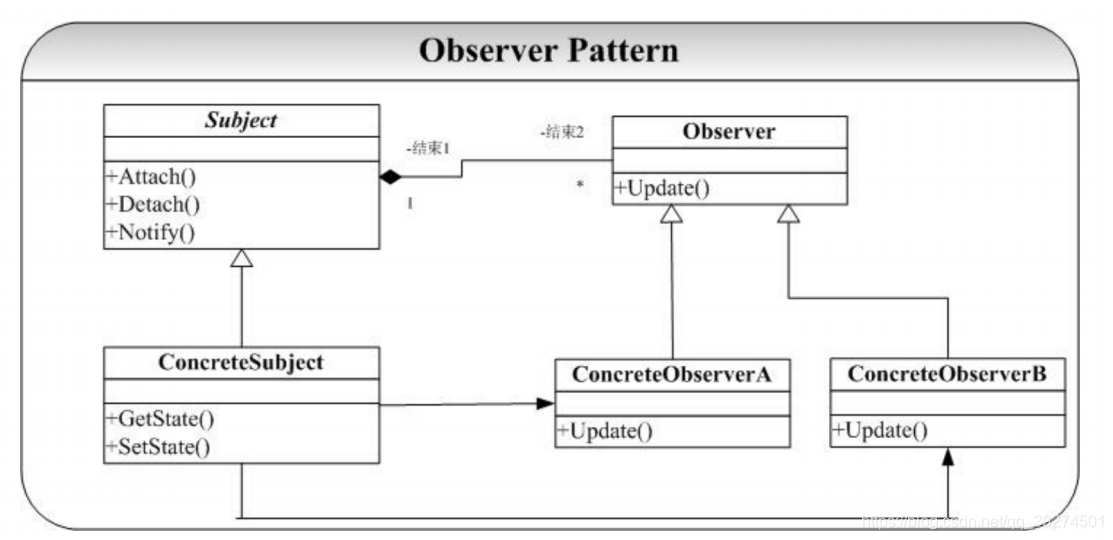
- 定义 定义对象间的⼀种⼀对多(变化)的依赖关系,以便当⼀个对象(Subject)的状态发⽣改变时,所有依赖于它的对象都得到通知并⾃动更新。 ——《 设计模式》 GoF
- 代码
- 要点
- 观察者模式使得我们可以独立地改变目标与观察者,从而使二者之间的关系松耦合
- 观察者⾃⼰决定是否订阅通知,⽬标对象并不关注谁订阅了;
- 观察者不要依赖通知顺序,⽬标对象也不知道通知顺序;
- 常使⽤在基于事件的ui框架中,也是MVC的组成部分;
- 常使⽤在分布式系统中,actor 框架中;
- 本质
- 触发联动
- 结构图
-
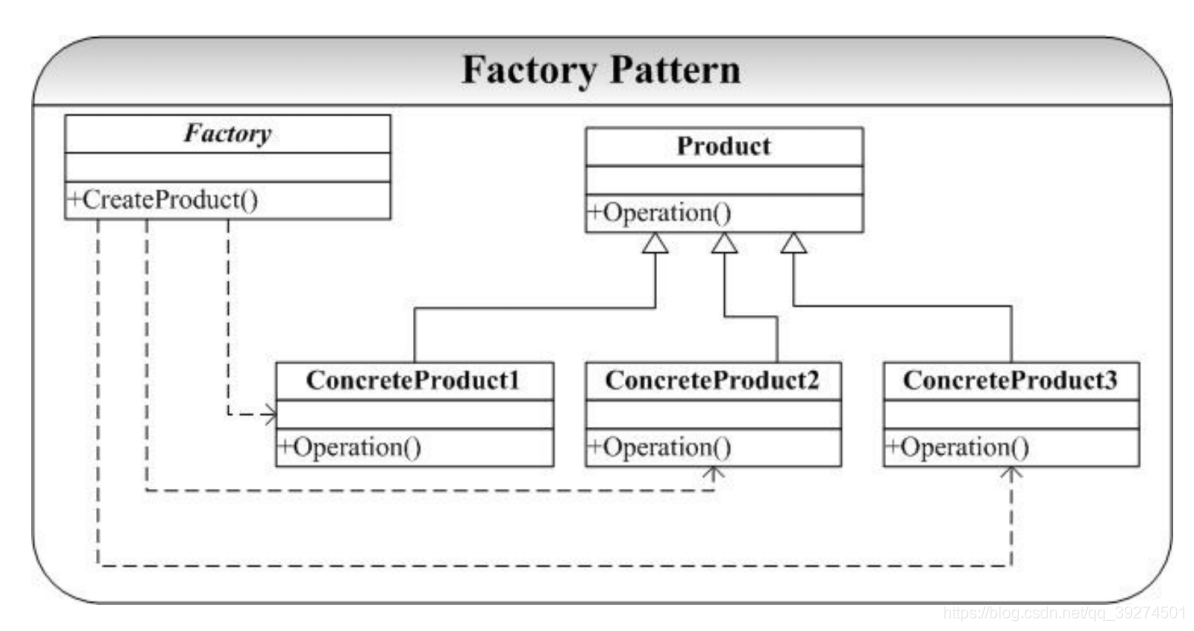
定义 定义⼀个⽤于创建对象的接⼝,让⼦类决定实例化哪⼀个类。Factory Method使得⼀个类的实例化 延迟到⼦类。 ——《设计模式》GoF
-
本质
- 延迟到子类来选择实现
-
代码
-
要点
- 解决 创建过程比较复杂, 希望对外隐藏这些细节;
-
比如连接池,线程池
-
隐藏对象真实模型
class A : public base class A_v1 : public base
-
对象创建会有很多参数来决定如何创建
-
创建对象有复杂的依赖关系
-
- 解决 创建过程比较复杂, 希望对外隐藏这些细节;
-
结构图
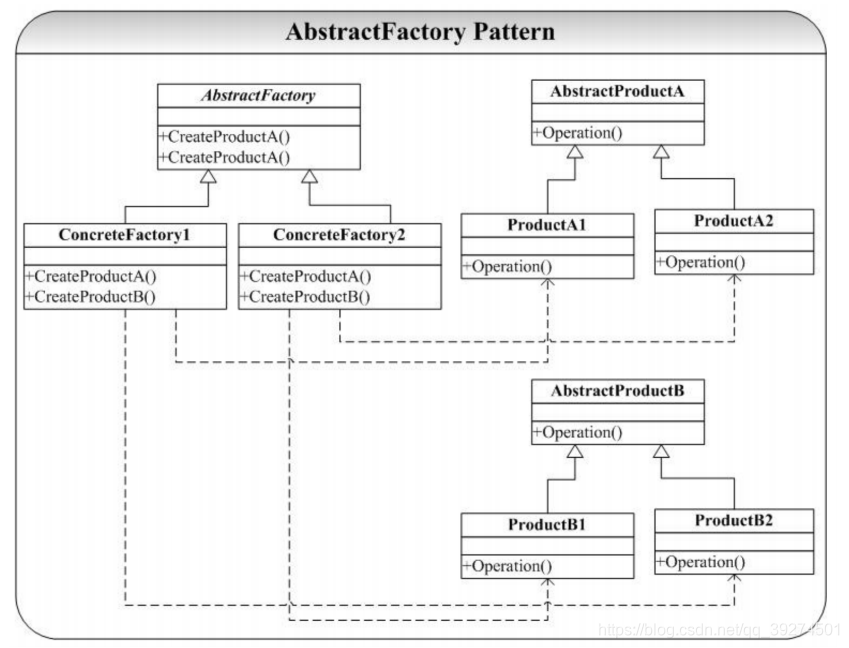
- 定义 提供一个接口,让该接口负责创建一系列“相关或者相互依赖的对象”,无需指定它们具体的类。 -- 《设计模式》 GOF
- 背景 实现一个拥有导出导入数据的接口,让客户选择数据的导出导入方式
- 代码
- 要点
- 本质
- 结构图
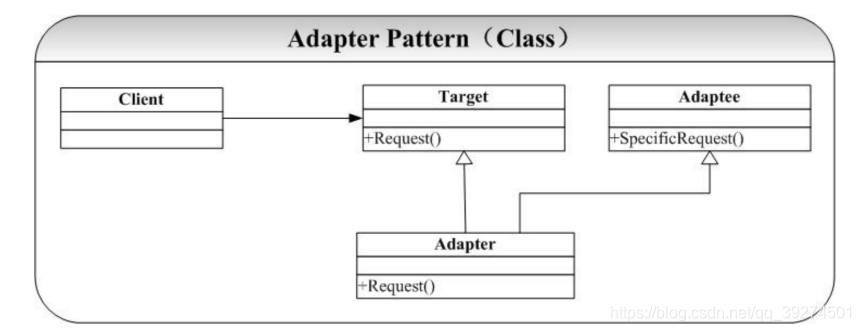
- 定义 将一个类的接口转换成客户希望的另一个接口。 Adapter 模式使得原本由于接口不兼容而不能一起工作的哪些类一起工作。 -- 《设计模式》 GOF
- 背景 日志系统,原来是通过写磁盘的方式进行存储,后来因为i查询不变,需要额外添加王数据库写日志的功能 (写文件和数据库并存)
- 代码
- 要点
- 原来的接口是稳定的,新的外来的需求是变化的,那么可以通过继承原来的接口,让原来的接口继续保持稳定,在子类通过组合的方式来扩展功能
- 本质
- 转换匹配,复用功能;
- 结构图
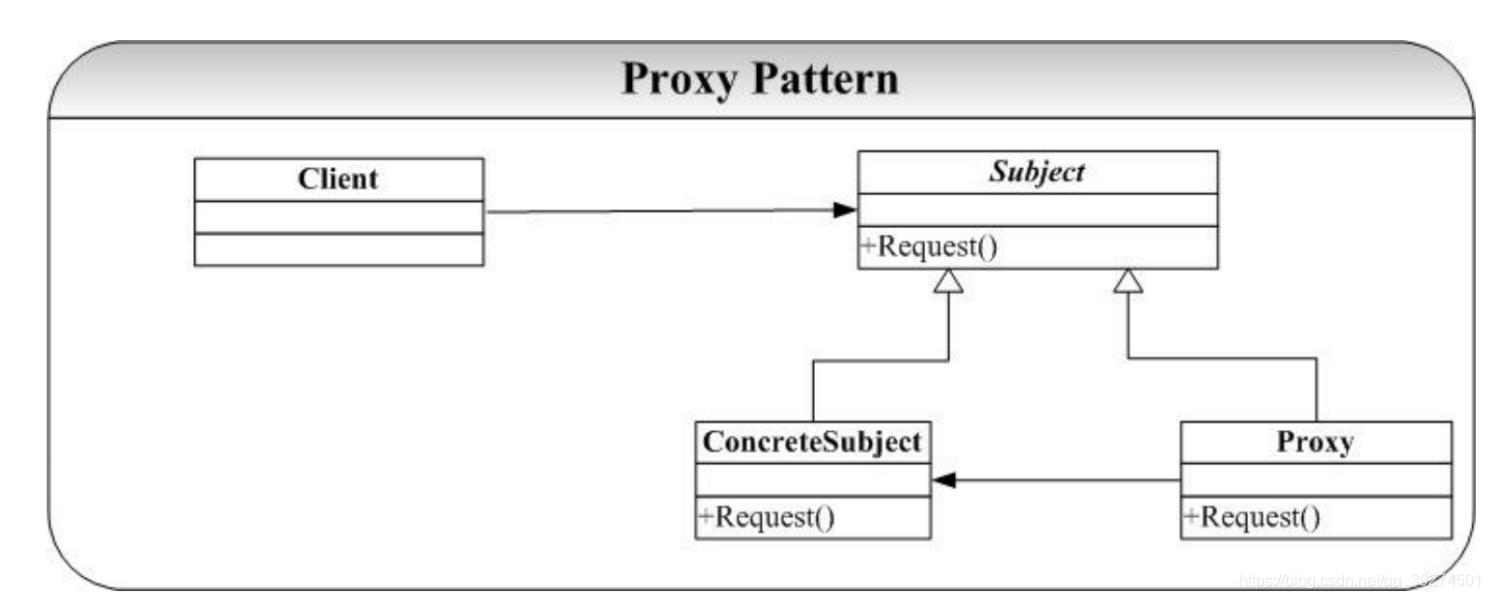
- 定义 为其他对象提供一种代理以控制对这对象的访问。 -- 《设计模式》 GoF
- 背景 在有些系统中,为了某些对象的纯粹性,只进⾏了功能相关封装(稳定点),后期添加了其他功能 需要对该对象进⾏额外操作(变化点),为了隔离变化点(也就是不直接在稳定点进⾏修改,这样 会让稳定点也变得不稳定),可以抽象⼀层代理层;
- 代码
- 要点
- 远程代理(隐藏⼀个对象存在不同的地址空间的事实),虚代理(延迟加载 lazyload ),保护代理(在 代理前后做额外操作,权限管理,引⽤计数等);
- 在分布式系统中, actor 模型 ( skynet ) 等常用的设计模式
- 本质
- 控制对象访问
- 结构图