⚡ 性能大幅提升! 新版本通过多线程并发和实时进度追踪,将导出效率提升15-20倍!
- 🎯 实时进度仪表板 - 动态显示导出进度、ETA预估、成功率统计
- 🧵 多线程图片下载 - 并发处理,15-20倍速度提升 (1,899张图片 < 15分钟)
- 📊 智能错误追踪 - 详细的失败原因分析和自动重试机制
- 🔄 断点续传 - 自动跳过已存在文件,支持中断后继续
- 📁 智能文件管理 - 按年份分类,自动转换相对路径
✅ 测试规模: 14个知识库,334篇文档,1,899张图片
✅ 导出时间: ~15-20分钟 (原版需要数小时)
✅ 成功率: >95%
✅ 内存优化: 流式下载,低内存占用
- 模拟用户浏览器操作一篇一篇导出 markdown 文档
- 按照知识库目录导出文档
- 支持导出失败重试
- 导出文档中的图片到本地
- 替换文档中的图片链接
ps: 后面两个功能是使用 python 实现,可以单独使用
效果展示:
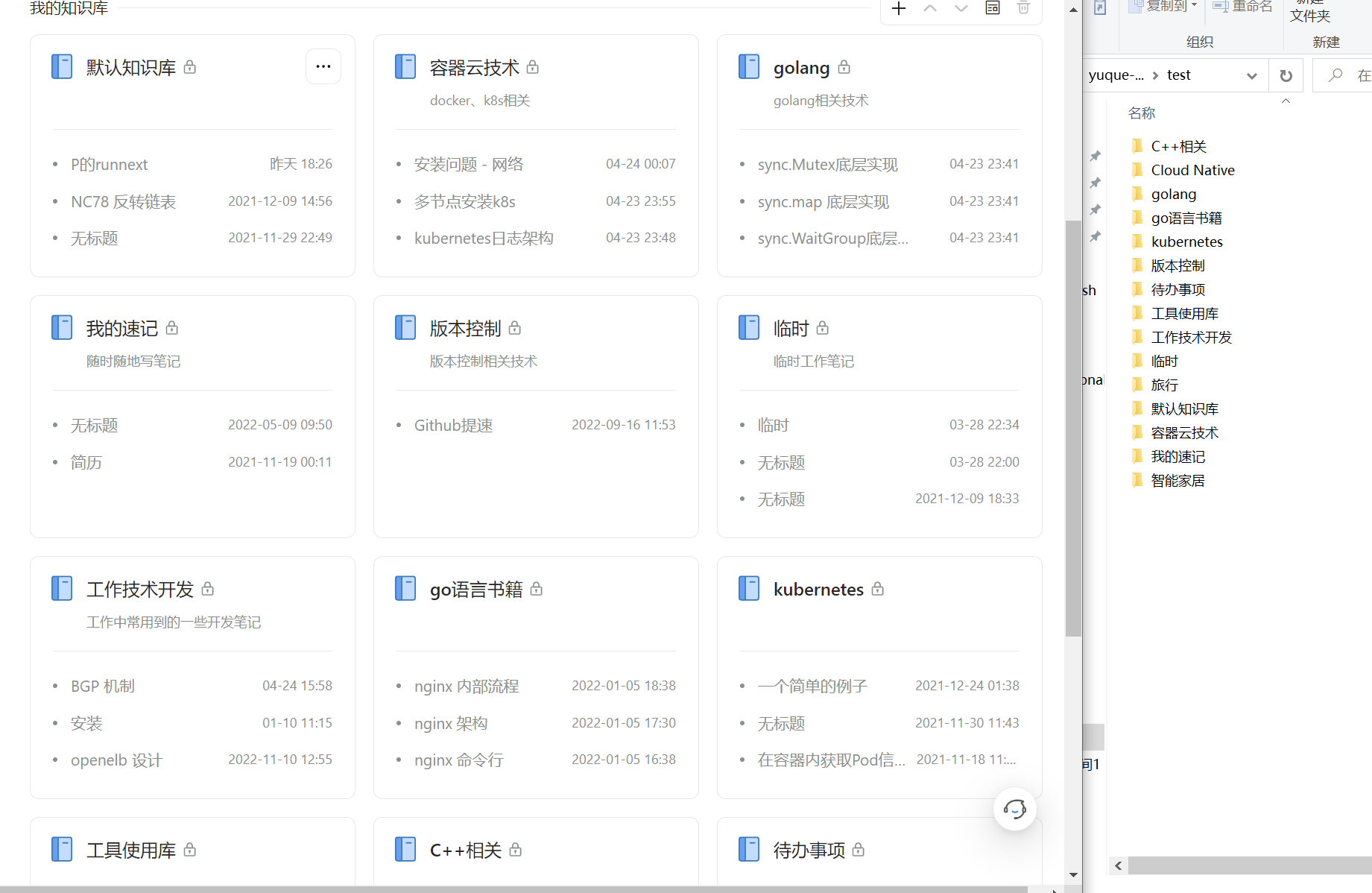
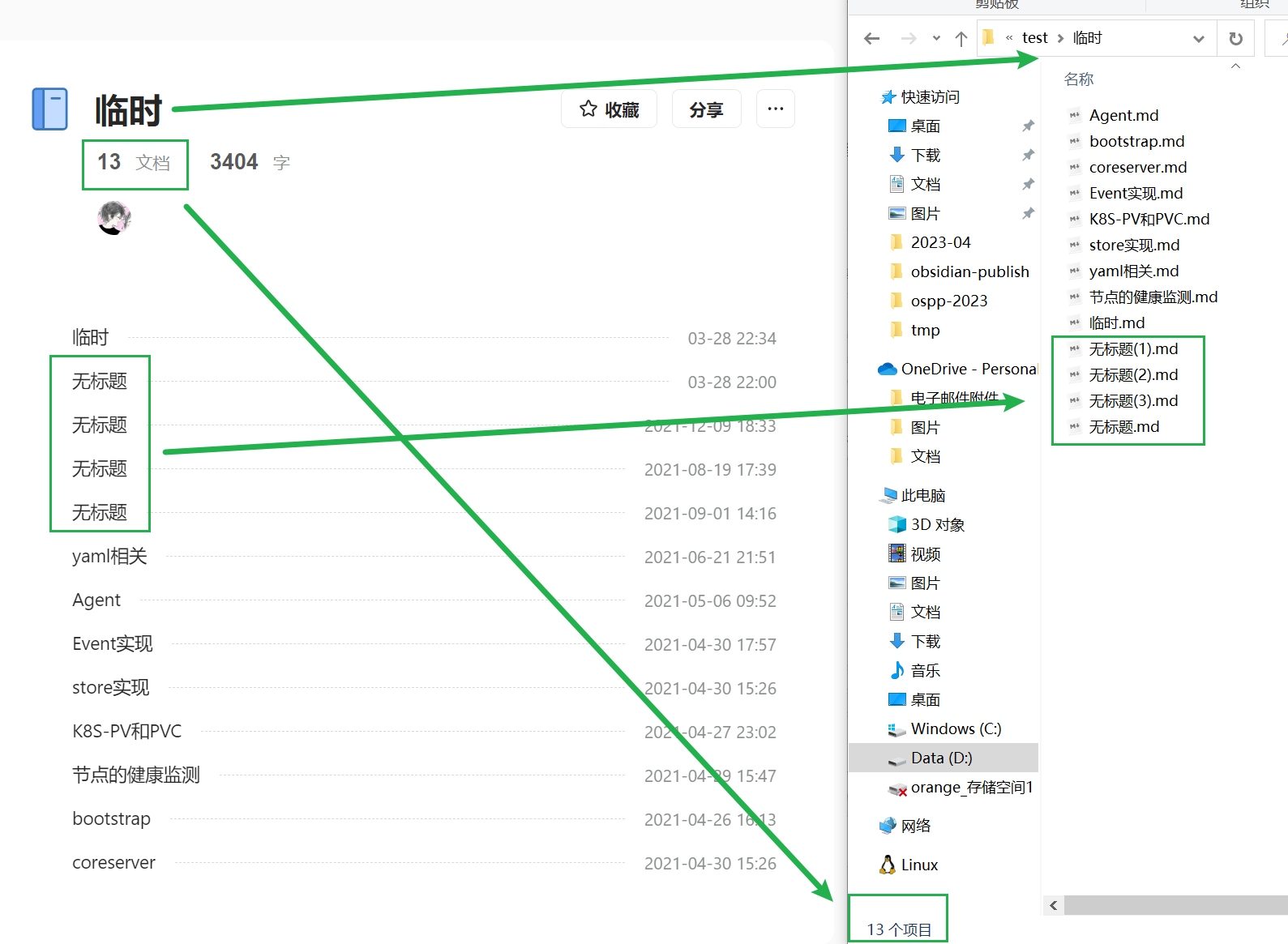
动图展示(旧版图,新版未更新图):
这是一个基于puppeteer 来模拟用户在浏览器的操作一篇一篇的导出语雀文档的工具。 关于语雀的导出可以详情说明见官方的文档:如何导入导出知识库
首先语雀支持导出文档为 markdown 格式。
- 单篇导出:支持导出为 markdown、word、pdf、lakebook等
- 批量导出:支持导出为 lakebook、pdf 格式。对于超级用户是可以通过创建 token 来使用官方的 exporter 工具或者其他基于 api 的工具进行批量导出;超级用户的价格为 299/年。
lakebook 格式为语雀私有的格式:lakebook 格式说明,语雀也没有相应的工具去支持迁移/导入到其他笔记软件。pdf 估计也不能直接导入其他笔记软件(这个没有研究过就不展开了)。
因此对于想要迁移自己文档的普通用户以及会员用户来说,你只能一篇一篇导出来完成你的迁移动作,这些用户也大多有上百篇文档,这无疑是劝退。所以我的迁移计划也一再搁置,同时也再等待其他的更友好的导出方式出现。最后还是不想等了,请教 GPT 写了这个工具,确实也怕像我这种白嫖用户之后的迁移的成本越来越大了。
ps: 本人也不是专门写 nodejs 的,代码可能也是烂成狗屎,请大家不喜勿喷。谢谢!
确保你的环境有 Chromium 浏览器。如 Google Chrome、Microsoft Edge、Opera 和 Brave等,都是基于 Chromium 浏览器构建的。
建议使用 nvm 管理 node,选取下列适合自己的方式安装:
- github 地址:nvm-sh/nvm: Node Version Manager
- gitee 地址:nvm-cn: 🧊 nvm国内安装工具 (gitee.com)
配置 npm 淘宝源:npm config set registry https://registry.npmmirror.com
安装 yarn:npm install -g yarn --registry=https://registry.npmmirror.com
下载代码并安装依赖
git clone https://github.com/renyunkang/yuque-exporter.git
cd yuque-exporter
npm install --registry=https://registry.npm.taobao.org
# 安装 JSONStream:
# npm install JSONStream --registry=https://registry.npm.taobao.org
# yarn 安装依赖如果下载报错的话,可以依据情况更换源。
yarn设置环境变量并使用工具导出
需要用到的环境变量:
| 环境变量 | 选项 | 描述 |
|---|---|---|
| USER | 必须(有cookie文件时非必须) | 登录的用户名 |
| PASSWORD | 必须(有cookie文件时非必须) | 登录的密码 |
| EXPORT_PATH | 非必须 | 指定导出路径,默认为当前工作目录下的 output 目录(自动创建) |
- ubuntu
# 第一次运行时,使用 USER + PASSWORD 登录
# USER=xxx PASSWORD=xxx node main.js
USER=xxx PASSWORD=xxx EXPORT_PATH=/path/to/exporter node main.js
# 登录一次后会保存 cookie,之后使用cookie登录
# node main.js
EXPORT_PATH=/path/to/exporter node main.js- windows
# 1. cmd
set USER="xxx"
set PASSWORD="xxx"
# set EXPORT_PATH=/path/to/exporter
node main.js
# 2. powershell
# $env:USER="xxx";$env:PASSWORD="xxx"; node .\main.js
$env:USER="xxx";$env:PASSWORD="xxx";$env:EXPORT_PATH="/path/to/exporter"; node .\main.js- MacOS
# 密码有特殊字符,建议单引号处理
export USER='xxx'
export PASSWORD='xxx'
# 运行
node main.js需要用到的几个环境变量:
| 环境变量 | 选项 | 描述 |
|---|---|---|
| MARKDOWN_DIR | 非必须 | 指定 mardown 文件夹路径,默认为当前工作目录的 output 目录 |
| DOWNLOAD_IMAGE | 非必须 | 指定是否导出图片,导出路径为 MARKDOWN_DIR 目录下的 images 目录,默认为 true |
| UPDATE_MDIMG_URL | 非必须 | 指定是否更新文件中的图片路径,未指定 REPLACE_IMAGE_HOST 时,会更新为图片路径的相对路径。默认为 false |
| REPLACE_IMAGE_HOST | 非必须 | 更新图片路径时自定义文件 url,格式为:{REPLACE_IMAGE_HOST}/{years}/{img_name},在使用自定义对象存储时,建议上传图片时的路径符合前面的格式;默认为空 |
使用工具导出
# 以 windows powershell 为例
# 下载图片,不更新 mardown 源文件的图片链接
python.exe .\export-image.py
# 不下载图片,更新文件的图片为相对路径
$env:DOWNLOAD_IMAGE="false";$env:UPDATE_MDIMG_URL="true"; python.exe .\export-image.py
# 不下载图片,更新文件的图片为自定义对象存储(自定义域名)
$env:DOWNLOAD_IMAGE="false";$env:UPDATE_MDIMG_URL="true"; $env:REPLACE_IMAGE_HOST="https://images.ryken.cloud/"; python.exe .\export-image.pyps:
- 当使用 python 运行时,如果没有相关依赖的话,需要手动下载一下; pip install xxx
- 相关环境变量的是指同上面"下载代码并导出"
- 根据自己需要,指定不同环境变量的值,来满足不同的需求吧
1.自动登录仅支持账号密码登录
2.无法保证兼容性,如果之后官方 api 修改后,可以自己根据 api 修改源码
3.无法导出内容为纯表格/思维导出的文档(官方也不支持将其直接导出为 markdown);因此报错的 timeout,可能为这些类型的文档,请重复确认后手动导出为其他格式。
4.团队的导出未测试
- Could not find Chromium 但是有 chorm 浏览器 在不同的操作系统上,Puppeteer 默认调用的 Chrome 路径如下:
- Windows: C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
- macOS: /Applications/Google Chrome.app/Contents/MacOS/Google Chrome
- Linux: /usr/bin/google-chrome
如果主机上对应的可执行文件路径与默认一致但仍然运行失败,可以修改源码手动指定一下,如果没有chorme也可以执行edge的二进制文件
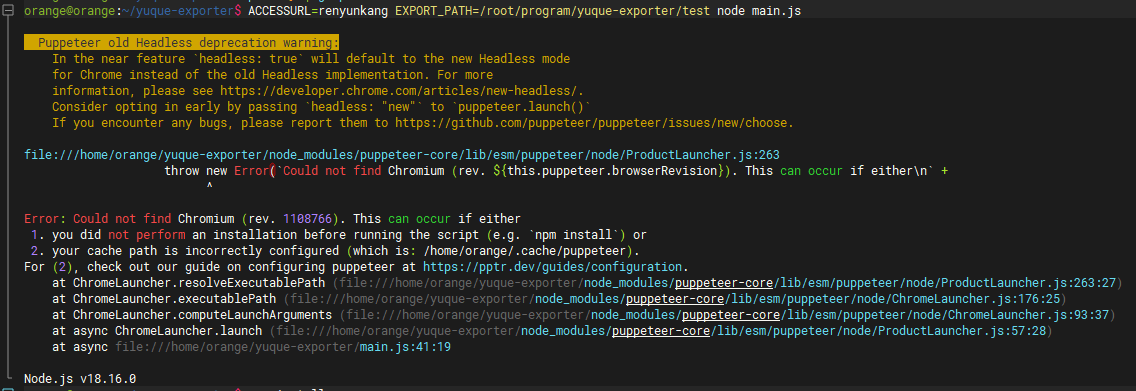
const browser = await puppeteer.launch({ headless: true });
to
const browser = await puppeteer.launch({ headless: true, executablePath: '/usr/bin/google-chrome' });
or
// headless: false 会打开浏览器实时观察模拟的操作,可用于调试;executablePath 替换为自己本机对应路径
const browser = await puppeteer.launch({ headless: false, executablePath: "C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe" });- 📊 动态仪表板: 实时显示导出进度、完成率、错误统计
- ⏱️ ETA 计算: 智能预估剩余时间和完成时间
- 📈 成功率监控: 跟踪下载成功率和失败原因
- 并发下载: 使用 ThreadPoolExecutor 实现15-20倍速度提升
- 智能重试: 自动重试失败的下载任务,提高成功率
- 内存优化: 流式下载大文件,减少内存占用
- 重复检测: 自动跳过已存在的文件,避免重复下载
- 目录结构: 按年份分类保存图片,保持组织性
- 相对路径: 自动转换为相对路径,便于文档迁移
# 文档导出配置
USER="your_username" # 语雀用户名
PASSWORD="your_password" # 语雀密码
EXPORT_PATH="/path/to/export" # 导出路径
# 图片处理配置
MARKDOWN_DIR="/path/to/markdown" # Markdown文件目录
DOWNLOAD_IMAGE="true" # 是否下载图片
UPDATE_MDIMG_URL="true" # 是否更新图片链接
REPLACE_IMAGE_HOST="https://..." # 自定义图片域名
MAX_WORKERS="10" # 最大线程数
REQUEST_TIMEOUT="30" # 请求超时时间(秒)# 高性能配置 (推荐用于大量文档)
MAX_WORKERS=15 REQUEST_TIMEOUT=60 python export-image.py
# 低内存配置 (适用于资源受限环境)
MAX_WORKERS=5 REQUEST_TIMEOUT=30 python export-image.py
# 网络优化配置 (适用于不稳定网络)
MAX_WORKERS=3 REQUEST_TIMEOUT=120 python export-image.py典型导出性能数据:
- 📚 知识库数量: 14个
- 📄 文档总数: 334篇
- 🖼️ 图片总数: 1,899张
- ⏱️ 导出时间: ~15-20分钟 (多线程)
- ✅ 成功率: >95%
- 网络问题: 增加
REQUEST_TIMEOUT时间 - 并发过高: 减少
MAX_WORKERS数量 - 权限问题: 检查图片URL访问权限
- 减少
MAX_WORKERS到 5 以下 - 增加
REQUEST_TIMEOUT避免超时重试 - 分批处理大量图片
- 检查网络连接稳定性
- 增加下载超时时间 (export.js 中的 timeout 设置)
- 确认语雀账号权限正常
欢迎提交 Issue 和 Pull Request!
- Fork 本仓库
- 创建特性分支:
git checkout -b feature/your-feature - 提交更改:
git commit -am 'Add some feature' - 推送到分支:
git push origin feature/your-feature - 提交 Pull Request
本项目基于 MIT 协议开源 - 查看 LICENSE 文件了解详情。
- 感谢语雀团队提供优秀的知识管理平台
- 感谢 Puppeteer 团队提供强大的自动化工具
- 感谢所有贡献者和用户的反馈与支持
⭐ 如果这个工具对你有帮助,请给个 Star 支持一下!