首先感谢大家的点赞。这个仓库是我复现某篇论文的代码,作用是对Dos,Normal,Probe,R2L,U2R五种网络流量进行分类。原文中,网络流量就是数字和字符串组成的文本,我们需要将其转化为图片的格式进行分类。训练流量和测试流量的以及他们处理后的文本文件我都放在DataSet/NSL-KDD/目录下面了,大家不要问我图片数据集啦,没有图片数据集,我也是自己处理的。下面和大家详细讲解一下吧。
正如我前面说的,这里只有文本文件数据,没有图片数据。所以我们需要对KDDTest+文件和KDDTrain+文件都进行处理
对应
PreHandle中的oneHotHandle方法和minMaxHandle方法
- 第一步:类型转化。数据集中,有三个字符特征,是
protocol_type、service和flag,由于他们是字符特征,所以需要进行one-hot编码,从而把字符型转为数值型 - 第二步:对数据做归一化处理。把所有数据的特征缩放到
0和1之间,使用的处理方法为min-max方法,此时将文本文件变成了五个不同流量类型的cvs文件,在目录DataSet/Change/中
对应
PreHandle中的csvToImage方法
- 第一步:因为
CNN的输入是图片形式,先把归一化之后的122个特征变换成矩阵的形式,大小是一个十二乘十二的方阵 - 第二步:进行像素化处理,将矩阵中的数据进行与
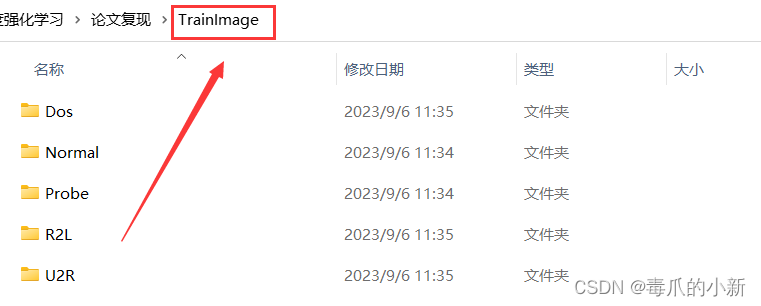
255相乘的操作,形成一张图片 - 第三步:将他们输出到文件夹中。根据我们的方法,处理完毕的不同类型的图片存储在不同名称文件夹下面,处理完毕的文件夹大概是这个样子
文件夹里面的流量图片是这个样子的(图片很小,所以要点开查看)
处理完毕图片我们就开始创建模型,对应代码CNNMould,注释写的很清楚,大家自己查看即可
从训练文件夹的不同的文件夹中读取图片开始训练模型,在代码中,不同文件夹的名称就等于给图片lable标签,所以不需要特别标注。对应代码Train,注释写的很清楚,大家自己查看即可
从预测文件夹的不同的文件夹中读取图片进行预测。对应代码Predict,注释写的很清楚,大家自己查看即可
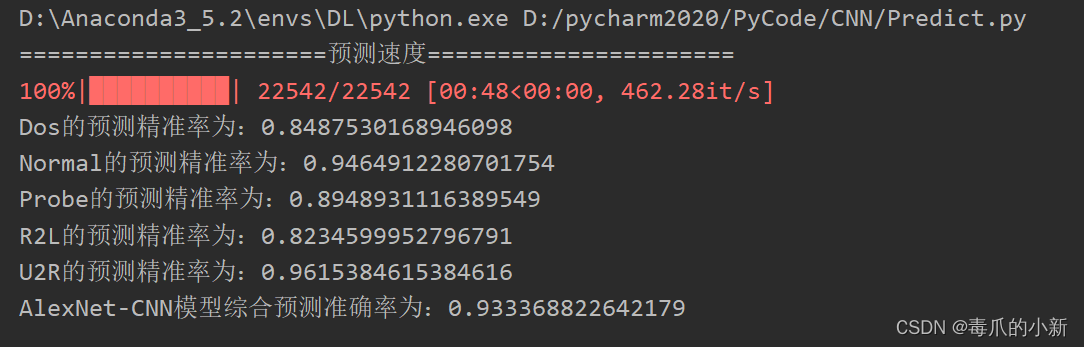
附一张最后的预测正确率图片