【导语】主要介绍 ** 在pytorch 中实现了余弦退火从启动学习率机制,支持 warmup 和 resume 训练。并且支持自定义下降函数,实现多种重启动机制。 觉得好用记得点个 star 哈...
代码: https://github.com/Huangdebo/CAWB

![如果 cawb_steps 为 [], 则会实现正常的余弦退火机制](https://img-blog.csdnimg.cn/50ad359e69f2459cbbe3268a1be821e4.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAd29uZGVyZnVsX2hkYg==,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
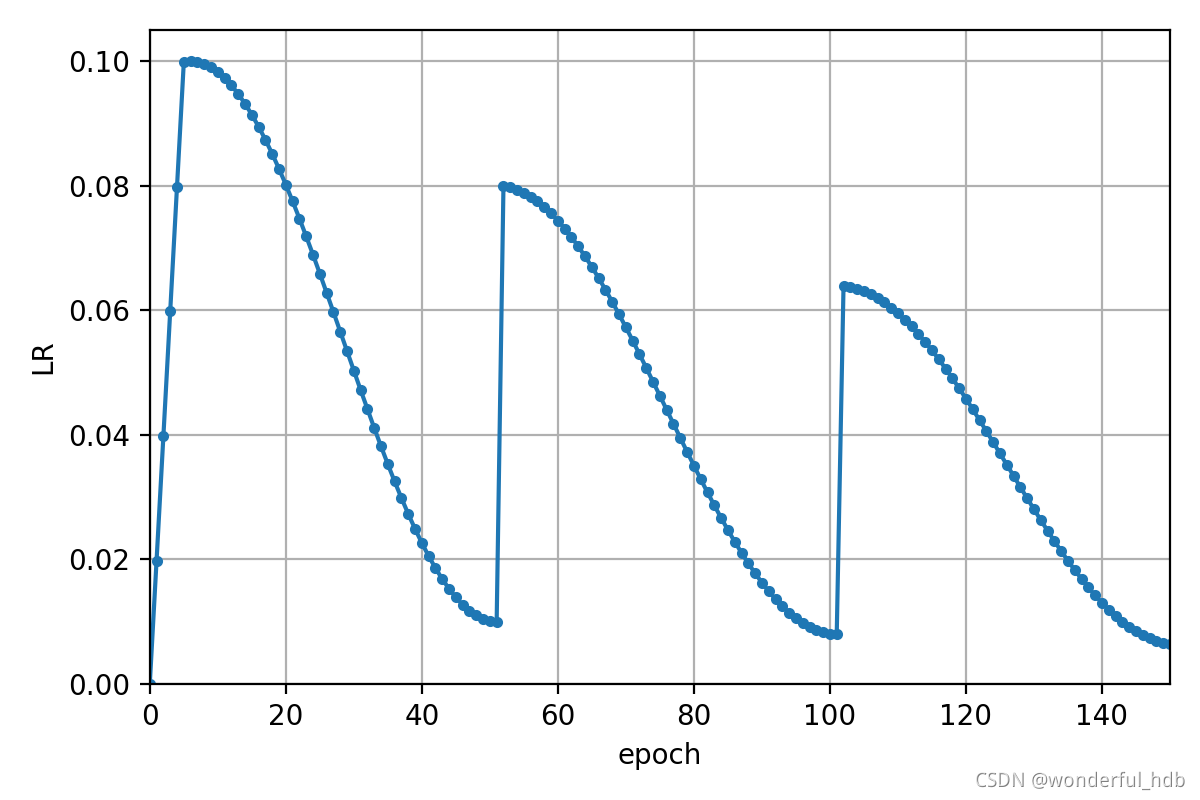
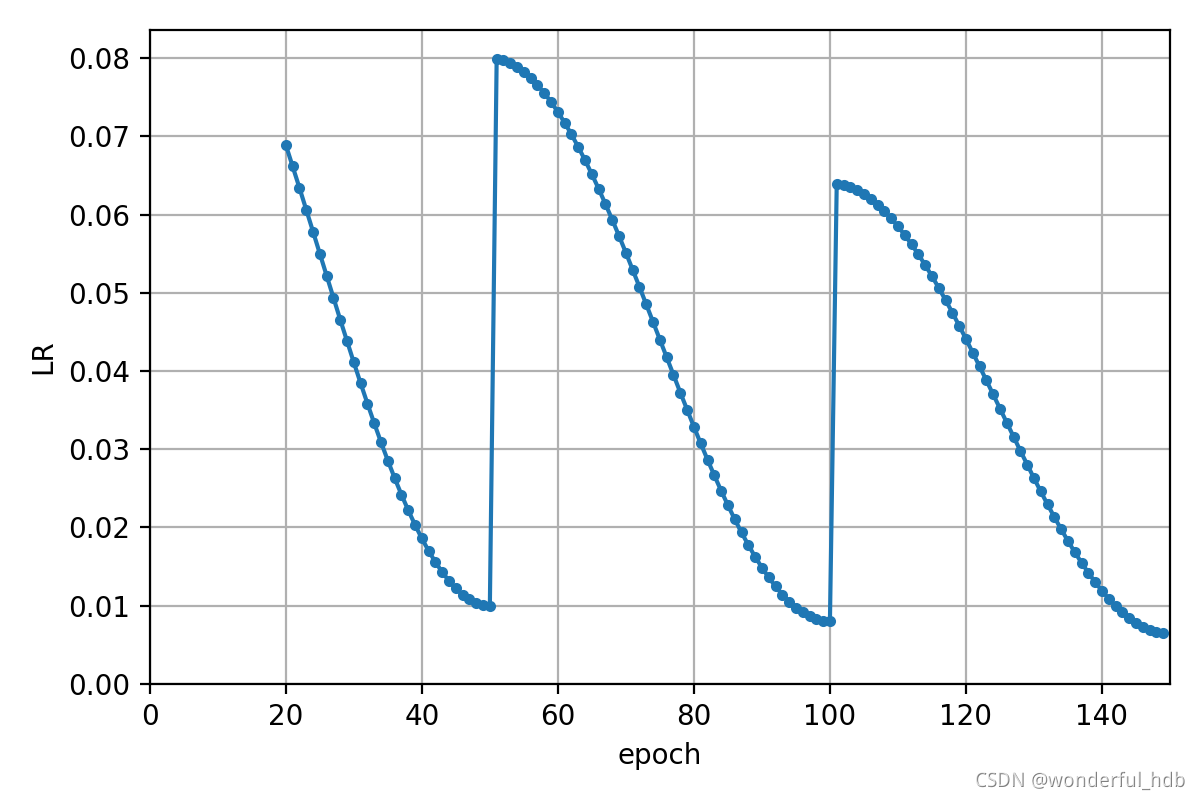
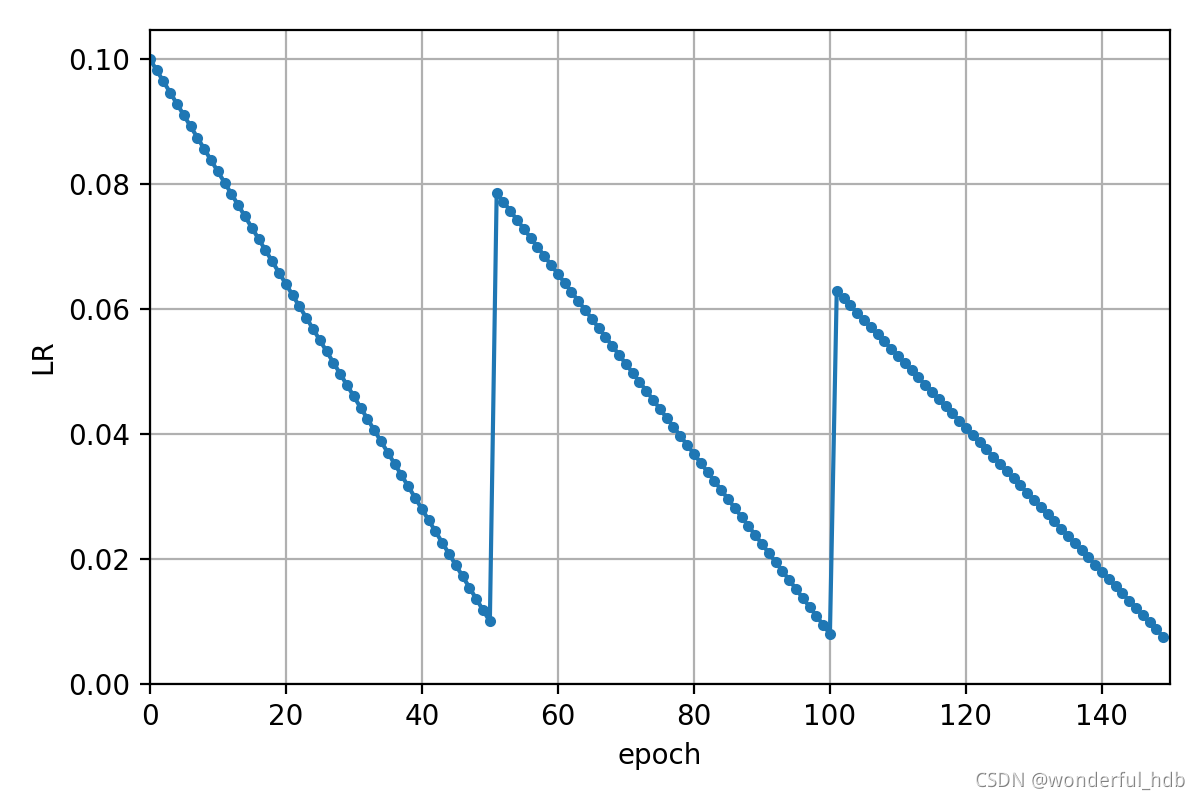
# lf = lambda x, y=opt.epochs: (((1 + math.cos(x * math.pi / y)) / 2) ** 1.0) * 0.9 + 0.1
lf = lambda x, y=opt.epochs: (1.0 - (x / y)) * 0.8 + 0.2
scheduler = CosineAnnealingWarmbootingLR(optimizer, epochs=opt.epochs, step_scale=0.7,
steps=opt.cawb_steps, lf=lf, batchs=len(data), warmup_epoch=0)本实验是在 COCO2017中随机选出 10000 图像和 1000 张图像分别作为训练集和验证集。检测网络使用 yolov5s,学习率调整机制分别原版的 cos 和 本文实现的 CAWB。
# yolov5
lf = lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# 本文
lf = lambda x, y=opt.epochs: (((1 + math.cos(x * math.pi / y)) / 2) ** 1.0) * 0.65 + 0.35
scheduler = CosineAnnealingWarmbootingLR(optimizer, epochs=opt.epochs, steps=opt.cawb_steps, step_scale=0.7,
lf=lf, batchs=len(train_loader), warmup_epoch=3, epoch_scale=4.0)
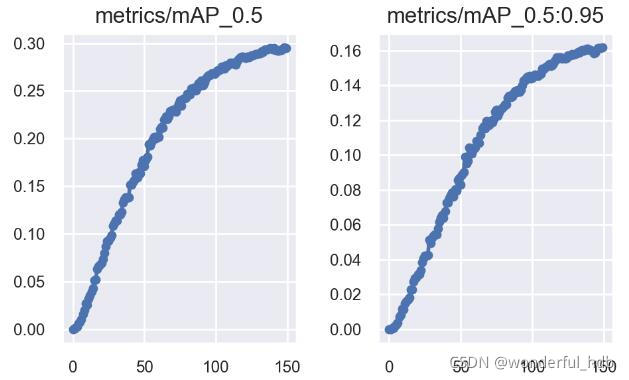
mAP_0.5 = 0.294; mAP_0.5:0.95 = 0.161
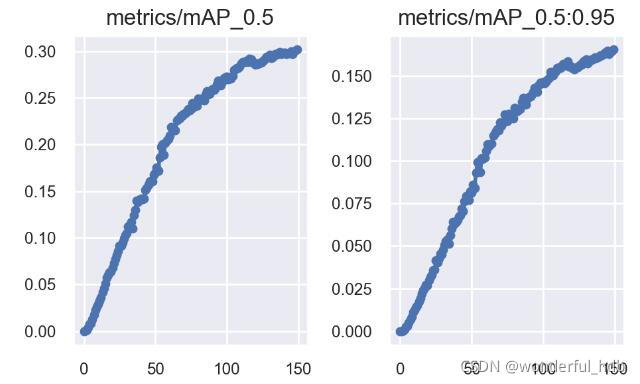
mAP_0.5 = 0.302; mAP_0.5:0.95 = 0.165
在实验中使用了 CAWB 学习率机制时候,mAP_0.5 和 mAP_0.5:0.95 都提升了一丢丢,而且上升趋势更加明显,增加 epochs 可能提升更大。
改变 CAWB 的参数可以实现更多形式的学习率变化机制。增加学习率突变就是想增加网络跳出局部最优的概率,所以不同数据集可能合适不同的变化机制。小伙伴们在其他数据集上尝试之后,记得来提个 issue 哈...