diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..62c8935
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1 @@
+.idea/
\ No newline at end of file
diff --git a/.idea/vcs.xml b/.idea/vcs.xml
new file mode 100644
index 0000000..94a25f7
--- /dev/null
+++ b/.idea/vcs.xml
@@ -0,0 +1,6 @@
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/workspace.xml b/.idea/workspace.xml
index dd437d1..b02df9e 100644
--- a/.idea/workspace.xml
+++ b/.idea/workspace.xml
@@ -1,7 +1,12 @@
-
+
+
+
+
+
+
@@ -14,7 +19,7 @@
-
+
@@ -37,16 +42,44 @@
-
+
-
-
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
@@ -66,6 +99,9 @@
+
+
+
@@ -85,9 +124,10 @@
-
-
+
+
+
@@ -103,8 +143,6 @@
-
-
@@ -117,6 +155,20 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
@@ -137,15 +189,21 @@
+
+
+
+
+
+
-
+
-
-
-
-
-
-
+
+
+
+
+
+
+
+
-
-
-
+
+
-
+
-
+
+
+
+
+
+
+
+
+
+
+
+
+
@@ -381,14 +458,104 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
@@ -423,5 +590,131 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.ipynb_checkpoints/LinearRegressionTutorial-checkpoint.ipynb b/.ipynb_checkpoints/LinearRegressionTutorial-checkpoint.ipynb
new file mode 100644
index 0000000..28bf5a5
--- /dev/null
+++ b/.ipynb_checkpoints/LinearRegressionTutorial-checkpoint.ipynb
@@ -0,0 +1,264 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "# INTRO to Machine Learning\n",
+ "\n",
+ "* Arthur Samuel defines ML as \"the field of study that gives computers the ability to learn without being explicitly programmed.\" \n",
+ "\n",
+ "* Tom Mitchell defines ML as \"[a] computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.\"\n",
+ "\n",
+ "Example: playing checkers.\n",
+ "E = the experience of playing many games of checkers\n",
+ "T = the task of playing checkers.\n",
+ "P = the probability that the program will win the next game.\n",
+ "\n",
+ "\n",
+ "## Supervised Learning vs. Unsupervised Learning\n",
+ "\n",
+ "> __Unsupervised Learning__:\n",
+ "\n",
+ "You are given a dataset but do not have an idea of what the output will be. In some cases relationships are determined to \"cluster\" variables together. In other cases, unsupervised learning is used to seperate things in a chaotic enviroment. \n",
+ "\n",
+ "Clustering Example: Taking a list of NBA player data and stats and grouping players that do similar things together.\n",
+ "Non-Clustering Example: Take a recording of people speakig and isolating the individual voices.\n",
+ "\n",
+ "\n",
+ "> ___Supervised Learning___: \n",
+ "\n",
+ "You are given a data set and already know what our correct output should look like, getting a sense of the relationship between the output and input. Essential, you are given the \"the right answers\". \n",
+ "\n",
+ "There are two kinds of supervised learning problems **REGRESSION & CLASSIFICATION**. Regression is trying to determing the results in a continous output. Classification is outputing inputs into catergories. \n",
+ "\n",
+ "Regresssion Example: A relationship between the hours of study a student puts in and exam results.\n",
+ "\n",
+ "Classification: Spam Detection, classification is used to group emails as spam or not \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## LINEAR REGRESSION "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Linear regression is a very simple approach for supervised learning. Though it may seem somewhat dull compared to some of the more modern algorithms, linear regression is still a useful and widely used statistical learning method. Linear regression is used to predict a quantitative response Y from the predictor variable X. Linear Regression is made with an assumption that there’s a linear relationship between X and Y. The simplest form of Linear Regression is \n",
+ "\n",
+ "$$f(y) = mx + b$$\n",
+ "\n",
+ "where is the equation for a line, where x is the input, m is the slope, and b is where the line crosses the y-axis or y intercept. When mapping multiple inputs to a single output the equation is updated to \n",
+ "\n",
+ "$$\\hat{f}Screen capture(y) = \\sum w_i * x_i = w_0 + w_1 * x_1 + w_2 * x_2 + \\dots + w_n + x_n$$\n",
+ "\n",
+ "In this form the $w_0$ represents the y intercept, the combination of $w_1 \\dots w_n$ correlates to the slope of the line, and $x_1 \\dots x_n$ are the inputs. Each instance of $w_i$ specifies how much each $x_i$ contributes to the output."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will now go through an example of linear regression."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Preliminary **"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "metadata": {
+ "collapsed": true
+ },
+ "outputs": [],
+ "source": [
+ "import pandas as pd\n",
+ "from sklearn import linear_model\n",
+ "import random\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Load Data**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Load the data\n",
+ "df = pd.read_csv('./resources/data/players_stats.csv')\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Explore Data**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# View the first few rows\n",
+ "df.head()\n",
+ "\n",
+ "\n",
+ "#below is some structure that can be observe from data \n",
+ "\"\"\"\n",
+ " From the structure that is represented in the graphs below, it is now possible to\n",
+ " determine what of kind of logic you will be used.\n",
+ "\"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "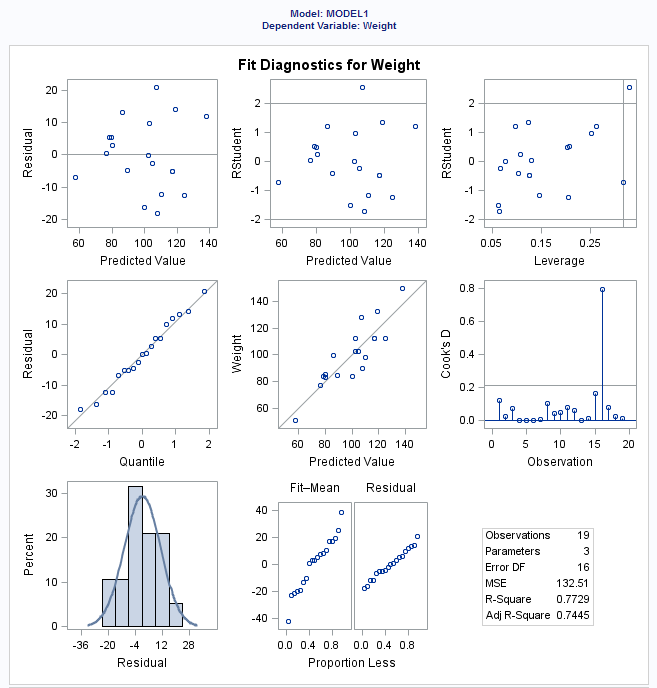"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Example:**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "from scipy import linspace, polyval, polyfit, sqrt, stats, randn\n",
+ "from pylab import plot, title, show , legend\n",
+ "\n",
+ "#Linear regression example\n",
+ "# This is a very simple example of using two scipy tools \n",
+ "# for linear regression, polyfit and stats.linregress\n",
+ "\n",
+ "#Sample data creation\n",
+ "#number of points \n",
+ "n=50\n",
+ "t=linspace(-5,5,n)\n",
+ "#parameters\n",
+ "a=0.8; b=-4\n",
+ "x=polyval([a,b],t)\n",
+ "#add some noise\n",
+ "xn=x+randn(n)\n",
+ "\n",
+ "#Linear regressison -polyfit - polyfit can be used other orders polys\n",
+ "(ar,br)=polyfit(t,xn,1)\n",
+ "xr=polyval([ar,br],t)\n",
+ "#compute the mean square error\n",
+ "err=sqrt(sum((xr-xn)**2)/n)\n",
+ "\n",
+ "print('Linear regression using polyfit')\n",
+ "print('parameters: a=%.2f b=%.2f \\nregression: a=%.2f b=%.2f, ms error= %.3f' % (a,b,ar,br,err))\n",
+ "\n",
+ "#matplotlib ploting\n",
+ "title('Linear Regression Example')\n",
+ "plot(t,x,'g.--')\n",
+ "plot(t,xn,'k.')\n",
+ "plot(t,xr,'r.-')\n",
+ "legend(['original','plus noise', 'regression'])\n",
+ "\n",
+ "show()\n",
+ "\n",
+ "#Linear regression using stats.linregress\n",
+ "(a_s,b_s,r,tt,stderr)=stats.linregress(t,xn)\n",
+ "print('Linear regression using stats.linregress')\n",
+ "print('parameters: a=%.2f b=%.2f \\nregression: a=%.2f b=%.2f, std error= %.3f' % (a,b,a_s,b_s,stderr))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "** Break Data Up Into Training And Test Datasets **"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now for the real work. To judge how how good our model is, we need something to test it against. We can accomplish this using a technique called cross-validation. Cross-validation can get much more complicated and powerful, but in this example we are going do the most simple version of this technique.\n",
+ "\n",
+ "Steps\n",
+ "\n",
+ "1. Divide the dataset into two datasets: A 'training' dataset that we will use to train our model and a 'test' dataset that we will use to judge the accuracy of that model.\n",
+ "2. Train the model on the 'training' data.\n",
+ "3. Apply that model to the test data's X variable, creating the model's guesses for the test data's Ys.\n",
+ "4. Compare how close the model's predictions for the test data's Ys were to the actual test data Ys.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(490, 25)"
+ ]
+ },
+ "execution_count": 15,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "# Create our predictor/independent variable\n",
+ "# and our response/dependent variable\n",
+ "X = df.drop('Playoffs', 1)\n",
+ "y = df['Playoffs']\n",
+ "df.shape\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.1"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/LinearRegressionTutorial.ipynb b/LinearRegressionTutorial.ipynb
new file mode 100644
index 0000000..28bf5a5
--- /dev/null
+++ b/LinearRegressionTutorial.ipynb
@@ -0,0 +1,264 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "# INTRO to Machine Learning\n",
+ "\n",
+ "* Arthur Samuel defines ML as \"the field of study that gives computers the ability to learn without being explicitly programmed.\" \n",
+ "\n",
+ "* Tom Mitchell defines ML as \"[a] computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.\"\n",
+ "\n",
+ "Example: playing checkers.\n",
+ "E = the experience of playing many games of checkers\n",
+ "T = the task of playing checkers.\n",
+ "P = the probability that the program will win the next game.\n",
+ "\n",
+ "\n",
+ "## Supervised Learning vs. Unsupervised Learning\n",
+ "\n",
+ "> __Unsupervised Learning__:\n",
+ "\n",
+ "You are given a dataset but do not have an idea of what the output will be. In some cases relationships are determined to \"cluster\" variables together. In other cases, unsupervised learning is used to seperate things in a chaotic enviroment. \n",
+ "\n",
+ "Clustering Example: Taking a list of NBA player data and stats and grouping players that do similar things together.\n",
+ "Non-Clustering Example: Take a recording of people speakig and isolating the individual voices.\n",
+ "\n",
+ "\n",
+ "> ___Supervised Learning___: \n",
+ "\n",
+ "You are given a data set and already know what our correct output should look like, getting a sense of the relationship between the output and input. Essential, you are given the \"the right answers\". \n",
+ "\n",
+ "There are two kinds of supervised learning problems **REGRESSION & CLASSIFICATION**. Regression is trying to determing the results in a continous output. Classification is outputing inputs into catergories. \n",
+ "\n",
+ "Regresssion Example: A relationship between the hours of study a student puts in and exam results.\n",
+ "\n",
+ "Classification: Spam Detection, classification is used to group emails as spam or not \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## LINEAR REGRESSION "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Linear regression is a very simple approach for supervised learning. Though it may seem somewhat dull compared to some of the more modern algorithms, linear regression is still a useful and widely used statistical learning method. Linear regression is used to predict a quantitative response Y from the predictor variable X. Linear Regression is made with an assumption that there’s a linear relationship between X and Y. The simplest form of Linear Regression is \n",
+ "\n",
+ "$$f(y) = mx + b$$\n",
+ "\n",
+ "where is the equation for a line, where x is the input, m is the slope, and b is where the line crosses the y-axis or y intercept. When mapping multiple inputs to a single output the equation is updated to \n",
+ "\n",
+ "$$\\hat{f}Screen capture(y) = \\sum w_i * x_i = w_0 + w_1 * x_1 + w_2 * x_2 + \\dots + w_n + x_n$$\n",
+ "\n",
+ "In this form the $w_0$ represents the y intercept, the combination of $w_1 \\dots w_n$ correlates to the slope of the line, and $x_1 \\dots x_n$ are the inputs. Each instance of $w_i$ specifies how much each $x_i$ contributes to the output."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will now go through an example of linear regression."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Preliminary **"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "metadata": {
+ "collapsed": true
+ },
+ "outputs": [],
+ "source": [
+ "import pandas as pd\n",
+ "from sklearn import linear_model\n",
+ "import random\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Load Data**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Load the data\n",
+ "df = pd.read_csv('./resources/data/players_stats.csv')\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Explore Data**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# View the first few rows\n",
+ "df.head()\n",
+ "\n",
+ "\n",
+ "#below is some structure that can be observe from data \n",
+ "\"\"\"\n",
+ " From the structure that is represented in the graphs below, it is now possible to\n",
+ " determine what of kind of logic you will be used.\n",
+ "\"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Example:**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "from scipy import linspace, polyval, polyfit, sqrt, stats, randn\n",
+ "from pylab import plot, title, show , legend\n",
+ "\n",
+ "#Linear regression example\n",
+ "# This is a very simple example of using two scipy tools \n",
+ "# for linear regression, polyfit and stats.linregress\n",
+ "\n",
+ "#Sample data creation\n",
+ "#number of points \n",
+ "n=50\n",
+ "t=linspace(-5,5,n)\n",
+ "#parameters\n",
+ "a=0.8; b=-4\n",
+ "x=polyval([a,b],t)\n",
+ "#add some noise\n",
+ "xn=x+randn(n)\n",
+ "\n",
+ "#Linear regressison -polyfit - polyfit can be used other orders polys\n",
+ "(ar,br)=polyfit(t,xn,1)\n",
+ "xr=polyval([ar,br],t)\n",
+ "#compute the mean square error\n",
+ "err=sqrt(sum((xr-xn)**2)/n)\n",
+ "\n",
+ "print('Linear regression using polyfit')\n",
+ "print('parameters: a=%.2f b=%.2f \\nregression: a=%.2f b=%.2f, ms error= %.3f' % (a,b,ar,br,err))\n",
+ "\n",
+ "#matplotlib ploting\n",
+ "title('Linear Regression Example')\n",
+ "plot(t,x,'g.--')\n",
+ "plot(t,xn,'k.')\n",
+ "plot(t,xr,'r.-')\n",
+ "legend(['original','plus noise', 'regression'])\n",
+ "\n",
+ "show()\n",
+ "\n",
+ "#Linear regression using stats.linregress\n",
+ "(a_s,b_s,r,tt,stderr)=stats.linregress(t,xn)\n",
+ "print('Linear regression using stats.linregress')\n",
+ "print('parameters: a=%.2f b=%.2f \\nregression: a=%.2f b=%.2f, std error= %.3f' % (a,b,a_s,b_s,stderr))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "** Break Data Up Into Training And Test Datasets **"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now for the real work. To judge how how good our model is, we need something to test it against. We can accomplish this using a technique called cross-validation. Cross-validation can get much more complicated and powerful, but in this example we are going do the most simple version of this technique.\n",
+ "\n",
+ "Steps\n",
+ "\n",
+ "1. Divide the dataset into two datasets: A 'training' dataset that we will use to train our model and a 'test' dataset that we will use to judge the accuracy of that model.\n",
+ "2. Train the model on the 'training' data.\n",
+ "3. Apply that model to the test data's X variable, creating the model's guesses for the test data's Ys.\n",
+ "4. Compare how close the model's predictions for the test data's Ys were to the actual test data Ys.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(490, 25)"
+ ]
+ },
+ "execution_count": 15,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "# Create our predictor/independent variable\n",
+ "# and our response/dependent variable\n",
+ "X = df.drop('Playoffs', 1)\n",
+ "y = df['Playoffs']\n",
+ "df.shape\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.1"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/Machine Learning is Fun .ipynb b/Machine Learning is Fun .ipynb
deleted file mode 100644
index 9a085db..0000000
--- a/Machine Learning is Fun .ipynb
+++ /dev/null
@@ -1,70 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "\n",
- "# INTRO to Machine Learning\n",
- "\n",
- "* Arthur Samuel defines ML as \"the field of study that gives computers the ability to learn without being explicitly programmed.\" \n",
- "\n",
- "* Tom Mitchell defines ML as \"[a] computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.\"\n",
- "\n",
- "Example: playing checkers.\n",
- "E = the experience of playing many games of checkers\n",
- "T = the task of playing checkers.\n",
- "P = the probability that the program will win the next game.\n",
- "\n",
- "\n",
- "## Supervised Learning vs. Unsupervised Learning\n",
- "\n",
- "> __Unsupervised Learning__:\n",
- "\n",
- "You are given a dataset but do not have an idea of what the output will be. In some cases relationships are determined to \"cluster\" variables together. In other cases, unsupervised learning is used to seperate things in a chaotic enviroment. \n",
- "\n",
- "Clustering Example: Taking a list of NBA player data and stats and grouping players that do similar things together.\n",
- "Non-Clustering Example: Take a recording of people speakig and isolating the individual voices.\n",
- "\n",
- "\n",
- "> ___Supervised Learning___: \n",
- "\n",
- "You are given a data set and already know what our correct output should look like, getting a sense of the relationship between the output and input. Essential, you are given the \"the right answers\". \n",
- "\n",
- "There are two kinds of supervised learning problems **REGRESSION & CLASSIFICATION**. Regression is trying to determing the results in a continous output. Classification is outputing inputs into catergories. \n",
- "\n",
- "Examples: (TO BE ADDED) \n",
- "\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.6.1"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 2
-}
diff --git a/PythonTutorial.ipynb b/PythonTutorial.ipynb
new file mode 100644
index 0000000..bf69c20
--- /dev/null
+++ b/PythonTutorial.ipynb
@@ -0,0 +1,259 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Session 1 Python Tutorial/ Parsing of a File Tutorial\n",
+ "\n",
+ "*Written By: **Nicholas Archibong\n",
+ "\n",
+ "In this Tutorial, you are taken through how to open a csv file, going through the file and checking for a specific entry, changing that entry, adding in a new coloumn, writing the changed file into a new file for other purposes, as well as going over some basics in python. \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Reading in of file\n",
+ "\n",
+ "In this section, the csv module is imported into our script to allow access to some of their useful methods. Such as reading in a file and writing to a file. \n",
+ "\n",
+ "*** You will have to change the readFile and writeFile to the location of the github repository that you cloned onto your desktop"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "import csv # module that contains the csv methods\n",
+ "\n",
+ "readFile = '' # file reading from\n",
+ "writeFile = '' # file writing to\n",
+ "\n",
+ "with open(readFile, 'r') as rf: # open csv file\n",
+ " data = csv.reader(rf) # read in csv file\n",
+ " playerList = list(data) # convert data to list data type\n",
+ " \n",
+ "print(playerList)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Loop Practice\n",
+ "\n",
+ "There are two type of loops in python, the while loop and the for loop. Both have similar functionality, however, they have their key differences. A while loop is used for iterations where the end is not known, while the for loop could be used for iterations where the end is known, or you have a specific number of iterations to complete. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "##### Counting of numbers from 1 to 10\n",
+ "\n",
+ "This example, you are to complete the code to have both the while loop and the for loop count from 1 to 10. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for num in range(,):\n",
+ " print(num)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "countNum = \n",
+ "while countNum <= :\n",
+ " print(countNum)\n",
+ " countNum += "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### More practice with loops\n",
+ "\n",
+ "In the next example, there is a list of strings. You are tasked with completing the code that is missing in order to find the string name 'Avery'. \n",
+ "\n",
+ "Counter Concept: A counter is a variable that typically increments when you go through an iteration of a loop. It's useful in the sense that you could use a counter to access list indices. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# practice with loops\n",
+ "import random\n",
+ "nameList = ['Michael', 'John', 'James', 'Rick', 'Avery', 'Roi', 'Matthew', 'Peter']\n",
+ "random.shuffle(nameList)\n",
+ "\n",
+ "nameCounter = \n",
+ "while nameList[nameCounter] != '':\n",
+ " nameCounter += \n",
+ " print('Avery not found yet in while loop...')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import random\n",
+ "nameList = ['Michael', 'John', 'James', 'Rick', 'Avery', 'Roi', 'Matthew', 'Peter']\n",
+ "random.shuffle(nameList)\n",
+ "\n",
+ "for name in nameList:\n",
+ " if name == '':\n",
+ " break\n",
+ " else:\n",
+ " print('Avery not found yet in for loop...')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### User I/O \n",
+ "\n",
+ "The input funciton is used to gather information from the user. You could type cast it to change the type from string to any of the other data types. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "userInput = 'c'\n",
+ "whileCounter = 1\n",
+ "\n",
+ "while userInput != 'q':\n",
+ " userInput = input('To quit please enter \\'q\\': ').lower()\n",
+ " whileCounter += 1\n",
+ "\n",
+ "print('Program Terminated...')\n",
+ "print('Number of iterations is...%',whileCounter)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### For Loop: Parsing of Strings\n",
+ "\n",
+ "In this section of code, you, the user, are looking for a \"specific value\" in the file. This specific value could be anything you want it, however, in this file, there are missing values \"''\" which you would like to replace with a 'NULL' instead to signify that that particular value was missing. \n",
+ "\n",
+ "A nested for loop is used to access the indcies of the nest list. This allows us to hit every index and check if there if it is missing a value or not. Two counters are used to allow the for loops to traverse the list correctly. \n",
+ "\n",
+ "Python Nested Lists Documentation: http://www.dreamincode.net/forums/topic/193487-a-quick-overview-of-nested-lists-in-python/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "rowCounter = 0; # counter that allows indexing\n",
+ "\n",
+ "for row in playerList:\n",
+ " colCounter = 0; # column counter needs to be resert\n",
+ " for col in row:\n",
+ " if playerList[rowCounter][colCounter] == '': # searching for specific entry\n",
+ " playerList[rowCounter][colCounter] = 'NULL' # replacing when specific entry is found\n",
+ " colCounter += 1\n",
+ " rowCounter += 1\n",
+ "\n",
+ "print(playerList)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Insert of new column\n",
+ "\n",
+ "In this section of code, you are tasked with finding a if that current value of file is greater than 60, if it is, then add a entry, \"1\", indicating that it was true, else add a 0 instead. This allows for the creation of a new coloumn."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "collapsed": true
+ },
+ "outputs": [],
+ "source": [
+ "# creation of new column\n",
+ "playerList[0].append('> 60pts') # add a new column to the 0th row of the list\n",
+ "\n",
+ "for index in range(1,len(playerList)): # begin at the 1st row of the list\n",
+ " if int(playerList[index][5]) > 60: # check if points is > 60\n",
+ " playerList[index].append('1') # adding of new coloumn \n",
+ " else:\n",
+ " playerList[index].append('0')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Writing to new File"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(writeFile, 'w+') as wf: # open to write to csv file\n",
+ " wr = csv.writer(wf, dialect='excel')\n",
+ " wr.writerows(playerList)\n",
+ " \n",
+ "print(playerList)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.1"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 1
+}
diff --git a/README.md b/README.md
index 6e47237..5ae6c73 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,33 @@
-### Hidden Genius - Python & Machine Learning
+# Hidden Genius - Machine Learning
+
+### Curriculum Overview
+This project has two objectives:
+ 1. introduce students to the Python programming language
+ 2. introduce the concept of Machine Learning (ML)
+
+ The curriculum will be broken down into two separate sessions, the first will cover the basics of the Python language,
+ and walk students through examples within the context of preparing a data set for fitting a ML algorithm. The second
+ and final session will involve a high level overview of Machine Learning principles, and commence with an explaination
+ and tutorial of Linear Regression. More information on Python and Machine Learning can be found in the
+ [wiki](https://github.com/packday/HGP_MachineLearning/wiki).
+
+ #### Schedule
+Time | Event Flow | Attendees/Speakers | Notes
+-----| -----------| ------------------ | -----
+9:00AM - 10:15AM | Travel to 2623 Camino Ramon, walk to 2700 BLD | HG staff and students |
+10:15AM – 11:00 AM | Check in, snacks & meet + greet | Melanie & Alexis |
+11:00AM – 11:30AM | Speaker 1 – GE overview, diversity etc. | Caleb Moore |
+11:30AM – 12:30PM | Break + lunch | All |
+12:30PM – 1:00PM | Session 1 – Python/Anaconda | Lead: Victor, Staff: Jon & Nick | [Presentation](https://prezi.com/p/n4sfmsgkmw-e/)
+1:00PM – 2:30PM | Session 2 – Machine Learning | Lead: Patrick, Staff: Stanley |
+2:30PM – 3:00PM | Tour | Melanie & Alexis |
+3:00PM | Departure | HG staff and students |
+
+
+### Anaconda Installation
+Anaconda is the leading open data science platform for the Python language. It is a high performance distribution of
+Python and R, that includes over a 100 of the popular data science packages for Python, R, and Scala programming languages.
+In addition by using conda, a package, dependency, & environment manager; you gain access to another 720 software packages,
+a one stop shop for all of your data science needs.
+
+Anaconda can be downloaded from [here](https://www.continuum.io/downloads).
\ No newline at end of file
diff --git a/resources/data/nba_players.csv b/resources/data/nba_players.csv
new file mode 100644
index 0000000..7311484
--- /dev/null
+++ b/resources/data/nba_players.csv
@@ -0,0 +1 @@
+Name,# of Rings,# of points,# of games,# of assists,career high
Michael Jordan,6,32292,,5633,69
Russel Westbrook,,15000,410,2384,51
LeBron James,4,28787,634,,61
Dwyane Wade,3,21231,612,1234,55
Kevin Durant,1,,439,,54
Stephen Curry,2,35235,378,2343,54
Allen Iverson,,24368,,5624,55
Kobe Bryant,5,31700,1346,,81
Bill Russell,11,14522,963,214,37
\ No newline at end of file
diff --git a/resources/docs/NCAAF HG site visit_final.pptx b/resources/docs/NCAAF HG site visit_final.pptx
new file mode 100644
index 0000000..f10f399
Binary files /dev/null and b/resources/docs/NCAAF HG site visit_final.pptx differ
diff --git a/resources/docs/Python Manual.pdf b/resources/docs/Python Manual.pdf
new file mode 100644
index 0000000..1a40df0
Binary files /dev/null and b/resources/docs/Python Manual.pdf differ