 -#### Conclusion:
+### Conclusion:
It depends on the height of the minimum of the largest buildings on either sides.
**Example:**
@@ -540,12 +593,13 @@ Water stored over building 5 depends on minimum of the largest building on eithe
---
+
### Question
Given N buildings with height of each building, find the rain water trapped between the buildings.
`A = [1, 2, 3, 2, 1]`
-**Choices**
+### Choices
- [ ] 2
- [ ] 9
- [x] 0
@@ -553,44 +607,36 @@ Given N buildings with height of each building, find the rain water trapped betw
-**Explanation:**
+### Explanation:
No water is trapped, Since the building is like a mountain.
-
-
+---
-#### Conclusion:
+### Conclusion:
It depends on the height of the minimum of the largest buildings on either sides.
**Example:**
@@ -540,12 +593,13 @@ Water stored over building 5 depends on minimum of the largest building on eithe
---
+
### Question
Given N buildings with height of each building, find the rain water trapped between the buildings.
`A = [1, 2, 3, 2, 1]`
-**Choices**
+### Choices
- [ ] 2
- [ ] 9
- [x] 0
@@ -553,44 +607,36 @@ Given N buildings with height of each building, find the rain water trapped betw
-**Explanation:**
+### Explanation:
No water is trapped, Since the building is like a mountain.
-
-
+---
 -
-
-
-
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
---
-### Rain Water Trapping Brute Force Approach
+
+## Problem 4 Brute Force Approach
For **ith** building,
We need to find maximum heights on both the left and right sides of **ith** building.
-NOTE: For **0th** and **(N-1)th** building, no water will be stored on top.
+### NOTE:
+For **0th** and **(N-1)th** building, no water will be stored on top.
-#### Pseudocode (Wrong)
+### Pseudocode (Wrong)
```cpp
ans = 0
-
-for (int i = 1; i < N - 1; i++) {
+
+for(i -> 1 to N - 2) {
maxL = max(0 to i - 1); //loop O(N)
maxR = max(i + 1 to N - 1); //loop O(N)
-
+
water = min(maxL, maxR) - A[i];
ans += water;
}
```
-#### Edge Case
+### Edge Case
-
-
-
-
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
---
-### Rain Water Trapping Brute Force Approach
+
+## Problem 4 Brute Force Approach
For **ith** building,
We need to find maximum heights on both the left and right sides of **ith** building.
-NOTE: For **0th** and **(N-1)th** building, no water will be stored on top.
+### NOTE:
+For **0th** and **(N-1)th** building, no water will be stored on top.
-#### Pseudocode (Wrong)
+### Pseudocode (Wrong)
```cpp
ans = 0
-
-for (int i = 1; i < N - 1; i++) {
+
+for(i -> 1 to N - 2) {
maxL = max(0 to i - 1); //loop O(N)
maxR = max(i + 1 to N - 1); //loop O(N)
-
+
water = min(maxL, maxR) - A[i];
ans += water;
}
```
-#### Edge Case
+### Edge Case
) @@ -600,29 +646,28 @@ water = **3 - 4 < 0**
So, for such case, we'll take water stored as 0.
-#### Pseudocode (Correct)
+### Pseudocode (Correct)
```cpp
ans = 0
-
-for (int i = 1; i < N - 1; i++) {
+
+for(i -> 1 to N - 2) {
maxL = max(0 to i - 1); //loop O(N)
maxR = max(i + 1 to N - 1); //loop O(N)
-
+
water = min(maxL, maxR) - A[i];
-
- if (water > 0) {
+
+ if(water > 0) {
ans += water;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2) {Since for every element, we'll loop to find max on left and right}
**Space Complexity:** O(N)
----
-### Rain Water Trapping Optimised Approach
+## Problem 4 Optimised Approach (Reduce TC)
We can store the max on right & left using carry forward approach.
* We can take 2 arrays, lmax[] & rmax[].
@@ -631,37 +676,30 @@ We can store the max on right & left using carry forward approach.
@@ -600,29 +646,28 @@ water = **3 - 4 < 0**
So, for such case, we'll take water stored as 0.
-#### Pseudocode (Correct)
+### Pseudocode (Correct)
```cpp
ans = 0
-
-for (int i = 1; i < N - 1; i++) {
+
+for(i -> 1 to N - 2) {
maxL = max(0 to i - 1); //loop O(N)
maxR = max(i + 1 to N - 1); //loop O(N)
-
+
water = min(maxL, maxR) - A[i];
-
- if (water > 0) {
+
+ if(water > 0) {
ans += water;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2) {Since for every element, we'll loop to find max on left and right}
**Space Complexity:** O(N)
----
-### Rain Water Trapping Optimised Approach
+## Problem 4 Optimised Approach (Reduce TC)
We can store the max on right & left using carry forward approach.
* We can take 2 arrays, lmax[] & rmax[].
@@ -631,37 +676,30 @@ We can store the max on right & left using carry forward approach.
 -#### Pseudocode
+### Pseudocode
```cpp
ans = 0;
-int lmax[N] = {
- 0
-};
-for (int i = 1; i < N; i++) {
+lmax[N] = {0};
+for(i -> 1 to N - 1) {
lmax[i] = max(lmax[i - 1], A[i - 1]);
}
-int rmax[N] = {
- 0
-};
-for (int i = N - 2; i >= 0; i--) {
+int rmax[N] = {0};
+for(i -> N - 2 down to 0) {
rmax[i] = max(rmax[i + 1], A[i + 1]);
}
-for (int i = 1; i < N - 1; i++) {
+for(i -> 1 to N - 2) {
water = min(lmax[i], rmax[i]) - A[i];
-
- if (water > 0) {
+
+ if(water > 0) {
ans += water;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N) {Since we have precalculated lmax & rmax}
-**Space Complexity:** O(N)
-
-
-
+**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md b/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md
index b8e1967..7c1c47a 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md
@@ -1,47 +1,100 @@
# Advanced DSA : Arrays 2: Two Dimensional
+## Revision Quizzes
+
+### Question
+Which algorithm would you choose as most efficient to find the maximum subarray sum efficiently?
+
+### Choices
+- [ ] Brute Force algorithm
+- [x] Kadane's Algorithm
+- [ ] Dijkstra's Algorithm
+- [ ] Moore's Voting algorithm
+
+
+---
+### Question
+In the context of finding the maximum subarray sum, what does the 'carry forward' technique imply?
+
+### Choices
+- [ ] Using a stack to store elements
+- [ ] Using recursion for sum calculation
+- [x] Continuously adding elements while maintaining the maximum sum
+- [ ] Using two pointers for sum calculation
+
+---
+
+### Question
+How can the time complexity be optimized for performing multiple increment operation queries from index i to last index in an array?
+
+### Choices
+- [ ] by using stack
+- [x] by using prefix sums
+- [ ] by using recursion
+- [ ] by using a queue
+
+---
+
+### Question
+What is the optimized time complexity for handling multiple range queries using the prefix sum technique?
+
+### Choices
+- [x] O(Q + N)
+- [ ] O(Q * N)
+- [ ] O(Q^2^)
+- [ ] O(N^2^)
+
---
-## Problem 1 Find in rowise and colwise sorted matrix
+
+### Question
+In the problem of rainwater trapping, what does the water stored over a building depend on?
+
+### Choices
+- [ ] the width of the building
+- [ ] the height of the building
+- [x] the minimum of the maximum heights on either side of the building
+- [ ] the total number of buildings
+
+---
+
+## Problem 1 Find in rowwise and colwise sorted matrix
### Problem Statement
Given a row wise and column wise sorted matrix, find out whether element **k** is present or not.
-**Example**
+### Example
Observe that rows and columns are both sorted.
-
-#### Pseudocode
+### Pseudocode
```cpp
ans = 0;
-int lmax[N] = {
- 0
-};
-for (int i = 1; i < N; i++) {
+lmax[N] = {0};
+for(i -> 1 to N - 1) {
lmax[i] = max(lmax[i - 1], A[i - 1]);
}
-int rmax[N] = {
- 0
-};
-for (int i = N - 2; i >= 0; i--) {
+int rmax[N] = {0};
+for(i -> N - 2 down to 0) {
rmax[i] = max(rmax[i + 1], A[i + 1]);
}
-for (int i = 1; i < N - 1; i++) {
+for(i -> 1 to N - 2) {
water = min(lmax[i], rmax[i]) - A[i];
-
- if (water > 0) {
+
+ if(water > 0) {
ans += water;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N) {Since we have precalculated lmax & rmax}
-**Space Complexity:** O(N)
-
-
-
+**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md b/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md
index b8e1967..7c1c47a 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Arrays 2 Two Dimensional.md
@@ -1,47 +1,100 @@
# Advanced DSA : Arrays 2: Two Dimensional
+## Revision Quizzes
+
+### Question
+Which algorithm would you choose as most efficient to find the maximum subarray sum efficiently?
+
+### Choices
+- [ ] Brute Force algorithm
+- [x] Kadane's Algorithm
+- [ ] Dijkstra's Algorithm
+- [ ] Moore's Voting algorithm
+
+
+---
+### Question
+In the context of finding the maximum subarray sum, what does the 'carry forward' technique imply?
+
+### Choices
+- [ ] Using a stack to store elements
+- [ ] Using recursion for sum calculation
+- [x] Continuously adding elements while maintaining the maximum sum
+- [ ] Using two pointers for sum calculation
+
+---
+
+### Question
+How can the time complexity be optimized for performing multiple increment operation queries from index i to last index in an array?
+
+### Choices
+- [ ] by using stack
+- [x] by using prefix sums
+- [ ] by using recursion
+- [ ] by using a queue
+
+---
+
+### Question
+What is the optimized time complexity for handling multiple range queries using the prefix sum technique?
+
+### Choices
+- [x] O(Q + N)
+- [ ] O(Q * N)
+- [ ] O(Q^2^)
+- [ ] O(N^2^)
+
---
-## Problem 1 Find in rowise and colwise sorted matrix
+
+### Question
+In the problem of rainwater trapping, what does the water stored over a building depend on?
+
+### Choices
+- [ ] the width of the building
+- [ ] the height of the building
+- [x] the minimum of the maximum heights on either side of the building
+- [ ] the total number of buildings
+
+---
+
+## Problem 1 Find in rowwise and colwise sorted matrix
### Problem Statement
Given a row wise and column wise sorted matrix, find out whether element **k** is present or not.
-**Example**
+### Example
Observe that rows and columns are both sorted.
- -
-**Test Case 1**
+
-
-**Test Case 1**
+ +
+ +
+) @@ -93,8 +146,7 @@ Now, **-2 < 0**, all elements on left of -2 are lesser than -2, hence can be neg
**Move Down**
@@ -93,8 +146,7 @@ Now, **-2 < 0**, all elements on left of -2 are lesser than -2, hence can be neg
**Move Down**
 -
-#### Approach
+### Approach
* We can start at top right cell.
* If A[i][j] < K, move down, else move left.
@@ -103,139 +155,29 @@ Now, **-2 < 0**, all elements on left of -2 are lesser than -2, hence can be neg
**NOTE:** We could have also started at bottom left cell.
-#### Pseudocode
+
+### Pseudocode
```cpp
-int i = 0, j = M - 1
-while (i < N && j >= 0) {
- if (arr[i][j] == K) {
- return true;
- } else if (arr[i][j] < K) {
- i++; //move down; next row
- } else {
- j--; //move left; previous column
- }
+i = 0, j = M - 1
+while(i < N && j>= 0){
+ if(arr[i][j] == K){
+ return true;
+ } else if(arr[i][j] < K){
+ i++; //move down; next row
+ } else{
+ j--; //move left; previous column
+ }
}
return false;
```
-#### Time & Space Complexity
+### Time & Space Complexity
**Time Complexity:** O(M+N) since at every step, we are either discarding a row or a column. Since total rows+columns are N+M, hence Iterations will be N+M.
**Space Complexity:** O(1)
----
-### Problem 2 Row with maximum number of 1s
-
-
-Given a binary sorted matrix A of size N x N. Find the row with the maximum number of 1.
-
-NOTE:
-
-* If two rows have the maximum number of 1 then return the row which has a lower index.
-* Assume each row to be sorted by values.
-
-
-**Example 1:**
-
-
-#### Approach
+### Approach
* We can start at top right cell.
* If A[i][j] < K, move down, else move left.
@@ -103,139 +155,29 @@ Now, **-2 < 0**, all elements on left of -2 are lesser than -2, hence can be neg
**NOTE:** We could have also started at bottom left cell.
-#### Pseudocode
+
+### Pseudocode
```cpp
-int i = 0, j = M - 1
-while (i < N && j >= 0) {
- if (arr[i][j] == K) {
- return true;
- } else if (arr[i][j] < K) {
- i++; //move down; next row
- } else {
- j--; //move left; previous column
- }
+i = 0, j = M - 1
+while(i < N && j>= 0){
+ if(arr[i][j] == K){
+ return true;
+ } else if(arr[i][j] < K){
+ i++; //move down; next row
+ } else{
+ j--; //move left; previous column
+ }
}
return false;
```
-#### Time & Space Complexity
+### Time & Space Complexity
**Time Complexity:** O(M+N) since at every step, we are either discarding a row or a column. Since total rows+columns are N+M, hence Iterations will be N+M.
**Space Complexity:** O(1)
----
-### Problem 2 Row with maximum number of 1s
-
-
-Given a binary sorted matrix A of size N x N. Find the row with the maximum number of 1.
-
-NOTE:
-
-* If two rows have the maximum number of 1 then return the row which has a lower index.
-* Assume each row to be sorted by values.
-
-
-**Example 1:**
- -
-**Output 1:** 0th row
-
-
-**Example 2:**
-
-
-**Output 1:** 0th row
-
-
-**Example 2:**
- -
-**Output 2:** 3th row
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Brute Force
-
-We can iterate over each row and maintain the max number of 1s.
-
-
-#### Complexity
-**Time Complexity:** O(N * N)
-
-
-
----
-### Question
-Find the row with the maximum number of 1.
-Note : If there are two rows with same no. of 1, consider the smaller row.
-| **0** | **1** | **1** | **1** |
-|---|---|---|---|
-| **0** | **0** | **0** | **1** |
-| **1** | **1** | **1** | **1** |
-| **1** | **1** | **1** | **1** |
-
-**Choices**
-- [ ] 0th Row
-- [ ] 1st Row
-- [x] 2nd Row
-- [ ] 3rd Row
-
-
-
----
-
-### Optimisation Approach
-
-We know that rows are sorted, how can we utilise this property of the matrix ?
-
-#### Idea
-
-Say we start from top right of first row and saw that there are 2 ones.
-Now, in the next row, we don't want to see 2 1s, rather we'll check if 3rd 1 is present or not?
-
-
-
-**Output 2:** 3th row
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Brute Force
-
-We can iterate over each row and maintain the max number of 1s.
-
-
-#### Complexity
-**Time Complexity:** O(N * N)
-
-
-
----
-### Question
-Find the row with the maximum number of 1.
-Note : If there are two rows with same no. of 1, consider the smaller row.
-| **0** | **1** | **1** | **1** |
-|---|---|---|---|
-| **0** | **0** | **0** | **1** |
-| **1** | **1** | **1** | **1** |
-| **1** | **1** | **1** | **1** |
-
-**Choices**
-- [ ] 0th Row
-- [ ] 1st Row
-- [x] 2nd Row
-- [ ] 3rd Row
-
-
-
----
-
-### Optimisation Approach
-
-We know that rows are sorted, how can we utilise this property of the matrix ?
-
-#### Idea
-
-Say we start from top right of first row and saw that there are 2 ones.
-Now, in the next row, we don't want to see 2 1s, rather we'll check if 3rd 1 is present or not?
-
- -
-If yes, it means we have three 1s, but then we want to check if more 1s are there, so we'll move towards left in the same row and check.
-
-
-
-If yes, it means we have three 1s, but then we want to check if more 1s are there, so we'll move towards left in the same row and check.
-
- -
-Now, in the subsequent rows, we'll proceed in the same manner.
-
-In 2nd and 3rd rows, 1 is not present at 1st index.
-
-In 4th row, it is present. So, we check on left if more 1s are present.
-
-In 4th row, we found the maximum 1s, i.e 5 in total. Hence that is our answer.
-
-#### Algorithm
-
-1. Start at i = 0, j = M - 1
-2. If 1 is present, decrement j i.e, move towards the left column.
- * Whenever j is decremented, it means that row has more 1s, so we can update our answer to that particular row number
-4. If 0 is present, then we want to check in next row that if 1 is present, so we increment i
-
-
-
-#### Pseudocode
-```cpp
-i = 0, j = N - 1
-
-while (i < N && j >= 0) {
- while (j >= 0 && arr[i][j] == 1) {
- j--;
- ans = i;
- }
- i++;
-}
-return ans;
-
-```
-
-#### Complexity
-**Time Complexity:** O(M + N) since at every step, we are either discarding a row or a column. Since total rows+columns are N+M, hence Iterations will be N+M.
-**Space Complexity:** O(1)
-
-
-
----
-### Problem 3 Print Boundary Elements
+## Problem 2 Print Boundary Elements
+### Print Boundary Elements
Given an matrix of N X N i.e. Mat[N][N], print boundary elements in clockwise direction.
@@ -249,6 +191,7 @@ N = 5
---
+
### Question
Given N and matrix mat, select the correct order of boundary elements traversed in clockwise direction.
```cpp
@@ -261,75 +204,99 @@ mat :-
| **7** | **8** | **9** |
-**Choices**
+### Choices
- [x] [1, 2, 3, 6, 9, 8, 7, 4]
- [ ] [1, 4, 7, 8, 9, 6, 3, 2]
- [ ] [1, 2, 3, 4, 5, 6, 7, 8]
- [ ] [2, 3, 4, 5, 6, 7, 8, 9]
+---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+### Approach
* Print N - 1 elements of first row from left to right
* Print N - 1 elements of last column from top to bottom
* Print N - 1 elements of last row from right to left
* Print N - 1 elements of first column from bottom to top
-#### Pseudocode
+### Pseudocode
```cpp
function printBoundaryElements(Mat[][], N) {
- i = 0 j = 0
+ i = 0 j = 0
+
+ // Print N - 1 elements of first row from left to right
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ j++
+ }
+
+ // Print N - 1 elements of last column from top to bottom
+ // i and j will already be 0 and 4 respectively after above loop ends
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ i++
+ }
+
+ // Print N - 1 elements of last row from right to left
+ // i and j will already be 4 and 4 respectively after above loop ends
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ j--
+ }
+
+ // Print N - 1 elements of first column from bottom to top
+ // i and j will already be 4 and 0 respectively after above loop ends
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ i--
+ }
+}
+```
+### Complexity
+**Time Complexity : O(N)**
+**Space Complexity : O(1)**
- // Print N - 1 elements of first row from left to right
+---
+## Problem 3 Lawn Mowing Challenge
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j++
- }
+### Scenerio
- // Print N - 1 elements of last column from top to bottom
- // i and j will already be 0 and 4 respectively after above loop ends
+You need to program an automated grass-mowing robot for "**GreenTech Robotics**" to navigate a square lawn (**N x N**) represented as a grid. The lawn is designed as a **square grid**, where each cell in the grid shows the grass height in that area...
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i++
- }
+### Problem Statement
- // Print N - 1 elements of last row from right to left
- // i and j will already be 4 and 4 respectively after above loop ends
+Your challenge is to find out the heights of grass patches that the robot needs to cut (in the order they are cut), with the robot's path following a **spiral pattern** from the **outer** edge towards the **center** of the lawn.
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j--
- }
- // Print N - 1 elements of first column from bottom to top
- // i and j will already be 4 and 0 respectively after above loop ends
+### Example
+**Input 1 :**
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i--
- }
-}
-```
-#### Complexity
-**Time Complexity : O(N)**
-**Space Complexity : O(1)**
----
-### Problem 4 Spiral Matrix
+| 1 | 2 | 3 | 4 | 5 |
+| --- | --- | --- | --- | --- |
+| 16 | 17 | 18 | 19 | 6 |
+| 15 | 24 | 25 | 20 | 7 |
+| 14 | 23 | 22 | 21 | 8 |
+| 13 | 12 | 11 | 10 | 9 |
-Given an matrix of N X N i.e. Mat[N][N]. Print elements in spiral order in clockwise direction.
+**OUTPUT :-**
+[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 ]
-**Example**
-```cpp
-N = 5
-```
+**Explanation :-**
+- The robot travels level by level starting from Level 1 -> Level 2 -> Level 3.
+- The order in which the robot travels is also displayed
+- Level 1 :- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
+- Level 2 :- [17, 18, 19, 20, 21, 22, 23, 24]
+- Level 3 :- [25]
+
+### Understanding Traversal
+
-
-Now, in the subsequent rows, we'll proceed in the same manner.
-
-In 2nd and 3rd rows, 1 is not present at 1st index.
-
-In 4th row, it is present. So, we check on left if more 1s are present.
-
-In 4th row, we found the maximum 1s, i.e 5 in total. Hence that is our answer.
-
-#### Algorithm
-
-1. Start at i = 0, j = M - 1
-2. If 1 is present, decrement j i.e, move towards the left column.
- * Whenever j is decremented, it means that row has more 1s, so we can update our answer to that particular row number
-4. If 0 is present, then we want to check in next row that if 1 is present, so we increment i
-
-
-
-#### Pseudocode
-```cpp
-i = 0, j = N - 1
-
-while (i < N && j >= 0) {
- while (j >= 0 && arr[i][j] == 1) {
- j--;
- ans = i;
- }
- i++;
-}
-return ans;
-
-```
-
-#### Complexity
-**Time Complexity:** O(M + N) since at every step, we are either discarding a row or a column. Since total rows+columns are N+M, hence Iterations will be N+M.
-**Space Complexity:** O(1)
-
-
-
----
-### Problem 3 Print Boundary Elements
+## Problem 2 Print Boundary Elements
+### Print Boundary Elements
Given an matrix of N X N i.e. Mat[N][N], print boundary elements in clockwise direction.
@@ -249,6 +191,7 @@ N = 5
---
+
### Question
Given N and matrix mat, select the correct order of boundary elements traversed in clockwise direction.
```cpp
@@ -261,75 +204,99 @@ mat :-
| **7** | **8** | **9** |
-**Choices**
+### Choices
- [x] [1, 2, 3, 6, 9, 8, 7, 4]
- [ ] [1, 4, 7, 8, 9, 6, 3, 2]
- [ ] [1, 2, 3, 4, 5, 6, 7, 8]
- [ ] [2, 3, 4, 5, 6, 7, 8, 9]
+---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+### Approach
* Print N - 1 elements of first row from left to right
* Print N - 1 elements of last column from top to bottom
* Print N - 1 elements of last row from right to left
* Print N - 1 elements of first column from bottom to top
-#### Pseudocode
+### Pseudocode
```cpp
function printBoundaryElements(Mat[][], N) {
- i = 0 j = 0
+ i = 0 j = 0
+
+ // Print N - 1 elements of first row from left to right
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ j++
+ }
+
+ // Print N - 1 elements of last column from top to bottom
+ // i and j will already be 0 and 4 respectively after above loop ends
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ i++
+ }
+
+ // Print N - 1 elements of last row from right to left
+ // i and j will already be 4 and 4 respectively after above loop ends
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ j--
+ }
+
+ // Print N - 1 elements of first column from bottom to top
+ // i and j will already be 4 and 0 respectively after above loop ends
+
+ for(idx -> 1 to N - 1 ){
+ print(Mat[i][j] + ",")
+ i--
+ }
+}
+```
+### Complexity
+**Time Complexity : O(N)**
+**Space Complexity : O(1)**
- // Print N - 1 elements of first row from left to right
+---
+## Problem 3 Lawn Mowing Challenge
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j++
- }
+### Scenerio
- // Print N - 1 elements of last column from top to bottom
- // i and j will already be 0 and 4 respectively after above loop ends
+You need to program an automated grass-mowing robot for "**GreenTech Robotics**" to navigate a square lawn (**N x N**) represented as a grid. The lawn is designed as a **square grid**, where each cell in the grid shows the grass height in that area...
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i++
- }
+### Problem Statement
- // Print N - 1 elements of last row from right to left
- // i and j will already be 4 and 4 respectively after above loop ends
+Your challenge is to find out the heights of grass patches that the robot needs to cut (in the order they are cut), with the robot's path following a **spiral pattern** from the **outer** edge towards the **center** of the lawn.
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j--
- }
- // Print N - 1 elements of first column from bottom to top
- // i and j will already be 4 and 0 respectively after above loop ends
+### Example
+**Input 1 :**
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i--
- }
-}
-```
-#### Complexity
-**Time Complexity : O(N)**
-**Space Complexity : O(1)**
----
-### Problem 4 Spiral Matrix
+| 1 | 2 | 3 | 4 | 5 |
+| --- | --- | --- | --- | --- |
+| 16 | 17 | 18 | 19 | 6 |
+| 15 | 24 | 25 | 20 | 7 |
+| 14 | 23 | 22 | 21 | 8 |
+| 13 | 12 | 11 | 10 | 9 |
-Given an matrix of N X N i.e. Mat[N][N]. Print elements in spiral order in clockwise direction.
+**OUTPUT :-**
+[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 ]
-**Example**
-```cpp
-N = 5
-```
+**Explanation :-**
+- The robot travels level by level starting from Level 1 -> Level 2 -> Level 3.
+- The order in which the robot travels is also displayed
+- Level 1 :- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
+- Level 2 :- [17, 18, 19, 20, 21, 22, 23, 24]
+- Level 3 :- [25]
+
+### Understanding Traversal
+
 Here is the depiction to understand the problem better
@@ -337,21 +304,16 @@ Here is the depiction to understand the problem better
Here is the depiction to understand the problem better
@@ -337,21 +304,16 @@ Here is the depiction to understand the problem better
 ```cpp
-Solution = [1,2,3,4,5,6,12,18,24,30,36,35,34,33,32,31,25,19,13,7,8,9,10,11,17,23,29,28,27,26,20,14,15,16,22,21]
+Complete Path of the Robot = [1,2,3,4,5,6,12,18,24,30,36,35,34,33,32,31,25,19,13,7,8,9,10,11,17,23,29,28,27,26,20,14,15,16,22,21]
```
The red arrow represents direction of traversal(clockwise) and fashion in which elements are traversed.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Approach
+### Approach
* We can break the problem into several boundary printing problem discussed above
-* So first print boundary of matrix of N x N
-* Then we print boundary of next submatrix with top left element being (1,1) and Bottom right element being (N - 2 , N - 2).
-* After every boundary, to print the next boundary, N will be reduced by 2 and i & j will be incremented by 1.
+* So first create boundary of matrix of N x N
+* Then we create boundary of next submatrix with top left element being (1,1) and Bottom right element being (N - 2 , N - 2).
+* After every boundary, to create the next boundary, N will be reduced by 2 and i & j will be incremented by 1.
* We do this till matrix of size least size is reached.
```cpp
-Solution = [1,2,3,4,5,6,12,18,24,30,36,35,34,33,32,31,25,19,13,7,8,9,10,11,17,23,29,28,27,26,20,14,15,16,22,21]
+Complete Path of the Robot = [1,2,3,4,5,6,12,18,24,30,36,35,34,33,32,31,25,19,13,7,8,9,10,11,17,23,29,28,27,26,20,14,15,16,22,21]
```
The red arrow represents direction of traversal(clockwise) and fashion in which elements are traversed.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Approach
+### Approach
* We can break the problem into several boundary printing problem discussed above
-* So first print boundary of matrix of N x N
-* Then we print boundary of next submatrix with top left element being (1,1) and Bottom right element being (N - 2 , N - 2).
-* After every boundary, to print the next boundary, N will be reduced by 2 and i & j will be incremented by 1.
+* So first create boundary of matrix of N x N
+* Then we create boundary of next submatrix with top left element being (1,1) and Bottom right element being (N - 2 , N - 2).
+* After every boundary, to create the next boundary, N will be reduced by 2 and i & j will be incremented by 1.
* We do this till matrix of size least size is reached.
 @@ -359,11 +321,12 @@ Please take some time to think about the solution approach on your own before re
Boundaries of submatricies are highlighted in different color.
-#### Edge Case
+### Edge Case
Will the above code work if matrix size is 1 ?
No, since the loops run N-1 times, therefore we have to handle it separately.
---
+
### Question
Print elements in spiral order in clockwise direction.
@@ -374,64 +337,53 @@ Print elements in spiral order in clockwise direction.
|**10**|**5**|**6**|**11**|
-**Choices**
+### Choices
- [ ] [13, 9, 0, 10, 5, 6, 11, 0, 7, 8, 12, 14, 1, 4, 2, 3]
- [ ] [13, 14, 12, 8, 9, 1, 2, 7, 0, 4, 3, 0, 10, 5, 6, 11]
- [x] [13, 14, 12, 8, 7, 0, 11, 6, 5, 10, 0, 9, 1, 2, 3, 4]
- [ ] [13, 14, 12, 8, 10, 5, 6, 11, 9, 1, 2, 7, 0, 4, 3, 0]
+---
-
-#### Pseudocode
+### Pseudocode
```cpp
-Function printBoundaryElements(Mat[][], N) {
- i = 0 j = 0
- while (N > 1) {
-
- // Print N-1 elements of first row from left to right
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j++
+function printGrass(mat[][]) {
+ N = mat.length, r = 0, c = 0;
+
+ while(N > 1){
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ c++;
+ }
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ r++;
+ }
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ c--;
+ }
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ r--;
+ }
+ r += 1;
+ c += 1;
+ N -= 2;
}
-
- // Print N-1 elements of last column from top to bottom
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i++
+
+ if(N == 1){
+ print(mat[r][c]);
}
-
- // Print N-1 elements of last row from right to left
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j--
- }
-
- // Print N-1 elements of first column from bottom to top
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i--
- }
-
- N = N - 2
- i++
- j++
- }
-
- if (N == 1) {
- print(Mat[i][j] + ",")
- }
}
-
```
-#### Complexity
-**Time Complexity : $O(N^2)$**
-**Space Complexity : O(1)**
----
-## What is a submatrices and how can we uniquely identify it
+### Complexity
+**Time Complexity : $O(N^2)$**
+**Space Complexity : $O(N^2)$**
-### What is a submatrix?
+## What is a submatrix?
Same as how a subarray is continuous part of an Array, a submatrix is continuous sub-matrix of a matrix.
@@ -444,7 +396,7 @@ Example,
is submatrix of the below matrix.
-
@@ -359,11 +321,12 @@ Please take some time to think about the solution approach on your own before re
Boundaries of submatricies are highlighted in different color.
-#### Edge Case
+### Edge Case
Will the above code work if matrix size is 1 ?
No, since the loops run N-1 times, therefore we have to handle it separately.
---
+
### Question
Print elements in spiral order in clockwise direction.
@@ -374,64 +337,53 @@ Print elements in spiral order in clockwise direction.
|**10**|**5**|**6**|**11**|
-**Choices**
+### Choices
- [ ] [13, 9, 0, 10, 5, 6, 11, 0, 7, 8, 12, 14, 1, 4, 2, 3]
- [ ] [13, 14, 12, 8, 9, 1, 2, 7, 0, 4, 3, 0, 10, 5, 6, 11]
- [x] [13, 14, 12, 8, 7, 0, 11, 6, 5, 10, 0, 9, 1, 2, 3, 4]
- [ ] [13, 14, 12, 8, 10, 5, 6, 11, 9, 1, 2, 7, 0, 4, 3, 0]
+---
-
-#### Pseudocode
+### Pseudocode
```cpp
-Function printBoundaryElements(Mat[][], N) {
- i = 0 j = 0
- while (N > 1) {
-
- // Print N-1 elements of first row from left to right
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j++
+function printGrass(mat[][]) {
+ N = mat.length, r = 0, c = 0;
+
+ while(N > 1){
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ c++;
+ }
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ r++;
+ }
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ c--;
+ }
+ for(i -> 1 to N - 1){
+ print(mat[r][c]);
+ r--;
+ }
+ r += 1;
+ c += 1;
+ N -= 2;
}
-
- // Print N-1 elements of last column from top to bottom
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i++
+
+ if(N == 1){
+ print(mat[r][c]);
}
-
- // Print N-1 elements of last row from right to left
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- j--
- }
-
- // Print N-1 elements of first column from bottom to top
- for (idx = 1; idx < N; idx++) {
- print(Mat[i][j] + ",")
- i--
- }
-
- N = N - 2
- i++
- j++
- }
-
- if (N == 1) {
- print(Mat[i][j] + ",")
- }
}
-
```
-#### Complexity
-**Time Complexity : $O(N^2)$**
-**Space Complexity : O(1)**
----
-## What is a submatrices and how can we uniquely identify it
+### Complexity
+**Time Complexity : $O(N^2)$**
+**Space Complexity : $O(N^2)$**
-### What is a submatrix?
+## What is a submatrix?
Same as how a subarray is continuous part of an Array, a submatrix is continuous sub-matrix of a matrix.
@@ -444,7 +396,7 @@ Example,
is submatrix of the below matrix.
- +
+ +
+) @@ -485,11 +439,9 @@ All Possible sub-matrices are -
Total Sum = 166
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+
+### Problem 4 Approach
This question sounds same as "Sum of all Subarray Sums". We did that question is Intermediate - Subarrays. The technique used was Contribution Technique, where for every element we had to find that in how many subarrays it was part of.
@@ -497,14 +449,14 @@ In "Sum of all Submatrices Sums", we have to find that in how many submatrices a
If we are able to find that, then we just have to add up the individual results.
-#### In what all submatrices, a particular element is part of ?
+### In what all submatrices, a particular element is part of ?
Let's look at the red cell in below figure.
If we combine all the top left cells(marked with green color) with all the bottom right cells(marked with blue color), then in all those submatrices, the red cell will be present.
@@ -485,11 +439,9 @@ All Possible sub-matrices are -
Total Sum = 166
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+
+### Problem 4 Approach
This question sounds same as "Sum of all Subarray Sums". We did that question is Intermediate - Subarrays. The technique used was Contribution Technique, where for every element we had to find that in how many subarrays it was part of.
@@ -497,14 +449,14 @@ In "Sum of all Submatrices Sums", we have to find that in how many submatrices a
If we are able to find that, then we just have to add up the individual results.
-#### In what all submatrices, a particular element is part of ?
+### In what all submatrices, a particular element is part of ?
Let's look at the red cell in below figure.
If we combine all the top left cells(marked with green color) with all the bottom right cells(marked with blue color), then in all those submatrices, the red cell will be present.
) -#### How to find the number of TL cells and BR cells in which (i,j) is part of.
+### How to find the number of TL cells and BR cells in which (i,j) is part of.
-#### How to find the number of TL cells and BR cells in which (i,j) is part of.
+### How to find the number of TL cells and BR cells in which (i,j) is part of.
) @@ -518,14 +470,14 @@ rows: [i N-1]
cols: [j M-1]
total cells = (N-i) * (M-j)
-#### Now, to find the total submatrices of whish (i,j) is part of -
+### Now, to find the total submatrices of whish (i,j) is part of -
**contribution of (i,j) = TOP LEFT * BOTTOM RIGHT**
Every top left cell can be combined with every bottom right cell.
-**Example**
+### Example
-
@@ -518,14 +470,14 @@ rows: [i N-1]
cols: [j M-1]
total cells = (N-i) * (M-j)
-#### Now, to find the total submatrices of whish (i,j) is part of -
+### Now, to find the total submatrices of whish (i,j) is part of -
**contribution of (i,j) = TOP LEFT * BOTTOM RIGHT**
Every top left cell can be combined with every bottom right cell.
-**Example**
+### Example
-) +
+ +
+) @@ -101,31 +168,34 @@ Overlapping Condition -
---
-### Question
-Given a sorted list of overlapping intervals, sorted based on start time, merge all overlapping intervals and return sorted list.
-**Input:**
-Interval[] = { (1,10), (2, 3), (4, 5), (9, 12)}
+### Question
+Given a sorted list of overlapping intervals, sorted based on start time, merge all overlapping intervals and return sorted list. Select output for following input.
+Input:
+Interval[] = { (1,10), (2, 3), (4, 5), (9, 12) }
-**Choices**
+### Choices
- [x] (1, 12)
- [ ] (1, 10), (9, 12)
- [ ] (1, 9), (9, 12)
- [ ] No Change
-#### Problem 1 Approach
+
+---
+
+## Problem 1 Approach
* Create an array to store the merged intervals.
* If the current and ith intervals overlaps, merge them. In this case update the current interval with the merged interval.
* Else, insert the current interval to answer array since it doesn't overlap with any other interval and update the current Interval to ith Interval.
-#### Dry Run
+### Dry Run
-**Input:**
+### Input:
Interval[] = {(0,2), (1,4), (5,6), (6,8), (7,10), (8,9), (12,14)}
-#### Explanation:
+### Explanation:
| current | ith | | After merging | answer list |
@@ -140,208 +210,92 @@ Interval[] = {(0,2), (1,4), (5,6), (6,8), (7,10), (8,9), (12,14)}
At the end, we are left with the last interval, so add it to the list.
-#### Pseudocode
+### Pseudocode
```cpp
-//Already a class/structure will be present for Interval
-//We will only need to create an answer array of type Interval
-
-list < Interval > ans;
-
-// Current Segment
-int cur_start = A[0].start, cur_end = A[0].end;
-
-for (int i = 1; i < A.size(); i++) {
-
- // if i'th interval overlaps with current interval
- if (A[i].start <= cur_end) {
- // merging them
- cur_end = max(cur_end, A[i].end);
- } else {
- //adding current interval to answer.
- //create a new Interval
- Interval temp(cur_start, cur_end); //if struct is declared, otherwise if class is declared then we can simply use new keyword
- ans.push_back(temp);
-
- // update cur Interval to ith
- cur_start = A[i].start;
- cur_end = A[i].end;
- }
+currS = A[0][0], currE = A[0][1];
+
+for (i -> 1 to N - 1) {
+ if (A[i][0] <= currE) {
+ currE = max(currE, A[i][1]);
+ } else {
+ ans.insert({currS, currE});
+ currS = A[i][0];
+ currE = A[i][1];
+ }
}
-Interval temp(cur_start, cur_end);
-ans.push_back(temp);
+ans.insert({currS, currE});
+
return ans;
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(1)
---
-### Problem 2 Sorted Set of Non Overlapping Intervals
-
-Given a sorted list of overlapping intervals based on start time, insert a new interval such that the final list of intervals is also sorted and non-overlapping.
-Print the Intervals.
-
-**Example 1:**
-**N = 9**
-(1,3)
-(4,7)
-(10,14)
-(16,19)
-(21,24)
-(27,30)
-(32,35)
-(38,41)
-(43,50)
-
-New Interval
-**(12, 22)**
-
-**Explanation:**
-
-| ith | new Interval | Overlaps? | Print |
-|-------|----------|----------|-----------------|
-| (1,3) | (12,22) | No | (1,3) |
-| (4,7) | (12,22) | No | (4,7) |
-| (10,14) | (12,22) | Yes; merged: (10,22) ||
-| (16,19) | (10,22) | Yes; merged: (10,22) ||
-| (21,24) | (10,22) | Yes; merged: (10,24) ||
-| (27,30) | (10,22) | No; small new Interval gets printed first |(10,22)|
-| (32,35)| | |(32,35)|
-| (38,41)| | |(38,41) |
-| (43,50)| | | (43,50)|
-
-**Please Note:** Once the new Interval gets printed, all the Intervals following it also gets printed.
-
-**More Examples**
-
-**Example 2:**
-**N = 5**
-(1,5)
-(8,10)
-(11,14)
-(15,20)
-(21,24)
-
-New Interval
-**(12, 24)**
-
-| ith | new Interval | Overlaps? | Print |
-|:-------:|:------------:|:--------------------:|:------:|
-| (1,5) | (12, 24) | No | (1,5) |
-| (8,10) | (12, 24) | No | (8,10) |
-| (11,14) | (12, 24) | Yes; merged:(11, 24) | |
-| (15,20) | (11, 24) | Yes; merged:(11, 24) | |
-| (21,24) | (11, 24) | Yes; merged:(11, 24) | |
-
-We are done with all the intervals but left the new Interval at the end; in this case we have to print the new Interval.
-
-**Example 3:**
-
-
@@ -101,31 +168,34 @@ Overlapping Condition -
---
-### Question
-Given a sorted list of overlapping intervals, sorted based on start time, merge all overlapping intervals and return sorted list.
-**Input:**
-Interval[] = { (1,10), (2, 3), (4, 5), (9, 12)}
+### Question
+Given a sorted list of overlapping intervals, sorted based on start time, merge all overlapping intervals and return sorted list. Select output for following input.
+Input:
+Interval[] = { (1,10), (2, 3), (4, 5), (9, 12) }
-**Choices**
+### Choices
- [x] (1, 12)
- [ ] (1, 10), (9, 12)
- [ ] (1, 9), (9, 12)
- [ ] No Change
-#### Problem 1 Approach
+
+---
+
+## Problem 1 Approach
* Create an array to store the merged intervals.
* If the current and ith intervals overlaps, merge them. In this case update the current interval with the merged interval.
* Else, insert the current interval to answer array since it doesn't overlap with any other interval and update the current Interval to ith Interval.
-#### Dry Run
+### Dry Run
-**Input:**
+### Input:
Interval[] = {(0,2), (1,4), (5,6), (6,8), (7,10), (8,9), (12,14)}
-#### Explanation:
+### Explanation:
| current | ith | | After merging | answer list |
@@ -140,208 +210,92 @@ Interval[] = {(0,2), (1,4), (5,6), (6,8), (7,10), (8,9), (12,14)}
At the end, we are left with the last interval, so add it to the list.
-#### Pseudocode
+### Pseudocode
```cpp
-//Already a class/structure will be present for Interval
-//We will only need to create an answer array of type Interval
-
-list < Interval > ans;
-
-// Current Segment
-int cur_start = A[0].start, cur_end = A[0].end;
-
-for (int i = 1; i < A.size(); i++) {
-
- // if i'th interval overlaps with current interval
- if (A[i].start <= cur_end) {
- // merging them
- cur_end = max(cur_end, A[i].end);
- } else {
- //adding current interval to answer.
- //create a new Interval
- Interval temp(cur_start, cur_end); //if struct is declared, otherwise if class is declared then we can simply use new keyword
- ans.push_back(temp);
-
- // update cur Interval to ith
- cur_start = A[i].start;
- cur_end = A[i].end;
- }
+currS = A[0][0], currE = A[0][1];
+
+for (i -> 1 to N - 1) {
+ if (A[i][0] <= currE) {
+ currE = max(currE, A[i][1]);
+ } else {
+ ans.insert({currS, currE});
+ currS = A[i][0];
+ currE = A[i][1];
+ }
}
-Interval temp(cur_start, cur_end);
-ans.push_back(temp);
+ans.insert({currS, currE});
+
return ans;
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(1)
---
-### Problem 2 Sorted Set of Non Overlapping Intervals
-
-Given a sorted list of overlapping intervals based on start time, insert a new interval such that the final list of intervals is also sorted and non-overlapping.
-Print the Intervals.
-
-**Example 1:**
-**N = 9**
-(1,3)
-(4,7)
-(10,14)
-(16,19)
-(21,24)
-(27,30)
-(32,35)
-(38,41)
-(43,50)
-
-New Interval
-**(12, 22)**
-
-**Explanation:**
-
-| ith | new Interval | Overlaps? | Print |
-|-------|----------|----------|-----------------|
-| (1,3) | (12,22) | No | (1,3) |
-| (4,7) | (12,22) | No | (4,7) |
-| (10,14) | (12,22) | Yes; merged: (10,22) ||
-| (16,19) | (10,22) | Yes; merged: (10,22) ||
-| (21,24) | (10,22) | Yes; merged: (10,24) ||
-| (27,30) | (10,22) | No; small new Interval gets printed first |(10,22)|
-| (32,35)| | |(32,35)|
-| (38,41)| | |(38,41) |
-| (43,50)| | | (43,50)|
-
-**Please Note:** Once the new Interval gets printed, all the Intervals following it also gets printed.
-
-**More Examples**
-
-**Example 2:**
-**N = 5**
-(1,5)
-(8,10)
-(11,14)
-(15,20)
-(21,24)
-
-New Interval
-**(12, 24)**
-
-| ith | new Interval | Overlaps? | Print |
-|:-------:|:------------:|:--------------------:|:------:|
-| (1,5) | (12, 24) | No | (1,5) |
-| (8,10) | (12, 24) | No | (8,10) |
-| (11,14) | (12, 24) | Yes; merged:(11, 24) | |
-| (15,20) | (11, 24) | Yes; merged:(11, 24) | |
-| (21,24) | (11, 24) | Yes; merged:(11, 24) | |
-
-We are done with all the intervals but left the new Interval at the end; in this case we have to print the new Interval.
-
-**Example 3:**
-
-) +## Real life application - Website Maintenance - follow up to first problem
----
-### Question
-If the sorted set of non-overlapping intervals is [1, 5], [6, 10], and [12, 15], what happens if you add the interval `[4, 7]` such that the final list of intervals is also sorted and non-overlapping.?
+### Background
+**Scaler Academy**, a leading ed-tech platform known for its comprehensive learning programs, is planning to conduct maintenance on its website to enhance user experience and introduce new features.
-**Choices**
-- [x] [1, 10] and [12, 15]
-- [ ] [1, 5], [4, 7], [6, 10], [12, 15]
-- [ ] [1, 5] and [6, 10] only
-- [ ] No change
+To ensure the maintenance work does not disrupt the learning process for its students, Scaler Academy aims to schedule this maintenance during the period of **no user activity**.
+### Problem Statement
-#### Explanation:
-(1,5)
-(6,10)
-(12,15)
+Given sorted data on the active hours of multiple learners on the platform, your task is to analyze this data and identify the longest continuous period when no learners are active. This identified time slot is crucial as it represents the best opportunity to perform website maintenance with the least disruption to learners' activities.
-New Interval
-**(4, 7)**
+### Example Input :
+DATA = [(9, 11), (14, 16), (15, 20)]
+### Output :
+Maximum time = **8**
+### Explanation
-| ith | new Interval | Overlaps? | Print |
-|:-------:|:------------:|:--------------------:|:------:|
-| (1,5) | (4, 7) | Yes; merged:(1, 7) | |
-| (6,10) | (1, 7) | Yes; merged:(1, 10) | |
-| (12,15) | (1, 10) | No; small new Interval gets printed first | (1, 10) |
-| (12,15) | | | (12, 15) |
+After merging the data, we get the following intervals -
+[(9, 11), (14, 20)]
-Thus after merging, the intervals are [1, 10] and [12, 15]
+There are three time intervals during which there is no user online for the day:-
+- First is (0, 9) => 9 hrs
+- Second is (11, 14) => 3 hrs
+- Third is (20, 24 (00)) => 4 hrs
-#### Problem 2 Pseudocode
+**Here the our answer is the longest time interval which is (0, 9) for 9 hours**
-```cpp
-void merge(int Interval[], int nS, int nE) {
- for (int i = 0; i < N; i++) {
- int L = Interval[i].start, R = Interval[i].end;
-
- //Not Overlapping
- if (nS > R) {
- print({
- L,
- R
- });
- }
- // new Interval is not overlapping and is smaller
- // print new Interval and then all the remaining Intervals
- else if (L > nE) {
- print({
- nS,
- nE
- });
-
- for (int j = i; j < N; j++) {
- print({
- Interval[j].start,
- Interval[j].end
- })
- }
- return;
- } else {
- nS = min(L, nS);
- nE = max(R, nE);
- }
- }
- print({
- nS,
- nE
- });
-}
-```
+### How does this question use the same concept?
+- Once intervals are **merged** as per problem 1, identifying **gaps** becomes straightforward.
+- Each gap between consecutive intervals represents a potential maintenance window.
+- The longest of these gaps is then an optimal time for maintenance.
+
+This is just a real life situation for above problem.
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
---
-### Problem 3 Find First Missing Natural Number
+## Problem 2 Find First Missing Natural Number
+### Problem Statement
Given an unsorted array of integers, Find first missing Natural Number.
-**Examples**
+### Examples
+## Real life application - Website Maintenance - follow up to first problem
----
-### Question
-If the sorted set of non-overlapping intervals is [1, 5], [6, 10], and [12, 15], what happens if you add the interval `[4, 7]` such that the final list of intervals is also sorted and non-overlapping.?
+### Background
+**Scaler Academy**, a leading ed-tech platform known for its comprehensive learning programs, is planning to conduct maintenance on its website to enhance user experience and introduce new features.
-**Choices**
-- [x] [1, 10] and [12, 15]
-- [ ] [1, 5], [4, 7], [6, 10], [12, 15]
-- [ ] [1, 5] and [6, 10] only
-- [ ] No change
+To ensure the maintenance work does not disrupt the learning process for its students, Scaler Academy aims to schedule this maintenance during the period of **no user activity**.
+### Problem Statement
-#### Explanation:
-(1,5)
-(6,10)
-(12,15)
+Given sorted data on the active hours of multiple learners on the platform, your task is to analyze this data and identify the longest continuous period when no learners are active. This identified time slot is crucial as it represents the best opportunity to perform website maintenance with the least disruption to learners' activities.
-New Interval
-**(4, 7)**
+### Example Input :
+DATA = [(9, 11), (14, 16), (15, 20)]
+### Output :
+Maximum time = **8**
+### Explanation
-| ith | new Interval | Overlaps? | Print |
-|:-------:|:------------:|:--------------------:|:------:|
-| (1,5) | (4, 7) | Yes; merged:(1, 7) | |
-| (6,10) | (1, 7) | Yes; merged:(1, 10) | |
-| (12,15) | (1, 10) | No; small new Interval gets printed first | (1, 10) |
-| (12,15) | | | (12, 15) |
+After merging the data, we get the following intervals -
+[(9, 11), (14, 20)]
-Thus after merging, the intervals are [1, 10] and [12, 15]
+There are three time intervals during which there is no user online for the day:-
+- First is (0, 9) => 9 hrs
+- Second is (11, 14) => 3 hrs
+- Third is (20, 24 (00)) => 4 hrs
-#### Problem 2 Pseudocode
+**Here the our answer is the longest time interval which is (0, 9) for 9 hours**
-```cpp
-void merge(int Interval[], int nS, int nE) {
- for (int i = 0; i < N; i++) {
- int L = Interval[i].start, R = Interval[i].end;
-
- //Not Overlapping
- if (nS > R) {
- print({
- L,
- R
- });
- }
- // new Interval is not overlapping and is smaller
- // print new Interval and then all the remaining Intervals
- else if (L > nE) {
- print({
- nS,
- nE
- });
-
- for (int j = i; j < N; j++) {
- print({
- Interval[j].start,
- Interval[j].end
- })
- }
- return;
- } else {
- nS = min(L, nS);
- nE = max(R, nE);
- }
- }
- print({
- nS,
- nE
- });
-}
-```
+### How does this question use the same concept?
+- Once intervals are **merged** as per problem 1, identifying **gaps** becomes straightforward.
+- Each gap between consecutive intervals represents a potential maintenance window.
+- The longest of these gaps is then an optimal time for maintenance.
+
+This is just a real life situation for above problem.
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
---
-### Problem 3 Find First Missing Natural Number
+## Problem 2 Find First Missing Natural Number
+### Problem Statement
Given an unsorted array of integers, Find first missing Natural Number.
-**Examples**
+### Examples
 ---
+
### Question
In the array [5, 3, 1, -1, -2, -4, 7, 2], what is the first missing natural number?
-**Choices**
+### Choices
- [x] 4
- [ ] 6
- [ ] -3
- [ ] 8
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+w## Find First Missing Natural Number Solution Approach
----
-### Find First Missing Natural Number Solution Approach
-#### Approach 1: Brute Force
+
+### Approach 1: Brute Force
Check for all the numbers from 1 till we get the answer
**T.C -** O(N * ans)
@@ -350,7 +304,10 @@ Here, in the worst case answer can go uptil N+1, in case if all numbers from 1 t
**Example -** {4, 1, 3, 2}
Here we will have to iterate till 5, ie. N+1.
-#### Idea
+
+## First Missing Natural Number Optimised Approach
+
+### Idea
**Can we utilise the fact that answer can be out of 1 to N+1?**
If any number other than 1 to N is present, then missing is out of 1 to N only.
If all elements from 1 to N are present, then it will be N+1.
@@ -372,7 +329,7 @@ We can set element at that index as negative.
*But what if negative number is part of the input?*
-**Let's assume only positive numbers are present**
+### Let's assume only positive numbers are present
We can use indices to mark the presence of a number.
We can set element at that index as negative.
@@ -399,21 +356,23 @@ Here, index: 4 is +ve, hence 5 is the answer.
**NOTE:** Since we are marking elements as negative, so when checking presence of a certain number, we'll have to consider the absolute value of it.
-#### Pseudocode
+### Pseudocode
```cpp
-for (int i = 0; i < N; i++) {
- int ele = abs(A[i]);
-
- if (ele >= 1 && ele <= N) {
+for(i -> 0 to N - 1) {
+ ele = absolute(A[i]);
+
+ if(ele >= 1 and ele <= N) {
int idx = ele - 1;
- A[idx] = -1 * abs(A[i]);
+ A[idx] = -1 * absolute(A[i]);
}
}
```
---
-### Find First Missing Natural Number For Negative Numbers
-#### How to resolve for negative numbers ?
+## First missing natural number if negative numbers are present
+
+
+### How to resolve for negative numbers ?
Will negatives ever be our answer?
**NO!**
@@ -428,29 +387,29 @@ Should we mark them 0?
***We can just change negative number to a number that is out of our answer range. **It can be N+2**.***
```cpp
-for (int i = 0; i < N; i++) {
- if (A[i] <= 0) {
+for(i -> 0 to N - 1) {
+ if(A[i] <= 0) {
A[i] = N + 2;
}
}
-for (int i = 0; i < N; i++) {
- int ele = abs(A[i]);
-
- if (ele >= 1 && ele <= N) {
- int idx = ele - 1;
+for(i -> 0 to N - 1) {
+ ele = abs(A[i]);
+
+ if(ele >= 1 && ele <= N) {
+ idx = ele - 1;
A[idx] = -1 * abs(A[i]);
}
}
-for (int i = 0; i < N; i++) {
- if (A[i] > 0) return i + 1;
+for(i -> 0 to N - 1) {
+ if(A[i] > 0) return i + 1;
}
return N + 1;
```
>Please show a dry run on - {4, 0, 1, -5, -10, 8, 2, 6}
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(1)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Backtracking.md b/Academy DSA Typed Notes/Advanced/DSA Backtracking 1.md
similarity index 73%
rename from Academy DSA Typed Notes/Advanced/DSA Backtracking.md
rename to Academy DSA Typed Notes/Advanced/DSA Backtracking 1.md
index 1c234ba..f051e43 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Backtracking.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Backtracking 1.md
@@ -1,144 +1,6 @@
-# Backtracking
-
----
-### Question
-What is the output of below code for N = 7 ?
-```
-int magicfun( int N) {
- if ( N == 0)
- return 0;
- else
- return magicfun(N/2) * 10 + (N % 2);
-}
-```
-
-**Choices**
-
-- [ ] 100
-- [x] 111
-- [ ] 99
-- [ ] 112
-
-**Explanation**
-```cpp
- magicfun(7)
-
- magicfun(3) * 10 + 1
-
- magicfun(1) * 10 + 1
-
- magicfun(0) * 10 + 1
-
- 0
-```
-
-
----
-### Question
-
-Time complexity of below code is?
-```
-int magicfun( int N) {
- if ( N == 0)
- return 0;
- else
- return magicfun(N/2) * 10 + (N % 2);
-}
-```
-
-**Choices**
-
-- [x] O(log N)
-- [ ] O(1)
-- [ ] O(N)
-- [ ] O(N/2)
-
-
-Everytime we are dividing N by 2. Hence complexity will be log N.
-
----
-### Question
-
-Output of below code is?
-```
-void fun(char s[], int x) {
- print(s)
- char temp
- if(x < s.length/2) {
- temp=s[x]
- s[x] = s[s.length-x-1]
- s[s.length-x-1]=temp
- fun(s, x+1)
- }
-}
-```
-
-Run for fun("SCROLL", 0)
-
-**Choices**
-
-- [ ] SCROLL
- SCROLL
- SCROLL
- SCROLL
-- [x] SCROLL
- LCROLS
- LLROCS
- LLORCS
-- [ ] LLORCS
- SCROLL
- LCROLS
- LLROCS
-
-
-We start with
-(SCROLL, 0); line 2 runs; print => SCROLL
-since 0 < 6/2, we run the if block and index 0 gets swapped with 5
-
-(LCROLS, 1); line 2 runs; print => LCROLS
-since 1 < 6/2, we run the if block and index 1 gets swapped with 4
-
-(LLROCS, 2); line 2 runs; print => LLROCS
-since 2 < 6/2, we run the if block and index 2 gets swapped with 3
-
-(LLORCS, 3); line 2 runs; print => LLORCS
-since 3 not less than 6/2, we skip if block and come back from recursion
-
----
-### Question
-
-Time Complexity of below code is?
-```
-void fun(char s[], int x) {
- print(s)
- char temp
- if(x < s.length/2) {
- temp=s[x]
- s[x] = s[s.length-x-1]
- s[s.length-x-1]=temp
- fun(s, x+1)
- }
-}
-```
-
-**Choices**
-
-- [ ] O(N^2)
-- [ ] O(1)
-- [x] O(N)
-- [ ] O(N/2)
-
-
-
-We are only iterating till half of the string. In the worst case, we can start at 0th index.
-
-Therefore, #iterations = N/2
-Hence, T.C = O(N)
-S.C is also O(N) since call will be made for half of the string.
-
----
-## What is Backtracking
+# Backtracking 1
+## What is Bracktracking ?
The above process is known as **Backtracking**.
@@ -158,9 +20,17 @@ The backtracking way of solving this problem would stop going down a path when t
In the above diagram backtracking didn't make us go down the path from node N. This is because there is a mismatch we found early on and we decided to go back to the next step instead. Backtracking reduced the number of steps taken to reach the final result. This is known as pruning the recursion tree because we don't take unnecessary paths.
----
-### Problem 1 : Print Valid Parenthesis Continued
-#### Explanation
+---
+## Problem 1 Print Valid Parenthesis
+
+
+### Problem Statement
+Given an integer A pairs of parentheses, write a function to generate all combinations of well-formed parentheses of length 2*A.
+
+A = 3
+[ "((()))", "(()())", "(())()", "()(())", "()()()" ]
+
+### Explanation
As shown in the picture below: ) is an invalid string, so every string prefixed with it is also invalid, and we can just drop it.
@@ -178,39 +48,42 @@ The function adds more parentheses to cur_string only when certain conditions ar
This function ensures that the generated string of length 2n is valid, and adds it directly to the answer. By only generating valid strings, we can avoid wasting time checking invalid strings.
+---
+## Print Valid Parenthesis Dry Run and Pseudocode
+
-#### Dry Run for N = 2, means overall length will be 4.
+### Dry Run for N = 2, means overall length will be 4.
---
+
### Question
In the array [5, 3, 1, -1, -2, -4, 7, 2], what is the first missing natural number?
-**Choices**
+### Choices
- [x] 4
- [ ] 6
- [ ] -3
- [ ] 8
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+w## Find First Missing Natural Number Solution Approach
----
-### Find First Missing Natural Number Solution Approach
-#### Approach 1: Brute Force
+
+### Approach 1: Brute Force
Check for all the numbers from 1 till we get the answer
**T.C -** O(N * ans)
@@ -350,7 +304,10 @@ Here, in the worst case answer can go uptil N+1, in case if all numbers from 1 t
**Example -** {4, 1, 3, 2}
Here we will have to iterate till 5, ie. N+1.
-#### Idea
+
+## First Missing Natural Number Optimised Approach
+
+### Idea
**Can we utilise the fact that answer can be out of 1 to N+1?**
If any number other than 1 to N is present, then missing is out of 1 to N only.
If all elements from 1 to N are present, then it will be N+1.
@@ -372,7 +329,7 @@ We can set element at that index as negative.
*But what if negative number is part of the input?*
-**Let's assume only positive numbers are present**
+### Let's assume only positive numbers are present
We can use indices to mark the presence of a number.
We can set element at that index as negative.
@@ -399,21 +356,23 @@ Here, index: 4 is +ve, hence 5 is the answer.
**NOTE:** Since we are marking elements as negative, so when checking presence of a certain number, we'll have to consider the absolute value of it.
-#### Pseudocode
+### Pseudocode
```cpp
-for (int i = 0; i < N; i++) {
- int ele = abs(A[i]);
-
- if (ele >= 1 && ele <= N) {
+for(i -> 0 to N - 1) {
+ ele = absolute(A[i]);
+
+ if(ele >= 1 and ele <= N) {
int idx = ele - 1;
- A[idx] = -1 * abs(A[i]);
+ A[idx] = -1 * absolute(A[i]);
}
}
```
---
-### Find First Missing Natural Number For Negative Numbers
-#### How to resolve for negative numbers ?
+## First missing natural number if negative numbers are present
+
+
+### How to resolve for negative numbers ?
Will negatives ever be our answer?
**NO!**
@@ -428,29 +387,29 @@ Should we mark them 0?
***We can just change negative number to a number that is out of our answer range. **It can be N+2**.***
```cpp
-for (int i = 0; i < N; i++) {
- if (A[i] <= 0) {
+for(i -> 0 to N - 1) {
+ if(A[i] <= 0) {
A[i] = N + 2;
}
}
-for (int i = 0; i < N; i++) {
- int ele = abs(A[i]);
-
- if (ele >= 1 && ele <= N) {
- int idx = ele - 1;
+for(i -> 0 to N - 1) {
+ ele = abs(A[i]);
+
+ if(ele >= 1 && ele <= N) {
+ idx = ele - 1;
A[idx] = -1 * abs(A[i]);
}
}
-for (int i = 0; i < N; i++) {
- if (A[i] > 0) return i + 1;
+for(i -> 0 to N - 1) {
+ if(A[i] > 0) return i + 1;
}
return N + 1;
```
>Please show a dry run on - {4, 0, 1, -5, -10, 8, 2, 6}
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(1)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Backtracking.md b/Academy DSA Typed Notes/Advanced/DSA Backtracking 1.md
similarity index 73%
rename from Academy DSA Typed Notes/Advanced/DSA Backtracking.md
rename to Academy DSA Typed Notes/Advanced/DSA Backtracking 1.md
index 1c234ba..f051e43 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Backtracking.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Backtracking 1.md
@@ -1,144 +1,6 @@
-# Backtracking
-
----
-### Question
-What is the output of below code for N = 7 ?
-```
-int magicfun( int N) {
- if ( N == 0)
- return 0;
- else
- return magicfun(N/2) * 10 + (N % 2);
-}
-```
-
-**Choices**
-
-- [ ] 100
-- [x] 111
-- [ ] 99
-- [ ] 112
-
-**Explanation**
-```cpp
- magicfun(7)
-
- magicfun(3) * 10 + 1
-
- magicfun(1) * 10 + 1
-
- magicfun(0) * 10 + 1
-
- 0
-```
-
-
----
-### Question
-
-Time complexity of below code is?
-```
-int magicfun( int N) {
- if ( N == 0)
- return 0;
- else
- return magicfun(N/2) * 10 + (N % 2);
-}
-```
-
-**Choices**
-
-- [x] O(log N)
-- [ ] O(1)
-- [ ] O(N)
-- [ ] O(N/2)
-
-
-Everytime we are dividing N by 2. Hence complexity will be log N.
-
----
-### Question
-
-Output of below code is?
-```
-void fun(char s[], int x) {
- print(s)
- char temp
- if(x < s.length/2) {
- temp=s[x]
- s[x] = s[s.length-x-1]
- s[s.length-x-1]=temp
- fun(s, x+1)
- }
-}
-```
-
-Run for fun("SCROLL", 0)
-
-**Choices**
-
-- [ ] SCROLL
- SCROLL
- SCROLL
- SCROLL
-- [x] SCROLL
- LCROLS
- LLROCS
- LLORCS
-- [ ] LLORCS
- SCROLL
- LCROLS
- LLROCS
-
-
-We start with
-(SCROLL, 0); line 2 runs; print => SCROLL
-since 0 < 6/2, we run the if block and index 0 gets swapped with 5
-
-(LCROLS, 1); line 2 runs; print => LCROLS
-since 1 < 6/2, we run the if block and index 1 gets swapped with 4
-
-(LLROCS, 2); line 2 runs; print => LLROCS
-since 2 < 6/2, we run the if block and index 2 gets swapped with 3
-
-(LLORCS, 3); line 2 runs; print => LLORCS
-since 3 not less than 6/2, we skip if block and come back from recursion
-
----
-### Question
-
-Time Complexity of below code is?
-```
-void fun(char s[], int x) {
- print(s)
- char temp
- if(x < s.length/2) {
- temp=s[x]
- s[x] = s[s.length-x-1]
- s[s.length-x-1]=temp
- fun(s, x+1)
- }
-}
-```
-
-**Choices**
-
-- [ ] O(N^2)
-- [ ] O(1)
-- [x] O(N)
-- [ ] O(N/2)
-
-
-
-We are only iterating till half of the string. In the worst case, we can start at 0th index.
-
-Therefore, #iterations = N/2
-Hence, T.C = O(N)
-S.C is also O(N) since call will be made for half of the string.
-
----
-## What is Backtracking
+# Backtracking 1
+## What is Bracktracking ?
The above process is known as **Backtracking**.
@@ -158,9 +20,17 @@ The backtracking way of solving this problem would stop going down a path when t
In the above diagram backtracking didn't make us go down the path from node N. This is because there is a mismatch we found early on and we decided to go back to the next step instead. Backtracking reduced the number of steps taken to reach the final result. This is known as pruning the recursion tree because we don't take unnecessary paths.
----
-### Problem 1 : Print Valid Parenthesis Continued
-#### Explanation
+---
+## Problem 1 Print Valid Parenthesis
+
+
+### Problem Statement
+Given an integer A pairs of parentheses, write a function to generate all combinations of well-formed parentheses of length 2*A.
+
+A = 3
+[ "((()))", "(()())", "(())()", "()(())", "()()()" ]
+
+### Explanation
As shown in the picture below: ) is an invalid string, so every string prefixed with it is also invalid, and we can just drop it.
@@ -178,39 +48,42 @@ The function adds more parentheses to cur_string only when certain conditions ar
This function ensures that the generated string of length 2n is valid, and adds it directly to the answer. By only generating valid strings, we can avoid wasting time checking invalid strings.
+---
+## Print Valid Parenthesis Dry Run and Pseudocode
+
-#### Dry Run for N = 2, means overall length will be 4.
+### Dry Run for N = 2, means overall length will be 4.
 - Here **"(())" and "()()"** are valid answers.
-#### PseudoCode
-```cpp
-void solve(str, N, opening, closing) { //also taking given N value in parameter
+### PseudoCode
+```cpp=
+function solve(str, N, opening, closing){ //also taking given N value in parameter
// base case
- if (str.length() == 2 N) {
+ if(str.length == 2N){
print(str);
return;
}
- if (opening < N) {
- solve(N, str + '(', opening + 1, closing)
+ if(opening < N){
+ solve(N, str+'(' , opening+1, closing)
}
- if (closing < opening) {
- solve(N, str + ')', opening, closing + 1)
+ if(closing < opening){
+ solve(N, str+')' , opening, closing+1)
}
}
```
-#### Complexity
+### Complexity
- **Time Complexity:** O(2N)
- **Space Complexity:** O(N)
---
-### Definition of Subset and Subsequences
+## Definition of Subset and Subsequences
-#### Definition of Subset and Example
+### Definition of Subset and Example
A subset is often confused with subarray and subsequence but a subset is nothing but any possible combination of the original array (or a set).
For example, the subsets of array arr = [1, 2, 3, 4, 5] can be:
@@ -220,7 +93,7 @@ For example, the subsets of array arr = [1, 2, 3, 4, 5] can be:
[1, 2], etc.
So, we can conclude that subset is the superset of subarrays i.e. all the subarrays are subsets but vice versa is not true.
-#### Definition of Subsequence and Example
+### Definition of Subsequence and Example
As the name suggests, a subsequence is a sequence of the elements of the array obtained by deleting some elements of the array. One important thing related to the subsequence is that even after deleting some elements, the sequence of the array elements is not changed. Both the string and arrays can have subsequences.
The subsequence should not be confused with the subarray or substring. The subarray or substring is contiguous but a subsequence need not to be contiguous.
@@ -234,11 +107,12 @@ For example, the subsequences of the array arr : [1, 2, 3, 4] can be:
Note: A subarray is a subsequence, a subsequence is a subset but the reverse order is not correct.
---
-### Problem 2 Subsets
+## Problem 2 Subsets
-Given an array with distinct integers. Print all the subsets using recursion.
-**Example**
+Given an array with distinct integers. Return all the subsets using recursion.
+
+### Example
**Input:** [1, 2, 3]
**Output:** {[], [1], [2], [3], [1, 2], [1, 3], [2, 3], [1, 2, 3]}
@@ -250,12 +124,7 @@ For every element, there can be two options:
Say there are **3 elements**, for each of them we have above two options, hence **2 * 2 * 2 = 2^N^** are the total options.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Approach
+### Approach
The approach to solve the problem is to use backtracking.
@@ -263,17 +132,18 @@ For each element, I have two choices whether to keep it or not, I execute my cho
Let us take an example of `[1, 2, 3]`.
-
- Here **"(())" and "()()"** are valid answers.
-#### PseudoCode
-```cpp
-void solve(str, N, opening, closing) { //also taking given N value in parameter
+### PseudoCode
+```cpp=
+function solve(str, N, opening, closing){ //also taking given N value in parameter
// base case
- if (str.length() == 2 N) {
+ if(str.length == 2N){
print(str);
return;
}
- if (opening < N) {
- solve(N, str + '(', opening + 1, closing)
+ if(opening < N){
+ solve(N, str+'(' , opening+1, closing)
}
- if (closing < opening) {
- solve(N, str + ')', opening, closing + 1)
+ if(closing < opening){
+ solve(N, str+')' , opening, closing+1)
}
}
```
-#### Complexity
+### Complexity
- **Time Complexity:** O(2N)
- **Space Complexity:** O(N)
---
-### Definition of Subset and Subsequences
+## Definition of Subset and Subsequences
-#### Definition of Subset and Example
+### Definition of Subset and Example
A subset is often confused with subarray and subsequence but a subset is nothing but any possible combination of the original array (or a set).
For example, the subsets of array arr = [1, 2, 3, 4, 5] can be:
@@ -220,7 +93,7 @@ For example, the subsets of array arr = [1, 2, 3, 4, 5] can be:
[1, 2], etc.
So, we can conclude that subset is the superset of subarrays i.e. all the subarrays are subsets but vice versa is not true.
-#### Definition of Subsequence and Example
+### Definition of Subsequence and Example
As the name suggests, a subsequence is a sequence of the elements of the array obtained by deleting some elements of the array. One important thing related to the subsequence is that even after deleting some elements, the sequence of the array elements is not changed. Both the string and arrays can have subsequences.
The subsequence should not be confused with the subarray or substring. The subarray or substring is contiguous but a subsequence need not to be contiguous.
@@ -234,11 +107,12 @@ For example, the subsequences of the array arr : [1, 2, 3, 4] can be:
Note: A subarray is a subsequence, a subsequence is a subset but the reverse order is not correct.
---
-### Problem 2 Subsets
+## Problem 2 Subsets
-Given an array with distinct integers. Print all the subsets using recursion.
-**Example**
+Given an array with distinct integers. Return all the subsets using recursion.
+
+### Example
**Input:** [1, 2, 3]
**Output:** {[], [1], [2], [3], [1, 2], [1, 3], [2, 3], [1, 2, 3]}
@@ -250,12 +124,7 @@ For every element, there can be two options:
Say there are **3 elements**, for each of them we have above two options, hence **2 * 2 * 2 = 2^N^** are the total options.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Approach
+### Approach
The approach to solve the problem is to use backtracking.
@@ -263,17 +132,18 @@ For each element, I have two choices whether to keep it or not, I execute my cho
Let us take an example of `[1, 2, 3]`.
- +
+ @@ -301,27 +169,83 @@ Continued
@@ -301,27 +169,83 @@ Continued
 -#### Complexity
+### Complexity
- **Time Complexity:** O(2^N^)
- **Space Complexity:** O(N)
----
+### NOTE:
+* *For producing individual sorted subsets, we need to sort the given array first. We will get the desired result with this since elements are being processed in sequence.*
+* *Moreover, if it is asked to sort the final array, then once we have generated all subsets, we can sort answer array before returning.*
+
+### Psuedocode for getting sorted
+
+```cpp=
+initialize ans list;
+function subsets(list A, list currset, idx){
+
+ //base case
+ if(idx == A.size){
+ ans.add(currset);
+ return;
+ }
+
+ //for every ele in A, we have 2 choices
+
+ //choice 1 : keep it in currset
+ currset.add(A[idx]);
+ subsets(A, currset, idx+1);
+
+ //choice 2 : Don't keep it in currset
+ currset.remove_back();
+ subsets(A, currset, idx+1);
+}
+```
+
+---
+
+
### Question
What is the count of total permutations of a string with unique characters? (N=String length)
-**Choices**
+### Choices
- [ ] N$^2$
- [ ] N + (N + 1) / 2
- [ ] N * (N - 1) / 2
- [x] N!
----
-### Problem 3 : Permutation
+---
+## Fitness Meets Variety
+
+### Problem
-Given a character array with distinct elements. Print all permutations of it without modifying it.
+A popular Fitness app **FitBit**, is looking to make workouts more exciting for its users. The app has noticed that people get bored when the same exercises are shown in the same order every time they work out. To mix things up, **FitBit** wants to show all the different ways the exercises can be arranged so that each workout feels new.
-**Example**
+Your challenge is to write a program for **FitBit** that takes a string **A** as input, where each character in the string represents a different exercise. Your program should then find and display all possible arrangements of these exercises.
+
+**Example:**
+A = Push-ups
+B = Squats
+C = Burpees
+D = Planks
+
+Then different ways of doing the exercise includes -
+ABCD
+ACBD
+ADBC
+ADCB
+.
+.
+etc...
+
+This problem is same as getting permutations.
+
+---
+## Problem 3 Permutation
+
+Given a string with distinct elements. Print all permutations of it without modifying it.
+
+### Example
For string **abc**, of length 3, we have total 3! = 6 permutations:
- abc
- acb
@@ -334,10 +258,10 @@ For string **abc**, of length 3, we have total 3! = 6 permutations:
**Output:** abc acb bac bca cab cba
-**Constraint**
+### Constraint
We don't have duplicate characters in a string.
----
+---
## Permutations Idea
- Every permutation has n number of characters, where n is the length of the original string.
@@ -347,11 +271,11 @@ We don't have duplicate characters in a string.
- Let us start with the first empty spot, which means from the 0th index.
- For the 0th index we have three options, `a, b, and c`, any of the three characters can occupy this position.
-
-#### Complexity
+### Complexity
- **Time Complexity:** O(2^N^)
- **Space Complexity:** O(N)
----
+### NOTE:
+* *For producing individual sorted subsets, we need to sort the given array first. We will get the desired result with this since elements are being processed in sequence.*
+* *Moreover, if it is asked to sort the final array, then once we have generated all subsets, we can sort answer array before returning.*
+
+### Psuedocode for getting sorted
+
+```cpp=
+initialize ans list;
+function subsets(list A, list currset, idx){
+
+ //base case
+ if(idx == A.size){
+ ans.add(currset);
+ return;
+ }
+
+ //for every ele in A, we have 2 choices
+
+ //choice 1 : keep it in currset
+ currset.add(A[idx]);
+ subsets(A, currset, idx+1);
+
+ //choice 2 : Don't keep it in currset
+ currset.remove_back();
+ subsets(A, currset, idx+1);
+}
+```
+
+---
+
+
### Question
What is the count of total permutations of a string with unique characters? (N=String length)
-**Choices**
+### Choices
- [ ] N$^2$
- [ ] N + (N + 1) / 2
- [ ] N * (N - 1) / 2
- [x] N!
----
-### Problem 3 : Permutation
+---
+## Fitness Meets Variety
+
+### Problem
-Given a character array with distinct elements. Print all permutations of it without modifying it.
+A popular Fitness app **FitBit**, is looking to make workouts more exciting for its users. The app has noticed that people get bored when the same exercises are shown in the same order every time they work out. To mix things up, **FitBit** wants to show all the different ways the exercises can be arranged so that each workout feels new.
-**Example**
+Your challenge is to write a program for **FitBit** that takes a string **A** as input, where each character in the string represents a different exercise. Your program should then find and display all possible arrangements of these exercises.
+
+**Example:**
+A = Push-ups
+B = Squats
+C = Burpees
+D = Planks
+
+Then different ways of doing the exercise includes -
+ABCD
+ACBD
+ADBC
+ADCB
+.
+.
+etc...
+
+This problem is same as getting permutations.
+
+---
+## Problem 3 Permutation
+
+Given a string with distinct elements. Print all permutations of it without modifying it.
+
+### Example
For string **abc**, of length 3, we have total 3! = 6 permutations:
- abc
- acb
@@ -334,10 +258,10 @@ For string **abc**, of length 3, we have total 3! = 6 permutations:
**Output:** abc acb bac bca cab cba
-**Constraint**
+### Constraint
We don't have duplicate characters in a string.
----
+---
## Permutations Idea
- Every permutation has n number of characters, where n is the length of the original string.
@@ -347,11 +271,11 @@ We don't have duplicate characters in a string.
- Let us start with the first empty spot, which means from the 0th index.
- For the 0th index we have three options, `a, b, and c`, any of the three characters can occupy this position.
- +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +---
## Basic AND XOR OR Properties
### Basic AND Properties
@@ -60,17 +62,20 @@ A ^ B = B ^ A // Bitwise XOR
```
---
+
+
### Question
Evaluate the expression: a ^ b ^ a ^ d ^ b
-**Choices**
+### Choices
- [ ] a ^ b ^ a ^ b
- [ ] b
- [ ] b ^ d
- [x] d
+### Explanation
We can evaluate the expression as follows:
```cpp
@@ -80,27 +85,34 @@ a ^ b ^ a ^ d ^ b = (a ^ a) ^ (b ^ b) ^ d // grouping the a's and the b's
```
Therefore, the expression a ^ b ^ a ^ d ^ b simplifies to d.
+---
+
### Question
Evaluate the expression: 1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5
-**Choices**
+### Choices
- [ ] 5
- [ ] 3
- [x] 2
- [ ] 1
+### Explanation
We can evaluate the expression as follows:
```cpp
-1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5 = ((1 ^ 1) ^ (3 ^ 3) ^ (5 ^ 5)) ^ 2 // grouping the pairs of equal values and XORing them
+// grouping the pairs of equal values and XORing them
+1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5 = ((1 ^ 1) ^ (3 ^ 3) ^ (5 ^ 5)) ^ 2
= (0 ^ 0 ^ 0) ^ 2 // since x ^ x is always 0
= 0 ^ 2 // since 0 ^ y is always y
= 2 // the result is 2
```
Therefore, the expression 1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5 simplifies to 2.
+---
+## Left Shift Operator
+
### Left Shift Operator (<<)
* The left shift operator (<<) shifts the bits of a number to the left by a specified number of positions.
@@ -136,7 +148,8 @@ In above case, if we shift the number 10 more than 4 positions to the left an ov
**Note:** We can increase the number of bits, but after a certain point it will reach limit and overflow will occur.
-
+---
+## Right Shift Operator
### Right Shift Operator (>>)
* The right shift operator (>>) shifts the bits of a number to the right by a specified number of positions.
@@ -160,11 +173,14 @@ a >> n = a/2^n
Here, overflow condition doesn't arise.
+---
+
+
### Question
What will we get if we do 1 << 3 ?
-**Choices**
+### Choices
- [ ] 1
- [x] 8
@@ -173,9 +189,14 @@ What will we get if we do 1 << 3 ?
---
-### Power of Left Shift Operator
+## Power of Left Shift Operator
+
+Let's see how left shift operator can be used in combination with other operators like (OR, AND, XOR) to set, unset, check or toggle an ith bit.
+
+
+---
+## SET ith bit
-### OR( | ) Operator
**Left Shift Operator** can be used with the **OR** operator to **SET** the **ith** bit in the number.
```
@@ -183,11 +204,13 @@ N = (N | (1<
+---
## Basic AND XOR OR Properties
### Basic AND Properties
@@ -60,17 +62,20 @@ A ^ B = B ^ A // Bitwise XOR
```
---
+
+
### Question
Evaluate the expression: a ^ b ^ a ^ d ^ b
-**Choices**
+### Choices
- [ ] a ^ b ^ a ^ b
- [ ] b
- [ ] b ^ d
- [x] d
+### Explanation
We can evaluate the expression as follows:
```cpp
@@ -80,27 +85,34 @@ a ^ b ^ a ^ d ^ b = (a ^ a) ^ (b ^ b) ^ d // grouping the a's and the b's
```
Therefore, the expression a ^ b ^ a ^ d ^ b simplifies to d.
+---
+
### Question
Evaluate the expression: 1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5
-**Choices**
+### Choices
- [ ] 5
- [ ] 3
- [x] 2
- [ ] 1
+### Explanation
We can evaluate the expression as follows:
```cpp
-1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5 = ((1 ^ 1) ^ (3 ^ 3) ^ (5 ^ 5)) ^ 2 // grouping the pairs of equal values and XORing them
+// grouping the pairs of equal values and XORing them
+1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5 = ((1 ^ 1) ^ (3 ^ 3) ^ (5 ^ 5)) ^ 2
= (0 ^ 0 ^ 0) ^ 2 // since x ^ x is always 0
= 0 ^ 2 // since 0 ^ y is always y
= 2 // the result is 2
```
Therefore, the expression 1 ^ 3 ^ 5 ^ 3 ^ 2 ^ 1 ^ 5 simplifies to 2.
+---
+## Left Shift Operator
+
### Left Shift Operator (<<)
* The left shift operator (<<) shifts the bits of a number to the left by a specified number of positions.
@@ -136,7 +148,8 @@ In above case, if we shift the number 10 more than 4 positions to the left an ov
**Note:** We can increase the number of bits, but after a certain point it will reach limit and overflow will occur.
-
+---
+## Right Shift Operator
### Right Shift Operator (>>)
* The right shift operator (>>) shifts the bits of a number to the right by a specified number of positions.
@@ -160,11 +173,14 @@ a >> n = a/2^n
Here, overflow condition doesn't arise.
+---
+
+
### Question
What will we get if we do 1 << 3 ?
-**Choices**
+### Choices
- [ ] 1
- [x] 8
@@ -173,9 +189,14 @@ What will we get if we do 1 << 3 ?
---
-### Power of Left Shift Operator
+## Power of Left Shift Operator
+
+Let's see how left shift operator can be used in combination with other operators like (OR, AND, XOR) to set, unset, check or toggle an ith bit.
+
+
+---
+## SET ith bit
-### OR( | ) Operator
**Left Shift Operator** can be used with the **OR** operator to **SET** the **ith** bit in the number.
```
@@ -183,11 +204,13 @@ N = (N | (1< -### XOR( ^ ) Operator
+---
+## TOGGLE ith bit
+
**Left Shift Operator** can be used with the **XOR** operator to **FLIP(or TOGGLE)** the **ith** bit in the number.
```
@@ -195,30 +218,55 @@ N = (N ^ (1<
-### XOR( ^ ) Operator
+---
+## TOGGLE ith bit
+
**Left Shift Operator** can be used with the **XOR** operator to **FLIP(or TOGGLE)** the **ith** bit in the number.
```
@@ -195,30 +218,55 @@ N = (N ^ (1< +---
+## UNSET ith bit
+
-### AND( & ) Operator
-**Left Shift Operator** can be used with **AND** operator to check whether the **ith** bit is set or not in the number.
+### Example
+Suppose we have a number ```N = 6```
+Binary Representation of 6:
```
-X = (N & (1<
+---
+## UNSET ith bit
+
-### AND( & ) Operator
-**Left Shift Operator** can be used with **AND** operator to check whether the **ith** bit is set or not in the number.
+### Example
+Suppose we have a number ```N = 6```
+Binary Representation of 6:
```
-X = (N & (1< +### Approach
+First of all, we can check if the bit is set or not by taking & with 1.
----
-### Problem 1 Check whether ith bit in **N** is SET or not
+```
+X = (N & (1<
+### Approach
+First of all, we can check if the bit is set or not by taking & with 1.
----
-### Problem 1 Check whether ith bit in **N** is SET or not
+```
+X = (N & (1< -
-
-
-* We will iterate on all the bits one by one.
-* We will count the numbers in the array for which the particular bit is set
-* If the count is odd, in the required number that bit is set.
-
-#### Pseudocode
-```cpp
-int ans = 0;
-
-for (int i = 0; i < 32; i++) { // go to every bit one by one
- int cnt = 0;
-
- for (int j = 0; j < arr.size(); j++) { // iterate on array
-
- // check if ith bit is set
- if ((arr[j] & (1 << i)) cnt++;
- }
-
- if (cnt & 1) // If the count is odd
- ans = ans | 1 << i; // set ith bit in ans
- }
-
- print(ans);
-```
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
+## Problem 1 Every element appear thrice except one
-
----
-### Problem 2 Single number 2
-
+### Problem Statement
Given an integer array, all the elements will occur thrice but one. Find the unique element.
-**Example**
+### Example
**Input:** [4, 5, 5, 4, 1, 6, 6, 4, 5, 6]
**Output:** 1
`Only 1 occurs a single time`
-#### Approach 1: Brute Force
+## Approach 1: Brute Force
Using two for loops and counting the occurence of each number.
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2)
**Space Complexity:** O(1)
-#### Approach 2: Hashmaps
-Iterate on array and store frequency of each number in Hashmap.
-Iterate on array/map and return the number with frequency 1.
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+## Approach 2: Best Approach
+**Interesting Solution!**
+Bitwise operators work on bit level, so let's see how XOR was working on bits.
+For that, let's write binary representation of every number.
-:::warning
-Please take some time to think about the optimsed approach on your own before reading further.....
-:::
+### Observations:
+For every bit position, if we count the number of 1s the count should be even because numbers appear in pairs, but it can be odd if the bit in a single number is set for that position.
-#### Approach 3: Best Approach
-Hint can be taken from the previous question.
-
-
-
-* We will iterate on all the bits one by one.
-* We will count the numbers in the array for which the particular bit is set
-* If the count is odd, in the required number that bit is set.
-
-#### Pseudocode
-```cpp
-int ans = 0;
-
-for (int i = 0; i < 32; i++) { // go to every bit one by one
- int cnt = 0;
-
- for (int j = 0; j < arr.size(); j++) { // iterate on array
-
- // check if ith bit is set
- if ((arr[j] & (1 << i)) cnt++;
- }
-
- if (cnt & 1) // If the count is odd
- ans = ans | 1 << i; // set ith bit in ans
- }
-
- print(ans);
-```
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
+## Problem 1 Every element appear thrice except one
-
----
-### Problem 2 Single number 2
-
+### Problem Statement
Given an integer array, all the elements will occur thrice but one. Find the unique element.
-**Example**
+### Example
**Input:** [4, 5, 5, 4, 1, 6, 6, 4, 5, 6]
**Output:** 1
`Only 1 occurs a single time`
-#### Approach 1: Brute Force
+## Approach 1: Brute Force
Using two for loops and counting the occurence of each number.
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2)
**Space Complexity:** O(1)
-#### Approach 2: Hashmaps
-Iterate on array and store frequency of each number in Hashmap.
-Iterate on array/map and return the number with frequency 1.
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+## Approach 2: Best Approach
+**Interesting Solution!**
+Bitwise operators work on bit level, so let's see how XOR was working on bits.
+For that, let's write binary representation of every number.
-:::warning
-Please take some time to think about the optimsed approach on your own before reading further.....
-:::
+### Observations:
+For every bit position, if we count the number of 1s the count should be even because numbers appear in pairs, but it can be odd if the bit in a single number is set for that position.
-#### Approach 3: Best Approach
-Hint can be taken from the previous question.
) @@ -149,40 +72,42 @@ Hint can be taken from the previous question.
* If the count of numbers in which ith bit is set is a multiple of 3, then in answer ith bit is NOT SET.
* If the count of numbers in which ith bit is of the form (3 * x) + 1, then in answer ith bit is SET.
-#### Pseudocode
+### Pseudocode
```cpp=
-int ans = 0;
-
-for (int i = 0; i < 32; i++) { // go to every bit one by one
- int cnt = 0;
-
- for (int j = 0; j < arr.size(); j++) { // iterate on array
-
- // check if ith bit is set
- if ((arr[j] & (1 << i)) cnt++;
- }
-
- if (cnt % 3 == 1) // If the count is not the multiple of 3
- ans = ans | 1 << i; // set ith bit in ans
+ans = 0;
+
+for(i -> 0 to 31) { // go to every bit one by one
+ cnt = 0;
+
+ for(j -> 0 to arr.size - 1) { // iterate on array
+
+ // check if ith bit is set
+ if((arr[j] & (1<
@@ -149,40 +72,42 @@ Hint can be taken from the previous question.
* If the count of numbers in which ith bit is set is a multiple of 3, then in answer ith bit is NOT SET.
* If the count of numbers in which ith bit is of the form (3 * x) + 1, then in answer ith bit is SET.
-#### Pseudocode
+### Pseudocode
```cpp=
-int ans = 0;
-
-for (int i = 0; i < 32; i++) { // go to every bit one by one
- int cnt = 0;
-
- for (int j = 0; j < arr.size(); j++) { // iterate on array
-
- // check if ith bit is set
- if ((arr[j] & (1 << i)) cnt++;
- }
-
- if (cnt % 3 == 1) // If the count is not the multiple of 3
- ans = ans | 1 << i; // set ith bit in ans
+ans = 0;
+
+for(i -> 0 to 31) { // go to every bit one by one
+ cnt = 0;
+
+ for(j -> 0 to arr.size - 1) { // iterate on array
+
+ // check if ith bit is set
+ if((arr[j] & (1< -
-We will remove all numbers where 0 is present.
-[13 and 7 gets removed or are set to 0]
-
-
-
-We will remove all numbers where 0 is present.
-[13 and 7 gets removed or are set to 0]
-
- -
-
-2. At position 3, there are 4 numbers with set bits(which haven't been cancelled). Since count is >=2, we can form a pair. Therefore, in answer 1 will be present at this position.
-ans:
-
-| 1 | 1 | _ | _ | _ |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will remove all numbers where 0 is present.
-[23 gets removed or is set to 0]
-
-
-
-2. At position 3, there are 4 numbers with set bits(which haven't been cancelled). Since count is >=2, we can form a pair. Therefore, in answer 1 will be present at this position.
-ans:
-
-| 1 | 1 | _ | _ | _ |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will remove all numbers where 0 is present.
-[23 gets removed or is set to 0]
- -
-
-3. At position 2, there is 1 number with set bit. Since count is less than 2, we can't form a pair. Therefore, in answer 0 will be present at this position.
-ans:
-
-| 1 | 1 | 0 | _ | _ |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will NOT remove any number.
-
-
-4. At position 1, there are 2 numbers with set bits. Since count is >=2, we can form a pair. Therefore, in answer 1 will be present at this position.
-
-ans:
-
-| 1 | 1 | 0 | 1 | _ |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will remove all numbers where 0 is present.
-[28 and 25 gets removed or are set to 0]
-
-
-
-
-3. At position 2, there is 1 number with set bit. Since count is less than 2, we can't form a pair. Therefore, in answer 0 will be present at this position.
-ans:
-
-| 1 | 1 | 0 | _ | _ |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will NOT remove any number.
-
-
-4. At position 1, there are 2 numbers with set bits. Since count is >=2, we can form a pair. Therefore, in answer 1 will be present at this position.
-
-ans:
-
-| 1 | 1 | 0 | 1 | _ |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will remove all numbers where 0 is present.
-[28 and 25 gets removed or are set to 0]
-
- -
-
-5. At position 0, there is 1 number with set bit. Since count is <2, we can't form a pair. Therefore, in answer 0 will be present at this position.
-
-ans:
-
-| 1 | 1 | 0 | 1 | 0 |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will NOT remove any number.
-
-**We are done and answer final answer is present in variable ans**.
-
----
-### Maximum AND pair Pseudocode
-#### Pseudocode
-```cpp
- int ans = 0;
-
- for (int i = 31; i >= 0; i--) {
- //count no. of set bits at ith index
- int count = 0;
-
- for (int j = 0; j < n; j++) {
- if (arr[j] & (1 << i))
- cnt++;
- }
-
- //set that bit in ans if count >=2
- if (count >= 2) {
- ans = ans | (1 << i);
-
- //set all numbers which have 0 bit at this position to 0
- for (int j = 0; j < n; j++) {
- if (arr[j] & (1 << i) == 0)
- arr[j] = 0;
- }
-
- }
- }
-
- print(ans);
-
-//The numbers which cannot be choosen to form a pair have been made zero
-
-```
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
-
-
-
-Similarly, if we have to find maximum & of triplets then we will do for count>=3 and for quadruples as count >= 4 and so on ...
-
-
----
-### Problem 5 Count of pairs with maximum AND
-
-Calculate the Count of Pairs for which bitwise & is maximum (GOOGLE Interview Question)
-
-#### Solution:
-
-Do exactly as above and then traverse on the array and find the number of elements which are greater than 0
-
-Required answer will be Nc2 or N(N-1)/2
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
-
diff --git a/Academy DSA Typed Notes/Advanced/DSA Classes, Objects & Linked List Introduction.md b/Academy DSA Typed Notes/Advanced/DSA Classes, Objects & Linked List Introduction.md
new file mode 100644
index 0000000..073b4e2
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Classes, Objects & Linked List Introduction.md
@@ -0,0 +1,545 @@
+# DSA: Classes, Objects & Linked List Introduction
+
+
+## Expectation setting for basic OOPS
+
+In this session we shall be covering basic oops as much as we need for learning further DSA.
+
+OOPS will be covered in much more depth and with hands on exercises in **LLD module**.
+
+---
+## Programming Paradigms
+
+
+### Programming Paradigms
+What is a programming paradigm?
+* **Answer** - Style or standard way of writing a program.
+
+**Eg:** Everyone must had a burger at Mc Donald ? Yes!
+
-
-
-5. At position 0, there is 1 number with set bit. Since count is <2, we can't form a pair. Therefore, in answer 0 will be present at this position.
-
-ans:
-
-| 1 | 1 | 0 | 1 | 0 |
-| -------- | -------- | -------- | -------- | -------- |
-
-We will NOT remove any number.
-
-**We are done and answer final answer is present in variable ans**.
-
----
-### Maximum AND pair Pseudocode
-#### Pseudocode
-```cpp
- int ans = 0;
-
- for (int i = 31; i >= 0; i--) {
- //count no. of set bits at ith index
- int count = 0;
-
- for (int j = 0; j < n; j++) {
- if (arr[j] & (1 << i))
- cnt++;
- }
-
- //set that bit in ans if count >=2
- if (count >= 2) {
- ans = ans | (1 << i);
-
- //set all numbers which have 0 bit at this position to 0
- for (int j = 0; j < n; j++) {
- if (arr[j] & (1 << i) == 0)
- arr[j] = 0;
- }
-
- }
- }
-
- print(ans);
-
-//The numbers which cannot be choosen to form a pair have been made zero
-
-```
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
-
-
-
-Similarly, if we have to find maximum & of triplets then we will do for count>=3 and for quadruples as count >= 4 and so on ...
-
-
----
-### Problem 5 Count of pairs with maximum AND
-
-Calculate the Count of Pairs for which bitwise & is maximum (GOOGLE Interview Question)
-
-#### Solution:
-
-Do exactly as above and then traverse on the array and find the number of elements which are greater than 0
-
-Required answer will be Nc2 or N(N-1)/2
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
-
diff --git a/Academy DSA Typed Notes/Advanced/DSA Classes, Objects & Linked List Introduction.md b/Academy DSA Typed Notes/Advanced/DSA Classes, Objects & Linked List Introduction.md
new file mode 100644
index 0000000..073b4e2
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Classes, Objects & Linked List Introduction.md
@@ -0,0 +1,545 @@
+# DSA: Classes, Objects & Linked List Introduction
+
+
+## Expectation setting for basic OOPS
+
+In this session we shall be covering basic oops as much as we need for learning further DSA.
+
+OOPS will be covered in much more depth and with hands on exercises in **LLD module**.
+
+---
+## Programming Paradigms
+
+
+### Programming Paradigms
+What is a programming paradigm?
+* **Answer** - Style or standard way of writing a program.
+
+**Eg:** Everyone must had a burger at Mc Donald ? Yes!
+ +
+No matter at which Mc D we go, we know the burger will be same, why is it so ? Because they follow a standard recepie.
+
+Because of which customers are usually satisfied as there is predictibility.
+
+While coding as well, it is extremely important to follow a programming paradigm, i.e everyone should follow a standard way of writing a code.
+
+
+### Without programming paradigm the code will be:
+* Less structured
+* Hard to read and understand
+* Hard to test
+* Difficult to maintain, etc.
+
+Different programming languages support different type of programming paradigms and some languages also support multiple types of programming paradigms.
+
+OOPS is one such programming paradigm followed by languages like JAVA, PYTHON, C++, C#, JS, RUBY, etc...
+
+
+---
+## Why OOP is required ?
+
+
+To introduce OOP concepts using a practical example, consider a scenario where you want to store and manage the marks and names of students.
+
+What data structure can be used ? ARRAYS!
+
+Imagine you have two arrays:
+
+**Names Array**: **`["Alice", "Bob", "Charlie"]`**
+**Marks Array**: **`[85, 92, 78]`**
+Each index in these arrays corresponds to a specific student. For example, index 0 holds "Alice" in the Names Array and 85 in the Marks Array, indicating that Alice scored 85.
+
+## Limitations of Using Arrays
+While this approach might seem straightforward, it has significant drawbacks as data complexity increases:
+
+### Scalability Issues:
+
+As you add more students, you need to ensure that every new entry in the names array has a corresponding entry in the marks array at the same index. This gets harder to manage as the array grows, increasing the risk of errors.
+Suppose you have hundreds or thousands of students; managing such large arrays can become very cumbersome and increases the likelihood of making mistakes during data entry or updates.
+
+### Maintainability:
+
+If you decide to add more details about each student, such as their address, phone number, or email, you would need to create and manage additional arrays for each attribute.
+For every attribute you add, you have to ensure all these arrays are updated consistently whenever changes occur (e.g., adding or removing a student). This not only increases the amount of code but also the potential for bugs where data might not line up correctly across arrays.
+
+### Data Association:
+
+If you sort the Names Array alphabetically, you must also reorder every other array (like Marks, Addresses, etc.) to ensure that each student's information still lines up correctly.
+This synchronization issue can lead to significant problems when filtering or searching through data. You might end up displaying or processing incorrect information if arrays are not perfectly aligned after modifications.
+
+### Real-World Implications
+The use of arrays in this way is akin to trying to manage a spreadsheet where each column is independent of the others. Any changes in one column require careful updates in the others, which is both time-consuming and prone to error, especially without the safeguards that more sophisticated data structures or systems provide.
+
+
+---
+## OOPs Introduction
+
+
+OOPs is extemely important concept since most of the languages follows this and this is one of the hot topic of interviews.
+
+It is not that diffcult as much as it sounds. The concept is a mapping to real world, hence this is something which we already experience in our day-to-day life.
+
+It is a philosophy and from that philosophy, it is just a way of writing code.
+
+The most fundamental things in oops is classes and objects.
+
+---
+## Class & Object Definition
+
+**`CLASS`**
+Think of a class as a blueprint for creating things. Imagine you’re a toy manufacturer and you want to produce a bunch of toy cars. Before you start, you need a design or a plan that tells you what the toy car will look like, what parts it will have, and how it will function. This design or plan is like a class.
+
+In programming, a class is a blueprint for creating objects. It defines what attributes (properties) and methods (behaviors) the objects created from it will have. But, by itself, the class doesn’t create any actual toy cars—it just provides the instructions.
+
+**`OBJECT`**
+An object is like one of the toy cars created from the blueprint. It’s a real, tangible instance of the design. Using the blueprint (class), you can create many toy cars (objects), each with the same properties and abilities defined by the blueprint.
+
+When you create an object, you’re bringing the blueprint to life and giving it specific values for its properties.
+
+
+**`EXAMPLE`**
+*Class (Cookie Cutter):*
+*Imagine you have a cookie cutter in the shape of a star. The cookie cutter is the blueprint (class) for making star-shaped cookies.*
+
+*Objects (Cookies):*
+*When you use the cookie cutter to cut dough, you create star-shaped cookies (objects). Each cookie is an instance of the star-shaped blueprint provided by the cookie cutter.*
+
+
+---
+## Create a class and an object in Java
+
+
+```javascript
+// creating a class
+class Book {
+ String title;
+ String author;
+
+ void read() {
+ System.out.print("Reading a book");
+ }
+
+ void cover() {
+ System.out.print("Covering a book");
+ }
+}
+
+public class Main {
+ public static void main(String[] args) {
+
+ // creating an object
+ Book java_b1 = new Book();
+ }
+}
+```
+
+### Note: Class comes into existence only when objects are created, otherwise it doesn't have any memory of its own.
+
+Now above we have created "java_b1" object which will have all the attributes - title, author and can execute functions - read(), cover()
+
+
+
+No matter at which Mc D we go, we know the burger will be same, why is it so ? Because they follow a standard recepie.
+
+Because of which customers are usually satisfied as there is predictibility.
+
+While coding as well, it is extremely important to follow a programming paradigm, i.e everyone should follow a standard way of writing a code.
+
+
+### Without programming paradigm the code will be:
+* Less structured
+* Hard to read and understand
+* Hard to test
+* Difficult to maintain, etc.
+
+Different programming languages support different type of programming paradigms and some languages also support multiple types of programming paradigms.
+
+OOPS is one such programming paradigm followed by languages like JAVA, PYTHON, C++, C#, JS, RUBY, etc...
+
+
+---
+## Why OOP is required ?
+
+
+To introduce OOP concepts using a practical example, consider a scenario where you want to store and manage the marks and names of students.
+
+What data structure can be used ? ARRAYS!
+
+Imagine you have two arrays:
+
+**Names Array**: **`["Alice", "Bob", "Charlie"]`**
+**Marks Array**: **`[85, 92, 78]`**
+Each index in these arrays corresponds to a specific student. For example, index 0 holds "Alice" in the Names Array and 85 in the Marks Array, indicating that Alice scored 85.
+
+## Limitations of Using Arrays
+While this approach might seem straightforward, it has significant drawbacks as data complexity increases:
+
+### Scalability Issues:
+
+As you add more students, you need to ensure that every new entry in the names array has a corresponding entry in the marks array at the same index. This gets harder to manage as the array grows, increasing the risk of errors.
+Suppose you have hundreds or thousands of students; managing such large arrays can become very cumbersome and increases the likelihood of making mistakes during data entry or updates.
+
+### Maintainability:
+
+If you decide to add more details about each student, such as their address, phone number, or email, you would need to create and manage additional arrays for each attribute.
+For every attribute you add, you have to ensure all these arrays are updated consistently whenever changes occur (e.g., adding or removing a student). This not only increases the amount of code but also the potential for bugs where data might not line up correctly across arrays.
+
+### Data Association:
+
+If you sort the Names Array alphabetically, you must also reorder every other array (like Marks, Addresses, etc.) to ensure that each student's information still lines up correctly.
+This synchronization issue can lead to significant problems when filtering or searching through data. You might end up displaying or processing incorrect information if arrays are not perfectly aligned after modifications.
+
+### Real-World Implications
+The use of arrays in this way is akin to trying to manage a spreadsheet where each column is independent of the others. Any changes in one column require careful updates in the others, which is both time-consuming and prone to error, especially without the safeguards that more sophisticated data structures or systems provide.
+
+
+---
+## OOPs Introduction
+
+
+OOPs is extemely important concept since most of the languages follows this and this is one of the hot topic of interviews.
+
+It is not that diffcult as much as it sounds. The concept is a mapping to real world, hence this is something which we already experience in our day-to-day life.
+
+It is a philosophy and from that philosophy, it is just a way of writing code.
+
+The most fundamental things in oops is classes and objects.
+
+---
+## Class & Object Definition
+
+**`CLASS`**
+Think of a class as a blueprint for creating things. Imagine you’re a toy manufacturer and you want to produce a bunch of toy cars. Before you start, you need a design or a plan that tells you what the toy car will look like, what parts it will have, and how it will function. This design or plan is like a class.
+
+In programming, a class is a blueprint for creating objects. It defines what attributes (properties) and methods (behaviors) the objects created from it will have. But, by itself, the class doesn’t create any actual toy cars—it just provides the instructions.
+
+**`OBJECT`**
+An object is like one of the toy cars created from the blueprint. It’s a real, tangible instance of the design. Using the blueprint (class), you can create many toy cars (objects), each with the same properties and abilities defined by the blueprint.
+
+When you create an object, you’re bringing the blueprint to life and giving it specific values for its properties.
+
+
+**`EXAMPLE`**
+*Class (Cookie Cutter):*
+*Imagine you have a cookie cutter in the shape of a star. The cookie cutter is the blueprint (class) for making star-shaped cookies.*
+
+*Objects (Cookies):*
+*When you use the cookie cutter to cut dough, you create star-shaped cookies (objects). Each cookie is an instance of the star-shaped blueprint provided by the cookie cutter.*
+
+
+---
+## Create a class and an object in Java
+
+
+```javascript
+// creating a class
+class Book {
+ String title;
+ String author;
+
+ void read() {
+ System.out.print("Reading a book");
+ }
+
+ void cover() {
+ System.out.print("Covering a book");
+ }
+}
+
+public class Main {
+ public static void main(String[] args) {
+
+ // creating an object
+ Book java_b1 = new Book();
+ }
+}
+```
+
+### Note: Class comes into existence only when objects are created, otherwise it doesn't have any memory of its own.
+
+Now above we have created "java_b1" object which will have all the attributes - title, author and can execute functions - read(), cover()
+
+ +
+### Set the values of attributes
+```javascript
+java_b1.title = "Almanack";
+java_b1.aurthor = "Naval";
+
+System.out.print(java_b1.title); //Almanack
+System.out.print(java_b1.aurthor); //Naval
+```
+
+
+
+### Set the values of attributes
+```javascript
+java_b1.title = "Almanack";
+java_b1.aurthor = "Naval";
+
+System.out.print(java_b1.title); //Almanack
+System.out.print(java_b1.aurthor); //Naval
+```
+
+ +
+---
+## Create a class and an object in Python
+
+
+(Copy on IPAD)
+
+```javascript
+// creating a class
+class Book:
+ title = ""
+ aurthor = ""
+
+ def read(self):
+ return "Reading a book"
+
+ def cover(self):
+ return "Covering a book"
+
+// creating an object
+python_b1 = Book()
+```
+
+### Set the values of attributes
+```javascript
+python_b1.title = "Almanack"
+python_b1.aurthor = "Naval"
+
+print(python_b1.title) //Almanack
+print(python_b1.aurthor) //Naval
+```
+
+---
+## Constructors
+
+
+### Constructors
+
+Let's define a class named Student.
+```java
+class Student {
+ String name;
+ int age;
+ double psp;
+ String univName;
+}
+```
+Now, let's make an object of the Student class.
+```java
+Student st = new Student();
+```
+
+We can see that **Student** is the Data type here and **st** is a variable name, but
+
+What does the `new Student()` part of the statement do here?
+
+This thing => **Student();** is called a **constructor**, which creates the object of the class.
+
+But can you see any method named Student() in the Student class?
+* *No!* Right?
+
+This thing, when you don't create a constructor, is called a **default constructor**. Let's discuss it in detail.
+
+---
+## Default constructor
+
+
+### Default Constructor
+If we don't create our own constructor in a class, a **default constructor** is created.
+
+**Default constructor** creates a new object of the class and sets the value of each attribute as the default value of that type.
+
+Examples of default values of datatype:
+* **0** for integer,
+* **null** for String,
+* **0.0** for float, etc.
+
+> **Note:** A default constructor will assign default values only if we haven't assigned values to class attributes while declaring the variable.
+
+So if we are not creating any constructor, then our class is going to make its own constructor.
+
+### A default constructor can be assumed to be present like this:
+```java
+class Student {
+ String name;
+ int age;
+ double psp;
+ String univName;
+
+ //This is how default constructor can be assumed to look like internally.
+ Student() {
+ name = null;
+ age = 0;
+ psp = 0.0;
+ univName = null;
+ }
+}
+```
+
+As soon as we write below statement, default values to all variables gets assigned.
+```
+Student st = new Student();
+```
+
+
+
+---
+## Create a class and an object in Python
+
+
+(Copy on IPAD)
+
+```javascript
+// creating a class
+class Book:
+ title = ""
+ aurthor = ""
+
+ def read(self):
+ return "Reading a book"
+
+ def cover(self):
+ return "Covering a book"
+
+// creating an object
+python_b1 = Book()
+```
+
+### Set the values of attributes
+```javascript
+python_b1.title = "Almanack"
+python_b1.aurthor = "Naval"
+
+print(python_b1.title) //Almanack
+print(python_b1.aurthor) //Naval
+```
+
+---
+## Constructors
+
+
+### Constructors
+
+Let's define a class named Student.
+```java
+class Student {
+ String name;
+ int age;
+ double psp;
+ String univName;
+}
+```
+Now, let's make an object of the Student class.
+```java
+Student st = new Student();
+```
+
+We can see that **Student** is the Data type here and **st** is a variable name, but
+
+What does the `new Student()` part of the statement do here?
+
+This thing => **Student();** is called a **constructor**, which creates the object of the class.
+
+But can you see any method named Student() in the Student class?
+* *No!* Right?
+
+This thing, when you don't create a constructor, is called a **default constructor**. Let's discuss it in detail.
+
+---
+## Default constructor
+
+
+### Default Constructor
+If we don't create our own constructor in a class, a **default constructor** is created.
+
+**Default constructor** creates a new object of the class and sets the value of each attribute as the default value of that type.
+
+Examples of default values of datatype:
+* **0** for integer,
+* **null** for String,
+* **0.0** for float, etc.
+
+> **Note:** A default constructor will assign default values only if we haven't assigned values to class attributes while declaring the variable.
+
+So if we are not creating any constructor, then our class is going to make its own constructor.
+
+### A default constructor can be assumed to be present like this:
+```java
+class Student {
+ String name;
+ int age;
+ double psp;
+ String univName;
+
+ //This is how default constructor can be assumed to look like internally.
+ Student() {
+ name = null;
+ age = 0;
+ psp = 0.0;
+ univName = null;
+ }
+}
+```
+
+As soon as we write below statement, default values to all variables gets assigned.
+```
+Student st = new Student();
+```
+
+ +
+
+### Few Question:
+#### 1. In what condition a **default constructor is not created**?
+* By the definition of the default constructor, we know that, **if we create our own constructor** then a default constructor is not created.
+
+#### 2. Do we pass any parameter to default constructor ?
+* NO! **the default constructors take no parameters**.
+
+#### 3. Do you notice something special about the **name of the constructor**?
+* *Yes*, the name of the constructor is same as the class name.
+
+#### 4. What really is the **data type** of the constructor i.e. what data type does the constructor return?
+* The data type is assumed to be the class name itself.
+
+### **Summarising** the default constructor:
+1. Takes no parameter.
+2. Sets every attribute of class to it's default value (unless defined).
+3. Created only if we don't write our own constructor.
+4. It's public i.e. can be access from anywhere.
+
+
+## Non-parameterised Constructor
+Say, we want to assign some other values by default to variables, for this we can create our own constructor
+```java
+class Student {
+ String name;
+ int age;
+ double psp;
+ String univName;
+
+ //This is how default constructor can be assumed to look like internally.
+ Student() {
+ name = "Bikram";
+ age = 40;
+ psp = 29.4;
+ univName = "ABC";
+ }
+}
+```
+
+As soon as we write below statement, default values to all variables gets assigned.
+```
+Student st = new Student();
+```
+
+
+
+
+### Few Question:
+#### 1. In what condition a **default constructor is not created**?
+* By the definition of the default constructor, we know that, **if we create our own constructor** then a default constructor is not created.
+
+#### 2. Do we pass any parameter to default constructor ?
+* NO! **the default constructors take no parameters**.
+
+#### 3. Do you notice something special about the **name of the constructor**?
+* *Yes*, the name of the constructor is same as the class name.
+
+#### 4. What really is the **data type** of the constructor i.e. what data type does the constructor return?
+* The data type is assumed to be the class name itself.
+
+### **Summarising** the default constructor:
+1. Takes no parameter.
+2. Sets every attribute of class to it's default value (unless defined).
+3. Created only if we don't write our own constructor.
+4. It's public i.e. can be access from anywhere.
+
+
+## Non-parameterised Constructor
+Say, we want to assign some other values by default to variables, for this we can create our own constructor
+```java
+class Student {
+ String name;
+ int age;
+ double psp;
+ String univName;
+
+ //This is how default constructor can be assumed to look like internally.
+ Student() {
+ name = "Bikram";
+ age = 40;
+ psp = 29.4;
+ univName = "ABC";
+ }
+}
+```
+
+As soon as we write below statement, default values to all variables gets assigned.
+```
+Student st = new Student();
+```
+
+ +
+#### If we write any constructor inside class, default will not be called.
+
+## Parameterised Constructor
+### Now what if we want to initialise with different values everytime an object is created?
+
+For this, we can create parameterised constructor and pass the values while creating an object itself.
+
+```java
+public class Student {
+ String name;
+ int age;
+ String univName;
+ double psp;
+
+ public Student (String studentName, int studentAge, String universityName, double problemSP) {
+ name = studentName;
+ age = studentAge;
+ univName = universityName;
+ psp = problemSP;
+ }
+}
+```
+
+### Create Object
+
+```java
+Student st = new Student("Salmaan Bhai", 20, "Holy", 55.6);
+```
+Now, we don't have to separately assign value to each attribute, but we can easily do so while creating an object.
+
+## Can we also write constructor like -
+```java
+public class Student {
+ String name;
+ int age;
+ String univName;
+ double psp;
+
+ public Student (String name, int age, String univName, double psp) {
+ name = name;
+ age = age;
+ univName = univName;
+ psp = psp;
+ }
+}
+```
+
+### What is different? The names of attributes and parameters are same! Isn't it confusing ?
+Yes! There is a way to distinguish the class attributes.
+We can simply put keyword -"this" in front of them.
+
+```java
+public class Student {
+ String name;
+ int age;
+ String univName;
+ double psp;
+
+ public Student (String name, int age, String univName, double psp) {
+ this.name = name;
+ this.age = age;
+ this.univName = univName;
+ this.psp = psp;
+ }
+}
+```
+
+### This Keyword in Java
+
+* It's typically used to distinguish between **`object variables`** and **`parameter variables`** with the same names.
+* This enhances code clarity and prevents naming conflicts.
+* Example "title" is a parameter name as well as class variable. If we put **`this.title`**, then we know it is class variable.
+
+## Constructor Code (Python)
+
+```javascript
+class Student:
+ # Without parameter
+ def __init__(self):
+ self.name = "Bikram"
+ self.age = 40
+ self.psp = 29.4
+ self.univ_name = "Unknown"
+
+ # With parameter
+ def __init__(self, name, age, psp, univ_name):
+ self.name = name
+ self.age = age
+ self.univ_name = univ_name
+ self.psp = psp
+```
+
+### Object creation with parameterised constructor
+```javascript
+python_b1 = Book("Salmaan Bhai", 20, "Holy", 55.6)
+```
+
+### Self Keyword in Python
+
+- **`Self`** keyword is same as "this" keyword in Java.
+- But whether **self** is used or not inside the method, it is important to pass as a parameter to the methods of class.
+- We can also say that **self** helps in establishing connection between calling object and class methods.
+
+
+---
+## Shallow Copy VS Deep Copy
+
+
+### Problem Statement
+Let's say we already have an object of student class, and then we want to create a new object of student that has the exact same values of attributes as older objects.
+
+**For example:**
+
+
+#### If we write any constructor inside class, default will not be called.
+
+## Parameterised Constructor
+### Now what if we want to initialise with different values everytime an object is created?
+
+For this, we can create parameterised constructor and pass the values while creating an object itself.
+
+```java
+public class Student {
+ String name;
+ int age;
+ String univName;
+ double psp;
+
+ public Student (String studentName, int studentAge, String universityName, double problemSP) {
+ name = studentName;
+ age = studentAge;
+ univName = universityName;
+ psp = problemSP;
+ }
+}
+```
+
+### Create Object
+
+```java
+Student st = new Student("Salmaan Bhai", 20, "Holy", 55.6);
+```
+Now, we don't have to separately assign value to each attribute, but we can easily do so while creating an object.
+
+## Can we also write constructor like -
+```java
+public class Student {
+ String name;
+ int age;
+ String univName;
+ double psp;
+
+ public Student (String name, int age, String univName, double psp) {
+ name = name;
+ age = age;
+ univName = univName;
+ psp = psp;
+ }
+}
+```
+
+### What is different? The names of attributes and parameters are same! Isn't it confusing ?
+Yes! There is a way to distinguish the class attributes.
+We can simply put keyword -"this" in front of them.
+
+```java
+public class Student {
+ String name;
+ int age;
+ String univName;
+ double psp;
+
+ public Student (String name, int age, String univName, double psp) {
+ this.name = name;
+ this.age = age;
+ this.univName = univName;
+ this.psp = psp;
+ }
+}
+```
+
+### This Keyword in Java
+
+* It's typically used to distinguish between **`object variables`** and **`parameter variables`** with the same names.
+* This enhances code clarity and prevents naming conflicts.
+* Example "title" is a parameter name as well as class variable. If we put **`this.title`**, then we know it is class variable.
+
+## Constructor Code (Python)
+
+```javascript
+class Student:
+ # Without parameter
+ def __init__(self):
+ self.name = "Bikram"
+ self.age = 40
+ self.psp = 29.4
+ self.univ_name = "Unknown"
+
+ # With parameter
+ def __init__(self, name, age, psp, univ_name):
+ self.name = name
+ self.age = age
+ self.univ_name = univ_name
+ self.psp = psp
+```
+
+### Object creation with parameterised constructor
+```javascript
+python_b1 = Book("Salmaan Bhai", 20, "Holy", 55.6)
+```
+
+### Self Keyword in Python
+
+- **`Self`** keyword is same as "this" keyword in Java.
+- But whether **self** is used or not inside the method, it is important to pass as a parameter to the methods of class.
+- We can also say that **self** helps in establishing connection between calling object and class methods.
+
+
+---
+## Shallow Copy VS Deep Copy
+
+
+### Problem Statement
+Let's say we already have an object of student class, and then we want to create a new object of student that has the exact same values of attributes as older objects.
+
+**For example:**
+ +
+
+---
+
+### Question
+
+Should we write `Student st2 = st1;`?
+
+### Choices
+
+- [ ] Yes
+- [ ] In some cases only
+- [x] No
+
+### Explanation
+
+
+Let's see how do things work internally?
+
+
+
+---
+
+### Question
+
+Should we write `Student st2 = st1;`?
+
+### Choices
+
+- [ ] Yes
+- [ ] In some cases only
+- [x] No
+
+### Explanation
+
+
+Let's see how do things work internally?
+ +
+* So we have a memory, and st1 is present in the memory with all the data, as shown in the above diagram.
+* When we write student `st2 = st1`, we just make st2 to point as s1, i.e., **a new object is not created**.
+* Now the problem here is if we do changes in st2, i.e. `st2.name = 'xyz'`, it will change the value of st1.
+---
+
+### The above is also known as "Shallow Copy" - when no new object gets. created.
+
+---
+## Deep Copy
+
+
+For creating a new copy of object, we will have to create object using "new" keyword and assign the values to it.
+
+Example -
+An object "st" already exist, now we want to create a copy of it.
+
+
+
+So, we can simply write -
+
+
+### Student st2 = new Student("Bikram", 40, 29.4, "ABC");
+
+The above it the deep copy, where we use "new" keyword to create the object.
+
+
+---
+## Linked List
+
+
+### Issues with Array
+We need continuous space in memory to store Array elements. Now, it may happen that we have required space in chunks but not continuous, then we will not be able to create an Array.
+
+### Linked List
+* A linear data structure that can utilize all the free memory
+* We need not have continuous space to store nodes of a Linked List.
+
+### Representation of Linked List
+
+
+
+* So we have a memory, and st1 is present in the memory with all the data, as shown in the above diagram.
+* When we write student `st2 = st1`, we just make st2 to point as s1, i.e., **a new object is not created**.
+* Now the problem here is if we do changes in st2, i.e. `st2.name = 'xyz'`, it will change the value of st1.
+---
+
+### The above is also known as "Shallow Copy" - when no new object gets. created.
+
+---
+## Deep Copy
+
+
+For creating a new copy of object, we will have to create object using "new" keyword and assign the values to it.
+
+Example -
+An object "st" already exist, now we want to create a copy of it.
+
+
+
+So, we can simply write -
+
+
+### Student st2 = new Student("Bikram", 40, 29.4, "ABC");
+
+The above it the deep copy, where we use "new" keyword to create the object.
+
+
+---
+## Linked List
+
+
+### Issues with Array
+We need continuous space in memory to store Array elements. Now, it may happen that we have required space in chunks but not continuous, then we will not be able to create an Array.
+
+### Linked List
+* A linear data structure that can utilize all the free memory
+* We need not have continuous space to store nodes of a Linked List.
+
+### Representation of Linked List
+
+ +
+* it has a data section where the data is present
+* a next pointer which points to next element of the linked list
+
+### Structure of Linked List
+
+```java
+class Node{
+ int data;
+ Node next;
+ Node(int x){
+ data = x;
+ next = null;
+ }
+}
+```
+### Example of Linked List
+
+
+
+* it has a data section where the data is present
+* a next pointer which points to next element of the linked list
+
+### Structure of Linked List
+
+```java
+class Node{
+ int data;
+ Node next;
+ Node(int x){
+ data = x;
+ next = null;
+ }
+}
+```
+### Example of Linked List
+
+ +
+
+
++ +
 +
+* the first node of the linked list is called head
+* any linked list is represented by its first node
+
+---
+
+
+### Question
+Where will the "next" pointer of the last node point to?
+
+### Choices
+- [ ] First Node
+- [ ] Any Node
+- [ ] Middle Node
+- [x] Null
+
+
+---
+
+
+### Question
+From which node can we travel the entire linked list ?
+
+### Choices
+- [ ] Middle
+- [x] First
+- [ ] Last
+- [ ] Any Node
+
+
+---
+## Access kth element
+
+
+### Access kth element(k = 0; k is the first element)
+
+```java
+Node temp = Head // temp is a compy
+for i -> 1 to k {
+ temp = temp.next
+}
+return temp.data // never update head otherwise the first node is lost
+```
+> Time complexity to access the kth element is O(K). Here we can see that linked list takes more time compared to array as it would take constant time to access the kth element.
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md b/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md
index cc6e314..dd24971 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md
@@ -1,48 +1,46 @@
-# DP 1: One Dimentional
+# DP 1: One Dimensional
----
-## Fibonacci Series
+### Fibonacci Series
`0 1 1 2 3 5 8 13 21 ...`
-### fibonacci Expresion
+### Fibonacci Expresion
* `fib(n) = fib(n-1) + fib(n-2)`
* base case for the fibonacci expression -> `fib(0) = 0; fib(1) = 1`
### Psuedocode
```java
-int fib(n) {
- if (n <= 1) return n;
+function fib(n){
+ if(n <= 1) return n;
return fib(n - 1) + (n - 2);
}
```
> Time complexity for the above code : **O(2^N)**
> Space Complexity for the above code : **O(N)**
----
-### Problem 1 Fibonacci Series
-#### Properties of Dynamic Programming
+## Problem 1 Fibonacci Series
+### Properties of Dynamic Programming
* **Optimal Substructure** - i.e. solving a problem by solving smaller subproblems
* **Overlapping Subproblems** - solving some subproblems multiple times
-#### Solution for Dynamic Programming
+### Solution for Dynamic Programming
* Store the information about already solved sub-problem and use it
-#### Psuedocode of Fibonacci series using dynamic Programming
-```java
-int f[N + 1] // intialize it with -1
-
-int fib(n) {
- if (N <= 1) return n;
+### Psuedocode of Fibonacci series using dynamic Programming
+```java=
+function f[N + 1] // intialize it with -1
+
+function fib(N){
+ if(N <= 1) return N;
// if already solved, don't repeat
- if (f[N] != -1) return f[N];
+ if(f[N] != -1) return f[N];
// store it
- f[N] = fib(n - 1) + (n - 2);
+ f[N] = fib(N - 1) + (N - 2);
return f[N];
}
```
@@ -50,7 +48,7 @@ int fib(n) {
* If we have already solved a problem just return the solution, don't repeat the step
* If not solved, solve and store the solution
-#### Dry Run
+### Dry Run
+
+* the first node of the linked list is called head
+* any linked list is represented by its first node
+
+---
+
+
+### Question
+Where will the "next" pointer of the last node point to?
+
+### Choices
+- [ ] First Node
+- [ ] Any Node
+- [ ] Middle Node
+- [x] Null
+
+
+---
+
+
+### Question
+From which node can we travel the entire linked list ?
+
+### Choices
+- [ ] Middle
+- [x] First
+- [ ] Last
+- [ ] Any Node
+
+
+---
+## Access kth element
+
+
+### Access kth element(k = 0; k is the first element)
+
+```java
+Node temp = Head // temp is a compy
+for i -> 1 to k {
+ temp = temp.next
+}
+return temp.data // never update head otherwise the first node is lost
+```
+> Time complexity to access the kth element is O(K). Here we can see that linked list takes more time compared to array as it would take constant time to access the kth element.
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md b/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md
index cc6e314..dd24971 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 1 One Dimentional.md
@@ -1,48 +1,46 @@
-# DP 1: One Dimentional
+# DP 1: One Dimensional
----
-## Fibonacci Series
+### Fibonacci Series
`0 1 1 2 3 5 8 13 21 ...`
-### fibonacci Expresion
+### Fibonacci Expresion
* `fib(n) = fib(n-1) + fib(n-2)`
* base case for the fibonacci expression -> `fib(0) = 0; fib(1) = 1`
### Psuedocode
```java
-int fib(n) {
- if (n <= 1) return n;
+function fib(n){
+ if(n <= 1) return n;
return fib(n - 1) + (n - 2);
}
```
> Time complexity for the above code : **O(2^N)**
> Space Complexity for the above code : **O(N)**
----
-### Problem 1 Fibonacci Series
-#### Properties of Dynamic Programming
+## Problem 1 Fibonacci Series
+### Properties of Dynamic Programming
* **Optimal Substructure** - i.e. solving a problem by solving smaller subproblems
* **Overlapping Subproblems** - solving some subproblems multiple times
-#### Solution for Dynamic Programming
+### Solution for Dynamic Programming
* Store the information about already solved sub-problem and use it
-#### Psuedocode of Fibonacci series using dynamic Programming
-```java
-int f[N + 1] // intialize it with -1
-
-int fib(n) {
- if (N <= 1) return n;
+### Psuedocode of Fibonacci series using dynamic Programming
+```java=
+function f[N + 1] // intialize it with -1
+
+function fib(N){
+ if(N <= 1) return N;
// if already solved, don't repeat
- if (f[N] != -1) return f[N];
+ if(f[N] != -1) return f[N];
// store it
- f[N] = fib(n - 1) + (n - 2);
+ f[N] = fib(N - 1) + (N - 2);
return f[N];
}
```
@@ -50,7 +48,7 @@ int fib(n) {
* If we have already solved a problem just return the solution, don't repeat the step
* If not solved, solve and store the solution
-#### Dry Run
+### Dry Run
 @@ -76,56 +74,50 @@ We keep using these small answers to find the bigger ones. If we already know an
By the end, we'll have the answer to fib(5), and all the smaller fib numbers stored in our array!
-#### Time and Space Complexity
+### Time and Space Complexity
**Time Complexity for the above code is O(N)** and **space complexity is O(N)**. Thus, we were able to reduce the time complexity from O(2^N) to O(N) using dynamic programing
----
-### Dynamic Programming Types
-
-
-#### Types of DP Solution:
+## Dynamic Programming Types
+### Types of DP Solution:
*Dynamic programming solution can be of two types*:
* **`Top-Down`** [Also know as **Memoization**]
* It is a recursive solution
* We start with the biggest problem and keep on breaking it till we reach the base case.
* Then store answers of already evaluated problems.
-* **`Bottom-Up`**
+* **`Bottom-Up`** [Also know as **Tabulation**]
* It is an iterative solution
* We start with the smallest problem, solve it and store its result.
* Then we keep on moving to the bigger problems and use the already calculated results from sub-problems.
-#### Bottom Up Approach for Fibonacci series
-#### Psuedocode
+### Bottom Up Approach for Fibonacci series
+### Psuedocode
```java
-int fib[N + 1];
+fib[N + 1];
fib[0] = 0;
fib[1] = 1;
-for (i = 2, i <= N; i++) {
+for(i -> 2 to N){
fib[i] = fib[i - 1] + fib[i - 2];
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
-
> Through this approach we were able to eliminate recursive stack.
-#### Further optimising the Space Complexity
+### Further optimising the Space Complexity
If seen closely, the above approach can be optimised by using just simple variables instead of an array. In this way, we can further optimize the space.
-#### Pseudocode
+### Pseudocode
```java
-int a = 0;
-int b = 1;
-int c;
-for (int i = 2; i <= N; i++) {
+a = 0 , b = 1;
+for(int i -> 2 to N){
c = a + b;
a = b;
b = c;
@@ -134,10 +126,10 @@ for (int i = 2; i <= N; i++) {
> In the above code we were able to optimize the space complexity to O(1).
---
+
### Question
What is the purpose of memoization in dynamic programming?
-
-**Choices**
+### Choices
- [ ] To minimize the space complexity of the algorithm
- [x] To store and reuse solutions to subproblems
@@ -145,11 +137,11 @@ What is the purpose of memoization in dynamic programming?
- [ ] To improve the readability of the code
---
-### Question
-Which approach is considered as an iterative process?
-**Choices**
+### Question
+Which approach is considered as an iterative process?
+### Choices
- [ ] Top-down approach
- [x] Bottom-up approach
- [ ] Both are iterative
@@ -157,10 +149,11 @@ Which approach is considered as an iterative process?
---
-### Problem 2 Climbing Staircase
+## Problem 2 Climbing Staircase
+### Problem Statement
*Calculate the number of ways to reach the Nth stair. You can take 1 step at a time or 2 steps at a time.*
@@ -76,56 +74,50 @@ We keep using these small answers to find the bigger ones. If we already know an
By the end, we'll have the answer to fib(5), and all the smaller fib numbers stored in our array!
-#### Time and Space Complexity
+### Time and Space Complexity
**Time Complexity for the above code is O(N)** and **space complexity is O(N)**. Thus, we were able to reduce the time complexity from O(2^N) to O(N) using dynamic programing
----
-### Dynamic Programming Types
-
-
-#### Types of DP Solution:
+## Dynamic Programming Types
+### Types of DP Solution:
*Dynamic programming solution can be of two types*:
* **`Top-Down`** [Also know as **Memoization**]
* It is a recursive solution
* We start with the biggest problem and keep on breaking it till we reach the base case.
* Then store answers of already evaluated problems.
-* **`Bottom-Up`**
+* **`Bottom-Up`** [Also know as **Tabulation**]
* It is an iterative solution
* We start with the smallest problem, solve it and store its result.
* Then we keep on moving to the bigger problems and use the already calculated results from sub-problems.
-#### Bottom Up Approach for Fibonacci series
-#### Psuedocode
+### Bottom Up Approach for Fibonacci series
+### Psuedocode
```java
-int fib[N + 1];
+fib[N + 1];
fib[0] = 0;
fib[1] = 1;
-for (i = 2, i <= N; i++) {
+for(i -> 2 to N){
fib[i] = fib[i - 1] + fib[i - 2];
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
-
> Through this approach we were able to eliminate recursive stack.
-#### Further optimising the Space Complexity
+### Further optimising the Space Complexity
If seen closely, the above approach can be optimised by using just simple variables instead of an array. In this way, we can further optimize the space.
-#### Pseudocode
+### Pseudocode
```java
-int a = 0;
-int b = 1;
-int c;
-for (int i = 2; i <= N; i++) {
+a = 0 , b = 1;
+for(int i -> 2 to N){
c = a + b;
a = b;
b = c;
@@ -134,10 +126,10 @@ for (int i = 2; i <= N; i++) {
> In the above code we were able to optimize the space complexity to O(1).
---
+
### Question
What is the purpose of memoization in dynamic programming?
-
-**Choices**
+### Choices
- [ ] To minimize the space complexity of the algorithm
- [x] To store and reuse solutions to subproblems
@@ -145,11 +137,11 @@ What is the purpose of memoization in dynamic programming?
- [ ] To improve the readability of the code
---
-### Question
-Which approach is considered as an iterative process?
-**Choices**
+### Question
+Which approach is considered as an iterative process?
+### Choices
- [ ] Top-down approach
- [x] Bottom-up approach
- [ ] Both are iterative
@@ -157,10 +149,11 @@ Which approach is considered as an iterative process?
---
-### Problem 2 Climbing Staircase
+## Problem 2 Climbing Staircase
+### Problem Statement
*Calculate the number of ways to reach the Nth stair. You can take 1 step at a time or 2 steps at a time.*
 @@ -203,16 +196,18 @@ Number of ways to reach two stairs : 3 (as shown in fig)
---
+
### Question
In Stairs Problems, the result for N=4
-
-**Choices**
+### Choices
- [ ] 4
- [x] 5
- [ ] 6
- [ ] 7
-**Explanation:**
+
+
+### Explanation:
To reach 1st staircase : 1 way
To reach 2nd staircase : 2 ways
@@ -221,13 +216,9 @@ To reach 4th staircase : 5 ways
---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+## Climbing Staircase Approach
-
-### Problem 2 Climbing Staircase Approach
-#### Approach
+### Approach
We can come to 4th stair from 2nd and 3rd step.
* If I get to know #steps to reach stair 3, we can take length 1 step and reach stair 4.
@@ -245,8 +236,9 @@ We can come to 4th stair from 2nd and 3rd step.
We can see that the above has been deduced to fibonacii expression
---
-### Problem 3 Get Minimum Squares
+## Problem 3 Get Minimum Squares
+### Problem Statement
*Find minimum number of perfect squares required to get sum = N. (duplicate squares are allowed)*
*example 1 --> N = 6*
@@ -273,17 +265,20 @@ sum 10 can be obtained by the addition of following squares:
---
+
+
### Question
What is the minimum number of perfect squares required to get sum = 5. (duplicate squares are allowed)
-**Choices**
+### Choices
- [ ] 5
- [ ] 1
- [x] 2
- [ ] 3
-**Explanation**:
+
+### Explanation:
sum 5 can be obtained by the addition of following squares:
* `1^2 + 1^2 + 1^2 + 1^2 + 1^2`
@@ -291,14 +286,10 @@ sum 5 can be obtained by the addition of following squares:
---
+## Get Minimum Squares Approach
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Get Minimum Squares Approach
-#### Approach 1
+### Approach 1
* Can we simply do **`N - (nearest perfect square)`** ?
* Verifying approach 1 with example N=12
@@ -308,7 +299,7 @@ Please take some time to think about the solution approach on your own before re
* 1-1 = 0
* We are using 4 perfect squares, whereas the minimum number of square is 3 (2^2 + 2^2 +2^2) so approach 1 is not useful in this case
-#### Brute Force Approach
+### Brute Force Approach
* Try every possible way to form the sum using brute force to solve a example N = 12
@@ -203,16 +196,18 @@ Number of ways to reach two stairs : 3 (as shown in fig)
---
+
### Question
In Stairs Problems, the result for N=4
-
-**Choices**
+### Choices
- [ ] 4
- [x] 5
- [ ] 6
- [ ] 7
-**Explanation:**
+
+
+### Explanation:
To reach 1st staircase : 1 way
To reach 2nd staircase : 2 ways
@@ -221,13 +216,9 @@ To reach 4th staircase : 5 ways
---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+## Climbing Staircase Approach
-
-### Problem 2 Climbing Staircase Approach
-#### Approach
+### Approach
We can come to 4th stair from 2nd and 3rd step.
* If I get to know #steps to reach stair 3, we can take length 1 step and reach stair 4.
@@ -245,8 +236,9 @@ We can come to 4th stair from 2nd and 3rd step.
We can see that the above has been deduced to fibonacii expression
---
-### Problem 3 Get Minimum Squares
+## Problem 3 Get Minimum Squares
+### Problem Statement
*Find minimum number of perfect squares required to get sum = N. (duplicate squares are allowed)*
*example 1 --> N = 6*
@@ -273,17 +265,20 @@ sum 10 can be obtained by the addition of following squares:
---
+
+
### Question
What is the minimum number of perfect squares required to get sum = 5. (duplicate squares are allowed)
-**Choices**
+### Choices
- [ ] 5
- [ ] 1
- [x] 2
- [ ] 3
-**Explanation**:
+
+### Explanation:
sum 5 can be obtained by the addition of following squares:
* `1^2 + 1^2 + 1^2 + 1^2 + 1^2`
@@ -291,14 +286,10 @@ sum 5 can be obtained by the addition of following squares:
---
+## Get Minimum Squares Approach
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Get Minimum Squares Approach
-#### Approach 1
+### Approach 1
* Can we simply do **`N - (nearest perfect square)`** ?
* Verifying approach 1 with example N=12
@@ -308,7 +299,7 @@ Please take some time to think about the solution approach on your own before re
* 1-1 = 0
* We are using 4 perfect squares, whereas the minimum number of square is 3 (2^2 + 2^2 +2^2) so approach 1 is not useful in this case
-#### Brute Force Approach
+### Brute Force Approach
* Try every possible way to form the sum using brute force to solve a example N = 12
 @@ -318,20 +309,20 @@ Now, to get minimum sum of 12 we will find minimum square of 11 or minimum squar
The above is a recursive problem where we can see overalapping subproblems, like for N=7.
-#### Dynamic Programming Approach
+### Dynamic Programming Approach
Here optimal structure has been obtained as well as overlapping subproblems
So, we can say that
`square(i) = 1 + min{ squares(i - x^2) for all x^2 <= i} `and base case is square[0] = 0
-#### Psuedocode
+### Psuedocode
```java
-int dp[N + 1]; //initialise (-1)
-int psquares(int N, int dp[]) {
- if (n == 0) return 0;
+dp[N + 1]; //initialise (-1)
+psquares(N) {
+ if (N == 0) return 0;
if (dp[N] != -1) return dp[N];
- ans = int - max;
- for (x = 1; x * x <= N; x++) {
+ ans = infinity;
+ for (x -> 1 to sqrt(N)) {
ans = min(ans, psquares(N - x ^ 2)); // dp
}
dp[N] = 1 + ans;
@@ -340,3 +331,4 @@ int psquares(int N, int dp[]) {
```
Time complexity for the above code is O(N(sqrt(N))) and space complexity is O(N).
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md b/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md
index 3045270..019366b 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md
@@ -1,143 +1,90 @@
-# DP 2: Two Dimensional
+# DP 2: Two Dimensional
----
-## Problem 1 Maximum Subsequence Sum
-
-Find maximum subsequence sum from a given array, where selecting adjacent element is not allowed.
-
-**Examples**
-Example 1: ar[] = {9, 4, 13}
-Output 1: 22. Since out of all possible non adjacent element subsequences, the subsequence (9, 13) will yield maximum sum.
-
-Example 2: ar[] = {9, 4, 13, 24}
-Output 2: 33 (24 + 9)
-
-
----
-### Question
-Find maximum subsequence sum from `[10, 20, 30, 40]`, where selecting adjacent element is not allowed.
-
-**Choices**
-- [ ] 70
-- [x] 60
-- [ ] 100
-- [ ] 50
+## Problem 1 House Robber
+### Problem Statement:
+Given an integer array nums, where each element represents the amount of money in a house, determine the maximum amount of money you can rob without triggering an alarm. The constraint is that you cannot rob two adjacent houses (i.e., you cannot rob house i and house i+1 together).
+**Example 1**:
+Input: nums = [1, 2, 3, 1]
+Output: 4
**Explanation**:
+- Rob house 1 (money = 1) and house 3 (money = 3).
+- Total amount = 1 + 3 = 4.
-Maximum Subsequence is 60. Since, Out of all possible non adjacent element subsequences, the subsequence (20, 40) will yield maximum sum of 60.
-
-
----
-### Maximum Subsequence Sum Brute Force Approach
-
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
-- Consider all the valid subsequences **`(this a backtracking step)`**.
-- For creating subsequences, for every element we can make a choice, whether to select it or reject it.
-- Say, we start from right most element. If we keep it, then (n - 1)th element can't be considered, so jump to (n - 2)th. If we don't, then (n - 1)th element can be considered. So on...
-
-
-
@@ -318,20 +309,20 @@ Now, to get minimum sum of 12 we will find minimum square of 11 or minimum squar
The above is a recursive problem where we can see overalapping subproblems, like for N=7.
-#### Dynamic Programming Approach
+### Dynamic Programming Approach
Here optimal structure has been obtained as well as overlapping subproblems
So, we can say that
`square(i) = 1 + min{ squares(i - x^2) for all x^2 <= i} `and base case is square[0] = 0
-#### Psuedocode
+### Psuedocode
```java
-int dp[N + 1]; //initialise (-1)
-int psquares(int N, int dp[]) {
- if (n == 0) return 0;
+dp[N + 1]; //initialise (-1)
+psquares(N) {
+ if (N == 0) return 0;
if (dp[N] != -1) return dp[N];
- ans = int - max;
- for (x = 1; x * x <= N; x++) {
+ ans = infinity;
+ for (x -> 1 to sqrt(N)) {
ans = min(ans, psquares(N - x ^ 2)); // dp
}
dp[N] = 1 + ans;
@@ -340,3 +331,4 @@ int psquares(int N, int dp[]) {
```
Time complexity for the above code is O(N(sqrt(N))) and space complexity is O(N).
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md b/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md
index 3045270..019366b 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 2 Two Dimentional.md
@@ -1,143 +1,90 @@
-# DP 2: Two Dimensional
+# DP 2: Two Dimensional
----
-## Problem 1 Maximum Subsequence Sum
-
-Find maximum subsequence sum from a given array, where selecting adjacent element is not allowed.
-
-**Examples**
-Example 1: ar[] = {9, 4, 13}
-Output 1: 22. Since out of all possible non adjacent element subsequences, the subsequence (9, 13) will yield maximum sum.
-
-Example 2: ar[] = {9, 4, 13, 24}
-Output 2: 33 (24 + 9)
-
-
----
-### Question
-Find maximum subsequence sum from `[10, 20, 30, 40]`, where selecting adjacent element is not allowed.
-
-**Choices**
-- [ ] 70
-- [x] 60
-- [ ] 100
-- [ ] 50
+## Problem 1 House Robber
+### Problem Statement:
+Given an integer array nums, where each element represents the amount of money in a house, determine the maximum amount of money you can rob without triggering an alarm. The constraint is that you cannot rob two adjacent houses (i.e., you cannot rob house i and house i+1 together).
+**Example 1**:
+Input: nums = [1, 2, 3, 1]
+Output: 4
**Explanation**:
+- Rob house 1 (money = 1) and house 3 (money = 3).
+- Total amount = 1 + 3 = 4.
-Maximum Subsequence is 60. Since, Out of all possible non adjacent element subsequences, the subsequence (20, 40) will yield maximum sum of 60.
-
-
----
-### Maximum Subsequence Sum Brute Force Approach
-
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
-- Consider all the valid subsequences **`(this a backtracking step)`**.
-- For creating subsequences, for every element we can make a choice, whether to select it or reject it.
-- Say, we start from right most element. If we keep it, then (n - 1)th element can't be considered, so jump to (n - 2)th. If we don't, then (n - 1)th element can be considered. So on...
-
-
- -
-
-The above image shows tree which has all the choices of selection. Here we can see that the choices are overlapping.
-
-Moreover, as the problem can be broken into smaller problems and has overlapping sub problems, we can use **dynamic programming**.
-
-
----
-### Maximum Subsequence Sum Top Down Approach
-
-#### Top Down Approach
-So for **maxSum(i)** there are two options:
-* either we can select element present at index i
- * if we select that element we will include its value ie ar[i] and the recursive call will be **maxSum(i-2)**
-* or we cannot select the element present at index i
- * so in this case we will not include its value and will make recursive call which is **maxSum(i-1)**
-
-`dp[i] = stores the maximum value that can be obtained by selecting 0 to ith toy.`
-
-The maximum of the choice we make will give us the final answer
-
-#### Psuedocode
-
-```cpp
-int dp[N] //initialize it with negative infinity
+**Example 2**:
+Input: nums = [2, 7, 9, 3, 1]
+Output: 12
+**Explanation**:
-// i will be initialised with N-1, i.e we start with the last element
-int maxSum(int[] arr, i, dp[N]) {
- if (i < 0) {
+- Rob house 1 (money = 2), house 3 (money = 9), and house 5 (money = 1).
+- Total amount = 2 + 9 + 1 = 12.
+
+**Step-by-Step Breakdown**:
+### Brute Force Approach (Inefficient):
+
+**Idea**: Recursively explore all subsets of houses by either robbing or skipping each house, and calculate the maximum amount you can rob.
+**Steps**:
+- For each house, you can choose to:
+1.Rob the house and skip the next one.
+2.Skip the house and move to the next one.
+- Recursively compute the maximum amount of money that can be robbed.
+**Complexity**: O(2^n)
+
+**Flaws**:
+ - The brute force approach becomes extremely slow as the number of houses increases due to redundant calculations.
+
+## Problem 1 House Robber Optimised Approach
+### Optimized Approach Using Dynamic Programming (DP):
+
+**Key Insight**:
+For each house, you can either:
+1. Rob it and add its value to the total amount robbed from all non-adjacent previous houses.
+2. Skip it and take the maximum amount robbed from the previous house.
+
+**State Transition**:
+- Let dp[i] represent the maximum amount of money that can be robbed from the first i houses.
+- **For each house i**:
+dp[i] = max(dp[i-1], nums[i] + dp[i-2])
+- This means: either take the maximum amount up to the previous house dp[i-1], or rob the current house nums[i] and add the value from the non-adjacent house dp[i-2].
+
+
+**Optimized Solution Pseudocode (Dynamic Programming Approach):**
+
+``` cpp function rob(nums):
+ if len(nums) == 0:
return 0
- }
- if (dp[i] != -infinity) {
- return dp[i]
- }
- //Don't consider the ith element, in this case we can consider (i-1)th element
- f1 = maxSum(arr, i - 1, dp);
- //Consider the ith element, in this case we can't consider (i-1)th element, so we jump to (i-2)th element
- f2 = arr[i] + maxSum(arr, i - 2, dp);
+ if len(nums) == 1:
+ return nums[0]
- ans = max(f1, f2)
+ # Initialize base cases
+ dp[0] = nums[0]
+ dp[1] = max(nums[0], nums[1])
- dp[i] = ans;
+ # Fill the dp array for each house
+ for i from 2 to len(nums) - 1:
+ dp[i] = max(dp[i-1], nums[i] + dp[i-2])
- return ans
-}
+ # Return the maximum amount possible, which is dp[n-1]
+ return dp[len(nums) - 1]
```
-
-#### Time & Space Complexity
-
-**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
-**Space complexity:** O(N), because of dp array of size N.
-
+
+### Complexity Analysis:
+**Time Complexity**: O(n)
+**Space Complexity**:
+- The DP approach uses O(n) space to store the dp array.
+- The space-optimized version uses O(1) space, as it only maintains two variables.
---
-### Maximum Subsequence Sum Bottom Up Approach
-
-**Problem 1**
-**`dp[i] is defined as the maximum subsequence sum from [0 - i] provided no adjacent elements are selected`**
-
-arr = {9, 4, 13, 24}
-
-We can start from arr[0] and we have two choices: either we can select arr[0] or reject.
-* If we select it, the maximum value we can acheive is arr[0] = 9
-* If we reject it, the value which we will get is 0
-* So, we will store arr[0] in dp[0]
-
-* Now, we will look at arr[0] and arr[1] to find the maximum
- * As arr[0] > arr[1], we will store arr[0] in dp[1]
-* Similary we will repeat the above steps to fill dp[].
-
-
-#### Psuedocode
-
-```cpp
-dp[N]
-for(i = 0; i < N; i++){
- dp[i] = max(dp[i - 1], arr[i] + dp[i - 2])
-}
-return dp[N - 1]
-```
-
-
-#### Time & Space Complexity
-**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
-**Space complexity:** O(N), because of dp array of size N.
-
----
-### Problem 2 Count Unique Paths
+## Problem 2 Count Unique Paths
+### Problem Statement
Given mat[n][m], find total number of ways from (0,0) to (n - 1, m - 1). We can move 1 step in horizontal direction or 1 step in vertical direction.
-
-
-The above image shows tree which has all the choices of selection. Here we can see that the choices are overlapping.
-
-Moreover, as the problem can be broken into smaller problems and has overlapping sub problems, we can use **dynamic programming**.
-
-
----
-### Maximum Subsequence Sum Top Down Approach
-
-#### Top Down Approach
-So for **maxSum(i)** there are two options:
-* either we can select element present at index i
- * if we select that element we will include its value ie ar[i] and the recursive call will be **maxSum(i-2)**
-* or we cannot select the element present at index i
- * so in this case we will not include its value and will make recursive call which is **maxSum(i-1)**
-
-`dp[i] = stores the maximum value that can be obtained by selecting 0 to ith toy.`
-
-The maximum of the choice we make will give us the final answer
-
-#### Psuedocode
-
-```cpp
-int dp[N] //initialize it with negative infinity
+**Example 2**:
+Input: nums = [2, 7, 9, 3, 1]
+Output: 12
+**Explanation**:
-// i will be initialised with N-1, i.e we start with the last element
-int maxSum(int[] arr, i, dp[N]) {
- if (i < 0) {
+- Rob house 1 (money = 2), house 3 (money = 9), and house 5 (money = 1).
+- Total amount = 2 + 9 + 1 = 12.
+
+**Step-by-Step Breakdown**:
+### Brute Force Approach (Inefficient):
+
+**Idea**: Recursively explore all subsets of houses by either robbing or skipping each house, and calculate the maximum amount you can rob.
+**Steps**:
+- For each house, you can choose to:
+1.Rob the house and skip the next one.
+2.Skip the house and move to the next one.
+- Recursively compute the maximum amount of money that can be robbed.
+**Complexity**: O(2^n)
+
+**Flaws**:
+ - The brute force approach becomes extremely slow as the number of houses increases due to redundant calculations.
+
+## Problem 1 House Robber Optimised Approach
+### Optimized Approach Using Dynamic Programming (DP):
+
+**Key Insight**:
+For each house, you can either:
+1. Rob it and add its value to the total amount robbed from all non-adjacent previous houses.
+2. Skip it and take the maximum amount robbed from the previous house.
+
+**State Transition**:
+- Let dp[i] represent the maximum amount of money that can be robbed from the first i houses.
+- **For each house i**:
+dp[i] = max(dp[i-1], nums[i] + dp[i-2])
+- This means: either take the maximum amount up to the previous house dp[i-1], or rob the current house nums[i] and add the value from the non-adjacent house dp[i-2].
+
+
+**Optimized Solution Pseudocode (Dynamic Programming Approach):**
+
+``` cpp function rob(nums):
+ if len(nums) == 0:
return 0
- }
- if (dp[i] != -infinity) {
- return dp[i]
- }
- //Don't consider the ith element, in this case we can consider (i-1)th element
- f1 = maxSum(arr, i - 1, dp);
- //Consider the ith element, in this case we can't consider (i-1)th element, so we jump to (i-2)th element
- f2 = arr[i] + maxSum(arr, i - 2, dp);
+ if len(nums) == 1:
+ return nums[0]
- ans = max(f1, f2)
+ # Initialize base cases
+ dp[0] = nums[0]
+ dp[1] = max(nums[0], nums[1])
- dp[i] = ans;
+ # Fill the dp array for each house
+ for i from 2 to len(nums) - 1:
+ dp[i] = max(dp[i-1], nums[i] + dp[i-2])
- return ans
-}
+ # Return the maximum amount possible, which is dp[n-1]
+ return dp[len(nums) - 1]
```
-
-#### Time & Space Complexity
-
-**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
-**Space complexity:** O(N), because of dp array of size N.
-
+
+### Complexity Analysis:
+**Time Complexity**: O(n)
+**Space Complexity**:
+- The DP approach uses O(n) space to store the dp array.
+- The space-optimized version uses O(1) space, as it only maintains two variables.
---
-### Maximum Subsequence Sum Bottom Up Approach
-
-**Problem 1**
-**`dp[i] is defined as the maximum subsequence sum from [0 - i] provided no adjacent elements are selected`**
-
-arr = {9, 4, 13, 24}
-
-We can start from arr[0] and we have two choices: either we can select arr[0] or reject.
-* If we select it, the maximum value we can acheive is arr[0] = 9
-* If we reject it, the value which we will get is 0
-* So, we will store arr[0] in dp[0]
-
-* Now, we will look at arr[0] and arr[1] to find the maximum
- * As arr[0] > arr[1], we will store arr[0] in dp[1]
-* Similary we will repeat the above steps to fill dp[].
-
-
-#### Psuedocode
-
-```cpp
-dp[N]
-for(i = 0; i < N; i++){
- dp[i] = max(dp[i - 1], arr[i] + dp[i - 2])
-}
-return dp[N - 1]
-```
-
-
-#### Time & Space Complexity
-**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
-**Space complexity:** O(N), because of dp array of size N.
-
----
-### Problem 2 Count Unique Paths
+## Problem 2 Count Unique Paths
+### Problem Statement
Given mat[n][m], find total number of ways from (0,0) to (n - 1, m - 1). We can move 1 step in horizontal direction or 1 step in vertical direction.
 -**Example**
+### Example
-**Example**
+### Example
 @@ -149,22 +96,23 @@ Given mat[n][m], find total number of ways from (0,0) to (n - 1, m - 1). We can
---
+
+
### Question
Find the total number of ways to go from (0, 0) to (1, 2)
-| o | | |
-|---|---|---|
-| | | **o** |
+
@@ -149,22 +96,23 @@ Given mat[n][m], find total number of ways from (0,0) to (n - 1, m - 1). We can
---
+
+
### Question
Find the total number of ways to go from (0, 0) to (1, 2)
-| o | | |
-|---|---|---|
-| | | **o** |
+ -**Choices**
+
+### Choices
- [ ] 1
- [ ] 2
- [x] 3
- [ ] 4
-**Explanation**:
+### Explanation:
The 2D matrix dp is
@@ -177,16 +125,12 @@ From here, the number of ways to go from (0, 0) to (1, 2) is 3.
---
-### Count Unique Paths Brute Force Approach
+## Count Unique Paths Brute Force Approach
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Brute Force Appoarch
+### Brute Force Appoarch
**Backtracking**, i.e., start from (0, 0) and try all possible scenarios to reach (n - 1, m - 1)
-#### Observation
+### Observation
Can we break it into subproblems?
- We can reach (n - 1, m - 1) in one step (by moving vertically) from (n - 2, m - 1)
- We can reach (n - 1, m - 1) in one step (by moving horizontally) (n - 1, m - 2)
@@ -195,19 +139,19 @@ Can we break it into subproblems?
-#### Recursive Relation
+### Recursive Relation
**ways(i, j) = ways(i - 1, j) + ways(i, j - 1)**
-#### Base Condition
+### Base Condition
- When i == 0, we have only one path to reach at the end, i.e., by moving vertically.
- Similary, when j == 0, we have only one path to reach at the end, i.e., by moving horizontally.
Therefore, **ways(0, j) = ways(i, 0) = 1**
-#### Pseudocode:
+### Pseudocode:
```java
-int ways(i, j) {
+function ways(i, j) {
if (i == 0 || j == 0) {
return 1;
}
@@ -218,10 +162,9 @@ int ways(i, j) {
Time Complexity: O(2 ^ (N * M)), as at every step we have two options, and there are total of N * M cells.
----
-### Count Unique Paths Optimization
+## Count Unique Paths Optimization
-#### Optimization using DP
+### Optimization using DP
We can see the **optimal substructure** in this problem as it can be defined in terms of smaller subproblems.
@@ -237,18 +180,18 @@ We can see that, `(i - 1, j - 1)` are the overlapping subproblems.
*Which type of array should be used?*
Since two args (i and j) are varying in above method, 2-d storage is needed of size N x M.
-#### Top Down Approach
+### Top Down Approach
**`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`**
-#### Pseudocode
+### Pseudocode
```java
-int dp[N][M]; // initialized with -1
-int ways(i, j) {
+dp[N][M]; // initialized with -1
+function ways(i, j) {
if (i == 0 || j == 0) {
return 1;
}
-
+
if (dp[i][j] != -1) {
return dp[i][j];
}
@@ -257,7 +200,7 @@ int ways(i, j) {
return ans;
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N * M), as we are filling a matrix of size N * M.
**Space Complexity:** O(N * M), as we have used dp matrix of size N * M.
@@ -265,7 +208,7 @@ int ways(i, j) {
>
> If you say 0, that means there is no way to reach (0, 0) or (0, 0) is unreachable. Hence, to reach (0, 0) from (0, 0), there is 1 way and not 0.
-#### Bottom Up Approach:
+### Bottom Up Approach:
Consider a 2D matrix `dp` of size N * M.
`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`
@@ -278,7 +221,7 @@ In bottom up approach, we start from the smallest problem which is (0, 0) in thi
-**Choices**
+
+### Choices
- [ ] 1
- [ ] 2
- [x] 3
- [ ] 4
-**Explanation**:
+### Explanation:
The 2D matrix dp is
@@ -177,16 +125,12 @@ From here, the number of ways to go from (0, 0) to (1, 2) is 3.
---
-### Count Unique Paths Brute Force Approach
+## Count Unique Paths Brute Force Approach
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Brute Force Appoarch
+### Brute Force Appoarch
**Backtracking**, i.e., start from (0, 0) and try all possible scenarios to reach (n - 1, m - 1)
-#### Observation
+### Observation
Can we break it into subproblems?
- We can reach (n - 1, m - 1) in one step (by moving vertically) from (n - 2, m - 1)
- We can reach (n - 1, m - 1) in one step (by moving horizontally) (n - 1, m - 2)
@@ -195,19 +139,19 @@ Can we break it into subproblems?
-#### Recursive Relation
+### Recursive Relation
**ways(i, j) = ways(i - 1, j) + ways(i, j - 1)**
-#### Base Condition
+### Base Condition
- When i == 0, we have only one path to reach at the end, i.e., by moving vertically.
- Similary, when j == 0, we have only one path to reach at the end, i.e., by moving horizontally.
Therefore, **ways(0, j) = ways(i, 0) = 1**
-#### Pseudocode:
+### Pseudocode:
```java
-int ways(i, j) {
+function ways(i, j) {
if (i == 0 || j == 0) {
return 1;
}
@@ -218,10 +162,9 @@ int ways(i, j) {
Time Complexity: O(2 ^ (N * M)), as at every step we have two options, and there are total of N * M cells.
----
-### Count Unique Paths Optimization
+## Count Unique Paths Optimization
-#### Optimization using DP
+### Optimization using DP
We can see the **optimal substructure** in this problem as it can be defined in terms of smaller subproblems.
@@ -237,18 +180,18 @@ We can see that, `(i - 1, j - 1)` are the overlapping subproblems.
*Which type of array should be used?*
Since two args (i and j) are varying in above method, 2-d storage is needed of size N x M.
-#### Top Down Approach
+### Top Down Approach
**`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`**
-#### Pseudocode
+### Pseudocode
```java
-int dp[N][M]; // initialized with -1
-int ways(i, j) {
+dp[N][M]; // initialized with -1
+function ways(i, j) {
if (i == 0 || j == 0) {
return 1;
}
-
+
if (dp[i][j] != -1) {
return dp[i][j];
}
@@ -257,7 +200,7 @@ int ways(i, j) {
return ans;
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N * M), as we are filling a matrix of size N * M.
**Space Complexity:** O(N * M), as we have used dp matrix of size N * M.
@@ -265,7 +208,7 @@ int ways(i, j) {
>
> If you say 0, that means there is no way to reach (0, 0) or (0, 0) is unreachable. Hence, to reach (0, 0) from (0, 0), there is 1 way and not 0.
-#### Bottom Up Approach:
+### Bottom Up Approach:
Consider a 2D matrix `dp` of size N * M.
`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`
@@ -278,7 +221,7 @@ In bottom up approach, we start from the smallest problem which is (0, 0) in thi
 -#### Pseudocode
+### Pseudocode
```java
dp[N][M];
// Initialize `dp` row - 0 and col - 0 with 1.
@@ -294,216 +237,112 @@ Time Complexity: O(N * M)
Space Complexity: O(N * M)
-#### Can we further optimize the space complexity?
+### Can we further optimize the space complexity?
- The answer of every row is dependent upon its previous row.
- So, essentially, we require two rows at a time - (1) current row (2) previous row. Thus, the space can be optimized to use just two 1-D arrays.
---
-### Problem 3 Total number of ways to go to bottom right corner from top left corner
-
-
-Find the total number of ways to go to bottom right corner (N - 1, M - 1) from top left corner (0, 0) where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
-We can either traverse one step down or one step right.
-
-
-#### Pseudocode
+### Pseudocode
```java
dp[N][M];
// Initialize `dp` row - 0 and col - 0 with 1.
@@ -294,216 +237,112 @@ Time Complexity: O(N * M)
Space Complexity: O(N * M)
-#### Can we further optimize the space complexity?
+### Can we further optimize the space complexity?
- The answer of every row is dependent upon its previous row.
- So, essentially, we require two rows at a time - (1) current row (2) previous row. Thus, the space can be optimized to use just two 1-D arrays.
---
-### Problem 3 Total number of ways to go to bottom right corner from top left corner
-
-
-Find the total number of ways to go to bottom right corner (N - 1, M - 1) from top left corner (0, 0) where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
-We can either traverse one step down or one step right.
-
- -
-
-#### Solution
-
-
-
-| 1 | 1 | 1 | 1 |
-| - | - | - | - |
-| 1 | 0 | 1 | 0 |
-| 0 | 0 | 1 | 1 |
-| 0 | 0 | 1 | 2 |
-| 0 | 0 | 1 | 3 |
-
-
-The given problem is just a variation of above problem. Only advancement is that if cell value has 0, then there is no way to reach the bottom right cell.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Pseudocode (Recursive Approach)
-
-```cpp
-if (mat[i][j] != 0) {
- ways(i, j) = ways(i - 1, j) + ways(i, j - 1);
-} else {
- ways[i][j] = 0;
-}
-```
-
-Similar base condition can be added to top-down and bottom-up approach to optimize it using DP.
-
-
----
-### Question
-How many unique paths in the grid from (0, 0) to (2, 2) ?
-
-| 1 | 1 | 1 |
-|-------|-------|-------|
-| **0** | **0** | **0** |
-| **1** | **1** | **1** |
-
-where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
-
-**Choices**
-- [x] 0
-- [ ] 1
-- [ ] 2
-- [ ] 3
-
+## Problem 3 N digit numbers
+### Problem Statement:
+You are tasked with finding how many A-digit positive numbers exist, such that the sum of their digits equals B. A valid number does not contain leading zeros (i.e., the first digit must be between 1 and 9). Since the answer can be large, return the result modulo 10^9+7 (1000000007).
+**Example 1**:
+Input: A = 2, B = 4
+Output: 4
**Explanation**:
-On the Grid, Row 1 is completely blocked. So there is no path from (0, 0) to (2, 2).
-
-Thus, the Total number of unique paths is 0.
-
----
-### Problem 4 Dungeons and Princess
-
-
-Find the minimum health level of the prince to start with to save the princess, where the negative numbers denote a dragon and positive numbers denote red bull.
-
-Redbull will increase the health whereas the dragons will decrease the health.
-
-The prince can move either in horizontal right direction or vertical down direction.
-If health level <= 0, it means prince is dead.
-
-
-
-
-#### Solution
-
-
-
-| 1 | 1 | 1 | 1 |
-| - | - | - | - |
-| 1 | 0 | 1 | 0 |
-| 0 | 0 | 1 | 1 |
-| 0 | 0 | 1 | 2 |
-| 0 | 0 | 1 | 3 |
-
-
-The given problem is just a variation of above problem. Only advancement is that if cell value has 0, then there is no way to reach the bottom right cell.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Pseudocode (Recursive Approach)
-
-```cpp
-if (mat[i][j] != 0) {
- ways(i, j) = ways(i - 1, j) + ways(i, j - 1);
-} else {
- ways[i][j] = 0;
-}
-```
-
-Similar base condition can be added to top-down and bottom-up approach to optimize it using DP.
-
-
----
-### Question
-How many unique paths in the grid from (0, 0) to (2, 2) ?
-
-| 1 | 1 | 1 |
-|-------|-------|-------|
-| **0** | **0** | **0** |
-| **1** | **1** | **1** |
-
-where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
-
-**Choices**
-- [x] 0
-- [ ] 1
-- [ ] 2
-- [ ] 3
-
+## Problem 3 N digit numbers
+### Problem Statement:
+You are tasked with finding how many A-digit positive numbers exist, such that the sum of their digits equals B. A valid number does not contain leading zeros (i.e., the first digit must be between 1 and 9). Since the answer can be large, return the result modulo 10^9+7 (1000000007).
+**Example 1**:
+Input: A = 2, B = 4
+Output: 4
**Explanation**:
-On the Grid, Row 1 is completely blocked. So there is no path from (0, 0) to (2, 2).
-
-Thus, the Total number of unique paths is 0.
-
----
-### Problem 4 Dungeons and Princess
-
-
-Find the minimum health level of the prince to start with to save the princess, where the negative numbers denote a dragon and positive numbers denote red bull.
-
-Redbull will increase the health whereas the dragons will decrease the health.
-
-The prince can move either in horizontal right direction or vertical down direction.
-If health level <= 0, it means prince is dead.
-
- -
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Observation
-One might argue to solve it by finding the path with minimum sum or maximum sum.
-
-Let's check does it even work or not?
-
-#### Using path with minimum sum(fails)
-- For the above matrix, the path with minimum sum is -3 -> -6 -> -15 -> -7 -> 5 -> -3 -> -4, which yields sum as 33. So, minimum health level should be (3 + 6 + 15 + 7) + 1 = 32, right?
-- No because if we start with **health 4** and follow the path -3 -> 2 -> 4 -> -5 -> 6 -> -2 -> -4, we can definitely reach the princess with lesser initial health.
-- Thus, finding the path with minimum sum doesn't work/
-
-#### Using path with maximum sum(fails)
-
-
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-#### Observation
-One might argue to solve it by finding the path with minimum sum or maximum sum.
-
-Let's check does it even work or not?
-
-#### Using path with minimum sum(fails)
-- For the above matrix, the path with minimum sum is -3 -> -6 -> -15 -> -7 -> 5 -> -3 -> -4, which yields sum as 33. So, minimum health level should be (3 + 6 + 15 + 7) + 1 = 32, right?
-- No because if we start with **health 4** and follow the path -3 -> 2 -> 4 -> -5 -> 6 -> -2 -> -4, we can definitely reach the princess with lesser initial health.
-- Thus, finding the path with minimum sum doesn't work/
-
-#### Using path with maximum sum(fails)
-
- -
-
-- For the above matrix, the path with maximum sum is -2 -> -8 -> 100 -> 1, which yields sum as 91. So, minimum health level should be (2 + 8) + 1 = 11, right?
-- No because if we start with **health 7** and follow the path -2 -> -1 -> -3 -> 1, we can definitely reach the princess with lesser initial health.
-- Similarly, finding the path with maximum sum doesn't work.
-
-> NOTE:
-> Finding the path with maximum or minimum sum is a greedy approach, which doesn't work for this problem.
+- Valid numbers with 2 digits whose sum is 4 are: {22, 31, 13, 40}.
+- Hence, the output is 4.
-#### How to approach the problem then?
-Let's start with finding the smallest problem.
-
-***Where does smallest problem lie?* (0, 0) ?*** **NO**
-
-The smallest problem lies at **`(M - 1, N - 1)`**, because we need to find the minimum health to finally enter that cell to save the princess.
-
-***Now, what should be the minimum health to enter a cell?***
-
-Suppose the cell(M - 1, N - 1) has value -4, then to enter the cell needed is: minimum_health + (-4) > 0 => minimum_health + (-4) = 1 => minimum_health = 5
-
-
-
-
-- For the above matrix, the path with maximum sum is -2 -> -8 -> 100 -> 1, which yields sum as 91. So, minimum health level should be (2 + 8) + 1 = 11, right?
-- No because if we start with **health 7** and follow the path -2 -> -1 -> -3 -> 1, we can definitely reach the princess with lesser initial health.
-- Similarly, finding the path with maximum sum doesn't work.
-
-> NOTE:
-> Finding the path with maximum or minimum sum is a greedy approach, which doesn't work for this problem.
+- Valid numbers with 2 digits whose sum is 4 are: {22, 31, 13, 40}.
+- Hence, the output is 4.
-#### How to approach the problem then?
-Let's start with finding the smallest problem.
-
-***Where does smallest problem lie?* (0, 0) ?*** **NO**
-
-The smallest problem lies at **`(M - 1, N - 1)`**, because we need to find the minimum health to finally enter that cell to save the princess.
-
-***Now, what should be the minimum health to enter a cell?***
-
-Suppose the cell(M - 1, N - 1) has value -4, then to enter the cell needed is: minimum_health + (-4) > 0 => minimum_health + (-4) = 1 => minimum_health = 5
-
- +**Example 2**:
+Input: A = 1, B = 3
+Output: 1
+**Explanation**:
+- The only valid 1-digit number whose sum is 3 is 3.
-There are two ways to enter the cell:
-**(1)** via TOP **(2)** via LEFT.
-***Which one to choose?***
+**Step-by-Step Breakdown**:
+### Brute Force Approach (Inefficient):
-We know, to enter the cell with value -4, the minimum health should be 5. Therefore, if we want to enter from top cell with value -2, then x + (-2) = 5; x = 7, where 'x' is minimum health to enter top cell.
+**Idea**: Generate all possible A-digit numbers, check each number to see if the sum of its digits equals B.
+**Steps**:
+- Iterate through all possible A-digit numbers.
+- For each number, calculate the sum of its digits and check if it equals B.
+- Count all valid numbers.
+**Time Complexity**: O(9^A)
-Similary, y + (-3) = 5; y = 8.
+**Flaws**:
-
+**Example 2**:
+Input: A = 1, B = 3
+Output: 1
+**Explanation**:
+- The only valid 1-digit number whose sum is 3 is 3.
-There are two ways to enter the cell:
-**(1)** via TOP **(2)** via LEFT.
-***Which one to choose?***
+**Step-by-Step Breakdown**:
+### Brute Force Approach (Inefficient):
-We know, to enter the cell with value -4, the minimum health should be 5. Therefore, if we want to enter from top cell with value -2, then x + (-2) = 5; x = 7, where 'x' is minimum health to enter top cell.
+**Idea**: Generate all possible A-digit numbers, check each number to see if the sum of its digits equals B.
+**Steps**:
+- Iterate through all possible A-digit numbers.
+- For each number, calculate the sum of its digits and check if it equals B.
+- Count all valid numbers.
+**Time Complexity**: O(9^A)
-Similary, y + (-3) = 5; y = 8.
+**Flaws**:
- +- This approach is inefficient for larger values of A since it involves generating many numbers and checking each one.
-Hence, we should choose minimum of these and enter the cell via top.
-**What is the minimum health required to enter a cell (i, j) which has two options to move ahead?**
-
+- This approach is inefficient for larger values of A since it involves generating many numbers and checking each one.
-Hence, we should choose minimum of these and enter the cell via top.
-**What is the minimum health required to enter a cell (i, j) which has two options to move ahead?**
- +## Problem 3 N digit numbers Optimized Approach
-
-
+### Optimized Approach Using Dynamic Programming (DP):
+**Key Insight**: Instead of generating all numbers, we can use dynamic programming to efficiently count valid numbers. We can build the solution step by step by keeping track of the sum of digits at each step.
-
+## Problem 3 N digit numbers Optimized Approach
-
-
+### Optimized Approach Using Dynamic Programming (DP):
+**Key Insight**: Instead of generating all numbers, we can use dynamic programming to efficiently count valid numbers. We can build the solution step by step by keeping track of the sum of digits at each step.
- +**State Definition**:
-> If the minimum health evaluates to negative, we should consider 1 in place of that as with any health <= 0, the prince will die.
+- Let dp[i][j] represent the number of valid i-digit numbers whose digit sum equals j.
+Our goal is to calculate dp[A][B].
-Let's fill the matrix using the same approach.
+**State Transition**:
+- For each i (number of digits so far) and each j (current sum of digits), we add a new digit d (ranging from 0 to 9) and update the state:
+dp[i][j] += dp[i-1][j-d]
+- This means: for each number with i-1 digits whose sum is j-d, we can form a new number by adding a digit d to it, resulting in an i-digit number whose sum is j.
-
+**State Definition**:
-> If the minimum health evaluates to negative, we should consider 1 in place of that as with any health <= 0, the prince will die.
+- Let dp[i][j] represent the number of valid i-digit numbers whose digit sum equals j.
+Our goal is to calculate dp[A][B].
-Let's fill the matrix using the same approach.
+**State Transition**:
+- For each i (number of digits so far) and each j (current sum of digits), we add a new digit d (ranging from 0 to 9) and update the state:
+dp[i][j] += dp[i-1][j-d]
+- This means: for each number with i-1 digits whose sum is j-d, we can form a new number by adding a digit d to it, resulting in an i-digit number whose sum is j.
- +**Base Case**:
+- dp[1][sum] = 1 for all valid sums where 1 ≤ sum ≤ 9, because there is exactly one 1-digit number for each sum.
-Here, `dp[i][j]` = min health with which prince should take the entry at (i, j) so that he can save the princess.
+**Optimized Solution Pseudocode (DP Approach)**:
----
-### Question
-What is the Time Complexity to find minimum cost path from (0,0) to (r-1, c-1)?
+``` cpp function countValidNumbers(A, B):
+ MOD = 1000000007
+
+ # Initialize dp array: dp[i][j] represents the number of valid i-digit numbers with digit sum j
+ dp = array of size [A + 1][B + 1] initialized to 0
+
+ # Base case: For 1-digit numbers
+ for d from 1 to 9:
+ if d <= B:
+ dp[1][d] = 1 # There's exactly one way to get a sum of d with one digit
-**Choices**
-- [ ] O(max(r, c))
-- [ ] O(c )
-- [x] O(r * c)
-- [ ] O(r + c)
+ # Fill dp array
+ for i from 2 to A: # Iterate through digit counts
+ for j from 0 to B: # Iterate through sums
+ for d from 0 to 9: # Try adding each digit d
+ if j - d >= 0:
+ dp[i][j] = (dp[i][j] + dp[i-1][j-d]) % MOD
----
-### Dungeons and Princess Algorithm and Pseudocode
-#### Algorithm
-```java
-arr[i][j] + x = min(dp[i + 1][j], dp[i][j + 1])
-x = min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]
+ # Return the result for A digits and sum B
+ return dp[A][B]
+
```
+**Explanation:**
+**Base Case**:
-Since `x` should be > 0
+- For i = 1 (1-digit numbers), dp[1][d] = 1 for all d from 1 to 9. This initializes the base case where there is exactly one way to form a 1-digit number for each sum d.
-```java
-x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j])
-```
+**Transition**:
-#### Pseudocode:
-```java
-declare dp[N][M];
-if (arr[N - 1][M - 1] > 0) {
- dp[N - 1][M - 1] = 1;
-} else {
- dp[N - 1][M - 1] = 1 + abs(arr[N - 1][M - 1]);
-}
+- For each digit count i (from 2 to A), and each sum j (from 0 to B), we check all possible new digits d (from 0 to 9).
+- If adding digit d to a number whose sum was j-d forms a valid i-digit number, we update the count of valid numbers for i digits and sum j.
-// Fill the last column and last row
+**Result**:
-for (i = N - 2; i >= 0; i--) {
- for (j = M - 2; j >= 0; j--) {
- x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]);
- dp[i][j] = x;
- }
-}
+- The final answer is stored in dp[A][B], which gives the number of valid A-digit numbers with a digit sum of B.
-return dp[0][0];
-```
-
-#### Complexity
-**Time Complexity:** O(N * M)
-**Space Complexity:** O(N * M)
+### Time Complexity Analysis:
+**Time Complexity**: O(A×B×10).
+**Space Complexity**: O(A×B).
-
----
### Catalan Numbers
-
The Catalan numbers form a sequence of natural numbers that have numerous applications in combinatorial mathematics. Each number in the sequence is a solution to a variety of counting problems. The Nth Catalan number, denoted as Cn, can be used to determine:
* The number of correct combinations of N pairs of parentheses.
@@ -519,29 +358,31 @@ C4 = C0 * C3 + C1 * C2 + C2 * C1 + C3 * C0 = 14
C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0 = 42
```
-#### Formula
+### Formula
+**Base Case**:
+- dp[1][sum] = 1 for all valid sums where 1 ≤ sum ≤ 9, because there is exactly one 1-digit number for each sum.
-Here, `dp[i][j]` = min health with which prince should take the entry at (i, j) so that he can save the princess.
+**Optimized Solution Pseudocode (DP Approach)**:
----
-### Question
-What is the Time Complexity to find minimum cost path from (0,0) to (r-1, c-1)?
+``` cpp function countValidNumbers(A, B):
+ MOD = 1000000007
+
+ # Initialize dp array: dp[i][j] represents the number of valid i-digit numbers with digit sum j
+ dp = array of size [A + 1][B + 1] initialized to 0
+
+ # Base case: For 1-digit numbers
+ for d from 1 to 9:
+ if d <= B:
+ dp[1][d] = 1 # There's exactly one way to get a sum of d with one digit
-**Choices**
-- [ ] O(max(r, c))
-- [ ] O(c )
-- [x] O(r * c)
-- [ ] O(r + c)
+ # Fill dp array
+ for i from 2 to A: # Iterate through digit counts
+ for j from 0 to B: # Iterate through sums
+ for d from 0 to 9: # Try adding each digit d
+ if j - d >= 0:
+ dp[i][j] = (dp[i][j] + dp[i-1][j-d]) % MOD
----
-### Dungeons and Princess Algorithm and Pseudocode
-#### Algorithm
-```java
-arr[i][j] + x = min(dp[i + 1][j], dp[i][j + 1])
-x = min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]
+ # Return the result for A digits and sum B
+ return dp[A][B]
+
```
+**Explanation:**
+**Base Case**:
-Since `x` should be > 0
+- For i = 1 (1-digit numbers), dp[1][d] = 1 for all d from 1 to 9. This initializes the base case where there is exactly one way to form a 1-digit number for each sum d.
-```java
-x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j])
-```
+**Transition**:
-#### Pseudocode:
-```java
-declare dp[N][M];
-if (arr[N - 1][M - 1] > 0) {
- dp[N - 1][M - 1] = 1;
-} else {
- dp[N - 1][M - 1] = 1 + abs(arr[N - 1][M - 1]);
-}
+- For each digit count i (from 2 to A), and each sum j (from 0 to B), we check all possible new digits d (from 0 to 9).
+- If adding digit d to a number whose sum was j-d forms a valid i-digit number, we update the count of valid numbers for i digits and sum j.
-// Fill the last column and last row
+**Result**:
-for (i = N - 2; i >= 0; i--) {
- for (j = M - 2; j >= 0; j--) {
- x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]);
- dp[i][j] = x;
- }
-}
+- The final answer is stored in dp[A][B], which gives the number of valid A-digit numbers with a digit sum of B.
-return dp[0][0];
-```
-
-#### Complexity
-**Time Complexity:** O(N * M)
-**Space Complexity:** O(N * M)
+### Time Complexity Analysis:
+**Time Complexity**: O(A×B×10).
+**Space Complexity**: O(A×B).
-
----
### Catalan Numbers
-
The Catalan numbers form a sequence of natural numbers that have numerous applications in combinatorial mathematics. Each number in the sequence is a solution to a variety of counting problems. The Nth Catalan number, denoted as Cn, can be used to determine:
* The number of correct combinations of N pairs of parentheses.
@@ -519,29 +358,31 @@ C4 = C0 * C3 + C1 * C2 + C2 * C1 + C3 * C0 = 14
C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0 = 42
```
-#### Formula
+### Formula

 -#### Psuedo Code
+### Psuedo Code
```cpp
-int C[N + 1];
+declare array C[N + 1];
C[0] = 1;
C[1] = 1;
-for (int i = 2; i <= N; i++) {
- for (int j = 0; j < i; j++) {
+for(i -> 2 to N)
+{
+ for(j -> 0 to i - 1)
+ {
C[i] += C[j] * C[N - 1 - j];
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2^)
**Space Complexity:** O(N)
@@ -550,12 +391,13 @@ Now, Let's look into a problem, which can be solved by finding the **Nth catalan
---
-### Problem 5 Total Number of Unique BSTs
+## Problem 4 Total Number of Unique BSTs
+### Problem Statement
You are given a number N, Count Total number of Unique Binary Search Trees, that can be formed using N distinct numbers.
-**Example**
+### Example
**Input:**
N = 3
@@ -575,18 +417,21 @@ The Unique binary Search Trees are
```
---
+
+
### Question
Count Total number of Unique Binary Search Trees, that can be formed using 2 distinct numbers
-**Choices**
+### Choices
- [ ] 1
- [x] 2
- [ ] 5
- [ ] 4
-**Explanation**:
-Lets take 2 distinct numbers as [10, 20]
+### Explanation:
+
+Let's take 2 distinct numbers as [10, 20]
The possible BSTs are
```
@@ -596,16 +441,10 @@ The possible BSTs are
```
---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
### Total Number of Unique BSTs Dryrun
+Let's take N = 5, the numbers are [10, 20, 30, 40, 50].
-
-Lets take N = 5, the numbers are [10, 20, 30, 40, 50].
-
-Lets keep each number as the root! one by one.
+Let's keep each number as the root! one by one.
**10 as root**
```
@@ -616,11 +455,11 @@ Lets keep each number as the root! one by one.
20, 30, 40, 50
```
-Here we notice that, 20, 30, 40 and 50 can be structured by various sub-roots. So, lets denote by C4.
+Here we notice that, 20, 30, 40 and 50 will be present on right side of 10. With these 4 nodes, we can create further BSTs, let's denote by C4
Also on the right side, there is no elements. So denoting by C0.
-`10 as root => C0 * C1`
+With `10 as root, the total number of BSTs => C0 * C1`
**20 as root**
@@ -686,28 +525,28 @@ C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0
which is 42.
-#### Solution
+### Solution
The Solution for finding the total number of Unique BSTs is the **Nth Catalan Number**.
+## Total Number of Unique BSTs Pseudo Code
----
-### Total Number of Unique BSTs Pseudo Code
-
-#### Psuedo Code
+### Psuedo Code
The pseudo code is same as the Catalan Number Psuedo code.
```cpp
-function findTotalUniqueBSTs(int N) {
- int C[N + 1];
+function findTotalUniqueBSTs(N){
+ declare array C[N + 1];
C[0] = 1;
C[1] = 1;
- for (int i = 2; i <= N; i++) {
- for (int j = 0; j < i; j++) {
+ for(i -> 2 to N)
+ {
+ for(j -> 0 to i - 1)
+ {
C[i] += C[j] * C[N - 1 - j];
}
}
@@ -716,9 +555,9 @@ function findTotalUniqueBSTs(int N) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2^)
**Space Complexity:** O(N)
-
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md b/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md
index 155722f..8cb023c 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md
@@ -1,7 +1,116 @@
# DP 3: Knapsack
----
-## Knapsack Problem
+
+## Subset Sum
+
+
+### Problem Statement:
+You are given an integer array nums. Determine whether it is possible to partition the array into two subsets such that the sum of elements in both subsets is equal. Return true if possible, and false otherwise.
+
+**Example 1**:
+Input: nums = [1, 5, 11, 5]
+Output: true
+**Explanation**:
+
+The array can be partitioned into two subsets: {1, 5, 5} and {11}, both with sum 11.
+
+**Example 2**:
+Input: nums = [1, 2, 3, 5]
+Output: false
+**Explanation**:
+
+It is not possible to partition the array into two subsets with equal sums.
+
+
+**Key Insight**:
+
+- The problem reduces to checking whether we can find a subset whose sum is equal to half of the total sum of the array.
+- If the total sum of the array is odd, it is immediately impossible to partition the array into two subsets with equal sums.
+If the total sum is even, we need to check if there exists a subset whose sum is half of the total sum.
+
+**Problem Restatement**:
+
+- Let the total sum of the array be S.
+- If S % 2 != 0, return false.
+- Otherwise, find out if there exists a subset in nums whose sum equals S / 2. This is a classic subset sum problem.
+
+### Approach 1: Brute Force (Inefficient)
+**Idea**: Explore all possible subsets and check if any subset has a sum equal to S / 2.
+
+**Steps**:
+
+Generate all possible subsets of nums.
+For each subset, calculate the sum and check if it equals S / 2.
+**Complexity**: O(2^n)
+
+
+**Flaws**:
+
+- This approach becomes highly inefficient for large arrays due to the exponential number of possible subsets.
+
+## Subset Sum optimized approach
+
+### Approach 2: Dynamic Programming (Optimized Solution)
+**Key Insight**: Use dynamic programming to determine if there exists a subset with sum S / 2.
+
+**State Definition**:
+
+- Let target = S / 2. We need to determine if a subset of nums can achieve this target sum.
+- Use a boolean DP array dp where dp[j] represents whether a subset with sum j is achievable using the elements in the array.
+
+**State Transition**:
+
+- Initialize dp[0] = true, because a subset with sum 0 is always possible (the empty subset).
+- For each element num in nums, update the DP array for sums from target down to num:
+dp[j] = dp[j] or dp[j - num]
+- This means: If we can form a sum j - num, we can also form the sum j by including the current element num.
+
+### Pseudocode (Dynamic Programming Approach):
+
+``` cpp
+function canPartition(nums):
+ totalSum = sum(nums)
+
+ # If totalSum is odd, we cannot partition the array into two equal subsets
+ if totalSum % 2 != 0:
+ return false
+
+ target = totalSum / 2
+ dp = array of size (target + 1) initialized to false
+ dp[0] = true # We can always form a sum of 0
+
+ # Process each number in nums
+ for num in nums:
+ # Update the dp array from target down to num
+ for j from target down to num:
+ dp[j] = dp[j] or dp[j - num]
+
+ # The result is whether we can form the sum 'target'
+ return dp[target]
+
+```
+
+**Explanation**:
+**Initialization**:
+
+- dp[0] = true because a sum of 0 can always be formed with an empty subset.
+- All other dp[j] values are initially false, as no subset sums have been processed yet.
+
+**State Transition**:
+
+- For each element num in nums, iterate backward from target down to num.
+- For each j, if dp[j - num] is true, set dp[j] = true, indicating that the sum j can now be formed by adding num to the subset.
+
+**Final Result**:
+
+- After processing all elements, the value dp[target] will tell us if it's possible to form a subset with sum target.
+
+### Complexity Analysis:
+**Time Complexity**: (n×target)
+**Space Complexity**: O(target)
+
+## Knapsack
+### Knapsack Problem
Given N objects with their values Vi profit/loss their weight Wi. A bag is given with capacity W that can be used to carry some objects such that the total sum of object weights W and sum of profit in the bag is maximized or sum of loss in the bag is minimized.
@@ -11,21 +120,18 @@ We will try Knapsack when these combinations are given:
* and capacity will be given
---
-### Problem 1 Fractional Knapsack
+## Problem 1 Fractional Knapsack
+### Problem Statement
Given N cakes with their happiness and weight. Find maximum total happiness that can be kept in a bag with capacity = W (cakes can be divided)
-**Example**:
+### Example:
N = 5; W = 40
Happiness of the 5 cakes = [3, 8, 10, 2, 5]
Weight of the 5 cakes = [10, 4, 20, 8, 15]
Goal - happiness should be maximum possible and the total sum of weights should be <= 40.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-**Approach**
+### Approach
**`Since we can divide the objects, hence they can be picked based on their value per unit weight.`**
@@ -39,7 +145,7 @@ Please take some time to think about the solution approach on your own before re
-#### Psuedo Code
+### Psuedo Code
```cpp
-int C[N + 1];
+declare array C[N + 1];
C[0] = 1;
C[1] = 1;
-for (int i = 2; i <= N; i++) {
- for (int j = 0; j < i; j++) {
+for(i -> 2 to N)
+{
+ for(j -> 0 to i - 1)
+ {
C[i] += C[j] * C[N - 1 - j];
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2^)
**Space Complexity:** O(N)
@@ -550,12 +391,13 @@ Now, Let's look into a problem, which can be solved by finding the **Nth catalan
---
-### Problem 5 Total Number of Unique BSTs
+## Problem 4 Total Number of Unique BSTs
+### Problem Statement
You are given a number N, Count Total number of Unique Binary Search Trees, that can be formed using N distinct numbers.
-**Example**
+### Example
**Input:**
N = 3
@@ -575,18 +417,21 @@ The Unique binary Search Trees are
```
---
+
+
### Question
Count Total number of Unique Binary Search Trees, that can be formed using 2 distinct numbers
-**Choices**
+### Choices
- [ ] 1
- [x] 2
- [ ] 5
- [ ] 4
-**Explanation**:
-Lets take 2 distinct numbers as [10, 20]
+### Explanation:
+
+Let's take 2 distinct numbers as [10, 20]
The possible BSTs are
```
@@ -596,16 +441,10 @@ The possible BSTs are
```
---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
### Total Number of Unique BSTs Dryrun
+Let's take N = 5, the numbers are [10, 20, 30, 40, 50].
-
-Lets take N = 5, the numbers are [10, 20, 30, 40, 50].
-
-Lets keep each number as the root! one by one.
+Let's keep each number as the root! one by one.
**10 as root**
```
@@ -616,11 +455,11 @@ Lets keep each number as the root! one by one.
20, 30, 40, 50
```
-Here we notice that, 20, 30, 40 and 50 can be structured by various sub-roots. So, lets denote by C4.
+Here we notice that, 20, 30, 40 and 50 will be present on right side of 10. With these 4 nodes, we can create further BSTs, let's denote by C4
Also on the right side, there is no elements. So denoting by C0.
-`10 as root => C0 * C1`
+With `10 as root, the total number of BSTs => C0 * C1`
**20 as root**
@@ -686,28 +525,28 @@ C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0
which is 42.
-#### Solution
+### Solution
The Solution for finding the total number of Unique BSTs is the **Nth Catalan Number**.
+## Total Number of Unique BSTs Pseudo Code
----
-### Total Number of Unique BSTs Pseudo Code
-
-#### Psuedo Code
+### Psuedo Code
The pseudo code is same as the Catalan Number Psuedo code.
```cpp
-function findTotalUniqueBSTs(int N) {
- int C[N + 1];
+function findTotalUniqueBSTs(N){
+ declare array C[N + 1];
C[0] = 1;
C[1] = 1;
- for (int i = 2; i <= N; i++) {
- for (int j = 0; j < i; j++) {
+ for(i -> 2 to N)
+ {
+ for(j -> 0 to i - 1)
+ {
C[i] += C[j] * C[N - 1 - j];
}
}
@@ -716,9 +555,9 @@ function findTotalUniqueBSTs(int N) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2^)
**Space Complexity:** O(N)
-
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md b/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md
index 155722f..8cb023c 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 3 Knapsack.md
@@ -1,7 +1,116 @@
# DP 3: Knapsack
----
-## Knapsack Problem
+
+## Subset Sum
+
+
+### Problem Statement:
+You are given an integer array nums. Determine whether it is possible to partition the array into two subsets such that the sum of elements in both subsets is equal. Return true if possible, and false otherwise.
+
+**Example 1**:
+Input: nums = [1, 5, 11, 5]
+Output: true
+**Explanation**:
+
+The array can be partitioned into two subsets: {1, 5, 5} and {11}, both with sum 11.
+
+**Example 2**:
+Input: nums = [1, 2, 3, 5]
+Output: false
+**Explanation**:
+
+It is not possible to partition the array into two subsets with equal sums.
+
+
+**Key Insight**:
+
+- The problem reduces to checking whether we can find a subset whose sum is equal to half of the total sum of the array.
+- If the total sum of the array is odd, it is immediately impossible to partition the array into two subsets with equal sums.
+If the total sum is even, we need to check if there exists a subset whose sum is half of the total sum.
+
+**Problem Restatement**:
+
+- Let the total sum of the array be S.
+- If S % 2 != 0, return false.
+- Otherwise, find out if there exists a subset in nums whose sum equals S / 2. This is a classic subset sum problem.
+
+### Approach 1: Brute Force (Inefficient)
+**Idea**: Explore all possible subsets and check if any subset has a sum equal to S / 2.
+
+**Steps**:
+
+Generate all possible subsets of nums.
+For each subset, calculate the sum and check if it equals S / 2.
+**Complexity**: O(2^n)
+
+
+**Flaws**:
+
+- This approach becomes highly inefficient for large arrays due to the exponential number of possible subsets.
+
+## Subset Sum optimized approach
+
+### Approach 2: Dynamic Programming (Optimized Solution)
+**Key Insight**: Use dynamic programming to determine if there exists a subset with sum S / 2.
+
+**State Definition**:
+
+- Let target = S / 2. We need to determine if a subset of nums can achieve this target sum.
+- Use a boolean DP array dp where dp[j] represents whether a subset with sum j is achievable using the elements in the array.
+
+**State Transition**:
+
+- Initialize dp[0] = true, because a subset with sum 0 is always possible (the empty subset).
+- For each element num in nums, update the DP array for sums from target down to num:
+dp[j] = dp[j] or dp[j - num]
+- This means: If we can form a sum j - num, we can also form the sum j by including the current element num.
+
+### Pseudocode (Dynamic Programming Approach):
+
+``` cpp
+function canPartition(nums):
+ totalSum = sum(nums)
+
+ # If totalSum is odd, we cannot partition the array into two equal subsets
+ if totalSum % 2 != 0:
+ return false
+
+ target = totalSum / 2
+ dp = array of size (target + 1) initialized to false
+ dp[0] = true # We can always form a sum of 0
+
+ # Process each number in nums
+ for num in nums:
+ # Update the dp array from target down to num
+ for j from target down to num:
+ dp[j] = dp[j] or dp[j - num]
+
+ # The result is whether we can form the sum 'target'
+ return dp[target]
+
+```
+
+**Explanation**:
+**Initialization**:
+
+- dp[0] = true because a sum of 0 can always be formed with an empty subset.
+- All other dp[j] values are initially false, as no subset sums have been processed yet.
+
+**State Transition**:
+
+- For each element num in nums, iterate backward from target down to num.
+- For each j, if dp[j - num] is true, set dp[j] = true, indicating that the sum j can now be formed by adding num to the subset.
+
+**Final Result**:
+
+- After processing all elements, the value dp[target] will tell us if it's possible to form a subset with sum target.
+
+### Complexity Analysis:
+**Time Complexity**: (n×target)
+**Space Complexity**: O(target)
+
+## Knapsack
+### Knapsack Problem
Given N objects with their values Vi profit/loss their weight Wi. A bag is given with capacity W that can be used to carry some objects such that the total sum of object weights W and sum of profit in the bag is maximized or sum of loss in the bag is minimized.
@@ -11,21 +120,18 @@ We will try Knapsack when these combinations are given:
* and capacity will be given
---
-### Problem 1 Fractional Knapsack
+## Problem 1 Fractional Knapsack
+### Problem Statement
Given N cakes with their happiness and weight. Find maximum total happiness that can be kept in a bag with capacity = W (cakes can be divided)
-**Example**:
+### Example:
N = 5; W = 40
Happiness of the 5 cakes = [3, 8, 10, 2, 5]
Weight of the 5 cakes = [10, 4, 20, 8, 15]
Goal - happiness should be maximum possible and the total sum of weights should be <= 40.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-**Approach**
+### Approach
**`Since we can divide the objects, hence they can be picked based on their value per unit weight.`**
@@ -39,7 +145,7 @@ Please take some time to think about the solution approach on your own before re
 -**Solution**
+### Solution
**`Arrange the cakes in descending order with respect to happiness/weight and start picking the element`**
* Select the 2nd cake (happiness = 2), reducing capacity to 36(40-4).
@@ -52,61 +158,81 @@ Please take some time to think about the solution approach on your own before re
**Space complexity** of the above solution is O(1).*
-#### Pseudo Code
-```cpp
-public class Solution {
- class Items {
- double cost;
- int weight, value, ind;
- Items(int weight, int value, double cost) {
- this.weight = weight;
- this.value = value;
- this.cost = cost;
- }
+### Pseudo Code
+```cpp=
+
+class Items {
+ declare cost, weight, value, ind;
+ constructor Items(weight, value, cost){
+ this.weight = weight;
+ this.value = value;
+ this.cost = cost;
}
+}
- public int solve(int[] A, int[] B, int C) {
- Items[] iVal = new Items[A.length];
- for (int i = 0; i < A.length; i++) {
- double cost = (A[i] * 1.0) / B[i];
- iVal[i] = new Items(B[i], A[i], cost);
- }
- Arrays.sort(iVal, new Comparator < Items > () {
- @Override
- public int compare(Items o1, Items o2) {
- if (o1.cost >= o2.cost) {
- return -1;
- }
- return 1;
- }
- });
- double totalValue = 0.0;
- for (int i = 0; i < A.length; i++) {
- int curWt = iVal[i].weight;
- int curVal = iVal[i].value;
- if (C >= curWt) {
- C = C - curWt;
- totalValue += curVal;
- } else {
- totalValue += (C * iVal[i].cost);
- break;
+function solve(A[], B[], C) {
+ iVal = new array of Items of size A.length;
+ for (i -> 0 to A.length - 1) {
+ cost = (A[i]*1.0) / B[i];
+ iVal[i] = Items(B[i], A[i], cost);
+ }
+ sort(iVal, on comparision logic compare(Items o1, Items o2){
+ if(o1.cost >= o2.cost){
+ place o1 first ;
+ }else {
+ place o2 first ;
}
+
+ }
+ });
+
+ totalValue = 0.0;
+ for (i -> 0 to A.length - 1) {
+ curWt = iVal[i].weight;
+ curVal = iVal[i].value;
+ if (C >= curWt) {
+ C = C - curWt;
+ totalValue += curVal;
}
+ else {
+ totalValue += (C * iVal[i].cost);
+ break;
+ }
+ }
- return (int)(totalValue * 100);
+ return (totalValue * 100);
- }
}
+
+
```
----
+
### Flipkart's Upcoming Special Promotional Event
+Flipkart is organizing a **`promotional event`** where they aim to craft an exclusive "**`combo offer`**" that **`maximizes customer satisfaction`**. This combo will be composed of various items selected based on their **`customer reviews`**.
+
+The challenge lies in ensuring that the combined cost of these selected items does not exceed a set budget for the combo. T*he goal is to strategically pick items that together deliver the greatest value and satisfaction to customers while adhering to the predefined price limit*.
+
+**Example:**
+Let’s say Flipkart has a budget of $100 for a promotional combo offer. They analyze various items like headphones, books, and kitchen gadgets, each with customer ratings and individual prices:
+
+**`Headphones`**: price: **$60**, rating: **9/10**.
+**`Book`**: price: **$20**, rating: **7/10**.
+**`Kitchen Gadget`**: price: **$45**, rating: **8/10**.
-Flipkart is planning a special promotional event where they need to create an exclusive combo offer. The goal is to create a combination of individual items that together offer the highest possible level of customer satisfaction (indicating its popularity and customer ratings) while ensuring the total cost of the items in the combo does not exceed a predefined combo price.
+***They could choose the following combos:***
+
+Combo 1: Headphones + Book = $80 (total satisfaction: 9 + 7 = 16)
+Combo 2: Headphones + Kitchen Gadget = $105 (over the budget)
+Combo 3: Book + Kitchen Gadget = $65 (total satisfaction: 7 + 8 = 15)
+
+The best choice under the budget with the highest satisfaction score is Combo 1, consisting of the headphones and the book, offering a combined satisfaction rating of 16, and costing $80, which is under the $100 budget.
+
+This is the real life example of a problem that we are about to study.
---
-### Problem 2 : 0-1 Knapsack
+## Problem 2 0-1 Knapsack
## 0-1 Knapsack
In this type of knapsack question, **division of object is not allowed.**
@@ -116,10 +242,11 @@ In this type of knapsack question, **division of object is not allowed.**
Given N toys with their happiness and weight. Find maximum total happiness that can be kept in a bag with capacity W. Division of toys are not allowed.
---
+
### Question
In the Fractional Knapsack problem, what is the key difference compared to the 0/1 Knapsack?
-**Choices**
+### Choices
- [ ] Items can only be fully included or excluded.
- [x] Items can be partially included, allowing fractions.
- [ ] The knapsack has infinite capacity.
@@ -127,28 +254,27 @@ In the Fractional Knapsack problem, what is the key difference compared to the 0
-**Explanation**
+### Explanation
In the Fractional Knapsack problem, items can be included in fractions, enabling optimization of the total value based on weight.
-**Example**:
+---
+## 0-1 Knapsack Example
+
+### Example:
N = 4; W = 7
Happiness of the 4 toys = [4, 1, 5, 7]
Weight of the 4 toys = [3, 2, 4, 5]
> If we buy toys based on maximum happiness or maximum happiness/weight we may not get the best possible answer.
-:::warning
-Please take some time to think about the bruteforce approach on your own before reading further.....
-:::
-
-#### Brute Force Approach:
+### Brute Force Approach:
* Consider all subsets of items and select the one with highest summation of happiness.
Since there are in total 2^N^ subsequences and we have to consider each of them. Therefore the time complexity is:
-**Solution**
+### Solution
**`Arrange the cakes in descending order with respect to happiness/weight and start picking the element`**
* Select the 2nd cake (happiness = 2), reducing capacity to 36(40-4).
@@ -52,61 +158,81 @@ Please take some time to think about the solution approach on your own before re
**Space complexity** of the above solution is O(1).*
-#### Pseudo Code
-```cpp
-public class Solution {
- class Items {
- double cost;
- int weight, value, ind;
- Items(int weight, int value, double cost) {
- this.weight = weight;
- this.value = value;
- this.cost = cost;
- }
+### Pseudo Code
+```cpp=
+
+class Items {
+ declare cost, weight, value, ind;
+ constructor Items(weight, value, cost){
+ this.weight = weight;
+ this.value = value;
+ this.cost = cost;
}
+}
- public int solve(int[] A, int[] B, int C) {
- Items[] iVal = new Items[A.length];
- for (int i = 0; i < A.length; i++) {
- double cost = (A[i] * 1.0) / B[i];
- iVal[i] = new Items(B[i], A[i], cost);
- }
- Arrays.sort(iVal, new Comparator < Items > () {
- @Override
- public int compare(Items o1, Items o2) {
- if (o1.cost >= o2.cost) {
- return -1;
- }
- return 1;
- }
- });
- double totalValue = 0.0;
- for (int i = 0; i < A.length; i++) {
- int curWt = iVal[i].weight;
- int curVal = iVal[i].value;
- if (C >= curWt) {
- C = C - curWt;
- totalValue += curVal;
- } else {
- totalValue += (C * iVal[i].cost);
- break;
+function solve(A[], B[], C) {
+ iVal = new array of Items of size A.length;
+ for (i -> 0 to A.length - 1) {
+ cost = (A[i]*1.0) / B[i];
+ iVal[i] = Items(B[i], A[i], cost);
+ }
+ sort(iVal, on comparision logic compare(Items o1, Items o2){
+ if(o1.cost >= o2.cost){
+ place o1 first ;
+ }else {
+ place o2 first ;
}
+
+ }
+ });
+
+ totalValue = 0.0;
+ for (i -> 0 to A.length - 1) {
+ curWt = iVal[i].weight;
+ curVal = iVal[i].value;
+ if (C >= curWt) {
+ C = C - curWt;
+ totalValue += curVal;
}
+ else {
+ totalValue += (C * iVal[i].cost);
+ break;
+ }
+ }
- return (int)(totalValue * 100);
+ return (totalValue * 100);
- }
}
+
+
```
----
+
### Flipkart's Upcoming Special Promotional Event
+Flipkart is organizing a **`promotional event`** where they aim to craft an exclusive "**`combo offer`**" that **`maximizes customer satisfaction`**. This combo will be composed of various items selected based on their **`customer reviews`**.
+
+The challenge lies in ensuring that the combined cost of these selected items does not exceed a set budget for the combo. T*he goal is to strategically pick items that together deliver the greatest value and satisfaction to customers while adhering to the predefined price limit*.
+
+**Example:**
+Let’s say Flipkart has a budget of $100 for a promotional combo offer. They analyze various items like headphones, books, and kitchen gadgets, each with customer ratings and individual prices:
+
+**`Headphones`**: price: **$60**, rating: **9/10**.
+**`Book`**: price: **$20**, rating: **7/10**.
+**`Kitchen Gadget`**: price: **$45**, rating: **8/10**.
-Flipkart is planning a special promotional event where they need to create an exclusive combo offer. The goal is to create a combination of individual items that together offer the highest possible level of customer satisfaction (indicating its popularity and customer ratings) while ensuring the total cost of the items in the combo does not exceed a predefined combo price.
+***They could choose the following combos:***
+
+Combo 1: Headphones + Book = $80 (total satisfaction: 9 + 7 = 16)
+Combo 2: Headphones + Kitchen Gadget = $105 (over the budget)
+Combo 3: Book + Kitchen Gadget = $65 (total satisfaction: 7 + 8 = 15)
+
+The best choice under the budget with the highest satisfaction score is Combo 1, consisting of the headphones and the book, offering a combined satisfaction rating of 16, and costing $80, which is under the $100 budget.
+
+This is the real life example of a problem that we are about to study.
---
-### Problem 2 : 0-1 Knapsack
+## Problem 2 0-1 Knapsack
## 0-1 Knapsack
In this type of knapsack question, **division of object is not allowed.**
@@ -116,10 +242,11 @@ In this type of knapsack question, **division of object is not allowed.**
Given N toys with their happiness and weight. Find maximum total happiness that can be kept in a bag with capacity W. Division of toys are not allowed.
---
+
### Question
In the Fractional Knapsack problem, what is the key difference compared to the 0/1 Knapsack?
-**Choices**
+### Choices
- [ ] Items can only be fully included or excluded.
- [x] Items can be partially included, allowing fractions.
- [ ] The knapsack has infinite capacity.
@@ -127,28 +254,27 @@ In the Fractional Knapsack problem, what is the key difference compared to the 0
-**Explanation**
+### Explanation
In the Fractional Knapsack problem, items can be included in fractions, enabling optimization of the total value based on weight.
-**Example**:
+---
+## 0-1 Knapsack Example
+
+### Example:
N = 4; W = 7
Happiness of the 4 toys = [4, 1, 5, 7]
Weight of the 4 toys = [3, 2, 4, 5]
> If we buy toys based on maximum happiness or maximum happiness/weight we may not get the best possible answer.
-:::warning
-Please take some time to think about the bruteforce approach on your own before reading further.....
-:::
-
-#### Brute Force Approach:
+### Brute Force Approach:
* Consider all subsets of items and select the one with highest summation of happiness.
Since there are in total 2^N^ subsequences and we have to consider each of them. Therefore the time complexity is:  -#### Dry Run of Brute Force Apporach
+### Dry Run of Brute Force Apporach
-#### Dry Run of Brute Force Apporach
+### Dry Run of Brute Force Apporach
 @@ -167,23 +293,23 @@ dp[N][W] = max happiness (considering N objects and capacity W)
> Here taking N = i and W = j, we have two choices either to select dp[i][j] or to reject it. On selecting it will result into` h[i] + dp[i - 1][j - wt[i]]`(h[i]=happiness of i) and on rejecting it will be `dp[i - 1][j]`.
-#### Base Case
+### Base Case
* for all j when i = 0, dp[0][j] = 0
* for all i when j = 0, dp[i][0] = 0
-#### Psuedocode
+### Psuedocode
```java
//for all i,j dp[i][j]=0
-for (i--> 1 to N) { // 1based index for input
- for (j--> 1 to W) {
- if (wt[i] <= j) {
- dp[i][j] = max(dp[i - 1][j], h[i] + dp(i - 1)(j - wt[i]))
- } else {
- dp[i][j] = dp[i - 1][j]
+for(i --> 1 to N){ // 1based index for input
+ for(j--> 1 to W){
+ if(wt[i] <= j){
+ dp[i][j] = max(dp[i - 1][j], h[i] + dp(i - 1)(j - wt[i]))
+ }else{
+ dp[i][j] = dp[i - 1][j]
+ }
}
}
-}
return dp[N][w]
}
```
@@ -191,7 +317,7 @@ return dp[N][w]
The dimensions should be (N + 1) * (W + 1) as the final answer would be at dp[N][W]
-#### Dry run
+### Dry run
taking the N = 4 and W = 7
Happiness of the 4 toys = [4, 1, 5, 7]
Weight of the 4 toys = [3, 2, 4, 5]
@@ -217,17 +343,16 @@ Similary we wil follow the above to fill the entire table.
> Space Complexity for the above code is O(N * W), we can furture optimize space complexity by using 2 rows. So the space complexity is O(2W) which can be written as O(W).
---
-### Problem 3 Unbounded Knapsack
-
+## Problem 3 Unbounded Knapsack
## Unbounded Knapsack or 0-N Knapsack
* objects cannot be divided
* same object can be selected multiple times
-#### Question
+### Question
Given N toys with their happiness and weight. Find more total happiness that can be kept in a bag with capacity W. Division of toys are not allowed and infinite toys are available.
-#### Example
+### Example
N = 3; W = 8
Happiness of the 3 toys = [2, 3, 5]
@@ -237,11 +362,40 @@ Weight of the 3 toys = [3, 4, 7]
Now here as we do not have any limitation on which toy to buy index will not matter, only capacity will matter.
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
+---
-#### Dry Run for Brute Force Appoarch
+
+### Question
+We have Weight Capacity of 100
+- Values = [1, 30]
+- Weights = [1, 50]
+
+What is the maximum value you can have?
+
+### Choices
+- [ ] 0
+- [x] 100
+- [ ] 60
+- [ ] 80
+
+
+### Explanation
+There are many ways to fill knapsack.
+
+- 2 instances of 50 unit weight item.
+- 100 instances of 1 unit weight item.
+- 1 instance of 50 unit weight item and 50
+ instances of 1 unit weight items.
+
+We get maximum value with option 2, i.e **100**
+
+
+---
+## Unbounded Knapsack Dry Run
+
+
+
+### Dry Run for Brute Force Appoarch
@@ -167,23 +293,23 @@ dp[N][W] = max happiness (considering N objects and capacity W)
> Here taking N = i and W = j, we have two choices either to select dp[i][j] or to reject it. On selecting it will result into` h[i] + dp[i - 1][j - wt[i]]`(h[i]=happiness of i) and on rejecting it will be `dp[i - 1][j]`.
-#### Base Case
+### Base Case
* for all j when i = 0, dp[0][j] = 0
* for all i when j = 0, dp[i][0] = 0
-#### Psuedocode
+### Psuedocode
```java
//for all i,j dp[i][j]=0
-for (i--> 1 to N) { // 1based index for input
- for (j--> 1 to W) {
- if (wt[i] <= j) {
- dp[i][j] = max(dp[i - 1][j], h[i] + dp(i - 1)(j - wt[i]))
- } else {
- dp[i][j] = dp[i - 1][j]
+for(i --> 1 to N){ // 1based index for input
+ for(j--> 1 to W){
+ if(wt[i] <= j){
+ dp[i][j] = max(dp[i - 1][j], h[i] + dp(i - 1)(j - wt[i]))
+ }else{
+ dp[i][j] = dp[i - 1][j]
+ }
}
}
-}
return dp[N][w]
}
```
@@ -191,7 +317,7 @@ return dp[N][w]
The dimensions should be (N + 1) * (W + 1) as the final answer would be at dp[N][W]
-#### Dry run
+### Dry run
taking the N = 4 and W = 7
Happiness of the 4 toys = [4, 1, 5, 7]
Weight of the 4 toys = [3, 2, 4, 5]
@@ -217,17 +343,16 @@ Similary we wil follow the above to fill the entire table.
> Space Complexity for the above code is O(N * W), we can furture optimize space complexity by using 2 rows. So the space complexity is O(2W) which can be written as O(W).
---
-### Problem 3 Unbounded Knapsack
-
+## Problem 3 Unbounded Knapsack
## Unbounded Knapsack or 0-N Knapsack
* objects cannot be divided
* same object can be selected multiple times
-#### Question
+### Question
Given N toys with their happiness and weight. Find more total happiness that can be kept in a bag with capacity W. Division of toys are not allowed and infinite toys are available.
-#### Example
+### Example
N = 3; W = 8
Happiness of the 3 toys = [2, 3, 5]
@@ -237,11 +362,40 @@ Weight of the 3 toys = [3, 4, 7]
Now here as we do not have any limitation on which toy to buy index will not matter, only capacity will matter.
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
+---
-#### Dry Run for Brute Force Appoarch
+
+### Question
+We have Weight Capacity of 100
+- Values = [1, 30]
+- Weights = [1, 50]
+
+What is the maximum value you can have?
+
+### Choices
+- [ ] 0
+- [x] 100
+- [ ] 60
+- [ ] 80
+
+
+### Explanation
+There are many ways to fill knapsack.
+
+- 2 instances of 50 unit weight item.
+- 100 instances of 1 unit weight item.
+- 1 instance of 50 unit weight item and 50
+ instances of 1 unit weight items.
+
+We get maximum value with option 2, i.e **100**
+
+
+---
+## Unbounded Knapsack Dry Run
+
+
+
+### Dry Run for Brute Force Appoarch
 @@ -270,43 +424,20 @@ Base case for the above question:
Equation `dp[i] = max(h[i] + dp[i - wt[j]])` for all toys j
-#### Psuedocode
+### Psuedocode
```java
for all i, dp[0] = 0
-for (i--> 1 to W) {
- for (j--> 1 to N) {
- if (wt[j] <= i)
- dp[i] = max(h[i] + dp[i - wt[j]])
+for (i --> 1 to W){
+ for(j --> 1 to N){
+ if(wt[j] <= i)
+ dp[i] = max(h[i] + dp[i - wt[j]])
}
-}
-return dp[W]
+} return dp[W]
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N * W)
**Space Complexity:** O(W)
---
-### Question
-We have Weight Capacity of 100
-- Values = {1, 30}
-- Weights = {1, 50}
-
-What is the maximum value you can have?
-
-**Choices**
-- [ ] 0
-- [x] 100
-- [ ] 60
-- [ ] 80
-
-**Explanation**
-There are many ways to fill knapsack.
-
-- 2 instances of 50 unit weight item.
-- 100 instances of 1 unit weight item.
-- 1 instance of 50 unit weight item and 50
- instances of 1 unit weight items.
-
-We get maximum value with option 2, i.e **100**
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md b/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md
index 9a07494..272a8d2 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md
@@ -1,64 +1,23 @@
-# DP 4: Applications of Knapsack
+# DSA: DP 4: Applications of Knapsack
----
-
-### Question
-Time Complexity of the unbounded 0-1 knapsack problem?
-- W : capacity of knapsack
-- N : no. of elements
-- K : Max weight of any item
-- P : max value of any item
-
-**Choices**
-Chose the correct answer
-- [x] O(NW)
-- [ ] O(NK)
-- [ ] O(NP)
-- [ ] O(WK)
-- [ ] O(WP)
-- [ ] O(KP)
-
-
-
-
-**Explanation**
-For every node, we need to go to its left, that's the only way we can reach the smallest one.
-
----
-## Introduction to the knapsack and DP
-
-### What Is Dynamic Programming?
-In the context of dynamic programming, the ``knapsack problem`` refers to a classic optimization problem that can be solved using dynamic programming techniques.
-
-### Example
-Suppose we are working on solving the fibonacci series problesm, then we can break it into step by step as follows:
-
-
@@ -270,43 +424,20 @@ Base case for the above question:
Equation `dp[i] = max(h[i] + dp[i - wt[j]])` for all toys j
-#### Psuedocode
+### Psuedocode
```java
for all i, dp[0] = 0
-for (i--> 1 to W) {
- for (j--> 1 to N) {
- if (wt[j] <= i)
- dp[i] = max(h[i] + dp[i - wt[j]])
+for (i --> 1 to W){
+ for(j --> 1 to N){
+ if(wt[j] <= i)
+ dp[i] = max(h[i] + dp[i - wt[j]])
}
-}
-return dp[W]
+} return dp[W]
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N * W)
**Space Complexity:** O(W)
---
-### Question
-We have Weight Capacity of 100
-- Values = {1, 30}
-- Weights = {1, 50}
-
-What is the maximum value you can have?
-
-**Choices**
-- [ ] 0
-- [x] 100
-- [ ] 60
-- [ ] 80
-
-**Explanation**
-There are many ways to fill knapsack.
-
-- 2 instances of 50 unit weight item.
-- 100 instances of 1 unit weight item.
-- 1 instance of 50 unit weight item and 50
- instances of 1 unit weight items.
-
-We get maximum value with option 2, i.e **100**
diff --git a/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md b/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md
index 9a07494..272a8d2 100644
--- a/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md
+++ b/Academy DSA Typed Notes/Advanced/DSA DP 4 Applications of Knapsack.md
@@ -1,64 +1,23 @@
-# DP 4: Applications of Knapsack
+# DSA: DP 4: Applications of Knapsack
----
-
-### Question
-Time Complexity of the unbounded 0-1 knapsack problem?
-- W : capacity of knapsack
-- N : no. of elements
-- K : Max weight of any item
-- P : max value of any item
-
-**Choices**
-Chose the correct answer
-- [x] O(NW)
-- [ ] O(NK)
-- [ ] O(NP)
-- [ ] O(WK)
-- [ ] O(WP)
-- [ ] O(KP)
-
-
-
-
-**Explanation**
-For every node, we need to go to its left, that's the only way we can reach the smallest one.
-
----
-## Introduction to the knapsack and DP
-
-### What Is Dynamic Programming?
-In the context of dynamic programming, the ``knapsack problem`` refers to a classic optimization problem that can be solved using dynamic programming techniques.
-
-### Example
-Suppose we are working on solving the fibonacci series problesm, then we can break it into step by step as follows:
-
- -
-Let us now solve some questions related to dynamic programming.
----
-### Problem 1 Cut the rod for maximum profit
+## Problem 1 Cuting a Rod
+### Problem Statement
A rod of length `N` and an array `A` of length `N` is given. The elements (`i`) of the array contain the length of the rod (1-based indexing). Find the maximum values that can be obtained by cutting the rod into some pieces and selling them.
-**Example**
+### Example
Suppose we have the length on `N = 5` and we have to divide it then the division can be done as:
-
-Let us now solve some questions related to dynamic programming.
----
-### Problem 1 Cut the rod for maximum profit
+## Problem 1 Cuting a Rod
+### Problem Statement
A rod of length `N` and an array `A` of length `N` is given. The elements (`i`) of the array contain the length of the rod (1-based indexing). Find the maximum values that can be obtained by cutting the rod into some pieces and selling them.
-**Example**
+### Example
Suppose we have the length on `N = 5` and we have to divide it then the division can be done as:
 Now, we can see that $9$ is the maximum value that we can get.
-#### Solution
+### Solution
A naive approach to solving this problem would involve considering all possible combinations of cutting the rod into pieces and calculating the total value for each combination. This can be achieved using recursion and backtracking, where for each possible cut, the value of the cut piece is added to the recursively calculated value of the remaining part of the rod. The maximum value obtained among all combinations is the desired result.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Our Approach
+### Our Approach
As we can visualize from the example, there is an overlapping subproblem and an optimal sub-structure. So, we should opt for the DP approach.
> **Note**: We can observe three things here:
@@ -68,94 +27,100 @@ As we can visualize from the example, there is an overlapping subproblem and an
The general observation that we can get here from these three things is that it is a knapsack problem.
---
+
+
### Question
The cutting rod question is:
-**Choices**
+### Choices
- [ ] Fractional Knapsack
- [ ] `0-1` Knapsack
- [x] Unbounded Knapsack (or `0-N` Knapsack)
---
-### Cut the rod for maximum profit Approach
+## Cut the rod for maximum profit Approach
-#### Approach
+### Approach
- First, define the state of the dp i.e. `dp[i]`, it will be the maximum value that can be received by the rod of length `i`.
- The base case will be 0 in the case when the length of the rod is 0. This means `dp[0] = 0`.
We will loop over the array, and then calculate the maximum profit, and finally store the maximum profit in the current dp state.
Let us now see the pseudo-code for the problem.
-
-#### Pseudocode
+### Pseudocode
```cpp
for all values of i: dp[i] = 0
-for (i = 1 to N) // length of rod to sell = i
+for (i = 1 to N) // length of rod to sell = i
{
- for (j = 1 to i) {
+ for (j = 1 to i)
+ {
dp[i] = max(dp[i], A[j] + dp[i - j])
}
}
return dp[N]
```
-#### Time and Space Complexity
+### Time and Space Complexity
- **Time Complexity**: $O(N^2)$, as we are traversing the N-length array using nested for loops (Simply, we can also say that the capacity is `N` and the length of the array is also `N`).
- **Space Complexity**: `O(N)`, as we are using an extra dp array to store the current state of profit.
+> **Note for the instructor**: We can do a dry run for better clarity.
---
-### Problem 2 Count the number of ways using coins (ordered selection)
-
+## Problem 2 Coin Sum Infinite [Ordered]
+### Problem Statement
In how many ways can the sum be equal to ``N`` by using coins given in the array? One coin can be used multiple times.
-**Example**
+### Example
There are 2 ways to solve this problem
a. **Ordered selection of coin**
Let us create the set of numbers that cummulate the value of `N`.
-
Now, we can see that $9$ is the maximum value that we can get.
-#### Solution
+### Solution
A naive approach to solving this problem would involve considering all possible combinations of cutting the rod into pieces and calculating the total value for each combination. This can be achieved using recursion and backtracking, where for each possible cut, the value of the cut piece is added to the recursively calculated value of the remaining part of the rod. The maximum value obtained among all combinations is the desired result.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Our Approach
+### Our Approach
As we can visualize from the example, there is an overlapping subproblem and an optimal sub-structure. So, we should opt for the DP approach.
> **Note**: We can observe three things here:
@@ -68,94 +27,100 @@ As we can visualize from the example, there is an overlapping subproblem and an
The general observation that we can get here from these three things is that it is a knapsack problem.
---
+
+
### Question
The cutting rod question is:
-**Choices**
+### Choices
- [ ] Fractional Knapsack
- [ ] `0-1` Knapsack
- [x] Unbounded Knapsack (or `0-N` Knapsack)
---
-### Cut the rod for maximum profit Approach
+## Cut the rod for maximum profit Approach
-#### Approach
+### Approach
- First, define the state of the dp i.e. `dp[i]`, it will be the maximum value that can be received by the rod of length `i`.
- The base case will be 0 in the case when the length of the rod is 0. This means `dp[0] = 0`.
We will loop over the array, and then calculate the maximum profit, and finally store the maximum profit in the current dp state.
Let us now see the pseudo-code for the problem.
-
-#### Pseudocode
+### Pseudocode
```cpp
for all values of i: dp[i] = 0
-for (i = 1 to N) // length of rod to sell = i
+for (i = 1 to N) // length of rod to sell = i
{
- for (j = 1 to i) {
+ for (j = 1 to i)
+ {
dp[i] = max(dp[i], A[j] + dp[i - j])
}
}
return dp[N]
```
-#### Time and Space Complexity
+### Time and Space Complexity
- **Time Complexity**: $O(N^2)$, as we are traversing the N-length array using nested for loops (Simply, we can also say that the capacity is `N` and the length of the array is also `N`).
- **Space Complexity**: `O(N)`, as we are using an extra dp array to store the current state of profit.
+> **Note for the instructor**: We can do a dry run for better clarity.
---
-### Problem 2 Count the number of ways using coins (ordered selection)
-
+## Problem 2 Coin Sum Infinite [Ordered]
+### Problem Statement
In how many ways can the sum be equal to ``N`` by using coins given in the array? One coin can be used multiple times.
-**Example**
+### Example
There are 2 ways to solve this problem
a. **Ordered selection of coin**
Let us create the set of numbers that cummulate the value of `N`.
- +
So, we can see that we have the value we get is $6$.
Now, let's look at the selection tree of the coin selection. We can divide the number by selecting the choices of subraction.
-
+
So, we can see that we have the value we get is $6$.
Now, let's look at the selection tree of the coin selection. We can divide the number by selecting the choices of subraction.
- +
-#### Solution - Ordered Selection of Coin
+### Solution - Ordered Selection of Coin
The naive approach to solving this problem involves using a recursive approach with backtracking. For each coin value in the array, subtract it from the target sum N, and recursively find the number of ways to form the remaining sum using the same coin set. Repeat this process for all coins and sum up the results.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach
+### Approach
As we can observe from the examples above, we have to calculate the number of ways of selection, it is similar to the unbounded knapsack problem (as one coin can be selected multiple times).
---
+
+
### Question
What is the number of ways to get `sum = 0`
-**Choices**
+### Choices
- [ ] 0
- [x] 1
- [ ] 2
- [ ] Undefined
---
-### Count the number of ways using coins Pseudocode
-#### Pseudocode
+
+## Count the number of ways using coins Pseudocode
+
+### Pseudocode
```cpp
for all values of i: dp[i] = 0
dp[0] = 1
-for (i = 1 to N) {
- for (j = 1 to(A.length - 1)) {
- if (A[j] <= i) {
+for (i -> 1 to N)
+{
+ for (j -> 1 to (A.length - 1))
+ {
+ if (A[j] <= i)
+ {
dp[i] += dp[i - A[j]]
}
}
@@ -165,17 +130,17 @@ return dp[N]
```
-#### Time and Space Complexity
+### Time and Space Complexity
- **Time Complexity**: $O(N * (length~ of ~the ~array))$.
- **Space Complexity**: $O(N)$.
---
-### Problem 3 Count the number of ways using coins (un-ordered selection)
-
+## Problem 3 Coin Sum Infinite [Unordered]
+### Problem Statement
Given a set of coins and a target sum, find the number of ways to make the target sum using the coins, where each coin can only be used once.
-**Example**
+### Example
Suppose we have a situation same as the last one.
N = 5 and coins we have [3, 1, 4].
@@ -189,11 +154,7 @@ Now, let us try to arrage the coins to get the desired value.
So, what we can observe out of it is:
- The current state of dp, i.e. `dp[i]` is to select the number of ways to get the sum equal to i by selecting coins from L to R in the array.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Solution: Un-ordered Selection of Coin
+### Solution: Un-ordered Selection of Coin
How we can solve it:
- Initialize an array dp with all values set to 0. This array will be used to store the number of ways to make change for each possible sum from 0 to N.
- Set the initial value of `dp[0]` to 1. This step indicates that there is one way to make change for an amount of 0, which is by not using any coins.
@@ -205,16 +166,17 @@ How we can solve it:
- Finally, return the value stored in `dp[N]`.
-#### Pseudocode
+### Pseudocode
```cpp
-for all values of i: dp[i] = 0
+for all values of i:dp[i] = 0
dp[0] = 1
-for (j = 0 to(A.length - 1)) // coins
+for (j = 0 to (A.length - 1)) // coins
{
- for (i = 1 to N) // sum
+ for (i = 1 to N) // sum
{
- if (A[j] <= i) {
+ if (A[j] <= i)
+ {
dp[i] += dp[i - A[j]]
}
}
@@ -224,15 +186,17 @@ return dp[N]
```
-#### Time and Space Complexity
+### Time and Space Complexity
- **Time Complexity**: $O(N * (length~ of~ the~ array))$.
- **Space Complexity**: `O(N)`.
+
---
-### Problem 4 Extended 0-1 Knapsack Problem
+## Problem 4 Extended 0-1 Knapsack Problem
+### Problem Statement
We are given `N` toys with their happiness and weight. Find max total happiness that can be kept in a bag with the capacity `W`. Here, we cannot divide the toys.
The constraints are:
@@ -243,6 +207,9 @@ $- 1 <= W <= 10^9$
---
+
+
+
### Question
What is the MAX value we can get for these items i.e. (weight, value) pairs in 0-1 knapsack of capacity W = 8.
Items = [(3, 12), (6, 20), (5, 15), (2, 6), (4, 10)]
@@ -250,25 +217,32 @@ Items = [(3, 12), (6, 20), (5, 15), (2, 6), (4, 10)]
Chose the correct answer
-**Choices**
+### Choices
- [x] 27
- [ ] 28
- [ ] 29
- [ ] 30
-**Explanation**
+
+
+
+### Explanation
Simple 0-1 Knapsack, after trying all combinations 27 is the highest value we can have inside the knapsack.
---
-### Extended 0-1 Knapsack Problem Approach and Explanation
+## Extended 0-1 Knapsack Problem Approach and Explanation
-#### Approach and Calculations
+### Approach and Calculations
-
+
-#### Solution - Ordered Selection of Coin
+### Solution - Ordered Selection of Coin
The naive approach to solving this problem involves using a recursive approach with backtracking. For each coin value in the array, subtract it from the target sum N, and recursively find the number of ways to form the remaining sum using the same coin set. Repeat this process for all coins and sum up the results.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach
+### Approach
As we can observe from the examples above, we have to calculate the number of ways of selection, it is similar to the unbounded knapsack problem (as one coin can be selected multiple times).
---
+
+
### Question
What is the number of ways to get `sum = 0`
-**Choices**
+### Choices
- [ ] 0
- [x] 1
- [ ] 2
- [ ] Undefined
---
-### Count the number of ways using coins Pseudocode
-#### Pseudocode
+
+## Count the number of ways using coins Pseudocode
+
+### Pseudocode
```cpp
for all values of i: dp[i] = 0
dp[0] = 1
-for (i = 1 to N) {
- for (j = 1 to(A.length - 1)) {
- if (A[j] <= i) {
+for (i -> 1 to N)
+{
+ for (j -> 1 to (A.length - 1))
+ {
+ if (A[j] <= i)
+ {
dp[i] += dp[i - A[j]]
}
}
@@ -165,17 +130,17 @@ return dp[N]
```
-#### Time and Space Complexity
+### Time and Space Complexity
- **Time Complexity**: $O(N * (length~ of ~the ~array))$.
- **Space Complexity**: $O(N)$.
---
-### Problem 3 Count the number of ways using coins (un-ordered selection)
-
+## Problem 3 Coin Sum Infinite [Unordered]
+### Problem Statement
Given a set of coins and a target sum, find the number of ways to make the target sum using the coins, where each coin can only be used once.
-**Example**
+### Example
Suppose we have a situation same as the last one.
N = 5 and coins we have [3, 1, 4].
@@ -189,11 +154,7 @@ Now, let us try to arrage the coins to get the desired value.
So, what we can observe out of it is:
- The current state of dp, i.e. `dp[i]` is to select the number of ways to get the sum equal to i by selecting coins from L to R in the array.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Solution: Un-ordered Selection of Coin
+### Solution: Un-ordered Selection of Coin
How we can solve it:
- Initialize an array dp with all values set to 0. This array will be used to store the number of ways to make change for each possible sum from 0 to N.
- Set the initial value of `dp[0]` to 1. This step indicates that there is one way to make change for an amount of 0, which is by not using any coins.
@@ -205,16 +166,17 @@ How we can solve it:
- Finally, return the value stored in `dp[N]`.
-#### Pseudocode
+### Pseudocode
```cpp
-for all values of i: dp[i] = 0
+for all values of i:dp[i] = 0
dp[0] = 1
-for (j = 0 to(A.length - 1)) // coins
+for (j = 0 to (A.length - 1)) // coins
{
- for (i = 1 to N) // sum
+ for (i = 1 to N) // sum
{
- if (A[j] <= i) {
+ if (A[j] <= i)
+ {
dp[i] += dp[i - A[j]]
}
}
@@ -224,15 +186,17 @@ return dp[N]
```
-#### Time and Space Complexity
+### Time and Space Complexity
- **Time Complexity**: $O(N * (length~ of~ the~ array))$.
- **Space Complexity**: `O(N)`.
+
---
-### Problem 4 Extended 0-1 Knapsack Problem
+## Problem 4 Extended 0-1 Knapsack Problem
+### Problem Statement
We are given `N` toys with their happiness and weight. Find max total happiness that can be kept in a bag with the capacity `W`. Here, we cannot divide the toys.
The constraints are:
@@ -243,6 +207,9 @@ $- 1 <= W <= 10^9$
---
+
+
+
### Question
What is the MAX value we can get for these items i.e. (weight, value) pairs in 0-1 knapsack of capacity W = 8.
Items = [(3, 12), (6, 20), (5, 15), (2, 6), (4, 10)]
@@ -250,25 +217,32 @@ Items = [(3, 12), (6, 20), (5, 15), (2, 6), (4, 10)]
Chose the correct answer
-**Choices**
+### Choices
- [x] 27
- [ ] 28
- [ ] 29
- [ ] 30
-**Explanation**
+
+
+
+### Explanation
Simple 0-1 Knapsack, after trying all combinations 27 is the highest value we can have inside the knapsack.
---
-### Extended 0-1 Knapsack Problem Approach and Explanation
+## Extended 0-1 Knapsack Problem Approach and Explanation
-#### Approach and Calculations
+### Approach and Calculations
- +
The normal approach to solve this problem would involve using a recursive or iterative algorithm to consider all possible combinations of toys and select the one with the maximum happiness that doesn't exceed the weight limit. However, due to the constraints provided (N up to 500, `wt[i]` up to $10^9$, ``W`` up to $10^9$), this approach would be extremely slow and inefficient.
By employing dynamic programming, we can optimize the solution significantly. The DP approach allows us to break down the problem into subproblems and store the results of these subproblems in a table to avoid redundant calculations. In this case, we can use a 2-D DP table where `dp[i][w]` represents the maximum happiness that can be achieved with the first `i` toys and a weight constraint of `w`.
DP offers a much faster solution, as it reduces the time complexity from exponential to polynomial time, making it suitable for large inputs like those in the given constraints. Therefore, opting for a DP approach is essential to meet the time and pace constraints of this problem.
+
+
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md b/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
index 0b5fa6d..102d31c 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
@@ -1,6 +1,5 @@
-# Graphs 1: Introduction with BFS & DFS
+# Graphs 1: Introduction, DFS & Cycle Detection
----
## Graphs Introduction
### Introduction
@@ -20,9 +19,7 @@ Some real life examples of Graph -
+
The normal approach to solve this problem would involve using a recursive or iterative algorithm to consider all possible combinations of toys and select the one with the maximum happiness that doesn't exceed the weight limit. However, due to the constraints provided (N up to 500, `wt[i]` up to $10^9$, ``W`` up to $10^9$), this approach would be extremely slow and inefficient.
By employing dynamic programming, we can optimize the solution significantly. The DP approach allows us to break down the problem into subproblems and store the results of these subproblems in a table to avoid redundant calculations. In this case, we can use a 2-D DP table where `dp[i][w]` represents the maximum happiness that can be achieved with the first `i` toys and a weight constraint of `w`.
DP offers a much faster solution, as it reduces the time complexity from exponential to polynomial time, making it suitable for large inputs like those in the given constraints. Therefore, opting for a DP approach is essential to meet the time and pace constraints of this problem.
+
+
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md b/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
index 0b5fa6d..102d31c 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
@@ -1,6 +1,5 @@
-# Graphs 1: Introduction with BFS & DFS
+# Graphs 1: Introduction, DFS & Cycle Detection
----
## Graphs Introduction
### Introduction
@@ -20,9 +19,7 @@ Some real life examples of Graph -
 ----
-### Types of Graph
-
+## Types of Graph
### Cyclic Graph
@@ -130,11 +127,7 @@ A -- B
D -- C
```
-
-
----
-### How to store a graph
-
+## How to store a graph
### Graph:
@@ -151,10 +144,10 @@ In adjacency matrix, `mat[i][j] = 1`, if there is an edge between them else it w
#### Pseudocode:
```cpp
-int N, M
-int mat[N+1][M+1] = {0}
+declare N, M
+declare 2D matrix with all values 0 -> mat[N+1][M+1]
-for(int i=0; i < A.size(); i++) {
+for(i -> 0 to A.size - 1) {
u = A[i][0];
v = A[i][1];
@@ -190,22 +183,20 @@ Stores the list of nodes connected corresponding to every node.
We can create map of
----
-### Types of Graph
-
+## Types of Graph
### Cyclic Graph
@@ -130,11 +127,7 @@ A -- B
D -- C
```
-
-
----
-### How to store a graph
-
+## How to store a graph
### Graph:
@@ -151,10 +144,10 @@ In adjacency matrix, `mat[i][j] = 1`, if there is an edge between them else it w
#### Pseudocode:
```cpp
-int N, M
-int mat[N+1][M+1] = {0}
+declare N, M
+declare 2D matrix with all values 0 -> mat[N+1][M+1]
-for(int i=0; i < A.size(); i++) {
+for(i -> 0 to A.size - 1) {
u = A[i][0];
v = A[i][1];
@@ -190,22 +183,20 @@ Stores the list of nodes connected corresponding to every node.
We can create map of  +
+
---
+
+
### Question
Time Complexity for DFS?
-**Choices**
+### Choices
- [x] O(V + E)
- [ ] O(V)
- [ ] O(2E)
-**Explanation**:
+
+
+### Explanation:
The time complexity of the DFS algorithm is O(V + E), where V is the number of vertices (nodes) in the graph, and E is the number of edges. This is because, in the worst case, the algorithm visits each vertex once and each edge once.
@@ -340,11 +338,12 @@ The time complexity of the DFS algorithm is O(V + E), where V is the number of v
---
-### Problem 1 Detecting Cycles in a Directed Graph
+## Problem 1 Detecting Cycles in a Directed Graph
+### Problem Statement
Check if given graph has a cycle?
-**Examples**
+### Examples
1)
+
+
---
+
+
### Question
Time Complexity for DFS?
-**Choices**
+### Choices
- [x] O(V + E)
- [ ] O(V)
- [ ] O(2E)
-**Explanation**:
+
+
+### Explanation:
The time complexity of the DFS algorithm is O(V + E), where V is the number of vertices (nodes) in the graph, and E is the number of edges. This is because, in the worst case, the algorithm visits each vertex once and each edge once.
@@ -340,11 +338,12 @@ The time complexity of the DFS algorithm is O(V + E), where V is the number of v
---
-### Problem 1 Detecting Cycles in a Directed Graph
+## Problem 1 Detecting Cycles in a Directed Graph
+### Problem Statement
Check if given graph has a cycle?
-**Examples**
+### Examples
1)
 @@ -353,11 +352,13 @@ Check if given graph has a cycle?
@@ -353,11 +352,13 @@ Check if given graph has a cycle?
 -:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+
+**Counter Example:** It is not true, because we can come to a visited node via some other path
+For eg, in Example 2, start at 0 -> 1 -> 3, now we can't go anywhere, backtrack to 1->2, then via 2 we'll find 3 which is already visited but there's no cycle in the graph.
+
+
+### Approach
Apply DFS, if a node in current path is encountered again, it means cycle is present!
With this, we will have to keep track of the path.
@@ -380,120 +381,31 @@ path[] = {0, 1, 2, 3}
Now, from 3, we come back to 1.
path[] = {0, 1, 2, 3, 1} ***[But 1 is already a part of that path, which means cycle is present]***
-#### Pseudocode
+### Pseudocode
```javascript
-list < int > graph[] //filled
-bool visited[] = {0}
-int path[N] = {0}
+list
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+
+**Counter Example:** It is not true, because we can come to a visited node via some other path
+For eg, in Example 2, start at 0 -> 1 -> 3, now we can't go anywhere, backtrack to 1->2, then via 2 we'll find 3 which is already visited but there's no cycle in the graph.
+
+
+### Approach
Apply DFS, if a node in current path is encountered again, it means cycle is present!
With this, we will have to keep track of the path.
@@ -380,120 +381,31 @@ path[] = {0, 1, 2, 3}
Now, from 3, we come back to 1.
path[] = {0, 1, 2, 3, 1} ***[But 1 is already a part of that path, which means cycle is present]***
-#### Pseudocode
+### Pseudocode
```javascript
-list < int > graph[] //filled
-bool visited[] = {0}
-int path[N] = {0}
+list -
-In this case we can see that our answer is 5.
-
-**Que: Do we need adjacency list ?**
-Ans: No, since the information is already present in form of matrix which can be utilised as it is.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach:
-
-**Set a Counter:** Start with a counter at zero for tracking island count.
-
-**Scan the Grid:** Go through each cell in the grid.
-
-**Search for Islands:** When you find a land cell ('1'), use either BFS or DFS to explore all connected land cells.
-
-**Mark Visited Cells:** Change each visited '1' to '0' during the search to avoid recounting.
-
-**Count Each Island:** Increase the counter by 1 for every complete search that identifies a new island.
-
-**Finish the Search:** Continue until all grid cells are checked.
-
-**Result:** The counter will indicate the total number of islands.
-
-
---
-### Number of Islands Dry Run and Pseudocode
-
-#### Dry-Run:
-```java
-[
- ['1', '1', '0', '0', '0'],
- ['1', '1', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '1', '1']
-]
-```
-
-* Initialize variable islands = 0.
-* Start iterating through the grid:
-* At grid[0][0], we find '1'. Increment islands to 1 and call visitIsland(grid, 0, 0).
-* visitIsland will mark all connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
-
-
-```cpp-
-[
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '1', '0', '0'],
- ['0', '0', '0', '1', '1']
-]
-```
-* Continue iterating through the grid:
-* At grid[2][2], we find '1'. Increment islands to 2 and call visitIsland(grid, 2, 2).
-* visitIsland will mark connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
-```java
-[
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '1', '1']
-]
-```
-* Continue the iteration.
-* At grid[3][3], we find '1'. Increment islands to 3 and call visitIsland(grid, 3, 3).
-
-We can visit only 4 coordinates, considering them to be i, j; it means we can visit **(i,j-1), (i-1, j), (i, j+1), (i+1, j)**
-
-
-
-In this case we can see that our answer is 5.
-
-**Que: Do we need adjacency list ?**
-Ans: No, since the information is already present in form of matrix which can be utilised as it is.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach:
-
-**Set a Counter:** Start with a counter at zero for tracking island count.
-
-**Scan the Grid:** Go through each cell in the grid.
-
-**Search for Islands:** When you find a land cell ('1'), use either BFS or DFS to explore all connected land cells.
-
-**Mark Visited Cells:** Change each visited '1' to '0' during the search to avoid recounting.
-
-**Count Each Island:** Increase the counter by 1 for every complete search that identifies a new island.
-
-**Finish the Search:** Continue until all grid cells are checked.
-
-**Result:** The counter will indicate the total number of islands.
-
-
---
-### Number of Islands Dry Run and Pseudocode
-
-#### Dry-Run:
-```java
-[
- ['1', '1', '0', '0', '0'],
- ['1', '1', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '1', '1']
-]
-```
-
-* Initialize variable islands = 0.
-* Start iterating through the grid:
-* At grid[0][0], we find '1'. Increment islands to 1 and call visitIsland(grid, 0, 0).
-* visitIsland will mark all connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
-
-
-```cpp-
-[
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '1', '0', '0'],
- ['0', '0', '0', '1', '1']
-]
-```
-* Continue iterating through the grid:
-* At grid[2][2], we find '1'. Increment islands to 2 and call visitIsland(grid, 2, 2).
-* visitIsland will mark connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
-```java
-[
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '0', '0'],
- ['0', '0', '0', '1', '1']
-]
-```
-* Continue the iteration.
-* At grid[3][3], we find '1'. Increment islands to 3 and call visitIsland(grid, 3, 3).
-
-We can visit only 4 coordinates, considering them to be i, j; it means we can visit **(i,j-1), (i-1, j), (i, j+1), (i+1, j)**
-
- -
-#### Pseudocode
-
-
-
-#### Pseudocode
-
- -
-
-
- -
-
-
- diff --git a/Academy DSA Typed Notes/Advanced/DSA Graphs 2 BFS & Matrix Questions.md b/Academy DSA Typed Notes/Advanced/DSA Graphs 2 BFS & Matrix Questions.md
new file mode 100644
index 0000000..aa43ddd
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Graphs 2 BFS & Matrix Questions.md
@@ -0,0 +1,399 @@
+# DSA: Graphs 2: BFS & Matrix Questions
+
+
+
+### BFS
+Breadth-First Search (BFS) is another graph traversal algorithm used to explore and navigate graphs or trees. It starts at a source node and explores all its neighbors at the current depth level before moving on to the next level. BFS uses a queue data structure to maintain the order of nodes to be visited.
+
+### Approach:
+* We use a queue to maintain the order of nodes to visit in a breadth-first manner.
+* We start with a vector visited to keep track of whether each node has been visited. Initially, all nodes are marked as unvisited (false).
+* We enqueue the startNode into the queue and mark it as visited.
+* We enter a loop that continues until the queue is empty.
+* In each iteration, we dequeue the front element (the current node) from the queue and process it. Processing can include printing the node or performing any other desired operation.
+* We then iterate through the neighbors of the current node. For each neighbor that hasn't been visited, we enqueue it into the queue and mark it as visited.
+* The BFS traversal continues until the queue is empty, visiting nodes level by level.
+
+
+### Example/Dry-Run
+```javascript
+ A --- B --- C
+ | |
+ +-----------+
+ |
+ D
+```
+Suppose in this if we want to perform BFS then:
+
+* Start from the source node (City A).
+* Explore neighboring nodes level by level.
+* Use a queue to maintain the order.
+* Mark visited nodes (using adjaency list) to avoid repetition.
+* Stop when the target node (City D) is reached.
+* This guarantees the shortest path in unweighted graphs.
+
+
+### Pseudocode:
+```javascript
+function bfs(startNode) {
+ declare visited array of size MAX_NODES with all values initially false); // Initialize all nodes as unvisited
+
+ declare queue
diff --git a/Academy DSA Typed Notes/Advanced/DSA Graphs 2 BFS & Matrix Questions.md b/Academy DSA Typed Notes/Advanced/DSA Graphs 2 BFS & Matrix Questions.md
new file mode 100644
index 0000000..aa43ddd
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Graphs 2 BFS & Matrix Questions.md
@@ -0,0 +1,399 @@
+# DSA: Graphs 2: BFS & Matrix Questions
+
+
+
+### BFS
+Breadth-First Search (BFS) is another graph traversal algorithm used to explore and navigate graphs or trees. It starts at a source node and explores all its neighbors at the current depth level before moving on to the next level. BFS uses a queue data structure to maintain the order of nodes to be visited.
+
+### Approach:
+* We use a queue to maintain the order of nodes to visit in a breadth-first manner.
+* We start with a vector visited to keep track of whether each node has been visited. Initially, all nodes are marked as unvisited (false).
+* We enqueue the startNode into the queue and mark it as visited.
+* We enter a loop that continues until the queue is empty.
+* In each iteration, we dequeue the front element (the current node) from the queue and process it. Processing can include printing the node or performing any other desired operation.
+* We then iterate through the neighbors of the current node. For each neighbor that hasn't been visited, we enqueue it into the queue and mark it as visited.
+* The BFS traversal continues until the queue is empty, visiting nodes level by level.
+
+
+### Example/Dry-Run
+```javascript
+ A --- B --- C
+ | |
+ +-----------+
+ |
+ D
+```
+Suppose in this if we want to perform BFS then:
+
+* Start from the source node (City A).
+* Explore neighboring nodes level by level.
+* Use a queue to maintain the order.
+* Mark visited nodes (using adjaency list) to avoid repetition.
+* Stop when the target node (City D) is reached.
+* This guarantees the shortest path in unweighted graphs.
+
+
+### Pseudocode:
+```javascript
+function bfs(startNode) {
+ declare visited array of size MAX_NODES with all values initially false); // Initialize all nodes as unvisited
+
+ declare queue +
+
+
+BFS (Breadth-First Search) explores neighbor nodes first before moving to the next level. Starting from node 0, BFS visits its neighbors 1 and 2. It then moves to the next level and visits 1's neighbor 3. Finally, it moves to the next level but finds no more unvisited nodes. Therefore, the order of BFS traversal is 0, 1, 2, 3.
+
+## Multisource BFS
+
+#### Problem
+There are N number of nodes and multisource(S1,S2,S3), we need to find the length of shortest path for given destination node to any one of the source node{S1,S2,S3}.
+
+
+
+
+
+BFS (Breadth-First Search) explores neighbor nodes first before moving to the next level. Starting from node 0, BFS visits its neighbors 1 and 2. It then moves to the next level and visits 1's neighbor 3. Finally, it moves to the next level but finds no more unvisited nodes. Therefore, the order of BFS traversal is 0, 1, 2, 3.
+
+## Multisource BFS
+
+#### Problem
+There are N number of nodes and multisource(S1,S2,S3), we need to find the length of shortest path for given destination node to any one of the source node{S1,S2,S3}.
+
+ +
+
+#### Solution
+Length = 2
+In the beginning, we need to push all source node at once and apply exact BFS,then return the distance of destination node.
+#### Time and Space Complexity
+* **TC -** O(N+E)
+* **SC -** O(N+E)
+
+---
+
+## Rotten Oranges
+
+#### Problem
+There is given a matrix and there are 3 values where 0 means empty cell, 1 means fresh orange present and 2 means rotten orange prsent, we need to find the time when all oranges will become rotten.
+**Note:** If not possible, return - 1.
+
+
+
+
+#### Solution
+Length = 2
+In the beginning, we need to push all source node at once and apply exact BFS,then return the distance of destination node.
+#### Time and Space Complexity
+* **TC -** O(N+E)
+* **SC -** O(N+E)
+
+---
+
+## Rotten Oranges
+
+#### Problem
+There is given a matrix and there are 3 values where 0 means empty cell, 1 means fresh orange present and 2 means rotten orange prsent, we need to find the time when all oranges will become rotten.
+**Note:** If not possible, return - 1.
+
+ +
+
+
+#### Solution
+
+
+
+
+
+#### Solution
+
+ +
+
+
+**Answer:** after 3 minutes all oranges will get rotten.
+* Initially, We need to insert all rotten oranges in Queue (where each element in queue is in a pair),
+* Then check if any fresh oranges has become rotten and if they did, return the time otherwise return -1.
+
+#### Pseudocode
+```java
+dx[] = {-1, 1, 0, 0};
+dy[] = {0, 0, -1, 1};
+
+function orangesRotting(grid[][]) {
+ rowCount = grid.length;
+ colCount = grid[0].length;
+ declare Queue of integer array named queue;
+
+ freshOranges = 0;
+ minutes = 0;
+
+ // Count fresh oranges and add rotten oranges to the queue
+ for (i -> 0 to rowCount - 1) {
+ for (j -> 0 to colCount - 1) {
+ if (grid[i][j] == 2) {
+ queue.push({i, j, minutes});
+ } else if (grid[i][j] == 1) {
+ freshOranges++;
+ }
+ }
+ }
+ if (freshOranges == 0) {
+ // If there are no fresh oranges initially, they are already rotten.
+ return 0;
+ }
+
+ while (not queue.isEmpty()) {
+ cell = queue.pop();
+ x = cell[0];
+ y = cell[1];
+ minutes = cell[2];
+
+ for (i -> 0 to 3 ) {
+ newX = x + dx[i];
+ newY = y + dy[i];
+
+ if (isValid(grid, newX, newY) and grid[newX][newY] == 1) {
+ grid[newX][newY] = 2;
+ freshOranges--;
+ queue.push({newX, newY, minutes + 1});
+ }
+ }
+ }
+
+ return (freshOranges == 0) ? minutes : -1;
+}
+function isValid(grid[][], x, y) {
+ rowCount = grid.length;
+ colCount = grid[0].length;
+ return x >= 0 and x < rowCount and y >= 0 and y < colCount;
+}
+```
+
+---
+
+## Problem 2 Number of Islands
+### Problem Statement
+
+You are given a 2D grid of '1's (land) and '0's (water). Your task is to determine the number of islands in the grid. An island is formed by connecting adjacent (horizontally or vertically) land cells. Diagonal connections are not considered.
+
+Given here if the cell values has 1 then there is land and 0 if it is water, and you may assume all four edges of the grid are all surrounded by water.
+
+
+
+In this case we can see that our answer is 5.
+
+**Que: Do we need adjacency list ?**
+Ans: No, since the information is already present in form of matrix which can be utilised as it is.
+
+### Approach:
+
+**Set a Counter:** Start with a counter at zero for tracking island count.
+
+**Scan the Grid:** Go through each cell in the grid.
+
+**Search for Islands:** When you find a land cell ('1'), use either BFS or DFS to explore all connected land cells.
+
+**Mark Visited Cells:** Change each visited '1' to '0' during the search to avoid recounting.
+
+**Count Each Island:** Increase the counter by 1 for every complete search that identifies a new island.
+
+**Finish the Search:** Continue until all grid cells are checked.
+
+**Result:** The counter will indicate the total number of islands.
+
+
+## Number of Islands Dry Run and Pseudocode
+
+### Dry-Run:
+```java
+[
+ ['1', '1', '0', '0', '0'],
+ ['1', '1', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+
+* Initialize variable islands = 0.
+* Start iterating through the grid:
+* At grid[0][0], we find '1'. Increment islands to 1 and call visitIsland(grid, 0, 0).
+* visitIsland will mark all connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+
+
+```cpp-
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '1', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue iterating through the grid:
+* At grid[2][2], we find '1'. Increment islands to 2 and call visitIsland(grid, 2, 2).
+* visitIsland will mark connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+```java
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue the iteration.
+* At grid[3][3], we find '1'. Increment islands to 3 and call visitIsland(grid, 3, 3).
+
+We can visit only 4 coordinates, considering them to be i, j; it means we can visit **(i,j-1), (i-1, j), (i, j+1), (i+1, j)**
+
+
+
+### Pseudocode
+
+
+
+
+
+
+
+## Take the next question if time permits, or just explain the problem statement to students.
+
+---
+## Problem 3 Shortest Distance in a maze
+
+### Problem Statement:
+Given an n x n binary matrix grid, return the length of the shortest clear path from the top-left corner (0, 0) to the bottom-right corner (n - 1, n - 1). A clear path is defined as one where:
+
+- All cells visited on the path are 0.
+- The path is connected in 8 directions (adjacent cells share an edge or a corner).
+If there is no clear path, return -1.
+
+**Example 1**:
+Input: grid = [[0, 1], [1, 0]]
+Output: 2
+**Explanation**:
+The path is from the top-left corner to the bottom-right corner. The minimum path length is 2 (cells (0,0) -> (1,1)).
+
+**Example 2**:
+Input: grid = [[0,0,0],[1,1,0],[1,1,0]]
+Output: 4
+**Explanation**:
+The shortest path is (0,0) -> (0,1) -> (0,2) -> (1,2) -> (2,2).
+The minimum path length is 4.
+
+**Example 3**:
+Input: grid = [[1, 0, 0], [1, 1, 0], [1, 1, 0]]
+Output: -1
+**Explanation**:
+Since the top-left corner contains a 1, there is no clear path, so the output is -1.
+
+
+### Breadth-First Search (BFS) Approach:
+
+The problem is a shortest path search on a grid, where all moves have equal weight. This makes it ideal for a Breadth-First Search (BFS), which explores the shortest path in unweighted graphs.
+BFS explores level by level, guaranteeing that when we reach the destination, the number of steps is minimal.
+
+**8-Directional Movement**:
+
+- We are allowed to move in 8 directions (up, down, left, right, and diagonally). Hence, from each cell (x, y), we can move to any of its 8 neighboring cells.
+- The valid neighbors are those within the bounds of the grid and whose values are 0 (i.e., walkable).
+
+**Early Termination**:
+
+- If the start cell (0, 0) or the end cell (n-1, n-1) is blocked (i.e., contains 1), return -1 immediately, as no path is possible.
+Optimized Solution Using BFS
+Approach:
+
+**BFS Initialization**:
+
+- Start BFS from the top-left corner (0, 0), and add it to the queue.
+- Maintain a visited set or mark cells as visited in the grid itself to avoid revisiting the same cell.
+
+**BFS Process**:
+
+- For each cell (x, y) dequeued, check its 8 possible neighboring cells.
+If a neighboring cell is walkable (i.e., 0), mark it as visited, add it to the queue, and increment the path length.
+If you reach the bottom-right corner, return the path length.
+
+**Edge Cases**:
+
+- If the start or end is blocked (i.e., contains a 1), return -1.
+If the grid has only one cell, check whether it’s walkable (0).
+
+### Optimized Solution Pseudocode:
+
+``` cpp
+function shortestPathBinaryMatrix(grid):
+ n = length of grid
+
+ # Edge case: If the start or end cell is blocked, return -1
+ if grid[0][0] == 1 or grid[n-1][n-1] == 1:
+ return -1
+
+ # Directions for 8 possible moves (horizontal, vertical, and diagonal)
+ directions = [(1, 0), (-1, 0), (0, 1), (0, -1), (1, 1), (-1, -1), (1, -1), (-1, 1)]
+
+ # BFS initialization
+ queue = [(0, 0, 1)] # (row, col, path_length)
+ grid[0][0] = 1 # Mark as visited
+
+ while queue is not empty:
+ (x, y, path_length) = dequeue
+
+ # If we reached the bottom-right corner, return the path length
+ if x == n - 1 and y == n - 1:
+ return path_length
+
+ # Explore all 8 neighbors
+ for direction in directions:
+ newX, newY = x + direction[0], y + direction[1]
+
+ if 0 <= newX < n and 0 <= newY < n and grid[newX][newY] == 0:
+ queue.append((newX, newY, path_length + 1))
+ grid[newX][newY] = 1 # Mark as visited
+
+ # If no path found, return -1
+ return -1
+
+```
+**Explanation**:
+**Base Case Check**:
+
+- If the starting cell (0, 0) or the ending cell (n-1, n-1) is blocked (i.e., contains a 1), return -1 immediately because no path is possible.
+
+**BFS Queue**:
+- Initialize a queue with the starting cell (0, 0) and the initial path length of 1. Each item in the queue is a tuple (x, y, path_length), where x and y represent the cell coordinates, and path_length represents the length of the path from the start to this cell.
+-
+**8-Directional Movement**:
+- From each cell (x, y), attempt to move to all 8 possible neighboring cells. If a neighbor is within bounds and walkable (0), mark it as visited (set its value to 1), and add it to the queue with an incremented path length.
+-
+**Termination**:
+
+- If we reach the destination cell (n-1, n-1), return the current path length.
+If the queue is empty and the destination was not reached, return -1 to indicate that no path exists.
+
+### Complexity Analysis**:
+**Time Complexity**: O(n^2)
+**Space Complexity**: O(n^2)
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md b/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
index 090f695..bcd00f7 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
@@ -1,9 +1,15 @@
# Graphs 3: MST & Dijkstra
----
-### Challenges in Flipkart's Logistics and Delivery
+### Agenda of the lecture:
+
+* Challenges in Flipkart's Logistics and Delivery Operations
+* Prim's Algorithm
+* Djikstra's Algorithm
+
+### Challenges in Flipkarts Logistics and Delivery
+
**Scenario:**
Suppose Flipkart has N local distribution centers spread across a large metropolitan city. These centers need to be interconnected for efficient movement of goods. However, building and maintaining roads between these centers is costly. Flipkart's goal is to minimize these costs while ensuring every center is connected and operational.
@@ -11,7 +17,7 @@ Suppose Flipkart has N local distribution centers spread across a large metropol
-**Explanation**
+### Explanation
**Example:**
@@ -55,6 +61,7 @@ The minimum spanning tree has all the properties of a spanning tree with an adde
**Algorithms for MST:** Kruskal's and Prim's algorithms are used to find MSTs. The MST found can vary based on the choices made for edges with equal weights. Both algorithms solve for same problem having same time and space complexities.
+*Note: We'll cover Prim's in today's session, Kruskal shall be covered in DSA 4.2*
### Solution to Flipkart's problem
@@ -67,9 +74,7 @@ The minimum spanning tree has all the properties of a spanning tree with an adde
* **Outcome:** The result is a network of roads connecting all centers with the shortest total length or the lowest cost.
----
-## Prim's Algorithm
-
+### Prims Algorithm
Let's consider the below **Graph:**
@@ -94,6 +99,32 @@ We choose 5 ---- 4 with weight 3
+
+
+
+**Answer:** after 3 minutes all oranges will get rotten.
+* Initially, We need to insert all rotten oranges in Queue (where each element in queue is in a pair),
+* Then check if any fresh oranges has become rotten and if they did, return the time otherwise return -1.
+
+#### Pseudocode
+```java
+dx[] = {-1, 1, 0, 0};
+dy[] = {0, 0, -1, 1};
+
+function orangesRotting(grid[][]) {
+ rowCount = grid.length;
+ colCount = grid[0].length;
+ declare Queue of integer array named queue;
+
+ freshOranges = 0;
+ minutes = 0;
+
+ // Count fresh oranges and add rotten oranges to the queue
+ for (i -> 0 to rowCount - 1) {
+ for (j -> 0 to colCount - 1) {
+ if (grid[i][j] == 2) {
+ queue.push({i, j, minutes});
+ } else if (grid[i][j] == 1) {
+ freshOranges++;
+ }
+ }
+ }
+ if (freshOranges == 0) {
+ // If there are no fresh oranges initially, they are already rotten.
+ return 0;
+ }
+
+ while (not queue.isEmpty()) {
+ cell = queue.pop();
+ x = cell[0];
+ y = cell[1];
+ minutes = cell[2];
+
+ for (i -> 0 to 3 ) {
+ newX = x + dx[i];
+ newY = y + dy[i];
+
+ if (isValid(grid, newX, newY) and grid[newX][newY] == 1) {
+ grid[newX][newY] = 2;
+ freshOranges--;
+ queue.push({newX, newY, minutes + 1});
+ }
+ }
+ }
+
+ return (freshOranges == 0) ? minutes : -1;
+}
+function isValid(grid[][], x, y) {
+ rowCount = grid.length;
+ colCount = grid[0].length;
+ return x >= 0 and x < rowCount and y >= 0 and y < colCount;
+}
+```
+
+---
+
+## Problem 2 Number of Islands
+### Problem Statement
+
+You are given a 2D grid of '1's (land) and '0's (water). Your task is to determine the number of islands in the grid. An island is formed by connecting adjacent (horizontally or vertically) land cells. Diagonal connections are not considered.
+
+Given here if the cell values has 1 then there is land and 0 if it is water, and you may assume all four edges of the grid are all surrounded by water.
+
+
+
+In this case we can see that our answer is 5.
+
+**Que: Do we need adjacency list ?**
+Ans: No, since the information is already present in form of matrix which can be utilised as it is.
+
+### Approach:
+
+**Set a Counter:** Start with a counter at zero for tracking island count.
+
+**Scan the Grid:** Go through each cell in the grid.
+
+**Search for Islands:** When you find a land cell ('1'), use either BFS or DFS to explore all connected land cells.
+
+**Mark Visited Cells:** Change each visited '1' to '0' during the search to avoid recounting.
+
+**Count Each Island:** Increase the counter by 1 for every complete search that identifies a new island.
+
+**Finish the Search:** Continue until all grid cells are checked.
+
+**Result:** The counter will indicate the total number of islands.
+
+
+## Number of Islands Dry Run and Pseudocode
+
+### Dry-Run:
+```java
+[
+ ['1', '1', '0', '0', '0'],
+ ['1', '1', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+
+* Initialize variable islands = 0.
+* Start iterating through the grid:
+* At grid[0][0], we find '1'. Increment islands to 1 and call visitIsland(grid, 0, 0).
+* visitIsland will mark all connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+
+
+```cpp-
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '1', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue iterating through the grid:
+* At grid[2][2], we find '1'. Increment islands to 2 and call visitIsland(grid, 2, 2).
+* visitIsland will mark connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+```java
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue the iteration.
+* At grid[3][3], we find '1'. Increment islands to 3 and call visitIsland(grid, 3, 3).
+
+We can visit only 4 coordinates, considering them to be i, j; it means we can visit **(i,j-1), (i-1, j), (i, j+1), (i+1, j)**
+
+
+
+### Pseudocode
+
+
+
+
+
+
+
+## Take the next question if time permits, or just explain the problem statement to students.
+
+---
+## Problem 3 Shortest Distance in a maze
+
+### Problem Statement:
+Given an n x n binary matrix grid, return the length of the shortest clear path from the top-left corner (0, 0) to the bottom-right corner (n - 1, n - 1). A clear path is defined as one where:
+
+- All cells visited on the path are 0.
+- The path is connected in 8 directions (adjacent cells share an edge or a corner).
+If there is no clear path, return -1.
+
+**Example 1**:
+Input: grid = [[0, 1], [1, 0]]
+Output: 2
+**Explanation**:
+The path is from the top-left corner to the bottom-right corner. The minimum path length is 2 (cells (0,0) -> (1,1)).
+
+**Example 2**:
+Input: grid = [[0,0,0],[1,1,0],[1,1,0]]
+Output: 4
+**Explanation**:
+The shortest path is (0,0) -> (0,1) -> (0,2) -> (1,2) -> (2,2).
+The minimum path length is 4.
+
+**Example 3**:
+Input: grid = [[1, 0, 0], [1, 1, 0], [1, 1, 0]]
+Output: -1
+**Explanation**:
+Since the top-left corner contains a 1, there is no clear path, so the output is -1.
+
+
+### Breadth-First Search (BFS) Approach:
+
+The problem is a shortest path search on a grid, where all moves have equal weight. This makes it ideal for a Breadth-First Search (BFS), which explores the shortest path in unweighted graphs.
+BFS explores level by level, guaranteeing that when we reach the destination, the number of steps is minimal.
+
+**8-Directional Movement**:
+
+- We are allowed to move in 8 directions (up, down, left, right, and diagonally). Hence, from each cell (x, y), we can move to any of its 8 neighboring cells.
+- The valid neighbors are those within the bounds of the grid and whose values are 0 (i.e., walkable).
+
+**Early Termination**:
+
+- If the start cell (0, 0) or the end cell (n-1, n-1) is blocked (i.e., contains 1), return -1 immediately, as no path is possible.
+Optimized Solution Using BFS
+Approach:
+
+**BFS Initialization**:
+
+- Start BFS from the top-left corner (0, 0), and add it to the queue.
+- Maintain a visited set or mark cells as visited in the grid itself to avoid revisiting the same cell.
+
+**BFS Process**:
+
+- For each cell (x, y) dequeued, check its 8 possible neighboring cells.
+If a neighboring cell is walkable (i.e., 0), mark it as visited, add it to the queue, and increment the path length.
+If you reach the bottom-right corner, return the path length.
+
+**Edge Cases**:
+
+- If the start or end is blocked (i.e., contains a 1), return -1.
+If the grid has only one cell, check whether it’s walkable (0).
+
+### Optimized Solution Pseudocode:
+
+``` cpp
+function shortestPathBinaryMatrix(grid):
+ n = length of grid
+
+ # Edge case: If the start or end cell is blocked, return -1
+ if grid[0][0] == 1 or grid[n-1][n-1] == 1:
+ return -1
+
+ # Directions for 8 possible moves (horizontal, vertical, and diagonal)
+ directions = [(1, 0), (-1, 0), (0, 1), (0, -1), (1, 1), (-1, -1), (1, -1), (-1, 1)]
+
+ # BFS initialization
+ queue = [(0, 0, 1)] # (row, col, path_length)
+ grid[0][0] = 1 # Mark as visited
+
+ while queue is not empty:
+ (x, y, path_length) = dequeue
+
+ # If we reached the bottom-right corner, return the path length
+ if x == n - 1 and y == n - 1:
+ return path_length
+
+ # Explore all 8 neighbors
+ for direction in directions:
+ newX, newY = x + direction[0], y + direction[1]
+
+ if 0 <= newX < n and 0 <= newY < n and grid[newX][newY] == 0:
+ queue.append((newX, newY, path_length + 1))
+ grid[newX][newY] = 1 # Mark as visited
+
+ # If no path found, return -1
+ return -1
+
+```
+**Explanation**:
+**Base Case Check**:
+
+- If the starting cell (0, 0) or the ending cell (n-1, n-1) is blocked (i.e., contains a 1), return -1 immediately because no path is possible.
+
+**BFS Queue**:
+- Initialize a queue with the starting cell (0, 0) and the initial path length of 1. Each item in the queue is a tuple (x, y, path_length), where x and y represent the cell coordinates, and path_length represents the length of the path from the start to this cell.
+-
+**8-Directional Movement**:
+- From each cell (x, y), attempt to move to all 8 possible neighboring cells. If a neighbor is within bounds and walkable (0), mark it as visited (set its value to 1), and add it to the queue with an incremented path length.
+-
+**Termination**:
+
+- If we reach the destination cell (n-1, n-1), return the current path length.
+If the queue is empty and the destination was not reached, return -1 to indicate that no path exists.
+
+### Complexity Analysis**:
+**Time Complexity**: O(n^2)
+**Space Complexity**: O(n^2)
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md b/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
index 090f695..bcd00f7 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
@@ -1,9 +1,15 @@
# Graphs 3: MST & Dijkstra
----
-### Challenges in Flipkart's Logistics and Delivery
+### Agenda of the lecture:
+
+* Challenges in Flipkart's Logistics and Delivery Operations
+* Prim's Algorithm
+* Djikstra's Algorithm
+
+### Challenges in Flipkarts Logistics and Delivery
+
**Scenario:**
Suppose Flipkart has N local distribution centers spread across a large metropolitan city. These centers need to be interconnected for efficient movement of goods. However, building and maintaining roads between these centers is costly. Flipkart's goal is to minimize these costs while ensuring every center is connected and operational.
@@ -11,7 +17,7 @@ Suppose Flipkart has N local distribution centers spread across a large metropol
-**Explanation**
+### Explanation
**Example:**
@@ -55,6 +61,7 @@ The minimum spanning tree has all the properties of a spanning tree with an adde
**Algorithms for MST:** Kruskal's and Prim's algorithms are used to find MSTs. The MST found can vary based on the choices made for edges with equal weights. Both algorithms solve for same problem having same time and space complexities.
+*Note: We'll cover Prim's in today's session, Kruskal shall be covered in DSA 4.2*
### Solution to Flipkart's problem
@@ -67,9 +74,7 @@ The minimum spanning tree has all the properties of a spanning tree with an adde
* **Outcome:** The result is a network of roads connecting all centers with the shortest total length or the lowest cost.
----
-## Prim's Algorithm
-
+### Prims Algorithm
Let's consider the below **Graph:**
@@ -94,6 +99,32 @@ We choose 5 ---- 4 with weight 3
 +---
+
+### Question
+What is the next node, we need to visit ?
+
+
+
+
+### Choices
+- [ ] 3
+- [x] 2
+- [ ] 1
+- [ ] 6
+
+
+
+
+### Explanation:
+
+The next we need to visit is **2**.
+
+We choose 4 ----> 2 with weight 3, This is the smallest weight node among all possible edges of 3, 4, and 5.
+
+---
+### Prims Algorithm Continued
+
Now, same process follows i.e, we can select a min weighted edge originating from 3, 4, or 5 such that it should connect to a vertex that hasn't been visited yet.
@@ -102,6 +133,27 @@ Now, same process follows i.e, we can select a min weighted edge originating fro
+---
+
+### Question
+What is the next node, we need to visit ?
+
+
+
+
+### Choices
+- [ ] 3
+- [x] 2
+- [ ] 1
+- [ ] 6
+
+
+
+
+### Explanation:
+
+The next we need to visit is **2**.
+
+We choose 4 ----> 2 with weight 3, This is the smallest weight node among all possible edges of 3, 4, and 5.
+
+---
+### Prims Algorithm Continued
+
Now, same process follows i.e, we can select a min weighted edge originating from 3, 4, or 5 such that it should connect to a vertex that hasn't been visited yet.
@@ -102,6 +133,27 @@ Now, same process follows i.e, we can select a min weighted edge originating fro
 +---
+
+
+### Question
+What is the most suitable data structure for implementing Prim's algorithm?
+
+### Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Heap
+- [ ] Stack
+
+
+### Explanation:
+
+Prim's algorithm typically uses a Heap (min-heap) to efficiently select the minimum-weight edge at each step of the algorithm. Min Heaps allow for constant time access to the minimum element, making them well-suited for this purpose.
+
+---
+## Prims Algorithm Execution
+
+
### Execution
Say we have a black box(we'll name it later)
@@ -127,12 +179,12 @@ Select the minimum weighted -> (3, 4)
Now, this shall continue.
-#### Pseudocode
+### Pseudocode
```java
-while (!heap.isEmpty()) {
-
- Pair p = heap.getMin();
+while (no heap.isEmpty()) {
+
+ p = heap.getMin();
if (vis[v] == true)
continue;
@@ -143,91 +195,272 @@ while (!heap.isEmpty()) {
// Now, you can optionally iterate through the adjacent vertices of 'v' and update the heap with new edges
for ((u, w) in adj[v]) {
-
+
if (!vis[u]) {
// Add the unvisited neighbor edges to the heap
- heap.add({w,u});
+ heap.add({w, u});
}
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(E * logE)
**Space Complexity:** O(V + E)
----
-## Dijkstra’s Algorithm
+## Dijkstras Algorithm
+### Question
There are N cities in a country, you are living in city-1. Find minimum distance to reach every other city from city-1.
We need to return the answer in the form of array
-
+---
+
+
+### Question
+What is the most suitable data structure for implementing Prim's algorithm?
+
+### Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Heap
+- [ ] Stack
+
+
+### Explanation:
+
+Prim's algorithm typically uses a Heap (min-heap) to efficiently select the minimum-weight edge at each step of the algorithm. Min Heaps allow for constant time access to the minimum element, making them well-suited for this purpose.
+
+---
+## Prims Algorithm Execution
+
+
### Execution
Say we have a black box(we'll name it later)
@@ -127,12 +179,12 @@ Select the minimum weighted -> (3, 4)
Now, this shall continue.
-#### Pseudocode
+### Pseudocode
```java
-while (!heap.isEmpty()) {
-
- Pair p = heap.getMin();
+while (no heap.isEmpty()) {
+
+ p = heap.getMin();
if (vis[v] == true)
continue;
@@ -143,91 +195,272 @@ while (!heap.isEmpty()) {
// Now, you can optionally iterate through the adjacent vertices of 'v' and update the heap with new edges
for ((u, w) in adj[v]) {
-
+
if (!vis[u]) {
// Add the unvisited neighbor edges to the heap
- heap.add({w,u});
+ heap.add({w, u});
}
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(E * logE)
**Space Complexity:** O(V + E)
----
-## Dijkstra’s Algorithm
+## Dijkstras Algorithm
+### Question
There are N cities in a country, you are living in city-1. Find minimum distance to reach every other city from city-1.
We need to return the answer in the form of array
-) +### Example
+
+**Input Graph:**
+
+### Example
+
+**Input Graph:**
+ **Output:**
-
**Output:**
- +| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
-**Initialize Data Structures:**
+### Result Array
-* Create an adjacency list (graph) to represent the cities and their distances.
-* Initialize a distances list with infinity for all cities except city-1 (set to 0).
-* Use a `Heap
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
-**Initialize Data Structures:**
+### Result Array
-* Create an adjacency list (graph) to represent the cities and their distances.
-* Initialize a distances list with infinity for all cities except city-1 (set to 0).
-* Use a `Heap +
+
+Lets set the starting point as **1**. So we need to find the Shortest to all the other vertexes from 1.
+
+
+Initally the distance array, d will be set to ∞.
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+We know that, from 1 -> 1 is always 0.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 1 into the min-heap, which is used to pick the minimum weighted node.
+
+The elements of the min heap is in the form **(weight, vertex)**.
+
+min heap = `[ (7,2) (8, 3) ]`
+
+**(7, 2) Picked**
+
+Pick the minimum weighted one, which is **(7, 2)**. So we can say that, from **1 -> 2**, the minimum path is 7. Updating in the distance array as well.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 2 into the min-heap, by adding the current weight + adjacent weight.
+i.e., (cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_3)
+(cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_4)
+
+Before adding the adjacent vertex in the min heap, check whether it is good enought to add it.
+
+Here the adjacent elements of 2 is 1, 3, 4. We notice that, there is no point in visiting 1, by **1 -> 2 -> 1** for the cost of **14**. Already we know that, 1 can be visited in **0 cost** by checking on the d (distance array). So in this case, we **dont insert in our min heap**.
+
+
+
+Adding the remaining two pairs in the min heap.
+
+min heap = `[ (8, 3) (10, 3) (13, 4)]`
+
+
+**(8, 3) Picked**
+Picking the minimum (8, 3) and updating the distance array.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+After adding the adjacent vertexes of 3,
+
+(16, 1) is not inserted, Since there is already a cost exist.
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+
+---
+
+### Question
+
+The current states are,
+
+Given Graph
+
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| distance array (d) | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+What would be the next step, which is going to take place?
+
+### Choices
+- [ ] Pick (10, 3) and Update the distance array at 3rd vertex as 10
+- [x] Pick (10, 3) and Dont update the distance array
+- [ ] Pick (13, 4) and Update the distance array at 4th vertex as 13
+- [ ] Pick (12, 4) and Dont update the distance array
+
+
+
+
+### Explanation:
+
+The current step is to **Pick (10, 3) and Dont update the distance array**. Since we have noticed that, On the distance array, vertex 3 can be visited at cost 8, which is obviously lesser than 10. So no need to update the array.
+
+After Picking (10, 3), the further steps are processed.
+
+---
+## Dijkstras Algorithm Dry Run continued
+
+**(10, 3) is Picked**
+
+But 3 can be visited by 8 cost already. So, No changes.
+
+min heap = `[ (13, 4) (11, 5) (12, 4)]`
+
+**(11, 5) is Picked**
+
+Updating the distance array
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | 11 | ∞ | ∞ |
+
+Inserting the adjacent vertexes of 5,
+
+min heap = `[ (13, 4) (12, 4) (13, 4) (16, 6) (13, 7)]`
+
+The pairs, (14, 3) is not inserted, since there is already minimum cost exist in the distance array.
+
+**(12, 4) is Picked**
+
+Updating the distance array
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | ∞ |
+
+Inserting adjacent of 4,
+
+min heap = `[ (13, 4) (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+The other possible pairs are not inserted, since it has the minimum cost already.
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (16, 6) (13, 7) (17, 6)]`
+**(13, 7) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7) (15, 6)]`
+
+**(15, 6) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7)]`
+
+
+**(16, 6) is Picked**
+
+No changes
+
+min heap = `[(17, 6) (18, 7)]`
+
+**(17, 6) is Picked**
+
+No changes
+
+min heap = `[(18, 7)]`
+
+**(18, 6) is Picked**
+
+No changes
+
+min heap = `[]`
+
+Thus the min heap is Emptied.
+
+The distance array is,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+
+### Pseudo code
```java
- while (!hp.isEmpty()) {
- Pair rp = hp.poll(); // Extract the minimum element
-
- int d = rp.first; // Distance
- int u = rp.second; // City
-
- // Skip if this distance is greater than the known distance
- if (d > dist[u]) {
- continue;
- }
-
- // Explore neighbors of u and update distances
- for ( /* Loop through neighbors */ ) {
- int v = /* Neighbor city */ ;
- int w = /* Weight to reach v from u */ ;
-
- // Calculate the new distance via u
- int new_dist = dist[u] + w;
-
- // If the new distance is shorter, update dist and add to heap
- if (new_dist < dist[v]) {
- dist[v] = new_dist;
- hp.add(new Pair(new_dist, v));
- }
- }
- }
- }
+ while (not hp.isEmpty()) {
+ rp = hp.pop(); // Extract the minimum element
+
+ d = rp.first; // Distance
+ u = rp.second; // City
+
+ // Skip if this distance is greater than the known distance
+ if (d > dist[u]) {
+ continue;
+ }
+
+ // Explore neighbors of u and update distances
+ for (/* Loop through neighbors */) {
+ v = /* Neighbor city */;
+ w = /* Weight to reach v from u */;
+
+ // Calculate the new distance via u
+ new_dist = dist[u] + w;
+
+ // If the new distance is shorter, update dist and add to heap
+ if (new_dist < dist[v]) {
+ dist[v] = new_dist;
+ hp.add(Pair(new_dist, v));
+ }
+ }
+ }
+ }
```
* The time complexity of the Dijkstra's algorithm implementation with a min-heap of pairs is $O((E + V) * log(V))$, where E is the number of edges, V is the number of vertices (cities), and log(V) represents the complexity of heap operations.
@@ -237,3 +470,19 @@ We need to return the answer in the form of array
Dijkstra's algorithm is not suitable for graphs with negative edge weights as it assumes non-negative weights to guarantee correct results. Negative weights can lead to unexpected behavior and incorrect shortest path calculations.
+---
+
+
+### Question
+Is Dijkstra's algorithm is commonly used for finding the Minimum Spanning Tree ?
+
+### Choices
+- [ ] Yes
+- [x] No
+
+
+### Explanation:
+
+Dijkstra's Algorithms is for finding the Single source shortest path algorithm
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Greedy.md b/Academy DSA Typed Notes/Advanced/DSA Greedy.md
index a8835d4..2dbf467 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Greedy.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Greedy.md
@@ -1,8 +1,8 @@
# Advanced DSA: Greedy
----
## Introduction on Greedy
+### Greedy
The greedy approach deals with maximizing our profit and minimizing our loss.
@@ -29,9 +29,7 @@ If we involve only one factor then selection will become easier and if multiple
In this lecture, we are going to do questions which involve multiple factors.
----
### Problem 1 Flipkart's Challenge in Effective Inventory Management
-
In the recent expansion into grocery delivery, Flipkart faces a crucial challenge in effective inventory management. Each grocery item on the platform carries its own expiration date and profit margin, represented by arrays A[i] (expiration date for the ith item) and B[i] (profit margin for the ith item). To mitigate potential losses due to expiring items, Flipkart is seeking a strategic solution. The objective is to identify a method to strategically promote certain items, ensuring they are sold before their expiration date, thereby maximizing overall profit. Can you assist Flipkart in developing an innovative approach to optimize their grocery inventory and enhance profitability?
@@ -42,7 +40,7 @@ Time starts with **T = 0**, and it takes 1 unit of time to sell one item and the
Sell items such that the sum of the **profit by items is maximized.**
-**Example**
+### Example
**`A[] = [3 1 3 2 3]`**
**`B[] = [6 5 3 1 9]`**
@@ -125,6 +123,7 @@ Initially T = 0
- Now the item at index 2 can't be sold as A[2] <= T. So we can not sell it
+
So we have a total profit 20.
Here we are getting the total profit greater than the total profit of the previously sold combination of items.
@@ -137,6 +136,7 @@ And we can achieve maximum profit 20.
---
+
### Question
What is the maximum profit we can achieve if we have two items with expiration time in A and profit in B:
@@ -144,7 +144,7 @@ What is the maximum profit we can achieve if we have two items with expiration t
A = [1, 2]
B = [3, 1500]
-**Choices**
+### Choices
- [ ] 3
- [ ] 1500
@@ -153,7 +153,8 @@ B = [3, 1500]
-**Explanation**
+
+### Explanation
A = [1, 2]
B = [3, 1500]
@@ -162,7 +163,7 @@ B = [3, 1500]
Initially T = 0
-- We have selected the item at index 9 and incremented T by 1.
+- We have selected the item at index 0 and incremented T by 1.
|T|Item Index|Profit|
@@ -187,7 +188,7 @@ So we have a total profit 1503.
- Pick the highest profit item first approach is not giving us the maximum profit, so it will not work. We have to think of another approach.
-#### Idea: Sell Everything
+### Idea: Sell Everything
Our approach is always towards selling all the items so that we can achieve maximum profit.
So our approach is to first sell the item with the minimum end time.
@@ -283,12 +284,14 @@ So we have a total profit 28.
**`At any point, if we weren't able to choose a item as T >= A[i] and realize we made a wrong choice before, we will get rid of the item with least profit we previously picked and choose the current one instead.`**
-#### Approach
+### Approach
The solution to this question is just like the team selection. We have to select the strongest player, if we have any player who is stronger than the player in our team, then we will remove the weaker player from the team and add that player to our team.
+***`[Ask Learners] Which data structure should we select ?`***
+**`MIN HEAP!`**
-**Example**: Solving using min-heap
+### Example: Solving using min-heap
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| -- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
@@ -360,65 +363,71 @@ All the items are sorted in the ascending order of expiration time.
So we have final answer = $1 + 3 + 4 + 5 + 7 + 8 = 28$
-#### PseudoCode
+### PseudoCode
```cpp
1. Sort them in increasing order of time.
2. Minheap heap:
T = 0
-for (i = 0; i < N; i++) {
- if (T < A[i]) {
- heap.insert(B[i])
- T++
- } else {
- if (B[i] <= root of heap) -> ignore {
-
- }
- else {
- extractMin()
+ for( i -> 0 to N - 1 ){
+ if(T < A[i]){
heap.insert(B[i])
+ T++
+ }
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin()
+ heap.insert(B[i])
+ }
}
}
-}
3. Remove all elements from the heap and add them to get the answer.
```
---
+
+
### Question
What is the time and space complexity of this question?
-**Choices**
+### Choices
- [ ] TC: O(N), SC: O(N)
- [x] TC: O(NlogN), SC: O(N)
- [ ] TC: O(N$^2$), SC: O(N)
- [ ] TC: O(N$^2$) , SC: O(N$^2$)
-
---
+
+
### Effective Inventory Management Complexity
**Time Complexity**
```cpp
-1. Sort them in increasing order of time.-- -> NlogN
+1. Sort them in increasing order of time. ---> NlogN
2. Minheap heap:
T = 0
-for (i = 0; i < N; i++) {
- -- -> N
- if (T < A[i]) {
- heap.insert(B[i]) -- -> logN
- T++
- } else {
- if (B[i] <= root of heap) -> ignore {
-
+ for( i -> 0 to N - 1 ){ ---> N
+ if(T < A[i]){
+ heap.insert(B[i]) ---> logN
+ T++
}
- else {
- extractMin() -- -> logN
- heap.insert(B[i]) -- -> logN
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin() ---> logN
+ heap.insert(B[i]) ---> logN
+ }
}
}
-}
3. Remove all elements from the heap and add them to get the answer.
```
@@ -428,8 +437,179 @@ So overall time complexity = O(NlogN) + O(NlogN)
- **Space Complexity: O(N)**
+
+---
+## Problem 2 Finish Maximum Jobs
+
+### Problem Statement
+
+Given N jobs with their start and end times. Find the maximum number of jobs that can be completed if only one job can be done at a time.
+
+### Example
+
+
+
+
+Lets set the starting point as **1**. So we need to find the Shortest to all the other vertexes from 1.
+
+
+Initally the distance array, d will be set to ∞.
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+We know that, from 1 -> 1 is always 0.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 1 into the min-heap, which is used to pick the minimum weighted node.
+
+The elements of the min heap is in the form **(weight, vertex)**.
+
+min heap = `[ (7,2) (8, 3) ]`
+
+**(7, 2) Picked**
+
+Pick the minimum weighted one, which is **(7, 2)**. So we can say that, from **1 -> 2**, the minimum path is 7. Updating in the distance array as well.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 2 into the min-heap, by adding the current weight + adjacent weight.
+i.e., (cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_3)
+(cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_4)
+
+Before adding the adjacent vertex in the min heap, check whether it is good enought to add it.
+
+Here the adjacent elements of 2 is 1, 3, 4. We notice that, there is no point in visiting 1, by **1 -> 2 -> 1** for the cost of **14**. Already we know that, 1 can be visited in **0 cost** by checking on the d (distance array). So in this case, we **dont insert in our min heap**.
+
+
+
+Adding the remaining two pairs in the min heap.
+
+min heap = `[ (8, 3) (10, 3) (13, 4)]`
+
+
+**(8, 3) Picked**
+Picking the minimum (8, 3) and updating the distance array.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+After adding the adjacent vertexes of 3,
+
+(16, 1) is not inserted, Since there is already a cost exist.
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+
+---
+
+### Question
+
+The current states are,
+
+Given Graph
+
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| distance array (d) | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+What would be the next step, which is going to take place?
+
+### Choices
+- [ ] Pick (10, 3) and Update the distance array at 3rd vertex as 10
+- [x] Pick (10, 3) and Dont update the distance array
+- [ ] Pick (13, 4) and Update the distance array at 4th vertex as 13
+- [ ] Pick (12, 4) and Dont update the distance array
+
+
+
+
+### Explanation:
+
+The current step is to **Pick (10, 3) and Dont update the distance array**. Since we have noticed that, On the distance array, vertex 3 can be visited at cost 8, which is obviously lesser than 10. So no need to update the array.
+
+After Picking (10, 3), the further steps are processed.
+
+---
+## Dijkstras Algorithm Dry Run continued
+
+**(10, 3) is Picked**
+
+But 3 can be visited by 8 cost already. So, No changes.
+
+min heap = `[ (13, 4) (11, 5) (12, 4)]`
+
+**(11, 5) is Picked**
+
+Updating the distance array
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | 11 | ∞ | ∞ |
+
+Inserting the adjacent vertexes of 5,
+
+min heap = `[ (13, 4) (12, 4) (13, 4) (16, 6) (13, 7)]`
+
+The pairs, (14, 3) is not inserted, since there is already minimum cost exist in the distance array.
+
+**(12, 4) is Picked**
+
+Updating the distance array
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | ∞ |
+
+Inserting adjacent of 4,
+
+min heap = `[ (13, 4) (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+The other possible pairs are not inserted, since it has the minimum cost already.
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (16, 6) (13, 7) (17, 6)]`
+**(13, 7) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7) (15, 6)]`
+
+**(15, 6) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7)]`
+
+
+**(16, 6) is Picked**
+
+No changes
+
+min heap = `[(17, 6) (18, 7)]`
+
+**(17, 6) is Picked**
+
+No changes
+
+min heap = `[(18, 7)]`
+
+**(18, 6) is Picked**
+
+No changes
+
+min heap = `[]`
+
+Thus the min heap is Emptied.
+
+The distance array is,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+
+### Pseudo code
```java
- while (!hp.isEmpty()) {
- Pair rp = hp.poll(); // Extract the minimum element
-
- int d = rp.first; // Distance
- int u = rp.second; // City
-
- // Skip if this distance is greater than the known distance
- if (d > dist[u]) {
- continue;
- }
-
- // Explore neighbors of u and update distances
- for ( /* Loop through neighbors */ ) {
- int v = /* Neighbor city */ ;
- int w = /* Weight to reach v from u */ ;
-
- // Calculate the new distance via u
- int new_dist = dist[u] + w;
-
- // If the new distance is shorter, update dist and add to heap
- if (new_dist < dist[v]) {
- dist[v] = new_dist;
- hp.add(new Pair(new_dist, v));
- }
- }
- }
- }
+ while (not hp.isEmpty()) {
+ rp = hp.pop(); // Extract the minimum element
+
+ d = rp.first; // Distance
+ u = rp.second; // City
+
+ // Skip if this distance is greater than the known distance
+ if (d > dist[u]) {
+ continue;
+ }
+
+ // Explore neighbors of u and update distances
+ for (/* Loop through neighbors */) {
+ v = /* Neighbor city */;
+ w = /* Weight to reach v from u */;
+
+ // Calculate the new distance via u
+ new_dist = dist[u] + w;
+
+ // If the new distance is shorter, update dist and add to heap
+ if (new_dist < dist[v]) {
+ dist[v] = new_dist;
+ hp.add(Pair(new_dist, v));
+ }
+ }
+ }
+ }
```
* The time complexity of the Dijkstra's algorithm implementation with a min-heap of pairs is $O((E + V) * log(V))$, where E is the number of edges, V is the number of vertices (cities), and log(V) represents the complexity of heap operations.
@@ -237,3 +470,19 @@ We need to return the answer in the form of array
Dijkstra's algorithm is not suitable for graphs with negative edge weights as it assumes non-negative weights to guarantee correct results. Negative weights can lead to unexpected behavior and incorrect shortest path calculations.
+---
+
+
+### Question
+Is Dijkstra's algorithm is commonly used for finding the Minimum Spanning Tree ?
+
+### Choices
+- [ ] Yes
+- [x] No
+
+
+### Explanation:
+
+Dijkstra's Algorithms is for finding the Single source shortest path algorithm
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Greedy.md b/Academy DSA Typed Notes/Advanced/DSA Greedy.md
index a8835d4..2dbf467 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Greedy.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Greedy.md
@@ -1,8 +1,8 @@
# Advanced DSA: Greedy
----
## Introduction on Greedy
+### Greedy
The greedy approach deals with maximizing our profit and minimizing our loss.
@@ -29,9 +29,7 @@ If we involve only one factor then selection will become easier and if multiple
In this lecture, we are going to do questions which involve multiple factors.
----
### Problem 1 Flipkart's Challenge in Effective Inventory Management
-
In the recent expansion into grocery delivery, Flipkart faces a crucial challenge in effective inventory management. Each grocery item on the platform carries its own expiration date and profit margin, represented by arrays A[i] (expiration date for the ith item) and B[i] (profit margin for the ith item). To mitigate potential losses due to expiring items, Flipkart is seeking a strategic solution. The objective is to identify a method to strategically promote certain items, ensuring they are sold before their expiration date, thereby maximizing overall profit. Can you assist Flipkart in developing an innovative approach to optimize their grocery inventory and enhance profitability?
@@ -42,7 +40,7 @@ Time starts with **T = 0**, and it takes 1 unit of time to sell one item and the
Sell items such that the sum of the **profit by items is maximized.**
-**Example**
+### Example
**`A[] = [3 1 3 2 3]`**
**`B[] = [6 5 3 1 9]`**
@@ -125,6 +123,7 @@ Initially T = 0
- Now the item at index 2 can't be sold as A[2] <= T. So we can not sell it
+
So we have a total profit 20.
Here we are getting the total profit greater than the total profit of the previously sold combination of items.
@@ -137,6 +136,7 @@ And we can achieve maximum profit 20.
---
+
### Question
What is the maximum profit we can achieve if we have two items with expiration time in A and profit in B:
@@ -144,7 +144,7 @@ What is the maximum profit we can achieve if we have two items with expiration t
A = [1, 2]
B = [3, 1500]
-**Choices**
+### Choices
- [ ] 3
- [ ] 1500
@@ -153,7 +153,8 @@ B = [3, 1500]
-**Explanation**
+
+### Explanation
A = [1, 2]
B = [3, 1500]
@@ -162,7 +163,7 @@ B = [3, 1500]
Initially T = 0
-- We have selected the item at index 9 and incremented T by 1.
+- We have selected the item at index 0 and incremented T by 1.
|T|Item Index|Profit|
@@ -187,7 +188,7 @@ So we have a total profit 1503.
- Pick the highest profit item first approach is not giving us the maximum profit, so it will not work. We have to think of another approach.
-#### Idea: Sell Everything
+### Idea: Sell Everything
Our approach is always towards selling all the items so that we can achieve maximum profit.
So our approach is to first sell the item with the minimum end time.
@@ -283,12 +284,14 @@ So we have a total profit 28.
**`At any point, if we weren't able to choose a item as T >= A[i] and realize we made a wrong choice before, we will get rid of the item with least profit we previously picked and choose the current one instead.`**
-#### Approach
+### Approach
The solution to this question is just like the team selection. We have to select the strongest player, if we have any player who is stronger than the player in our team, then we will remove the weaker player from the team and add that player to our team.
+***`[Ask Learners] Which data structure should we select ?`***
+**`MIN HEAP!`**
-**Example**: Solving using min-heap
+### Example: Solving using min-heap
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| -- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
@@ -360,65 +363,71 @@ All the items are sorted in the ascending order of expiration time.
So we have final answer = $1 + 3 + 4 + 5 + 7 + 8 = 28$
-#### PseudoCode
+### PseudoCode
```cpp
1. Sort them in increasing order of time.
2. Minheap heap:
T = 0
-for (i = 0; i < N; i++) {
- if (T < A[i]) {
- heap.insert(B[i])
- T++
- } else {
- if (B[i] <= root of heap) -> ignore {
-
- }
- else {
- extractMin()
+ for( i -> 0 to N - 1 ){
+ if(T < A[i]){
heap.insert(B[i])
+ T++
+ }
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin()
+ heap.insert(B[i])
+ }
}
}
-}
3. Remove all elements from the heap and add them to get the answer.
```
---
+
+
### Question
What is the time and space complexity of this question?
-**Choices**
+### Choices
- [ ] TC: O(N), SC: O(N)
- [x] TC: O(NlogN), SC: O(N)
- [ ] TC: O(N$^2$), SC: O(N)
- [ ] TC: O(N$^2$) , SC: O(N$^2$)
-
---
+
+
### Effective Inventory Management Complexity
**Time Complexity**
```cpp
-1. Sort them in increasing order of time.-- -> NlogN
+1. Sort them in increasing order of time. ---> NlogN
2. Minheap heap:
T = 0
-for (i = 0; i < N; i++) {
- -- -> N
- if (T < A[i]) {
- heap.insert(B[i]) -- -> logN
- T++
- } else {
- if (B[i] <= root of heap) -> ignore {
-
+ for( i -> 0 to N - 1 ){ ---> N
+ if(T < A[i]){
+ heap.insert(B[i]) ---> logN
+ T++
}
- else {
- extractMin() -- -> logN
- heap.insert(B[i]) -- -> logN
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin() ---> logN
+ heap.insert(B[i]) ---> logN
+ }
}
}
-}
3. Remove all elements from the heap and add them to get the answer.
```
@@ -428,8 +437,179 @@ So overall time complexity = O(NlogN) + O(NlogN)
- **Space Complexity: O(N)**
+
+---
+## Problem 2 Finish Maximum Jobs
+
+### Problem Statement
+
+Given N jobs with their start and end times. Find the maximum number of jobs that can be completed if only one job can be done at a time.
+
+### Example
+
+ +
+**Answer:** 5
+
+We will select the jobs that are not overlapping:
+- We select job `9 am - 11 am`, then we can not select `10 am - 1 pm` and `10 am - 2 pm`
+- Then we select jobs `3 pm - 4 pm` and `4 pm - 6 pm`
+- Then we select job `4 pm - 8 pm` and `8 pm - 10 pm` but we do not select job `7 pm - 9 pm`
+
+
+
+
+
+**Answer:** 5
+
+We will select the jobs that are not overlapping:
+- We select job `9 am - 11 am`, then we can not select `10 am - 1 pm` and `10 am - 2 pm`
+- Then we select jobs `3 pm - 4 pm` and `4 pm - 6 pm`
+- Then we select job `4 pm - 8 pm` and `8 pm - 10 pm` but we do not select job `7 pm - 9 pm`
+
+
+
+ +
+
+### Approach
+We have to select the job in such a way that the start time of a currently selected job is greater than or equal to the end time of the previous job.
+
+`S[i] >= E[i - 1]`
+
+---
+
+### Question
+
+What is the maximum number of jobs one person can do if only one job at a time is allowed, the start times and end times of jobs are:
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+### Choices
+
+- [ ] 2
+- [x] 3
+- [ ] 4
+- [ ] 5
+
+
+
+### Explanation
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+---
+
+
+
+
+### Approach
+We have to select the job in such a way that the start time of a currently selected job is greater than or equal to the end time of the previous job.
+
+`S[i] >= E[i - 1]`
+
+---
+
+### Question
+
+What is the maximum number of jobs one person can do if only one job at a time is allowed, the start times and end times of jobs are:
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+### Choices
+
+- [ ] 2
+- [x] 3
+- [ ] 4
+- [ ] 5
+
+
+
+### Explanation
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+---
+
+ +
+We will pick jobs `1 - 2`, `5 - 10` and `12 - 20`. So we can pick total three jobs.
+
+
+
+We will pick jobs `1 - 2`, `5 - 10` and `12 - 20`. So we can pick total three jobs.
+
+ +
+
+
+### Maximum jobs - Solution
+
+The first idea towards a solution is to first pick a job with minimum duration.
+
+### Idea 1 - Greedy based on duration
+Pick the job in the ascending order of the minimum duration. Let us take an example:
+
+
+
+
+
+### Maximum jobs - Solution
+
+The first idea towards a solution is to first pick a job with minimum duration.
+
+### Idea 1 - Greedy based on duration
+Pick the job in the ascending order of the minimum duration. Let us take an example:
+
+ +
+In this case, if we select the minimum duration job first, then we will select the job `10 - 13`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `10 - 13`, then we can select both other jobs, which means we can select two jobs.
+
+
+
+
+In this case, if we select the minimum duration job first, then we will select the job `10 - 13`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `10 - 13`, then we can select both other jobs, which means we can select two jobs.
+
+
+ +
+So selecting a job in the ascending order of the duration will not always give us the maximum number of jobs.
+
+
+### Idea 2 - Greedy based on start time
+Pick the job in the ascending order of the start time. Let us take an example:
+
+
+
+
+
+So selecting a job in the ascending order of the duration will not always give us the maximum number of jobs.
+
+
+### Idea 2 - Greedy based on start time
+Pick the job in the ascending order of the start time. Let us take an example:
+
+
+
+ +
+
+In this case, if we select the minimum start time job first, then we will select the job `2 - 20`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `2 - 20`, then we can select both other jobs, which means we can select two jobs.
+
+
+
+
+In this case, if we select the minimum start time job first, then we will select the job `2 - 20`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `2 - 20`, then we can select both other jobs, which means we can select two jobs.
+
+ +
+So selecting a job in the ascending order of the start time will not always give us the maximum number of jobs.
+
+### Observation
+We have to take a combination of the above approaches means we have to start early with the minimum duration job.
+
+start early + minimum duration
+
+A combination of both is nothing but simply means ending early.
+
+start early + minimum duration = end early
+
+### Solution
+We have to be greedy based on the end time, so we have to select jobs in the ascending order of end times.
+
+**Example:**
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+Sort these jobs based on the end time.
+
+
+S = [1, 5, 8, 7, 13, 12]
+E = [2, 10, 10, 11, 19, 20]
+
+Initially ans = 0.
+
+| Index | 0 | 1 | 2 | 3 | 4 | 5 |
+|:----------:| --- | --- | --- |:---:|:---:|:---:|
+| Start time | 1 | 5 | 8 | 7 | 13 | 12 |
+| end time | 2 | 10 | 10 | 11 | 19 | 20 |
+
+
+- We will start with the first job, which has an end time 2 but now the start time of any next job must be greater than the end time of this job.
+
+
+**So we need to keep track of the last end time.**
+
+Till now lastEndTime = 2
+ans+=1, ans = 1
+
+- Now the job at index 1 has start time = 5, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 10
+ans+=1, ans = 2
+- Now the job at index 2 has start time = 8, lastEndTime > start time, so we can not select this job.
+- Now the job at index 3 has start time = 7, lastEndTime > start time, so we can not select this job.
+- Now the job at index 4 has start time = 13, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 19
+ans+=1, ans = 3
+- Now the job at index 5 has start time = 20, lastEndTime > start time, so we can not select this job.
+
+**Answer:** 3
+
+### PseudoCode
+```cpp
+1. Sort on the basis of end-time
+2. ans = 1, lastEndTime = E[0]
+ for( i -> 1 to N - 1){
+ if(S[i] >= lastEndTime){
+ ans++;
+ lastEndTime = E[i];
+ }
+ }
+3. return ans;
+```
+
+### Complexity
+
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(N)
+
+
+
+
---
-### Problem 2 Candy Distribution
+## Problem 3 Distribute Candy
+
+### Problem Description
There are N students with their marks. The teacher has to give them candies such that
a) Every student should have at least one candy
@@ -438,7 +618,7 @@ b) Students with more marks than any of his/her neighbours have more candies tha
Find minimum candies to distribute.
-**Example**
+### Example
**Input:** [1, 5, 2, 1]
**Explanation:** First we will give 1 candy to all students.
|index|0|1|2|3|
@@ -473,11 +653,13 @@ Now all the conditions of the question are satisfied, so total 7 candies are req
---
+
+
### Question
What is the minimum number of candies teacher has to use if the marks are: [4, 4, 4, 4, 4]
-**Choices**
+### Choices
- [ ] 1
- [x] 5
@@ -485,7 +667,8 @@ What is the minimum number of candies teacher has to use if the marks are: [4, 4
- [ ] 20
-**Explanation**
+
+### Explanation
[4, 4, 4, 4, 4]
@@ -502,9 +685,9 @@ Now any student does not have marks greater than its neighbors. So our candy dis
---
-### Candy Distribution Example
-**Example**
+## Candy Distribution Example
+### Example
**Input:** [8, 10, 6, 2]
@@ -536,11 +719,12 @@ So total 7 candies are required.
---
+
### Question
What is the minimum number of candies the teacher has to use if the marks are: [1, 6, 3, 1, 10, 12, 20, 5, 2]
-**Choices**
+### Choices
- [ ] 15
- [x] 19
@@ -548,7 +732,8 @@ What is the minimum number of candies the teacher has to use if the marks are: [
- [ ] 20
-**Explanation**
+
+### Explanation
[1, 6, 3, 1, 10, 12, 20, 5, 2]
@@ -632,10 +817,6 @@ So a total 19 candies are required.
### Candy Distribution - Solution
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
**Step 1:** Assign 1 candy to all the students.
**Step 2:** For all the values of i, consider its left neighbour, if(A[i] > A[i - 1]) then C[i] > C[i - 1], means candy of ith index should be greater than (i-1)th index candy, so we will follow the greedy approach as we want to distribute a minimum number of candies, so we do `C[i] = C[i - 1] + 1`
@@ -654,188 +835,26 @@ if(A[i] > A[i + 1]){
}
```
-#### PsuedoCode
-```cpp
-int C[N];
+### PsuedoCode
+```cpp=
+C[N];
for all i, C[i] = 1
-for (i = 1; i < N; i++) {
- if (arr[i] > arr[i - 1]) {
- C[i] = C[i - 1] + 1
+for( i -> 1 to N - 1){
+ if(arr[i] > arr[i - 1]){
+ C[i] = C[i - 1] + 1
}
}
-for (i = N - 2; i >= 0; i--) {
- if (arr[i] > arr[i + 1] && C[i] < C[i + 1] + 1) {
- C[i] = C[i + 1] + 1
+for( i -> N - 2 down to 0 ){
+ if(arr[i] > arr[i + 1] and C[i] < C[i + 1] + 1 ){
+ C[i] = C[i + 1] + 1
}
}
-ans = sum of all values in C[]
+ans = sum of all values in C[]
```
-#### Complexity
+### Complexity
- **Time Complexity:** O(N)
- **Space Complexity:** O(N)
-
----
-### Problem 3 Maximum jobs
-
-
-Given N jobs with their start and end times. Find the maximum number of jobs that can be completed if only one job can be done at a time.
-
-**Example**
-
-
-
-**Answer:** 5
-
-We will select the jobs that are not overlapping:
-- We select job `9 am - 11 am`, then we can not select `10 am - 1 pm` and `10 am - 2 pm`
-- Then we select jobs `3 pm - 4 pm` and `4 pm - 6 pm`
-- Then we select job `4 pm - 8 pm` and `8 pm - 10 pm` but we do not select job `7 pm - 9 pm`
-
-
-
-
-
-
-#### Approach
-We have to select the job in such a way that the start time of a currently selected job is greater than or equal to the end time of the previous job.
-
-`S[i] >= E[i - 1]`
-
-
---
-### Question
-
-What is the maximum number of jobs one person can do if only one job at a time is allowed, the start times and end times of jobs are:
-
-S = [1, 5, 8, 7, 12, 13]
-E = [2, 10, 10, 11, 20, 19]
-
-**Choices**
-
-- [ ] 2
-- [x] 3
-- [ ] 4
-- [ ] 5
-
-
-**Explanation**
-
-S = [1, 5, 8, 7, 12, 13]
-E = [2, 10, 10, 11, 20, 19]
-
-
-
-We will pick jobs `1 - 2`, `5 - 10` and `12 - 20`. So we can pick total three jobs.
-
-
-
-
----
-
-
-### Maximum jobs - Solution
-
-The first idea towards a solution is to first pick a job with minimum duration.
-
-#### Idea 1 - Greedy based on duration
-Pick the job in the ascending order of the minimum duration. Let us take an example:
-
-
-
-In this case, if we select the minimum duration job first, then we will select the job `10 - 13`, then we can not select any other job because both overlap with it.
-
-But if we have not selected `10 - 13`, then we can select both other jobs, which means we can select two jobs.
-
-
-
-
-So selecting a job in the ascending order of the duration will not always give us the maximum number of jobs.
-
-
-#### Idea 2 - Greedy based on start time
-Pick the job in the ascending order of the start time. Let us take an example:
-
-
-
-
-
-
-In this case, if we select the minimum start time job first, then we will select the job `2 - 20`, then we can not select any other job because both overlap with it.
-
-But if we have not selected `2 - 20`, then we can select both other jobs, which means we can select two jobs.
-
-
-
-So selecting a job in the ascending order of the start time will not always give us the maximum number of jobs.
-
-#### Observation
-We have to take a combination of the above approaches means we have to start early with the minimum duration job.
-
-start early + minimum duration
-
-A combination of both is nothing but simply means ending early.
-
-start early + minimum duration = end early
-
-#### Solution
-We have to be greedy based on the end time, so we have to select jobs in the ascending order of end times.
-
-**Example:**
-
-S = [1, 5, 8, 7, 12, 13]
-E = [2, 10, 10, 11, 20, 19]
-
-Sort these jobs based on the end time.
-
-
-S = [1, 5, 8, 7, 13, 12]
-E = [2, 10, 10, 11, 19, 20]
-
-Initially ans = 0.
-
-| Index | 0 | 1 | 2 | 3 | 4 | 5 |
-|:----------:| --- | --- | --- |:---:|:---:|:---:|
-| Start time | 1 | 5 | 8 | 7 | 13 | 12 |
-| end time | 2 | 10 | 10 | 11 | 19 | 20 |
-
-
-- We will start with the first job, which has an end time 2 but now the start time of any next job must be greater than the end time of this job.
-
-
-**So we need to keep track of the last end time.**
-
-Till now lastEndTime = 2
-ans+=1, ans = 1
-
-- Now the job at index 1 has start time = 5, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
-lastEndTime = 10
-ans+=1, ans = 2
-- Now the job at index 2 has start time = 8, lastEndTime > start time, so we can not select this job.
-- Now the job at index 3 has start time = 7, lastEndTime > start time, so we can not select this job.
-- Now the job at index 4 has start time = 13, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
-lastEndTime = 19
-ans+=1, ans = 3
-- Now the job at index 5 has start time = 20, lastEndTime > start time, so we can not select this job.
-
-**Answer:** 3
-
-#### PseudoCode
-```cpp
-1. Sort on the basis of end-time
-2. ans = 1, lastEndTime = E[0]
- for( i = 1 ; i < N ; i++){
- if(S[i] >= lastEndTime){
- ans++;
- lastEndTime = E[i];
- }
- }
-3. return ans;
-```
-
-#### Complexity
-
-- **Time Complexity:** O(NlogN)
-- **Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md b/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md
index 1d169d8..e728c38 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md
@@ -1,8 +1,9 @@
# Hashing 1: Introduction
----
-## HashMap
+## Hashmap and HashSet Introduction
+
+### HashMap
Let's take an example:-
@@ -50,17 +51,19 @@ Solution: The hotel may maintain a manual register for five rooms like:-
Let's see some questions based on Hashmap.
---
+
### Question
Which of the following HashMap will you use to store the population of every country?
-**Choices**
+### Choices
- [ ] HashMap
+
+So selecting a job in the ascending order of the start time will not always give us the maximum number of jobs.
+
+### Observation
+We have to take a combination of the above approaches means we have to start early with the minimum duration job.
+
+start early + minimum duration
+
+A combination of both is nothing but simply means ending early.
+
+start early + minimum duration = end early
+
+### Solution
+We have to be greedy based on the end time, so we have to select jobs in the ascending order of end times.
+
+**Example:**
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+Sort these jobs based on the end time.
+
+
+S = [1, 5, 8, 7, 13, 12]
+E = [2, 10, 10, 11, 19, 20]
+
+Initially ans = 0.
+
+| Index | 0 | 1 | 2 | 3 | 4 | 5 |
+|:----------:| --- | --- | --- |:---:|:---:|:---:|
+| Start time | 1 | 5 | 8 | 7 | 13 | 12 |
+| end time | 2 | 10 | 10 | 11 | 19 | 20 |
+
+
+- We will start with the first job, which has an end time 2 but now the start time of any next job must be greater than the end time of this job.
+
+
+**So we need to keep track of the last end time.**
+
+Till now lastEndTime = 2
+ans+=1, ans = 1
+
+- Now the job at index 1 has start time = 5, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 10
+ans+=1, ans = 2
+- Now the job at index 2 has start time = 8, lastEndTime > start time, so we can not select this job.
+- Now the job at index 3 has start time = 7, lastEndTime > start time, so we can not select this job.
+- Now the job at index 4 has start time = 13, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 19
+ans+=1, ans = 3
+- Now the job at index 5 has start time = 20, lastEndTime > start time, so we can not select this job.
+
+**Answer:** 3
+
+### PseudoCode
+```cpp
+1. Sort on the basis of end-time
+2. ans = 1, lastEndTime = E[0]
+ for( i -> 1 to N - 1){
+ if(S[i] >= lastEndTime){
+ ans++;
+ lastEndTime = E[i];
+ }
+ }
+3. return ans;
+```
+
+### Complexity
+
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(N)
+
+
+
+
---
-### Problem 2 Candy Distribution
+## Problem 3 Distribute Candy
+
+### Problem Description
There are N students with their marks. The teacher has to give them candies such that
a) Every student should have at least one candy
@@ -438,7 +618,7 @@ b) Students with more marks than any of his/her neighbours have more candies tha
Find minimum candies to distribute.
-**Example**
+### Example
**Input:** [1, 5, 2, 1]
**Explanation:** First we will give 1 candy to all students.
|index|0|1|2|3|
@@ -473,11 +653,13 @@ Now all the conditions of the question are satisfied, so total 7 candies are req
---
+
+
### Question
What is the minimum number of candies teacher has to use if the marks are: [4, 4, 4, 4, 4]
-**Choices**
+### Choices
- [ ] 1
- [x] 5
@@ -485,7 +667,8 @@ What is the minimum number of candies teacher has to use if the marks are: [4, 4
- [ ] 20
-**Explanation**
+
+### Explanation
[4, 4, 4, 4, 4]
@@ -502,9 +685,9 @@ Now any student does not have marks greater than its neighbors. So our candy dis
---
-### Candy Distribution Example
-**Example**
+## Candy Distribution Example
+### Example
**Input:** [8, 10, 6, 2]
@@ -536,11 +719,12 @@ So total 7 candies are required.
---
+
### Question
What is the minimum number of candies the teacher has to use if the marks are: [1, 6, 3, 1, 10, 12, 20, 5, 2]
-**Choices**
+### Choices
- [ ] 15
- [x] 19
@@ -548,7 +732,8 @@ What is the minimum number of candies the teacher has to use if the marks are: [
- [ ] 20
-**Explanation**
+
+### Explanation
[1, 6, 3, 1, 10, 12, 20, 5, 2]
@@ -632,10 +817,6 @@ So a total 19 candies are required.
### Candy Distribution - Solution
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
**Step 1:** Assign 1 candy to all the students.
**Step 2:** For all the values of i, consider its left neighbour, if(A[i] > A[i - 1]) then C[i] > C[i - 1], means candy of ith index should be greater than (i-1)th index candy, so we will follow the greedy approach as we want to distribute a minimum number of candies, so we do `C[i] = C[i - 1] + 1`
@@ -654,188 +835,26 @@ if(A[i] > A[i + 1]){
}
```
-#### PsuedoCode
-```cpp
-int C[N];
+### PsuedoCode
+```cpp=
+C[N];
for all i, C[i] = 1
-for (i = 1; i < N; i++) {
- if (arr[i] > arr[i - 1]) {
- C[i] = C[i - 1] + 1
+for( i -> 1 to N - 1){
+ if(arr[i] > arr[i - 1]){
+ C[i] = C[i - 1] + 1
}
}
-for (i = N - 2; i >= 0; i--) {
- if (arr[i] > arr[i + 1] && C[i] < C[i + 1] + 1) {
- C[i] = C[i + 1] + 1
+for( i -> N - 2 down to 0 ){
+ if(arr[i] > arr[i + 1] and C[i] < C[i + 1] + 1 ){
+ C[i] = C[i + 1] + 1
}
}
-ans = sum of all values in C[]
+ans = sum of all values in C[]
```
-#### Complexity
+### Complexity
- **Time Complexity:** O(N)
- **Space Complexity:** O(N)
-
----
-### Problem 3 Maximum jobs
-
-
-Given N jobs with their start and end times. Find the maximum number of jobs that can be completed if only one job can be done at a time.
-
-**Example**
-
-
-
-**Answer:** 5
-
-We will select the jobs that are not overlapping:
-- We select job `9 am - 11 am`, then we can not select `10 am - 1 pm` and `10 am - 2 pm`
-- Then we select jobs `3 pm - 4 pm` and `4 pm - 6 pm`
-- Then we select job `4 pm - 8 pm` and `8 pm - 10 pm` but we do not select job `7 pm - 9 pm`
-
-
-
-
-
-
-#### Approach
-We have to select the job in such a way that the start time of a currently selected job is greater than or equal to the end time of the previous job.
-
-`S[i] >= E[i - 1]`
-
-
---
-### Question
-
-What is the maximum number of jobs one person can do if only one job at a time is allowed, the start times and end times of jobs are:
-
-S = [1, 5, 8, 7, 12, 13]
-E = [2, 10, 10, 11, 20, 19]
-
-**Choices**
-
-- [ ] 2
-- [x] 3
-- [ ] 4
-- [ ] 5
-
-
-**Explanation**
-
-S = [1, 5, 8, 7, 12, 13]
-E = [2, 10, 10, 11, 20, 19]
-
-
-
-We will pick jobs `1 - 2`, `5 - 10` and `12 - 20`. So we can pick total three jobs.
-
-
-
-
----
-
-
-### Maximum jobs - Solution
-
-The first idea towards a solution is to first pick a job with minimum duration.
-
-#### Idea 1 - Greedy based on duration
-Pick the job in the ascending order of the minimum duration. Let us take an example:
-
-
-
-In this case, if we select the minimum duration job first, then we will select the job `10 - 13`, then we can not select any other job because both overlap with it.
-
-But if we have not selected `10 - 13`, then we can select both other jobs, which means we can select two jobs.
-
-
-
-
-So selecting a job in the ascending order of the duration will not always give us the maximum number of jobs.
-
-
-#### Idea 2 - Greedy based on start time
-Pick the job in the ascending order of the start time. Let us take an example:
-
-
-
-
-
-
-In this case, if we select the minimum start time job first, then we will select the job `2 - 20`, then we can not select any other job because both overlap with it.
-
-But if we have not selected `2 - 20`, then we can select both other jobs, which means we can select two jobs.
-
-
-
-So selecting a job in the ascending order of the start time will not always give us the maximum number of jobs.
-
-#### Observation
-We have to take a combination of the above approaches means we have to start early with the minimum duration job.
-
-start early + minimum duration
-
-A combination of both is nothing but simply means ending early.
-
-start early + minimum duration = end early
-
-#### Solution
-We have to be greedy based on the end time, so we have to select jobs in the ascending order of end times.
-
-**Example:**
-
-S = [1, 5, 8, 7, 12, 13]
-E = [2, 10, 10, 11, 20, 19]
-
-Sort these jobs based on the end time.
-
-
-S = [1, 5, 8, 7, 13, 12]
-E = [2, 10, 10, 11, 19, 20]
-
-Initially ans = 0.
-
-| Index | 0 | 1 | 2 | 3 | 4 | 5 |
-|:----------:| --- | --- | --- |:---:|:---:|:---:|
-| Start time | 1 | 5 | 8 | 7 | 13 | 12 |
-| end time | 2 | 10 | 10 | 11 | 19 | 20 |
-
-
-- We will start with the first job, which has an end time 2 but now the start time of any next job must be greater than the end time of this job.
-
-
-**So we need to keep track of the last end time.**
-
-Till now lastEndTime = 2
-ans+=1, ans = 1
-
-- Now the job at index 1 has start time = 5, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
-lastEndTime = 10
-ans+=1, ans = 2
-- Now the job at index 2 has start time = 8, lastEndTime > start time, so we can not select this job.
-- Now the job at index 3 has start time = 7, lastEndTime > start time, so we can not select this job.
-- Now the job at index 4 has start time = 13, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
-lastEndTime = 19
-ans+=1, ans = 3
-- Now the job at index 5 has start time = 20, lastEndTime > start time, so we can not select this job.
-
-**Answer:** 3
-
-#### PseudoCode
-```cpp
-1. Sort on the basis of end-time
-2. ans = 1, lastEndTime = E[0]
- for( i = 1 ; i < N ; i++){
- if(S[i] >= lastEndTime){
- ans++;
- lastEndTime = E[i];
- }
- }
-3. return ans;
-```
-
-#### Complexity
-
-- **Time Complexity:** O(NlogN)
-- **Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md b/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md
index 1d169d8..e728c38 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Hashing 1 Introduction.md
@@ -1,8 +1,9 @@
# Hashing 1: Introduction
----
-## HashMap
+## Hashmap and HashSet Introduction
+
+### HashMap
Let's take an example:-
@@ -50,17 +51,19 @@ Solution: The hotel may maintain a manual register for five rooms like:-
Let's see some questions based on Hashmap.
---
+
### Question
Which of the following HashMap will you use to store the population of every country?
-**Choices**
+### Choices
- [ ] HashMap -
- +- Create an array for this max-heap.
-* Here, since we are not allowed to consider pairs where i == j these diagonal elements (marked in red) will not be considered.
-* Now, as you can see the upper (blue) and lower (yellow) triangles represent the same pairs (order of pair doesn't matter here) our program would work with either one of these triangular parts.
+>
+- Create an array for this max-heap.
-* Here, since we are not allowed to consider pairs where i == j these diagonal elements (marked in red) will not be considered.
-* Now, as you can see the upper (blue) and lower (yellow) triangles represent the same pairs (order of pair doesn't matter here) our program would work with either one of these triangular parts.
+>  -*Now, considering upper triangle -*
-#### Observation:
+- Say, we extract an element, which element will we get? The Maximum!
+Now, the maximum element can be swapped with the last index. This way, maximum element will come at its correct position in sorted array.
-| i | j loops from [i...(N - 1)] |
-|:---:|:------------------------:|
-| 0 | [0..N-1] |
-| 1 | [1..N-1] |
-| 2 | [2..N-1] |
-| 3 | [3..N-1] |
-| 4 | - |
+>
-*Now, considering upper triangle -*
-#### Observation:
+- Say, we extract an element, which element will we get? The Maximum!
+Now, the maximum element can be swapped with the last index. This way, maximum element will come at its correct position in sorted array.
-| i | j loops from [i...(N - 1)] |
-|:---:|:------------------------:|
-| 0 | [0..N-1] |
-| 1 | [1..N-1] |
-| 2 | [2..N-1] |
-| 3 | [3..N-1] |
-| 4 | - |
+>  -Here for every index of i, j loops from i to N - 1
+- Now we will virtually remove the last element, which means we consider an array till the second last element of an array.
-For an `arr[i]`, the target will be `K-arr[i]`
+- Now, since the tree is not satisfying the heap order property, so we will call `heapify()` for index 0.
-#### Pseudocode:
-```kotlin
-boolean checkPair(int arr[], int K) {
+- So when we call `heapify()`, firstly 3 is swapped with 13(maximum of 13 and 10).
- int N = arr.length
- for (int i = 0; i < N; i++) {
- //target: K-arr[i]
- for (int j = i; j < N; j++) {
- if (arr[i] == K - arr[i]) {
- return true;
- }
- }
- }
- return false;
-}
+>
-Here for every index of i, j loops from i to N - 1
+- Now we will virtually remove the last element, which means we consider an array till the second last element of an array.
-For an `arr[i]`, the target will be `K-arr[i]`
+- Now, since the tree is not satisfying the heap order property, so we will call `heapify()` for index 0.
-#### Pseudocode:
-```kotlin
-boolean checkPair(int arr[], int K) {
+- So when we call `heapify()`, firstly 3 is swapped with 13(maximum of 13 and 10).
- int N = arr.length
- for (int i = 0; i < N; i++) {
- //target: K-arr[i]
- for (int j = i; j < N; j++) {
- if (arr[i] == K - arr[i]) {
- return true;
- }
- }
- }
- return false;
-}
+>  -```
+- Now again 3 is swapped with 7.
-#### Complexity
-**Time Complexity:** O(N^2)
-**Space Complexity:** O(1)
+>
-```
+- Now again 3 is swapped with 7.
-#### Complexity
-**Time Complexity:** O(N^2)
-**Space Complexity:** O(1)
+>  +- Now 3 is the maximum among 3, 2 and 1. Hence, no further swaps are needed.
+Now we have an array,
----
-### Problem 1 Optimization with HashSet(Doesn't Work)
+>
+- Now 3 is the maximum among 3, 2 and 1. Hence, no further swaps are needed.
+Now we have an array,
----
-### Problem 1 Optimization with HashSet(Doesn't Work)
+>  -* We can insert all elements in the set initially.
-* Now, iterate over every arr[i] and check if K-arr[i] is present in the set. If yes, return tue, else false.
+- As we know now a maximum of all available elements is present at root, call `extract-max()`, swap maximum element with the last index element(index 8) and then we will call heapify for the value 1.
+>
-* We can insert all elements in the set initially.
-* Now, iterate over every arr[i] and check if K-arr[i] is present in the set. If yes, return tue, else false.
+- As we know now a maximum of all available elements is present at root, call `extract-max()`, swap maximum element with the last index element(index 8) and then we will call heapify for the value 1.
+>  -
- +- 1 is swapped with 10, then swapped with 8, after that 1 will reach to its correct position.
+>
+- 1 is swapped with 10, then swapped with 8, after that 1 will reach to its correct position.
+>  ----
-**ISSUE: (Edge Case)**
+- Again extract the maximum and swap it with the last(7th) index element. Then call Heapify for it.
-* For even K value, say arr[i] is K/2 and only one occurrence of it is present.
-* Eg: A[] = {8, 9, 2, -1, 4, 5, 11, -6, 4}; K=4, we will end up considering 2(present at index 2) two times.
+In this way, repeat these steps we completed with all the elements of the tree.
-
----
-**ISSUE: (Edge Case)**
+- Again extract the maximum and swap it with the last(7th) index element. Then call Heapify for it.
-* For even K value, say arr[i] is K/2 and only one occurrence of it is present.
-* Eg: A[] = {8, 9, 2, -1, 4, 5, 11, -6, 4}; K=4, we will end up considering 2(present at index 2) two times.
+In this way, repeat these steps we completed with all the elements of the tree.
- +## Sort an Array PseudoCode
+### PseudoCode
+```cpp=
+Build max-heap ---> TC:O(N)
+j = N - 1;
+while(j > 0){
+ swap(A[0], A[j]);
+ j--;
+ heapify(0, arr[], j)
+}
+```
-We can see the above logic isn't working
+### Complexity
-### Resolution:
-We need not insert all elements into set at once. Rather only insert from [0, i - 1].
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(1), we are not taking an extra array, we are converting the max heap into sorted array.
----
-### Problem 1 Optimization with HashSet(Works)
+### Is heap sort an in-place sorting algorithm?
+**Answer:** Yes it is in-place as we are sorting an array using heap sort in constant time in the above question.
-At ith index: Hashset should contain all the elements:[0...i - 1]
+### Is heap sort a stable sorting algorithm?
+**Answer:** No heap sort is not stable.
+**Explanation:** Heap sort is not stable because operations in the heap can change the relative order of equivalent keys.
-Let's take an example,
+---
-
+## Sort an Array PseudoCode
+### PseudoCode
+```cpp=
+Build max-heap ---> TC:O(N)
+j = N - 1;
+while(j > 0){
+ swap(A[0], A[j]);
+ j--;
+ heapify(0, arr[], j)
+}
+```
-We can see the above logic isn't working
+### Complexity
-### Resolution:
-We need not insert all elements into set at once. Rather only insert from [0, i - 1].
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(1), we are not taking an extra array, we are converting the max heap into sorted array.
----
-### Problem 1 Optimization with HashSet(Works)
+### Is heap sort an in-place sorting algorithm?
+**Answer:** Yes it is in-place as we are sorting an array using heap sort in constant time in the above question.
-At ith index: Hashset should contain all the elements:[0...i - 1]
+### Is heap sort a stable sorting algorithm?
+**Answer:** No heap sort is not stable.
+**Explanation:** Heap sort is not stable because operations in the heap can change the relative order of equivalent keys.
-Let's take an example,
+---
- +## Problem 2 kth Largest Element
+### Problem Statement
+Given arr[N], find the kth largest element.
-* Initially set is empty.
-* For every element at ith index, search for target (arr[i] - K) in set.
-* If found, it means it must have been previously inserted. If not, we'll insert arr[i], because in future if we'll find a pair, we'll be able to get the current element.
-Let's take another example,
+### Example
+**Input:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
-
+## Problem 2 kth Largest Element
+### Problem Statement
+Given arr[N], find the kth largest element.
-* Initially set is empty.
-* For every element at ith index, search for target (arr[i] - K) in set.
-* If found, it means it must have been previously inserted. If not, we'll insert arr[i], because in future if we'll find a pair, we'll be able to get the current element.
-Let's take another example,
+### Example
+**Input:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
- +**Output:**
+7
+**Explanation:**
+In the above array,
+- First largest element = 9
+- Second largest element = 8
+- Third largest element = 7
+We need to return the third largest element.
-#### Pseudocode:
-```kotlin
-boolean targetSum(int arr[], int K) {
- int N = arr.length;
- Hashset < int > bs;
- for (int i = 0; i < N; i++) {
- //target = K - arr[i]
- if (bs.contains(K - arr[i])) {
- return true;
- } else {
- bs.add(arr[i]);
- }
- }
- return false;
-}
-```
---
+
### Question
-Count pairs(i, j) such that, arr[i] + arr[j] == K && i != j in the given array.
-A = [3, 5, 1, 2, 1, 2] and K = 3.
+What is the 5th largest element of an array `[1, 2, 3, 4, 5]`?
-**Choices**
-- [ ] 1
-- [ ] 2
-- [ ] 3
-- [x] 4
+### Choices
+- [ ] 5
+- [ ] 3
+- [x] 1
+- [ ] 2
-In the given array A = [3, 5, 1, 2, 1, 2], pairs with sum = 3 are:
+### Explanation
+In the above array,
+- First largest element = 5
+- Second largest element = 4
+- Third largest element = 3
+- Fourth largest element = 2
+- Fifth largest element = 1
-| Pairs |
-| ------ |
-| {2, 3} |
-| {2, 5} |
-| {3, 4} |
+We need to return the fifth largest element.
---
-### Problem 2 Count no. of pairs with sum K
-Given an `arr[n]`, count number of pairs such that
-```kotlin
-arr[i] + arr[j] = K && i != j
-```
+## kth Largest Element solution approach
-**Example**
+### :bulb: Idea 1(by sorting)
+Sort an array and simply return arr[N-K].
-Provided we have an arr[8] and K = 10, we have
-| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
-|:------:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
-| arr[8] | 2 | 5 | 2 | 5 | 8 | 5 | 2 | 8 |
+**Example:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
-**Pairs:**
+**Solution**
+Sort an array, [1, 2, 4, 5, 7, 8, 9]
+Now return arr[N-K] element i.e. arr[7-3] = arr[4] = 7
-| Pairs: 9 |
-|:--------:|
-| {0, 4} |
-| {0, 7} |
-| {1, 5} |
-| {1, 3} |
-| {2, 4} |
-| {2, 7} |
-| {3, 5} |
-| {4, 6} |
-| {6, 7} |
+**Time Complexity:** O(NlogN), **Space Complexity:** O(1).
-Here (i, j) and (j, i) considered as same.
+### :bulb: Idea 2(Using binary search)
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
+We can find the kth largest element by applying binary search just like we have used in the kth smallest element.
+**Time Complexity:** O(Nlog(max-min))
-### Optimised Approach(Same as in previous question)
-* Similar to our previous problem, we'll be searching for our target.
-* This time we also need to consider the frequency of how many times a particular element appeared, so we shall be maintianing a map.
+### :bulb: Idea 3(Using heap sort)
+1. Build a max-heap.
+2. Call extract-max() k-1 times to remove K-1 elements(for first largest we need zero removals, for second largest we need 1 removal, in this way for kth largest we need k-1 removals)
+### Complexity
+**Time Complexity:** O(N + KlogN)
+**Space Complexity:** O(1)
-
+**Output:**
+7
+**Explanation:**
+In the above array,
+- First largest element = 9
+- Second largest element = 8
+- Third largest element = 7
+We need to return the third largest element.
-#### Pseudocode:
-```kotlin
-boolean targetSum(int arr[], int K) {
- int N = arr.length;
- Hashset < int > bs;
- for (int i = 0; i < N; i++) {
- //target = K - arr[i]
- if (bs.contains(K - arr[i])) {
- return true;
- } else {
- bs.add(arr[i]);
- }
- }
- return false;
-}
-```
---
+
### Question
-Count pairs(i, j) such that, arr[i] + arr[j] == K && i != j in the given array.
-A = [3, 5, 1, 2, 1, 2] and K = 3.
+What is the 5th largest element of an array `[1, 2, 3, 4, 5]`?
-**Choices**
-- [ ] 1
-- [ ] 2
-- [ ] 3
-- [x] 4
+### Choices
+- [ ] 5
+- [ ] 3
+- [x] 1
+- [ ] 2
-In the given array A = [3, 5, 1, 2, 1, 2], pairs with sum = 3 are:
+### Explanation
+In the above array,
+- First largest element = 5
+- Second largest element = 4
+- Third largest element = 3
+- Fourth largest element = 2
+- Fifth largest element = 1
-| Pairs |
-| ------ |
-| {2, 3} |
-| {2, 5} |
-| {3, 4} |
+We need to return the fifth largest element.
---
-### Problem 2 Count no. of pairs with sum K
-Given an `arr[n]`, count number of pairs such that
-```kotlin
-arr[i] + arr[j] = K && i != j
-```
+## kth Largest Element solution approach
-**Example**
+### :bulb: Idea 1(by sorting)
+Sort an array and simply return arr[N-K].
-Provided we have an arr[8] and K = 10, we have
-| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
-|:------:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
-| arr[8] | 2 | 5 | 2 | 5 | 8 | 5 | 2 | 8 |
+**Example:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
-**Pairs:**
+**Solution**
+Sort an array, [1, 2, 4, 5, 7, 8, 9]
+Now return arr[N-K] element i.e. arr[7-3] = arr[4] = 7
-| Pairs: 9 |
-|:--------:|
-| {0, 4} |
-| {0, 7} |
-| {1, 5} |
-| {1, 3} |
-| {2, 4} |
-| {2, 7} |
-| {3, 5} |
-| {4, 6} |
-| {6, 7} |
+**Time Complexity:** O(NlogN), **Space Complexity:** O(1).
-Here (i, j) and (j, i) considered as same.
+### :bulb: Idea 2(Using binary search)
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
+We can find the kth largest element by applying binary search just like we have used in the kth smallest element.
+**Time Complexity:** O(Nlog(max-min))
-### Optimised Approach(Same as in previous question)
-* Similar to our previous problem, we'll be searching for our target.
-* This time we also need to consider the frequency of how many times a particular element appeared, so we shall be maintianing a map.
+### :bulb: Idea 3(Using heap sort)
+1. Build a max-heap.
+2. Call extract-max() k-1 times to remove K-1 elements(for first largest we need zero removals, for second largest we need 1 removal, in this way for kth largest we need k-1 removals)
+### Complexity
+**Time Complexity:** O(N + KlogN)
+**Space Complexity:** O(1)
- +## kth Largest Element Using min-heap
+### :bulb: Idea 4(Using min-heap)
-### Pseudocode:
-```kotlin
-int countTargetSum(int arr[], int K) {
- int N = arr.length;
- Hashmap < int, int > hm;
+Let us take an example, we want to create a cricket team of 4 batsmen and we have 8 batsmen i.e. b1, b2, b3, b4, b5, b6, b7 and b8, and every batsman is given only 1 over and everyone tries to achieve maximum run in that over.
- int c = 0;
+Firstly, 4 batsmen played and scored
+|b1|b2|b3|b4|
+|-|-|-|-|
+|12|8|4|6|
- for (int i = 0; i < n; i++) {
- //target = K-arr[i]
- if (hm.contains(K - arr[i])) {
- c = c + hm[K - arr[i]] //freq of target = pairs
- }
+We have recently incorporated four batsmen into our team with respective scores of **`12, 8, 4, and 6`**. When batsman **`B5 joins, scoring 7`**, we opt to replace the player with the lowest score to maintain team quality. Since we use a min heap to track scores, we **`remove the batsman with a score of 4 and include B5`**, updating our heap to **[12, 8, 7, 6]**.
- //insert arr[i]
- if (hm.contains(arr[i])) {
- hm[arr[i]]++;
- } else {
- hm.put(arr[i], 1);
- }
- }
- return c;
-}
+Later, batsman **`B6 arrives, earning 3 runs`**. However, his score **`doesn't surpass our team's minimum`**, so he isn't added. Then, batsman **`B7 steps in, scoring a notable 10 runs`**. Outperforming our lowest score, **`B7's addition leads us to drop the current minimum`** scorer and update the heap to **[12, 8, 7, 10]**.
+
+Following this, batsman **`B8 enters with a score of 9`**. Exceeding the lowest score in our lineup, we **`incorporate B8 by removing the now lowest scorer`**, refining our heap to **[12, 8, 9, 10]**.
+
+Thus, in this dynamic team selection process, the minimum element in our heap represents the fourth-highest score among our players.
+
+### Example:
+To find the 3rd largest element in an array using a min-heap of size 3:
+
+Given array: **`arr = [8, 5, 1, 2, 4, 9, 7] and k=3`**.
+- Initialize an empty min-heap.
+- Add the first three elements of the array to the heap: [8, 5, 1].
+- Iterate over the remaining elements. If an element is greater than the heap's minimum, remove the minimum and insert the new element.
+- After processing elements 2, 4, 9, and 7, the heap evolves as follows:
+ - [8, 5, 2] (after adding 2)
+ - [8, 5, 4] (after adding 4)
+ - [8, 5, 9] (after adding 9)
+ - [8, 7, 9] (after adding 7)
+- The 3rd largest element is the minimum in the heap: 7.
+
+### PseudoCode
+```cpp=
+Build min-heap with first k elements. -> O(K)
+Iterate on the remaining elements. -> (N-K)
+ for every element, check
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ }
+ans = getMin()
```
### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+- **Time Complexity:** O(K+(N-K)logK)
+- **Space Complexity:** O(K)
+
+:bulb: What should we use for finding k-th smallest?
+- A max-heap of size K.
+
----
-### Problem 3 Subarray with Sum K
-Given an array arr[n] check if there exists a subarray with sum = K
-### Example:
-We have the following array
+## Problem 2 kth Largest Element for all windows
-| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
-|:------:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
-| arr[7] | 2 | 3 | 9 | -4 | 1 | 5 | 6 | 2 | 5 |
+### Problem Statement
+Find the kth largest element for all the windows of an array starting from 0 index.
-Possible subarrays for the following values of K are,
-* k = 11: {2 3 9 -4 1}, {5, 6}
-* k = 10: {2 3 9 -4}
-* k = 15: {-4, 1, 5, 6, 2, 5}
+### Example
+**Input:**
+arr[] = `[10, 18, 7, 5, 16, 19, 3]`
+k = 3
+
+
+**Solution:**
+
+- We need atleast 3 elements in a window, so we will consider first window from index 0 to k-1, we have elements in that `[10, 18, 7]`; third largest is 7, ans=`[7]`.
+- Window 0 to 3 `[10, 18, 7, 5]`,third largest = 7, ans=`[7, 7]`.
+- Window 0 to 4 `[10, 18, 7, 5, 16]`,third largest = 10, ans=`[7, 7, 10]`.
+- Window 0 to 5 `[10, 18, 7, 5, 16, 19]`,third largest = 16, ans=`[7, 7, 10, 16]`.
+- Window 0 to 6 `[10, 18, 7, 5, 16, 19, 3]`,third largest = 16, ans=`[7, 7, 10, 16, 16]`.
---
+
### Question
-Check if there exist a subarray with sum = 110 in the given array?
-A = [ 5, 10, 20, 100, 105 ]
-
+Find the kth largest element for all the windows of an array starting from 0 index.
-**Choices**
-- [x] No
-- [ ] YES
+arr[] = `[5, 4, 1, 6, 7]`
+k = 2
+### Choices
+- [x] [4, 4, 5, 6]
+- [ ] [6, 6, 6, 6]
+- [ ] [5, 4, 1, 6]
+- [ ] [4, 1, 6, 7]
----
-### Approach
-To get subarray sum for any subarray in constant time, we can create a prefix sum array.
-Now, a subarray sum `PF[i] - PF[j]` should be equal to `K`
-OR
-**a - b = K**
+### Explanation:
+To find the second largest element in each window of a given size in an array:
-We can fix `a` and get the corresponding pair for it, given by `a - K`
+- Start with the first window (from index 0 to k-1). For example, in [5, 4], the second largest is 4. Answer array starts as [4].
+- Shift the window one element at a time and find the second largest in each new window.
+ - Window [5, 4, 1] gives second largest 4. Answer array becomes [4, 4].
+ - Window [5, 4, 1, 6] gives second largest 5. Answer array becomes [4, 4, 5].
+ - Window [5, 4, 1, 6, 7] gives second largest 6. Answer array becomes [4, 4, 5, 6].
-> We can create a HashSet at the time of traversal simultaneously
-> Here, instead of creating prefix sum initially, we are calculating it while iterating through the array.
+---
-
+## kth Largest Element Using min-heap
+### :bulb: Idea 4(Using min-heap)
-### Pseudocode:
-```kotlin
-int countTargetSum(int arr[], int K) {
- int N = arr.length;
- Hashmap < int, int > hm;
+Let us take an example, we want to create a cricket team of 4 batsmen and we have 8 batsmen i.e. b1, b2, b3, b4, b5, b6, b7 and b8, and every batsman is given only 1 over and everyone tries to achieve maximum run in that over.
- int c = 0;
+Firstly, 4 batsmen played and scored
+|b1|b2|b3|b4|
+|-|-|-|-|
+|12|8|4|6|
- for (int i = 0; i < n; i++) {
- //target = K-arr[i]
- if (hm.contains(K - arr[i])) {
- c = c + hm[K - arr[i]] //freq of target = pairs
- }
+We have recently incorporated four batsmen into our team with respective scores of **`12, 8, 4, and 6`**. When batsman **`B5 joins, scoring 7`**, we opt to replace the player with the lowest score to maintain team quality. Since we use a min heap to track scores, we **`remove the batsman with a score of 4 and include B5`**, updating our heap to **[12, 8, 7, 6]**.
- //insert arr[i]
- if (hm.contains(arr[i])) {
- hm[arr[i]]++;
- } else {
- hm.put(arr[i], 1);
- }
- }
- return c;
-}
+Later, batsman **`B6 arrives, earning 3 runs`**. However, his score **`doesn't surpass our team's minimum`**, so he isn't added. Then, batsman **`B7 steps in, scoring a notable 10 runs`**. Outperforming our lowest score, **`B7's addition leads us to drop the current minimum`** scorer and update the heap to **[12, 8, 7, 10]**.
+
+Following this, batsman **`B8 enters with a score of 9`**. Exceeding the lowest score in our lineup, we **`incorporate B8 by removing the now lowest scorer`**, refining our heap to **[12, 8, 9, 10]**.
+
+Thus, in this dynamic team selection process, the minimum element in our heap represents the fourth-highest score among our players.
+
+### Example:
+To find the 3rd largest element in an array using a min-heap of size 3:
+
+Given array: **`arr = [8, 5, 1, 2, 4, 9, 7] and k=3`**.
+- Initialize an empty min-heap.
+- Add the first three elements of the array to the heap: [8, 5, 1].
+- Iterate over the remaining elements. If an element is greater than the heap's minimum, remove the minimum and insert the new element.
+- After processing elements 2, 4, 9, and 7, the heap evolves as follows:
+ - [8, 5, 2] (after adding 2)
+ - [8, 5, 4] (after adding 4)
+ - [8, 5, 9] (after adding 9)
+ - [8, 7, 9] (after adding 7)
+- The 3rd largest element is the minimum in the heap: 7.
+
+### PseudoCode
+```cpp=
+Build min-heap with first k elements. -> O(K)
+Iterate on the remaining elements. -> (N-K)
+ for every element, check
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ }
+ans = getMin()
```
### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+- **Time Complexity:** O(K+(N-K)logK)
+- **Space Complexity:** O(K)
+
+:bulb: What should we use for finding k-th smallest?
+- A max-heap of size K.
+
----
-### Problem 3 Subarray with Sum K
-Given an array arr[n] check if there exists a subarray with sum = K
-### Example:
-We have the following array
+## Problem 2 kth Largest Element for all windows
-| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
-|:------:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
-| arr[7] | 2 | 3 | 9 | -4 | 1 | 5 | 6 | 2 | 5 |
+### Problem Statement
+Find the kth largest element for all the windows of an array starting from 0 index.
-Possible subarrays for the following values of K are,
-* k = 11: {2 3 9 -4 1}, {5, 6}
-* k = 10: {2 3 9 -4}
-* k = 15: {-4, 1, 5, 6, 2, 5}
+### Example
+**Input:**
+arr[] = `[10, 18, 7, 5, 16, 19, 3]`
+k = 3
+
+
+**Solution:**
+
+- We need atleast 3 elements in a window, so we will consider first window from index 0 to k-1, we have elements in that `[10, 18, 7]`; third largest is 7, ans=`[7]`.
+- Window 0 to 3 `[10, 18, 7, 5]`,third largest = 7, ans=`[7, 7]`.
+- Window 0 to 4 `[10, 18, 7, 5, 16]`,third largest = 10, ans=`[7, 7, 10]`.
+- Window 0 to 5 `[10, 18, 7, 5, 16, 19]`,third largest = 16, ans=`[7, 7, 10, 16]`.
+- Window 0 to 6 `[10, 18, 7, 5, 16, 19, 3]`,third largest = 16, ans=`[7, 7, 10, 16, 16]`.
---
+
### Question
-Check if there exist a subarray with sum = 110 in the given array?
-A = [ 5, 10, 20, 100, 105 ]
-
+Find the kth largest element for all the windows of an array starting from 0 index.
-**Choices**
-- [x] No
-- [ ] YES
+arr[] = `[5, 4, 1, 6, 7]`
+k = 2
+### Choices
+- [x] [4, 4, 5, 6]
+- [ ] [6, 6, 6, 6]
+- [ ] [5, 4, 1, 6]
+- [ ] [4, 1, 6, 7]
----
-### Approach
-To get subarray sum for any subarray in constant time, we can create a prefix sum array.
-Now, a subarray sum `PF[i] - PF[j]` should be equal to `K`
-OR
-**a - b = K**
+### Explanation:
+To find the second largest element in each window of a given size in an array:
-We can fix `a` and get the corresponding pair for it, given by `a - K`
+- Start with the first window (from index 0 to k-1). For example, in [5, 4], the second largest is 4. Answer array starts as [4].
+- Shift the window one element at a time and find the second largest in each new window.
+ - Window [5, 4, 1] gives second largest 4. Answer array becomes [4, 4].
+ - Window [5, 4, 1, 6] gives second largest 5. Answer array becomes [4, 4, 5].
+ - Window [5, 4, 1, 6, 7] gives second largest 6. Answer array becomes [4, 4, 5, 6].
-> We can create a HashSet at the time of traversal simultaneously
-> Here, instead of creating prefix sum initially, we are calculating it while iterating through the array.
+---
- +### kth Largest Element for all windows Idea
+To find the k-largest elements in an array using a min-heap:
+- **Initialize Min-Heap**: Start with a min-heap and add the first k elements from the array to it.
+- **Compare and Update**: For each remaining array element, if it's larger than the heap's minimum, replace the minimum with this element.
+- **Track Minimums**: After each update, record the heap's minimum. This shows the evolving k-th largest element.
-
-**Edge case:**
-If subarray from index 0 has sum = K.
-Say, K = 10
-a = 10, b = 10-10=0, now 0 won't be present in the array.
-Please take below example:
+### Pseudocode
+```java
+Build min-heap with first K elements. -> O(K)
+ans.add(extractMin())
+
+Iterate on the remaining elements. -> (N-K)
+ for every element, check {
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ ans.add(extractMin())
+ }
+ }
+```
-
+### kth Largest Element for all windows Idea
+To find the k-largest elements in an array using a min-heap:
+- **Initialize Min-Heap**: Start with a min-heap and add the first k elements from the array to it.
+- **Compare and Update**: For each remaining array element, if it's larger than the heap's minimum, replace the minimum with this element.
+- **Track Minimums**: After each update, record the heap's minimum. This shows the evolving k-th largest element.
-
-**Edge case:**
-If subarray from index 0 has sum = K.
-Say, K = 10
-a = 10, b = 10-10=0, now 0 won't be present in the array.
-Please take below example:
+### Pseudocode
+```java
+Build min-heap with first K elements. -> O(K)
+ans.add(extractMin())
+
+Iterate on the remaining elements. -> (N-K)
+ for every element, check {
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ ans.add(extractMin())
+ }
+ }
+```
- -**To resolve this, take 0 in the set initially.**
+## Flipkart's Delivery Time Estimation Challenge
-
-**To resolve this, take 0 in the set initially.**
+## Flipkart's Delivery Time Estimation Challenge
- +*Flipkart is currently dealing with the difficulty of precisely estimating and displaying the expected delivery time for orders to a specific pin code.*
+*The existing method relies on historical delivery time data for that pin code, using the median value as the expected delivery time.*
-#### Pseudocode:
-```kotlin
-boolean targetSubarray(int arr[], int K) {
- int N = arr.length;
- long a = 0;
+*As the order history expands with new entries, Flipkart aims to enhance this process by dynamically updating the expected delivery time whenever a new delivery time is added. The objective is to find the expected delivery time after each new element is incorporated into the list of delivery times.*
- //cumulative sum, long -> to avoid overflow
- HashSet < long > hs;
- hs.add(0);
- for (int i = 0; i < N; i++) {
- a = a + arr[i];
+**End Goal:** With every addition of new delivery time, requirement is to find the median value.
- //cumulative sum = target = a - k
- if (hs.contains(a - K)) {
- //subarray exists
- return true;
- } else {
- hs.add(a);
+**Why Median ?**
+The median is calculated because it provides a more robust measure of the expected delivery time
- }
+The median is less sensitive to outliers or extreme values than the mean. In the context of delivery times, this is crucial because occasional delays or unusually fast deliveries (outliers) can skew the mean significantly, leading to inaccurate estimations.
- }
- return false;
-}
+---
-```
+## Problem 3 Find the median
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+### Problem Statement
+Given an infinite stream of integers. Find the median of the current set of elements
+>### Median
+>Median is the Middle element in a sorted array.
+
+>The median of [1, 2, 5, 4, 3, 6]
+First, we need to sort an array [1, 2, 3, 4, 5, 6]
+We have two middle values as the size of the array is even i.e. 3, 4.
+So to find the median, we need to take the average of both middle values, median = (3+4)/2 = 3.5
---
-### Problem 4 Distinct elements in every window of size K
-Given an array of integers and a number, K. Find the count of distinct elements in every window of size K in the array.
-**Example**
+### Question
-```java
-// Input:
-Array = [1, 2, 1, 3, 4, 2, 3]
-K = 4
+The median of [1, 2, 4, 3]
-// Output:
-[3, 4, 4, 3]
-```
+### Choices
-- In the first window `[1, 2, 1, 3]`, there are 3 distinct elements: 1, 2, and 3.
-- In the second window `[2, 1, 3, 4]`, there are 4 distinct elements: 2, 1, 3, and 4.
-- In the third window `[1, 3, 4, 2]`, there are again 4 distinct elements: 1, 3, 4, and 2.
-- In the fourth window `[3, 4, 2, 3]`, there are 3 distinct elements: 3, 4, and 2.
+- [ ] 2
+- [ ] 4
+- [ ] 3
+- [x] 2.5
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+### Explanation:
-#### Approach - Using HashSet
+The median of [1, 2, 4, 3]
+First, we need to sort an array [1, 2, 3, 4]
+We have two middle values as the size of the array is even i.e. 2, 3.
+So to find the median, we need to take the average of both middle values,
-- The code iterates through each possible window of size K in the given array.
-- For each window, a temporary HashSet (`distinctSet`) is created to store the distinct elements within that window.
-- Within the inner loop, the code adds each element of the window to the HashSet.
-- After processing the entire window, the size of the HashSet is calculated using `distinctSet.size()`, which represents the count of distinct elements.
-- The count is then added to the result list.
-- This process is repeated for all possible windows in the array.
-- The result list contains the count of distinct elements in each window
+Median = (2+3)/2 = 2.5
-#### Pseudocode
-```java
-//Pseudo code for 'countDistinctElements' function
-function countDistinctElements(arr, k):
- result = empty list
- for i = 0 to length of arr - k:
- distinctSet = empty set
+---
- for j = i to i + k - 1:
- add arr[j] to distinctSet
+## Find the median Brute Force Approach
- add size of distinctSet to result
+### Understanding the question
+We have an infinite stream of elements.
+1. First we have one element.
+6, then median = 6.
+2. Next element if 3
+6, 3, then median = 4.5
+3. 6, 3, 8, then median = 6
+4. 6, 3, 8, 11, then median = 7
+5. 6, 3, 8, 11, 10 then median = 8
- return result
-```
-#### Complexity
-**Time Complexity:** `O((N-K+1) * K)`
+### Brute Force Idea
+For every incoming value, include the value and sort an array. Find the middle point/average of 2 middle points.
+**Time Complexity:** O(N^2^logN)
-Considering the values of `K` as N/2, 1, and N.
-**When K = N/2:**
- If `K` is about half of `N`, then the expression simplifies to `O((N/2 + 1) * N/2)`, which further simplifies to `O((N^2 + N) / 4)`. In this case, the primary factor is `N^2`, leading to a time complexity of approximately `O(N^2)`.
-**When K = 1:**
- When `K` is set to 1, the expression becomes `O((N - 1 + 1) * 1)`, which straightforwardly simplifies to `O(N)`. It's important to note that this doesn't align with the original statement of the time complexity being `O(N^2)`.
-**When K = N:**
- If `K` is equal to `N`, then the expression becomes `O((N - N + 1) * N)`, which further simplifies to `O(N^2)`.
-
-**Space Complexity:** O(K)
----
-### Problem 4 Sliding Window - Map
+## Find the median solution approach
-Sliding Window suggests to insert all elements of the first window in the set. Now slide the window, throw the prev element out and insert new adjacent element in the set.
+### Idea(Using Insertion Sort)
+Every time find the correct position of the upcoming element i.e. Insertion Sort
-But we can't use Set here, since it is possible that the element just thrown out may be present in the current window.
+**Time Complexity:** O(N^2^)
-We will also need to maintain the frequency of elements, hence we will use Hashmap.
+### Idea(Using heap)
-- Maintain a HashMap to track the frequency of elements within the current subarray.
-- Initially, the algorithm populates the HashMap with the elements of the first subarray, counting distinct elements.
-- Then, as the window slides one step at a time:
- - The algorithm updates the HashMap by updating frequency of the element leaving the window and increasing frequency of the new element entering the window.
-- The distinct element count for each subarray is determined by the size of the HashMap.
+To find the median in an array by dividing it into two parts - one with smaller elements and the other with larger elements:
-#### Pseudocode
+Consider an array, **`for example, [6, 3, 8, 11]`**. We divide it such that **`6, 3 are on the smaller side`** and **`8, 11 on the larger side`**, as shown in the image:
+
+*Flipkart is currently dealing with the difficulty of precisely estimating and displaying the expected delivery time for orders to a specific pin code.*
+*The existing method relies on historical delivery time data for that pin code, using the median value as the expected delivery time.*
-#### Pseudocode:
-```kotlin
-boolean targetSubarray(int arr[], int K) {
- int N = arr.length;
- long a = 0;
+*As the order history expands with new entries, Flipkart aims to enhance this process by dynamically updating the expected delivery time whenever a new delivery time is added. The objective is to find the expected delivery time after each new element is incorporated into the list of delivery times.*
- //cumulative sum, long -> to avoid overflow
- HashSet < long > hs;
- hs.add(0);
- for (int i = 0; i < N; i++) {
- a = a + arr[i];
+**End Goal:** With every addition of new delivery time, requirement is to find the median value.
- //cumulative sum = target = a - k
- if (hs.contains(a - K)) {
- //subarray exists
- return true;
- } else {
- hs.add(a);
+**Why Median ?**
+The median is calculated because it provides a more robust measure of the expected delivery time
- }
+The median is less sensitive to outliers or extreme values than the mean. In the context of delivery times, this is crucial because occasional delays or unusually fast deliveries (outliers) can skew the mean significantly, leading to inaccurate estimations.
- }
- return false;
-}
+---
-```
+## Problem 3 Find the median
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+### Problem Statement
+Given an infinite stream of integers. Find the median of the current set of elements
+>### Median
+>Median is the Middle element in a sorted array.
+
+>The median of [1, 2, 5, 4, 3, 6]
+First, we need to sort an array [1, 2, 3, 4, 5, 6]
+We have two middle values as the size of the array is even i.e. 3, 4.
+So to find the median, we need to take the average of both middle values, median = (3+4)/2 = 3.5
---
-### Problem 4 Distinct elements in every window of size K
-Given an array of integers and a number, K. Find the count of distinct elements in every window of size K in the array.
-**Example**
+### Question
-```java
-// Input:
-Array = [1, 2, 1, 3, 4, 2, 3]
-K = 4
+The median of [1, 2, 4, 3]
-// Output:
-[3, 4, 4, 3]
-```
+### Choices
-- In the first window `[1, 2, 1, 3]`, there are 3 distinct elements: 1, 2, and 3.
-- In the second window `[2, 1, 3, 4]`, there are 4 distinct elements: 2, 1, 3, and 4.
-- In the third window `[1, 3, 4, 2]`, there are again 4 distinct elements: 1, 3, 4, and 2.
-- In the fourth window `[3, 4, 2, 3]`, there are 3 distinct elements: 3, 4, and 2.
+- [ ] 2
+- [ ] 4
+- [ ] 3
+- [x] 2.5
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+### Explanation:
-#### Approach - Using HashSet
+The median of [1, 2, 4, 3]
+First, we need to sort an array [1, 2, 3, 4]
+We have two middle values as the size of the array is even i.e. 2, 3.
+So to find the median, we need to take the average of both middle values,
-- The code iterates through each possible window of size K in the given array.
-- For each window, a temporary HashSet (`distinctSet`) is created to store the distinct elements within that window.
-- Within the inner loop, the code adds each element of the window to the HashSet.
-- After processing the entire window, the size of the HashSet is calculated using `distinctSet.size()`, which represents the count of distinct elements.
-- The count is then added to the result list.
-- This process is repeated for all possible windows in the array.
-- The result list contains the count of distinct elements in each window
+Median = (2+3)/2 = 2.5
-#### Pseudocode
-```java
-//Pseudo code for 'countDistinctElements' function
-function countDistinctElements(arr, k):
- result = empty list
- for i = 0 to length of arr - k:
- distinctSet = empty set
+---
- for j = i to i + k - 1:
- add arr[j] to distinctSet
+## Find the median Brute Force Approach
- add size of distinctSet to result
+### Understanding the question
+We have an infinite stream of elements.
+1. First we have one element.
+6, then median = 6.
+2. Next element if 3
+6, 3, then median = 4.5
+3. 6, 3, 8, then median = 6
+4. 6, 3, 8, 11, then median = 7
+5. 6, 3, 8, 11, 10 then median = 8
- return result
-```
-#### Complexity
-**Time Complexity:** `O((N-K+1) * K)`
+### Brute Force Idea
+For every incoming value, include the value and sort an array. Find the middle point/average of 2 middle points.
+**Time Complexity:** O(N^2^logN)
-Considering the values of `K` as N/2, 1, and N.
-**When K = N/2:**
- If `K` is about half of `N`, then the expression simplifies to `O((N/2 + 1) * N/2)`, which further simplifies to `O((N^2 + N) / 4)`. In this case, the primary factor is `N^2`, leading to a time complexity of approximately `O(N^2)`.
-**When K = 1:**
- When `K` is set to 1, the expression becomes `O((N - 1 + 1) * 1)`, which straightforwardly simplifies to `O(N)`. It's important to note that this doesn't align with the original statement of the time complexity being `O(N^2)`.
-**When K = N:**
- If `K` is equal to `N`, then the expression becomes `O((N - N + 1) * N)`, which further simplifies to `O(N^2)`.
-
-**Space Complexity:** O(K)
----
-### Problem 4 Sliding Window - Map
+## Find the median solution approach
-Sliding Window suggests to insert all elements of the first window in the set. Now slide the window, throw the prev element out and insert new adjacent element in the set.
+### Idea(Using Insertion Sort)
+Every time find the correct position of the upcoming element i.e. Insertion Sort
-But we can't use Set here, since it is possible that the element just thrown out may be present in the current window.
+**Time Complexity:** O(N^2^)
-We will also need to maintain the frequency of elements, hence we will use Hashmap.
+### Idea(Using heap)
-- Maintain a HashMap to track the frequency of elements within the current subarray.
-- Initially, the algorithm populates the HashMap with the elements of the first subarray, counting distinct elements.
-- Then, as the window slides one step at a time:
- - The algorithm updates the HashMap by updating frequency of the element leaving the window and increasing frequency of the new element entering the window.
-- The distinct element count for each subarray is determined by the size of the HashMap.
+To find the median in an array by dividing it into two parts - one with smaller elements and the other with larger elements:
-#### Pseudocode
+Consider an array, **`for example, [6, 3, 8, 11]`**. We divide it such that **`6, 3 are on the smaller side`** and **`8, 11 on the larger side`**, as shown in the image:
+ -```java
-void subfreq(int ar[], int k) {
- int N = ar.length;
-
- HashMap < int, int > hm;
-
- // Step 1: Insert 1st subarray [0, k-1]
- for (int i = 0; i < k; i++) {
- //Increase frequecy by 1
- if (hm.contains(ar[i])) {
- int val = hm.get(ar[i]);
- hm.put(ar[i], val + 1);
- } else {
- hm.put(ar[i], 1);
- }
+To find the median:
- print(hm.size());
- }
+- If both sides have an equal number of elements, take the average of the largest element on the smaller side and the smallest element on the larger side.
+- If the sizes are unequal, choose the largest element from the smaller side if it's larger, or the smallest from the larger side otherwise.
- //step 2: Iterate all other subarrays
- int s = 1, e = k;
+**The key is to use two heaps:** a min-heap for the larger elements and a max-heap for the smaller elements. This approach maintains a balanced partition of the array for efficient median calculation.
- while (e < N) {
- //Remove ar[s-1]
- int val = hm[ar[s - 1]];
- hm[ar[s - 1]]--;
+### Example
+arr = [6, 3, 8, 11, 20, 2, 10, 8, 13, 50, _ _ _ ]
- if (hm.get[ar[s - 1]] == 0) {
- hm.remove(ar[s - 1]);
- }
+Take two heaps, min-heap and max-heap
+
-```java
-void subfreq(int ar[], int k) {
- int N = ar.length;
-
- HashMap < int, int > hm;
-
- // Step 1: Insert 1st subarray [0, k-1]
- for (int i = 0; i < k; i++) {
- //Increase frequecy by 1
- if (hm.contains(ar[i])) {
- int val = hm.get(ar[i]);
- hm.put(ar[i], val + 1);
- } else {
- hm.put(ar[i], 1);
- }
+To find the median:
- print(hm.size());
- }
+- If both sides have an equal number of elements, take the average of the largest element on the smaller side and the smallest element on the larger side.
+- If the sizes are unequal, choose the largest element from the smaller side if it's larger, or the smallest from the larger side otherwise.
- //step 2: Iterate all other subarrays
- int s = 1, e = k;
+**The key is to use two heaps:** a min-heap for the larger elements and a max-heap for the smaller elements. This approach maintains a balanced partition of the array for efficient median calculation.
- while (e < N) {
- //Remove ar[s-1]
- int val = hm[ar[s - 1]];
- hm[ar[s - 1]]--;
+### Example
+arr = [6, 3, 8, 11, 20, 2, 10, 8, 13, 50, _ _ _ ]
- if (hm.get[ar[s - 1]] == 0) {
- hm.remove(ar[s - 1]);
- }
+Take two heaps, min-heap and max-heap
+ - //add ar[e]
- if (hm.contains(ar[e])) {
- //Inc freq by 1
- int val = hm[ar[e]];
- hm[ar[e]]++;
- } else {
- hm.put(ar[e], 1);
- }
+Smaller side elements are stored in max-heap and Greater side elements are stored in min-heap
- print(hm.size());
- s++
- }
-}
+1. First element is 6, simply add it in max-heap
+
- //add ar[e]
- if (hm.contains(ar[e])) {
- //Inc freq by 1
- int val = hm[ar[e]];
- hm[ar[e]]++;
- } else {
- hm.put(ar[e], 1);
- }
+Smaller side elements are stored in max-heap and Greater side elements are stored in min-heap
- print(hm.size());
- s++
- }
-}
+1. First element is 6, simply add it in max-heap
+ +**The median is 6.**
+
+
+2. Second element is 3; compare with h1.getMax(), if 3<6 then it must be included in h1.
+
+**The median is 6.**
+
+
+2. Second element is 3; compare with h1.getMax(), if 3<6 then it must be included in h1.
+ +but now both the heaps do not have half-half elements. Remove the maximum element from max-heap and insert it into h2.
+
+but now both the heaps do not have half-half elements. Remove the maximum element from max-heap and insert it into h2.
+ +Now we have an equal number of elements in both heaps, so the median is the average of the largest value of h1 and the smallest value of h2.
+**Median is 4.5**
+
+
+3. Next element is 8.
+Compare it with h1.getMax(), 8>3 so 8 will go to h2.
+
+Now we have an equal number of elements in both heaps, so the median is the average of the largest value of h1 and the smallest value of h2.
+**Median is 4.5**
+
+
+3. Next element is 8.
+Compare it with h1.getMax(), 8>3 so 8 will go to h2.
+ +size(h2) is greater by 1
+**Median is 6**
+
+
+4. Next element is 11.
+Compare it with h1.getMax(), 11>3 so 11 will go to h2.
+
+size(h2) is greater by 1
+**Median is 6**
+
+
+4. Next element is 11.
+Compare it with h1.getMax(), 11>3 so 11 will go to h2.
+ +But now both heap does not have nearly half elements.
+So remove the minimum element and add it to h1.
+
+But now both heap does not have nearly half elements.
+So remove the minimum element and add it to h1.
+ +**Median is average of 6,8 = (6+8)/2 = 7**
+
+
+5. Next element is 20.
+Compare it with h1.getMax(), 20>6 so 20 will go to h2.
+
+**Median is average of 6,8 = (6+8)/2 = 7**
+
+
+5. Next element is 20.
+Compare it with h1.getMax(), 20>6 so 20 will go to h2.
+ +size(h2) is greater by 1
+**The median is 8.**
+
+In this way we will do for all the elements of an array, and find the median at every step, we need to take care that the |h1.size()-h2.size()|<=1.
+After adding all the medians in an array, we will get an answer: [6, 4.5, 6, 7, 8, 7, 8, 8, 8, _ _ _ ]
+
+### PseudoCode
+```cpp
+ h1, h2
+ h1.insert(arr[0])
+ print(arr[0])
+ for(i -> 1 to N - 1){
+ if(arr[i] > h1.getMax()){
+ h2.insert(arr[i]);
+ }
+ else{
+ h1.insert(arr[i]);
+ }
+ diff = |h1.size() - h2.size()|
+ if(diff > 1){
+ if(h1.size() > h2.size()) {
+ h2.insert(h1.getMax());
+ }
+ else {
+ h1.insert(h2.getMin());
+ }
+ }
+ if(h1.size() > h2.size()){
+ print(h1.getMax());
+ }
+ else if(h2.size() > h1.size()){
+ print(h2.getMin())
+ }
+ else{
+ print((h1.getMax() + h2.getMin()) / 2.0);
+ }
+ }
```
-#### Complexity
-**Time Complexity**: `O(n)`
-**Space Complexity**: `O(n)`
+### Complexity
+
+**Time Complexity:** O(NlogN)
+**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md b/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md
index 4d84e85..8ab32ad 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md
@@ -1,12 +1,10 @@
# Hashmap Implementation
----
## Check if given element exists in Q queries
-
Given an array of size N and Q queries. In each query, an element is given. We have to check whether that element exists or not in the given array.
-**Example**
+### Example
A [ ] = {`2, 4, 11, 15 , 6, 8, 14, 9`}
@@ -16,18 +14,14 @@ A [ ] = {`2, 4, 11, 15 , 6, 8, 14, 9`}
`K = 17` (return false)
`K = 14` (return true)
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
+### Brute Force Approach
For every query, loop through the given array to check the presence.
Time Complexity - **O(N * Q)**
Space Complexity - **O(1)**
-#### Observation
+### Observation
We can create an array to mark the presence of an element against that particular index.
@@ -50,7 +44,7 @@ int dat[16] = {0}; //initally assuming an element is not present
Let's mark the presence.
```cpp
-for(int i = 0; i < N; i++) {
+for(i -> 0 to N - 1) {
dat[A[i]] = 1;
}
```
@@ -61,13 +55,13 @@ Below is how that array looks like -
| -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
-#### Advantage of using DAT
+### Advantage of using DAT
1. Time Complexity of Insertion - `O(1)`
2. Time Complexity of Deletion - `O(1)`
3. Time Complexity of Search - `O(1)`
-#### Issues with such a representation
+### Issues with such a representation
**1. Wastage of Space**
* Say array is `A[] = {23, 60, 37, 90}`; now just to store presence of 4 elements, we'll have to construct an array of `size 91`.
@@ -79,8 +73,9 @@ Below is how that array looks like -
* We'll have to make some adjustments to store negative numbers or characters. (It'll be possible but needs some work-around)
---
-### Overcome Issues while retaining Advantages
+## Overcome Issues while retaining Advantages
+### How to overcome the Issues provided we retain the advantages ?
Let's say we have restriction of creating only array of size 10.
@@ -110,7 +105,7 @@ In array of size 10, we'll have indices from 0 to 9. How can we map all the valu
| 30 | 21 | 42 | 0 | 0 | 45 | 0 | 37 | 0 | 99 |
-#### What Have We Done ?
+### What Have We Done ?
* We have basically done Hashing. Hashing is a process where we pass our data through the Hash Funtion which gives us the hash value(index) to map our data to.
* In this case, the hash function used is **MOD**. This is the simplest hash function. Usually, more complex hash functions are used.
@@ -118,7 +113,7 @@ In array of size 10, we'll have indices from 0 to 9. How can we map all the valu
-#### Issue with Hashing ?
+### Issue with Hashing ?
**COLLISION!**
@@ -149,7 +144,7 @@ Say we have 11 pigeons and we have only 8 holes to keep them. Now, provided hole
But, we can find some resolutions to collision.
---
-### Collision Resolution Techniques
+## Collision Resolution Techniques
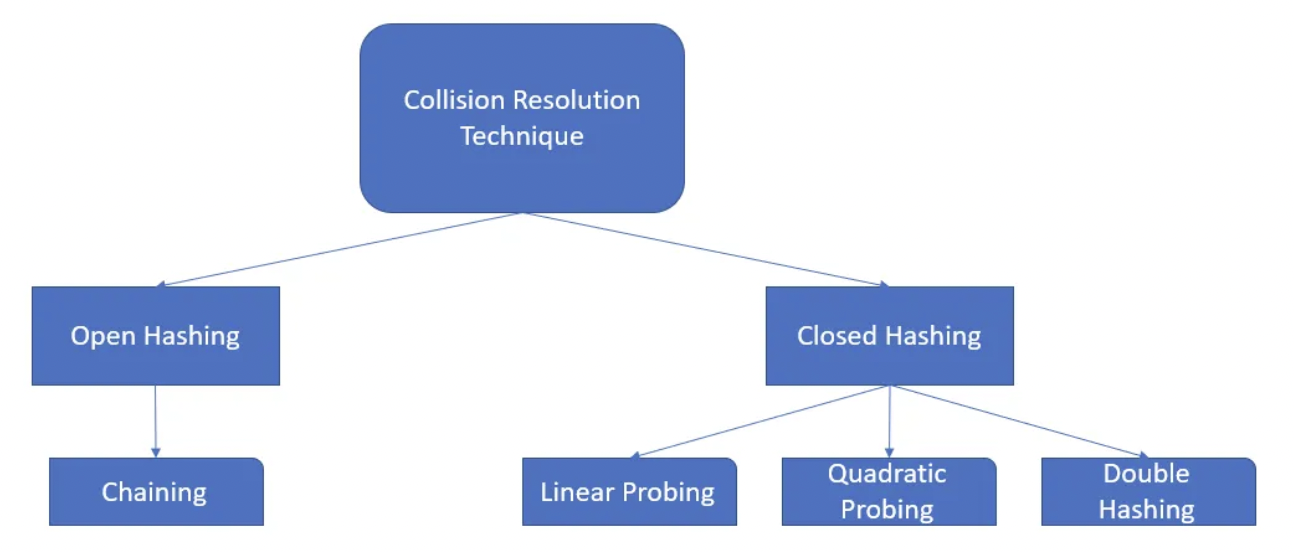
@@ -157,11 +152,10 @@ But, we can find some resolutions to collision.
>From Interview Perspective, Open Hashing is Important hence, we'll dive into that.
-
+>Whereas, please feel free to read about "Closed Hashing" if interested.
---
-### Chaining
-
+## Chaining
Let's take the above problem where collision happened!
@@ -177,7 +171,6 @@ We can somehow store both 21 & 31 at the same index.
Basically we can have a linked list at every index.
i.e, Array of Linked List
-
Every index shall have head node of Linked List.
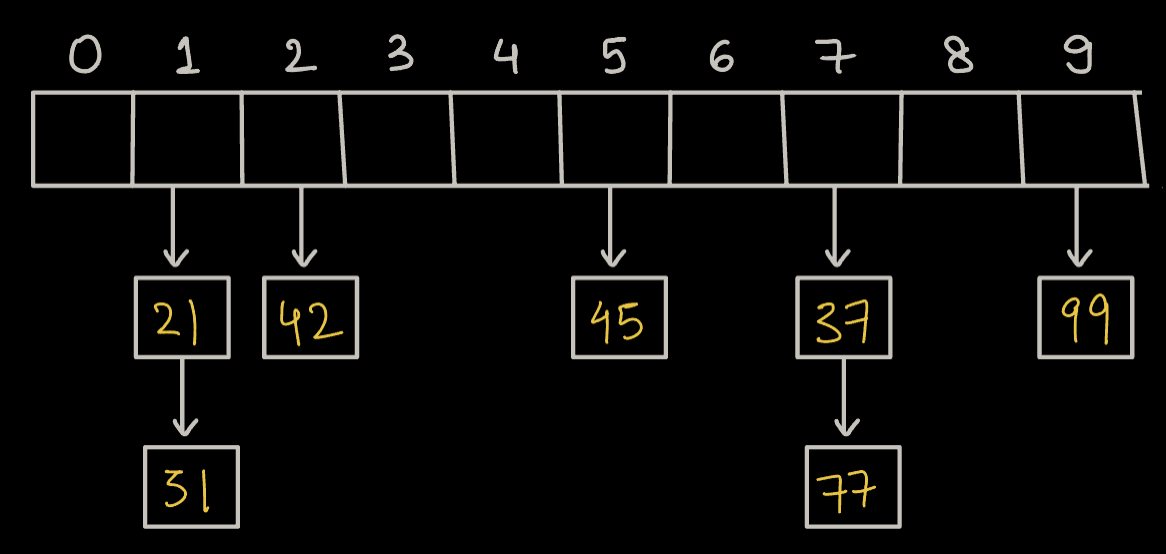
@@ -201,7 +194,7 @@ Since order of Insertion doesn't matter to us, so we can **simply insert at head
* Time Complexity in worst case is still O(N)
---
-### What is lamda
+## What is lamda
There is a lamba($\lambda$) function which is nothing but a ratio of (number of elements inserted / size of the array).
@@ -227,9 +220,10 @@ Let's assume the predefined threshold is 0.7. The load factor is exceeding this
$\lambda$ = $\frac{6}{16} = 0.375$ (within the threshold of 0.7)
---
-### Code Implementation
+## Code Implementation
-#### Declaring the HashMap Class
+
+### Declaring the HashMap Class
Let's go through the code implementation of a hashmap:
@@ -244,33 +238,33 @@ import java.util.ArrayList;
class HashMap < K, V > {
- private class HMNode {
- K key;
- V value;
+ private class HMNode {
+ K key;
+ V value;
- public HMNode(K key, V value) {
- this.key = key;
- this.value = value;
- }
+ public HMNode(K key, V value) {
+ this.key = key;
+ this.value = value;
}
+ }
- private ArrayList < HMNode > [] buckets;
- private int size; // number of key-value pairs
+ private ArrayList < HMNode > [] buckets;
+ private int size; // number of key-value pairs
- public HashMap() {
- initbuckets();
- size = 0;
- }
+ public HashMap() {
+ initbuckets();
+ size = 0;
+ }
- private void initbuckets() {
- buckets = new ArrayList[4];
- for (int i = 0; i < 4; i++) {
- buckets[i] = new ArrayList < > ();
- }
+ private void initbuckets() {
+ buckets = new ArrayList[4];
+ for (int i = 0; i < 4; i++) {
+ buckets[i] = new ArrayList<>();
}
+ }
```
-#### Put Method
+### Put Method
* The `put` method adds a key-value pair to the hashmap.
* It calculates the bucket index (`bi`) using the `hash` method and finds the data index within the bucket using `getIndexWithinBucket`.
* If the key is found in the bucket, it updates the value. Otherwise, it inserts a new node.
@@ -299,22 +293,22 @@ class HashMap < K, V > {
}
```
-#### Hash Method
+### Hash Method
* The `hash` method calculates the bucket index using the hash code of the key and takes the modulus to ensure it stays within the array size.
```java
private int hash(K key) {
- int hc = key.hashCode();
- int bi = Math.abs(hc) % buckets.length;
- return bi;
- }
+ int hc = key.hashCode();
+ int bi = Math.abs(hc) % buckets.length;
+ return bi;
+ }
```
-#### Get Index within Bucket
+### Get Index within Bucket
* The `getIndexWithinBucket` method searches for the data index (`di`) of a key within a specific bucket. It returns -1 if the key is not found
```java
private int getIndexWithinBucket(K key, int bi) {
int di = 0;
- for (HMNode node: buckets[bi]) {
+ for (HMNode node : buckets[bi]) {
if (node.key.equals(key)) {
return di; // Key found
}
@@ -324,26 +318,26 @@ class HashMap < K, V > {
}
```
-#### Rehash Method
+### Rehash Method
* The `rehash` method is called when the load factor exceeds 2.0.
* It creates a new array of buckets, initializes the size to 0, and iterates through the old buckets, reinserting each key-value pair into the new array.
*
```java
private void rehash() {
- ArrayList < HMNode > [] oldBuckets = buckets;
+ ArrayList
+size(h2) is greater by 1
+**The median is 8.**
+
+In this way we will do for all the elements of an array, and find the median at every step, we need to take care that the |h1.size()-h2.size()|<=1.
+After adding all the medians in an array, we will get an answer: [6, 4.5, 6, 7, 8, 7, 8, 8, 8, _ _ _ ]
+
+### PseudoCode
+```cpp
+ h1, h2
+ h1.insert(arr[0])
+ print(arr[0])
+ for(i -> 1 to N - 1){
+ if(arr[i] > h1.getMax()){
+ h2.insert(arr[i]);
+ }
+ else{
+ h1.insert(arr[i]);
+ }
+ diff = |h1.size() - h2.size()|
+ if(diff > 1){
+ if(h1.size() > h2.size()) {
+ h2.insert(h1.getMax());
+ }
+ else {
+ h1.insert(h2.getMin());
+ }
+ }
+ if(h1.size() > h2.size()){
+ print(h1.getMax());
+ }
+ else if(h2.size() > h1.size()){
+ print(h2.getMin())
+ }
+ else{
+ print((h1.getMax() + h2.getMin()) / 2.0);
+ }
+ }
```
-#### Complexity
-**Time Complexity**: `O(n)`
-**Space Complexity**: `O(n)`
+### Complexity
+
+**Time Complexity:** O(NlogN)
+**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md b/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md
index 4d84e85..8ab32ad 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Hashing 3 Internal Implementation & Problems.md
@@ -1,12 +1,10 @@
# Hashmap Implementation
----
## Check if given element exists in Q queries
-
Given an array of size N and Q queries. In each query, an element is given. We have to check whether that element exists or not in the given array.
-**Example**
+### Example
A [ ] = {`2, 4, 11, 15 , 6, 8, 14, 9`}
@@ -16,18 +14,14 @@ A [ ] = {`2, 4, 11, 15 , 6, 8, 14, 9`}
`K = 17` (return false)
`K = 14` (return true)
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
+### Brute Force Approach
For every query, loop through the given array to check the presence.
Time Complexity - **O(N * Q)**
Space Complexity - **O(1)**
-#### Observation
+### Observation
We can create an array to mark the presence of an element against that particular index.
@@ -50,7 +44,7 @@ int dat[16] = {0}; //initally assuming an element is not present
Let's mark the presence.
```cpp
-for(int i = 0; i < N; i++) {
+for(i -> 0 to N - 1) {
dat[A[i]] = 1;
}
```
@@ -61,13 +55,13 @@ Below is how that array looks like -
| -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
-#### Advantage of using DAT
+### Advantage of using DAT
1. Time Complexity of Insertion - `O(1)`
2. Time Complexity of Deletion - `O(1)`
3. Time Complexity of Search - `O(1)`
-#### Issues with such a representation
+### Issues with such a representation
**1. Wastage of Space**
* Say array is `A[] = {23, 60, 37, 90}`; now just to store presence of 4 elements, we'll have to construct an array of `size 91`.
@@ -79,8 +73,9 @@ Below is how that array looks like -
* We'll have to make some adjustments to store negative numbers or characters. (It'll be possible but needs some work-around)
---
-### Overcome Issues while retaining Advantages
+## Overcome Issues while retaining Advantages
+### How to overcome the Issues provided we retain the advantages ?
Let's say we have restriction of creating only array of size 10.
@@ -110,7 +105,7 @@ In array of size 10, we'll have indices from 0 to 9. How can we map all the valu
| 30 | 21 | 42 | 0 | 0 | 45 | 0 | 37 | 0 | 99 |
-#### What Have We Done ?
+### What Have We Done ?
* We have basically done Hashing. Hashing is a process where we pass our data through the Hash Funtion which gives us the hash value(index) to map our data to.
* In this case, the hash function used is **MOD**. This is the simplest hash function. Usually, more complex hash functions are used.
@@ -118,7 +113,7 @@ In array of size 10, we'll have indices from 0 to 9. How can we map all the valu
-#### Issue with Hashing ?
+### Issue with Hashing ?
**COLLISION!**
@@ -149,7 +144,7 @@ Say we have 11 pigeons and we have only 8 holes to keep them. Now, provided hole
But, we can find some resolutions to collision.
---
-### Collision Resolution Techniques
+## Collision Resolution Techniques

@@ -157,11 +152,10 @@ But, we can find some resolutions to collision.
>From Interview Perspective, Open Hashing is Important hence, we'll dive into that.
-
+>Whereas, please feel free to read about "Closed Hashing" if interested.
---
-### Chaining
-
+## Chaining
Let's take the above problem where collision happened!
@@ -177,7 +171,6 @@ We can somehow store both 21 & 31 at the same index.
Basically we can have a linked list at every index.
i.e, Array of Linked List
-
Every index shall have head node of Linked List.

@@ -201,7 +194,7 @@ Since order of Insertion doesn't matter to us, so we can **simply insert at head
* Time Complexity in worst case is still O(N)
---
-### What is lamda
+## What is lamda
There is a lamba($\lambda$) function which is nothing but a ratio of (number of elements inserted / size of the array).
@@ -227,9 +220,10 @@ Let's assume the predefined threshold is 0.7. The load factor is exceeding this
$\lambda$ = $\frac{6}{16} = 0.375$ (within the threshold of 0.7)
---
-### Code Implementation
+## Code Implementation
-#### Declaring the HashMap Class
+
+### Declaring the HashMap Class
Let's go through the code implementation of a hashmap:
@@ -244,33 +238,33 @@ import java.util.ArrayList;
class HashMap < K, V > {
- private class HMNode {
- K key;
- V value;
+ private class HMNode {
+ K key;
+ V value;
- public HMNode(K key, V value) {
- this.key = key;
- this.value = value;
- }
+ public HMNode(K key, V value) {
+ this.key = key;
+ this.value = value;
}
+ }
- private ArrayList < HMNode > [] buckets;
- private int size; // number of key-value pairs
+ private ArrayList < HMNode > [] buckets;
+ private int size; // number of key-value pairs
- public HashMap() {
- initbuckets();
- size = 0;
- }
+ public HashMap() {
+ initbuckets();
+ size = 0;
+ }
- private void initbuckets() {
- buckets = new ArrayList[4];
- for (int i = 0; i < 4; i++) {
- buckets[i] = new ArrayList < > ();
- }
+ private void initbuckets() {
+ buckets = new ArrayList[4];
+ for (int i = 0; i < 4; i++) {
+ buckets[i] = new ArrayList<>();
}
+ }
```
-#### Put Method
+### Put Method
* The `put` method adds a key-value pair to the hashmap.
* It calculates the bucket index (`bi`) using the `hash` method and finds the data index within the bucket using `getIndexWithinBucket`.
* If the key is found in the bucket, it updates the value. Otherwise, it inserts a new node.
@@ -299,22 +293,22 @@ class HashMap < K, V > {
}
```
-#### Hash Method
+### Hash Method
* The `hash` method calculates the bucket index using the hash code of the key and takes the modulus to ensure it stays within the array size.
```java
private int hash(K key) {
- int hc = key.hashCode();
- int bi = Math.abs(hc) % buckets.length;
- return bi;
- }
+ int hc = key.hashCode();
+ int bi = Math.abs(hc) % buckets.length;
+ return bi;
+ }
```
-#### Get Index within Bucket
+### Get Index within Bucket
* The `getIndexWithinBucket` method searches for the data index (`di`) of a key within a specific bucket. It returns -1 if the key is not found
```java
private int getIndexWithinBucket(K key, int bi) {
int di = 0;
- for (HMNode node: buckets[bi]) {
+ for (HMNode node : buckets[bi]) {
if (node.key.equals(key)) {
return di; // Key found
}
@@ -324,26 +318,26 @@ class HashMap < K, V > {
}
```
-#### Rehash Method
+### Rehash Method
* The `rehash` method is called when the load factor exceeds 2.0.
* It creates a new array of buckets, initializes the size to 0, and iterates through the old buckets, reinserting each key-value pair into the new array.
*
```java
private void rehash() {
- ArrayList < HMNode > [] oldBuckets = buckets;
+ ArrayList -**Example 2**:
+### Example 2:
**`Initial Ropes: [2, 5, 6, 3]`**
@@ -34,7 +35,7 @@ Final Rope: [16]
This is one of the options for finding the cost of connecting all ropes, but we need to find the minimum cost of connecting all the ropes.
-#### Observation
+### Observation
Say, we have 3 ropes, **`x < y < z`**
Which 2 ropes should we connect first ?
@@ -50,7 +51,7 @@ Comparing case 2 and 3, x and y are different, now since x < y, we can say cost
**`Conclusion:`** Connecting smaller length ropes gives us lesser cost.
-#### Process:
+### Process:
**`Initial Setup:`** Start with an array of rope lengths, e.g., [2, 2, 3, 5, 6]. First, sort the array.
@@ -71,7 +72,7 @@ We are basically applying **`insertion sort`**.
- Combine ropes 7 and 11 (cost = 18). Final rope: 18. Total cost: 40.
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2^)
**Space Complexity:** O(1)
@@ -79,15 +80,13 @@ We are basically applying **`insertion sort`**.
### Question
What is the minimum cost of connecting all the ropes for the array [1, 2, 3, 4]?
-**Choices**
+### Choices
- [x] 19
- [ ] 20
- [ ] 10
- [ ] 0
-
-
-**Explanation**:
+### Explanation:
**Always pick two of the smallest ropes and combine them.**
@@ -100,16 +99,10 @@ After combining the two smallest ropes at every step, we need to sort an array a
Final Length: 10
Total Cost = (3 + 6 + 10) = 19
-
---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
### Connecting the ropes optimisation
-
Heaps efficiently perform the necessary operations:
- Insertion of elements in **`O(log n)`** time.
@@ -123,14 +116,13 @@ Say, for above problem, we use a min heap. At every step, it will give us the 2
-**Example 2**:
+### Example 2:
**`Initial Ropes: [2, 5, 6, 3]`**
@@ -34,7 +35,7 @@ Final Rope: [16]
This is one of the options for finding the cost of connecting all ropes, but we need to find the minimum cost of connecting all the ropes.
-#### Observation
+### Observation
Say, we have 3 ropes, **`x < y < z`**
Which 2 ropes should we connect first ?
@@ -50,7 +51,7 @@ Comparing case 2 and 3, x and y are different, now since x < y, we can say cost
**`Conclusion:`** Connecting smaller length ropes gives us lesser cost.
-#### Process:
+### Process:
**`Initial Setup:`** Start with an array of rope lengths, e.g., [2, 2, 3, 5, 6]. First, sort the array.
@@ -71,7 +72,7 @@ We are basically applying **`insertion sort`**.
- Combine ropes 7 and 11 (cost = 18). Final rope: 18. Total cost: 40.
-#### Complexity
+### Complexity
**Time Complexity:** O(N^2^)
**Space Complexity:** O(1)
@@ -79,15 +80,13 @@ We are basically applying **`insertion sort`**.
### Question
What is the minimum cost of connecting all the ropes for the array [1, 2, 3, 4]?
-**Choices**
+### Choices
- [x] 19
- [ ] 20
- [ ] 10
- [ ] 0
-
-
-**Explanation**:
+### Explanation:
**Always pick two of the smallest ropes and combine them.**
@@ -100,16 +99,10 @@ After combining the two smallest ropes at every step, we need to sort an array a
Final Length: 10
Total Cost = (3 + 6 + 10) = 19
-
---
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
### Connecting the ropes optimisation
-
Heaps efficiently perform the necessary operations:
- Insertion of elements in **`O(log n)`** time.
@@ -123,14 +116,13 @@ Say, for above problem, we use a min heap. At every step, it will give us the 2
 -#### Time & Space Complexity
+### Time & Space Complexity
For every operation, we are removing 2 elements and inserting one back, hence it is 3 * log N. For N operations, **`the time complexity will be O(N * log N)`**
**`Space Complexity is O(N)`**
----
-## Heap Data Structure
+## Heap Data Structure
The heap data structure is a binary tree with two special properties.
- First property is based on structure.
- **Complete Binary Tree:** All levels are completely filled. The last level can be the exception but is should also be filled from left to right.
@@ -138,7 +130,7 @@ The heap data structure is a binary tree with two special properties.
- **Heap Order Property:** In the case of max heap, the value of the parent is greater than the value of the children. And in the case of min heap, the value of the parent is less than the value of the children.
-**Examples**
+### Examples
**`Example 1:`**
@@ -157,9 +149,7 @@ The heap data structure is a binary tree with two special properties.
- Heap Order Property is also valid at every point in the tree, as 58 is greater than 39 and 26, 39 is greater than 34 and 12, 26 is greater than 3 and 9, 34 is greater than 16 and 1.
- Hence, it is a **max-heap.**
----
-### Array Implementation of Trees(Complete Binary Tree)
-
+### Binary Heap Implementation via Array
-#### Time & Space Complexity
+### Time & Space Complexity
For every operation, we are removing 2 elements and inserting one back, hence it is 3 * log N. For N operations, **`the time complexity will be O(N * log N)`**
**`Space Complexity is O(N)`**
----
-## Heap Data Structure
+## Heap Data Structure
The heap data structure is a binary tree with two special properties.
- First property is based on structure.
- **Complete Binary Tree:** All levels are completely filled. The last level can be the exception but is should also be filled from left to right.
@@ -138,7 +130,7 @@ The heap data structure is a binary tree with two special properties.
- **Heap Order Property:** In the case of max heap, the value of the parent is greater than the value of the children. And in the case of min heap, the value of the parent is less than the value of the children.
-**Examples**
+### Examples
**`Example 1:`**
@@ -157,9 +149,7 @@ The heap data structure is a binary tree with two special properties.
- Heap Order Property is also valid at every point in the tree, as 58 is greater than 39 and 26, 39 is greater than 34 and 12, 26 is greater than 3 and 9, 34 is greater than 16 and 1.
- Hence, it is a **max-heap.**
----
-### Array Implementation of Trees(Complete Binary Tree)
-
+### Binary Heap Implementation via Array
 @@ -179,9 +169,8 @@ The heap data structure is a binary tree with two special properties.
@@ -179,9 +169,8 @@ The heap data structure is a binary tree with two special properties.
 ----
-### Insertion in min heap
+### Insertion in min heap
----
-### Insertion in min heap
+### Insertion in min heap
 @@ -190,7 +179,7 @@ The heap data structure is a binary tree with two special properties.
|5|12|20|25|13|24|22|35|
-**Example 1**: Insert 10
+### Example 1: Insert 10
In an array, if we will insert 10 at index 8, then our array becomes,
@@ -252,7 +241,7 @@ Now this tree satisfies the min-heap order property.
@@ -190,7 +179,7 @@ The heap data structure is a binary tree with two special properties.
|5|12|20|25|13|24|22|35|
-**Example 1**: Insert 10
+### Example 1: Insert 10
In an array, if we will insert 10 at index 8, then our array becomes,
@@ -252,7 +241,7 @@ Now this tree satisfies the min-heap order property.
 -**Example 2**: Insert 3
+### Example 2: Insert 3
First insert 3 at index 9.
@@ -276,11 +265,12 @@ First insert 3 at index 9.
**`NOTE: The maximum swap we can perform for any element to be inserted is equal to the height of the tree.`**
---
+
### Question
Time Complexity of inserting an element in a heap having n nodes?
-**Choices**
+### Choices
- [ ] O(1)
- [x] O(log n)
@@ -289,31 +279,32 @@ Time Complexity of inserting an element in a heap having n nodes?
---
-### Inserting in min heap pseudocode
-#### Pseudocode
+
+### Pseudocode
+
```cpp
heap[];
heap.insert(val); // inserting at last
i = heap.size - 1;
-while (i > 0) {
- pi = (i - 1) / 2;
- if (heap[pi] > heap[i]) {
- swap(heap, pi, i);
- i = pi;
- } else {
+while(i>0){
+ pi = (i-1)/2;
+ if(heap[pi] > heap[i]){
+ swap(heap,pi,i);
+ i=pi;
+ }
+ else
+ {
break;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(height of tree) = O(logN)
----
### Extract Min
-
**`Min Heap -`**
-**Example 2**: Insert 3
+### Example 2: Insert 3
First insert 3 at index 9.
@@ -276,11 +265,12 @@ First insert 3 at index 9.
**`NOTE: The maximum swap we can perform for any element to be inserted is equal to the height of the tree.`**
---
+
### Question
Time Complexity of inserting an element in a heap having n nodes?
-**Choices**
+### Choices
- [ ] O(1)
- [x] O(log n)
@@ -289,31 +279,32 @@ Time Complexity of inserting an element in a heap having n nodes?
---
-### Inserting in min heap pseudocode
-#### Pseudocode
+
+### Pseudocode
+
```cpp
heap[];
heap.insert(val); // inserting at last
i = heap.size - 1;
-while (i > 0) {
- pi = (i - 1) / 2;
- if (heap[pi] > heap[i]) {
- swap(heap, pi, i);
- i = pi;
- } else {
+while(i>0){
+ pi = (i-1)/2;
+ if(heap[pi] > heap[i]){
+ swap(heap,pi,i);
+ i=pi;
+ }
+ else
+ {
break;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(height of tree) = O(logN)
----
### Extract Min
-
**`Min Heap -`**
 @@ -326,6 +317,8 @@ In this tree, we have a minimum element at the root. First we swap the first and
@@ -326,6 +317,8 @@ In this tree, we have a minimum element at the root. First we swap the first and
 +
+
+
+
 But the tree is not satisfying the heap-order property. To regain this heap-order property, first check 12, 4 and 5, the minimum is 4, so swap 12 with 4.
@@ -340,44 +333,46 @@ But the tree is not satisfying the heap-order property. To regain this heap-orde
But the tree is not satisfying the heap-order property. To regain this heap-order property, first check 12, 4 and 5, the minimum is 4, so swap 12 with 4.
@@ -340,44 +333,46 @@ But the tree is not satisfying the heap-order property. To regain this heap-orde
 -**`NOTE to Instructor: Perform extract-min again for more clarity on above tree.`**
-#### Pseudocode
+
+### Pseudocode
```cpp
-swap(heap, 0, heap - size() - 1)
-heap.remove(heap.size() - 1)
+swap(heap, 0, heap-size()-1)
+heap.remove(heap.size()-1)
heapify(heap[], 0);
-void heapify(heap[], i) {
- while (2 i + 1 < N) { //need to handle the edge case when left child is there but not the right child
- x = min(heap[i], heap[2 i + 1], heap[2 i + 2])
-
+function heapify(heap[], i ) {
+ while (2i+1 < N) { //need to handle the edge case when left child is there but not the right child
+ x = min (heap [i], heap [2i+1], heap [2i+2])
+
if (x == heap[i]) {
break
- } else if (x == heap[2 i + 1]) {
- swap(heap, i, 2 i + 1)
- i = 2 i + 1
- } else {
- swap(heap, i, 2 i + 2)
- i = 2 i + 2
+ }
+ else if (x == heap[2i+1]){
+ swap (heap, i, 2i+1)
+ i = 2i+1
+ }
+ else{
+ swap (heap, i, 2i+2)
+ i = 2i+2
}
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(log N)
----
+
### Build a heap
We have an array of values, we want to make a heap of it.
**`[5, 13, -2, 11, 27, 31, 0, 19]`**
-#### Idea 1
+### Idea 1
Sort the array.
[-2, 0, 5, 11, 13, 19, 27, 31]
@@ -389,7 +384,7 @@ Looking at the tree below, we can see this is a heap.
**`Time Complexity: O(N * logN)`**
-#### Idea 2
+### Idea 2
Call insert(arr[i]) for every element of an array.
**Explanation:**
@@ -399,10 +394,9 @@ It will take N * logN, as for each element, we will take O(log N) as heapify sha
**`Time Complexity:O(N * logN)`**
---
-### Build a heap Idea 3
+## Build a heap Idea 3 linear time
-#### Idea to build in linear time
+### Idea to build in linear time
We have an array
**`[7, 3, 5, 1, 6, 8, 10, 2, 13, 14, -2]`**
@@ -416,8 +410,8 @@ We can represent this array in the form of a tree.
- The first non-leaf is nothing but the parent of the last leaf node of the tree and the index of the last node is $n-1$, so the index of the first non-leaf is $((n-1-1)/2)=((n-2)/2)=(n/2)-1$.
- We will call heapify() starting from for $(n/2)-1$ index to index 0.
-```cpp
-for (int i = (n / 2) - 1; i >= 0; i--) {
+```cpp=
+for(i -> (n/2)-1 down to 0){
heapify(heap[], i);
}
```
@@ -451,7 +445,7 @@ for (int i = (n / 2) - 1; i >= 0; i--) {
- Now all the nodes has valid heap-order property.
-#### Time Complexity
+### Time Complexity
-**`NOTE to Instructor: Perform extract-min again for more clarity on above tree.`**
-#### Pseudocode
+
+### Pseudocode
```cpp
-swap(heap, 0, heap - size() - 1)
-heap.remove(heap.size() - 1)
+swap(heap, 0, heap-size()-1)
+heap.remove(heap.size()-1)
heapify(heap[], 0);
-void heapify(heap[], i) {
- while (2 i + 1 < N) { //need to handle the edge case when left child is there but not the right child
- x = min(heap[i], heap[2 i + 1], heap[2 i + 2])
-
+function heapify(heap[], i ) {
+ while (2i+1 < N) { //need to handle the edge case when left child is there but not the right child
+ x = min (heap [i], heap [2i+1], heap [2i+2])
+
if (x == heap[i]) {
break
- } else if (x == heap[2 i + 1]) {
- swap(heap, i, 2 i + 1)
- i = 2 i + 1
- } else {
- swap(heap, i, 2 i + 2)
- i = 2 i + 2
+ }
+ else if (x == heap[2i+1]){
+ swap (heap, i, 2i+1)
+ i = 2i+1
+ }
+ else{
+ swap (heap, i, 2i+2)
+ i = 2i+2
}
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(log N)
----
+
### Build a heap
We have an array of values, we want to make a heap of it.
**`[5, 13, -2, 11, 27, 31, 0, 19]`**
-#### Idea 1
+### Idea 1
Sort the array.
[-2, 0, 5, 11, 13, 19, 27, 31]
@@ -389,7 +384,7 @@ Looking at the tree below, we can see this is a heap.
**`Time Complexity: O(N * logN)`**
-#### Idea 2
+### Idea 2
Call insert(arr[i]) for every element of an array.
**Explanation:**
@@ -399,10 +394,9 @@ It will take N * logN, as for each element, we will take O(log N) as heapify sha
**`Time Complexity:O(N * logN)`**
---
-### Build a heap Idea 3
+## Build a heap Idea 3 linear time
-#### Idea to build in linear time
+### Idea to build in linear time
We have an array
**`[7, 3, 5, 1, 6, 8, 10, 2, 13, 14, -2]`**
@@ -416,8 +410,8 @@ We can represent this array in the form of a tree.
- The first non-leaf is nothing but the parent of the last leaf node of the tree and the index of the last node is $n-1$, so the index of the first non-leaf is $((n-1-1)/2)=((n-2)/2)=(n/2)-1$.
- We will call heapify() starting from for $(n/2)-1$ index to index 0.
-```cpp
-for (int i = (n / 2) - 1; i >= 0; i--) {
+```cpp=
+for(i -> (n/2)-1 down to 0){
heapify(heap[], i);
}
```
@@ -451,7 +445,7 @@ for (int i = (n / 2) - 1; i >= 0; i--) {
- Now all the nodes has valid heap-order property.
-#### Time Complexity
+### Time Complexity
 @@ -490,68 +484,14 @@ Then
Here both will cancel out with each other and so our overall time complexity for building a heap is **O(N)**
---
+
### Question
What is the time complexity for building a heap with N nodes?
-**Choices**
+### Choices
- [ ] O(1)
-- [ ] O(N$^2$)
+- [ ] O(N2)
- [x] O(N)
- [ ] O(logN)
-
-
---
-
-
-### Merge N-sorted arrays
-a - [2, 3, 11, 15, 20]
-b - [1, 5, 7, 9]
-c - [0, 2, 4]
-d - [3, 4, 5, 6, 7, 8]
-e - [-2, 5, 10, 20]
-
-We have to merge these sorted arrays.
-
-#### Idea
-- If we want to merge two sorted arrays then we need two pointers.
-- If we want to merge three sorted arrays then we need three pointers.
-- If we want to merge N sorted arrays then we need N pointers, in which complexity becomes very high and we need to keep track of N pointers.
-
----
-### Question
-For merging N sorted arrays, which data structure would be the most efficient for this task ?
-
-**Choices**
-- [ ] Linked List
-- [ ] Array
-- [x] Min-Heap
-- [ ] Hash Table
-
-**Explanation:**
-
-A Min-Heap is an efficient data structure choice. The Min-Heap ensures that the smallest element among all the elements in the arrays is always at the front. This allows for constant-time access to the minimum element, making it efficient to extract and merge elements in sorted order.
-
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
-
-#### Optimized Solution
-- First, we need to compare the 0th index element of every array.
-- Now we use heap here.
-- We will add an index 0 element of every array in the heap, in the form of element value, array number and Index of the element in particular.
-
-
@@ -490,68 +484,14 @@ Then
Here both will cancel out with each other and so our overall time complexity for building a heap is **O(N)**
---
+
### Question
What is the time complexity for building a heap with N nodes?
-**Choices**
+### Choices
- [ ] O(1)
-- [ ] O(N$^2$)
+- [ ] O(N2)
- [x] O(N)
- [ ] O(logN)
-
-
---
-
-
-### Merge N-sorted arrays
-a - [2, 3, 11, 15, 20]
-b - [1, 5, 7, 9]
-c - [0, 2, 4]
-d - [3, 4, 5, 6, 7, 8]
-e - [-2, 5, 10, 20]
-
-We have to merge these sorted arrays.
-
-#### Idea
-- If we want to merge two sorted arrays then we need two pointers.
-- If we want to merge three sorted arrays then we need three pointers.
-- If we want to merge N sorted arrays then we need N pointers, in which complexity becomes very high and we need to keep track of N pointers.
-
----
-### Question
-For merging N sorted arrays, which data structure would be the most efficient for this task ?
-
-**Choices**
-- [ ] Linked List
-- [ ] Array
-- [x] Min-Heap
-- [ ] Hash Table
-
-**Explanation:**
-
-A Min-Heap is an efficient data structure choice. The Min-Heap ensures that the smallest element among all the elements in the arrays is always at the front. This allows for constant-time access to the minimum element, making it efficient to extract and merge elements in sorted order.
-
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
-
-#### Optimized Solution
-- First, we need to compare the 0th index element of every array.
-- Now we use heap here.
-- We will add an index 0 element of every array in the heap, in the form of element value, array number and Index of the element in particular.
-
- -
-Now take the minimum element and insert it in the resultant array,
-
-- Now insert the next element of the list for which the minimum element is selected, like first, we have taken the fourth list element, so now insert the next element of the fourth list.
-
-
-
-Now take the minimum element and insert it in the resultant array,
-
-- Now insert the next element of the list for which the minimum element is selected, like first, we have taken the fourth list element, so now insert the next element of the fourth list.
-
- -
-- Now again extract-min() from the heap and insert the next element of that list to which the minimum element belongs.
-- And keep repeating this until we have done with all the elements.
-
-#### Time Complexity
-**Time Complexity:** (XlogN)
-Here X is a total number of elements of all arrays.
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/Advanced/DSA Interview Problems 2.md b/Academy DSA Typed Notes/Advanced/DSA Interview Problems 2.md
new file mode 100644
index 0000000..d4360e5
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Interview Problems 2.md
@@ -0,0 +1,332 @@
+# Interview Problems 2
+
+## Problem 1 Meeting Rooms
+### Problem Statement:
+You are given an array of meeting time intervals where each interval is represented as [start, end] (start time is less than the end time). Your task is to find the minimum number of conference rooms required to schedule all meetings without overlap.
+
+
+### Example 1:
+
+Input: [[0, 30], [5, 10], [15, 20]]
+Output: 2
+
+**Explanation**:
+
+- The first meeting (0, 30) starts at 0 and ends at 30.
+- The second meeting (5, 10) overlaps with the first meeting, so a second room is required.
+- The third meeting (15, 20) can reuse a room after the second meeting ends, resulting in a total of 2 rooms.
+### Example 2:
+
+Input: [[7, 10], [2, 4]]
+Output: 1
+**Explanation**:
+
+The two meetings don’t overlap. The second room finishes at time 4, and the first one starts at time 7. Hence, only 1 room is required.
+
+
+### Brute Force Approach (Inefficient)
+
+**Idea**: For each meeting, check whether it overlaps with any other meeting and keep count of rooms.
+
+ **Explanation**:
+- Sort all meetings by start time.
+- Iterate through the meetings and compare the current meeting with all previous meetings to find overlaps.
+- Keep track of the maximum number of overlapping meetings (i.e., required rooms).
+
+**Complexity**:
+
+**Time Complexity**: O(N^2)
+
+## Meeting Rooms Optimised Approach
+
+### Optimized Approach Using Time Points (Sweep Line Algorithm)
+
+**Key Insight**:
+Instead of comparing every meeting to every other meeting, we can treat the problem as a series of time points where meetings start and end. We can then track how many rooms are being used at any given time.
+
+**Steps**:
+
+- Record every meeting's start time as an event where a room is needed.
+- Record every meeting's end time as an event where a room is freed.
+- Count the rooms used at each time point and return the maximum number of rooms required.
+### Pseudo code
+```cpp
+function minMeetingRooms(intervals):
+ n = 1000010
+ // For room allocation
+ delta = array of size n initialized to 0
+
+ // Step 1: Update room allocation at each time point
+ for each interval in intervals:
+ start_time = interval[0]
+ end_time = interval[1]
+
+ // A room is needed when a meeting starts
+ delta[start_time] += 1
+
+ // A room is freed when a meeting ends
+ delta[end_time]-= 1
+
+ // Step 2: Calculate the prefix sum to determine how many rooms are needed over time
+ for i from 0 to n - 2:
+ delta[i + 1] += delta[i] // Accumulate the room changes over time
+
+ // Step 3: Return the maximum number of rooms needed at any point in time
+ return max value in delta array
+```
+
+### Compexity
+**Time Complexity:** O(K + N.logK)
+**Space Complexity:** O(K)
+
+---
+
+## Problem 3 Merge K sorted arrays
+### Merge K-sorted arrays
+a - [2, 3, 11, 15, 20]
+b - [1, 5, 7, 9]
+c - [0, 2, 4]
+d - [3, 4, 5, 6, 7, 8]
+e - [-2, 5, 10, 20]
+
+We have to merge these sorted arrays.
+
+### Idea
+- If we want to merge two sorted arrays then we need two pointers.
+- If we want to merge three sorted arrays then we need three pointers.
+- If we want to merge K sorted arrays then we need K pointers, in which complexity becomes very high and we need to keep track of K pointers.
+
+---
+
+
+### Question
+For merging K sorted arrays, which data structure would be the most efficient for this task ?
+
+### Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Min-Heap
+- [ ] Hash Table
+
+
+
+
+### Explanation:
+
+A Min-Heap is an efficient data structure choice. The Min-Heap ensures that the smallest element among all the elements in the arrays is always at the front. This allows for constant-time access to the minimum element, making it efficient to extract and merge elements in sorted order.
+
+---
+
+## Merge K sorted arrays Solution
+
+### Optimized Solution
+- First, we need to compare the 0th index element of every array.
+- Now we use heap here.
+- We will add an index 0 element of every array in the heap, in the form of element value, array number and Index of the element in particular.
+
+
+
+Now take the minimum element and insert it in the resultant array,
+
+- Now insert the next element of the list for which the minimum element is selected, like first, we have taken the fourth list element, so now insert the next element of the fourth list.
+
+
+
+- Now again extract-min() from the heap and insert the next element of that list to which the minimum element belongs.
+- And keep repeating this until we have done with all the elements.
+
+### Time Complexity
+**Time Complexity:** (XlogK)
+Here X is a total number of elements of all arrays.
+
+
+---
+
+## Problem 4 Minimum Distance Equal Pair
+
+### Problem Statement:
+Given an array A, find a pair of indices (i, j) such that A[i] = A[j] and the absolute difference |i - j| is minimized. In simpler terms, you need to find two equal elements in the array that are the closest to each other and return the minimum distance between them.
+
+**Example 1:**
+
+Input: A = [7, 1, 3, 4, 1, 7]
+Output: 3
+
+**Explanation**:
+
+- Two options exist:
+a.Elements at indices 1 and 4 are both 1, so |1 - 4| = 3.
+b.Elements at indices 0 and 5 are both 7, so |0 - 5| = 5.
+- The minimum distance is 3.
+**Example 2**:
+
+Input: A = [1, 1]
+Output: 1
+**Explanation**:
+
+The only pair of equal elements are at indices 0 and 1, so |0 - 1| = 1.
+
+### Brute Force Approach (Inefficient):
+
+**Idea**:
+Compare every element with every other element to find pairs of equal values and compute the difference in their indices.
+
+**Explanation:**
+For every element A[i], check all subsequent elements A[j] to see if they are equal.
+Track the minimum difference between the indices of any matching pair.
+
+**Time Complexity**: O(N^2)
+
+**Flaws**:
+
+The brute force method becomes inefficient as the size of the array increases due to the quadratic time complexity.
+
+## Minimum Distance Equal Pair Optimised Approach
+### Optimized Approach Using Hash Map:
+**Key Insight**: Instead of comparing every element with every other element, use a hash map to store the last seen index of each element.
+**Steps**:
+As you traverse the array, if an element has been seen before, calculate the distance between the current index and the last seen index from the hash map.
+Keep track of the minimum distance found so far.
+
+
+### Dry Run:
+- Consider A = [7, 1, 3, 4, 1, 7].
+- Initialize an empty hash map: lastSeen = {}.
+- Initialize minDistance = ∞.
+
+
+ | Index (i) | Element(A[i]) | lastSeen Map | Distance Calculation | minDistance |
+|----------- |--------------- |-------------------------- |---------------------- |------------- |
+| 0 | 7 | {7: 0} | - | ∞ |
+| 1 | 1 | {7: 0, 1: 1} | - | ∞ |
+| 2 | 3 | {7: 0, 1: 1, 3: 2} | - | ∞ |
+| 3 | 4 | {7: 0, 1: 1, 3: 2, 4: 3} | - | ∞ |
+| 4 | 1 | {7: 0, 1: 1, 3: 2, 4: 3} | 4-1 | 3 |
+| 5 | 7 | {7: 0, 1: 4, 3: 2, 4: 3} | 5-0 | 3 |
+### Pseudo code
+
+```cpp
+function findMinDistance(A):
+ Create hash map 'lastSeen'
+ Set 'minDistance' to infinity
+
+ for i from 0 to len(A):
+ if A[i] in 'lastSeen':
+ distance = abs(i - lastSeen[A[i]])
+ minDistance = min(minDistance, distance)
+
+ lastSeen[A[i]] = i
+
+ if minDistance < infinity:
+ return minDistance
+ return -1 # No pair found
+```
+
+
+
+### Complexity Analysis:
+**Time Complexity**: O(n)
+**Space Complexity**: O(n)
+
+
+---
+
+## Problem 5 Minimum Window Substring
+
+### Problem Statement:
+Given two strings s and t, find the minimum window in s which contains all characters of t (including duplicates). If no such window exists, return an empty string "".
+
+**Example 1**:
+Input: s = "ADOBECODEBANC", t = "ABC"
+Output: "BANC"
+**Explanation**:
+
+- The substring "BANC" in s contains all characters 'A', 'B', and 'C' from string t in the minimum length.
+
+**Example 2**:
+Input: s = "a", t = "a"
+Output: "a"
+**Explanation**:
+- The entire string s contains the only character 'a' from string t.
+
+**Example 3**:
+Input: s = "a", t = "aa"
+Output: ""
+**Explanation**:
+- The string s only contains one 'a', but t requires two 'a's. Thus, no valid window exists, and the output is "".
+
+
+### Brute Force Approach (Inefficient):
+
+**Idea**: Check every possible substring of s, and for each substring, verify if it contains all characters of t.
+**Steps**:
+- For every substring of s, check if it includes all characters of t by counting the occurrences of each character.
+- Track the smallest valid substring.
+
+**Complexity**: O(m^2⋅n)
+
+
+## Minimum Window Substring Optimised Approach
+
+### Optimized Approach Using Sliding Window:
+**Key Insight**: Use a sliding window to progressively expand and contract the substring of s while keeping track of the characters required from t.
+**Steps**:
+- Maintain a window using two pointers (left and right), expanding the window by moving the right pointer, and shrinking it by moving the left pointer.
+- Use a hash map or frequency counter to track how many of each character from t are still needed within the current window.
+- Whenever the window contains all characters from t, attempt to shrink the window from the left to minimize its size.
+- Continue until the entire string s is processed.
+
+### Pseudocode
+
+``` cpp
+function minWindow(s, t):
+ if len(t) > len(s):
+ return "" # Impossible case
+
+ Create hash map 'targetCount' to store frequency of chars in t
+ Create hash map 'windowCount' to store frequency of chars in current window
+
+ Initialize variables:
+ left = 0
+ right = 0
+ required = number of unique characters in t
+ formed = 0 # Tracks how many unique chars in the current window match t's requirements
+ minWindow = (infinity, 0, 0) # Format: (window length, left index, right index)
+
+ while right < len(s):
+ # Add character from s[right] to windowCount
+ char = s[right]
+ Increase windowCount[char]
+
+ # If the current char in the window matches targetCount, increment 'formed'
+ if windowCount[char] == targetCount[char]:
+ formed += 1
+
+ # Try shrinking the window from left if it's valid (i.e., all characters are formed)
+ while left <= right and formed == required:
+ # Update minWindow if the current window is smaller
+ if (right - left + 1) < minWindow[0]:
+ minWindow = (right - left + 1, left, right)
+
+ # Remove char at s[left] from windowCount and shrink window
+ char = s[left]
+ Decrease windowCount[char]
+
+ if windowCount[char] < targetCount[char]:
+ formed -= 1
+
+ left += 1 # Shrink the window
+
+ right += 1 # Expand the window
+
+ if minWindow[0] == infinity:
+ return ""
+
+ return s[minWindow[1]:minWindow[2] + 1]
+```
+
+### Complexity Analysis:
+**Time Complexity**: O(m+n)
+
+---
+
diff --git a/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md b/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md
index 4779efb..bdf7e84 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md
@@ -1,82 +1,7 @@
# Linked List 1: Introduction
----
-## Linked List
-
-### Issues with Array
-We need continuous space in memory to store Array elements. Now, it may happen that we have required space in chunks but not continuous, then we will not be able to create an Array.
-
-### Linked List
-* A linear data structure that can utilize all the free memory
-* We need not have continuous space to store nodes of a Linked List.
-
-### Representation of Linked List
-
-
-
-* it has a data section where the data is present
-* a next pointer which points to next element of the linked list
-
-### Structure of Linked List
-
-```java
-class Node{
- int data;
- Node next;
- Node(int x){
- data = x;
- next = null;
- }
-}
-```
-**Example of Linked List**
-
-
-
-
-
-- Now again extract-min() from the heap and insert the next element of that list to which the minimum element belongs.
-- And keep repeating this until we have done with all the elements.
-
-#### Time Complexity
-**Time Complexity:** (XlogN)
-Here X is a total number of elements of all arrays.
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/Advanced/DSA Interview Problems 2.md b/Academy DSA Typed Notes/Advanced/DSA Interview Problems 2.md
new file mode 100644
index 0000000..d4360e5
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Interview Problems 2.md
@@ -0,0 +1,332 @@
+# Interview Problems 2
+
+## Problem 1 Meeting Rooms
+### Problem Statement:
+You are given an array of meeting time intervals where each interval is represented as [start, end] (start time is less than the end time). Your task is to find the minimum number of conference rooms required to schedule all meetings without overlap.
+
+
+### Example 1:
+
+Input: [[0, 30], [5, 10], [15, 20]]
+Output: 2
+
+**Explanation**:
+
+- The first meeting (0, 30) starts at 0 and ends at 30.
+- The second meeting (5, 10) overlaps with the first meeting, so a second room is required.
+- The third meeting (15, 20) can reuse a room after the second meeting ends, resulting in a total of 2 rooms.
+### Example 2:
+
+Input: [[7, 10], [2, 4]]
+Output: 1
+**Explanation**:
+
+The two meetings don’t overlap. The second room finishes at time 4, and the first one starts at time 7. Hence, only 1 room is required.
+
+
+### Brute Force Approach (Inefficient)
+
+**Idea**: For each meeting, check whether it overlaps with any other meeting and keep count of rooms.
+
+ **Explanation**:
+- Sort all meetings by start time.
+- Iterate through the meetings and compare the current meeting with all previous meetings to find overlaps.
+- Keep track of the maximum number of overlapping meetings (i.e., required rooms).
+
+**Complexity**:
+
+**Time Complexity**: O(N^2)
+
+## Meeting Rooms Optimised Approach
+
+### Optimized Approach Using Time Points (Sweep Line Algorithm)
+
+**Key Insight**:
+Instead of comparing every meeting to every other meeting, we can treat the problem as a series of time points where meetings start and end. We can then track how many rooms are being used at any given time.
+
+**Steps**:
+
+- Record every meeting's start time as an event where a room is needed.
+- Record every meeting's end time as an event where a room is freed.
+- Count the rooms used at each time point and return the maximum number of rooms required.
+### Pseudo code
+```cpp
+function minMeetingRooms(intervals):
+ n = 1000010
+ // For room allocation
+ delta = array of size n initialized to 0
+
+ // Step 1: Update room allocation at each time point
+ for each interval in intervals:
+ start_time = interval[0]
+ end_time = interval[1]
+
+ // A room is needed when a meeting starts
+ delta[start_time] += 1
+
+ // A room is freed when a meeting ends
+ delta[end_time]-= 1
+
+ // Step 2: Calculate the prefix sum to determine how many rooms are needed over time
+ for i from 0 to n - 2:
+ delta[i + 1] += delta[i] // Accumulate the room changes over time
+
+ // Step 3: Return the maximum number of rooms needed at any point in time
+ return max value in delta array
+```
+
+### Compexity
+**Time Complexity:** O(K + N.logK)
+**Space Complexity:** O(K)
+
+---
+
+## Problem 3 Merge K sorted arrays
+### Merge K-sorted arrays
+a - [2, 3, 11, 15, 20]
+b - [1, 5, 7, 9]
+c - [0, 2, 4]
+d - [3, 4, 5, 6, 7, 8]
+e - [-2, 5, 10, 20]
+
+We have to merge these sorted arrays.
+
+### Idea
+- If we want to merge two sorted arrays then we need two pointers.
+- If we want to merge three sorted arrays then we need three pointers.
+- If we want to merge K sorted arrays then we need K pointers, in which complexity becomes very high and we need to keep track of K pointers.
+
+---
+
+
+### Question
+For merging K sorted arrays, which data structure would be the most efficient for this task ?
+
+### Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Min-Heap
+- [ ] Hash Table
+
+
+
+
+### Explanation:
+
+A Min-Heap is an efficient data structure choice. The Min-Heap ensures that the smallest element among all the elements in the arrays is always at the front. This allows for constant-time access to the minimum element, making it efficient to extract and merge elements in sorted order.
+
+---
+
+## Merge K sorted arrays Solution
+
+### Optimized Solution
+- First, we need to compare the 0th index element of every array.
+- Now we use heap here.
+- We will add an index 0 element of every array in the heap, in the form of element value, array number and Index of the element in particular.
+
+
+
+Now take the minimum element and insert it in the resultant array,
+
+- Now insert the next element of the list for which the minimum element is selected, like first, we have taken the fourth list element, so now insert the next element of the fourth list.
+
+
+
+- Now again extract-min() from the heap and insert the next element of that list to which the minimum element belongs.
+- And keep repeating this until we have done with all the elements.
+
+### Time Complexity
+**Time Complexity:** (XlogK)
+Here X is a total number of elements of all arrays.
+
+
+---
+
+## Problem 4 Minimum Distance Equal Pair
+
+### Problem Statement:
+Given an array A, find a pair of indices (i, j) such that A[i] = A[j] and the absolute difference |i - j| is minimized. In simpler terms, you need to find two equal elements in the array that are the closest to each other and return the minimum distance between them.
+
+**Example 1:**
+
+Input: A = [7, 1, 3, 4, 1, 7]
+Output: 3
+
+**Explanation**:
+
+- Two options exist:
+a.Elements at indices 1 and 4 are both 1, so |1 - 4| = 3.
+b.Elements at indices 0 and 5 are both 7, so |0 - 5| = 5.
+- The minimum distance is 3.
+**Example 2**:
+
+Input: A = [1, 1]
+Output: 1
+**Explanation**:
+
+The only pair of equal elements are at indices 0 and 1, so |0 - 1| = 1.
+
+### Brute Force Approach (Inefficient):
+
+**Idea**:
+Compare every element with every other element to find pairs of equal values and compute the difference in their indices.
+
+**Explanation:**
+For every element A[i], check all subsequent elements A[j] to see if they are equal.
+Track the minimum difference between the indices of any matching pair.
+
+**Time Complexity**: O(N^2)
+
+**Flaws**:
+
+The brute force method becomes inefficient as the size of the array increases due to the quadratic time complexity.
+
+## Minimum Distance Equal Pair Optimised Approach
+### Optimized Approach Using Hash Map:
+**Key Insight**: Instead of comparing every element with every other element, use a hash map to store the last seen index of each element.
+**Steps**:
+As you traverse the array, if an element has been seen before, calculate the distance between the current index and the last seen index from the hash map.
+Keep track of the minimum distance found so far.
+
+
+### Dry Run:
+- Consider A = [7, 1, 3, 4, 1, 7].
+- Initialize an empty hash map: lastSeen = {}.
+- Initialize minDistance = ∞.
+
+
+ | Index (i) | Element(A[i]) | lastSeen Map | Distance Calculation | minDistance |
+|----------- |--------------- |-------------------------- |---------------------- |------------- |
+| 0 | 7 | {7: 0} | - | ∞ |
+| 1 | 1 | {7: 0, 1: 1} | - | ∞ |
+| 2 | 3 | {7: 0, 1: 1, 3: 2} | - | ∞ |
+| 3 | 4 | {7: 0, 1: 1, 3: 2, 4: 3} | - | ∞ |
+| 4 | 1 | {7: 0, 1: 1, 3: 2, 4: 3} | 4-1 | 3 |
+| 5 | 7 | {7: 0, 1: 4, 3: 2, 4: 3} | 5-0 | 3 |
+### Pseudo code
+
+```cpp
+function findMinDistance(A):
+ Create hash map 'lastSeen'
+ Set 'minDistance' to infinity
+
+ for i from 0 to len(A):
+ if A[i] in 'lastSeen':
+ distance = abs(i - lastSeen[A[i]])
+ minDistance = min(minDistance, distance)
+
+ lastSeen[A[i]] = i
+
+ if minDistance < infinity:
+ return minDistance
+ return -1 # No pair found
+```
+
+
+
+### Complexity Analysis:
+**Time Complexity**: O(n)
+**Space Complexity**: O(n)
+
+
+---
+
+## Problem 5 Minimum Window Substring
+
+### Problem Statement:
+Given two strings s and t, find the minimum window in s which contains all characters of t (including duplicates). If no such window exists, return an empty string "".
+
+**Example 1**:
+Input: s = "ADOBECODEBANC", t = "ABC"
+Output: "BANC"
+**Explanation**:
+
+- The substring "BANC" in s contains all characters 'A', 'B', and 'C' from string t in the minimum length.
+
+**Example 2**:
+Input: s = "a", t = "a"
+Output: "a"
+**Explanation**:
+- The entire string s contains the only character 'a' from string t.
+
+**Example 3**:
+Input: s = "a", t = "aa"
+Output: ""
+**Explanation**:
+- The string s only contains one 'a', but t requires two 'a's. Thus, no valid window exists, and the output is "".
+
+
+### Brute Force Approach (Inefficient):
+
+**Idea**: Check every possible substring of s, and for each substring, verify if it contains all characters of t.
+**Steps**:
+- For every substring of s, check if it includes all characters of t by counting the occurrences of each character.
+- Track the smallest valid substring.
+
+**Complexity**: O(m^2⋅n)
+
+
+## Minimum Window Substring Optimised Approach
+
+### Optimized Approach Using Sliding Window:
+**Key Insight**: Use a sliding window to progressively expand and contract the substring of s while keeping track of the characters required from t.
+**Steps**:
+- Maintain a window using two pointers (left and right), expanding the window by moving the right pointer, and shrinking it by moving the left pointer.
+- Use a hash map or frequency counter to track how many of each character from t are still needed within the current window.
+- Whenever the window contains all characters from t, attempt to shrink the window from the left to minimize its size.
+- Continue until the entire string s is processed.
+
+### Pseudocode
+
+``` cpp
+function minWindow(s, t):
+ if len(t) > len(s):
+ return "" # Impossible case
+
+ Create hash map 'targetCount' to store frequency of chars in t
+ Create hash map 'windowCount' to store frequency of chars in current window
+
+ Initialize variables:
+ left = 0
+ right = 0
+ required = number of unique characters in t
+ formed = 0 # Tracks how many unique chars in the current window match t's requirements
+ minWindow = (infinity, 0, 0) # Format: (window length, left index, right index)
+
+ while right < len(s):
+ # Add character from s[right] to windowCount
+ char = s[right]
+ Increase windowCount[char]
+
+ # If the current char in the window matches targetCount, increment 'formed'
+ if windowCount[char] == targetCount[char]:
+ formed += 1
+
+ # Try shrinking the window from left if it's valid (i.e., all characters are formed)
+ while left <= right and formed == required:
+ # Update minWindow if the current window is smaller
+ if (right - left + 1) < minWindow[0]:
+ minWindow = (right - left + 1, left, right)
+
+ # Remove char at s[left] from windowCount and shrink window
+ char = s[left]
+ Decrease windowCount[char]
+
+ if windowCount[char] < targetCount[char]:
+ formed -= 1
+
+ left += 1 # Shrink the window
+
+ right += 1 # Expand the window
+
+ if minWindow[0] == infinity:
+ return ""
+
+ return s[minWindow[1]:minWindow[2] + 1]
+```
+
+### Complexity Analysis:
+**Time Complexity**: O(m+n)
+
+---
+
diff --git a/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md b/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md
index 4779efb..bdf7e84 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Linked List 1 Introduction.md
@@ -1,82 +1,7 @@
# Linked List 1: Introduction
----
-## Linked List
-
-### Issues with Array
-We need continuous space in memory to store Array elements. Now, it may happen that we have required space in chunks but not continuous, then we will not be able to create an Array.
-
-### Linked List
-* A linear data structure that can utilize all the free memory
-* We need not have continuous space to store nodes of a Linked List.
-
-### Representation of Linked List
-
-
-
-* it has a data section where the data is present
-* a next pointer which points to next element of the linked list
-
-### Structure of Linked List
-
-```java
-class Node{
- int data;
- Node next;
- Node(int x){
- data = x;
- next = null;
- }
-}
-```
-**Example of Linked List**
-
-
-
-- -
-
-* the first node of the linked list is called head
-* any linked list is represented by its first node
-
----
-### Question
-Where will the "next" pointer of the last node point to?
-
-**Choices**
-- [ ] First Node
-- [ ] Any Node
-- [ ] Middle Node
-- [x] Null
-
----
-### Question
-From which node can we travel the entire linked list ?
-
-**Choices**
-- [ ] Middle
-- [x] First
-- [ ] Last
-- [ ] Any Node
-
-
----
-### Operation on Linked List
-
-### 1. Access kth element(k = 0; k is the first element)
-
-```java
-Node temp = Head // temp is a compy
-for i -> 1 to k {
- temp = temp.next
-}
-return temp.data // never update head otherwise the first node is lost
-```
-> Time complexity to access the kth element is O(K). Here we can see that linked list takes more time compared to array as it would take constant time to access the kth element.
-
-### 2. Check for value X (searching)
+## Check for value X (searching)
We can simply iterate and check if value X exists of not.
```java
temp = Head
@@ -94,10 +19,12 @@ Time Complexity for searching in Linked list is O(N).
> In linked list we cannot perform binary search because we have to travel to the middle element. We cannot jump to the middle element unlike array.
---
+
+
### Question
What is the time complexity to search any node in the linked list?
-**Choices**
+### Choices
- [ ] O(1)
- [ ] O(log(N))
- [x] O(N)
@@ -105,11 +32,13 @@ What is the time complexity to search any node in the linked list?
---
+
+
### Question
What is the time complexity to access the Kth element of the linked list? [index K is valid]
-**Choices**
+### Choices
- [ ] O(1)
- [ ] O(log(N))
- [ ] O(N)
@@ -117,35 +46,37 @@ What is the time complexity to access the Kth element of the linked list? [index
---
-### Problem 1 Insert a New Node with Data
+## Problem 1 Insert a New Node with Data
### Insert a New Node with Data
Insert a new node with data **v** at index **p** in the linked list
>Though indexing doesn't exist is LL, but for our understanding, let's say Node 1 is at index 0, Node 2 at index 1, etc.
-**Testcase 1**
+### Testcase 1
v = 60 and p = 3
 -**Solution to Testcase 1**
+### Solution to Testcase 1
* Iterate to the node having index p-1 where p-1>=0 from start of linked list. Here p is 3 so we iterate till 2
* On reaching index 2 we create a new node riz with data v i.e. 60
* Set **riz.next = t.next** and set **t.next = riz**
-**Solution to Testcase 1**
+### Solution to Testcase 1
* Iterate to the node having index p-1 where p-1>=0 from start of linked list. Here p is 3 so we iterate till 2
* On reaching index 2 we create a new node riz with data v i.e. 60
* Set **riz.next = t.next** and set **t.next = riz**
 -**Testcase 2**
+### Testcase 2
-**Testcase 2**
+### Testcase 2
 -**Solution to Testcase 2**
+### Solution to Testcase 2
**We can do the dry run similar to testcase 1 here is the final result**
-**Solution to Testcase 2**
+### Solution to Testcase 2
**We can do the dry run similar to testcase 1 here is the final result**
 ---
+
+
### Question
Insert a new node with data **10** at index **2** in the Given linked list.
@@ -153,7 +84,7 @@ Head -> 1 -> 6 -> 7 -> 9 -> Null
Choose the correct LinkedList after insertion.
-**Choices**
+### Choices
- [ ] Head -> 1 -> 6 -> 7 -> 9 -> **10** -> Null
- [x] Head -> 1 -> 6 -> **10** -> 7 -> 9 -> Null
- [ ] Head -> 1 -> **10** -> 6 -> 7 -> 9 -> Null
@@ -161,9 +92,10 @@ Choose the correct LinkedList after insertion.
---
-### Insert a New Node with Data Approach
+## Insert a New Node with Data Approach
+
-#### Approach
+### Approach
* Traverse till **(p - 1)th** node. Let's call it **t**.
* Create a new node **newNode**, with data **v**.
@@ -171,53 +103,54 @@ Choose the correct LinkedList after insertion.
* Set **t.next** to reference of **newNode**.
-#### Pseudocode 1
+### Pseudocode 1
```cpp
-Function insertAtIndex(p, v, Node head) {
- Node t = head
- for (i = 1; i < p; i++) // iterating updating t, p-1 times
- {
- t = t.next
- }
-
- // create a new node
- Node newNode = Node(v)
-
- // Inserting the Node
- newNode.next = t.next
- t.next = newNode
+Function insertAtIndex(p,v,Node head)
+{
+ Node t = head
+ for(i -> 1 to p - 1) // iterating updating t, p-1 times
+ {
+ t = t.next
+ }
+
+ // create a new node
+ Node newNode = Node(v)
+
+ // Inserting the Node
+ newNode.next = t.next
+ t.next = newNode
}
```
>Again there is an edge case to above solution can anyone figure it out ?
-#### Edge Case
+### Edge Case
If p = 0 then where to insert the node ?
=> At head of the list.
---
+
+
### Question
Insert a new node with data **10** at index **2** in the Given linked list.
@@ -153,7 +84,7 @@ Head -> 1 -> 6 -> 7 -> 9 -> Null
Choose the correct LinkedList after insertion.
-**Choices**
+### Choices
- [ ] Head -> 1 -> 6 -> 7 -> 9 -> **10** -> Null
- [x] Head -> 1 -> 6 -> **10** -> 7 -> 9 -> Null
- [ ] Head -> 1 -> **10** -> 6 -> 7 -> 9 -> Null
@@ -161,9 +92,10 @@ Choose the correct LinkedList after insertion.
---
-### Insert a New Node with Data Approach
+## Insert a New Node with Data Approach
+
-#### Approach
+### Approach
* Traverse till **(p - 1)th** node. Let's call it **t**.
* Create a new node **newNode**, with data **v**.
@@ -171,53 +103,54 @@ Choose the correct LinkedList after insertion.
* Set **t.next** to reference of **newNode**.
-#### Pseudocode 1
+### Pseudocode 1
```cpp
-Function insertAtIndex(p, v, Node head) {
- Node t = head
- for (i = 1; i < p; i++) // iterating updating t, p-1 times
- {
- t = t.next
- }
-
- // create a new node
- Node newNode = Node(v)
-
- // Inserting the Node
- newNode.next = t.next
- t.next = newNode
+Function insertAtIndex(p,v,Node head)
+{
+ Node t = head
+ for(i -> 1 to p - 1) // iterating updating t, p-1 times
+ {
+ t = t.next
+ }
+
+ // create a new node
+ Node newNode = Node(v)
+
+ // Inserting the Node
+ newNode.next = t.next
+ t.next = newNode
}
```
>Again there is an edge case to above solution can anyone figure it out ?
-#### Edge Case
+### Edge Case
If p = 0 then where to insert the node ?
=> At head of the list.
 -#### Pseudocode 2
+### Pseudocode 2
```cpp
-Function insertAtIndex(p, v, Node head) {
- // create a new node
- Node newNode = Node(v)
-
- Node t = head
-
- if (p == 0) { // edge case
- newNode.next = head
- head = newNode
- }
-
- for (i = 1; i < p; i++) { // iterating updating t p-1 times
- t = t.next
- }
-
- // Inserting the Node
- newNode.next = t.next
- t.next = newNode
+Function insertAtIndex(p,v,Node head){
+ // create a new node
+ Node newNode = Node(v)
+
+ Node t = head
+
+ if(p == 0){ // edge case
+ newNode.next = head
+ head = newNode
+ }
+
+ for(i -> 1 to p - 1){ // iterating updating t p-1 times
+ t = t.next
+ }
+
+ // Inserting the Node
+ newNode.next = t.next
+ t.next = newNode
}
```
@@ -227,11 +160,14 @@ O(K)
---
+## Problem 2 Deletion in Linked List
+
### Deletion in Linked List
*Delete the first occurrence of value X in the given linked list. If element is not present, leave as is.*
+### Examples
**Example 1:**
```java
List: 1 -> 8 -> 4 -> -2 -> 12
@@ -252,7 +188,7 @@ List: 1 -> 8 -> -2 -> 4 -> 12
The first occurrence of 4 has been deleted from the list.
```
-#### Cases:
+### Cases:
1. **Empty list i.e., head = null**
```java
@@ -290,30 +226,30 @@ List: 1 -> 8 -> -2 -> 7 -> 12
```
---
+
+
### Question
Delete the first occurrence of value **X** in the given linked list. If element is not present, leave as is.
Linked List : ```5 -> 4 -> 7 -> 1 -> NULL```
X (to Delete) : 1
-
-**Choices**
+### Choices
- [ ] 5 -> 4 -> 7 -> 1 -> NULL
- [x] 5 -> 4 -> 7 -> NULL
- [ ] 4 -> 7 -> 1 -> NULL
- [ ] 5 -> 7 -> NULL
+---
-**Explanation:**
-
-The Value 1 is not present in the Linked List. So leave as it is.
-
-Thus, the final Linked List is 5 -> 4 -> 7 -> -1 -> NULL
+### Explanation:
+The Value 1 is present at 4th index in the Linked List. So if we remove it.The final Linked List will look something like this `5 -> 4 -> 7 -> -1 -> NULL`
---
-### Deletion in Linked List Approach and Pseudocode
-#### Approach
+## Deletion in Linked List Approach and Pseudocode
+
+### Approach
- Check if the list is empty; if so, return it as is.
- If the target value X is at the head, update the head to the next node.
@@ -321,47 +257,88 @@ Thus, the final Linked List is 5 -> 4 -> 7 -> -1 -> NULL
- When X is found, skip the node containing it by updating the next reference of the previous node.
- Return the modified head (which may or may not have changed during the operation).
-#### Pseudocode
+### Pseudocode
```java
if (head == null) return head
-if (head.data == X) {
- tmp = head
- free(tmp) //automatically done in java, whereas have to do manually for c++ and other languages.
- head = Head.next
- return head
+if(head.data == X){
+ tmp = head
+ free(tmp) //automatically done in java, whereas have to do manually for c++ and other languages.
+ head = Head.next
+ return head
}
temp = head
-while (temp.next != null) {
- if (temp.next.data == X) {
- tmp = temp.next
- temp.next = temp.next.next
- free(tmp)
- return head
- }
- temp = temp.next
+while(temp.next != null) {
+ if(temp.next.data == X){
+ tmp = temp.next
+ temp.next = temp.next.next
+ free(tmp)
+ return head
+ }
+ temp = temp.next
}
return head
```
-#### Time complexity for Deletion
+### Time complexity for Deletion
**O(N)**
> It can be seen that every operation in linked list takes linear time complexity unlike arrays.
+
+
+---
+## OnePlus removes Defects
+
+### Scenerio
+**OnePlus** has a lineup of **N** mobile phones ready in their manufacturing line. It has detected a defect in one of their phone models during production.
+
+They have decided to recall all phones of the defective model from their manufacturing line. Your task is to help **OnePlus** remove all defective phones from their production lineup efficiently.
+
+### Problem
+You are given a **linked list A of N** nodes where each node represents a specific **model type of a OnePlus mobile phone** in the manufacturing line. Each node contains an integer representing the model number of the phone. You will also be given an integer **B** which represents the model number of the defective phone that needs to be removed.
+
+Your goal is to remove all **nodes** (phones) from the linked list that have the model number **B** and return the modified linked list representing the updated manufacturing line.
+
+### Approach
+
+- We need to first check for all occurrences at the head node and change the head node appropriately.
+- Then we need to check for all occurrences inside a loop and delete them one by one.
+- This problem very similar to the above problem, the only difference is that we need to remove all occurences in this problem.
+
+### PseudoCode
+```java=
+Functin remove(Node A, B) {
+ // Remove nodes from the beginning if they match B
+ while (A != null and A.val == B) {
+ A = A.next;
+ }
+
+ // Now, handle the rest of the list
+ Node current = A;
+ while (current != null and current.next != null) {
+ if (current.next.val == B) {
+ current.next = current.next.next;
+ } else {
+ current = current.next;
+ }
+ }
+ return A;
+}
+```
+
+
---
-### Problem 3 Reverse the linked list
+## Problem 3 Reverse the linked list
+### Linked List
+
**Note:** We can't use extra space. Manipulate the pointers only.
-**Example**
+### Example
-#### Pseudocode 2
+### Pseudocode 2
```cpp
-Function insertAtIndex(p, v, Node head) {
- // create a new node
- Node newNode = Node(v)
-
- Node t = head
-
- if (p == 0) { // edge case
- newNode.next = head
- head = newNode
- }
-
- for (i = 1; i < p; i++) { // iterating updating t p-1 times
- t = t.next
- }
-
- // Inserting the Node
- newNode.next = t.next
- t.next = newNode
+Function insertAtIndex(p,v,Node head){
+ // create a new node
+ Node newNode = Node(v)
+
+ Node t = head
+
+ if(p == 0){ // edge case
+ newNode.next = head
+ head = newNode
+ }
+
+ for(i -> 1 to p - 1){ // iterating updating t p-1 times
+ t = t.next
+ }
+
+ // Inserting the Node
+ newNode.next = t.next
+ t.next = newNode
}
```
@@ -227,11 +160,14 @@ O(K)
---
+## Problem 2 Deletion in Linked List
+
### Deletion in Linked List
*Delete the first occurrence of value X in the given linked list. If element is not present, leave as is.*
+### Examples
**Example 1:**
```java
List: 1 -> 8 -> 4 -> -2 -> 12
@@ -252,7 +188,7 @@ List: 1 -> 8 -> -2 -> 4 -> 12
The first occurrence of 4 has been deleted from the list.
```
-#### Cases:
+### Cases:
1. **Empty list i.e., head = null**
```java
@@ -290,30 +226,30 @@ List: 1 -> 8 -> -2 -> 7 -> 12
```
---
+
+
### Question
Delete the first occurrence of value **X** in the given linked list. If element is not present, leave as is.
Linked List : ```5 -> 4 -> 7 -> 1 -> NULL```
X (to Delete) : 1
-
-**Choices**
+### Choices
- [ ] 5 -> 4 -> 7 -> 1 -> NULL
- [x] 5 -> 4 -> 7 -> NULL
- [ ] 4 -> 7 -> 1 -> NULL
- [ ] 5 -> 7 -> NULL
+---
-**Explanation:**
-
-The Value 1 is not present in the Linked List. So leave as it is.
-
-Thus, the final Linked List is 5 -> 4 -> 7 -> -1 -> NULL
+### Explanation:
+The Value 1 is present at 4th index in the Linked List. So if we remove it.The final Linked List will look something like this `5 -> 4 -> 7 -> -1 -> NULL`
---
-### Deletion in Linked List Approach and Pseudocode
-#### Approach
+## Deletion in Linked List Approach and Pseudocode
+
+### Approach
- Check if the list is empty; if so, return it as is.
- If the target value X is at the head, update the head to the next node.
@@ -321,47 +257,88 @@ Thus, the final Linked List is 5 -> 4 -> 7 -> -1 -> NULL
- When X is found, skip the node containing it by updating the next reference of the previous node.
- Return the modified head (which may or may not have changed during the operation).
-#### Pseudocode
+### Pseudocode
```java
if (head == null) return head
-if (head.data == X) {
- tmp = head
- free(tmp) //automatically done in java, whereas have to do manually for c++ and other languages.
- head = Head.next
- return head
+if(head.data == X){
+ tmp = head
+ free(tmp) //automatically done in java, whereas have to do manually for c++ and other languages.
+ head = Head.next
+ return head
}
temp = head
-while (temp.next != null) {
- if (temp.next.data == X) {
- tmp = temp.next
- temp.next = temp.next.next
- free(tmp)
- return head
- }
- temp = temp.next
+while(temp.next != null) {
+ if(temp.next.data == X){
+ tmp = temp.next
+ temp.next = temp.next.next
+ free(tmp)
+ return head
+ }
+ temp = temp.next
}
return head
```
-#### Time complexity for Deletion
+### Time complexity for Deletion
**O(N)**
> It can be seen that every operation in linked list takes linear time complexity unlike arrays.
+
+
+---
+## OnePlus removes Defects
+
+### Scenerio
+**OnePlus** has a lineup of **N** mobile phones ready in their manufacturing line. It has detected a defect in one of their phone models during production.
+
+They have decided to recall all phones of the defective model from their manufacturing line. Your task is to help **OnePlus** remove all defective phones from their production lineup efficiently.
+
+### Problem
+You are given a **linked list A of N** nodes where each node represents a specific **model type of a OnePlus mobile phone** in the manufacturing line. Each node contains an integer representing the model number of the phone. You will also be given an integer **B** which represents the model number of the defective phone that needs to be removed.
+
+Your goal is to remove all **nodes** (phones) from the linked list that have the model number **B** and return the modified linked list representing the updated manufacturing line.
+
+### Approach
+
+- We need to first check for all occurrences at the head node and change the head node appropriately.
+- Then we need to check for all occurrences inside a loop and delete them one by one.
+- This problem very similar to the above problem, the only difference is that we need to remove all occurences in this problem.
+
+### PseudoCode
+```java=
+Functin remove(Node A, B) {
+ // Remove nodes from the beginning if they match B
+ while (A != null and A.val == B) {
+ A = A.next;
+ }
+
+ // Now, handle the rest of the list
+ Node current = A;
+ while (current != null and current.next != null) {
+ if (current.next.val == B) {
+ current.next = current.next.next;
+ } else {
+ current = current.next;
+ }
+ }
+ return A;
+}
+```
+
+
---
-### Problem 3 Reverse the linked list
+## Problem 3 Reverse the linked list
+### Linked List
+
**Note:** We can't use extra space. Manipulate the pointers only.
-**Example**
+### Example
 -:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach:
+### Approach:
- Check for Empty List:
- If head is null, return it as is.
- Handle Single Node List:
@@ -376,14 +353,14 @@ Please take some time to think about the solution approach on your own before re
- Update head:
- After the loop, set head to pre, making the reversed list the new head.
-#### Dry Run
+### Dry Run
**Initialize the pointers**
prev = null
curr = 2 -> 5 -> 8 -> 7 -> 3 -> null
nxt = null
-#### Iteration 1:
+### Iteration 1:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 5 -> 8 -> 7 -> 3 -> null
@@ -399,7 +376,7 @@ curr = nxt
prev = 2 -> null
curr = 5 -> 8 -> 7 -> 3 -> null
```
-#### Iteration 2:
+### Iteration 2:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 8 -> 7 -> 3 -> null
@@ -416,7 +393,7 @@ prev = 5 -> 2 -> null
curr = 8 -> 7 -> 3 -> null
```
-#### Iteration 3:
+### Iteration 3:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 7 -> 3 -> null
@@ -433,7 +410,7 @@ prev = 8 -> 5 -> 2 -> null
curr = 7 -> 3 -> null
```
-#### Iteration 4:
+### Iteration 4:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 3->null
@@ -479,122 +456,293 @@ The head of the linked list is now prev, which is the reversed linked list:
```
---
+
### Question
Reverse the given Linked List.
Linked List : 5 -> 6 -> 7 -> 8 -> 9
-**Choices**
+### Choices
- [ ] 5 -> 6 -> 7 -> 8 -> 9
- [x] 5 <- 6 <- 7 <- 8 <- 9
- [ ] 9 -> 6 -> 7 -> 8 -> 5
- [ ] 5 <- 6 -> 7 <- 8 <- 9
-
-
---
-### Reverse the LinkedList Psuedo code and Time Complexity
-#### Psuedocode
-```java
-if (head == null)
- return head;
+## Reverse the LinkedList Psuedo code and Time Complexity
-if (head.next == null)
- return head;
+### Psuedocode
+```java
cur = head;
pre = null;
while (cur != null) {
- next = cur.next;
- cur.next = pre;
- pre = cur;
- cur = next;
+ next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
}
head = pre;
```
-#### TC & SC
+### TC & SC
**Time complexity -** O(N)
**Space complexity -** O(1)
---
-### Problem 2 Check Palindrome
-Given a Linked List, check if it is a palindrome.
+---
+## Deep copy of a doubly linked list
+
-**Example:**
-maam, racecar, never, 121, 12321
+### Problem Statement
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach:
+### Approach:
- Check for Empty List:
- If head is null, return it as is.
- Handle Single Node List:
@@ -376,14 +353,14 @@ Please take some time to think about the solution approach on your own before re
- Update head:
- After the loop, set head to pre, making the reversed list the new head.
-#### Dry Run
+### Dry Run
**Initialize the pointers**
prev = null
curr = 2 -> 5 -> 8 -> 7 -> 3 -> null
nxt = null
-#### Iteration 1:
+### Iteration 1:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 5 -> 8 -> 7 -> 3 -> null
@@ -399,7 +376,7 @@ curr = nxt
prev = 2 -> null
curr = 5 -> 8 -> 7 -> 3 -> null
```
-#### Iteration 2:
+### Iteration 2:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 8 -> 7 -> 3 -> null
@@ -416,7 +393,7 @@ prev = 5 -> 2 -> null
curr = 8 -> 7 -> 3 -> null
```
-#### Iteration 3:
+### Iteration 3:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 7 -> 3 -> null
@@ -433,7 +410,7 @@ prev = 8 -> 5 -> 2 -> null
curr = 7 -> 3 -> null
```
-#### Iteration 4:
+### Iteration 4:
**Store the next node in nxt**
```java
nxt = curr.next; nxt = 3->null
@@ -479,122 +456,293 @@ The head of the linked list is now prev, which is the reversed linked list:
```
---
+
### Question
Reverse the given Linked List.
Linked List : 5 -> 6 -> 7 -> 8 -> 9
-**Choices**
+### Choices
- [ ] 5 -> 6 -> 7 -> 8 -> 9
- [x] 5 <- 6 <- 7 <- 8 <- 9
- [ ] 9 -> 6 -> 7 -> 8 -> 5
- [ ] 5 <- 6 -> 7 <- 8 <- 9
-
-
---
-### Reverse the LinkedList Psuedo code and Time Complexity
-#### Psuedocode
-```java
-if (head == null)
- return head;
+## Reverse the LinkedList Psuedo code and Time Complexity
-if (head.next == null)
- return head;
+### Psuedocode
+```java
cur = head;
pre = null;
while (cur != null) {
- next = cur.next;
- cur.next = pre;
- pre = cur;
- cur = next;
+ next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
}
head = pre;
```
-#### TC & SC
+### TC & SC
**Time complexity -** O(N)
**Space complexity -** O(1)
---
-### Problem 2 Check Palindrome
-Given a Linked List, check if it is a palindrome.
+---
+## Deep copy of a doubly linked list
+
-**Example:**
-maam, racecar, never, 121, 12321
+### Problem Statement
- +We have to create a deep copy of the Doubly Linked list with random pointers. Here there is no certain next and previous pointer, a node can point to some other node.
+The deep copy should consist of exactly `n` brand new nodes, where each new node has its value set to the value of its corresponding **original** node.
----
-### Question
-Check the Given linked list is Palindrome or not.
+Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state.
-Linked List : ```Head -> 1 -> Null```
+**Note:** None of the pointers in the new list should point to nodes in the **original list**.
-**Choices**
-- [x] YES
-- [ ] NO
+## Example
+**Input:**
+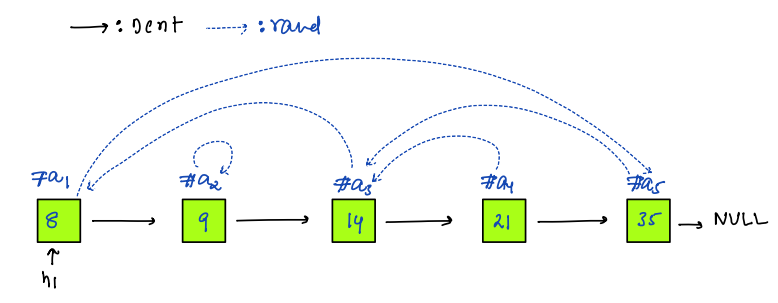
**Explanation:**
+- Here black line representing `next` of the node and dotted line representing `rand` of node.
+ - If we see node `a1`
+ - `a1.next = a2`
+ - `a1.rand = a5`
+ - If we see node `a2`
+ - `a2.next = a3`
+ - `a2.rand = a2`
+ - If we see node `a3`
+ - `a3.next = a4`
+ - `a3.rand = a1`
+ - If we see node `a4`
+ - `a4.next = a5`
+ - `a4.rand = a3`
+ - If we see node `a5`
+ - `a5.next = null`
+ - `a5.rand = a3`
+- Now we need to create the copy of input linked list, in which `data` should be same and `next` and `rand` linking should also be same, but addresses of nodes should be different.
+
+
+**Output:**
+
+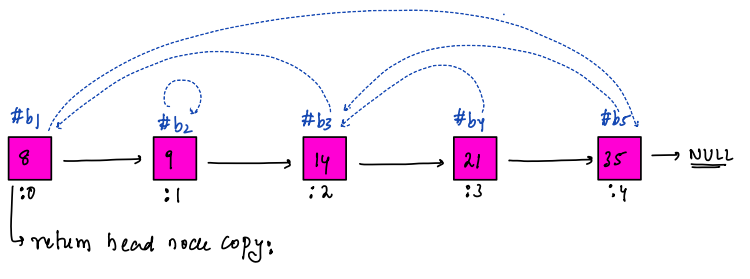
+
+
+**NOTE :** No **next or random** pointer can point to any of the node in original linked list.
+
+**Another example of how the final Structure Looks like :**
+
+We have to create a deep copy of the Doubly Linked list with random pointers. Here there is no certain next and previous pointer, a node can point to some other node.
+The deep copy should consist of exactly `n` brand new nodes, where each new node has its value set to the value of its corresponding **original** node.
----
-### Question
-Check the Given linked list is Palindrome or not.
+Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state.
-Linked List : ```Head -> 1 -> Null```
+**Note:** None of the pointers in the new list should point to nodes in the **original list**.
-**Choices**
-- [x] YES
-- [ ] NO
+## Example
+**Input:**
+
**Explanation:**
+- Here black line representing `next` of the node and dotted line representing `rand` of node.
+ - If we see node `a1`
+ - `a1.next = a2`
+ - `a1.rand = a5`
+ - If we see node `a2`
+ - `a2.next = a3`
+ - `a2.rand = a2`
+ - If we see node `a3`
+ - `a3.next = a4`
+ - `a3.rand = a1`
+ - If we see node `a4`
+ - `a4.next = a5`
+ - `a4.rand = a3`
+ - If we see node `a5`
+ - `a5.next = null`
+ - `a5.rand = a3`
+- Now we need to create the copy of input linked list, in which `data` should be same and `next` and `rand` linking should also be same, but addresses of nodes should be different.
+
+
+**Output:**
+
+
+
+
+**NOTE :** No **next or random** pointer can point to any of the node in original linked list.
+
+**Another example of how the final Structure Looks like :**
+ -Yes, The Given Linked List is an Palindrome, Because it reads the same in reverse order as well.
---
+## Deep Copy Solution flow
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+### Obvious Idea :
+Use a **HashMap** to take care of **Random Pointers.** Simple, right ?
+Yes, this takes $O(N)$ space, but can we do better ? Can we save space and solve this problem in $O(1)$ extra space ?
-### Check Palindrome Solution
+## Space Optimisation Idea
+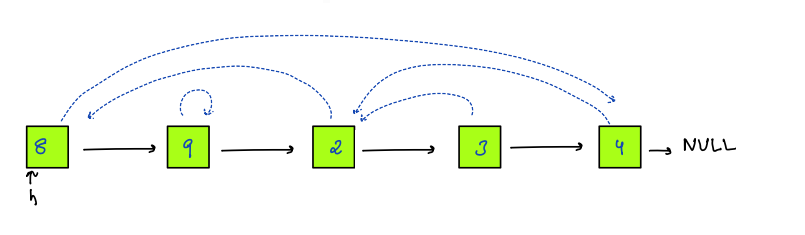
-**Solution 1 :**
-Create a copy of linked list. Reverse it and Compare
+- Take a temp node `t`.
-**Complexity**
-**Time Complexity -** O(N)
-**Space Complexity -** O(N).
+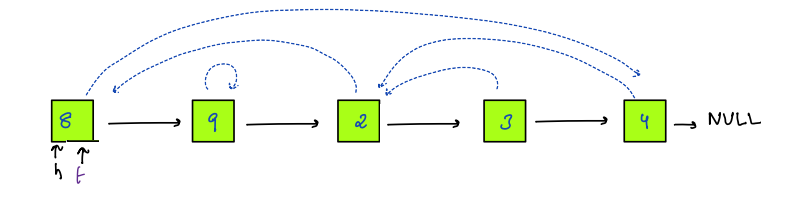
+- Create a new node with data `8` with the name `nn`.
-**Solution 2 :**
-1. Find middle element of linked list
-2. Reverse second half of linked list
-3. Compare first half and compare second half
+```cpp
+Node nn = new Node(t.data);
+```
+
-**Step wise solution:**
+- Insert this new node `nn` between `8` and `9` of original list.
+```cpp
+nn.next = t.next;
+t.next = nn;
+t = nn.next; // t 9 in original list
+```
-1. **Find length of linked list**
-```java
-n = 0
-temp = Head
-while(temp != null){
- n++
- temp = temp.next
+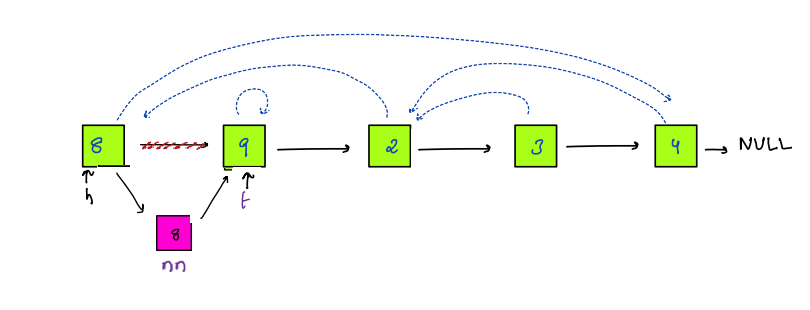
+
+
+- Again create a new node with data `9` and insert it in between `9` and `2` in original list.
+
+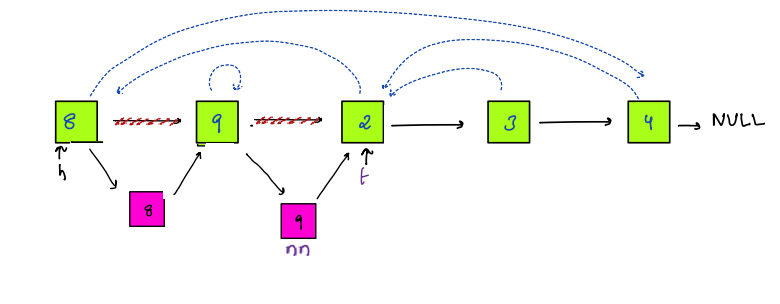
+
+- In this way create new node for all the nodes of linked list till `t!=null` and insert it in between.
+
+
+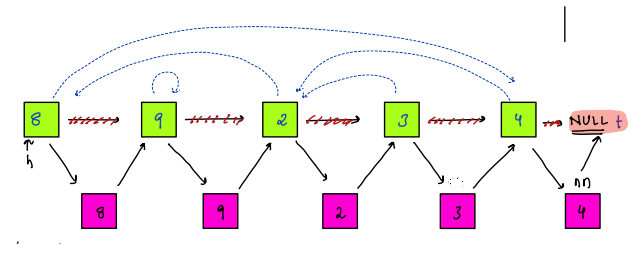
+
+
+The **Pseudocode** for this part is as follows:
+```cpp
+Node t = h;
+while(t!-NULL){
+Node nn = new Node(t.data);
+nn.next = t.next;
+t.next = nn;
+t = nn.next;
}
```
-2. **Go to the middle element**
-// If n = 10(even), we'll reverse from 6th node.
-// If n = 9(odd), then also we'll reverse from 6th node.(**5th node will be middle one that need not be compared with any node**)
-So, regardless of even/odd, we can skip (n + 1) / 2 nodes.
-```java
-temp Head
-(for i --> 1 to (n + 1) / 2){
- temp =temp.next
+**By doing this we have made our task of handling random pointers a lot easier :**
+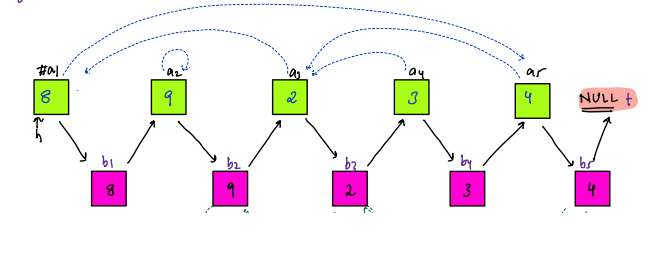
+
+
+- Now `a1.rand=a5`, so `b1.rand` should also equal to `b5`, but how can we get `b5`, here `b5=a5.next`.
+- Take two nodes `t1` and `t2`, `t1` at `h` node and `t2` at `h.next`.
+```cpp
+Node t1 = h;
+Node t2 = h.next;
+```
+
+
+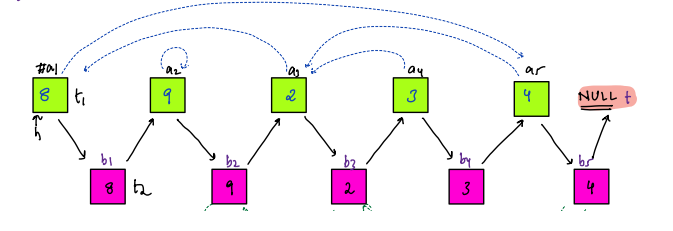
+
+- Now `t2.rand = t1.rand.next`.
+
+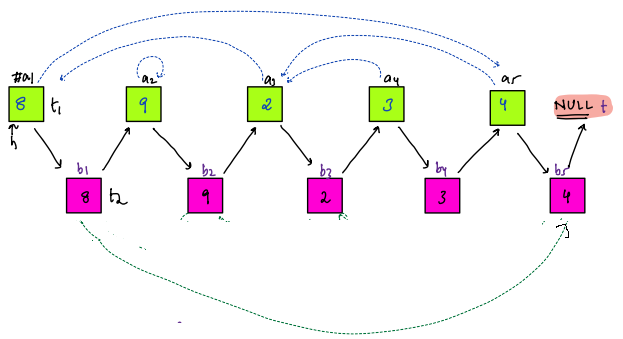
+
+- Now `t1 = t2.next` and `t2 = t1.next`, to move `t1` and `t2` forward.
+
+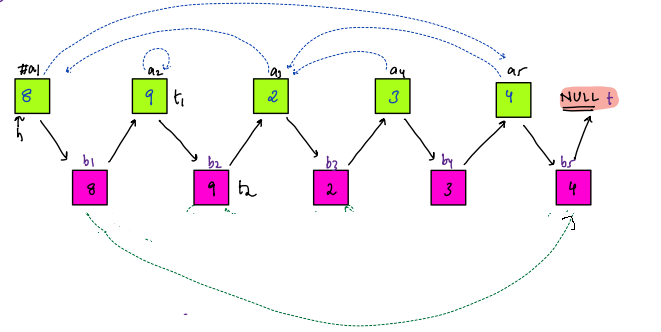
+
+- Now again `t2.rand = t1.rand.next` and `t1 = t2.next` and `t2 = t1.next` to move `t1` and `t2` forward.
+
+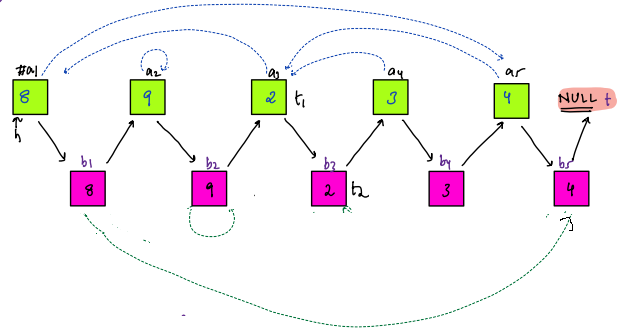
+
+- In this way do it until, `t1!=NULL`. So that every new node points to their `rand` node.
+
+- While updating `t2.next = t1.next`, we need to check `t1!=NULL`, otherwise it will give an `nullpointerexception` in last iteration when `t1` becomes `NULL`.
+
+
+Here is how the **Pseudocode** looks like:
+```cpp
+Node t1 = h;
+Node t2 = h.next;
+while(t1 != NULL){
+t2.rand = t1.rand.next;
+t1 = t2.next;
+if(t1 != NULL){
+t2 = t1.next;
+}
}
-//temp middle
```
-3. Now reverse the linked list from $((n+1)/2 + 1)th$ node.
-4. Compare both the linked list
-#### T.C & S.C
+- Now random links are also arranged in purple list.
-Total time complexity for checking palindrome is O(N) and space complexity is O(N).
+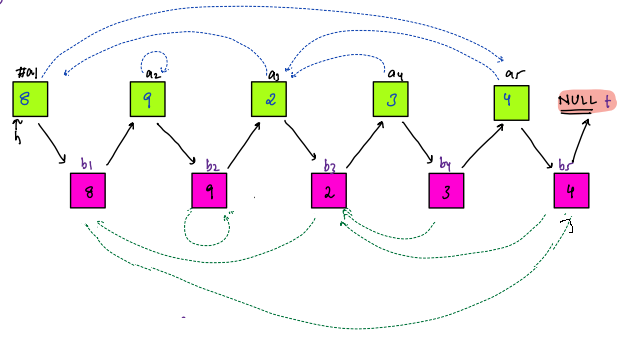
+
+- Now again take two nodes `t1` and `t2`, `t1` at `h` node and `t2` at `h.next`.
+```cpp
+Node t1 = h;
+Node t2 = h.next;
+```
+
+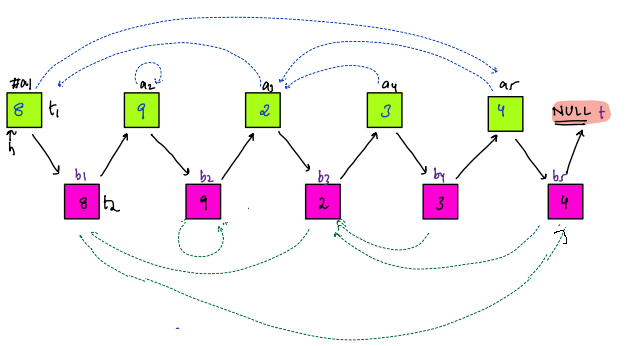
+
+- `t1.next` is actually `a2` in original list, so `t1.next = t2.next`.
+
+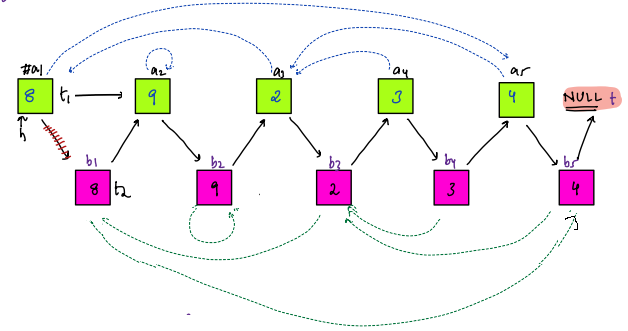
+
+- Now update `t1 = t1.next`.
+
+
+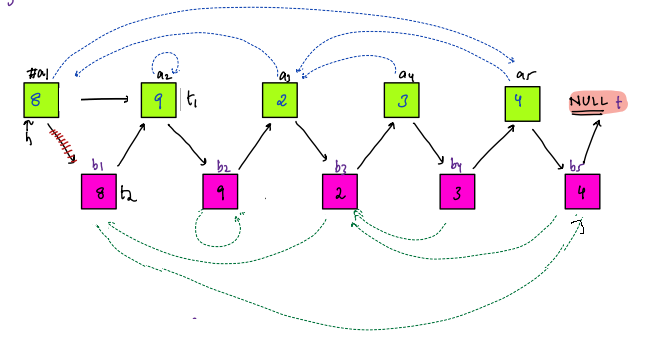
+
+- `t2.next = t1.next`.
+
+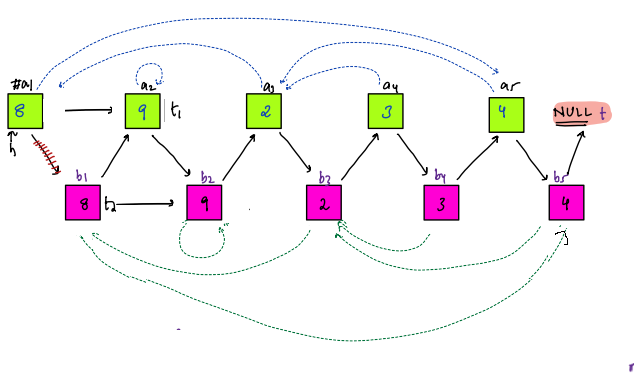
+
+- Now we will update `t2`, `t2 = t2.next`.
+
+
+
+- In this way do this, until `t1!=NULL`.
+
+```cpp
+Node dh = h.next;
+Node t1 = h;
+Node t2 = h.next;
+while(t1 != NULL){
+ t1.next = t2.next;
+ t1 = t1.next;
+ if(t1 != NULL){
+ t2.next = t1.next;
+ }
+ t2 = t2.next;
+}
+```
+
+- Now final list becomes, and we will return `dh` which we have initialized by `h.next`.
+
+
+
+
+
+## PseudoCode
+```cpp
+Node Clone(Node h) {
+ Node t = h;
+ while (t != NULL) {
+ Node nn = new Node(t.data);
+ nn.next = t.next;
+ t.next = nn;
+ t = nn.next;
+ }
+
+ Node t1 = h;
+ Node t2 = h.next;
+ while (t1 != NULL) {
+ t2.rand = t1.rand.next;
+ t1 = t2.next;
+ if (t1 != NULL) {
+ t2 = t1.next;
+ }
+ }
+
+ Node dh = h.next;
+ t1 = h;
+ t2 = h.next;
+ while (t1 != NULL) {
+ t1.next = t2.next;
+ t1 = t1.next;
+ if (t1 != NULL) {
+ t2.next = t1.next;
+ }
+ t2 = t2.next;
+ }
+
+ return dh;
+}
+
+```
+
+## Complexity
+- **Time Complexity:** $O(N)$
+- **Space Complexity:** $O(1)$ because we are **not** using extra memory like **Hashmap**.
+
+---
+
+### Question
+What is the time complexity of creating a deep copy of a Doubly Linked List consists of N nodes with random pointers using extra space?
+
+### Choices
+- [x] O(N)
+- [ ] O(N * N)
+- [ ] O(1)
+- [ ] O(log(N))
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md b/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md
index 13691b3..fe072d3 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md
@@ -1,503 +1,571 @@
-# Linked List 2: Sorting and Detecting Loop
+# Linked List 3: Problems & Doubly Linked List
----
-### Question
-What is the time complexity needed to delete a node from a linked list?
+## Revision Quizzes
-**Choices**
-- [ ] O(1)
-- [ ] O(log(N))
-- [x] O(N)
-- [ ] O(N^2)
-
-#### Explanation
+### Question
+What is the time complexity to merge two sorted linked lists into a single sorted linked list?
-To delete a node from the linked list we need to traverse till that node. In the worst case, the time-complexity would be O(N).
+### Choices
+- [x] O(n + m)
+- [ ] O(n log(n))
+- [ ] O(n * m)
+- [ ] O(m log(m))
---
### Question
-What is the time complexity needed to insert a node as the head of a linked list?
+How is the starting point of the cycle found once a cycle is detected in the linked list?
+### Choices
-**Choices**
-- [x] O(1)
-- [ ] O(log(N))
-- [ ] O(N)
-- [ ] O(N$^2$)
+- [x] Reset the slow pointer to head and move both pointers one step at a time.
+- [ ] Continue moving fast pointer until it reaches the head.
+- [ ] Move slow pointer two steps at a time.
+- [ ] Move fast pointer to the start of the cycle.
-**Explanation**
+---
+## Agenda
+- What is doubly linked list?
+- LRU Cache
+- Check if LL is palindrome
-No traversal is needed to reach the head node. Therefore the time complexity needed is constant i.e. O(1).
+So let's start.
---
-### Question
-What is the time complexity needed to delete the last node from a linked list?
+### What is doubly linked list?
+A dll is a type of data structure used to store collection of elements. It is similar to a singly linked list but with an additional feature- each node in a dll contains pointers or references to both the next and the previous nodes in the list.
-**Choices**
-- [ ] O(1)
-- [ ] O(log(N))
-- [x] O(N)
-- [ ] O(N$^2$)
+### Example
-**Explanation:**
+
-Yes, The Given Linked List is an Palindrome, Because it reads the same in reverse order as well.
---
+## Deep Copy Solution flow
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+### Obvious Idea :
+Use a **HashMap** to take care of **Random Pointers.** Simple, right ?
+Yes, this takes $O(N)$ space, but can we do better ? Can we save space and solve this problem in $O(1)$ extra space ?
-### Check Palindrome Solution
+## Space Optimisation Idea
+
-**Solution 1 :**
-Create a copy of linked list. Reverse it and Compare
+- Take a temp node `t`.
-**Complexity**
-**Time Complexity -** O(N)
-**Space Complexity -** O(N).
+
+- Create a new node with data `8` with the name `nn`.
-**Solution 2 :**
-1. Find middle element of linked list
-2. Reverse second half of linked list
-3. Compare first half and compare second half
+```cpp
+Node nn = new Node(t.data);
+```
+
-**Step wise solution:**
+- Insert this new node `nn` between `8` and `9` of original list.
+```cpp
+nn.next = t.next;
+t.next = nn;
+t = nn.next; // t 9 in original list
+```
-1. **Find length of linked list**
-```java
-n = 0
-temp = Head
-while(temp != null){
- n++
- temp = temp.next
+
+
+
+- Again create a new node with data `9` and insert it in between `9` and `2` in original list.
+
+
+
+- In this way create new node for all the nodes of linked list till `t!=null` and insert it in between.
+
+
+
+
+
+The **Pseudocode** for this part is as follows:
+```cpp
+Node t = h;
+while(t!-NULL){
+Node nn = new Node(t.data);
+nn.next = t.next;
+t.next = nn;
+t = nn.next;
}
```
-2. **Go to the middle element**
-// If n = 10(even), we'll reverse from 6th node.
-// If n = 9(odd), then also we'll reverse from 6th node.(**5th node will be middle one that need not be compared with any node**)
-So, regardless of even/odd, we can skip (n + 1) / 2 nodes.
-```java
-temp Head
-(for i --> 1 to (n + 1) / 2){
- temp =temp.next
+**By doing this we have made our task of handling random pointers a lot easier :**
+
+
+
+- Now `a1.rand=a5`, so `b1.rand` should also equal to `b5`, but how can we get `b5`, here `b5=a5.next`.
+- Take two nodes `t1` and `t2`, `t1` at `h` node and `t2` at `h.next`.
+```cpp
+Node t1 = h;
+Node t2 = h.next;
+```
+
+
+
+
+- Now `t2.rand = t1.rand.next`.
+
+
+
+- Now `t1 = t2.next` and `t2 = t1.next`, to move `t1` and `t2` forward.
+
+
+
+- Now again `t2.rand = t1.rand.next` and `t1 = t2.next` and `t2 = t1.next` to move `t1` and `t2` forward.
+
+
+
+- In this way do it until, `t1!=NULL`. So that every new node points to their `rand` node.
+
+- While updating `t2.next = t1.next`, we need to check `t1!=NULL`, otherwise it will give an `nullpointerexception` in last iteration when `t1` becomes `NULL`.
+
+
+Here is how the **Pseudocode** looks like:
+```cpp
+Node t1 = h;
+Node t2 = h.next;
+while(t1 != NULL){
+t2.rand = t1.rand.next;
+t1 = t2.next;
+if(t1 != NULL){
+t2 = t1.next;
+}
}
-//temp middle
```
-3. Now reverse the linked list from $((n+1)/2 + 1)th$ node.
-4. Compare both the linked list
-#### T.C & S.C
+- Now random links are also arranged in purple list.
-Total time complexity for checking palindrome is O(N) and space complexity is O(N).
+
+
+- Now again take two nodes `t1` and `t2`, `t1` at `h` node and `t2` at `h.next`.
+```cpp
+Node t1 = h;
+Node t2 = h.next;
+```
+
+
+
+- `t1.next` is actually `a2` in original list, so `t1.next = t2.next`.
+
+
+
+- Now update `t1 = t1.next`.
+
+
+
+
+- `t2.next = t1.next`.
+
+
+
+- Now we will update `t2`, `t2 = t2.next`.
+
+
+
+- In this way do this, until `t1!=NULL`.
+
+```cpp
+Node dh = h.next;
+Node t1 = h;
+Node t2 = h.next;
+while(t1 != NULL){
+ t1.next = t2.next;
+ t1 = t1.next;
+ if(t1 != NULL){
+ t2.next = t1.next;
+ }
+ t2 = t2.next;
+}
+```
+
+- Now final list becomes, and we will return `dh` which we have initialized by `h.next`.
+
+
+
+
+
+## PseudoCode
+```cpp
+Node Clone(Node h) {
+ Node t = h;
+ while (t != NULL) {
+ Node nn = new Node(t.data);
+ nn.next = t.next;
+ t.next = nn;
+ t = nn.next;
+ }
+
+ Node t1 = h;
+ Node t2 = h.next;
+ while (t1 != NULL) {
+ t2.rand = t1.rand.next;
+ t1 = t2.next;
+ if (t1 != NULL) {
+ t2 = t1.next;
+ }
+ }
+
+ Node dh = h.next;
+ t1 = h;
+ t2 = h.next;
+ while (t1 != NULL) {
+ t1.next = t2.next;
+ t1 = t1.next;
+ if (t1 != NULL) {
+ t2.next = t1.next;
+ }
+ t2 = t2.next;
+ }
+
+ return dh;
+}
+
+```
+
+## Complexity
+- **Time Complexity:** $O(N)$
+- **Space Complexity:** $O(1)$ because we are **not** using extra memory like **Hashmap**.
+
+---
+
+### Question
+What is the time complexity of creating a deep copy of a Doubly Linked List consists of N nodes with random pointers using extra space?
+
+### Choices
+- [x] O(N)
+- [ ] O(N * N)
+- [ ] O(1)
+- [ ] O(log(N))
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md b/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md
index 13691b3..fe072d3 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Linked List 2 Sorting and Detecting Loop.md
@@ -1,503 +1,571 @@
-# Linked List 2: Sorting and Detecting Loop
+# Linked List 3: Problems & Doubly Linked List
----
-### Question
-What is the time complexity needed to delete a node from a linked list?
+## Revision Quizzes
-**Choices**
-- [ ] O(1)
-- [ ] O(log(N))
-- [x] O(N)
-- [ ] O(N^2)
-
-#### Explanation
+### Question
+What is the time complexity to merge two sorted linked lists into a single sorted linked list?
-To delete a node from the linked list we need to traverse till that node. In the worst case, the time-complexity would be O(N).
+### Choices
+- [x] O(n + m)
+- [ ] O(n log(n))
+- [ ] O(n * m)
+- [ ] O(m log(m))
---
### Question
-What is the time complexity needed to insert a node as the head of a linked list?
+How is the starting point of the cycle found once a cycle is detected in the linked list?
+### Choices
-**Choices**
-- [x] O(1)
-- [ ] O(log(N))
-- [ ] O(N)
-- [ ] O(N$^2$)
+- [x] Reset the slow pointer to head and move both pointers one step at a time.
+- [ ] Continue moving fast pointer until it reaches the head.
+- [ ] Move slow pointer two steps at a time.
+- [ ] Move fast pointer to the start of the cycle.
-**Explanation**
+---
+## Agenda
+- What is doubly linked list?
+- LRU Cache
+- Check if LL is palindrome
-No traversal is needed to reach the head node. Therefore the time complexity needed is constant i.e. O(1).
+So let's start.
---
-### Question
-What is the time complexity needed to delete the last node from a linked list?
+### What is doubly linked list?
+A dll is a type of data structure used to store collection of elements. It is similar to a singly linked list but with an additional feature- each node in a dll contains pointers or references to both the next and the previous nodes in the list.
-**Choices**
-- [ ] O(1)
-- [ ] O(log(N))
-- [x] O(N)
-- [ ] O(N$^2$)
+### Example
-**Explanation:**
+ -To delete the last node from the linked list we need to traverse till that node. In that case, the time-complexity would be O(N).
+The `previous` pointer of the first node always points to `null` and the `next` pointer of the last node also points to `null` in the doubly linked list.
----
-### Question
-
-Can we do Binary Search in a sorted Linked List?
+### Structure
+```
+class Node {
+ int data;
+ Node prev, next;
+
+ Node(x) {
+ data = x;
+ prev = NULL;
+ next = NULL;
+ }
+}
+```
-**Choices**
-- [ ] Yes
-- [x] No
+
-To delete the last node from the linked list we need to traverse till that node. In that case, the time-complexity would be O(N).
+The `previous` pointer of the first node always points to `null` and the `next` pointer of the last node also points to `null` in the doubly linked list.
----
-### Question
-
-Can we do Binary Search in a sorted Linked List?
+### Structure
+```
+class Node {
+ int data;
+ Node prev, next;
+
+ Node(x) {
+ data = x;
+ prev = NULL;
+ next = NULL;
+ }
+}
+```
-**Choices**
-- [ ] Yes
-- [x] No
+ +---
-**Explanation:**
-Binary search relies on random access to elements, which is not possible in a linked list.
+### Question
+`prev` Pointer of Head of Doubly Linked List points to:
+### Choices
+- [ ] Next to Head Node
+- [x] Null pointer
+- [ ] Tail
+- [ ] Depends
---
-### Problem 1 Find the middle element.
+## Real Life Application - Spotify's Music Manager
-Given a Linked List, Find the middle element.
-**Examples**
+### Scenerio
+**Spotify** wants to enhance its user experience by allowing users to navigate through their music playlist seamlessly using "**next**" and "**previous**" song functionalities.
-Following 0 based indexing: The middle node is the node having the index (n / 2), where n is the number of nodes.
+### Problem
+You are tasked to implement this feature using a **doubly linked list** where each node represents a song in the playlist. The system should support the following operations:
-```cpp
-Input: [1 -> 2 -> 3 -> 4 -> 5]
-Output: [3]
+- **Add Song**: Insert a new song into the playlist. If the playlist is currently empty, this song becomes the "**Current song**".
+- **Play Next Song**: Move to the next song in the playlist and display its details.
+- **Play Previous Song**: Move to the previous song in the playlist and display its details.
+- **Current Song**: Display the **details** of the current song **being played**.
-Here 3 is the middle element
-```
+### Constraints:
-```cpp
-Input: [1 -> 2 -> 3 -> 4]
-Output: [2]
+- Each song is uniquely identified by its song ID.
+- The playlist starts empty, and the first song added becomes the current song.
+- All operations are valid within the current state of the playlist (i.e., there won’t be a request to play the next song if there is no next song, and no request to play the previous song if there is no previous song).
-There are two middle elements here: 2 and 3 respectively.
+### Example Input :
+```=
+Add Song (ID: 1, Name: "Yesterday Blues")
+Add Song (ID: 2, Name: "Imagine Dragons")
+Play Next Song
+Current Song
+Add Song (ID: 3, Name: "Hotel California")
+Play Next Song
+Current Song
+Play Previous Song
+Play Previous Song
+Current Song
```
----
+### Output :
+``` =
+Current song playing: Imagine Dragons
+Current song playing: Hotel California
+Current song playing: Yesterday Blues
+```
+
+Since we shall have to move to and from in a list, we can use doubly linked list. This is a real life application of DLL.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+---
+## Problem 1 Insert node just before tail in a dll
-### Find the middle element Solution
-#### Solution
+1. Say we have direct access to first and last node via head and tail pointer.
+2. temp = tail.prev
+3. Then we can make connections as shown in image below
-* First, We will find the length of the linked-list.
-* Now we will traverse half the length to find the middle node
+
+---
-**Explanation:**
-Binary search relies on random access to elements, which is not possible in a linked list.
+### Question
+`prev` Pointer of Head of Doubly Linked List points to:
+### Choices
+- [ ] Next to Head Node
+- [x] Null pointer
+- [ ] Tail
+- [ ] Depends
---
-### Problem 1 Find the middle element.
+## Real Life Application - Spotify's Music Manager
-Given a Linked List, Find the middle element.
-**Examples**
+### Scenerio
+**Spotify** wants to enhance its user experience by allowing users to navigate through their music playlist seamlessly using "**next**" and "**previous**" song functionalities.
-Following 0 based indexing: The middle node is the node having the index (n / 2), where n is the number of nodes.
+### Problem
+You are tasked to implement this feature using a **doubly linked list** where each node represents a song in the playlist. The system should support the following operations:
-```cpp
-Input: [1 -> 2 -> 3 -> 4 -> 5]
-Output: [3]
+- **Add Song**: Insert a new song into the playlist. If the playlist is currently empty, this song becomes the "**Current song**".
+- **Play Next Song**: Move to the next song in the playlist and display its details.
+- **Play Previous Song**: Move to the previous song in the playlist and display its details.
+- **Current Song**: Display the **details** of the current song **being played**.
-Here 3 is the middle element
-```
+### Constraints:
-```cpp
-Input: [1 -> 2 -> 3 -> 4]
-Output: [2]
+- Each song is uniquely identified by its song ID.
+- The playlist starts empty, and the first song added becomes the current song.
+- All operations are valid within the current state of the playlist (i.e., there won’t be a request to play the next song if there is no next song, and no request to play the previous song if there is no previous song).
-There are two middle elements here: 2 and 3 respectively.
+### Example Input :
+```=
+Add Song (ID: 1, Name: "Yesterday Blues")
+Add Song (ID: 2, Name: "Imagine Dragons")
+Play Next Song
+Current Song
+Add Song (ID: 3, Name: "Hotel California")
+Play Next Song
+Current Song
+Play Previous Song
+Play Previous Song
+Current Song
```
----
+### Output :
+``` =
+Current song playing: Imagine Dragons
+Current song playing: Hotel California
+Current song playing: Yesterday Blues
+```
+
+Since we shall have to move to and from in a list, we can use doubly linked list. This is a real life application of DLL.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+---
+## Problem 1 Insert node just before tail in a dll
-### Find the middle element Solution
-#### Solution
+1. Say we have direct access to first and last node via head and tail pointer.
+2. temp = tail.prev
+3. Then we can make connections as shown in image below
-* First, We will find the length of the linked-list.
-* Now we will traverse half the length to find the middle node
+ +### Pseudocode
-#### Pseudocode
-```cpp
-function findMiddle(head)
- if head is null
- return null
-
- count = 0
- current = head
- while current is not null
- count = count + 1
- current = current.next
-
- middleIndex = count / 2
- current = head
- for i = 0 to middleIndex - 1
- current = current.next
-
- return current
+```javascript
+function insert_back(Node head, Node tail, Node new_node) {
+ temp = tail.prev;
+ new_node.prev = temp;
+ new_node.next = tail;
+ temp.next = new_node;
+ tail.prev = new_node
}
```
-#### Complexity
-**Time Complexity:** O(n * 2) = O(n)
-**Space Complexity:** O(1)
+### T.C
+O(1)
-#### Optimized Solution
-We can optimize the solution using the **Two Pointers** technique.
-* Take two pointers initially pointing at the head of the Linked List and name them slowPointer and fastPointer respectively.
-* The fastPointer will travel two nodes at a time, whereas the slowPointer will traverse a single node at a time
-* When the fastPointer reaches the end node, the slowPointer must necessarily be pointing at the middle node
-
+### Pseudocode
-#### Pseudocode
-```cpp
-function findMiddle(head)
- if head is null
- return null
-
- count = 0
- current = head
- while current is not null
- count = count + 1
- current = current.next
-
- middleIndex = count / 2
- current = head
- for i = 0 to middleIndex - 1
- current = current.next
-
- return current
+```javascript
+function insert_back(Node head, Node tail, Node new_node) {
+ temp = tail.prev;
+ new_node.prev = temp;
+ new_node.next = tail;
+ temp.next = new_node;
+ tail.prev = new_node
}
```
-#### Complexity
-**Time Complexity:** O(n * 2) = O(n)
-**Space Complexity:** O(1)
+### T.C
+O(1)
-#### Optimized Solution
-We can optimize the solution using the **Two Pointers** technique.
-* Take two pointers initially pointing at the head of the Linked List and name them slowPointer and fastPointer respectively.
-* The fastPointer will travel two nodes at a time, whereas the slowPointer will traverse a single node at a time
-* When the fastPointer reaches the end node, the slowPointer must necessarily be pointing at the middle node
- +---
-#### Pseudocode
-```java
-function findMiddleTwoPointers(head)
- if head is null
- return null
-
- slowPointer = head
- fastPointer = head
-
- while fastPointer is not null and fastPointer.next is not null
- slowPointer = slowPointer.next
- fastPointer = fastPointer.next.next
-
- return slowPointer
-```
-#### Complexity
-**Time Complexity:** O(n / 2) = O(n)
-**Space Complexity:** O(1)
+### Question
+In a doubly linked list, the number of pointers affected for an insertion operation between two nodes will be?
+### Choices
+- [ ] 1
+- [ ] 2
+- [ ] 3
+- [x] 4
+- [ ] Depends
---
-### Problem 2 Merge two sorted Linked Lists
+## Problem 2 Delete a given node from dll
-Given two sorted Linked Lists, Merge them into a single sorted linked list.
-**Example 1 :**
+### Problem Statement
+Delete a given node from dll
+1. Node reference is given
+2. Given node will not be head/tail
+3. DLL is not NULL
-```cpp
-Input: [1 -> 2 -> 8 -> 10], [3 -> 5 -> 9 -> 11]
+Example -
+Say we are given address of node x (#adx), then below connections have to be made
-Output: [1 -> 2 -> 3 -> 8 -> 9 -> 10 -> 11]
+
+---
-#### Pseudocode
-```java
-function findMiddleTwoPointers(head)
- if head is null
- return null
-
- slowPointer = head
- fastPointer = head
-
- while fastPointer is not null and fastPointer.next is not null
- slowPointer = slowPointer.next
- fastPointer = fastPointer.next.next
-
- return slowPointer
-```
-#### Complexity
-**Time Complexity:** O(n / 2) = O(n)
-**Space Complexity:** O(1)
+### Question
+In a doubly linked list, the number of pointers affected for an insertion operation between two nodes will be?
+### Choices
+- [ ] 1
+- [ ] 2
+- [ ] 3
+- [x] 4
+- [ ] Depends
---
-### Problem 2 Merge two sorted Linked Lists
+## Problem 2 Delete a given node from dll
-Given two sorted Linked Lists, Merge them into a single sorted linked list.
-**Example 1 :**
+### Problem Statement
+Delete a given node from dll
+1. Node reference is given
+2. Given node will not be head/tail
+3. DLL is not NULL
-```cpp
-Input: [1 -> 2 -> 8 -> 10], [3 -> 5 -> 9 -> 11]
+Example -
+Say we are given address of node x (#adx), then below connections have to be made
-Output: [1 -> 2 -> 3 -> 8 -> 9 -> 10 -> 11]
+ +
+### Pseudocode
+```
+ function remove(Node x) {
+ p = x.prev
+ n = x.next
+ p.next = n;
+ n.prev = p;
+ x.prev = x.next = NULL;
+ free(x);
+ }
```
-**Example 2 :**
+### T.C
+O(1)
-```cpp
-Input: [1 -> 7 -> 8 -> 9], [2 -> 5 -> 10 -> 11]
+---
+## Memory Hierarchy
-Output: [1 -> 2 -> 5 -> 7 -> 8 -> 9 -> 11]
-```
----
-### Question
-Given two sorted Linked Lists, Merge them into a single sorted linked list.
+
+
+### Pseudocode
+```
+ function remove(Node x) {
+ p = x.prev
+ n = x.next
+ p.next = n;
+ n.prev = p;
+ x.prev = x.next = NULL;
+ free(x);
+ }
```
-**Example 2 :**
+### T.C
+O(1)
-```cpp
-Input: [1 -> 7 -> 8 -> 9], [2 -> 5 -> 10 -> 11]
+---
+## Memory Hierarchy
-Output: [1 -> 2 -> 5 -> 7 -> 8 -> 9 -> 11]
-```
----
-### Question
-Given two sorted Linked Lists, Merge them into a single sorted linked list.
+ -`Input: [2 -> 10 -> 11] [1 -> 5 -> 12 -> 15]`
+Cache Memory is a special very high-speed memory. The cache is a smaller and faster memory that stores copies of the data from frequently used main memory locations. There are various different independent caches in a CPU, which store instructions and data. The most important use of cache memory is that it is used to reduce the average time to access data from the main memory.
-**Choices**
-- [x] [1 -> 2 -> 5 -> 10 -> 11 -> 12 -> 15]
-- [ ] [2 -> 10 -> 11 -> 1 -> 5 -> 12 -> 15]
-- [ ] [1 -> 5 -> 12 -> 15 -> 2 -> 10 -> 11]
-- [ ] [1 -> 2 -> 10 -> 5 -> 12 -> 11 -> 15]
+There are different ways of implementing cache, one of them is LRU cache.
+The Least Recently Used (LRU) Cache operates on the principle that the data most recently accessed is likely to be accessed again in the near future. By evicting the least recently accessed items first, LRU Cache ensures that the most relevant data remains available in the cache.
---
+## Problem 3 Implement LRU Cache
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+### Problem Statement
+We have been given a running stream of integers and the fixed memory size of `M`, we have to maintain the most recent `M` elements. In case the current memory is full, we have to delete the least recent element and insert the current data into the memory (as the most recent item).
-### Merge two sorted Linked Lists Solution
-#### Solution
- * Base Cases Handling: First of all, we need to take care of the Base cases: if either list is empty,we return the other list
- * Determine Merged List's Head: The algorithm compares the first nodes of the two lists. The smaller node becomes the head of the merged list.
- * Merge the Remaining Nodes:Merge the remaining nodes in such a way that whichever linked lists node is the smallest, we add it to the current list
- * We continue doing this till the end of one of the linked lists is reached
- * Finally we attach any remaining nodes from list1 or list2
-* Returning the Result: We return the linked list
+### Example
-#### Pseudocode
+{ 7, 3, 9, 2, 6, 10, 14, 2, 10, 15, 8, 14 }
+Given cache size = 5
-```cpp
-function mergeSortedLists(list1, list2)
- if list1 is null
- return list2
- if list2 is null
- return list1
-
- mergedList = null
-
- if list1.data <= list2.data
- mergedList = list1
- list1 = list1.next
- else
- mergedList = list2
- list2 = list2.next
-
- current = mergedList
-
- while list1 is not null and list2 is not null
- if list1.data <= list2.data
- current.next = list1
- list1 = list1.next
- else
- current.next = list2
- list2 = list2.next
- current = current.next
-
- if list1 is not null
- current.next = list1
- if list2 is not null
- current.next = list2
-
- return mergedList
-
-}
+Insert 7
+```
+-----------
+7
+-----------
+size = 1
```
-#### Complexity
-**Time Complexity:** O(n + m)
-**Space Complexity:** O(1)
+Insert 3
+```
+-----------
+7 3
+-----------
+size = 2
+```
----
-### Problem 3 Sort a Linked List
+Insert 9
+```
+------------
+7 3 9
+------------
+size = 3
+```
-A Linked List is given, Sort the Linked list using merge sort.
+Insert 2
+```
+------------
+7 3 9 2
+------------
+size = 4
+```
-**Example**
-```cpp
-Input: [1 -> 2 -> 5 -> 4 -> 3]
-Output: [1 -> 2 -> 3 -> 4 -> 5]
+Insert 6
+```
+----------
+7 3 9 2 6
+----------
+size = 5
+```
+Insert 10
+```
+remove 7
+-----------
+3 9 2 6 10
+-----------
+size = 5
```
-```cpp
-Input: [1 -> 4 -> 3 -> 2]
-Output: [1 -> 2 -> 3 -> 4]
+Insert 14
+```
+remove 3
+------------
+9 2 6 10 14
+------------
+size = 5
+```
+Insert 2
+```
+2 is already there, remove it and add at end
+-----------
+9 6 10 14 2
+-----------
+size = 5
```
+Insert 10
+```
+10 is already there, remove it and add at end
+-----------
+9 6 14 2 10
+-----------
+size = 5
+```
-#### Solution
+Insert 15
+```
+remove 9
+------------
+6 14 2 10 15
+------------
+size = 5
+```
-**Base Case:**
-`Input: [2 -> 10 -> 11] [1 -> 5 -> 12 -> 15]`
+Cache Memory is a special very high-speed memory. The cache is a smaller and faster memory that stores copies of the data from frequently used main memory locations. There are various different independent caches in a CPU, which store instructions and data. The most important use of cache memory is that it is used to reduce the average time to access data from the main memory.
-**Choices**
-- [x] [1 -> 2 -> 5 -> 10 -> 11 -> 12 -> 15]
-- [ ] [2 -> 10 -> 11 -> 1 -> 5 -> 12 -> 15]
-- [ ] [1 -> 5 -> 12 -> 15 -> 2 -> 10 -> 11]
-- [ ] [1 -> 2 -> 10 -> 5 -> 12 -> 11 -> 15]
+There are different ways of implementing cache, one of them is LRU cache.
+The Least Recently Used (LRU) Cache operates on the principle that the data most recently accessed is likely to be accessed again in the near future. By evicting the least recently accessed items first, LRU Cache ensures that the most relevant data remains available in the cache.
---
+## Problem 3 Implement LRU Cache
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+### Problem Statement
+We have been given a running stream of integers and the fixed memory size of `M`, we have to maintain the most recent `M` elements. In case the current memory is full, we have to delete the least recent element and insert the current data into the memory (as the most recent item).
-### Merge two sorted Linked Lists Solution
-#### Solution
- * Base Cases Handling: First of all, we need to take care of the Base cases: if either list is empty,we return the other list
- * Determine Merged List's Head: The algorithm compares the first nodes of the two lists. The smaller node becomes the head of the merged list.
- * Merge the Remaining Nodes:Merge the remaining nodes in such a way that whichever linked lists node is the smallest, we add it to the current list
- * We continue doing this till the end of one of the linked lists is reached
- * Finally we attach any remaining nodes from list1 or list2
-* Returning the Result: We return the linked list
+### Example
-#### Pseudocode
+{ 7, 3, 9, 2, 6, 10, 14, 2, 10, 15, 8, 14 }
+Given cache size = 5
-```cpp
-function mergeSortedLists(list1, list2)
- if list1 is null
- return list2
- if list2 is null
- return list1
-
- mergedList = null
-
- if list1.data <= list2.data
- mergedList = list1
- list1 = list1.next
- else
- mergedList = list2
- list2 = list2.next
-
- current = mergedList
-
- while list1 is not null and list2 is not null
- if list1.data <= list2.data
- current.next = list1
- list1 = list1.next
- else
- current.next = list2
- list2 = list2.next
- current = current.next
-
- if list1 is not null
- current.next = list1
- if list2 is not null
- current.next = list2
-
- return mergedList
-
-}
+Insert 7
+```
+-----------
+7
+-----------
+size = 1
```
-#### Complexity
-**Time Complexity:** O(n + m)
-**Space Complexity:** O(1)
+Insert 3
+```
+-----------
+7 3
+-----------
+size = 2
+```
----
-### Problem 3 Sort a Linked List
+Insert 9
+```
+------------
+7 3 9
+------------
+size = 3
+```
-A Linked List is given, Sort the Linked list using merge sort.
+Insert 2
+```
+------------
+7 3 9 2
+------------
+size = 4
+```
-**Example**
-```cpp
-Input: [1 -> 2 -> 5 -> 4 -> 3]
-Output: [1 -> 2 -> 3 -> 4 -> 5]
+Insert 6
+```
+----------
+7 3 9 2 6
+----------
+size = 5
+```
+Insert 10
+```
+remove 7
+-----------
+3 9 2 6 10
+-----------
+size = 5
```
-```cpp
-Input: [1 -> 4 -> 3 -> 2]
-Output: [1 -> 2 -> 3 -> 4]
+Insert 14
+```
+remove 3
+------------
+9 2 6 10 14
+------------
+size = 5
+```
+Insert 2
+```
+2 is already there, remove it and add at end
+-----------
+9 6 10 14 2
+-----------
+size = 5
```
+Insert 10
+```
+10 is already there, remove it and add at end
+-----------
+9 6 14 2 10
+-----------
+size = 5
+```
-#### Solution
+Insert 15
+```
+remove 9
+------------
+6 14 2 10 15
+------------
+size = 5
+```
-**Base Case:**The function starts by checking if the head of the linked list is null or if it has only one element (i.e., head.next is null). These are the base cases for the recursion. If either of these conditions is met, it means that the list is already sorted (either empty or has only one element), so the function simply returns the head itself. +Insert 8 +``` +remove 6 +------------ +14 2 10 15 8 +------------ +size = 5 +``` -**Find the Middle Node:**
If the base case is not met, the function proceeds to sort the list. First, it calls the findMiddle function to find the middle node of the current list. This step is essential for dividing the list into two halves for sorting. +Insert 14 +``` +14 is already there, remove it and add at end +------------ +2 10 15 8 14 +------------ +size = 5 +``` -**Split the List:**
After finding the middle node (middle), the function creates a new pointer nextToMiddle to store the next node after the middle node. Then, it severs the connection between the middle node and the next node by setting middle.next to null. This effectively splits the list into two separate sublists: left, which starts from head and ends at middle, and right, which starts from nextToMiddle. +--- -**Recursively Sort Both Halves:**
The function now recursively calls itself on both left and right sublists. This recursive step continues until each sublist reaches the base case (empty or one element). Each recursive call sorts its respective sublist. -**Merge the Sorted Halves:**
Once the recursive calls return and both left and right sublists are sorted, the function uses the mergeSortedLists function to merge these two sorted sublists into a single sorted list. This merging process combines the elements from left and right in ascending order. +### Question +What is the behavior of an LRU cache memory when a new item is inserted and the cache is already full? -**Return the Sorted List:**
Finally, the function returns the sortedList, which is the fully sorted linked list obtained by merging the sorted left and right sublists +### Choices -#### Pseudocode -```cpp -// Function to merge two sorted linked lists +- [x] The new item is added to the cache, and the least recently used item is removed from the cache. +- [ ] The new item is not added to the cache, and the least recently used item is not removed from the cache. +- [ ] The new item is added to the cache, and the least recently used item is updated to be the most recently used item. +- [ ] The new item is not added to the cache, and the most recently used item is removed from the cache. -function mergeSortedLists(list1, list2) - if list1 is null - return list2 - if list2 is null - return list1 - - mergedList = null - - if list1.data <= list2.data - mergedList = list1 - mergedList.next = mergeSortedLists(list1.next, list2) - else - mergedList = list2 - mergedList.next = mergeSortedLists(list1, list2.next) - - return mergedList -function findMiddle(head) - if head is null or head.next is null - return head - - slow = head - fast = head.next - - while fast is not null and fast.next is not null - slow = slow.next - fast = fast.next.next - - return slow +--- +### Explanation -function mergeSort(head) - if head is null or head.next is null - return head - - // Find the middle node - middle = findMiddle(head) - nextToMiddle = middle.next - middle.next = null - - // Recursively sort both halves - left = mergeSort(head) - right = mergeSort(nextToMiddle) - - // Merge the sorted halves - sortedList = mergeSortedLists(left, right) - - return sortedList -``` -#### Complexity -**Time Complexity:** O(Nlog(N)) -**Space Complexity:** O(log(N)) +In an LRU cache, the least recently used item is always the one that is removed when the cache is full and a new item needs to be inserted. This ensures that the most recently accessed items are always prioritized and kept in the cache. --- -### Problem 4 Detect Cycle in a Linked List. +## LRU Solution flow -Given a Linked List, Find whether it contains a cycle. +## Flowchart -**Example 1** + -**Input:** +- If a data `x` will come, so first we search it in cache, it is available or not. + - If `x` is present in cache(HIT) then: + - delete(x) + - insertBack(x) + - If `x` is not present in cache(MISS) then: + - If cache size is not full, insertBack(x) + - If cache size is full, deleteFront() and insertBack(x). -
 -**Output:**
-```plaintext
-Yes
-```
+**Note :** Duplicates are not possible inside cache.
-**Example 2**
+**Finally operations Required :**
+1. **search(x)**
+2. **remove(x)**
+3. **insertBack(x)**
-**Input:**
-Input: [1 -> 4 -> 3 -> 2 -> 11 -> 45 -> 99]
+## Complexities of implementing LRU through various Data Structures
+| Operations | ArrayList | Singly Linked List | Singly LinkedList + HashSet`` | Doubly Linked List + `HashMap
-**Output:**
-```plaintext
-Yes
-```
+**Note :** Duplicates are not possible inside cache.
-**Example 2**
+**Finally operations Required :**
+1. **search(x)**
+2. **remove(x)**
+3. **insertBack(x)**
-**Input:**
-Input: [1 -> 4 -> 3 -> 2 -> 11 -> 45 -> 99]
+## Complexities of implementing LRU through various Data Structures
+| Operations | ArrayList | Singly Linked List | Singly LinkedList + HashSet`` | Doubly Linked List + `HashMapStart with two pointers, slow and fast, both pointing to the head of the linked list. +**Solution:** +In some cases, sometimes we may need to delete head/tail node also. So first of all we are taking two dummy nodes `head` and `tail`. -* **Traversal:**
In each iteration, the slow pointer advances by one step, while the fast pointer advances by two steps. This mimics the tortoise and hare analogy. If there is a cycle, these two pointers will eventually meet at some point within the cycle. +
 -* **Cycle Detection:**
-* **Cycle Detection:**While traversing, if the slow pointer becomes equal to the fast pointer, this indicates that the linked list contains a cycle. This is because the fast pointer "catches up" to the slow pointer within the cycle. +- Declare a `HashMap
If the fast pointer reaches the end of the linked list and becomes null or if the fast pointer's next becomes nullp, this means there is no cycle in the linked list. +
 -* **Cycle Detected:**
-* **Cycle Detected:**If the slow and fast pointers meet, it implies that the linked list contains a cycle. The function returns true. +`hm: {<7,a1>}` -#### Pseudo Code -```cpp -function hasCycle(head) - if head is null or head.next is null - return false // No cycle in an empty or single-node list - - slow = head - fast = head.next - - while fast is not null and fast.next is not null - if slow is the same as fast - return true // Cycle detected - slow = slow.next - fast = fast.next.next - - return false // No cycle detected +- Now 3 will come, 3 is not present in the cache as it is not in Map, so insert 3 in doubly linked list just before `tail` and store the `<3,address_of_node _inserted>` in map. +
 -```
+`hm:{<7,a1>, <3,a2>}`
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
+- Now 9 will come, 9 is also not present in the cache as it is not in Map, so insert 9 in doubly linked list just before `tail` and store the `<9,address_of_node _inserted>` in map.
+
-```
+`hm:{<7,a1>, <3,a2>}`
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
+- Now 9 will come, 9 is also not present in the cache as it is not in Map, so insert 9 in doubly linked list just before `tail` and store the `<9,address_of_node _inserted>` in map.
+ ----
-### Problem 5 Find the starting point
+`hm:{<7,a1>, <3,a2>, <9,a3>}`
-Given a Linked List which contains a cycle , Find the start point of the cycle.
+- Now 10 will come, 10 is also not present in the cache as it is not in Map, but the size of cache is fill as hashmap size is equal to the cache size, so delete `#a1`, and `#a1` can be accessed by `head.next` then we can simply delete it and delete it from hashMap also and insert 10 in doubly linked list just before `tail` and store the `<10,address_of_node _inserted>` in map.
-**Example**
+
----
-### Problem 5 Find the starting point
+`hm:{<7,a1>, <3,a2>, <9,a3>}`
-Given a Linked List which contains a cycle , Find the start point of the cycle.
+- Now 10 will come, 10 is also not present in the cache as it is not in Map, but the size of cache is fill as hashmap size is equal to the cache size, so delete `#a1`, and `#a1` can be accessed by `head.next` then we can simply delete it and delete it from hashMap also and insert 10 in doubly linked list just before `tail` and store the `<10,address_of_node _inserted>` in map.
-**Example**
+ -**Input:**
+hm:{ ~~<7,a1>~~, <3,a2>, <9,a3>, <10,a4>}
-
-**Input:**
+hm:{ ~~<7,a1>~~, <3,a2>, <9,a3>, <10,a4>}
- +- Now 14, we can insert 14 as similar to 10.
+
+- Now 14, we can insert 14 as similar to 10.
+ -**Output:**
-```plaintext
-5
-```
+hm:{ ~~<7,a1>~~, ~~<3,a2>~~ , <9,a3>, <10,a4>, <14,a5>}
+- Now 9, it is already present in cache,so first get the address of 9 from HashMap. Then delete 9 from doubly linked list and insert 9 at back before the `tail` node and update address of 9 in hashMap also.
----
-### Find the starting point Solution
+
-**Output:**
-```plaintext
-5
-```
+hm:{ ~~<7,a1>~~, ~~<3,a2>~~ , <9,a3>, <10,a4>, <14,a5>}
+- Now 9, it is already present in cache,so first get the address of 9 from HashMap. Then delete 9 from doubly linked list and insert 9 at back before the `tail` node and update address of 9 in hashMap also.
----
-### Find the starting point Solution
+ +hm:{ ~~<7,a1>~~, ~~<3,a2>~~ , <9,~~a3~~ a6>, <10,a4>, <14,a5>}
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+- Now 10, it is already present in cache,so first get the address of 10 from HashMap. Then delete 10 from doubly linked list and insert 10 at back before the `tail` node and update address of 10 in hashMap also.
+hm:{ ~~<7,a1>~~, ~~<3,a2>~~ , <9,~~a3~~ a6>, <10,~~a4~~ a7>, <14,a5>}
-#### Solution
-* **Initialization:**
+hm:{ ~~<7,a1>~~, ~~<3,a2>~~ , <9,~~a3~~ a6>, <10,a4>, <14,a5>}
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+- Now 10, it is already present in cache,so first get the address of 10 from HashMap. Then delete 10 from doubly linked list and insert 10 at back before the `tail` node and update address of 10 in hashMap also.
+hm:{ ~~<7,a1>~~, ~~<3,a2>~~ , <9,~~a3~~ a6>, <10,~~a4~~ a7>, <14,a5>}
-#### Solution
-* **Initialization:**Similar to cycle detection, start with two pointers, slow and fast, both pointing to the head of the linked list. +- similary other elements can be inserted in cache. -* **Cycle Detection:**
In each iteration, move the slow pointer by one step and the fast pointer by two steps. If a cycle exists, they will eventually meet within the cycle. +Implementation of LRU is mentioned in different langauges(https://docs.google.com/document/d/1IC_c1mFOwWHyst-YtuXbhxfZlNXxxYTnxu1MWTS6QkA/edit) -* **Meeting Point:**
If a cycle is detected (slow meets fast), set a flag hasCycle to true. +## PseudoCode +```java +class Node { + integer data; + Node next; + Node prev; -* **Start Point Identification:**
Reset the slow pointer to the head of the list while keeping the fast pointer at the meeting point. Advance both pointers by one step in each iteration. They will eventually meet at the start point of the cycle. + constructor Node(x) { + data = x; + next = null; + prev = null; + } +} -* **Returning the Result:**
Once the slow and fast pointers meet again, it implies that the linked list has a cycle, and the meeting point is the start of the cycle. Return this pointer. +// Initialization +Node head = new Node(-1); +Node tail = new Node(-1); +head.next = prev; +tail.prev = head; +HashMap
- +---
-* **No Cycle Check:** If the fast pointer reaches the end of the linked list (i.e., becomes nullptr) or if the fast pointer's next becomes nullptr, there is no cycle. In such cases, return nullptr.
+### Question
+Check the Given linked list is Palindrome or not.
-This approach ensures that you can find the start point of the cycle using the Floyd's Tortoise and Hare algorithm with a slightly modified process.
+Linked List : ```Head -> 1 -> Null```
+### Choices
+- [x] YES
+- [ ] NO
-#### Pseudo Code
-```cpp
-function detectCycleStart(head)
- if head is null or head.next is null
- return null // No cycle in an empty or single-node list
+### Explanation:
- slow = head
- fast = head
- hasCycle = false
+Yes, The Given Linked List is an Palindrome, Because it reads the same in reverse order as well.
- while fast is not null and fast.next is not null
- slow = slow.next
- fast = fast.next.next
+---
- if slow is the same as fast
- hasCycle = true
- break
+### Solution 1 :
+Create a copy of linked list. Reverse it and Compare
- if not hasCycle
- return null // No cycle detected
+### Complexity
+**Time Complexity -** O(N)
+**Space Complexity -** O(N).
- slow = head
- while slow is not the same as fast
- slow = slow.next
- fast = fast.next
- return slow // Return the start point of the cycle
+### Solution 2 :
+1. Find middle element of linked list
+2. Reverse second half of linked list
+3. Compare first half and compare second half
+
+**Step wise solution:**
+
+1. **Find length of linked list**
+```java
+n = 0
+temp = Head
+while(temp != null){
+ n++
+ temp = temp.next
+}
+```
+2. **Go to the middle element**
+// If n = 10(even), we'll reverse from 6th node.
+// If n = 9(odd), then also we'll reverse from 6th node.(**5th node will be middle one that need not be compared with any node**)
+So, regardless of even/odd, we can skip (n + 1) / 2 nodes.
+```java
+temp Head
+(for i --> 1 to (n + 1) / 2){
+ temp =temp.next
+}
+//temp middle
```
+3. Now reverse the linked list from $((n+1)/2 + 1)th$ node.
+4. Compare both the linked list
+
+### T.C & S.C
+
+Total time complexity for checking palindrome is O(N) and space complexity is O(N).
+
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md b/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md
index abaea6e..875210c 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md
@@ -1,5 +1,20 @@
# Maths 1: Modular Arithmetic & GCD
+---
+title: Agenda
+description:
+duration: 900
+card_type: cue_card
+---
+
+**Agenda of this Lecture:**
+
+* Modular Arithmetic Introduction
+* Mod on power function
+* Count pairs whose sum mod m is 0
+* Introduction to GCD
+* Properties of GCD
+
---
## Modular Arithmetic Introduction
@@ -17,7 +32,7 @@ The most useful need of `%` is to limit the range of data. We don't have unlimit
**Example:**
-
+---
-* **No Cycle Check:** If the fast pointer reaches the end of the linked list (i.e., becomes nullptr) or if the fast pointer's next becomes nullptr, there is no cycle. In such cases, return nullptr.
+### Question
+Check the Given linked list is Palindrome or not.
-This approach ensures that you can find the start point of the cycle using the Floyd's Tortoise and Hare algorithm with a slightly modified process.
+Linked List : ```Head -> 1 -> Null```
+### Choices
+- [x] YES
+- [ ] NO
-#### Pseudo Code
-```cpp
-function detectCycleStart(head)
- if head is null or head.next is null
- return null // No cycle in an empty or single-node list
+### Explanation:
- slow = head
- fast = head
- hasCycle = false
+Yes, The Given Linked List is an Palindrome, Because it reads the same in reverse order as well.
- while fast is not null and fast.next is not null
- slow = slow.next
- fast = fast.next.next
+---
- if slow is the same as fast
- hasCycle = true
- break
+### Solution 1 :
+Create a copy of linked list. Reverse it and Compare
- if not hasCycle
- return null // No cycle detected
+### Complexity
+**Time Complexity -** O(N)
+**Space Complexity -** O(N).
- slow = head
- while slow is not the same as fast
- slow = slow.next
- fast = fast.next
- return slow // Return the start point of the cycle
+### Solution 2 :
+1. Find middle element of linked list
+2. Reverse second half of linked list
+3. Compare first half and compare second half
+
+**Step wise solution:**
+
+1. **Find length of linked list**
+```java
+n = 0
+temp = Head
+while(temp != null){
+ n++
+ temp = temp.next
+}
+```
+2. **Go to the middle element**
+// If n = 10(even), we'll reverse from 6th node.
+// If n = 9(odd), then also we'll reverse from 6th node.(**5th node will be middle one that need not be compared with any node**)
+So, regardless of even/odd, we can skip (n + 1) / 2 nodes.
+```java
+temp Head
+(for i --> 1 to (n + 1) / 2){
+ temp =temp.next
+}
+//temp middle
```
+3. Now reverse the linked list from $((n+1)/2 + 1)th$ node.
+4. Compare both the linked list
+
+### T.C & S.C
+
+Total time complexity for checking palindrome is O(N) and space complexity is O(N).
+
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(1)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md b/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md
index abaea6e..875210c 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Maths 1 Modular Arithmetic & GCD.md
@@ -1,5 +1,20 @@
# Maths 1: Modular Arithmetic & GCD
+---
+title: Agenda
+description:
+duration: 900
+card_type: cue_card
+---
+
+**Agenda of this Lecture:**
+
+* Modular Arithmetic Introduction
+* Mod on power function
+* Count pairs whose sum mod m is 0
+* Introduction to GCD
+* Properties of GCD
+
---
## Modular Arithmetic Introduction
@@ -17,7 +32,7 @@ The most useful need of `%` is to limit the range of data. We don't have unlimit
**Example:**
- +
---
**2.** `(a * b) % m = (a % m * b % m) % m`
@@ -43,21 +58,24 @@ Now we can simly do
(a raise to power b)
---
+
+
+
### Question
Evaluate :
$(37^{103} - 1) \% 12$
-**Choices**
+### Choices
- [ ] 1
- [x] 0
- [ ] No Idea
- [ ] 10
-**Explanation**:
+### Explanation:
$(37^{103}-1)\%12$
@@ -68,31 +86,14 @@ $=>~ (((37\%12){103}~\%12)-1+12)~\%12$
$=>~ (1-1+12)\%12 = 12\%12 =0$
---
-### Question
+## Problem 1 Count pairs whose sum is a multiple of m
-What is the result of the following modular arithmetic operation?
-(25+13)%7
-
-**Choices**
-
-- [ ] 1
-- [ ] 2
-- [x] 6
-- [ ] 4
-
-**Explanation**
-
-(25+13)%7=38%7=3⋅7+3=3
-Therefore, the correct choice is 6.
-
----
-### Question 1 Count pairs whose sum is a multiple of m
Given N array elements, find count of pairs (i, j) such that $(arr[i] + arr[j]) ~\%~ m = 0$
**Note:** $i~!=~j$ and pair(i, j) is same as pair(j, i)
-**Example**
+### Example
`A[ ] = {4, 3, 6, 3, 8, 12}`
`m = 6`
@@ -101,27 +102,24 @@ Pairs that satisfy **$(arr[i] + arr[j]) ~\%~ 6 = 0$** are:
`(3 + 3) % 6 = 0`
`(6 + 12) % 6 = 0`
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Brute Force Approach
+### Brute Force Approach
* For each pair of distinct indices `i` and `j` (where `i != j`), the sum $arr[i] ~+~ arr[j]$ is calculated, and then the remainder of this sum when divided by `m` is checked.
* If the remainder is 0, then the pair `(i, j)` satisfies the condition, and the count is incremented. This approach has a time complexity of $O(N^2)$, where N is the number of elements in the array, as it involves checking all possible pairs.
-#### Optimal Approach
+### Optimal Approach
-**Hint:**
+#### Hint:
We can utilise the property: $(a + b) \% m = (a \% m + b \% m) \% m$
Instead of directly checking for $(a+b)\%m$, we can check for $(a ~\%~ m ~+~ b \% m) \% m$
-**Idea:**
+#### Idea:
* Iterate through the array and calculate `A[i] % m` for all values.
* Now, the sum of `A[i] % m` for two values should be divisible by m.
-**Example**:
+### Example:
```java
A[ ] = {2, 3, 4, 8, 6, 15, 5, 12, 17, 7, 18}
m = 6
@@ -134,14 +132,14 @@ Note: The range of A[i] % 6 is from 0 to 5
* Summing 1 with 5 will give sum divisible by 6.
* Likewise, 2 with 4, 3 with 3, and lastly 0 with 0.
-#### Algorithm
+### Algorithm
* Iterate given array and calculate $A[i]\%m$.
* Create a frequency array of size **m** to store the frequency of remainders obtained from the elements.
* For each element, find the complement remainder needed for the sum to be divisible by `m`. Count frequency of complement remainder. Add these counts to get the total count of pairs satisfying the condition.
* **Note:** Mod 0 will form a pair with 0, i.e if m = 6, and say 12 & 18 are present in given array, doing 12 % 6 and 18 % 6 will result in 0.
-#### Dry Run
+### Dry Run
```java
A[ ] = {2, 3, 4, 8, 6, 15, 5, 12, 17, 7, 18}
m = 6
@@ -171,20 +169,18 @@ After doing mod with 6, we'll get
-#### Pseudocode
+### Pseudocode
```cpp
-int pairSumDivisibleByM(A, m) {
+function pairSumDivisibleByM(A, m) {
N = A.length;
- freq[N] = {
- 0
- };
+ freq[N] = {0};
count = 0;
- for (int i = 0; i < N; i++) {
+ for(i -> 0 to N - 1) {
val = A[i] % m;
-
- if (val == 0) {
+
+ if(val == 0) {
pair = 0;
} else {
pair = m - val;
@@ -199,25 +195,32 @@ int pairSumDivisibleByM(A, m) {
**Time Complexity** - `O(N)`
+*Space Complexity is asked in the next Quiz.*
---
+
### Question
**Space Complexity**: Pair Sum Divisible by M
-**Choices**
+### Choices
- [ ] O(N)
- [x] O(M)
- [ ] O(N+M)
-**Explanation**
+---
+
+
+### Explanation
Space Complexity (SC) is `O(M)`, where M is the modulus value. This is because the frequency array of size M is required to store frequency of elements from 0 to M-1.
---
## GCD Basics
+
+
### Explanation
* GCD - Greatest Common Division
@@ -233,20 +236,20 @@ This implies:-
and hence `x` is the highest factor of both A and B
-**Example - 1**
+### Example - 1
GCD(15, 25) = 5
+
---
**2.** `(a * b) % m = (a % m * b % m) % m`
@@ -43,21 +58,24 @@ Now we can simly do
(a raise to power b)
---
+
+
+
### Question
Evaluate :
$(37^{103} - 1) \% 12$
-**Choices**
+### Choices
- [ ] 1
- [x] 0
- [ ] No Idea
- [ ] 10
-**Explanation**:
+### Explanation:
$(37^{103}-1)\%12$
@@ -68,31 +86,14 @@ $=>~ (((37\%12){103}~\%12)-1+12)~\%12$
$=>~ (1-1+12)\%12 = 12\%12 =0$
---
-### Question
+## Problem 1 Count pairs whose sum is a multiple of m
-What is the result of the following modular arithmetic operation?
-(25+13)%7
-
-**Choices**
-
-- [ ] 1
-- [ ] 2
-- [x] 6
-- [ ] 4
-
-**Explanation**
-
-(25+13)%7=38%7=3⋅7+3=3
-Therefore, the correct choice is 6.
-
----
-### Question 1 Count pairs whose sum is a multiple of m
Given N array elements, find count of pairs (i, j) such that $(arr[i] + arr[j]) ~\%~ m = 0$
**Note:** $i~!=~j$ and pair(i, j) is same as pair(j, i)
-**Example**
+### Example
`A[ ] = {4, 3, 6, 3, 8, 12}`
`m = 6`
@@ -101,27 +102,24 @@ Pairs that satisfy **$(arr[i] + arr[j]) ~\%~ 6 = 0$** are:
`(3 + 3) % 6 = 0`
`(6 + 12) % 6 = 0`
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Brute Force Approach
+### Brute Force Approach
* For each pair of distinct indices `i` and `j` (where `i != j`), the sum $arr[i] ~+~ arr[j]$ is calculated, and then the remainder of this sum when divided by `m` is checked.
* If the remainder is 0, then the pair `(i, j)` satisfies the condition, and the count is incremented. This approach has a time complexity of $O(N^2)$, where N is the number of elements in the array, as it involves checking all possible pairs.
-#### Optimal Approach
+### Optimal Approach
-**Hint:**
+#### Hint:
We can utilise the property: $(a + b) \% m = (a \% m + b \% m) \% m$
Instead of directly checking for $(a+b)\%m$, we can check for $(a ~\%~ m ~+~ b \% m) \% m$
-**Idea:**
+#### Idea:
* Iterate through the array and calculate `A[i] % m` for all values.
* Now, the sum of `A[i] % m` for two values should be divisible by m.
-**Example**:
+### Example:
```java
A[ ] = {2, 3, 4, 8, 6, 15, 5, 12, 17, 7, 18}
m = 6
@@ -134,14 +132,14 @@ Note: The range of A[i] % 6 is from 0 to 5
* Summing 1 with 5 will give sum divisible by 6.
* Likewise, 2 with 4, 3 with 3, and lastly 0 with 0.
-#### Algorithm
+### Algorithm
* Iterate given array and calculate $A[i]\%m$.
* Create a frequency array of size **m** to store the frequency of remainders obtained from the elements.
* For each element, find the complement remainder needed for the sum to be divisible by `m`. Count frequency of complement remainder. Add these counts to get the total count of pairs satisfying the condition.
* **Note:** Mod 0 will form a pair with 0, i.e if m = 6, and say 12 & 18 are present in given array, doing 12 % 6 and 18 % 6 will result in 0.
-#### Dry Run
+### Dry Run
```java
A[ ] = {2, 3, 4, 8, 6, 15, 5, 12, 17, 7, 18}
m = 6
@@ -171,20 +169,18 @@ After doing mod with 6, we'll get
-#### Pseudocode
+### Pseudocode
```cpp
-int pairSumDivisibleByM(A, m) {
+function pairSumDivisibleByM(A, m) {
N = A.length;
- freq[N] = {
- 0
- };
+ freq[N] = {0};
count = 0;
- for (int i = 0; i < N; i++) {
+ for(i -> 0 to N - 1) {
val = A[i] % m;
-
- if (val == 0) {
+
+ if(val == 0) {
pair = 0;
} else {
pair = m - val;
@@ -199,25 +195,32 @@ int pairSumDivisibleByM(A, m) {
**Time Complexity** - `O(N)`
+*Space Complexity is asked in the next Quiz.*
---
+
### Question
**Space Complexity**: Pair Sum Divisible by M
-**Choices**
+### Choices
- [ ] O(N)
- [x] O(M)
- [ ] O(N+M)
-**Explanation**
+---
+
+
+### Explanation
Space Complexity (SC) is `O(M)`, where M is the modulus value. This is because the frequency array of size M is required to store frequency of elements from 0 to M-1.
---
## GCD Basics
+
+
### Explanation
* GCD - Greatest Common Division
@@ -233,20 +236,20 @@ This implies:-
and hence `x` is the highest factor of both A and B
-**Example - 1**
+### Example - 1
GCD(15, 25) = 5
 -**Example - 2**
+### Example - 2
GCD(12, 30) = 6
-**Example - 2**
+### Example - 2
GCD(12, 30) = 6
 -**Example - 3**
+### Example - 3
GCD(0, 4) = 4
@@ -254,16 +257,38 @@ GCD(0, 4) = 4
-**Example - 4**
+### Example - 4
GCD(0, 0) = Infinity
-**Example - 3**
+### Example - 3
GCD(0, 4) = 4
@@ -254,16 +257,38 @@ GCD(0, 4) = 4
-**Example - 4**
+### Example - 4
GCD(0, 0) = Infinity
 +---
+
+
+### Question
+What is the GCD(4, 7) ?
+
+### Choices
+- [ ] 0
+- [x] 1
+- [ ] 4
+- [ ] 7
+- [ ] 28
+
+
+### Explanation:
+
+The GCD of 4 and 7 is 1.
+
+
+---
+
+
+### Question
+What is the GCD(4, 7) ?
+
+### Choices
+- [ ] 0
+- [x] 1
+- [ ] 4
+- [ ] 7
+- [ ] 28
+
+
+### Explanation:
+
+The GCD of 4 and 7 is 1.
+
+ +
+
---
## Properties of GCD
+
### Property - 1
GCD(A, B) = GCD(B, A)
@@ -283,51 +308,20 @@ GCD(A, B, C) = GCD(A, GCD(B, C)) = GCD(B, GCD(C, A)) = GCD(C, GCD(A, B))
Given `A >= B > 0`,
**GCD(A, B) = GCD(A - B, B)**
+>Note: The proof isn't asked in Interviews. If you want to study, please stay back.
**Example:**
-
+
+
---
## Properties of GCD
+
### Property - 1
GCD(A, B) = GCD(B, A)
@@ -283,51 +308,20 @@ GCD(A, B, C) = GCD(A, GCD(B, C)) = GCD(B, GCD(C, A)) = GCD(C, GCD(A, B))
Given `A >= B > 0`,
**GCD(A, B) = GCD(A - B, B)**
+>Note: The proof isn't asked in Interviews. If you want to study, please stay back.
**Example:**
- +
### Property - 5
GCD(A, B) = GCD(A % B, B)
----
-### Question
-gcd(0,8) = ?
-Chose the correct answer
-
-**Choices**
-- [ ] 1
-- [x] 8
-- [ ] 0
-- [ ] not defined
-
-
----
-### Question
-TC of gcd(a1,a2,a3,....,an) is:
-Chose the correct answer
-
-**Choices**
-- [ ] O(log(max number))
-- [ ] O(N)
-- [x] O(N*log(max number)
-- [ ] O(N^2)
-
----
-### Question
-Given an array A = [15, 21, 33, 45], find the GCD of all elements in the array.
-
-**Choices**
-- [ ] 4
-- [x] 3
-- [ ] 6
-- [ ] 9
-
---
## Function of GCD
+
### Write a function to find GCD(A, B)
+
### Property - 5
GCD(A, B) = GCD(A % B, B)
----
-### Question
-gcd(0,8) = ?
-Chose the correct answer
-
-**Choices**
-- [ ] 1
-- [x] 8
-- [ ] 0
-- [ ] not defined
-
-
----
-### Question
-TC of gcd(a1,a2,a3,....,an) is:
-Chose the correct answer
-
-**Choices**
-- [ ] O(log(max number))
-- [ ] O(N)
-- [x] O(N*log(max number)
-- [ ] O(N^2)
-
----
-### Question
-Given an array A = [15, 21, 33, 45], find the GCD of all elements in the array.
-
-**Choices**
-- [ ] 4
-- [x] 3
-- [ ] 6
-- [ ] 9
-
---
## Function of GCD
+
### Write a function to find GCD(A, B)
 @@ -336,7 +330,7 @@ Given an array A = [15, 21, 33, 45], find the GCD of all elements in the array.
Suppose we have two positive numbers a, b then:
```java
-int gcd(a, b) {
+function gcd(a, b) {
if (b == 0) {
return a;
}
@@ -344,95 +338,47 @@ int gcd(a, b) {
}
```
-**Time Complexity(TC):** O(log(max(a, b)))
+**Time Complexity(TC):** O(log(min(a, b))) [Explanation is not in syllabus]
### Given an array, calculate GCD of the entire array
**Example:**
@@ -336,7 +330,7 @@ Given an array A = [15, 21, 33, 45], find the GCD of all elements in the array.
Suppose we have two positive numbers a, b then:
```java
-int gcd(a, b) {
+function gcd(a, b) {
if (b == 0) {
return a;
}
@@ -344,95 +338,47 @@ int gcd(a, b) {
}
```
-**Time Complexity(TC):** O(log(max(a, b)))
+**Time Complexity(TC):** O(log(min(a, b))) [Explanation is not in syllabus]
### Given an array, calculate GCD of the entire array
**Example:**
 -
+
+
```java
-int gcdArr(int[] arr) {
- int ans = arr[0];
- int n = arr.length();
- for (int i = 0; i < n; i++) {
+function gcdArr(arr[]) {
+ ans = arr[0];
+ n = arr.length();
+ for (i -> 0 to n - 1) {
ans = gcd(ans, arr[i])
}
return ans;
}
```
----
-### Problem 2 Delete One
-**Question**
-Given arr[N] elements , we have to delete one element such that GCD of the remaining elements becomes maximum.
-
-**Example:**
-
-
-
+
+
```java
-int gcdArr(int[] arr) {
- int ans = arr[0];
- int n = arr.length();
- for (int i = 0; i < n; i++) {
+function gcdArr(arr[]) {
+ ans = arr[0];
+ n = arr.length();
+ for (i -> 0 to n - 1) {
ans = gcd(ans, arr[i])
}
return ans;
}
```
----
-### Problem 2 Delete One
-**Question**
-Given arr[N] elements , we have to delete one element such that GCD of the remaining elements becomes maximum.
-
-**Example:**
-
- -
-#### Brute Force Approach
-
-The brute approach for this problem will be to delete arr[i], and then calculate the GCD for all the remaining elements. This will be repeated for all the elements.
-
-
-
-#### Brute Force Approach
-
-The brute approach for this problem will be to delete arr[i], and then calculate the GCD for all the remaining elements. This will be repeated for all the elements.
-
- -
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
+---
-#### Optimal Approach: Prefix Array
+### Question
+Time Complexity of GCD(a1, a2, a3, ...., an) is:
+Choose the correct answer
+### Choices
+- [ ] O(log(max_number))
+- [ ] O(N)
+- [x] O(N\*log(max_number)
+- [ ] O(N^2)
-**Approach:**
+### Explanation
-* Idea is to find the GCD value of all the sub-sequences of length (N – 1) and removing the element which is not present in the sub-sequence with that GCD. The maximum GCD found would be the answer.
-* To find the GCD of the sub-sequences optimally, maintain a `prefixGCD[]` and a `suffixGCD[]` array using single state dynamic programming.
-* The maximum value of GCD(`prefixGCD[i – 1]`, `suffixGCD[i + 1]`) is the required answer.
+The time complexity of finding the GCD of two numbers is `O(log(min(a,b)))`. In the worst case, the minimum of the two numbers can be as large as the **maximum number** in the list.
-The implementation is given below:
+For simplicity, let’s denote this maximum number as **max_number**.
-```java
- // Recursive function to return gcd of a and b
- static int gcd(int a, int b) {
- if (b == 0)
- return a;
- return gcd(b, a % b);
- }
-
- static int MaxGCD(int a[], int n) {
-
- // Prefix and Suffix arrays
- int Prefix[] = new int[n + 2];
- int Suffix[] = new int[n + 2] ;
-
- Prefix[1] = a[0];
- for (int i = 2; i <= n; i += 1) {
- Prefix[i] = gcd(Prefix[i - 1], a[i - 1]);
- }
-
- Suffix[n] = a[n - 1];
- for (int i = n - 1; i >= 1; i -= 1) {
- Suffix[i] = gcd(Suffix[i + 1], a[i - 1]);
- }
-
- // If first or last element of the array has to be removed
- int ans = Math.max(Suffix[2], Prefix[n - 1]);
-
- // If any other element is replaced
- for (int i = 2; i < n; i += 1) {
- ans = Math.max(ans, gcd(Prefix[i - 1], Suffix[i + 1]));
- }
- return ans;
- }
-```
+Given the iterative nature of the GCD calculation for a list of N numbers, the total time complexity involves calculating the GCD for N pairs, each taking `log(max_number)` time.
-
-
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
+---
-#### Optimal Approach: Prefix Array
+### Question
+Time Complexity of GCD(a1, a2, a3, ...., an) is:
+Choose the correct answer
+### Choices
+- [ ] O(log(max_number))
+- [ ] O(N)
+- [x] O(N\*log(max_number)
+- [ ] O(N^2)
-**Approach:**
+### Explanation
-* Idea is to find the GCD value of all the sub-sequences of length (N – 1) and removing the element which is not present in the sub-sequence with that GCD. The maximum GCD found would be the answer.
-* To find the GCD of the sub-sequences optimally, maintain a `prefixGCD[]` and a `suffixGCD[]` array using single state dynamic programming.
-* The maximum value of GCD(`prefixGCD[i – 1]`, `suffixGCD[i + 1]`) is the required answer.
+The time complexity of finding the GCD of two numbers is `O(log(min(a,b)))`. In the worst case, the minimum of the two numbers can be as large as the **maximum number** in the list.
-The implementation is given below:
+For simplicity, let’s denote this maximum number as **max_number**.
-```java
- // Recursive function to return gcd of a and b
- static int gcd(int a, int b) {
- if (b == 0)
- return a;
- return gcd(b, a % b);
- }
-
- static int MaxGCD(int a[], int n) {
-
- // Prefix and Suffix arrays
- int Prefix[] = new int[n + 2];
- int Suffix[] = new int[n + 2] ;
-
- Prefix[1] = a[0];
- for (int i = 2; i <= n; i += 1) {
- Prefix[i] = gcd(Prefix[i - 1], a[i - 1]);
- }
-
- Suffix[n] = a[n - 1];
- for (int i = n - 1; i >= 1; i -= 1) {
- Suffix[i] = gcd(Suffix[i + 1], a[i - 1]);
- }
-
- // If first or last element of the array has to be removed
- int ans = Math.max(Suffix[2], Prefix[n - 1]);
-
- // If any other element is replaced
- for (int i = 2; i < n; i += 1) {
- ans = Math.max(ans, gcd(Prefix[i - 1], Suffix[i + 1]));
- }
- return ans;
- }
-```
+Given the iterative nature of the GCD calculation for a list of N numbers, the total time complexity involves calculating the GCD for N pairs, each taking `log(max_number)` time.
- +Thus, the time complexity for finding the GCD of the list [a1,a2,a3,...,an] is: `O(N * log(max_number))`
---
-### Proof of gcd(a, b) = gcd(a-b, b)
-
-
-
+Thus, the time complexity for finding the GCD of the list [a1,a2,a3,...,an] is: `O(N * log(max_number))`
---
-### Proof of gcd(a, b) = gcd(a-b, b)
-
-
- \ No newline at end of file
diff --git a/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md b/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md
index 49d8d2e..0df1fdd 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md
@@ -1,9 +1,18 @@
# Maths 2: Combinatorics Basic
+## Agenda
+
+* Addition and Multiplication Rule
+* Permutation basics
+* Combination basics and properties
+* Pascal Triangle
+* Find N-th column title
+
---
## Addition and Multiplication Rule Example 1
+
### Example - 1
Given 10 girls and 7 boys, How many different pairs can be formed?
@@ -15,7 +24,7 @@ Given 10 girls and 7 boys, How many different pairs can be formed?
Since each pair consists of one boy and one girl, you can pair each of the 7 boys with any of the 10 girls. This results in a total of 7 boys × 10 girls = 70 different pairs that can be formed.
---
-### Addition and Multiplication Rule Example 2
+## Addition and Multiplication Rule Example 2
### Example - 2
@@ -35,18 +44,20 @@ So, the total number of ways to reach Agra via Delhi from Pune is:
---
-# Question
+### Question
No. of ways of reaching Agra from Pune ?
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md b/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md
index 49d8d2e..0df1fdd 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Maths 2 Combinatorics Basics.md
@@ -1,9 +1,18 @@
# Maths 2: Combinatorics Basic
+## Agenda
+
+* Addition and Multiplication Rule
+* Permutation basics
+* Combination basics and properties
+* Pascal Triangle
+* Find N-th column title
+
---
## Addition and Multiplication Rule Example 1
+
### Example - 1
Given 10 girls and 7 boys, How many different pairs can be formed?
@@ -15,7 +24,7 @@ Given 10 girls and 7 boys, How many different pairs can be formed?
Since each pair consists of one boy and one girl, you can pair each of the 7 boys with any of the 10 girls. This results in a total of 7 boys × 10 girls = 70 different pairs that can be formed.
---
-### Addition and Multiplication Rule Example 2
+## Addition and Multiplication Rule Example 2
### Example - 2
@@ -35,18 +44,20 @@ So, the total number of ways to reach Agra via Delhi from Pune is:
---
-# Question
+### Question
No. of ways of reaching Agra from Pune ?
 -# Choices
+### Choices
- [ ] 72
- [ ] 12
- [x] 18
- [ ] 20
+### Explanation
+
To go to Pune to delhi , there are 3 ways. And do go from delhi to agra there are 4 ways. From pune to Mumbai there are 2 ways, from Mumbai to agra there are 3 ways.
-# Choices
+### Choices
- [ ] 72
- [ ] 12
- [x] 18
- [ ] 20
+### Explanation
+
To go to Pune to delhi , there are 3 ways. And do go from delhi to agra there are 4 ways. From pune to Mumbai there are 2 ways, from Mumbai to agra there are 3 ways.
 @@ -70,6 +81,56 @@ There are 18 different ways to reach Agra from Pune through these routes.
@@ -70,6 +81,56 @@ There are 18 different ways to reach Agra from Pune through these routes.
 +---
+## Most Varied Meal Combo
+
+### Scenerio
+**Zomato**, features an exciting option for its users - meal combos. Each combo includes one main course, one *dessert*, and one *beverage*, offering a complete dining experience from various restaurants. Zomato believes that a greater variety of combos can significantly enhance customer satisfaction.
+
+### Problem Statement
+
+You're tasked with helping **Zomato** identify which restaurant offers the most variety in its meal combos. You're provided with a list, shaped like a grid or a 2D matrix **A**, where each row corresponds to a different restaurant's offerings.
+
+Each row is divided into three parts:
+1. A[i][0] tells you the number of main courses,
+2. A[i][1] the number of desserts, and
+3. A[i][2] the number of beverages a restaurant offers.
+
+Your challenge is to analyze this data and pinpoint which restaurant gives its customers the most options to mix and match their meal combo.
+
+### Examples
+#### Example 1 :
+```csharp
+A = [
+ [3, 2, 2], # Restaurant 1
+ [4, 3, 3], # Restaurant 2
+ [1, 1, 1] # Restaurant 3
+]
+```
+#### Output : $2$
+#### Explanation for input 1 :
+- Restaurant 1 offers 12 combos (3 mains x 2 desserts x 2 beverages)
+- Restaurant 2 offers 36 combos (4 mains x 3 desserts x 3 beverages)
+- Restaurant 3 offers 1 combo (1 main x 1 dessert x 1 beverage)
+
+So, Restaurant 2 provides the most variety with 36 possible combinations.
+
+### Solution
+1. **Understanding the Combinations:** The number of ways to form a meal combo at each restaurant is determined by the product of the number of main courses, desserts, and beverages. This is based on the combinatorial principle where each choice of a main course can be combined with each choice of a dessert and each choice of a beverage.
+
+
+2. **Iterating through Restaurants:** For each restaurant (each row in the matrix):
+ - Multiply the numbers from the three columns together (main courses x desserts x beverages).
+ - This product gives the total number of unique meal combos that can be created using the menu items listed by the restaurant.
+
+
+3. **Tracking Maximum Variety**: As you compute the number of possible combinations for each restaurant, you need to keep track of which restaurant has the highest number. This involves:
+ - Maintaining a variable to store the maximum number of combinations found so far.
+ - Keeping an index or identifier for the restaurant that offers these maximum combinations.
+
+4. **Result**: After evaluating all the rows, the restaurant with the highest product (representing the maximum number of meal combos) is identified as offering the most variety.
+
+
---
## Permutation
@@ -88,11 +149,12 @@ Given 3 distinct characters, in how many ways can we arrange them?
---
+
### Question
In how many ways n distinct characters can be arranged?
-**Choices**
+### Choices
- [ ] N * (N + 1) / 2
- [x] N! (N Factorial)
@@ -104,6 +166,7 @@ In how many ways n distinct characters can be arranged?
N distinct characters can be arranged in n! (n factorial) ways. This means that for each distinct character you have, you can multiply the total number of arrangements by the count of characters. Here's the formula:
+---
+---
+## Most Varied Meal Combo
+
+### Scenerio
+**Zomato**, features an exciting option for its users - meal combos. Each combo includes one main course, one *dessert*, and one *beverage*, offering a complete dining experience from various restaurants. Zomato believes that a greater variety of combos can significantly enhance customer satisfaction.
+
+### Problem Statement
+
+You're tasked with helping **Zomato** identify which restaurant offers the most variety in its meal combos. You're provided with a list, shaped like a grid or a 2D matrix **A**, where each row corresponds to a different restaurant's offerings.
+
+Each row is divided into three parts:
+1. A[i][0] tells you the number of main courses,
+2. A[i][1] the number of desserts, and
+3. A[i][2] the number of beverages a restaurant offers.
+
+Your challenge is to analyze this data and pinpoint which restaurant gives its customers the most options to mix and match their meal combo.
+
+### Examples
+#### Example 1 :
+```csharp
+A = [
+ [3, 2, 2], # Restaurant 1
+ [4, 3, 3], # Restaurant 2
+ [1, 1, 1] # Restaurant 3
+]
+```
+#### Output : $2$
+#### Explanation for input 1 :
+- Restaurant 1 offers 12 combos (3 mains x 2 desserts x 2 beverages)
+- Restaurant 2 offers 36 combos (4 mains x 3 desserts x 3 beverages)
+- Restaurant 3 offers 1 combo (1 main x 1 dessert x 1 beverage)
+
+So, Restaurant 2 provides the most variety with 36 possible combinations.
+
+### Solution
+1. **Understanding the Combinations:** The number of ways to form a meal combo at each restaurant is determined by the product of the number of main courses, desserts, and beverages. This is based on the combinatorial principle where each choice of a main course can be combined with each choice of a dessert and each choice of a beverage.
+
+
+2. **Iterating through Restaurants:** For each restaurant (each row in the matrix):
+ - Multiply the numbers from the three columns together (main courses x desserts x beverages).
+ - This product gives the total number of unique meal combos that can be created using the menu items listed by the restaurant.
+
+
+3. **Tracking Maximum Variety**: As you compute the number of possible combinations for each restaurant, you need to keep track of which restaurant has the highest number. This involves:
+ - Maintaining a variable to store the maximum number of combinations found so far.
+ - Keeping an index or identifier for the restaurant that offers these maximum combinations.
+
+4. **Result**: After evaluating all the rows, the restaurant with the highest product (representing the maximum number of meal combos) is identified as offering the most variety.
+
+
---
## Permutation
@@ -88,11 +149,12 @@ Given 3 distinct characters, in how many ways can we arrange them?
---
+
### Question
In how many ways n distinct characters can be arranged?
-**Choices**
+### Choices
- [ ] N * (N + 1) / 2
- [x] N! (N Factorial)
@@ -104,6 +166,7 @@ In how many ways n distinct characters can be arranged?
N distinct characters can be arranged in n! (n factorial) ways. This means that for each distinct character you have, you can multiply the total number of arrangements by the count of characters. Here's the formula:
+---
 ---
@@ -145,6 +208,7 @@ Here:
---
## Combination
+
### Explanation
Combination is defined as the number of ways to select something.
@@ -176,6 +240,7 @@ Number of Selections * Number of Arrangements in Each Selection = $4 * 6 = 24$
---
## nCr Formulae
+
### Example - 3
Given **n** distinct elements, in how many ways we can select **r** elements s.t `0 <= r <= n`
@@ -192,9 +257,10 @@ Given **n** distinct elements, in how many ways we can select **r** elements s.t
---
## Properties of Combination
+
### Property - 1
- The number of ways of selecting **0** items from **N** items, i.e. number of ways to **not select anything**, will always be **1**.
+The number of ways of selecting **0** items from **N** items, i.e. number of ways to **not select anything**, will always be **1**.
---
@@ -145,6 +208,7 @@ Here:
---
## Combination
+
### Explanation
Combination is defined as the number of ways to select something.
@@ -176,6 +240,7 @@ Number of Selections * Number of Arrangements in Each Selection = $4 * 6 = 24$
---
## nCr Formulae
+
### Example - 3
Given **n** distinct elements, in how many ways we can select **r** elements s.t `0 <= r <= n`
@@ -192,9 +257,10 @@ Given **n** distinct elements, in how many ways we can select **r** elements s.t
---
## Properties of Combination
+
### Property - 1
- The number of ways of selecting **0** items from **N** items, i.e. number of ways to **not select anything**, will always be **1**.
+The number of ways of selecting **0** items from **N** items, i.e. number of ways to **not select anything**, will always be **1**.
 @@ -240,19 +306,18 @@ When you choose to "reject" an element, it means that you are not including that
---
## Problem 1 Pascal Triangle
+
+### Pascal Triangle
+### Problem Description
+
Generate Pascal's triangle for given value of `n`.
-**Example**
+### Example
Pascal Triangle for `n = 4` is given below
@@ -240,19 +306,18 @@ When you choose to "reject" an element, it means that you are not including that
---
## Problem 1 Pascal Triangle
+
+### Pascal Triangle
+### Problem Description
+
Generate Pascal's triangle for given value of `n`.
-**Example**
+### Example
Pascal Triangle for `n = 4` is given below
 -
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
**Brute Force:** For each and every value, calculate the factorial and print it.
`c[i][j]` represents the element in the i-th and j-th column. Each element is the sum of the two numbers directly above it from the previous row. In combinatorial terms, `c[i][j]` indicates the number of ways to choose j items from a set of i items without repetition and without order.
@@ -272,12 +337,12 @@ But as we know that, factorial grows very fast as the number increases, hence th
### Pseudo Code
```java
-void pascalsTriangle(int n) {
+function pascalsTriangle(n) {
nCr[n][n] = {0};
- for (int i = 0; i < n; i++) {
+ for (i -> 0 to n) {
nCr[i][0] = 1;
nCr[i][i] = 1;
- for (int j = 1; j < i; j++) {
+ for (j -> 1 to i - 1) {
nCr[i][j] = nCr[i-1][j] + nCr[i-1][j-1];
// If mentioned in the question to take % M then:
// nCr[i][j] = (nCr[i-1][j] + nCr[i-1][j-1]) % M;
@@ -292,7 +357,10 @@ void pascalsTriangle(int n) {
**Space Complexity:** $O(N^2)$
---
-### Problem 2 Finding N-th column title
+## Problem 2 Finding N-th column title
+
+
+### Problem Description
Find the n-th column title, the columns are titled as A, B, C... and after Z, it is AA, AB, AC... and so on. Given the column number, find the title of the column.
@@ -301,15 +369,11 @@ Find the n-th column title, the columns are titled as A, B, C... and after Z, it
Base for mapping A-Z will be 26
-#### Example
+### Example
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
**Brute Force:** For each and every value, calculate the factorial and print it.
`c[i][j]` represents the element in the i-th and j-th column. Each element is the sum of the two numbers directly above it from the previous row. In combinatorial terms, `c[i][j]` indicates the number of ways to choose j items from a set of i items without repetition and without order.
@@ -272,12 +337,12 @@ But as we know that, factorial grows very fast as the number increases, hence th
### Pseudo Code
```java
-void pascalsTriangle(int n) {
+function pascalsTriangle(n) {
nCr[n][n] = {0};
- for (int i = 0; i < n; i++) {
+ for (i -> 0 to n) {
nCr[i][0] = 1;
nCr[i][i] = 1;
- for (int j = 1; j < i; j++) {
+ for (j -> 1 to i - 1) {
nCr[i][j] = nCr[i-1][j] + nCr[i-1][j-1];
// If mentioned in the question to take % M then:
// nCr[i][j] = (nCr[i-1][j] + nCr[i-1][j-1]) % M;
@@ -292,7 +357,10 @@ void pascalsTriangle(int n) {
**Space Complexity:** $O(N^2)$
---
-### Problem 2 Finding N-th column title
+## Problem 2 Finding N-th column title
+
+
+### Problem Description
Find the n-th column title, the columns are titled as A, B, C... and after Z, it is AA, AB, AC... and so on. Given the column number, find the title of the column.
@@ -301,15 +369,11 @@ Find the n-th column title, the columns are titled as A, B, C... and after Z, it
Base for mapping A-Z will be 26
-#### Example
+### Example
 -:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach
+### Approach
* Start with the given number **n**.
* For each digit of the column title (from right to left):
@@ -321,9 +385,9 @@ Please take some time to think about the solution approach on your own before re
* The resulting string is the Excel column title for the original number n.
-#### Code
+### Code
```java
-void columnTitle(int n) {
+function columnTitle(n) {
ans = "";
while(n > 0) {
ans = (char) ((n - 1) % 26 + 'A') + ans; // char + string
@@ -333,7 +397,7 @@ void columnTitle(int n) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(log(N)) [base 26]
**Space Complexity:** O(1)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md b/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md
index b9fc846..a35bd3a 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md
@@ -1,5 +1,13 @@
# Maths 3: Prime Numbers
+## Agenda
+
+* Introduction to Prime Numbers
+* Get all primes from 1 to N
+* Print smallest prime factor for 2 to N
+* Prime Factorization
+* Get the number of factors/divisors
+
---
## Introduction to Prime Numbers
@@ -11,11 +19,14 @@ Numbers having only 2 factors i.e, 1 and the number itself are known as Prime Nu
**Example:** 2, 5, 7, 11
---
-### Problem 1 Check if a number is prime or not
+## Problem 1 Check if a number is prime or not
+
+
+### Problem Description
Given a number, we need to check wheather its a prime number or not
-**Example**
+### Example
**Input:**
```
n = 3
@@ -31,14 +42,20 @@ false
```
---
+
+
### Question
Check whether 11 is a prime number or not!
-**Choices**
+### Choices
- [x] true, 11 is a prime number
- [ ] false, 11 is not a prime number
+---
+## Check if a number is prime or not Approach
+
+
### Approach
@@ -50,56 +67,70 @@ Check whether 11 is a prime number or not!
### Code snippet
```java
-boolean checkPrime(int n) {
- count = 0;
- for (int i = 1; i * i <= n; i++) {
- if (n % i == 0) {
- if (i == n / i) {
+function checkPrime(function n){
+ count=0;
+ for(i -> 1 to sqrt(n)){
+ if(n % i == 0){
+ if(i == n / i) {
count++;
- } else {
+ }
+ else {
count += 2;
}
}
}
- if (count == 2) {
+ if(count == 2) {
print("prime");
- } else {
- print("Not Prime");
}
+ else {
+ print("Not Prime");
+ }
}
```
---
-## Problem 2 Print all prime numbers from 1 to N
+## Problem 2 SecurePrime's Encryption Strategy
+
+### Scenerio
+**SecurePrime Inc.** a renowned cybersecurity firm, is on a mission to upgrade its **encryption** techniques to outsmart potential attackers. Their strategy involves utilizing **prime numbers**, known for their pivotal role in strengthening cryptographic systems
+
+### Problem Statement
+**SecurePrime Inc.** plans to enhance its **encryption keys** by incorporating **random prime numbers** from the **1 to A** into their algorithms. This approach significantly complicates any brute force attempts by attackers, making the encryption much more robust and reliable.
-Given a number N, we need to print all the prime no. from 1 to N
+### Task
+As the requirement , you need to generate prime numbers** from the **1 to A**
-**Example**
+### Example
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach
+### Approach
* Start with the given number **n**.
* For each digit of the column title (from right to left):
@@ -321,9 +385,9 @@ Please take some time to think about the solution approach on your own before re
* The resulting string is the Excel column title for the original number n.
-#### Code
+### Code
```java
-void columnTitle(int n) {
+function columnTitle(n) {
ans = "";
while(n > 0) {
ans = (char) ((n - 1) % 26 + 'A') + ans; // char + string
@@ -333,7 +397,7 @@ void columnTitle(int n) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(log(N)) [base 26]
**Space Complexity:** O(1)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md b/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md
index b9fc846..a35bd3a 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Maths 3 Prime Numbers.md
@@ -1,5 +1,13 @@
# Maths 3: Prime Numbers
+## Agenda
+
+* Introduction to Prime Numbers
+* Get all primes from 1 to N
+* Print smallest prime factor for 2 to N
+* Prime Factorization
+* Get the number of factors/divisors
+
---
## Introduction to Prime Numbers
@@ -11,11 +19,14 @@ Numbers having only 2 factors i.e, 1 and the number itself are known as Prime Nu
**Example:** 2, 5, 7, 11
---
-### Problem 1 Check if a number is prime or not
+## Problem 1 Check if a number is prime or not
+
+
+### Problem Description
Given a number, we need to check wheather its a prime number or not
-**Example**
+### Example
**Input:**
```
n = 3
@@ -31,14 +42,20 @@ false
```
---
+
+
### Question
Check whether 11 is a prime number or not!
-**Choices**
+### Choices
- [x] true, 11 is a prime number
- [ ] false, 11 is not a prime number
+---
+## Check if a number is prime or not Approach
+
+
### Approach
@@ -50,56 +67,70 @@ Check whether 11 is a prime number or not!
### Code snippet
```java
-boolean checkPrime(int n) {
- count = 0;
- for (int i = 1; i * i <= n; i++) {
- if (n % i == 0) {
- if (i == n / i) {
+function checkPrime(function n){
+ count=0;
+ for(i -> 1 to sqrt(n)){
+ if(n % i == 0){
+ if(i == n / i) {
count++;
- } else {
+ }
+ else {
count += 2;
}
}
}
- if (count == 2) {
+ if(count == 2) {
print("prime");
- } else {
- print("Not Prime");
}
+ else {
+ print("Not Prime");
+ }
}
```
---
-## Problem 2 Print all prime numbers from 1 to N
+## Problem 2 SecurePrime's Encryption Strategy
+
+### Scenerio
+**SecurePrime Inc.** a renowned cybersecurity firm, is on a mission to upgrade its **encryption** techniques to outsmart potential attackers. Their strategy involves utilizing **prime numbers**, known for their pivotal role in strengthening cryptographic systems
+
+### Problem Statement
+**SecurePrime Inc.** plans to enhance its **encryption keys** by incorporating **random prime numbers** from the **1 to A** into their algorithms. This approach significantly complicates any brute force attempts by attackers, making the encryption much more robust and reliable.
-Given a number N, we need to print all the prime no. from 1 to N
+### Task
+As the requirement , you need to generate prime numbers** from the **1 to A**
-**Example**
+### Example
 +---
+
### Question
Find all the prime numbers from 1 to N
-**Choices**
+### Choices
- [ ] 1, 2, 3, 5, 7
- [ ] 2, 3, 5, 7, 8
- [x] 2, 3, 5, 7
- [ ] 2, 5 ,7
+
+
+---
+## SecurePrime's Encryption Strategy Solution
+
+
### Solution
**Brute Force:** Iterate from 1 to N, and check if a number is prime or not.
```java
-void printAllPrime(int n) {
- for (int i = 2; i <= n; ++i) {
- boolean isPrime = true;
- for (int j = 2; j * j <= i; ++j) {
- if (i % j == 0) {
- isPrime = false;
- break;
- }
- }
+function printAllPrime(n) {
+ for (i -> 2 to n) {
+ if(checkPrime(i) == true) {
+ print(i + " ");
}
+ }
+}
```
* **Time Complexity (TC):** The time complexity of the given function is $O(n√n)$, as it iterates through numbers from 2 to N and for each number, it checks divisibility up to the square root of that number.
@@ -108,9 +139,10 @@ void printAllPrime(int n) {
---
## Sieve of Eratosthenes
+
### Optimized approach for counting number of primes between 1 to N
-**Approach**
+### Approach
* **Assumption:** Begin by assuming that all numbers from 2 to N are prime numbers.
* **Marking Non-Primes:** Start with the first prime number, which is 2. Since 2 is a prime number, mark all its multiples as non-prime. These multiples are 4, 6, 8, and so on.
@@ -123,14 +155,16 @@ void printAllPrime(int n) {
### Code Snippet
```java
-void printAllPrime(int n) {
- boolean[] isPrime = new boolean[n + 1]; // Initialize a boolean array to track prime numbers
- Arrays.fill(isPrime, 2, n + 1, true); // Assume all numbers from 2 to n are prime
-
- for (int i = 2; i * i <= n; ++i) {
+function printAllPrime(n) {
+ isPrime = new array of size [n + 1]; // Initialize a boolean array to track prime numbers
+ fill all values of isPrime from 2 to n with true // Assume all numbers from 2 to n are prime
+
+ for (i -> 2 to sqrt(n)) {
if (isPrime[i]) {
- for (int j = i * i; j <= n; j += i) {
+ j = i * i ;
+ while(j <= n) {
isPrime[j] = false; // Mark multiples of the current prime as non-prime
+ j = j + i ;
}
}
}
@@ -150,151 +184,106 @@ Starting from the square of each prime number, mark all its multiples as non-pri
* **Time Complexity (TC):** The optimized Sieve of Eratosthenes has a time complexity of O(n log log n), which means it grows very slowly. This is because the algorithm only visits and marks numbers up to the square root of N, and the number of non-prime numbers marked is logarithmic with respect to N.
* **Space Complexity (SC):** The space complexity is O(n), which is used to store the boolean array indicating whether each number is prime or not. The space used is directly proportional to the input size N.
----
-### Problem 3 Smallest Prime Factor
-
-Given N, return the smallest prime factors for all numbers from 2 to N
-
-**Example:**
-
-
+---
+
### Question
Find all the prime numbers from 1 to N
-**Choices**
+### Choices
- [ ] 1, 2, 3, 5, 7
- [ ] 2, 3, 5, 7, 8
- [x] 2, 3, 5, 7
- [ ] 2, 5 ,7
+
+
+---
+## SecurePrime's Encryption Strategy Solution
+
+
### Solution
**Brute Force:** Iterate from 1 to N, and check if a number is prime or not.
```java
-void printAllPrime(int n) {
- for (int i = 2; i <= n; ++i) {
- boolean isPrime = true;
- for (int j = 2; j * j <= i; ++j) {
- if (i % j == 0) {
- isPrime = false;
- break;
- }
- }
+function printAllPrime(n) {
+ for (i -> 2 to n) {
+ if(checkPrime(i) == true) {
+ print(i + " ");
}
+ }
+}
```
* **Time Complexity (TC):** The time complexity of the given function is $O(n√n)$, as it iterates through numbers from 2 to N and for each number, it checks divisibility up to the square root of that number.
@@ -108,9 +139,10 @@ void printAllPrime(int n) {
---
## Sieve of Eratosthenes
+
### Optimized approach for counting number of primes between 1 to N
-**Approach**
+### Approach
* **Assumption:** Begin by assuming that all numbers from 2 to N are prime numbers.
* **Marking Non-Primes:** Start with the first prime number, which is 2. Since 2 is a prime number, mark all its multiples as non-prime. These multiples are 4, 6, 8, and so on.
@@ -123,14 +155,16 @@ void printAllPrime(int n) {
### Code Snippet
```java
-void printAllPrime(int n) {
- boolean[] isPrime = new boolean[n + 1]; // Initialize a boolean array to track prime numbers
- Arrays.fill(isPrime, 2, n + 1, true); // Assume all numbers from 2 to n are prime
-
- for (int i = 2; i * i <= n; ++i) {
+function printAllPrime(n) {
+ isPrime = new array of size [n + 1]; // Initialize a boolean array to track prime numbers
+ fill all values of isPrime from 2 to n with true // Assume all numbers from 2 to n are prime
+
+ for (i -> 2 to sqrt(n)) {
if (isPrime[i]) {
- for (int j = i * i; j <= n; j += i) {
+ j = i * i ;
+ while(j <= n) {
isPrime[j] = false; // Mark multiples of the current prime as non-prime
+ j = j + i ;
}
}
}
@@ -150,151 +184,106 @@ Starting from the square of each prime number, mark all its multiples as non-pri
* **Time Complexity (TC):** The optimized Sieve of Eratosthenes has a time complexity of O(n log log n), which means it grows very slowly. This is because the algorithm only visits and marks numbers up to the square root of N, and the number of non-prime numbers marked is logarithmic with respect to N.
* **Space Complexity (SC):** The space complexity is O(n), which is used to store the boolean array indicating whether each number is prime or not. The space used is directly proportional to the input size N.
----
-### Problem 3 Smallest Prime Factor
-
-Given N, return the smallest prime factors for all numbers from 2 to N
-
-**Example:**
-
- -
-### Question
-What is the smallest prime factor of 25
-
-**Choices**
-- [ ] 1
-- [x] 5
-- [ ] 10
-- [ ] 25
-
----
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Smallest Prime Factor Approach
-
-* **Initialization:** Create an integer array to store the smallest prime factors for each number from 2 to N. Initialize each element of the array to its own value, indicating that it's not yet known if the number is prime or not.
-* **Smallest Prime Factor Determination:** Starting from the first prime number (2), for each prime number:
- * If the smallest prime factor for a number is still its own value (indicating it's not determined yet), mark it as the smallest prime factor for all its multiples.
-* **Iterate Over All Numbers:** Go through each number from 2 to N, and for each number, if its smallest prime factor is still itself, mark it as prime and set its smallest prime factor to itself.
-* **Smallest Prime Factors:** The array will now hold the smallest prime factors for all numbers from 2 to N.
-
-
-
-### Question
-What is the smallest prime factor of 25
-
-**Choices**
-- [ ] 1
-- [x] 5
-- [ ] 10
-- [ ] 25
-
----
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Smallest Prime Factor Approach
-
-* **Initialization:** Create an integer array to store the smallest prime factors for each number from 2 to N. Initialize each element of the array to its own value, indicating that it's not yet known if the number is prime or not.
-* **Smallest Prime Factor Determination:** Starting from the first prime number (2), for each prime number:
- * If the smallest prime factor for a number is still its own value (indicating it's not determined yet), mark it as the smallest prime factor for all its multiples.
-* **Iterate Over All Numbers:** Go through each number from 2 to N, and for each number, if its smallest prime factor is still itself, mark it as prime and set its smallest prime factor to itself.
-* **Smallest Prime Factors:** The array will now hold the smallest prime factors for all numbers from 2 to N.
-
- -
-```java
-public int[] smallestPrimeFactors(int n) {
- int[] spf = new int[n + 1];
-
- for (int i = 2; i <= n; ++i) {
- spf[i] = i; // Initialize smallest prime factor with its own value
-
- if (spf[i] == i) { // i is prime
- for (int j = i * i; j <= n; j += i) {
- if (spf[j] == j) {
- spf[j] = i; // Mark smallest prime factor for multiples
- }
- }
- }
- }
-
- return spf;
-}
-```
---
-## Prime Factorization
+## Count of Divisors
-Prime factorization is the process of finding the prime numbers, which are multiplied together to get the original number. For example, the prime factors of 16 are $2 × 2 × 2 × 2$.
+### Problem Statement
+Given a number n, you need to find the count of divisors for every integer from 1 to n. The task is to efficiently calculate the number of divisors for all numbers in the range using a modified prime sieve technique.
+### Examples
+Input: n=6
+Output: [1,2,2,3,2,4]
+This means:
+1 has 1 divisor.
+2 has 2 divisors: 1,2
+3 has 2 divisors: 1,3
+4 has 3 divisors: 1,2,4
+5 has 2 divisors: 1,5
+6 has 4 divisors: 1,2,3,6
-
-
-```java
-public int[] smallestPrimeFactors(int n) {
- int[] spf = new int[n + 1];
-
- for (int i = 2; i <= n; ++i) {
- spf[i] = i; // Initialize smallest prime factor with its own value
-
- if (spf[i] == i) { // i is prime
- for (int j = i * i; j <= n; j += i) {
- if (spf[j] == j) {
- spf[j] = i; // Mark smallest prime factor for multiples
- }
- }
- }
- }
-
- return spf;
-}
-```
---
-## Prime Factorization
+## Count of Divisors
-Prime factorization is the process of finding the prime numbers, which are multiplied together to get the original number. For example, the prime factors of 16 are $2 × 2 × 2 × 2$.
+### Problem Statement
+Given a number n, you need to find the count of divisors for every integer from 1 to n. The task is to efficiently calculate the number of divisors for all numbers in the range using a modified prime sieve technique.
+### Examples
+Input: n=6
+Output: [1,2,2,3,2,4]
+This means:
+1 has 1 divisor.
+2 has 2 divisors: 1,2
+3 has 2 divisors: 1,3
+4 has 3 divisors: 1,2,4
+5 has 2 divisors: 1,5
+6 has 4 divisors: 1,2,3,6
- -
-
-
-
-
- +### Observation
+The number of divisors for a number k can be calculated by counting how many integers between 1 and k divide k exactly.
+### For example:
+4 is divisible by 1,2 and 4, so it has 3 divisors.
+6 is divisible by 1,2,3 and 6, so it has 4 divisors.
---
-### Problem 4 Total Number of Factors
-
-Given a number n, assume its prime factorization
-
-$n=i^{a1}*j^{a2}*k^{a3}...z^{ax}$
+## Count of Divisors using Sieve
-the number of choices we have for the power of every prime is [0, a1], [0,a2], [0, a3].............[0, ax]
+We can use a modified sieve approach to calculate the number of divisors for each number up to n.
-the number of divisor/factors will be given by the formula:
+The idea is to iterate over each number i and increment the divisor count for all multiples of i. **Here's how it works:**
+1. Initialize an array divisor_count of size n+1 with all elements set to zero. This array will hold the number of divisors for each number.
+2. Iterate through each number i from 1 to n. **For each i:**
+ - Increment the divisor count for all multiples of i (i.e., divisor_count[j]++ where j is a multiple of i).
+3. Return the divisor_count array (ignoring the 0th index as it is unused).
-(a1 + 1)*(a2 + 1)*(a3 + 1)*.....(ax + 1)
-
-
-Example
-
-**Example 1**
-$25 = 5^2$
-
-Number of divisors = $(2+1) = 3$
-
-
-**Example 2**
+### Find divisors
+### Observation
+The number of divisors for a number k can be calculated by counting how many integers between 1 and k divide k exactly.
+### For example:
+4 is divisible by 1,2 and 4, so it has 3 divisors.
+6 is divisible by 1,2,3 and 6, so it has 4 divisors.
---
-### Problem 4 Total Number of Factors
-
-Given a number n, assume its prime factorization
-
-$n=i^{a1}*j^{a2}*k^{a3}...z^{ax}$
+## Count of Divisors using Sieve
-the number of choices we have for the power of every prime is [0, a1], [0,a2], [0, a3].............[0, ax]
+We can use a modified sieve approach to calculate the number of divisors for each number up to n.
-the number of divisor/factors will be given by the formula:
+The idea is to iterate over each number i and increment the divisor count for all multiples of i. **Here's how it works:**
+1. Initialize an array divisor_count of size n+1 with all elements set to zero. This array will hold the number of divisors for each number.
+2. Iterate through each number i from 1 to n. **For each i:**
+ - Increment the divisor count for all multiples of i (i.e., divisor_count[j]++ where j is a multiple of i).
+3. Return the divisor_count array (ignoring the 0th index as it is unused).
-(a1 + 1)*(a2 + 1)*(a3 + 1)*.....(ax + 1)
-
-
-Example
-
-**Example 1**
-$25 = 5^2$
-
-Number of divisors = $(2+1) = 3$
-
-
-**Example 2**
+### Find divisors
 -### Question
-Find the total number of factors of 20
-
-**Choices**
-- [x] 5
-- [ ] 1
-- [ ] 3
-- [ ] 4
-
-
-**Explanation:**
-
-20 = 2^2^ * 5^1^
- = (2 + 1) * (1 + 1)
- = 5
-
-
-The factors are 1, 2, 5, 10, 20.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
---
-### Total Number of Factors Approach
+## Sorted Permutation Rank
-#### Approach
-* **Prime Factorization:** For each number from 1 to N, find its prime factorization. Determine the prime factors of the number and their respective powers.
-* **Counting Factors:** The number of factors for a given number is calculated by adding 1 to each power of its prime factors and then multiplying those incremented powers together.
-* **Iterate through Numbers:** Iterate through the numbers from 1 to N. For each number:
- * Calculate its prime factorization.
- * Count the factors using the prime factors' powers.
-* **Store or Output Results:** Store or output the number of factors/divisors for each number.
+### Problem Description
+You are given a string AAA containing distinct characters (no characters are repeated). The task is to find the rank of this string among all its permutations when sorted in lexicographical (dictionary) order.
-The number of factors for a given number is calculated by adding 1 to each power of its prime factors and then multiplying those incremented powers together.
+### Explanation in Simple Steps
+Lexicographical order is the order in which words are arranged in a dictionary. For example, for the string "ABC":
+The permutations in order are: "ABC", "ACB", "BAC", "BCA", "CAB", "CBA".
+The rank of "ACB" is 2, because it is the second permutation in this list.
-* **For 1:** $(1+1) = 2$ factors (1 and itself).
-* **For 2:** $(1+1) = 2$ factors (1 and 2).
-* **For 3:** $(1+1) = 2$ factors (1 and 3).
-* **For 4:** $(2+1) = 3$ factors (1, 2, and 4).
-* **For 5:** $(1+1) = 2$ factors (1 and 5).
-* **For 6:** $(1+1) * (1+1) = 4$ factors (1, 2, 3, and 6).
-* **For 7:** $(1+1) = 2$ factors (1 and 7).
-* **For 8:** $(3+1) = 4$ factors (1, 2, 4, and 8).
-* **For 9:** $(2+1) = 3$ factors (1, 3, and 9).
-* **For 10:** $(1+1) * (1+1) = 4$ factors (1, 2, 5, and 10).
+### How to Find the Rank of the String:
+* To determine the rank of the string AAA, we need to count how many permutations would appear before it in lexicographical order.
+* For each character in the string, you compare it with the characters that come after it and count how many characters are smaller than it. These smaller characters could have appeared in the earlier permutations.
-
-### Question
-Find the total number of factors of 20
-
-**Choices**
-- [x] 5
-- [ ] 1
-- [ ] 3
-- [ ] 4
-
-
-**Explanation:**
-
-20 = 2^2^ * 5^1^
- = (2 + 1) * (1 + 1)
- = 5
-
-
-The factors are 1, 2, 5, 10, 20.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
---
-### Total Number of Factors Approach
+## Sorted Permutation Rank
-#### Approach
-* **Prime Factorization:** For each number from 1 to N, find its prime factorization. Determine the prime factors of the number and their respective powers.
-* **Counting Factors:** The number of factors for a given number is calculated by adding 1 to each power of its prime factors and then multiplying those incremented powers together.
-* **Iterate through Numbers:** Iterate through the numbers from 1 to N. For each number:
- * Calculate its prime factorization.
- * Count the factors using the prime factors' powers.
-* **Store or Output Results:** Store or output the number of factors/divisors for each number.
+### Problem Description
+You are given a string AAA containing distinct characters (no characters are repeated). The task is to find the rank of this string among all its permutations when sorted in lexicographical (dictionary) order.
-The number of factors for a given number is calculated by adding 1 to each power of its prime factors and then multiplying those incremented powers together.
+### Explanation in Simple Steps
+Lexicographical order is the order in which words are arranged in a dictionary. For example, for the string "ABC":
+The permutations in order are: "ABC", "ACB", "BAC", "BCA", "CAB", "CBA".
+The rank of "ACB" is 2, because it is the second permutation in this list.
-* **For 1:** $(1+1) = 2$ factors (1 and itself).
-* **For 2:** $(1+1) = 2$ factors (1 and 2).
-* **For 3:** $(1+1) = 2$ factors (1 and 3).
-* **For 4:** $(2+1) = 3$ factors (1, 2, and 4).
-* **For 5:** $(1+1) = 2$ factors (1 and 5).
-* **For 6:** $(1+1) * (1+1) = 4$ factors (1, 2, 3, and 6).
-* **For 7:** $(1+1) = 2$ factors (1 and 7).
-* **For 8:** $(3+1) = 4$ factors (1, 2, 4, and 8).
-* **For 9:** $(2+1) = 3$ factors (1, 3, and 9).
-* **For 10:** $(1+1) * (1+1) = 4$ factors (1, 2, 5, and 10).
+### How to Find the Rank of the String:
+* To determine the rank of the string AAA, we need to count how many permutations would appear before it in lexicographical order.
+* For each character in the string, you compare it with the characters that come after it and count how many characters are smaller than it. These smaller characters could have appeared in the earlier permutations.
- -
-#### Code
-
-
-
-#### Code
-
- +---
+## Sorted Permutation Rank Solution
+
+
+### Step-by-Step Process:
+* Start with the first character of the string.
+* For each character, calculate how many permutations can be formed with the smaller characters to the right of it.
+* Add up these counts to get the total number of permutations that come before the string.
+* The rank is 1 plus this total count (since rank starts at 1).
+
+### Modulo Operation:
+Since the rank might be a large number, return the answer modulo 100000310000031000003 (a large prime number) to ensure it fits within standard data types.
+
+### Example Walkthrough
+Consider the string A="BAC":
+**Step 1:** Look at the first character, "B".
+Characters that could come before "B" in sorted order are "A".
+There are 2 remaining characters ("AC"), which can be arranged in 2!=2 ways.
+So, 2 permutations start with "A", which would come before any permutation starting with "B".
+**Step 2:** Move to the next character, "A".
+There are no characters smaller than "A" after it, so no new permutations can be formed that would come before "BAC".
+**Step 3:** Finally, count the total permutations before "BAC":
+There are 2 permutations before "BAC", so the rank of "BAC" is 2+1=32 + 1 = 32+1=3.
+Thus, the rank of "BAC" is 3.
+
+### Pseudocode
+```javascript
+function find_rank(A):
+ rank = 1
+ n = len(A)
+ factorials[0] = 1
+ FOR i FROM 1 TO n:
+ factorials[i] = (factorials[i-1] * i) % 1000003
+
+ FOR i FROM 0 TO n-1:
+ COUNT smaller characters on the right of A[i]
+ rank += COUNT * factorials[n-i-1]
+ rank %= 1000003
+
+ RETURN rank
+```
-* **Time Complexity (TC):** The time complexity of this code is O(N * log N), mainly due to the prime factorization process for each number from 1 to N.
-* **Space Complexity (SC):** The space complexity is O(N), where the primary space usage comes from the arrays for storing the smallest prime factors and the hashmap for storing the factors count for each number.
+### Key Points:
+- **Counting:** For each character, count the number of smaller characters to its right and calculate the permutations.
+- **Result:** Add up these permutation counts, add 1 for the current string, and return the result modulo 1000003.
+- This approach efficiently calculates the rank in O(n^2^) time complexity, which is feasible for strings of moderate length.
diff --git a/Academy DSA Typed Notes/Advanced/DSA OOPS 1 Introduction.md b/Academy DSA Typed Notes/Advanced/DSA OOPS 1 Introduction.md
deleted file mode 100644
index 091d661..0000000
--- a/Academy DSA Typed Notes/Advanced/DSA OOPS 1 Introduction.md
+++ /dev/null
@@ -1,488 +0,0 @@
-# OOPS 1
-
-
-### Programming Paradigms
-
-Types:
-* **Imperative Programming** - It tells the computer how to do the task by giving a set of instructions in a particular order i.e. line by line.
-```cpp
-// For eg:
-int a = 10;
-int b = 20;
-int sum = a + b;
-print(sum);
-int dif = a - b;
-print(dif);
-```
-* **Procedural Programming** - It splits the entire program into small procedures or functions (section of code that perform a specific task) which are reusable code blocks.
-```cpp
-// For eg:
-int a = 10;
-int b = 20;
-addTwoNumbers(a, b);
-subtractTwoNumbers(a, b);
-
-void addTwoNumbers(a, b) {
- int sum = a + b;
- print(sum);
-}
-
-void subtractTwoNumbers(a, b) {
- int dif = a - b;
- print(dif);
-}
-```
-
-* **Object Oriented Programming** - It builds the entire program using classes and objects. [will discuss this in detail today!]
-
-* **Declarative Programming** - In this paradigm, you specify "what" you want the program to do without specifying "how" it should be done.
-```SQL
--- For eg: (SQL Queries)
-select * from Customer;
-```
-* **Functional Programming**, **Logic Programming**, etc.
-
-Most of the people start their coding journey with procedural programming and hence let's start with the first type of paradigm i.e. procedural programming.
-
----
-## Procedural Programming
-It splits the entire program into small procedures or functions (section of code that perform a specific task) which are reusable code blocks. Eg - C, C++, etc.
-
-Procedure is an oldage name of function/method.
-
-```cpp
-// For eg:
-void addTwoNumbers(a, b) {
- int sum = a + b;
- print(sum);
-}
-
-void addThreeNumbers(a, b, c) {
- int sum = a + b;
- addTwoNumbers(sum, c);
-}
-
-void main() {
- addThreeNumbers(10, 20, 30);
-}
-```
----
-### Problems with Procedural Programming
-
-**Cons of Procedural programming:**
-* Difficult to make sense
-* Difficult to debug and understand
-* Spaghetti code i.e. unstructured and needs to be tracked form multiple locations.
-
-So this is all about procedural programming, now lets move to OOPs as we are preparing for the base of OOPs.
-
----
-## Object Oriented Programming Introduction
-
-### OOPS
-
-OOPs came from the need of thinking of software systems in terms of how we humans think about real world.
-* Entities are core in OOPs
-* Every entity has some attribute and behaviour
-
-In object oriented programming we build the entire program using classes and objects (entity).
-
-**Class:** Blueprint of an idea.
-
-Example - Floor plan of an apartment.
-So, while designing new house, we make something called blue print.
-
+---
+## Sorted Permutation Rank Solution
+
+
+### Step-by-Step Process:
+* Start with the first character of the string.
+* For each character, calculate how many permutations can be formed with the smaller characters to the right of it.
+* Add up these counts to get the total number of permutations that come before the string.
+* The rank is 1 plus this total count (since rank starts at 1).
+
+### Modulo Operation:
+Since the rank might be a large number, return the answer modulo 100000310000031000003 (a large prime number) to ensure it fits within standard data types.
+
+### Example Walkthrough
+Consider the string A="BAC":
+**Step 1:** Look at the first character, "B".
+Characters that could come before "B" in sorted order are "A".
+There are 2 remaining characters ("AC"), which can be arranged in 2!=2 ways.
+So, 2 permutations start with "A", which would come before any permutation starting with "B".
+**Step 2:** Move to the next character, "A".
+There are no characters smaller than "A" after it, so no new permutations can be formed that would come before "BAC".
+**Step 3:** Finally, count the total permutations before "BAC":
+There are 2 permutations before "BAC", so the rank of "BAC" is 2+1=32 + 1 = 32+1=3.
+Thus, the rank of "BAC" is 3.
+
+### Pseudocode
+```javascript
+function find_rank(A):
+ rank = 1
+ n = len(A)
+ factorials[0] = 1
+ FOR i FROM 1 TO n:
+ factorials[i] = (factorials[i-1] * i) % 1000003
+
+ FOR i FROM 0 TO n-1:
+ COUNT smaller characters on the right of A[i]
+ rank += COUNT * factorials[n-i-1]
+ rank %= 1000003
+
+ RETURN rank
+```
-* **Time Complexity (TC):** The time complexity of this code is O(N * log N), mainly due to the prime factorization process for each number from 1 to N.
-* **Space Complexity (SC):** The space complexity is O(N), where the primary space usage comes from the arrays for storing the smallest prime factors and the hashmap for storing the factors count for each number.
+### Key Points:
+- **Counting:** For each character, count the number of smaller characters to its right and calculate the permutations.
+- **Result:** Add up these permutation counts, add 1 for the current string, and return the result modulo 1000003.
+- This approach efficiently calculates the rank in O(n^2^) time complexity, which is feasible for strings of moderate length.
diff --git a/Academy DSA Typed Notes/Advanced/DSA OOPS 1 Introduction.md b/Academy DSA Typed Notes/Advanced/DSA OOPS 1 Introduction.md
deleted file mode 100644
index 091d661..0000000
--- a/Academy DSA Typed Notes/Advanced/DSA OOPS 1 Introduction.md
+++ /dev/null
@@ -1,488 +0,0 @@
-# OOPS 1
-
-
-### Programming Paradigms
-
-Types:
-* **Imperative Programming** - It tells the computer how to do the task by giving a set of instructions in a particular order i.e. line by line.
-```cpp
-// For eg:
-int a = 10;
-int b = 20;
-int sum = a + b;
-print(sum);
-int dif = a - b;
-print(dif);
-```
-* **Procedural Programming** - It splits the entire program into small procedures or functions (section of code that perform a specific task) which are reusable code blocks.
-```cpp
-// For eg:
-int a = 10;
-int b = 20;
-addTwoNumbers(a, b);
-subtractTwoNumbers(a, b);
-
-void addTwoNumbers(a, b) {
- int sum = a + b;
- print(sum);
-}
-
-void subtractTwoNumbers(a, b) {
- int dif = a - b;
- print(dif);
-}
-```
-
-* **Object Oriented Programming** - It builds the entire program using classes and objects. [will discuss this in detail today!]
-
-* **Declarative Programming** - In this paradigm, you specify "what" you want the program to do without specifying "how" it should be done.
-```SQL
--- For eg: (SQL Queries)
-select * from Customer;
-```
-* **Functional Programming**, **Logic Programming**, etc.
-
-Most of the people start their coding journey with procedural programming and hence let's start with the first type of paradigm i.e. procedural programming.
-
----
-## Procedural Programming
-It splits the entire program into small procedures or functions (section of code that perform a specific task) which are reusable code blocks. Eg - C, C++, etc.
-
-Procedure is an oldage name of function/method.
-
-```cpp
-// For eg:
-void addTwoNumbers(a, b) {
- int sum = a + b;
- print(sum);
-}
-
-void addThreeNumbers(a, b, c) {
- int sum = a + b;
- addTwoNumbers(sum, c);
-}
-
-void main() {
- addThreeNumbers(10, 20, 30);
-}
-```
----
-### Problems with Procedural Programming
-
-**Cons of Procedural programming:**
-* Difficult to make sense
-* Difficult to debug and understand
-* Spaghetti code i.e. unstructured and needs to be tracked form multiple locations.
-
-So this is all about procedural programming, now lets move to OOPs as we are preparing for the base of OOPs.
-
----
-## Object Oriented Programming Introduction
-
-### OOPS
-
-OOPs came from the need of thinking of software systems in terms of how we humans think about real world.
-* Entities are core in OOPs
-* Every entity has some attribute and behaviour
-
-In object oriented programming we build the entire program using classes and objects (entity).
-
-**Class:** Blueprint of an idea.
-
-Example - Floor plan of an apartment.
-So, while designing new house, we make something called blue print.
- -
-Now this will have exact dimensions as per need. Is the house built? No not yet, but whenever it will get built, the design will be look like this.
-
-**Class represent the strucutre of the idea.**
-Class has attributes to define data and methods to define functionalities/behaviour.
-
-Lets build a `Student` class with some attributes and methods.
-
-Its the basic structure, its not a real thing, it just show what data every student holds upto. Also, You can create multiple instances of this class.
-
-
-Now this will have exact dimensions as per need. Is the house built? No not yet, but whenever it will get built, the design will be look like this.
-
-**Class represent the strucutre of the idea.**
-Class has attributes to define data and methods to define functionalities/behaviour.
-
-Lets build a `Student` class with some attributes and methods.
-
-Its the basic structure, its not a real thing, it just show what data every student holds upto. Also, You can create multiple instances of this class.
- -
-**Object:** They are real instances of the class.
-
-### Question
-
-Will the object of a class occupy memory?
-
-**Choices**
-
-- [ ] No
-- [ ] In some cases only
-- [x] Yes
-
-
-Yes they will occupy memory because they are real instance of the class / blueprint.
-
----
-### Classes & Objects Example
-
-Now lets create a class and object and see how this thing works on machine.
-
-1. We will create a class named Student
-
-
-
-**Object:** They are real instances of the class.
-
-### Question
-
-Will the object of a class occupy memory?
-
-**Choices**
-
-- [ ] No
-- [ ] In some cases only
-- [x] Yes
-
-
-Yes they will occupy memory because they are real instance of the class / blueprint.
-
----
-### Classes & Objects Example
-
-Now lets create a class and object and see how this thing works on machine.
-
-1. We will create a class named Student
-
- -```java
-}
-```
-
-2. Then, we will create the main class
-
-
-```java
-}
-```
-
-2. Then, we will create the main class
-
- -
-3. And we can see that both naman and dinesh have their own identity
-
-
-3. And we can see that both naman and dinesh have their own identity
- -
----
-### Pillars of Object Oriented Programming
-
-Now what is principle and pillar?
-* **Principle** - Fundamental foundation / concept.
-* **Pillar** - Support to hold things together
-
-
-**So what does the principle of OOP says?**
-
-Idea of OOP is based on **abstraction** and the whole software system is build around abstraction.
-
-But how would we implement the abstraction? ---> Using the 3 pillars of OOPs i.e.
-* **Inheritance**
-* **Polymorphism**
-* **Encapsulation**
-
-
-**For example:**
-
-Your **principal** can be:
-- I will be a good person.
-
-But how you would be a good person? Here comes your **pillars**:
-- I will be truthfull,
-- I will do hardwork,
-- I respect everyone, etc.
-
-So we got to know that abstraction is not the pillar of OOPs, it is the main principle on which whole concept of OOP is based.
-
-
----
-### OOPs Abstraction
-
-Abstraction means ---> **Representing in terms of ideas**.
-
-Now what does ideas mean? ---> Anything in software system that has attrubute and associated behaviour.
-
-So if you are building scaler, you don't have to think about storing individuals like, Naman, Anshuman, Indarjeet. You can use Students, Mentors, TAs, Classes, etc. with their attributes.
-
-**Do they have a behaviour?**
-
-Yes they all have some behaviour. Student can send messages, pause courses these are all behaviours.
-So abstraction is an idea of representing complex software system interms of ideas, because ideas are easy to understand.
-So, its an concept of making something abstract.
-
-### What is the purpose of abstraction?
-
-The main purpose is that others dont need to know the details of the idea.
-
-Suppose you are driving a car, and you want it to turn left and speed up, and you steer the steering to left and press the acceleration pedal. It works right? Do you need to know how does this happen? What combustion is happening, how much fuel is used, How steering wheel turned the car?
-No right? This is what we call as abstraction.
-
-Abstraction is way to represent complex software system, in terms of ideas.
-
-What needed to be represented in terms of ideas?
-* Data
-* Anything that has behaviours
-
-No one else need to know the details about the ideas.
-
-Now let's move to encapsulation.
-
----
-## OOPs Encapsulation
-
-
-So what are the purpose for making capsules, and not normal medicine?
-
-If the capsule breaks away, what will happen?
-- It will flow away. So first purpose is to hold the medicine powder together.
-- Then there are multiple powders are present in the capsule, it helps them to avoid mixing with each other.
-- Third purpose is it protects the medicine from the outside environment.
-
-This is exactly the purpose of Encapsulation in OOP.
-
-Encapsulation allows us to store attribute and Behaviours together.
-
-### Question
-
-Where do we store attribute and behavious together? What is the technical term for that?
-
-**Choices**
-
-- [x] Class
-- [ ] Object
-- [ ] Project
-
-
-
-Yes, a **class**, and it protects attributes & methods from outer environment i.e. other classes can't have access to it if we restrict.
-
-
-
----
-### Pillars of Object Oriented Programming
-
-Now what is principle and pillar?
-* **Principle** - Fundamental foundation / concept.
-* **Pillar** - Support to hold things together
-
-
-**So what does the principle of OOP says?**
-
-Idea of OOP is based on **abstraction** and the whole software system is build around abstraction.
-
-But how would we implement the abstraction? ---> Using the 3 pillars of OOPs i.e.
-* **Inheritance**
-* **Polymorphism**
-* **Encapsulation**
-
-
-**For example:**
-
-Your **principal** can be:
-- I will be a good person.
-
-But how you would be a good person? Here comes your **pillars**:
-- I will be truthfull,
-- I will do hardwork,
-- I respect everyone, etc.
-
-So we got to know that abstraction is not the pillar of OOPs, it is the main principle on which whole concept of OOP is based.
-
-
----
-### OOPs Abstraction
-
-Abstraction means ---> **Representing in terms of ideas**.
-
-Now what does ideas mean? ---> Anything in software system that has attrubute and associated behaviour.
-
-So if you are building scaler, you don't have to think about storing individuals like, Naman, Anshuman, Indarjeet. You can use Students, Mentors, TAs, Classes, etc. with their attributes.
-
-**Do they have a behaviour?**
-
-Yes they all have some behaviour. Student can send messages, pause courses these are all behaviours.
-So abstraction is an idea of representing complex software system interms of ideas, because ideas are easy to understand.
-So, its an concept of making something abstract.
-
-### What is the purpose of abstraction?
-
-The main purpose is that others dont need to know the details of the idea.
-
-Suppose you are driving a car, and you want it to turn left and speed up, and you steer the steering to left and press the acceleration pedal. It works right? Do you need to know how does this happen? What combustion is happening, how much fuel is used, How steering wheel turned the car?
-No right? This is what we call as abstraction.
-
-Abstraction is way to represent complex software system, in terms of ideas.
-
-What needed to be represented in terms of ideas?
-* Data
-* Anything that has behaviours
-
-No one else need to know the details about the ideas.
-
-Now let's move to encapsulation.
-
----
-## OOPs Encapsulation
-
-
-So what are the purpose for making capsules, and not normal medicine?
-
-If the capsule breaks away, what will happen?
-- It will flow away. So first purpose is to hold the medicine powder together.
-- Then there are multiple powders are present in the capsule, it helps them to avoid mixing with each other.
-- Third purpose is it protects the medicine from the outside environment.
-
-This is exactly the purpose of Encapsulation in OOP.
-
-Encapsulation allows us to store attribute and Behaviours together.
-
-### Question
-
-Where do we store attribute and behavious together? What is the technical term for that?
-
-**Choices**
-
-- [x] Class
-- [ ] Object
-- [ ] Project
-
-
-
-Yes, a **class**, and it protects attributes & methods from outer environment i.e. other classes can't have access to it if we restrict.
-
- -
-Here no one can access the age of student other than the class student.
-
----
-## Access Modifiers
-
-We got to know that Encapsulation has two advantages,
-* ONE is it holds data and attributes together and
-* SECOND is it protect members from illegitimate access. You can't access the data from class unless the class allows you to.
-
-Now, The first thing gets sorted by class, i.e. we create a class, and it holds the behaviors and attributes together.
-
-But, **How the SECOND one is implemented?**
-i.e., How in code illegitimate access is prevented?
-How the encapsulation prevents access to class data?
-
-That is something called **access modifiers**.
-
----
-### Question
-
-Which one of these is **not** an access modifier?
-
-**Choices**
-
-- [ ] Public
-- [x] Open
-- [ ] Private
-- [ ] Protected
-
----
-### Types of Access Modifiers
-
-There are four access modifiers in most of the programming languages, they are:
-* **Public**
-* **Private**
-* **Protected**
-* **Default** (if we don't use any of the above three, then its the default one)
-
-So what are these access modifiers? Let's quickly look at them.
-
-**Public access modifier** - A public attribute or method can be accessed by everyone.
-
-**Private access modifiers** - A private attribute or method can be accessed by no one, not even the child class.
-**Explanation** - It can be accessed by the **same** class. No one outside the class has access to private methods.
-
-**Protected access modifier** - A protected attribute or method can be accessed only from the classes of the same package.
-
-Let me show you a diagram that will be helpful in understanding and will clear most of your doubts.
-
-where:
-
-Here no one can access the age of student other than the class student.
-
----
-## Access Modifiers
-
-We got to know that Encapsulation has two advantages,
-* ONE is it holds data and attributes together and
-* SECOND is it protect members from illegitimate access. You can't access the data from class unless the class allows you to.
-
-Now, The first thing gets sorted by class, i.e. we create a class, and it holds the behaviors and attributes together.
-
-But, **How the SECOND one is implemented?**
-i.e., How in code illegitimate access is prevented?
-How the encapsulation prevents access to class data?
-
-That is something called **access modifiers**.
-
----
-### Question
-
-Which one of these is **not** an access modifier?
-
-**Choices**
-
-- [ ] Public
-- [x] Open
-- [ ] Private
-- [ ] Protected
-
----
-### Types of Access Modifiers
-
-There are four access modifiers in most of the programming languages, they are:
-* **Public**
-* **Private**
-* **Protected**
-* **Default** (if we don't use any of the above three, then its the default one)
-
-So what are these access modifiers? Let's quickly look at them.
-
-**Public access modifier** - A public attribute or method can be accessed by everyone.
-
-**Private access modifiers** - A private attribute or method can be accessed by no one, not even the child class.
-**Explanation** - It can be accessed by the **same** class. No one outside the class has access to private methods.
-
-**Protected access modifier** - A protected attribute or method can be accessed only from the classes of the same package.
-
-Let me show you a diagram that will be helpful in understanding and will clear most of your doubts.
-
-where: -
----
-### Question
-
-Which is the **most restricted** access modifier?
-
-**Choices**
-
-- [ ] Public
-- [ ] Default
-- [x] Private
-- [ ] Protected
-
----
-### Question
-
-Which is the **most open** access modifier?
-
-**Choices**
-
-- [x] Public
-- [ ] Default
-- [ ] Private
-- [ ] Protected
-
----
-### `this` Keyword
-
-Before we see the example of access modifier, let's understand **"this" keyword**:
-* In programming, "this" is a keyword used to refer to the **current instance of a class or object**.
-* It's typically used to distinguish between instance variables and local variables or method parameters with the same names, and to access or modify instance members within methods.
-* This enhances code clarity and prevents naming conflicts in object-oriented languages like Java and C++.
-
-Here is an example:
-```Java
-public class Person {
- private String name;
-
- public Person(String name) {
- this.name = name; // "this" refers to the current instance of the class
- }
-
- public void introduceYourself() {
- System.out.println("Hello, I am " + this.name); // Using "this" to access the instance variable
- }
-
- public static void main(String[] args) {
- Person person1 = new Person("Alice");
- Person person2 = new Person("Bob");
-
- person1.introduceYourself(); // Output: Hello, I am Alice
- person2.introduceYourself(); // Output: Hello, I am Bob
- }
-}
-```
-In this example, the "this" keyword is used to differentiate between the instance variable name and the constructor parameter name, ensuring that the correct value is assigned and accessed within the class methods.
-
----
-### Example of Access Modifiers
-
-```Java
-package mypackage;
-
-public class AccessModifierExample {
- public int publicVariable = 10; // Public access
-
- private int privateVariable = 20; // Private access
-
- protected int protectedVariable = 30; // Protected access
-
- int defaultVariable = 40; // Default (package-private) access
-
- public void publicMethod() {
- System.out.println("This is a public method.");
- }
-
- private void privateMethod() {
- System.out.println("This is a private method.");
- }
-
- public static void main(String[] args) {
- AccessModifierExample example = new AccessModifierExample();
-
- System.out.println("Public variable: " + example.publicVariable);
- System.out.println("Private variable: " + example.privateVariable);
- System.out.println("Protected variable: " + example.protectedVariable);
- System.out.println("Default variable: " + example.defaultVariable);
- }
-}
-```
-```Java
-package otherpackage;
-
-import mypackage.AccessModifierExample; // Import the class from a different package
-
-public class AnotherClass {
- public static void main(String[] args) {
- AccessModifierExample example = new AccessModifierExample();
-
- System.out.println(example.publicVariable); // Accessing publicVariable is valid
- System.out.println(example.defaultVariable); // Error: Cannot access defaultVariable from a different package
-
- example.publicMethod();
- example.privateMethod(); // Error: Private method is not accessible outside the class
- }
-}
-```
-In this example:
-
-The class **AccessModifierExample** has variables and methods with different access modifiers: public, private, protected, and default.
-Access modifiers control the visibility and accessibility of members (variables and methods) outside the class.
-Public members are accessible from anywhere, private members are only accessible within the class, protected members are accessible within the class and its subclasses, and default members are accessible within the same package.
-
-Now, you can try all these on your machine just by creating classes and accessing them.
-
----
-
-### `static` Keyword
-
-The **static** keyword in programming languages like Java and C++ is used to declare **class-level members or methods**, which are associated with the class itself rather than with instances (objects) of the class.
-
-1. **Static Variables (Class Variables):** When you declare a variable as "static" within a class, it becomes a class variable. These variables are shared among all instances of the class. They are initialized only once when the class is loaded, and their values are common to all objects of the class.
-
-2. **Static Methods (Class Methods):** When you declare a method as "static," it becomes a class method. These methods are invoked on the class itself, not on instances of the class. They can access static variables and perform operations that don't require access to instance-specific data.
-
-The **static** keyword is often used for utility methods and constants that are relevant at the class level rather than the instance level. It allows you to access these members without creating an object of the class.
-
-Static variable is created when we load a class.
-
-Here is an example:
-```Java
-public class MyClass {
- // Static variable
- static int staticVar = 0;
-
- // Instance variable
- int instanceVar;
-
- public MyClass(int value) {
- this.instanceVar = value;
- staticVar++;
- }
-
- public static void main(String[] args) {
- MyClass obj1 = new MyClass(10);
- MyClass obj2 = new MyClass(20);
-
- System.out.println("Static Variable: " + staticVar); // Output: Static Variable: 2
- System.out.println("Instance Variable (obj1): " + obj1.instanceVar); // Output: Instance Variable (obj1): 10
- System.out.println("Instance Variable (obj2): " + obj2.instanceVar); // Output: Instance Variable (obj2): 20
- }
-}
-```
-In this example, we have a static variable **staticVar** and an instance variable **instanceVar**. The staticVar is incremented every time an object is created, and we access both static and instance variables directly within the main method.
-
----
-
-### Scope of a variable
-
-Now let's talk about scope of a variable within a program!
-
-In Java, scope refers to the region or context within your code where a specific variable or identifier is accessible and can be used. The scope of a variable is determined by where it is declared, and it influences its visibility and lifetime within the program.
-**There are primarily four types of variable scope in Java:**
-
-1. **Class/Static Scope:** Variables declared as `static` within a class have class-level scope. These variables are associated with the class itself rather than with instances (objects) of the class. They can be accessed using the class name and are shared among all instances of the class.
-
-2. **Instance Scope:** Variables declared within a class but outside any method or constructor have instance scope. These are often referred to as instance variables, and they are associated with specific instances (objects) of the class. Each object has its own copy of these variables.
-
-3. **Method/Local Scope:** Variables declared within a method or a block of code have method or local scope. These variables are only accessible within the specific method or block where they are defined. They go out of scope when the method or block's execution is complete.
-
-4. **Block Scope:** Variables declared within a pair of curly braces `{}` have scope limited to that block. These variables are only accessible within the block in which they are defined.
-
-The scope of a variable is essential for ensuring that the right variables are accessed at the right time and for avoiding naming conflicts. Properly managing variable scope contributes to the clarity and reliability of your code.
-
-Here's a brief example to illustrate variable scope in Java:
-
-```java
-public class ScopeExample {
- // Class-level variable (static scope)
- static int classVar = 10;
-
- // Instance variable (instance scope)
- int instanceVar = 20;
-
- public void exampleMethod() {
- // Method-level variable (method scope)
- int methodVar = 30;
-
- if (true) {
- // Block-level variable (block scope)
- int blockVar = 40;
- System.out.println(classVar + instanceVar + methodVar + blockVar);
- }
- // The 'blockVar' is out of scope here.
- }
-
- public static void main(String[] args) {
- ScopeExample obj = new ScopeExample();
- obj.exampleMethod();
- // The 'methodVar' and 'blockVar' are out of scope here.
- }
-}
-```
-
-In this example, you can see how variables with different scopes are defined and accessed within a Java class.
diff --git a/Academy DSA Typed Notes/Advanced/DSA OOPS 2 Constuctors, Inheritance & Polymorphism.md b/Academy DSA Typed Notes/Advanced/DSA OOPS 2 Constuctors, Inheritance & Polymorphism.md
deleted file mode 100644
index 6b50d85..0000000
--- a/Academy DSA Typed Notes/Advanced/DSA OOPS 2 Constuctors, Inheritance & Polymorphism.md
+++ /dev/null
@@ -1,660 +0,0 @@
-# OOPs 2
-### Constructors
-
-If you remember, we have studied **classes and objects** in the previous lecture, so what is a class and object? Let's have a quick recap of it.
-
-
-**Class:** Blueprint of an entity.
-**Object:** Instance of class
-
-Now let's look at how a class comes into reality.
-
-Let's define a class named Student.
-```java
-Student {
- String name;
- int age;
- doubly psp;
-}
-```
-Now, let's make an object of the Student class.
-```java
-Student st = new Student();
-```
-Now, from the basics of programming, we all know that to declare a variable, we write:
-```java
-int a = 12;
-```
-Let's compare this with object creation:
-```java
-int a = 12;
-Student st = new Student();
-```
-We can see that **Student** is the Data type here and **st** is a variable name, but
-
-
-This thing => **Student();** is called a **constructor**, which creates the object of the class.
-
-This thing, when you don't create a constructor, is called a **default constructor**. Let's discuss it in detail.
-
----
-
-### Default Constructor
-If we don't create our own constructor in a class, a **default constructor** is created.
-
-**Default constructor** creates a new object of the class and sets the value of each attribute as the default value of that type.
-
-Examples of default values of datatype:
-* **0** for integer,
-* **null** for String,
-* **0.0** for float, etc.
-
-> **Note:** A default constructor will assign default values only if we haven't assigned values to class attributes while declaring the variable.
-
-So if we are not creating any constructor, then our class is going to make its own constructor.
-
-A default constructor can be assumed to be present like this:
-```java
-class Student {
- String name;
- int age;
- double psp;
- String univName;
-
- Student() {
- name = null;
- age = 0;
- psp = 0.0;
- univName = null;
- }
-}
-```
-
-
-
----
-### Question
-
-Which is the **most restricted** access modifier?
-
-**Choices**
-
-- [ ] Public
-- [ ] Default
-- [x] Private
-- [ ] Protected
-
----
-### Question
-
-Which is the **most open** access modifier?
-
-**Choices**
-
-- [x] Public
-- [ ] Default
-- [ ] Private
-- [ ] Protected
-
----
-### `this` Keyword
-
-Before we see the example of access modifier, let's understand **"this" keyword**:
-* In programming, "this" is a keyword used to refer to the **current instance of a class or object**.
-* It's typically used to distinguish between instance variables and local variables or method parameters with the same names, and to access or modify instance members within methods.
-* This enhances code clarity and prevents naming conflicts in object-oriented languages like Java and C++.
-
-Here is an example:
-```Java
-public class Person {
- private String name;
-
- public Person(String name) {
- this.name = name; // "this" refers to the current instance of the class
- }
-
- public void introduceYourself() {
- System.out.println("Hello, I am " + this.name); // Using "this" to access the instance variable
- }
-
- public static void main(String[] args) {
- Person person1 = new Person("Alice");
- Person person2 = new Person("Bob");
-
- person1.introduceYourself(); // Output: Hello, I am Alice
- person2.introduceYourself(); // Output: Hello, I am Bob
- }
-}
-```
-In this example, the "this" keyword is used to differentiate between the instance variable name and the constructor parameter name, ensuring that the correct value is assigned and accessed within the class methods.
-
----
-### Example of Access Modifiers
-
-```Java
-package mypackage;
-
-public class AccessModifierExample {
- public int publicVariable = 10; // Public access
-
- private int privateVariable = 20; // Private access
-
- protected int protectedVariable = 30; // Protected access
-
- int defaultVariable = 40; // Default (package-private) access
-
- public void publicMethod() {
- System.out.println("This is a public method.");
- }
-
- private void privateMethod() {
- System.out.println("This is a private method.");
- }
-
- public static void main(String[] args) {
- AccessModifierExample example = new AccessModifierExample();
-
- System.out.println("Public variable: " + example.publicVariable);
- System.out.println("Private variable: " + example.privateVariable);
- System.out.println("Protected variable: " + example.protectedVariable);
- System.out.println("Default variable: " + example.defaultVariable);
- }
-}
-```
-```Java
-package otherpackage;
-
-import mypackage.AccessModifierExample; // Import the class from a different package
-
-public class AnotherClass {
- public static void main(String[] args) {
- AccessModifierExample example = new AccessModifierExample();
-
- System.out.println(example.publicVariable); // Accessing publicVariable is valid
- System.out.println(example.defaultVariable); // Error: Cannot access defaultVariable from a different package
-
- example.publicMethod();
- example.privateMethod(); // Error: Private method is not accessible outside the class
- }
-}
-```
-In this example:
-
-The class **AccessModifierExample** has variables and methods with different access modifiers: public, private, protected, and default.
-Access modifiers control the visibility and accessibility of members (variables and methods) outside the class.
-Public members are accessible from anywhere, private members are only accessible within the class, protected members are accessible within the class and its subclasses, and default members are accessible within the same package.
-
-Now, you can try all these on your machine just by creating classes and accessing them.
-
----
-
-### `static` Keyword
-
-The **static** keyword in programming languages like Java and C++ is used to declare **class-level members or methods**, which are associated with the class itself rather than with instances (objects) of the class.
-
-1. **Static Variables (Class Variables):** When you declare a variable as "static" within a class, it becomes a class variable. These variables are shared among all instances of the class. They are initialized only once when the class is loaded, and their values are common to all objects of the class.
-
-2. **Static Methods (Class Methods):** When you declare a method as "static," it becomes a class method. These methods are invoked on the class itself, not on instances of the class. They can access static variables and perform operations that don't require access to instance-specific data.
-
-The **static** keyword is often used for utility methods and constants that are relevant at the class level rather than the instance level. It allows you to access these members without creating an object of the class.
-
-Static variable is created when we load a class.
-
-Here is an example:
-```Java
-public class MyClass {
- // Static variable
- static int staticVar = 0;
-
- // Instance variable
- int instanceVar;
-
- public MyClass(int value) {
- this.instanceVar = value;
- staticVar++;
- }
-
- public static void main(String[] args) {
- MyClass obj1 = new MyClass(10);
- MyClass obj2 = new MyClass(20);
-
- System.out.println("Static Variable: " + staticVar); // Output: Static Variable: 2
- System.out.println("Instance Variable (obj1): " + obj1.instanceVar); // Output: Instance Variable (obj1): 10
- System.out.println("Instance Variable (obj2): " + obj2.instanceVar); // Output: Instance Variable (obj2): 20
- }
-}
-```
-In this example, we have a static variable **staticVar** and an instance variable **instanceVar**. The staticVar is incremented every time an object is created, and we access both static and instance variables directly within the main method.
-
----
-
-### Scope of a variable
-
-Now let's talk about scope of a variable within a program!
-
-In Java, scope refers to the region or context within your code where a specific variable or identifier is accessible and can be used. The scope of a variable is determined by where it is declared, and it influences its visibility and lifetime within the program.
-**There are primarily four types of variable scope in Java:**
-
-1. **Class/Static Scope:** Variables declared as `static` within a class have class-level scope. These variables are associated with the class itself rather than with instances (objects) of the class. They can be accessed using the class name and are shared among all instances of the class.
-
-2. **Instance Scope:** Variables declared within a class but outside any method or constructor have instance scope. These are often referred to as instance variables, and they are associated with specific instances (objects) of the class. Each object has its own copy of these variables.
-
-3. **Method/Local Scope:** Variables declared within a method or a block of code have method or local scope. These variables are only accessible within the specific method or block where they are defined. They go out of scope when the method or block's execution is complete.
-
-4. **Block Scope:** Variables declared within a pair of curly braces `{}` have scope limited to that block. These variables are only accessible within the block in which they are defined.
-
-The scope of a variable is essential for ensuring that the right variables are accessed at the right time and for avoiding naming conflicts. Properly managing variable scope contributes to the clarity and reliability of your code.
-
-Here's a brief example to illustrate variable scope in Java:
-
-```java
-public class ScopeExample {
- // Class-level variable (static scope)
- static int classVar = 10;
-
- // Instance variable (instance scope)
- int instanceVar = 20;
-
- public void exampleMethod() {
- // Method-level variable (method scope)
- int methodVar = 30;
-
- if (true) {
- // Block-level variable (block scope)
- int blockVar = 40;
- System.out.println(classVar + instanceVar + methodVar + blockVar);
- }
- // The 'blockVar' is out of scope here.
- }
-
- public static void main(String[] args) {
- ScopeExample obj = new ScopeExample();
- obj.exampleMethod();
- // The 'methodVar' and 'blockVar' are out of scope here.
- }
-}
-```
-
-In this example, you can see how variables with different scopes are defined and accessed within a Java class.
diff --git a/Academy DSA Typed Notes/Advanced/DSA OOPS 2 Constuctors, Inheritance & Polymorphism.md b/Academy DSA Typed Notes/Advanced/DSA OOPS 2 Constuctors, Inheritance & Polymorphism.md
deleted file mode 100644
index 6b50d85..0000000
--- a/Academy DSA Typed Notes/Advanced/DSA OOPS 2 Constuctors, Inheritance & Polymorphism.md
+++ /dev/null
@@ -1,660 +0,0 @@
-# OOPs 2
-### Constructors
-
-If you remember, we have studied **classes and objects** in the previous lecture, so what is a class and object? Let's have a quick recap of it.
-
-
-**Class:** Blueprint of an entity.
-**Object:** Instance of class
-
-Now let's look at how a class comes into reality.
-
-Let's define a class named Student.
-```java
-Student {
- String name;
- int age;
- doubly psp;
-}
-```
-Now, let's make an object of the Student class.
-```java
-Student st = new Student();
-```
-Now, from the basics of programming, we all know that to declare a variable, we write:
-```java
-int a = 12;
-```
-Let's compare this with object creation:
-```java
-int a = 12;
-Student st = new Student();
-```
-We can see that **Student** is the Data type here and **st** is a variable name, but
-
-
-This thing => **Student();** is called a **constructor**, which creates the object of the class.
-
-This thing, when you don't create a constructor, is called a **default constructor**. Let's discuss it in detail.
-
----
-
-### Default Constructor
-If we don't create our own constructor in a class, a **default constructor** is created.
-
-**Default constructor** creates a new object of the class and sets the value of each attribute as the default value of that type.
-
-Examples of default values of datatype:
-* **0** for integer,
-* **null** for String,
-* **0.0** for float, etc.
-
-> **Note:** A default constructor will assign default values only if we haven't assigned values to class attributes while declaring the variable.
-
-So if we are not creating any constructor, then our class is going to make its own constructor.
-
-A default constructor can be assumed to be present like this:
-```java
-class Student {
- String name;
- int age;
- double psp;
- String univName;
-
- Student() {
- name = null;
- age = 0;
- psp = 0.0;
- univName = null;
- }
-}
-```
-
- -
-But,
-* By the definition of the default constructor, we know that, **if we create our own constructor** then a default constructor is not created.
-
-So, by looking at Student(), we can say that no parameters are passed here, right?
-So, **the default constructors take no parameters**.
-
-**Summarising** the default constructor:
-1. Takes no parameter.
-2. Sets every attribute of class to it's default value (unless defined).
-3. Created only if we don't write our own constructor.
-4. It's public i.e. can be access from anywhere.
-
----
-
-### Manual Constructor
-Now, let's create our own constructor using the same `Student` class
-
-```java
-public class Student {
- String name;
- private int age = 21;
- String univName;
- double psp;
-
- public Student (String studentName, String universityName) {
- name = studentName;
- univName = universityName;
- }
-}
-```
-Let's create a client class.
-```java
-public class Client {
- public static void main(String[] args) {
- Student st = new Student(); //ERROR
-}
-```
-But here, why its throwing error?
-* Because now there is no default constructor, since we have our own constructor, and it has parameters. So we have to pass the parameters here.
-
-So, let's do like this,
-```java
-public class Client {
-public static void main(String[] args) {
- Student st = new Student("Utkarsh", "JIIT");
-}
-```
-
-
-But,
-* By the definition of the default constructor, we know that, **if we create our own constructor** then a default constructor is not created.
-
-So, by looking at Student(), we can say that no parameters are passed here, right?
-So, **the default constructors take no parameters**.
-
-**Summarising** the default constructor:
-1. Takes no parameter.
-2. Sets every attribute of class to it's default value (unless defined).
-3. Created only if we don't write our own constructor.
-4. It's public i.e. can be access from anywhere.
-
----
-
-### Manual Constructor
-Now, let's create our own constructor using the same `Student` class
-
-```java
-public class Student {
- String name;
- private int age = 21;
- String univName;
- double psp;
-
- public Student (String studentName, String universityName) {
- name = studentName;
- univName = universityName;
- }
-}
-```
-Let's create a client class.
-```java
-public class Client {
- public static void main(String[] args) {
- Student st = new Student(); //ERROR
-}
-```
-But here, why its throwing error?
-* Because now there is no default constructor, since we have our own constructor, and it has parameters. So we have to pass the parameters here.
-
-So, let's do like this,
-```java
-public class Client {
-public static void main(String[] args) {
- Student st = new Student("Utkarsh", "JIIT");
-}
-```
- -
-Now, let's move to the copy constructor and learn more about it.
-
----
-### Copy Constructor
-
-Now, **What is a copy constructor?**
-Let's say we already have an object of student class, and then we want to create a new object of student that has the exact same values of attributes as older objects.
-
-**For example:**
-
-
-Now, let's move to the copy constructor and learn more about it.
-
----
-### Copy Constructor
-
-Now, **What is a copy constructor?**
-Let's say we already have an object of student class, and then we want to create a new object of student that has the exact same values of attributes as older objects.
-
-**For example:**
- -
-If `st1` as an object and we need to create one more object `st2`, with the same attribute values, we can do it with the copy constructor.
-
-```java
-class Student {
- String name;
- int age;
-
- Student() {
- name = null;
- age = 0;
- }
- Student(Student st) {
- name = st.name;
- age = st.age;
- }
-}
-```
-
-So basically, to make a copy, we need to pass it as a parameter to the copy constructor, as the data type is Student.
-```java
-Student st1 = new Student();
-st1.name = "Utkarsh";
-st1.age = 27;
-
-Student st2 = new Student(st1); // Copy Constructor
-```
-
-So now we understand how to write a copy constructor, but what is the use case of the copy constructor?
-
-* The copy constructor comes in use when we have an object, and a newly created object needs the same values, so we don't assign it ourselves. We use the copy constructor the get the work done.
-* Some of the attributes may be private and cannot be accessed by the user, but a copy constructor can access it and make the copy itself.
-
-### Question
-
-Is copy constructor same as doing `Student st2 = st1;`?
-
-**Choices**
-
-- [ ] Yes
-- [ ] In some cases only
-- [x] No
-
-
-Let's see how do things work internally?
-
-
-If `st1` as an object and we need to create one more object `st2`, with the same attribute values, we can do it with the copy constructor.
-
-```java
-class Student {
- String name;
- int age;
-
- Student() {
- name = null;
- age = 0;
- }
- Student(Student st) {
- name = st.name;
- age = st.age;
- }
-}
-```
-
-So basically, to make a copy, we need to pass it as a parameter to the copy constructor, as the data type is Student.
-```java
-Student st1 = new Student();
-st1.name = "Utkarsh";
-st1.age = 27;
-
-Student st2 = new Student(st1); // Copy Constructor
-```
-
-So now we understand how to write a copy constructor, but what is the use case of the copy constructor?
-
-* The copy constructor comes in use when we have an object, and a newly created object needs the same values, so we don't assign it ourselves. We use the copy constructor the get the work done.
-* Some of the attributes may be private and cannot be accessed by the user, but a copy constructor can access it and make the copy itself.
-
-### Question
-
-Is copy constructor same as doing `Student st2 = st1;`?
-
-**Choices**
-
-- [ ] Yes
-- [ ] In some cases only
-- [x] No
-
-
-Let's see how do things work internally?
- -
-* So we have a memory, and st1 is present in the memory with all the data, as shown in the above diagram.
-* When we write student `st2 = st1`, we just make st2 to point as s1, i.e., **a new object is not created**.
-* Now the problem here is if we do changes in st2, i.e. `st2.name = 'xyz'`, it will change the value of st1.
-
-
-Now if we create the object using copy constructor then it has a different address. So it's not pointing in the memory, as we have seen in the example above.
-
----
-### Deep and Shallow copy
-
-### Shallow copy
-
-* When we have created a new object, but behind the scenes, the new object still refer to attributes of the old object. i.e., the new object still refers to the same data as the old copy.
-
-```python
-original_books = ["Book A", "Book B"]
-shallow_copy_books = original_books
-
-shallow_copy_books.append("Book C")
-
-print(original_books) # Output: ["Book A", "Book B", "Book C"]
-```
-
-### Deep copy
-
-* When we have created a new object behind the scenes, the new object do not refer to attributes of the old object. i.e., the new object has no shared data.
-
-```python
-import copy
-
-original_books = ["Book A", "Book B"]
-deep_copy_books = copy.deepcopy(original_books)
-
-deep_copy_books.append("Book C")
-
-print(original_books) # Output: ["Book A", "Book B"]
-```
-
----
-### Inheritance
-
-
-
-**How is inheritance represented?**
-**Ans** - Inheritance is represented as parent-child relations between different classes.
-
-Now, let's talk about the scaler's hierarchy of representation.
-
-
-
-* So we have a memory, and st1 is present in the memory with all the data, as shown in the above diagram.
-* When we write student `st2 = st1`, we just make st2 to point as s1, i.e., **a new object is not created**.
-* Now the problem here is if we do changes in st2, i.e. `st2.name = 'xyz'`, it will change the value of st1.
-
-
-Now if we create the object using copy constructor then it has a different address. So it's not pointing in the memory, as we have seen in the example above.
-
----
-### Deep and Shallow copy
-
-### Shallow copy
-
-* When we have created a new object, but behind the scenes, the new object still refer to attributes of the old object. i.e., the new object still refers to the same data as the old copy.
-
-```python
-original_books = ["Book A", "Book B"]
-shallow_copy_books = original_books
-
-shallow_copy_books.append("Book C")
-
-print(original_books) # Output: ["Book A", "Book B", "Book C"]
-```
-
-### Deep copy
-
-* When we have created a new object behind the scenes, the new object do not refer to attributes of the old object. i.e., the new object has no shared data.
-
-```python
-import copy
-
-original_books = ["Book A", "Book B"]
-deep_copy_books = copy.deepcopy(original_books)
-
-deep_copy_books.append("Book C")
-
-print(original_books) # Output: ["Book A", "Book B"]
-```
-
----
-### Inheritance
-
-
-
-**How is inheritance represented?**
-**Ans** - Inheritance is represented as parent-child relations between different classes.
-
-Now, let's talk about the scaler's hierarchy of representation.
-
- -
-Now, Let's say User has the following attributes:
-* Username
-* Login
-
-
-So, We can say that:
-* Instructor
-* Mentor
-* TA
-* Student
-
-They all are **specific types** of users i.e. they will share all the members / attributes / methods of **User** and may have some more of their own.
-
-A **child class / subclass** can have specific attributes / behaviors which may not be present in the **parent class / superclass**.
-
->Consider the below diagram for explaining child / subclass & parent / superclass terms more clearly.
-
-
-Now, Let's say User has the following attributes:
-* Username
-* Login
-
-
-So, We can say that:
-* Instructor
-* Mentor
-* TA
-* Student
-
-They all are **specific types** of users i.e. they will share all the members / attributes / methods of **User** and may have some more of their own.
-
-A **child class / subclass** can have specific attributes / behaviors which may not be present in the **parent class / superclass**.
-
->Consider the below diagram for explaining child / subclass & parent / superclass terms more clearly.
- -
-So we can **conclude**: A child class inherits all the members of the parent class and may or may not add their own members.
-
----
-
-### Parent-Child Relationship in Code
-
-How can we represent a parent-child relationship in code? Let's say we need to make a relationship between the User and the Instructor.
-
-
-To build this, Let's say we have a **Parent class called User**, as shown below:
-```java
-class User {
- String userName;
-
- void login() {
- ...
- }
-}
-```
-**Instructor** is a child/subclass of User, so how can we do that?
-```java
-Class Instructor extends User.
-```
-So here `extends` is the **keyword in Java** that is used to create a child class.
-
-The `extend` keyword is specific to Java and is used to create a subclass that inherits properties and behaviors from a superclass.
-
-While the keyword itself may vary in other programming languages, the concept is similar. Here are a few examples from different languages:
-
-- **In Python:** The inheritance is indicated using **parentheses**.
-For example: `class Subclass(SuperClass):`
-
-- **In C++:** The inheritance is specified using a **colon**.
-For example: `class Subclass : public SuperClass { };`
-
-- **In C#:** The inheritance is specified using a **colon**.
-For example: `class Subclass : BaseClass { }`
-
-So, while the specific syntax and keywords may differ, the concept of class extension or inheritance is present in various object-oriented programming languages.
-
-The instructor class has the following methods:
-```java
-class Instructor extends User {
- String batchName;
- double avgRating;
-
- void scheduleClass() {
- ...
- }
-}
-```
-
-* Does the Instructor class needs a username property?
- * Yes
-* Do we need to code it?
- * No
-* So, how can we use it?
- * We are extending it from the User class.
-
-Extends means, **keeping the original things and adding more things to it**.
-
----
-### Constructor Chaining
-
-
-How do we create an object of any class?
-```java
-Instructor i = new Instructor();
-```
-* Did we ever created `Instructor()` constructor?
- * No, Right?
-
-* So, how it came into the picture?
- * Yes, It is a Default Constructor.
-This constructor initializes to default values of all the attributes, so can we do like:
-```java
-i.username = "Utkarsh";
-i.login();
-```
-Yes, because it's coming from the `User` class.
-
-Can we also do:
-```java
-i.avgRating = 4
-```
-Yes, because it's part of the Instructor's class.
-
-**Note:** In Inheritance, a parent class is nothing but generalization, and every child is a specification.
-
-Now, assume we are given this relation:
-
-
-So we can **conclude**: A child class inherits all the members of the parent class and may or may not add their own members.
-
----
-
-### Parent-Child Relationship in Code
-
-How can we represent a parent-child relationship in code? Let's say we need to make a relationship between the User and the Instructor.
-
-
-To build this, Let's say we have a **Parent class called User**, as shown below:
-```java
-class User {
- String userName;
-
- void login() {
- ...
- }
-}
-```
-**Instructor** is a child/subclass of User, so how can we do that?
-```java
-Class Instructor extends User.
-```
-So here `extends` is the **keyword in Java** that is used to create a child class.
-
-The `extend` keyword is specific to Java and is used to create a subclass that inherits properties and behaviors from a superclass.
-
-While the keyword itself may vary in other programming languages, the concept is similar. Here are a few examples from different languages:
-
-- **In Python:** The inheritance is indicated using **parentheses**.
-For example: `class Subclass(SuperClass):`
-
-- **In C++:** The inheritance is specified using a **colon**.
-For example: `class Subclass : public SuperClass { };`
-
-- **In C#:** The inheritance is specified using a **colon**.
-For example: `class Subclass : BaseClass { }`
-
-So, while the specific syntax and keywords may differ, the concept of class extension or inheritance is present in various object-oriented programming languages.
-
-The instructor class has the following methods:
-```java
-class Instructor extends User {
- String batchName;
- double avgRating;
-
- void scheduleClass() {
- ...
- }
-}
-```
-
-* Does the Instructor class needs a username property?
- * Yes
-* Do we need to code it?
- * No
-* So, how can we use it?
- * We are extending it from the User class.
-
-Extends means, **keeping the original things and adding more things to it**.
-
----
-### Constructor Chaining
-
-
-How do we create an object of any class?
-```java
-Instructor i = new Instructor();
-```
-* Did we ever created `Instructor()` constructor?
- * No, Right?
-
-* So, how it came into the picture?
- * Yes, It is a Default Constructor.
-This constructor initializes to default values of all the attributes, so can we do like:
-```java
-i.username = "Utkarsh";
-i.login();
-```
-Yes, because it's coming from the `User` class.
-
-Can we also do:
-```java
-i.avgRating = 4
-```
-Yes, because it's part of the Instructor's class.
-
-**Note:** In Inheritance, a parent class is nothing but generalization, and every child is a specification.
-
-Now, assume we are given this relation:
- -
----
-### Question
-
-Which of these classes has the highest level of abstraction?
-
-**Choices**
-
-- [x] A
-- [ ] B
-- [ ] C
-- [ ] D
-
-
-First of all, what is abstraction?
-- It's an idea.
-
-So, what does the highest level of abstraction mean?
-- A bigger idea that means a more general idea.
-
-So out of them, **A** is the most generic class, right?
-That's why **A has the highest level of abstraction.**
-
----
-### Question
-
-Do the child class contains all the attributes of parent class?
-
-**Choices**
-
-- [x] Yes
-- [ ] No
-- [ ] Can't say
-
-
-Definitely, **Yes**.
-Example is Animal :arrow_right: Dog
-
-So now the question is, how are they initialized? Who initializes them?
-
-Let's see what happens behind the scenes:
-
-* Let's say we have a User class as shown below:
-
-
----
-### Question
-
-Which of these classes has the highest level of abstraction?
-
-**Choices**
-
-- [x] A
-- [ ] B
-- [ ] C
-- [ ] D
-
-
-First of all, what is abstraction?
-- It's an idea.
-
-So, what does the highest level of abstraction mean?
-- A bigger idea that means a more general idea.
-
-So out of them, **A** is the most generic class, right?
-That's why **A has the highest level of abstraction.**
-
----
-### Question
-
-Do the child class contains all the attributes of parent class?
-
-**Choices**
-
-- [x] Yes
-- [ ] No
-- [ ] Can't say
-
-
-Definitely, **Yes**.
-Example is Animal :arrow_right: Dog
-
-So now the question is, how are they initialized? Who initializes them?
-
-Let's see what happens behind the scenes:
-
-* Let's say we have a User class as shown below:
-  -And we create a `User` object:
- **`User user = new User();`**
-
-So,
-How will the attributes get initialized?
-**Ans** - Since we haven't created our constructor, our attributes get assigned to null values by default constructor, as shown below.
- *
-And we create a `User` object:
- **`User user = new User();`**
-
-So,
-How will the attributes get initialized?
-**Ans** - Since we haven't created our constructor, our attributes get assigned to null values by default constructor, as shown below.
- *  -
-* Or we may create our own constructor:
-
-
-* Or we may create our own constructor:
- -
-
-Now, If we create a child class / sub-class named instructor:
-
-
-
-Now, If we create a child class / sub-class named instructor:
- -
-**Now the question is:** When we create an instructor, someone has to initialize the attribute that came from the parent.
-
-There are scenarios now:
-1. We know how to initialize, and we understand how to change, so **we will initialize** the values to those attributes, like this:
-
-
-**Now the question is:** When we create an instructor, someone has to initialize the attribute that came from the parent.
-
-There are scenarios now:
-1. We know how to initialize, and we understand how to change, so **we will initialize** the values to those attributes, like this:
- -
-But DO YOU THINK we will always Know how to initialize the attributes?
-Ans - **No!** But there is someone who'll always know how and what to initialize.
-
-2. A **constructor of the parent** definitely knows how and what to initialize the attributes. Let's understand How it's done!
-
----
-### Steps to Create an Object of Child
-
-**(Assuiming no constructor is created, its only default constructors are present)**
-
-Suppose we have a class named **A**.
-
-
-But DO YOU THINK we will always Know how to initialize the attributes?
-Ans - **No!** But there is someone who'll always know how and what to initialize.
-
-2. A **constructor of the parent** definitely knows how and what to initialize the attributes. Let's understand How it's done!
-
----
-### Steps to Create an Object of Child
-
-**(Assuiming no constructor is created, its only default constructors are present)**
-
-Suppose we have a class named **A**.
- -
-Now `B` is a child of `A`,
-`C` is a child of `B`, and
-`D` is a child of `C.`
-
-Suppose we create an object of **D**:
-```java
-D d = new D();
-```
-
-So, **What really happens when we call `D()`?**
-1. Constructor of D will be called.
-2. Since D is also a child of someone, so before its execution, it will call the constructor of C.
-3. Similarly, C will call the constructor of B first.
-4. And B will call the constructor of A before it's execution.
-
-So, **Who's constructor will be finished first?**
-- **A**'s constructor will be finished first, then **B** will be finished, then **C** will be finished, then **D** will be finished.
-
-Because,
-* **Can a child be born before its parents are born?**
-**No**, right?
- * That's why the parent class constructor will be called first. We haven't specifically called the parents constructor but by default, the parent constructor is called.
-
-**Note:**
-
-
-Now `B` is a child of `A`,
-`C` is a child of `B`, and
-`D` is a child of `C.`
-
-Suppose we create an object of **D**:
-```java
-D d = new D();
-```
-
-So, **What really happens when we call `D()`?**
-1. Constructor of D will be called.
-2. Since D is also a child of someone, so before its execution, it will call the constructor of C.
-3. Similarly, C will call the constructor of B first.
-4. And B will call the constructor of A before it's execution.
-
-So, **Who's constructor will be finished first?**
-- **A**'s constructor will be finished first, then **B** will be finished, then **C** will be finished, then **D** will be finished.
-
-Because,
-* **Can a child be born before its parents are born?**
-**No**, right?
- * That's why the parent class constructor will be called first. We haven't specifically called the parents constructor but by default, the parent constructor is called.
-
-**Note:**
- -
-What will happen if we add a parameterized constructor in class **C** as shown below:
-```java
-public class C extends B {
- C() {
- System.out.println("Constructor of C");
- }
- C(String a) {
- System.out.println("Constructor of C with params");
- }
-}
-```
-What will be the output if we run the code now?
-The output will still be the same right, i.e., `Default Constructor of C` will be printed with all other constructors from A, B & D.
-
-But, What if we want to **print the manual constructor** of class C?
-
-To make this happen, we need to make changes in our **D** class.
-We have to add the **super** function in the first line of our constructor.
-
-```java
-public class D extends C {
- D() {
- super ("Hello"); // This must be the first line
- System.out.println("Constructor of D");
- }
-}
-```
-The **super("Hello");** will make the parametrized constructor from Class C become active.
-
-**Note:** This super() line in the code must be written in the **first line inside a constructor**. Otherwise, it throws an error.
-
----
-## Polymorphism
-
-What really is polymorphism?
-
-There's a very famous explanation of Polymorphism i.e. **Poly means Many** and **Morphism means Form**.
-
-Which means, someone who has multiple forms.
-
-So, till now, in today's class, have you learned about something which had multiple forms?
-**Ans** - Yes, a user could have multiple forms. Because a user can be a student, instructor, TA, etc.
-
-So this can be an example of multiple forms.
-
-**Another example** - Suppose we have a list of Animals. Animals have Mammals, Reptiles, Aquatic, etc. classifications.
-
-**Can we write:**
-`Animal a = new Dog();`
-Yes, because this is an **object of type Dog**, which is a Mammal and which is an Animal. So we can write it!
-
-**But, Can we write:**
-`Dog d = new Animal();`
-No, this is **not allowed** since every Dog is an Animal, but every Animal must not be a Dog.
-
-**That means: We can put an object of the child class in a variable that takes parent data type.**
-
-**Suppose we have three classes, A, B, and C.** as shown below:
-
-
-What will happen if we add a parameterized constructor in class **C** as shown below:
-```java
-public class C extends B {
- C() {
- System.out.println("Constructor of C");
- }
- C(String a) {
- System.out.println("Constructor of C with params");
- }
-}
-```
-What will be the output if we run the code now?
-The output will still be the same right, i.e., `Default Constructor of C` will be printed with all other constructors from A, B & D.
-
-But, What if we want to **print the manual constructor** of class C?
-
-To make this happen, we need to make changes in our **D** class.
-We have to add the **super** function in the first line of our constructor.
-
-```java
-public class D extends C {
- D() {
- super ("Hello"); // This must be the first line
- System.out.println("Constructor of D");
- }
-}
-```
-The **super("Hello");** will make the parametrized constructor from Class C become active.
-
-**Note:** This super() line in the code must be written in the **first line inside a constructor**. Otherwise, it throws an error.
-
----
-## Polymorphism
-
-What really is polymorphism?
-
-There's a very famous explanation of Polymorphism i.e. **Poly means Many** and **Morphism means Form**.
-
-Which means, someone who has multiple forms.
-
-So, till now, in today's class, have you learned about something which had multiple forms?
-**Ans** - Yes, a user could have multiple forms. Because a user can be a student, instructor, TA, etc.
-
-So this can be an example of multiple forms.
-
-**Another example** - Suppose we have a list of Animals. Animals have Mammals, Reptiles, Aquatic, etc. classifications.
-
-**Can we write:**
-`Animal a = new Dog();`
-Yes, because this is an **object of type Dog**, which is a Mammal and which is an Animal. So we can write it!
-
-**But, Can we write:**
-`Dog d = new Animal();`
-No, this is **not allowed** since every Dog is an Animal, but every Animal must not be a Dog.
-
-**That means: We can put an object of the child class in a variable that takes parent data type.**
-
-**Suppose we have three classes, A, B, and C.** as shown below:
- -
-Now if we write:
-```java
-A a = new C();
-a.company = "ABC";
-```
-This will **throw an error** because **a** has a datatype of **A**, but A doesn't have any variable named company.
-
-* Compiler only allows you access to members of the data type of the variable.
-
-Now, suppose you have a method called:
-**changePassword()**
-
-* Is this change password method need a Student / TA / Instructor, OR just a user?
- * Just a User, right?
-Because it doesn't matter which type of user is asking for a changepassword.
-
-=> **The more generic your code is, the better the reusability will be.**
-This is one of the use cases of Polymorphism.
-
-There are **two types of polymorphism**:
-1. Compile Time Polyphormism
-2. RunTime Polymorphism
-
-Now we have seen that one way of having many forms is **Inheritance**. The other is called **Method overloading**.
-
----
-
-### Method Overloading
-
-
-Now if we write:
-```java
-A a = new C();
-a.company = "ABC";
-```
-This will **throw an error** because **a** has a datatype of **A**, but A doesn't have any variable named company.
-
-* Compiler only allows you access to members of the data type of the variable.
-
-Now, suppose you have a method called:
-**changePassword()**
-
-* Is this change password method need a Student / TA / Instructor, OR just a user?
- * Just a User, right?
-Because it doesn't matter which type of user is asking for a changepassword.
-
-=> **The more generic your code is, the better the reusability will be.**
-This is one of the use cases of Polymorphism.
-
-There are **two types of polymorphism**:
-1. Compile Time Polyphormism
-2. RunTime Polymorphism
-
-Now we have seen that one way of having many forms is **Inheritance**. The other is called **Method overloading**.
-
----
-
-### Method Overloading
- -
-Suppose we have a class **A**, and it has a method named `hello()`.
-
-* Can a class have another method with the same name but having different parameters?
- * Yes, this second method `hello(String Name)` is having same name.
-
-Now, this is called **Method overloading**.
-
-Here also, can you identify **Polymorphism**?
-**Ans** - The same method name has many forms.
-
-So, If we write:
-```java
-hello();
-hello(name);
-```
-Does the compiler knows which method to call? In each of the statements?
-* Yes, It knows. So it will be the respective parameters which matches the method definition.
-
-:arrow_right: As here, the final form that will execute is known to the *Compiler*. That's why it is known as **Compile time Polymorphism**.
-
-Which of the following is a method overloading, and which of them is not?
-*
-
-Suppose we have a class **A**, and it has a method named `hello()`.
-
-* Can a class have another method with the same name but having different parameters?
- * Yes, this second method `hello(String Name)` is having same name.
-
-Now, this is called **Method overloading**.
-
-Here also, can you identify **Polymorphism**?
-**Ans** - The same method name has many forms.
-
-So, If we write:
-```java
-hello();
-hello(name);
-```
-Does the compiler knows which method to call? In each of the statements?
-* Yes, It knows. So it will be the respective parameters which matches the method definition.
-
-:arrow_right: As here, the final form that will execute is known to the *Compiler*. That's why it is known as **Compile time Polymorphism**.
-
-Which of the following is a method overloading, and which of them is not?
-*  -Yes, the first 2 are method overloading, but the last one is not method overloading.
-
-
-:arrow_right: So there is something called a **Method Signature**.
-A method signature is: **`Name of method (Data type of Params)`**
-
-Example: If we have a method:
-`void printHello(String Name, int age)`
-
-* Method signature for this method will be:
- `printHello(String, int)`
-
-**Methods are known to be overloaded when they have the same name but different signatures.**
-
----
-### Question
-
-Is this allowed in the same class?
-```
-void printHello(String s) {...}
-
-String printHello(String s) {...}
-```
-
-**Choices**
-
-- [ ] Yes
-- [x] No
-- [ ] Can't say
-
-
-Since the method signature of both the functions is same, the compiler will not be able to distinguish between the functions and hence will give **compile time error**.
-
----
-### Method overriding
-
-Suppose we have a class **A**,
-```java
-Class A {
- void doSomething(String a) {
- ...
- }
-}
-```
-And we have another class **B** which inherits from **A**, and this class also had a method named `doSometihng`,
-```java
-Class B extends A {
- String doSomething(String c) {
- ...
- }
-}
-```
-So, Is this allowed?
-**Ans** - No,
-Since all the methods of the parent class are present in the child class, like:
-```java
-Class B extends A {
- String doSomething(String c) {
- ...
- }
- // Parent method inherited
- void doSomething(String a) {
- ...
- }
-}
-```
-And, in the child class, we are having 2 methods with the same signature which it's not allowed. It's going to give us a **Compile time error**.
-
-
-Now let's see another scenario of the same classes. But here, the **return type of both methods is going to be the same**.
-
-Suppose we have a class **A**,
-```java
-Class A {
- void doSomething(String a) {
- ...
- }
-}
-```
-And we have another class **B** which inherits from **A**, and this class also had a method named `doSometihng`, like:
-```java
-Class B extends A {
- void doSomething(String c) {
- ...
- }
-}
-```
-
-If parent and child classes have the same method with the same name and same return type, and the same signature, this is called **Method overriding.**
-In Method overriding, the Parent class methods get hidden.
-
-Let's say we have two classes, as shown below:
-
-Yes, the first 2 are method overloading, but the last one is not method overloading.
-
-
-:arrow_right: So there is something called a **Method Signature**.
-A method signature is: **`Name of method (Data type of Params)`**
-
-Example: If we have a method:
-`void printHello(String Name, int age)`
-
-* Method signature for this method will be:
- `printHello(String, int)`
-
-**Methods are known to be overloaded when they have the same name but different signatures.**
-
----
-### Question
-
-Is this allowed in the same class?
-```
-void printHello(String s) {...}
-
-String printHello(String s) {...}
-```
-
-**Choices**
-
-- [ ] Yes
-- [x] No
-- [ ] Can't say
-
-
-Since the method signature of both the functions is same, the compiler will not be able to distinguish between the functions and hence will give **compile time error**.
-
----
-### Method overriding
-
-Suppose we have a class **A**,
-```java
-Class A {
- void doSomething(String a) {
- ...
- }
-}
-```
-And we have another class **B** which inherits from **A**, and this class also had a method named `doSometihng`,
-```java
-Class B extends A {
- String doSomething(String c) {
- ...
- }
-}
-```
-So, Is this allowed?
-**Ans** - No,
-Since all the methods of the parent class are present in the child class, like:
-```java
-Class B extends A {
- String doSomething(String c) {
- ...
- }
- // Parent method inherited
- void doSomething(String a) {
- ...
- }
-}
-```
-And, in the child class, we are having 2 methods with the same signature which it's not allowed. It's going to give us a **Compile time error**.
-
-
-Now let's see another scenario of the same classes. But here, the **return type of both methods is going to be the same**.
-
-Suppose we have a class **A**,
-```java
-Class A {
- void doSomething(String a) {
- ...
- }
-}
-```
-And we have another class **B** which inherits from **A**, and this class also had a method named `doSometihng`, like:
-```java
-Class B extends A {
- void doSomething(String c) {
- ...
- }
-}
-```
-
-If parent and child classes have the same method with the same name and same return type, and the same signature, this is called **Method overriding.**
-In Method overriding, the Parent class methods get hidden.
-
-Let's say we have two classes, as shown below:
- -
-And in the **Main()** method we run the following:
-
-
-And in the **Main()** method we run the following:
- -So we can see that at first, we have `Hello` as output, and in the last statement, we get `Bye` as output.
-
-Now there are some points that you have to understand:
-
-* The method that is executed is of the data type that is **actually** present at the time of code and **not the type of variable**.
-* Do we know the exact code that is about to run in compile time?
- * No, and that's why it's called **RunTime polymorphism**
-
-=> ***Compiler relies on the data type of variable, whereas runtime relies on the actual object.***
diff --git a/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md b/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md
index c88a699..63b978d 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md
@@ -1,8 +1,19 @@
# Queues: Implementation & Problems
+
+## Agenda
+**Topics to cover in DSA(Queue):**
+
+* Queue
+* Implementation of the queue using array
+* Implementation of the queue using stack
+* Perfect Number Question
+* Doubly ended queue
+* Sliding Window Maximum
+
---
-## Queue
+## Queue
A queue represents a linear data structure where items are added at one end and removed from the other end. It follows the "First-In-First-Out" (FIFO) principle, meaning that the item that has been inserted first in queue will be the first one to be removed. To illustrate this concept, let's use a ticket counter as an example.
**Example: Ticket Counter Queue**
@@ -20,33 +31,33 @@ Common operations in a queue include:
4. **IsEmpty**:
-So we can see that at first, we have `Hello` as output, and in the last statement, we get `Bye` as output.
-
-Now there are some points that you have to understand:
-
-* The method that is executed is of the data type that is **actually** present at the time of code and **not the type of variable**.
-* Do we know the exact code that is about to run in compile time?
- * No, and that's why it's called **RunTime polymorphism**
-
-=> ***Compiler relies on the data type of variable, whereas runtime relies on the actual object.***
diff --git a/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md b/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md
index c88a699..63b978d 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Queues Implementation & Problems.md
@@ -1,8 +1,19 @@
# Queues: Implementation & Problems
+
+## Agenda
+**Topics to cover in DSA(Queue):**
+
+* Queue
+* Implementation of the queue using array
+* Implementation of the queue using stack
+* Perfect Number Question
+* Doubly ended queue
+* Sliding Window Maximum
+
---
-## Queue
+## Queue
A queue represents a linear data structure where items are added at one end and removed from the other end. It follows the "First-In-First-Out" (FIFO) principle, meaning that the item that has been inserted first in queue will be the first one to be removed. To illustrate this concept, let's use a ticket counter as an example.
**Example: Ticket Counter Queue**
@@ -20,33 +31,33 @@ Common operations in a queue include:
4. **IsEmpty**:This operation checks if the queue is empty. If it's empty, it means there are no elements in the queue. 5. **Size or Length**:
This operation returns the number of elements currently in the queue. It provides the count of items in the queue. + **Q. Can a stack or queue have a limit of elements it can have, and then we can use isFull()?** **Sol.** Yes, both stacks and queues can have a limit on the number of elements they can hold, and you can use an "isFull()" method to check if they have reached their capacity. This concept is commonly referred to as a "bounded" stack or queue. --- - Implementaion of queue -description: Discussion about the various concepts related to implementaion of queue in detail. -duration: 2100 -card_type: cue_card ---- +## Implementaion of queue + ### Implementaion of Queue Here's how you can implement a queue using a dynamic array along with pseudocode for the `enqueue`, `dequeue`, and `isEmpty` operations: -```sql Queue using Dynamic Array: - Initialize an empty dynamic array (e.g., ArrayList or Python list) to store the elements. - Initialize two pointers: 'front' and 'rear'. Initially, both are set to -1. -Pseudocode for Enqueue (Add an element to the rear of the queue): + +### enqueue() +```java enqueue(element): if rear is -1: - # Empty queue, set both front and rear to 0 + //Queue is empty set front and rear to 0 + else if rear is at the end of the array: - # Check if there is space for expansion + //Check if there is space for expansion if front > 0: # Move elements to the beginning of the array for i from front to rear: @@ -55,7 +66,9 @@ enqueue(element): set front to 0 else: # If no space, resize the array by creating a new larger array - new_size = current_array_size * 2 # You can choose your resizing strategy + # You can choose your resizing strategy + new_size = current_array_size * 2 + create a new array of size new_size copy elements from the current array to the new array set array to new_array @@ -66,7 +79,10 @@ enqueue(element): array[rear] = element increment rear by 1 -Pseudocode for Dequeue (Remove an element from the front of the queue): +``` + +### dequeue() +```javascript dequeue(): if front is -1: # Empty queue, nothing to dequeue @@ -78,8 +94,11 @@ dequeue(): # Reset front and rear to -1 if the queue is empty set front and rear to -1 return element +``` + -Pseudocode for isEmpty (Check if the queue is empty): +### isEmpty() +```javascript isEmpty(): if front is -1: return true @@ -117,19 +136,20 @@ Queue functionality can be achieved by using two of the methods mentioned: --- + + ### Question What will be the state of the queue after these operations enqueue(3), enqueue(7), enqueue(12), dqueue(), dqueue(), enqueue(8), enqueue(3) -**Choices** +### Choices - [x] 12, 8, 3 - [ ] 3, 7, 12, 8 - [ ] 3, 8, 3 - [ ] 7, 12, 3 - -**Explanation** +### Explanation Let's break down the sequence of queue operations: @@ -144,22 +164,24 @@ enqueue(3) : Queue becomes [12, 8, 3] So, after these operations, the final state of the queue is [12, 8, 3] + + --- + + ### Question What will be the state of the queue after these operations enqueue(4), dqueue(), enqueue(9), enqueue(3), enqueue(7), enqueue(11), enqueue(20), dqueue() -**Choices** +### Choices - [ ] 4, 9, 3, 7 - [x] 3, 7, 11, 20 - [ ] 9, 3, 7, 11 - [ ] 3, 7, 20 - - -**Explanation** +### Explanation Let's go through the sequence of queue operations: enqueue(4): Queue becomes [4] @@ -174,173 +196,115 @@ dequeue(): Removes the element from the front, and the queue becomes [3, 7, 11, So, after these operations, the final state of the queue is [3, 7, 11, 20] - --- -### Implementaion of queue using Stack +## Problem 1 Implementaion of queue using Stack -The explaination for implementing a queue using two stacks step by step: -```cpp -class QueueUsingTwoStacks { -private: - std::stack
 -```cpp
- bool isEmpty() {
- return stack1.empty() && stack2.empty();
- }
-};
-```
+Now, From the data, It is an Dequeue operation, So we need to remove the front element which appears at the bottom of the stack.
-The `isEmpty` method checks whether the queue is empty. It returns `true` if both `stack1` and `stack2` are empty, indicating that there are no elements in the queue.
+How to remove that ?
-In the `main` function, we create an instance of `QueueUsingTwoStacks`, perform enqueue and dequeue operations, and check if the queue is empty. The example code demonstrates the usage of this queue implementation.
+Since we cant remove the element, at the bottom.
+- Lets have another stack and push all the elements of Stack1 to Stack2.
+- Then pop the top element of Stack2.
+- Then Push all the elements of Stack2 to Stack1.
+
-```cpp
- bool isEmpty() {
- return stack1.empty() && stack2.empty();
- }
-};
-```
+Now, From the data, It is an Dequeue operation, So we need to remove the front element which appears at the bottom of the stack.
-The `isEmpty` method checks whether the queue is empty. It returns `true` if both `stack1` and `stack2` are empty, indicating that there are no elements in the queue.
+How to remove that ?
-In the `main` function, we create an instance of `QueueUsingTwoStacks`, perform enqueue and dequeue operations, and check if the queue is empty. The example code demonstrates the usage of this queue implementation.
+Since we cant remove the element, at the bottom.
+- Lets have another stack and push all the elements of Stack1 to Stack2.
+- Then pop the top element of Stack2.
+- Then Push all the elements of Stack2 to Stack1.
+ ----
-### Problem 1 Nth perfect number
+### Idea 1 - Approach
-Write a function `findNthPerfectNumber(N)` that takes an integer N as input and returns the Nth perfect number formed by the only digits 1 and 2.
+For Enqueue: -> O(1)
+* Push x in Stack1
-**Input:**
-- An integer $N (1 <= N <= 1000)$, representing the position of the desired perfect number.
+For Dequeue: -> O(N)
+* Transfer all the elements from Stack1 -> Stack2
+* Remove top element of Stack2
+* Transfer all the elements from Stack2 -> Stack1
-**Output:**
-- Return the Nth perfect number formed using only digits 1 and 2.
-**Example:**
+### Idea 2 - DryRun
-
----
-### Problem 1 Nth perfect number
+### Idea 1 - Approach
-Write a function `findNthPerfectNumber(N)` that takes an integer N as input and returns the Nth perfect number formed by the only digits 1 and 2.
+For Enqueue: -> O(1)
+* Push x in Stack1
-**Input:**
-- An integer $N (1 <= N <= 1000)$, representing the position of the desired perfect number.
+For Dequeue: -> O(N)
+* Transfer all the elements from Stack1 -> Stack2
+* Remove top element of Stack2
+* Transfer all the elements from Stack2 -> Stack1
-**Output:**
-- Return the Nth perfect number formed using only digits 1 and 2.
-**Example:**
+### Idea 2 - DryRun
- +Consider the below data,
-**Question Explanation**
+`[5 4 7 9 Dequeue 8 10 Dequeue Dequeue 14 Dequeue Dequeue 21]`
-
+Consider the below data,
-**Question Explanation**
+`[5 4 7 9 Dequeue 8 10 Dequeue Dequeue 14 Dequeue Dequeue 21]`
- +Enqueue 5, 4, 7 and 9 one by one into Stack1
-
+Enqueue 5, 4, 7 and 9 one by one into Stack1
- +
+ -* As we can see in above example, we have to insert 1 and 2 in the queue.
-* The next numbers can be made using the previous digits by appending the combination of 1 and 2.
-* Like to get 11 we append 1 after 1, to get 12 we append 2 after 1.
-* Similarly, we can generate numbers 21 by appending 1 after 2, and to get the 22, we can append 2 to 2 and so on.
-* As we have to append and remove digits frequently so queue can help us here.
+Now Its an **Dequeue** operation.
----
-### Question
-What is the **5th** perfect number formed by the only digits 1 and 2.
+We will do the same process like before, except the last.
-**Choices**
-- [ ] 11111
-- [ ] 22222
-- [x] 21
-- [ ] 12
+- Push all the elements of Stack1 to Stack2.
+- Then pop the top element of Stack2.
+Now we haven't copied to the Stack 1
+
-* As we can see in above example, we have to insert 1 and 2 in the queue.
-* The next numbers can be made using the previous digits by appending the combination of 1 and 2.
-* Like to get 11 we append 1 after 1, to get 12 we append 2 after 1.
-* Similarly, we can generate numbers 21 by appending 1 after 2, and to get the 22, we can append 2 to 2 and so on.
-* As we have to append and remove digits frequently so queue can help us here.
+Now Its an **Dequeue** operation.
----
-### Question
-What is the **5th** perfect number formed by the only digits 1 and 2.
+We will do the same process like before, except the last.
-**Choices**
-- [ ] 11111
-- [ ] 22222
-- [x] 21
-- [ ] 12
+- Push all the elements of Stack1 to Stack2.
+- Then pop the top element of Stack2.
+Now we haven't copied to the Stack 1
+ -**Explanation:**
+Now Enqueue 8 and 10 one by one, to the Stack1.
-
+
-**Explanation:**
+Now Enqueue 8 and 10 one by one, to the Stack1.
-
+ -From the image, the 5th Perfect Number is **21**.
+Now its an Dequeue Operation! Which number is standing at the front of the queue ?
+
-From the image, the 5th Perfect Number is **21**.
+Now its an Dequeue Operation! Which number is standing at the front of the queue ?
+ ----
-### Nth perfect number Solution
+Its 4, Its is found on the Top of Stack2.
-#### Solution
+Pop 4 from Stack2
-```javascript
-int solve(N) {
- if (N <= 2) return N
- // Queue ->q
- q.enqueue(1) q.enqueue(2)
- i = 3
- while (i <= N) {
- x = q.dequeue()
- a = x * 10 + 1
- b = x * 10 + 2 //a + 1
- if (i == N) return a
- if (i + 1 == N) return b
- q.enqueue(a)
- q.enqueue(b)
- i = i + 2
- }
-}
-```
+Again Its an Dequeue Operation, Pop 7 from Stack2 which is the Front element of the Queue.
-#### Dry Run
+
----
-### Nth perfect number Solution
+Its 4, Its is found on the Top of Stack2.
-#### Solution
+Pop 4 from Stack2
-```javascript
-int solve(N) {
- if (N <= 2) return N
- // Queue ->q
- q.enqueue(1) q.enqueue(2)
- i = 3
- while (i <= N) {
- x = q.dequeue()
- a = x * 10 + 1
- b = x * 10 + 2 //a + 1
- if (i == N) return a
- if (i + 1 == N) return b
- q.enqueue(a)
- q.enqueue(b)
- i = i + 2
- }
-}
-```
+Again Its an Dequeue Operation, Pop 7 from Stack2 which is the Front element of the Queue.
-#### Dry Run
+ -To dry run the provided code for N = 10, we'll create a table to keep track of the values of `q` (the queue) and `i` at each step.
-```plaintext
-| N | q | i | |
-|:---:|:----:| --- |:-----------------:|
-| 10 | 1, 2 | 3 | // Initial values |
+Enqueue 14 to Stack1.
-// Loop starts
-| N | q | i |
-|-------|----------------|-----|
-| 10 | 2, 11, 12 | 3 |// Dequeue 1, enqueue 11 and 12
-| 10 | 11, 12,21,22 | 5 |// Dequeue 2, enqueue 21 and 22
-| 10 |12,21,22,111,112| 7 |// Dequeue 11, enqueue 111 and 112
-| 10 |21,22,111,112,121,122| 9 |// Dequeue 12, enqueue 121 and 122
+
-To dry run the provided code for N = 10, we'll create a table to keep track of the values of `q` (the queue) and `i` at each step.
-```plaintext
-| N | q | i | |
-|:---:|:----:| --- |:-----------------:|
-| 10 | 1, 2 | 3 | // Initial values |
+Enqueue 14 to Stack1.
-// Loop starts
-| N | q | i |
-|-------|----------------|-----|
-| 10 | 2, 11, 12 | 3 |// Dequeue 1, enqueue 11 and 12
-| 10 | 11, 12,21,22 | 5 |// Dequeue 2, enqueue 21 and 22
-| 10 |12,21,22,111,112| 7 |// Dequeue 11, enqueue 111 and 112
-| 10 |21,22,111,112,121,122| 9 |// Dequeue 12, enqueue 121 and 122
+ -// Now Loop ends at N == 10 , and ans = 122
-```
+Dequeue Operation
-The function dequeues and enqueues values in the queue until `i` reaches `N`. When `i` equals `N`, it returns the current value of `a`. In this case, for `N = 10`, the function returns 112.
+- Pop 9 from Stack2;
+Again Dequeue Opeation, Right now Stack2 is Empty!
+
+Now lets do the same process again,
+- Push all the elements of Stack1 to Stack2
+- Pop the Top element of Stack1
+
+
-// Now Loop ends at N == 10 , and ans = 122
-```
+Dequeue Operation
-The function dequeues and enqueues values in the queue until `i` reaches `N`. When `i` equals `N`, it returns the current value of `a`. In this case, for `N = 10`, the function returns 112.
+- Pop 9 from Stack2;
+Again Dequeue Opeation, Right now Stack2 is Empty!
+
+Now lets do the same process again,
+- Push all the elements of Stack1 to Stack2
+- Pop the Top element of Stack1
+
+ +
+
+### Idea 2- Approach
+
+For Enqueue: -> O(1)
+* Push x in Stack1
+
+For Dequeue: -> Best Case: O(1) Worst Case: O(N)
+* If Stack2 is empty:
+ * Transfer all the elements from Stack1 -> Stack2
+* Then Remove top element of Stack2
-#### Complexity
-**Time Complexity:** O(n)
-**Space Complexity:** O(n)
---
-### Doubly Ended Queue
+## Doubly Ended Queue
A double-ended queue (deque) is a data structure that allows elements to be added or removed from both ends, making it versatile for various operations. A double-linked list is a common choice for implementing a deque because it provides efficient operations for adding and removing elements from both ends.
@@ -357,24 +321,26 @@ A **double-linked list** is well-suited for implementing a **deque** because it
---
-### Problem 2 Sliding Window Maximum
-#### Problem Statement
+## Problem 2 Sliding Window Maximum
+
+
+### Problem Statement
Given an integer array `A` and an window of size k find the max element.
-**Input**
+### Input
- An integer array `A` and integer `k` .
-**Output**
+### Output
- An integer representing the maximum length of a subarray of `A` in which the average of all elements is greater than or equal to `k`. If no such subarray exists, return 0.
-**Example**
+### Example
+
+
+### Idea 2- Approach
+
+For Enqueue: -> O(1)
+* Push x in Stack1
+
+For Dequeue: -> Best Case: O(1) Worst Case: O(N)
+* If Stack2 is empty:
+ * Transfer all the elements from Stack1 -> Stack2
+* Then Remove top element of Stack2
-#### Complexity
-**Time Complexity:** O(n)
-**Space Complexity:** O(n)
---
-### Doubly Ended Queue
+## Doubly Ended Queue
A double-ended queue (deque) is a data structure that allows elements to be added or removed from both ends, making it versatile for various operations. A double-linked list is a common choice for implementing a deque because it provides efficient operations for adding and removing elements from both ends.
@@ -357,24 +321,26 @@ A **double-linked list** is well-suited for implementing a **deque** because it
---
-### Problem 2 Sliding Window Maximum
-#### Problem Statement
+## Problem 2 Sliding Window Maximum
+
+
+### Problem Statement
Given an integer array `A` and an window of size k find the max element.
-**Input**
+### Input
- An integer array `A` and integer `k` .
-**Output**
+### Output
- An integer representing the maximum length of a subarray of `A` in which the average of all elements is greater than or equal to `k`. If no such subarray exists, return 0.
-**Example**
+### Example
 -#### Question Explanation
+### Question Explanation
Find max elements in 4-element sliding windows of array A:
- `[1, 8, 5, 6]` -> max: 8
- `[8, 5, 6, 7]` -> max: 8
@@ -390,20 +356,21 @@ Result: `[8, 8, 7, 7, 7, 4]`.
4. Result: `[8, 8, 7, 7, 7, 4]`, representing max elements in each 4-element window in `A`.
---
+
### Question
Given an integer array `A` and an window of size k find the max element.
A = [1, 4, 3, 2, 5]
k = 3
-**Choices**
+### Choices
- [x] [4, 4, 5]
- [ ] [5, 5, 5]
- [ ] [1, 4, 3]
- [ ] [5, 4, 3]
-**Explanation:**
+### Explanation:
Maximum of [1, 4, 3] is 4
Maximum of [4, 3, 2] is 4
@@ -412,18 +379,15 @@ Maximum of [3, 2, 5] is 5
So, `[4, 4, 5]` is the answer.
---
+## Sliding Window Maximum Approaches
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-### Sliding Window Maximum Approaches
-#### Brute Force Approach
+### Brute Force Approach
Brute-force approach to find max element in a window of size `k` in array `A` involves iterating through windows, finding max within each, and storing results. Time complexity: **O(n * k)** and space complexity: **O(1)**.
-#### Dry Run using the Sliding Window Approach
+### Dry Run using the Sliding Window Approach
Array `A = [1, 8, 5, 6, 7, 4, 2, 0, 3]` and `k = 4`.
@@ -462,7 +426,7 @@ To slide the window, check if A[i - k] is present in front, if yes then dequeue
So, the dry run demonstrates how the code finds and prints the maximum elements in groups of size `k` as it iterates through the array.
-#### Pseudocode (Using Dequeue)
+### Pseudocode (Using Dequeue)
```javascript
function findMaximumInGroups(A, k):
@@ -488,13 +452,76 @@ function findMaximumInGroups(A, k):
print A[q.front()] // Print the maximum element in the last group
-# Example usage:
+# Example usage:
A = [1, 8, 5, 6, 7, 4, 2, 0, 3]
k = 4
findMaximumInGroups(A, k)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(n)
**Space Complexity:** O(n)
+
+---
+## Scenario Real-Time Stock Trading Alerts
+
+
+### **Scenario:**
+At TechTrade Inc., a trading team focuses on day-trading technology stocks. They employ a strategy that involves selling stocks at short-term peaks to maximize profits. The team uses an algorithm to determine the best time to sell stocks based on minute-to-minute price data.
+
+Stock Prices Array 𝐴
+Consider the minute-by-minute stock prices of a tech company, TechCorp, over a 10-minute interval:
+
+A=[220,215,230,225,240,235,230,245,250,240]
+
+### **Objective:**
+The trading team wants to identify the highest stock price in every 3-minute window to pinpoint the optimal selling moments.
+
+Detailed Process and Trader Actions:
+
+1. First Window
+* 9:00−9:02AM: Prices = [220, 215, 230]
+* Maximum = 230
+* Action: The team sets an alert to consider selling if the price approaches 230 again.
+
+2. Second Window
+* 9:01−9:03AM: Prices = [215, 230, 225]
+* Maximum = 230
+* Action: No immediate action as the price did not increase.
+
+3. Third Window
+* 9:02−9:04AM: Prices = [230, 225, 240]
+* Maximum = 240
+* Action: The team sells a portion of their holdings at 240, capitalizing on the peak.
+
+4. Fourth Window
+* 9:03−9:05AM: Prices = [225, 240, 235]
+* Maximum = 240
+* Action: No additional sales as the price remains below the previous maximum.
+
+5. Fifth Window
+* 9:04−9:06AM: Prices = [240, 235, 230]
+* Maximum = 240
+* Action: Monitor for stability or increase beyond 240 for further sales.
+
+6. Sixth Window
+* 9:05−9:07AM: Prices = [235, 230, 245]
+* Maximum = 245
+* Action: Another selling opportunity as the price peaks at 245.
+
+7. Seventh Window
+* 9:06−9:08AM: Prices = [230, 245, 250]
+* Maximum = 250
+* Action: The highest peak yet; the team sells a significant portion at 250.
+
+8. Eighth Window
+* 9:07−9:09AM: Prices = [245, 250, 240]
+* Maximum = 250
+* Action: The price did not increase; the team holds off on further sales.
+
+### **Conclusion:**
+Each value in the output array 230,230,240,240,240,245,250,250 guides the traders on when to sell. By setting alerts based on these maximum values, the team can execute trades at the most advantageous moments, capitalizing on short-term highs to maximize returns. This real-time decision-making process aids in managing a high-volume trading portfolio efficiently and profitably.
+
+### Approach to solve
+This problem is nothing but a real life application of sliding window.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md b/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md
index ab20916..8d8d4b7 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md
@@ -1,15 +1,16 @@
# Recursion 1
----
+
## Introduction to Recursion
+
### Definition
-1. See this video - [LINK](https://www.youtube.com/watch?v=-xMYvVr9fd4)
+1. Watch this video - [LINK](https://www.youtube.com/watch?v=-xMYvVr9fd4)
2. Function calling itself.
3. A problem is broke into smaller problem(subproblem) and the solution is generated using the subproblems.
-**Example**
+### Example
Here's an example of how recursion can be used to calculate the sum of the first **N** natural numbers:
```cpp
sum(N) = 1 + 2 + 3 + 4 + ..... + N-1 + N
@@ -25,36 +26,50 @@ We can solve any recursive problem using below magic steps:
2. **Main logic:** Break the problem down into smaller subproblems to solve the assumption.
3. **Base case:** Identify the inputs for which we need to stop the recursion.
+### Sum of N
+```
+//Assumption: function sum(N) will return sum of numbers from 1 to N
+
+function sum(N) {
+ //Base Case
+ if(N==0) {
+ return 0;
+ }
+
+ //Main Logic
+ return N + sum(N-1); //sum(N-1) will return sum of numbers from 1 to N-1
+}
+```
+
---
## Function Call Tracing
+
* Function call tracing involves tracing the sequence of function calls that are made when a program is executed.
* It involves keeping track of the function calls, their arguments, and the return values in order to understand the flow of the program and how the functions are interacting with each other.
### Example:
We have the following code:
```cpp
-int add(int x, int y) {
+function add(x, y) {
return x + y;
}
-int mul(int x, int y, int z) {
+function mul(x, y, z) {
return x * y * z;
}
-int sub(int x, int y) {
+function sub( x, y) {
return x - y;
}
-void(int x) {
+function ( x) {
cout << x << endl;
}
-int main() {
- int x = 10;
- int y = 20;
+function main() {
+ x = 10, y = 20;
print(sub(mul(add(x, y), 30), 75));
- return 0;
}
```
Here are the steps involved in function call tracing of the above code:
@@ -75,19 +90,24 @@ Here are the steps involved in function call tracing of the above code:
-#### Question Explanation
+### Question Explanation
Find max elements in 4-element sliding windows of array A:
- `[1, 8, 5, 6]` -> max: 8
- `[8, 5, 6, 7]` -> max: 8
@@ -390,20 +356,21 @@ Result: `[8, 8, 7, 7, 7, 4]`.
4. Result: `[8, 8, 7, 7, 7, 4]`, representing max elements in each 4-element window in `A`.
---
+
### Question
Given an integer array `A` and an window of size k find the max element.
A = [1, 4, 3, 2, 5]
k = 3
-**Choices**
+### Choices
- [x] [4, 4, 5]
- [ ] [5, 5, 5]
- [ ] [1, 4, 3]
- [ ] [5, 4, 3]
-**Explanation:**
+### Explanation:
Maximum of [1, 4, 3] is 4
Maximum of [4, 3, 2] is 4
@@ -412,18 +379,15 @@ Maximum of [3, 2, 5] is 5
So, `[4, 4, 5]` is the answer.
---
+## Sliding Window Maximum Approaches
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-### Sliding Window Maximum Approaches
-#### Brute Force Approach
+### Brute Force Approach
Brute-force approach to find max element in a window of size `k` in array `A` involves iterating through windows, finding max within each, and storing results. Time complexity: **O(n * k)** and space complexity: **O(1)**.
-#### Dry Run using the Sliding Window Approach
+### Dry Run using the Sliding Window Approach
Array `A = [1, 8, 5, 6, 7, 4, 2, 0, 3]` and `k = 4`.
@@ -462,7 +426,7 @@ To slide the window, check if A[i - k] is present in front, if yes then dequeue
So, the dry run demonstrates how the code finds and prints the maximum elements in groups of size `k` as it iterates through the array.
-#### Pseudocode (Using Dequeue)
+### Pseudocode (Using Dequeue)
```javascript
function findMaximumInGroups(A, k):
@@ -488,13 +452,76 @@ function findMaximumInGroups(A, k):
print A[q.front()] // Print the maximum element in the last group
-# Example usage:
+# Example usage:
A = [1, 8, 5, 6, 7, 4, 2, 0, 3]
k = 4
findMaximumInGroups(A, k)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(n)
**Space Complexity:** O(n)
+
+---
+## Scenario Real-Time Stock Trading Alerts
+
+
+### **Scenario:**
+At TechTrade Inc., a trading team focuses on day-trading technology stocks. They employ a strategy that involves selling stocks at short-term peaks to maximize profits. The team uses an algorithm to determine the best time to sell stocks based on minute-to-minute price data.
+
+Stock Prices Array 𝐴
+Consider the minute-by-minute stock prices of a tech company, TechCorp, over a 10-minute interval:
+
+A=[220,215,230,225,240,235,230,245,250,240]
+
+### **Objective:**
+The trading team wants to identify the highest stock price in every 3-minute window to pinpoint the optimal selling moments.
+
+Detailed Process and Trader Actions:
+
+1. First Window
+* 9:00−9:02AM: Prices = [220, 215, 230]
+* Maximum = 230
+* Action: The team sets an alert to consider selling if the price approaches 230 again.
+
+2. Second Window
+* 9:01−9:03AM: Prices = [215, 230, 225]
+* Maximum = 230
+* Action: No immediate action as the price did not increase.
+
+3. Third Window
+* 9:02−9:04AM: Prices = [230, 225, 240]
+* Maximum = 240
+* Action: The team sells a portion of their holdings at 240, capitalizing on the peak.
+
+4. Fourth Window
+* 9:03−9:05AM: Prices = [225, 240, 235]
+* Maximum = 240
+* Action: No additional sales as the price remains below the previous maximum.
+
+5. Fifth Window
+* 9:04−9:06AM: Prices = [240, 235, 230]
+* Maximum = 240
+* Action: Monitor for stability or increase beyond 240 for further sales.
+
+6. Sixth Window
+* 9:05−9:07AM: Prices = [235, 230, 245]
+* Maximum = 245
+* Action: Another selling opportunity as the price peaks at 245.
+
+7. Seventh Window
+* 9:06−9:08AM: Prices = [230, 245, 250]
+* Maximum = 250
+* Action: The highest peak yet; the team sells a significant portion at 250.
+
+8. Eighth Window
+* 9:07−9:09AM: Prices = [245, 250, 240]
+* Maximum = 250
+* Action: The price did not increase; the team holds off on further sales.
+
+### **Conclusion:**
+Each value in the output array 230,230,240,240,240,245,250,250 guides the traders on when to sell. By setting alerts based on these maximum values, the team can execute trades at the most advantageous moments, capitalizing on short-term highs to maximize returns. This real-time decision-making process aids in managing a high-volume trading portfolio efficiently and profitably.
+
+### Approach to solve
+This problem is nothing but a real life application of sliding window.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md b/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md
index ab20916..8d8d4b7 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Recursion 1.md
@@ -1,15 +1,16 @@
# Recursion 1
----
+
## Introduction to Recursion
+
### Definition
-1. See this video - [LINK](https://www.youtube.com/watch?v=-xMYvVr9fd4)
+1. Watch this video - [LINK](https://www.youtube.com/watch?v=-xMYvVr9fd4)
2. Function calling itself.
3. A problem is broke into smaller problem(subproblem) and the solution is generated using the subproblems.
-**Example**
+### Example
Here's an example of how recursion can be used to calculate the sum of the first **N** natural numbers:
```cpp
sum(N) = 1 + 2 + 3 + 4 + ..... + N-1 + N
@@ -25,36 +26,50 @@ We can solve any recursive problem using below magic steps:
2. **Main logic:** Break the problem down into smaller subproblems to solve the assumption.
3. **Base case:** Identify the inputs for which we need to stop the recursion.
+### Sum of N
+```
+//Assumption: function sum(N) will return sum of numbers from 1 to N
+
+function sum(N) {
+ //Base Case
+ if(N==0) {
+ return 0;
+ }
+
+ //Main Logic
+ return N + sum(N-1); //sum(N-1) will return sum of numbers from 1 to N-1
+}
+```
+
---
## Function Call Tracing
+
* Function call tracing involves tracing the sequence of function calls that are made when a program is executed.
* It involves keeping track of the function calls, their arguments, and the return values in order to understand the flow of the program and how the functions are interacting with each other.
### Example:
We have the following code:
```cpp
-int add(int x, int y) {
+function add(x, y) {
return x + y;
}
-int mul(int x, int y, int z) {
+function mul(x, y, z) {
return x * y * z;
}
-int sub(int x, int y) {
+function sub( x, y) {
return x - y;
}
-void(int x) {
+function ( x) {
cout << x << endl;
}
-int main() {
- int x = 10;
- int y = 20;
+function main() {
+ x = 10, y = 20;
print(sub(mul(add(x, y), 30), 75));
- return 0;
}
```
Here are the steps involved in function call tracing of the above code:
@@ -75,19 +90,24 @@ Here are the steps involved in function call tracing of the above code:
 ---
-### Problem 1 : Factorial of N
+## Problem 1 Factorial of N
+
+### Problem Statement
Given a positive integer N, find the factorial of N.
+---
+
### Question
If N = 5, find the factorial of N.
-
-**Choices**
+### Choices
- [ ] 100
- [x] 120
- [ ] 150
- [ ] 125
-**Solution**
+
+---
+### Factorial of N Solution
**Assumptions:** Create a function which -
* takes an integer value `N` as parameter.
@@ -96,7 +116,7 @@ If N = 5, find the factorial of N.
**Main logic:**
* The factorial of N is equal to N times the factorial of (N-1)
-* We made assumption that sum(N) calculates and return factorial of N natural number. Similarly, sum(N-1) shall calculate and return the factorial of N-1 natural number.
+* We made assumption that sum(N) calculates and return sum of N natural number. Similarly, sum(N-1) shall calculate and return the factorial of N-1 natural number.
`factorial(N) = N * factorial(N-1)`
**Base case:** The base case is when N equals 0, i.e., `0! = 1`
@@ -107,15 +127,15 @@ When we perform, `factorial(N) = N * factorial(N-1)`, value of N keeps on decrea
for N = 1 as well as 0, the factorial is 1.
So, we can write base case for N = 0 which will also cover for N = 1.
-#### Pseudocode
+### Pseudocode
```cpp
-int factorial(int N) {
+factorial(N) {
// base case
- if (N == 0) {
+ if (N == 0) {
return 1;
- }
+ }
// recursive case
- return N * factorial(N - 1);
+ return N * factorial(N-1);
}
```
@@ -123,10 +143,158 @@ int factorial(int N) {
---
-### Problem 1 : Factorial of N
+## Problem 1 Factorial of N
+
+### Problem Statement
Given a positive integer N, find the factorial of N.
+---
+
### Question
If N = 5, find the factorial of N.
-
-**Choices**
+### Choices
- [ ] 100
- [x] 120
- [ ] 150
- [ ] 125
-**Solution**
+
+---
+### Factorial of N Solution
**Assumptions:** Create a function which -
* takes an integer value `N` as parameter.
@@ -96,7 +116,7 @@ If N = 5, find the factorial of N.
**Main logic:**
* The factorial of N is equal to N times the factorial of (N-1)
-* We made assumption that sum(N) calculates and return factorial of N natural number. Similarly, sum(N-1) shall calculate and return the factorial of N-1 natural number.
+* We made assumption that sum(N) calculates and return sum of N natural number. Similarly, sum(N-1) shall calculate and return the factorial of N-1 natural number.
`factorial(N) = N * factorial(N-1)`
**Base case:** The base case is when N equals 0, i.e., `0! = 1`
@@ -107,15 +127,15 @@ When we perform, `factorial(N) = N * factorial(N-1)`, value of N keeps on decrea
for N = 1 as well as 0, the factorial is 1.
So, we can write base case for N = 0 which will also cover for N = 1.
-#### Pseudocode
+### Pseudocode
```cpp
-int factorial(int N) {
+factorial(N) {
// base case
- if (N == 0) {
+ if (N == 0) {
return 1;
- }
+ }
// recursive case
- return N * factorial(N - 1);
+ return N * factorial(N-1);
}
```
@@ -123,10 +143,158 @@ int factorial(int N) {
 +---
+## Problem 2 Printing numbers in increasing order
+
+
+### Problem Statement
+Given N, print all numbers from 1 to N in increasing order.
+
+Inc(5)= 1 2 3 4 5
+Inc(5) = Inc(4) + 5
+Subproblem: Inc(4)
+
+---
+### Question
+
+Which of the following correctly represents the N Increasing numbers in form of subproblems?
+
+### Choices
+- [x] Inc(N - 1)
+- [ ] Inc(N + 1)
+- [ ] Inc(N)
+
+---
+### Solution
+
+```javascript
+// Assumption - Given N, print all numbers from 1 to N
+
+function increasing(N) {
+ //Base Condition
+ if(N == 1) {
+ print(N)
+ return
+ }
+
+ //Main Logic
+ increasing(N-1) //subproblem
+ print(N) //first we call for recursion and then print
+}
+```
+
+**Dry Run**
+
+
+---
+## Problem 2 Printing numbers in increasing order
+
+
+### Problem Statement
+Given N, print all numbers from 1 to N in increasing order.
+
+Inc(5)= 1 2 3 4 5
+Inc(5) = Inc(4) + 5
+Subproblem: Inc(4)
+
+---
+### Question
+
+Which of the following correctly represents the N Increasing numbers in form of subproblems?
+
+### Choices
+- [x] Inc(N - 1)
+- [ ] Inc(N + 1)
+- [ ] Inc(N)
+
+---
+### Solution
+
+```javascript
+// Assumption - Given N, print all numbers from 1 to N
+
+function increasing(N) {
+ //Base Condition
+ if(N == 1) {
+ print(N)
+ return
+ }
+
+ //Main Logic
+ increasing(N-1) //subproblem
+ print(N) //first we call for recursion and then print
+}
+```
+
+**Dry Run**
+
+ +
+**Note:**
+* If the return type is void we can still write **return statement** to exit the function.
+* When the function ends {last line executed} or when we execute a return, it will go back to where it was called.
+
+---
+## Problem 3 Whirlpool's countdown timer
+
+
+### Problem
+**Whirlpool** wants to design a timer for their **washing machines**. This feature is a simple countdown timer. When a user sets a time, for example, 10 minutes, the washing machine needs to show each minute passing, counting down until it reaches 0.
+
+Your task is to write a program that takes an integer **A** (the time in minutes set by the user) and then prints out each minute as it counts down to **0**.The requirement is that after a user set a timer for the washing machine for some time say **A** , the washing machine should display each minute after that decremented one by one till the time becomes **0**.
+
+
+### Simplified Problem statement
+Given **N**, print all numbers from **1 to N** in decreasing order.
+
+### Approach
+
+- `decreasing(5) = 5 4 3 2 1`
+- `decreasing(5) = print(5) decreasing(4)`
+- `decreasing(N) = N N - 1 N - 2 ... 2 1`
+- `decreasing(N) = print(N) decreasing(N - 1)`
+
+### Pseudocode
+```java
+// Assumption - Given N, print all numbers from N to 1
+
+function decreasing(N) {
+ //Base Condition
+ if(N == 1) {
+ print(N)
+ return
+ }
+
+ //Main Logic
+ print(N) //first we print and then we call for recursion
+ decreasing(N-1) //subproblem
+}
+```
+
+### Time and Space Complexity of Recursion
+
+
+**Time Complexity = O(Number of function calls * Time per function call)**
+
+**Space Complexity = O(Maximum depth of recursion tree/stack space + Space per function call)**
+
+The space complexity of recursion refers to the amount of memory required by a recursive algorithm as it executes. It is determined by the maximum amount of memory needed on the call stack at any given point during the recursion(stack space can be measured from height of the tree).
+
+## Factorial(N)
+
+#### Pseudocode
+```cpp
+function factorial(N) {
+ // base case
+ if (N == 0) {
+ return 1;
+ }
+ // recursive case
+ return N * factorial(N-1);
+}
+```
+
+#### Recursive Tree for Factorial
+
+
+
+**Note:**
+* If the return type is void we can still write **return statement** to exit the function.
+* When the function ends {last line executed} or when we execute a return, it will go back to where it was called.
+
+---
+## Problem 3 Whirlpool's countdown timer
+
+
+### Problem
+**Whirlpool** wants to design a timer for their **washing machines**. This feature is a simple countdown timer. When a user sets a time, for example, 10 minutes, the washing machine needs to show each minute passing, counting down until it reaches 0.
+
+Your task is to write a program that takes an integer **A** (the time in minutes set by the user) and then prints out each minute as it counts down to **0**.The requirement is that after a user set a timer for the washing machine for some time say **A** , the washing machine should display each minute after that decremented one by one till the time becomes **0**.
+
+
+### Simplified Problem statement
+Given **N**, print all numbers from **1 to N** in decreasing order.
+
+### Approach
+
+- `decreasing(5) = 5 4 3 2 1`
+- `decreasing(5) = print(5) decreasing(4)`
+- `decreasing(N) = N N - 1 N - 2 ... 2 1`
+- `decreasing(N) = print(N) decreasing(N - 1)`
+
+### Pseudocode
+```java
+// Assumption - Given N, print all numbers from N to 1
+
+function decreasing(N) {
+ //Base Condition
+ if(N == 1) {
+ print(N)
+ return
+ }
+
+ //Main Logic
+ print(N) //first we print and then we call for recursion
+ decreasing(N-1) //subproblem
+}
+```
+
+### Time and Space Complexity of Recursion
+
+
+**Time Complexity = O(Number of function calls * Time per function call)**
+
+**Space Complexity = O(Maximum depth of recursion tree/stack space + Space per function call)**
+
+The space complexity of recursion refers to the amount of memory required by a recursive algorithm as it executes. It is determined by the maximum amount of memory needed on the call stack at any given point during the recursion(stack space can be measured from height of the tree).
+
+## Factorial(N)
+
+#### Pseudocode
+```cpp
+function factorial(N) {
+ // base case
+ if (N == 0) {
+ return 1;
+ }
+ // recursive case
+ return N * factorial(N-1);
+}
+```
+
+#### Recursive Tree for Factorial
+
+ +
+
+
+### Time Complexity
+
+For finding number of function calls, we can see the above recursive tree.
+If N=5, number of function calls = 5
+If N=6, number of function calls = 6
+Hence for N, number of function calls = N
+Time take per call = O(1)
+
+Hence, for factorial, overall time complexity = O(N)
+
+### Space Complexity
+Total N call will be stored in the stack.
+```
+factorial(1)
+factorial(2)
+---------------
+---------------
+---------------
+factorial(N-1)
+factorial(N)
+```
+The height of recursive tree = N, hence stack space is O(N) and no extra space is used in calls, hence total space complexity O(N)
+
+## increasing(N) /decreasing(N)
+
+### Time Complexity
+Number of function calls are N
+Time per call is O(1)
+Total T.C = O(N)
+
+### Space Complexity
+Since height of recursive tree is N, and no extra space is used otherwise, the S.C = O(N)
+
---
-### Problem 2 : Nth number in the Fibonacci Series
+## Problem 4 Nth number in the Fibonacci Series
+### Problem Statement
The Fibonacci sequence is a series of numbers in which each number is the sum of the two preceding numbers.
@@ -138,7 +306,7 @@ The sequence goes like this:
Given a positive integer N, write a function to compute the Nth number in the Fibonacci sequence using recursion.
-**Example**
+### Example
```cpp
Input = 6
Output = 8
@@ -151,23 +319,20 @@ Output = 8
Fibonacci(6) = Fibonacci(5) + Fibonacci(4) = 3 + 5 = 8.
---
+
### Question
If N = 7, find the Nth number in the fibonacci sequence.
-
-**Choices**
+### Choices
- [ ] 8
- [ ] 5
- [x] 13
- [ ] 10
---
+## Nth number in the Fibonacci sequence Solution
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-### Nth number in the Fibonacci sequence Solution
-#### Solution
+### Solution
**Assumptions:** Create a function which -
* takes an integer value `N` as parameter.
* calculates and returns Nth number in the fibonacci sequence.
@@ -180,195 +345,80 @@ Please take some time to think about the solution approach on your own before re
* Since, according to the definition of fibonacci sequence, the smallest two possible values of N are `N = 1` & `N = 2`, therefore, stop recursion as soon as N becomes 0 or 1.
-#### Pseudocode
+### Pseudocode
```cpp
-int fibonacci(int N) {
+function fibonacci(N) {
// base case
if (N == 0 || N == 1) {
return N;
}
-
+
// recursive case
return fibonacci(N - 1) + fibonacci(N - 2);
}
```
-#### Function Call Tracing
+### Function Call Tracing
+
+
+
+### Time Complexity
+
+For finding number of function calls, we can see the above recursive tree.
+If N=5, number of function calls = 5
+If N=6, number of function calls = 6
+Hence for N, number of function calls = N
+Time take per call = O(1)
+
+Hence, for factorial, overall time complexity = O(N)
+
+### Space Complexity
+Total N call will be stored in the stack.
+```
+factorial(1)
+factorial(2)
+---------------
+---------------
+---------------
+factorial(N-1)
+factorial(N)
+```
+The height of recursive tree = N, hence stack space is O(N) and no extra space is used in calls, hence total space complexity O(N)
+
+## increasing(N) /decreasing(N)
+
+### Time Complexity
+Number of function calls are N
+Time per call is O(1)
+Total T.C = O(N)
+
+### Space Complexity
+Since height of recursive tree is N, and no extra space is used otherwise, the S.C = O(N)
+
---
-### Problem 2 : Nth number in the Fibonacci Series
+## Problem 4 Nth number in the Fibonacci Series
+### Problem Statement
The Fibonacci sequence is a series of numbers in which each number is the sum of the two preceding numbers.
@@ -138,7 +306,7 @@ The sequence goes like this:
Given a positive integer N, write a function to compute the Nth number in the Fibonacci sequence using recursion.
-**Example**
+### Example
```cpp
Input = 6
Output = 8
@@ -151,23 +319,20 @@ Output = 8
Fibonacci(6) = Fibonacci(5) + Fibonacci(4) = 3 + 5 = 8.
---
+
### Question
If N = 7, find the Nth number in the fibonacci sequence.
-
-**Choices**
+### Choices
- [ ] 8
- [ ] 5
- [x] 13
- [ ] 10
---
+## Nth number in the Fibonacci sequence Solution
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-### Nth number in the Fibonacci sequence Solution
-#### Solution
+### Solution
**Assumptions:** Create a function which -
* takes an integer value `N` as parameter.
* calculates and returns Nth number in the fibonacci sequence.
@@ -180,195 +345,80 @@ Please take some time to think about the solution approach on your own before re
* Since, according to the definition of fibonacci sequence, the smallest two possible values of N are `N = 1` & `N = 2`, therefore, stop recursion as soon as N becomes 0 or 1.
-#### Pseudocode
+### Pseudocode
```cpp
-int fibonacci(int N) {
+function fibonacci(N) {
// base case
if (N == 0 || N == 1) {
return N;
}
-
+
// recursive case
return fibonacci(N - 1) + fibonacci(N - 2);
}
```
-#### Function Call Tracing
+### Function Call Tracing
 -
+**HW:** Do the above function call tracing with stack.
---
-### Time Complexity of Recursion - using Recurrence Relation
+## Time and Space for Fibonacci
-**Factorial(N)**
-#### Pseudocode
-```cpp
-int factorial(int N) {
- // base case
- if (N == 0) {
- return 1;
- }
- // recursive case
- return N * factorial(N - 1);
-}
-```
-
-* Let's assume that time taken to calculate **factorial(n)** = **T(n)**.
-* **factorial(n)** depends on the time taken by **factorial(n-1)** and other than that, constant work is being performed.
-* Time taken by **factorial(n-1) = T(n-1) + O(1)**.
-* Therefore, for the sum of digits, the recursive relation will be defined as follows:
-
-#### Equation 1
-```
-T(n) = T(n-1) + 1
-```
-**1** is added because other than function calls, a constant amount of work is being done.
-
-Substituting the value of ```T(n-1) = T(n-2) + 1```
-
-#### Equation 2
-```
-T(n) = T(n-2) + 2
-```
-Substituting the value of ```T(n-2) = T(n-3) + 1```
-
-#### Equation 3
-```
-T(n) = T(n-3) + 3
-```
-Substituting the value of ```T(n-3) = T(n-4) + 1```
-#### Equation 4
-```
-T(n) = T(n-4) + 4
-```
-
-After say **k** iterations, we shall reach to the base step.
-The equation will be:
-#### Equation 5
-```
-T(n) = T(n-k) + k
-```
-
-The base case shall take constant time:
-
-```
-T(0) = O(1)
-```
-
-We shall substitute the value of **n - k = 0**
-
-```
-=> n - k = 0
-=> n = k
-```
-Put the above value in a generalized equation, we get
-```
-T(n) = T(0) + n
-T(n) = 1 + n
-T(n) = O(n)
-```
-Hence we can say that.
-```
-T(n) = O(n)
-```
----
-### Time Complexity of Fibonacci
#### Pseudocode
-```cpp
-Function fibonacci(int n) {
- if (n == 0 || n == 1) return n;
- return fibonacci(n - 1) + fibonacci(n - 2);
-}
-```
-Recurrence Relation is:
-```
- T(n) = T(n-1) + T(n-2)
-```
-For easy calculation, we can write the recurrence relation as follows:
-```
- T(n) = 2 * T(n-1)
+```c++
+Function fibonacci(n){
+ if(n == 0 || n == 1) return n;
+ return fibonacci(n-1) + fibonacci(n-2);
+}
```
-It will evaluate to **O(2N)**
->Note to Instructor: Please evaluate above recurrence relation in class.
+#### Recursive Tree for Fibonacci
+
-
+**HW:** Do the above function call tracing with stack.
---
-### Time Complexity of Recursion - using Recurrence Relation
+## Time and Space for Fibonacci
-**Factorial(N)**
-#### Pseudocode
-```cpp
-int factorial(int N) {
- // base case
- if (N == 0) {
- return 1;
- }
- // recursive case
- return N * factorial(N - 1);
-}
-```
-
-* Let's assume that time taken to calculate **factorial(n)** = **T(n)**.
-* **factorial(n)** depends on the time taken by **factorial(n-1)** and other than that, constant work is being performed.
-* Time taken by **factorial(n-1) = T(n-1) + O(1)**.
-* Therefore, for the sum of digits, the recursive relation will be defined as follows:
-
-#### Equation 1
-```
-T(n) = T(n-1) + 1
-```
-**1** is added because other than function calls, a constant amount of work is being done.
-
-Substituting the value of ```T(n-1) = T(n-2) + 1```
-
-#### Equation 2
-```
-T(n) = T(n-2) + 2
-```
-Substituting the value of ```T(n-2) = T(n-3) + 1```
-
-#### Equation 3
-```
-T(n) = T(n-3) + 3
-```
-Substituting the value of ```T(n-3) = T(n-4) + 1```
-#### Equation 4
-```
-T(n) = T(n-4) + 4
-```
-
-After say **k** iterations, we shall reach to the base step.
-The equation will be:
-#### Equation 5
-```
-T(n) = T(n-k) + k
-```
-
-The base case shall take constant time:
-
-```
-T(0) = O(1)
-```
-
-We shall substitute the value of **n - k = 0**
-
-```
-=> n - k = 0
-=> n = k
-```
-Put the above value in a generalized equation, we get
-```
-T(n) = T(0) + n
-T(n) = 1 + n
-T(n) = O(n)
-```
-Hence we can say that.
-```
-T(n) = O(n)
-```
----
-### Time Complexity of Fibonacci
#### Pseudocode
-```cpp
-Function fibonacci(int n) {
- if (n == 0 || n == 1) return n;
- return fibonacci(n - 1) + fibonacci(n - 2);
-}
-```
-Recurrence Relation is:
-```
- T(n) = T(n-1) + T(n-2)
-```
-For easy calculation, we can write the recurrence relation as follows:
-```
- T(n) = 2 * T(n-1)
+```c++
+Function fibonacci(n){
+ if(n == 0 || n == 1) return n;
+ return fibonacci(n-1) + fibonacci(n-2);
+}
```
-It will evaluate to **O(2N)**
->Note to Instructor: Please evaluate above recurrence relation in class.
+#### Recursive Tree for Fibonacci
+ -### Another definition of Time Complexity
-
-Time Complexity can also be defined as
-
-**Time taken in a single function call * Number of function calls**
-
----
-### Question
-How many recursive calls in the factorial(6)?
-
-Choose the correct answer
-**Choices**
-- [ ] 0
-- [ ] 2
-- [x] 6
-- [ ] 10
-
----
-### Space Complexity of Recursive Code
-
-
-The space complexity of recursion refers to the amount of memory required by a recursive algorithm as it executes. It is determined by the maximum amount of memory needed on the call stack at any given point during the recursion.
-
-### Space Complexity of factorial(N)
-Total N call will be stored in the stack.
-```
-factorial(1)
-factorial(2)
----------------
----------------
----------------
-factorial(N-1)
-factorial(N)
-```
+### T.C
-Maximum stack space used is N, hence space is O(N)
+In above tree, how many function calls are there ?
+In level 1 => 2^0^
+In level 2 => 2^1^
+In level 3 => 2^2^
+.
+.
+.
+In level x => 2^x-1^
-Hence, total O(N) space is required to execute all the recursive calls.
+The last is Nth level, hence x = N.
-### Space complexity of fibonacci(n)
-If the time complexity of our recursive Fibonacci is O(2^n), what’s the space complexity?
+Total function calls are -
+2^0^ + 2^1^ + 2^2^ + 2^3^ + ....... + 2^N-1^
+This is sum of GP, a=1, r=2, #terms = N
-***Tempted to say the same?***
-> NOTE to Instructor: Show it using a stack
+Formula = a(r^#terms^ - 1) / (r-1)
+ = 1(2^N^ - 1) / (2-1)
+ = O(2^N^)
-**SPACE COMPLEXITY** can also be calculated using **RECURSIVE TREE**
-
->Please Note: This tree is known as Recursive Tree.
+### S.C
-Space complexity is the amount of memory used by the algorithm.
+Space complexity is the maximum amount of stack space used by the algorithm.
When a function is called, it is added to the stack.
-
When a function returns, it is popped off the stack.
We’re not adding all of the function calls to the stack at once.
-
We only make n calls at any given time as we move up and down branches.
We proceed branch by branch, making our function calls until our base case is met, then we return and make our calls down to the next branch.
-### Another definition of Time Complexity
-
-Time Complexity can also be defined as
-
-**Time taken in a single function call * Number of function calls**
-
----
-### Question
-How many recursive calls in the factorial(6)?
-
-Choose the correct answer
-**Choices**
-- [ ] 0
-- [ ] 2
-- [x] 6
-- [ ] 10
-
----
-### Space Complexity of Recursive Code
-
-
-The space complexity of recursion refers to the amount of memory required by a recursive algorithm as it executes. It is determined by the maximum amount of memory needed on the call stack at any given point during the recursion.
-
-### Space Complexity of factorial(N)
-Total N call will be stored in the stack.
-```
-factorial(1)
-factorial(2)
----------------
----------------
----------------
-factorial(N-1)
-factorial(N)
-```
+### T.C
-Maximum stack space used is N, hence space is O(N)
+In above tree, how many function calls are there ?
+In level 1 => 2^0^
+In level 2 => 2^1^
+In level 3 => 2^2^
+.
+.
+.
+In level x => 2^x-1^
-Hence, total O(N) space is required to execute all the recursive calls.
+The last is Nth level, hence x = N.
-### Space complexity of fibonacci(n)
-If the time complexity of our recursive Fibonacci is O(2^n), what’s the space complexity?
+Total function calls are -
+2^0^ + 2^1^ + 2^2^ + 2^3^ + ....... + 2^N-1^
+This is sum of GP, a=1, r=2, #terms = N
-***Tempted to say the same?***
-> NOTE to Instructor: Show it using a stack
+Formula = a(r^#terms^ - 1) / (r-1)
+ = 1(2^N^ - 1) / (2-1)
+ = O(2^N^)
-**SPACE COMPLEXITY** can also be calculated using **RECURSIVE TREE**
-
->Please Note: This tree is known as Recursive Tree.
+### S.C
-Space complexity is the amount of memory used by the algorithm.
+Space complexity is the maximum amount of stack space used by the algorithm.
When a function is called, it is added to the stack.
-
When a function returns, it is popped off the stack.
We’re not adding all of the function calls to the stack at once.
-
We only make n calls at any given time as we move up and down branches.
We proceed branch by branch, making our function calls until our base case is met, then we return and make our calls down to the next branch.
 -We can also define **Space Complexity** as **height of the Recursive Tree**.
+Hence, at a time at max calls = height of the tree, will be present in stack, hence space complexity is O(N) for fibonacci.
----
-### Question
-What is the height of tree for fibonacci(6) ?
-Choose the correct answer
+#### Emulation of space for Fibonacci(3) using stack
+
+
-We can also define **Space Complexity** as **height of the Recursive Tree**.
+Hence, at a time at max calls = height of the tree, will be present in stack, hence space complexity is O(N) for fibonacci.
----
-### Question
-What is the height of tree for fibonacci(6) ?
-Choose the correct answer
+#### Emulation of space for Fibonacci(3) using stack
+
+ -**Choices**
-- [ ] 0
-- [ ] 7
-- [x] 6
-- [ ] 8
diff --git a/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md b/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md
index 4bf0555..3c2fbdc 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md
@@ -1,162 +1,100 @@
# Recursion 2
-## Question
-What is the output of the following code for N = 3?
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- solve(N-1);
- print(N);
-}
-```
-
-**Choices**
-
-- [x] 1 2 3
-- [ ] 0 1 2
-- [ ] 2 1 0
-- [ ] 3 2 1
+## Revision Quizzes
-
-
-
-```cpp
-void solve(int N) {
- if (N == 0)
- return;
- solve(N - 1);
- print(N);
-}
-```
-N=3
-
-1. So first of all, solve(3) is called,
-1. Then solve(3) will first call for solve(2) as n!=0,
-1. Similarly, solve(2) calls for solve(1), and then solve(1) calls for solve(0).
-
-
-**Choices**
-- [ ] 0
-- [ ] 7
-- [x] 6
-- [ ] 8
diff --git a/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md b/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md
index 4bf0555..3c2fbdc 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Recursion 2.md
@@ -1,162 +1,100 @@
# Recursion 2
-## Question
-What is the output of the following code for N = 3?
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- solve(N-1);
- print(N);
-}
-```
-
-**Choices**
-
-- [x] 1 2 3
-- [ ] 0 1 2
-- [ ] 2 1 0
-- [ ] 3 2 1
+## Revision Quizzes
-
-
-
-```cpp
-void solve(int N) {
- if (N == 0)
- return;
- solve(N - 1);
- print(N);
-}
-```
-N=3
-
-1. So first of all, solve(3) is called,
-1. Then solve(3) will first call for solve(2) as n!=0,
-1. Similarly, solve(2) calls for solve(1), and then solve(1) calls for solve(0).
-
- -
-
-Now n==0 so return.
-
-Then solve(1) will print 1, then it will return, and after that solve(2) will print 2, in this way 1, 2, 3 will be printed as an output.
-
-
-
-
----
### Question
-What is the output of the following code for N = 3?
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
+What is recursion ?
-**Choices**
+### Choices
-- [ ] 1 2 3
+- [ ] A function that calls itself
+- [ ] A function that calls another function
+- [ ] A loop that repeats until a condition is met
+- [x] A function that solves a problem by breaking it into smaller subproblems and calling itself
-- [ ] 0 1 2
+---
-- [ ] 2 1 0
-- [x] 3 2 1
+### Question
+What data structure is used for function call tracing in recursion?
+### Choices
+- [ ] Queue
+- [ ] Linked List
+- [x] Stack
+- [ ] Array
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
-N=3
+---
-1. So first of all, solve(3) is called,
-1. Then solve(3) will first **print 3**, then call for solve(2) as n!=0,
-1. In this way solve(2) first **print 2**, then call for solve(1), and then solve(1) will **print 1**, then call for solve(0).
+### Question
+ Which of the following is the base case for calculating the factorial of a number using recursion?
-
+### Choices
+- [ ] N == 2
+- [x] N == 0
+- [ ] N == 1
+- [ ] N == -1
-Now n==0 so return.
+---
-Then solve(1) will return, after that solve(2) will return.
-In this way 3, 2, 1 will be printed as an output.
+### Question
+What is the time and space complexity for calculating factorial using recurion ?
+### Choices
+- [x] O(N), O(N)
+- [ ] O(N), O(1)
+- [ ] O(1), O(N)
+- [ ] O(N), O(log(N))
---
-### Question
-What is the output of the following code for N = -3?
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
-
-**Choices**
-- [ ] -3 -2 -1
-- [ ] 3 2 1
+### Question
+To compute Fibonacci(N) you need answers of ?
-- [x] Error; Stack Overflow
-- [ ] 1 2 3
+### Choices
+- [ ] fibonacci(N - 1)
+- [ ] Fibonacci(N - 2)
+- [x] Fibonacci(N - 1) and Fibonacci(N - 2)
+- [ ] none
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
-`N = -3`
-
+---
+## Agenda
-In this question we will never reach 0, that's why we are getting stack overflow.
-At first solve(-3) is called, then it will print -3
-call for solve(-4), then it will print -4
-call for solve(-5), in this way, it will keep making calls infinitely, as we will not reach zero, hence stack overflow error occurs.
+* Power Function
+* Print array
+* Indices of an Array
+* Check palindrome
---
## Problem 1 Power Function
-**Problem Statement**
+
+
+### Problem Statement
Given two integers **a** and **n**, find **an** using recursion.
-**Input**
+### Input
```
a = 2
n = 3
```
-**Output**
+### Output
```
8
```
-**Explanation**
+### Explanation
23 i.e, 2 * 2 * 2 = 8.
-:::warning
-Please take some time to think about the recursive approach on your own before reading further.....
-:::
-#### Brute Force Approach
+### Brute Force Approach
The above problem can be redefined as:
```
a ^ n = a * a * a......* a (n times).
@@ -179,20 +117,33 @@ Below is the algorithm:
* Return a * pow(a,n-1).
* Base Case:
* Base condition: if **n** = 0, then return 1.
-
-#### Pseudocode
-```cpp
-function pow(int a, int n) {
- if (n == 0) return 1;
- return a * pow(a, n - 1);
+### Pseudocode
+```
+function pow(int a, int n){
+ if(n == 0) return 1;
+ return a * pow(a,n-1);
}
```
-#### Complexity
-We shall calculate Time Complexity at the end.
+### Complexity
+
+Recursive Tree for 5^3^
+
-
-
-Now n==0 so return.
-
-Then solve(1) will print 1, then it will return, and after that solve(2) will print 2, in this way 1, 2, 3 will be printed as an output.
-
-
-
-
----
### Question
-What is the output of the following code for N = 3?
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
+What is recursion ?
-**Choices**
+### Choices
-- [ ] 1 2 3
+- [ ] A function that calls itself
+- [ ] A function that calls another function
+- [ ] A loop that repeats until a condition is met
+- [x] A function that solves a problem by breaking it into smaller subproblems and calling itself
-- [ ] 0 1 2
+---
-- [ ] 2 1 0
-- [x] 3 2 1
+### Question
+What data structure is used for function call tracing in recursion?
+### Choices
+- [ ] Queue
+- [ ] Linked List
+- [x] Stack
+- [ ] Array
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
-N=3
+---
-1. So first of all, solve(3) is called,
-1. Then solve(3) will first **print 3**, then call for solve(2) as n!=0,
-1. In this way solve(2) first **print 2**, then call for solve(1), and then solve(1) will **print 1**, then call for solve(0).
+### Question
+ Which of the following is the base case for calculating the factorial of a number using recursion?
-
+### Choices
+- [ ] N == 2
+- [x] N == 0
+- [ ] N == 1
+- [ ] N == -1
-Now n==0 so return.
+---
-Then solve(1) will return, after that solve(2) will return.
-In this way 3, 2, 1 will be printed as an output.
+### Question
+What is the time and space complexity for calculating factorial using recurion ?
+### Choices
+- [x] O(N), O(N)
+- [ ] O(N), O(1)
+- [ ] O(1), O(N)
+- [ ] O(N), O(log(N))
---
-### Question
-What is the output of the following code for N = -3?
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
-
-**Choices**
-- [ ] -3 -2 -1
-- [ ] 3 2 1
+### Question
+To compute Fibonacci(N) you need answers of ?
-- [x] Error; Stack Overflow
-- [ ] 1 2 3
+### Choices
+- [ ] fibonacci(N - 1)
+- [ ] Fibonacci(N - 2)
+- [x] Fibonacci(N - 1) and Fibonacci(N - 2)
+- [ ] none
-```cpp
-void solve(int N){
- if(N == 0)
- return;
- print(N);
- solve(N-1);
-}
-```
-`N = -3`
-
+---
+## Agenda
-In this question we will never reach 0, that's why we are getting stack overflow.
-At first solve(-3) is called, then it will print -3
-call for solve(-4), then it will print -4
-call for solve(-5), in this way, it will keep making calls infinitely, as we will not reach zero, hence stack overflow error occurs.
+* Power Function
+* Print array
+* Indices of an Array
+* Check palindrome
---
## Problem 1 Power Function
-**Problem Statement**
+
+
+### Problem Statement
Given two integers **a** and **n**, find **an** using recursion.
-**Input**
+### Input
```
a = 2
n = 3
```
-**Output**
+### Output
```
8
```
-**Explanation**
+### Explanation
23 i.e, 2 * 2 * 2 = 8.
-:::warning
-Please take some time to think about the recursive approach on your own before reading further.....
-:::
-#### Brute Force Approach
+### Brute Force Approach
The above problem can be redefined as:
```
a ^ n = a * a * a......* a (n times).
@@ -179,20 +117,33 @@ Below is the algorithm:
* Return a * pow(a,n-1).
* Base Case:
* Base condition: if **n** = 0, then return 1.
-
-#### Pseudocode
-```cpp
-function pow(int a, int n) {
- if (n == 0) return 1;
- return a * pow(a, n - 1);
+### Pseudocode
+```
+function pow(int a, int n){
+ if(n == 0) return 1;
+ return a * pow(a,n-1);
}
```
-#### Complexity
-We shall calculate Time Complexity at the end.
+### Complexity
+
+Recursive Tree for 5^3^
+ +
+#### T.C
+
+Number of calls = N+1
+Work done in each call = O(1)
+Total T.C = O(N)
+
+#### S.C
+
+The height of the tree is N, hence the S.C = O(N)
---
-### Power Function Optimized Approach 1
+## Power Function Another Approach
+
+### Optimized Approach 1
We can also divide pow(a, n) as follows:
if **n** is even:
```
@@ -202,7 +153,7 @@ if **n** is odd:
```
pow(a,n) = pow(a,n/2) * pow(a,n/2) * a
```
-#### Recursion Steps:
+### Recursion Steps:
* Assumption Step:
* Define a recursive function pow(a,n).
* Main Logic:
@@ -211,87 +162,60 @@ pow(a,n) = pow(a,n/2) * pow(a,n/2) * a
* Base Condition:
* if **n** is equal to 0, then return 1.
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
-
- if (n % 2 == 0) {
- return pow(a, n / 2) * pow(a, n / 2);
- } else {
- return pow(a, n / 2) * pow(a, n / 2) * a;
+### Pseudocode
+```
+Function pow(int a, int n){
+ if(n == 0) return 1;
+
+ if(n % 2 == 0) {
+ return pow(a,n/2) * pow(a,n/2);
+ }
+ else {
+ return pow(a,n/2) * pow(a,n/2) * a;
}
}
```
The above function will have more time complexity due to calling the same function twice. We will see it while calculating Time Compleixity.
----
-### Time Complexity of Power Function
+### Complexity
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
+Recursive Tree -
- if (n % 2 == 0) {
- return pow(a, n / 2) * pow(a, n / 2);
- } else {
- return pow(a, n / 2) * pow(a, n / 2) * a;
- }
-}
-```
+
+
+#### T.C
+
+Number of calls = N+1
+Work done in each call = O(1)
+Total T.C = O(N)
+
+#### S.C
+
+The height of the tree is N, hence the S.C = O(N)
---
-### Power Function Optimized Approach 1
+## Power Function Another Approach
+
+### Optimized Approach 1
We can also divide pow(a, n) as follows:
if **n** is even:
```
@@ -202,7 +153,7 @@ if **n** is odd:
```
pow(a,n) = pow(a,n/2) * pow(a,n/2) * a
```
-#### Recursion Steps:
+### Recursion Steps:
* Assumption Step:
* Define a recursive function pow(a,n).
* Main Logic:
@@ -211,87 +162,60 @@ pow(a,n) = pow(a,n/2) * pow(a,n/2) * a
* Base Condition:
* if **n** is equal to 0, then return 1.
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
-
- if (n % 2 == 0) {
- return pow(a, n / 2) * pow(a, n / 2);
- } else {
- return pow(a, n / 2) * pow(a, n / 2) * a;
+### Pseudocode
+```
+Function pow(int a, int n){
+ if(n == 0) return 1;
+
+ if(n % 2 == 0) {
+ return pow(a,n/2) * pow(a,n/2);
+ }
+ else {
+ return pow(a,n/2) * pow(a,n/2) * a;
}
}
```
The above function will have more time complexity due to calling the same function twice. We will see it while calculating Time Compleixity.
----
-### Time Complexity of Power Function
+### Complexity
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
+Recursive Tree -
- if (n % 2 == 0) {
- return pow(a, n / 2) * pow(a, n / 2);
- } else {
- return pow(a, n / 2) * pow(a, n / 2) * a;
- }
-}
-```
+ -Let Time taken to calculate pow(a,n) = f(n).
-```
-T(n) = 2 * T(n/2) + 1
-```
+#### T.C
-Substituting the value of T(n/2) = 2 * T(n/4) + 1
-```
-T(n) = 2 * [2 * T(n/4) + 1] + 1
- = 4 * T(n/4) + 3
- = 2^2 * T(n/2^2) + (2^2 - 1)
-```
+At level 1, the number of nodes are 2^0^
+At level 2, the number of nodes are 2^1^
+At level 3, the number of nodes are 2^2^
+.
+.
+.
+At level x, the number of nodes are 2^x-1^
-Substituting the value of T(n/4) = 2 * T(n/8) + 1
-```
-T(n) = 4 * [2 * T(n/8) + 1] + 3
- = 8 * T(n/8) + 7
- = 2^3 * T(n/2^3) + (2^3 - 1)
-```
-Substituting the value of T(n/8) = 2 * T(n/16) + 1
-```
-T(n) = 8 * [ 2 * T(n/16) + 1] + 7
- = 16 * T(n/16) + 15
- = 2^4 * T(n/2^4) + (2^4 - 1)
-```
-After, say, **k** iterations, we shall reach the base step.
-The equation will be:
-```
-T(n) = 2^k * T(n/2^k) + (2^k - 1)
-```
-The base case shall take contant time:
+Here, if we see one path from root to leaf, then reduction happens as n -> n/2 -> n/4 -> ... 1 which means height of the tree is log N.
+x = log N **or** N = 2^x^
-```
-T(0) = O(1) or T(1) will also be constant
-```
+
-Let Time taken to calculate pow(a,n) = f(n).
-```
-T(n) = 2 * T(n/2) + 1
-```
+#### T.C
-Substituting the value of T(n/2) = 2 * T(n/4) + 1
-```
-T(n) = 2 * [2 * T(n/4) + 1] + 1
- = 4 * T(n/4) + 3
- = 2^2 * T(n/2^2) + (2^2 - 1)
-```
+At level 1, the number of nodes are 2^0^
+At level 2, the number of nodes are 2^1^
+At level 3, the number of nodes are 2^2^
+.
+.
+.
+At level x, the number of nodes are 2^x-1^
-Substituting the value of T(n/4) = 2 * T(n/8) + 1
-```
-T(n) = 4 * [2 * T(n/8) + 1] + 3
- = 8 * T(n/8) + 7
- = 2^3 * T(n/2^3) + (2^3 - 1)
-```
-Substituting the value of T(n/8) = 2 * T(n/16) + 1
-```
-T(n) = 8 * [ 2 * T(n/16) + 1] + 7
- = 16 * T(n/16) + 15
- = 2^4 * T(n/2^4) + (2^4 - 1)
-```
-After, say, **k** iterations, we shall reach the base step.
-The equation will be:
-```
-T(n) = 2^k * T(n/2^k) + (2^k - 1)
-```
-The base case shall take contant time:
+Here, if we see one path from root to leaf, then reduction happens as n -> n/2 -> n/4 -> ... 1 which means height of the tree is log N.
+x = log N **or** N = 2^x^
-```
-T(0) = O(1) or T(1) will also be constant
-```
+ -```
-n/(2 ^ k) = 1
-n = 2^k
-k = log2(n)
-```
-Hence we can say that
-```
-T(n) = n * T(1) + (n - 1)
- = O(n)
-```
+Total calls are -
+2^0^ + 2^1^ + 2^2^ + ...... + 2^x-1^
+This is sum of GP, a=1, r=2, #terms = x
-Let's see time complexity of the optimised pow function.
+Formula = a(r^#terms^ - 1) / (r-1)
+ = 1(2^x^ - 1) / (2-1)
+ = 2^x^ = N
+Time taken by each call = O(1)
+Total Time Complexity = O(N)
+
+#### S.C
+
+The height = S.C is O(log N)
---
-### Power Function Optimized Approach - Fast Power
+## Power Function Optimized Approach - Fast Power
+
In above approach, we are calling function **pow(a, n/2)** twice. Rather, we can just call it once and use the result twice.
Below is the algorithm:
@@ -304,244 +228,374 @@ Below is the algorithm:
* Base Condition:
* if **n = 0**, then return **1**.
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
-
- int p = pow(a, n / 2);
-
- if (n % 2 == 0) {
+### Pseudocode
+```
+Function pow(int a, int n){
+ if(n == 0) return 1;
+
+ int p = pow(a, n/2);
+
+ if(n % 2 == 0) {
return p * p;
- } else {
+ }
+ else {
return p * p * a;
}
}
```
> Note: The above function is known as Fast Power or Fast Exponentiation.
+### Complexity
+
+Recursive Tree -
+
+
-```
-n/(2 ^ k) = 1
-n = 2^k
-k = log2(n)
-```
-Hence we can say that
-```
-T(n) = n * T(1) + (n - 1)
- = O(n)
-```
+Total calls are -
+2^0^ + 2^1^ + 2^2^ + ...... + 2^x-1^
+This is sum of GP, a=1, r=2, #terms = x
-Let's see time complexity of the optimised pow function.
+Formula = a(r^#terms^ - 1) / (r-1)
+ = 1(2^x^ - 1) / (2-1)
+ = 2^x^ = N
+Time taken by each call = O(1)
+Total Time Complexity = O(N)
+
+#### S.C
+
+The height = S.C is O(log N)
---
-### Power Function Optimized Approach - Fast Power
+## Power Function Optimized Approach - Fast Power
+
In above approach, we are calling function **pow(a, n/2)** twice. Rather, we can just call it once and use the result twice.
Below is the algorithm:
@@ -304,244 +228,374 @@ Below is the algorithm:
* Base Condition:
* if **n = 0**, then return **1**.
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
-
- int p = pow(a, n / 2);
-
- if (n % 2 == 0) {
+### Pseudocode
+```
+Function pow(int a, int n){
+ if(n == 0) return 1;
+
+ int p = pow(a, n/2);
+
+ if(n % 2 == 0) {
return p * p;
- } else {
+ }
+ else {
return p * p * a;
}
}
```
> Note: The above function is known as Fast Power or Fast Exponentiation.
+### Complexity
+
+Recursive Tree -
+
+ +
+#### T.C
+The number of calls are log N
+Time taken by each call is O(1)
+Total T.C = O(log N)
+
+#### S.C
+The height = S.C is O(log N)
+
---
-### Time Complexity of Fast Power
+## Problem 2 Print array using recursion
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
- long p = pow(a, n / 2);
+### Problem Statement
- if (n % 2 == 0) {
- return p * p;
- } else {
- return p * p * a;
- }
-}
-```
-Let time taken to calculate pow(a,n) = f(n).
-Recurrence Relation is:
-```
-T(n) = T(n/2) + 1
-```
+Given an array of integers, write a recursive function to print all the elements of the array.
-Substituting the value of T(n/2) = T(n/4) + 1
-```
-T(n) = [T(n/4) + 1] + 1
- = T(n/4) + 2
-```
+Example
+
+Input:
+`A = [1, 2, 3, 4, 5]`
+
+Output:
+`1 2 3 4 5`
+
+### Approach
+To print an array using recursion:
+
+- Base Case: If the index is equal to the size of the array, then return.
+- Print the element corresponding to the index.
+- Recursively call the function by incrementing the index by 1.
-Substituting the value of T(n/4) = T(n/8) + 1
+
+### Pseudocode
+
+```python
+function printArray(arr, index):
+ if n == arr.size():
+ return
+ print arr[index]
+ printArray(arr, index + 1)
```
-T(n) = [T(n/8) + 1] + 2
- = T(n/8) + 3
+
+
+### Complexity Analysis
+Time Complexity: O(n), where n is the size of the array.
+
+---
+
+### Question
+
+To find the **sum of the array** using recursion, what is the Recursive state to be used ?
+**Tip:** We have used `max(arr[index], findMax(arr, index + 1))` to find the maximum of the array.
+
+### Choices
+- [x] arr[index] + findSum(arr, index + 1)
+- [ ] max(arr[index], findSum(arr, index + 1))
+- [ ] arr[index] + max(arr[index], findSum(arr, index + 1))
+- [ ] arr[index] - findSum(arr, index + 1)
+
+
+### Explanation:
+
+For finding the maximum of the array, our goal on each step is to compare two elements, one is the current element and another one is the maximum of the remaining array.
+
+The same idea goes for sum of the array also, here our goal on each step is to return the sum of two numbers, one is the current number and another one is the sum of the remaining array.
+
+The entire pseudo code will look as follows,
+
+```javascript
+function findSum(arr, index):
+ if index == arr.size() - 1:
+ return arr[index]
+ return arr[index] + findSum(arr, index + 1))
```
-Substituting the value of T(n/8) = T(n/16) + 1
+
+---
+## Problem 3 All Indices Of Array
+
+
+### Problem Statement
+
+Given an array of integers A with N elements and a target integer B, the task is to find all the indices at which B occurs in the array.
+
+It is guaranteed that the target B, exist atleast once in the Array A.
+
+### Example
+
+Input :
```
-T(n) = [T(n/16) + 1] + 3
- = T(n/16) + 4
+A = [4, 5, 3, 1, 5, 4, 5]
+B = 5
```
-After say **k** iterations, we shall reach to the base step.
-The equation will be:
+
+Output :
```
-T(n) = T(n/2^k) + k
+[1, 4, 6]
```
-Base case shall take constant time:
+
+
+---
+
+
+### Question
+Find all the Indices at which B occurs in the given array, A:
```
-T(0) = O(1) or T(1) will also be constant
+A = [1, 2, 3, 1, 1]
+B = 1
```
+### Choices
+- [ ] [1, 2, 4]
+- [ ] [0, 1, 2, 3, 4]
+- [ ] [1, 5]
+- [x] [0, 3, 4]
+
+---
+## All Indices Of Array Observation
+
+
+### Observation
+
+Here we don't know about size of the array beforehand. So, in our function, we shall be taking a variable "cnt", to track the number of B found so far so that we can create a new array(with cnt size) in base case and return it.
+
+Now, on our way back from recursion, we can keep filling the elements in array.
+Hence, to solve this problem using recursion, we will include two additional variables in the recursive call:
+* one to track the **index of the current element** and
+* another to **count the occurrences** of the target integer.
+
+**Recursive Function**:
+**`recur(A, B, index, cnt)`**
+
+### Steps
+
+1. **Assumption:** **`recur(A, B, index, cnt)`** return an array with indices where B is found from index till end.
+2. **Main Logic:** We can break the problem for 2 different cases -
+ * When B is present at index
+ * **`recur(A, B, index+1, cnt+1)`**
+ * When B is not present
+ * **`recur(A, B, index+1, cnt)`**
+3. **Base Case:**
```
-n/(2 ^ k) = 1
-n = 2^k
-k = log2(n)
+if(index == N) {
+ return new ans[cnt]
+}
```
-Hence we can say that
+
+### Dryrun
+
+Input:
```
-T(n) = T(1) + log2(n)
- = O(log2(n))
+A = [1, 2, 3, 2, 4, 4, 2]
+B = 2
```
----
-### Question
-How many recursive call in the FAST pow(2,5)?
+Initial Call -> (A, B, 0, 0)
-Choose the correct answer
+|call no. | A | B | A[index] | recurive call |
+|--|---|---|--| --|
+|1 | A | B | A[0] = 1 | (A, B, index=1, count=0) |
+|2 | A | B | A[1] = **2**(found)|(A, B, index=2, count=1) |
+|3 | A | B | A[2] = 3|(A, B, index=3, count=1) |
+|4 | A | B | A[3] = **2**(found)|(A, B, index=4, count=2) |
+|5 | A | B | A[4] = 4|(A, B, index=5, count=2) |
+|6 | A | B | A[5] = 4|(A, B, index=6, count=2) |
+|7 | A | B | A[6] = **2**(found)|(A, B, index=7, count=3)
-**Choices**
-- [ ] 0
-- [ ] 2
-- [x] 4
-- [ ] 5
+When **`index reaches 7`**, we **`create array of size=3(count)`**, and **`return ans[3]`**
+`ans = [0, 0, 0]`
+While coming back from recursion, in call number 2, 4, 7, the ans array will get updated
+1. Call Number 2, update ans[0] = 1
+2. Call Number 4, update ans[1] = 3
+3. Call Number 7, update ans[2] = 6
+---
+## All Indices Of Array Pseudo code
-This is ~ log N calls.
-Therefore, time complexity of sum of digits = O(log N) * 1 = O(log N)
+### Pseudo code
----
-### Space Complexity of pow(a,n)
+```java
+int[] recur(int[] A, int B, int index, int count) {
+ if (index == A.length)
+ return new int[count];
-There are total **log2(N)** recursive calls as shown below:
-```
-pow(a,0)
-pow(a,1)
-pow(a,2)
-pow(a,4)
----------------
----------------
----------------
-sumofdigits(a,N/2)
-sumofdigits(a,N)
+ if (A[index] == B){
+ int[] ans = recur(A, B, index + 1, count + 1);
+ ans[count] = idx;
+ }
+ else {
+ int[] ans = recur(A, B, index + 1, count);
+ }
+
+ return ans;
+}
```
-Hence, the total O(log2(N)) space required to execute all the recursive calls.
---
-### Problem 2 Tower of Hanoi
-There are n disks placed on tower A of different sizes.
+## Problem 4 Check palindrome using recursion
+
-**Goal**
-Move all disks from tower A to C using tower B if needed.
+### Problem Statement
+Given a string, write a recursive function to check if it is a palindrome.
-**Constraint**
-- Only 1 disk can be moved at a time.
-- Larger disk can not be placed on a small disk at any step.
+### Example
-Print the movement of disks from A to C in minimum steps.
+Input:
+str = "radar"
-**Example 1**
+Output:
+True
-**Input:** N = 1
+Input:
+str = "area"
-
+
+#### T.C
+The number of calls are log N
+Time taken by each call is O(1)
+Total T.C = O(log N)
+
+#### S.C
+The height = S.C is O(log N)
+
---
-### Time Complexity of Fast Power
+## Problem 2 Print array using recursion
-#### Pseudocode
-```cpp
-Function pow(int a, int n) {
- if (n == 0) return 1;
- long p = pow(a, n / 2);
+### Problem Statement
- if (n % 2 == 0) {
- return p * p;
- } else {
- return p * p * a;
- }
-}
-```
-Let time taken to calculate pow(a,n) = f(n).
-Recurrence Relation is:
-```
-T(n) = T(n/2) + 1
-```
+Given an array of integers, write a recursive function to print all the elements of the array.
-Substituting the value of T(n/2) = T(n/4) + 1
-```
-T(n) = [T(n/4) + 1] + 1
- = T(n/4) + 2
-```
+Example
+
+Input:
+`A = [1, 2, 3, 4, 5]`
+
+Output:
+`1 2 3 4 5`
+
+### Approach
+To print an array using recursion:
+
+- Base Case: If the index is equal to the size of the array, then return.
+- Print the element corresponding to the index.
+- Recursively call the function by incrementing the index by 1.
-Substituting the value of T(n/4) = T(n/8) + 1
+
+### Pseudocode
+
+```python
+function printArray(arr, index):
+ if n == arr.size():
+ return
+ print arr[index]
+ printArray(arr, index + 1)
```
-T(n) = [T(n/8) + 1] + 2
- = T(n/8) + 3
+
+
+### Complexity Analysis
+Time Complexity: O(n), where n is the size of the array.
+
+---
+
+### Question
+
+To find the **sum of the array** using recursion, what is the Recursive state to be used ?
+**Tip:** We have used `max(arr[index], findMax(arr, index + 1))` to find the maximum of the array.
+
+### Choices
+- [x] arr[index] + findSum(arr, index + 1)
+- [ ] max(arr[index], findSum(arr, index + 1))
+- [ ] arr[index] + max(arr[index], findSum(arr, index + 1))
+- [ ] arr[index] - findSum(arr, index + 1)
+
+
+### Explanation:
+
+For finding the maximum of the array, our goal on each step is to compare two elements, one is the current element and another one is the maximum of the remaining array.
+
+The same idea goes for sum of the array also, here our goal on each step is to return the sum of two numbers, one is the current number and another one is the sum of the remaining array.
+
+The entire pseudo code will look as follows,
+
+```javascript
+function findSum(arr, index):
+ if index == arr.size() - 1:
+ return arr[index]
+ return arr[index] + findSum(arr, index + 1))
```
-Substituting the value of T(n/8) = T(n/16) + 1
+
+---
+## Problem 3 All Indices Of Array
+
+
+### Problem Statement
+
+Given an array of integers A with N elements and a target integer B, the task is to find all the indices at which B occurs in the array.
+
+It is guaranteed that the target B, exist atleast once in the Array A.
+
+### Example
+
+Input :
```
-T(n) = [T(n/16) + 1] + 3
- = T(n/16) + 4
+A = [4, 5, 3, 1, 5, 4, 5]
+B = 5
```
-After say **k** iterations, we shall reach to the base step.
-The equation will be:
+
+Output :
```
-T(n) = T(n/2^k) + k
+[1, 4, 6]
```
-Base case shall take constant time:
+
+
+---
+
+
+### Question
+Find all the Indices at which B occurs in the given array, A:
```
-T(0) = O(1) or T(1) will also be constant
+A = [1, 2, 3, 1, 1]
+B = 1
```
+### Choices
+- [ ] [1, 2, 4]
+- [ ] [0, 1, 2, 3, 4]
+- [ ] [1, 5]
+- [x] [0, 3, 4]
+
+---
+## All Indices Of Array Observation
+
+
+### Observation
+
+Here we don't know about size of the array beforehand. So, in our function, we shall be taking a variable "cnt", to track the number of B found so far so that we can create a new array(with cnt size) in base case and return it.
+
+Now, on our way back from recursion, we can keep filling the elements in array.
+Hence, to solve this problem using recursion, we will include two additional variables in the recursive call:
+* one to track the **index of the current element** and
+* another to **count the occurrences** of the target integer.
+
+**Recursive Function**:
+**`recur(A, B, index, cnt)`**
+
+### Steps
+
+1. **Assumption:** **`recur(A, B, index, cnt)`** return an array with indices where B is found from index till end.
+2. **Main Logic:** We can break the problem for 2 different cases -
+ * When B is present at index
+ * **`recur(A, B, index+1, cnt+1)`**
+ * When B is not present
+ * **`recur(A, B, index+1, cnt)`**
+3. **Base Case:**
```
-n/(2 ^ k) = 1
-n = 2^k
-k = log2(n)
+if(index == N) {
+ return new ans[cnt]
+}
```
-Hence we can say that
+
+### Dryrun
+
+Input:
```
-T(n) = T(1) + log2(n)
- = O(log2(n))
+A = [1, 2, 3, 2, 4, 4, 2]
+B = 2
```
----
-### Question
-How many recursive call in the FAST pow(2,5)?
+Initial Call -> (A, B, 0, 0)
-Choose the correct answer
+|call no. | A | B | A[index] | recurive call |
+|--|---|---|--| --|
+|1 | A | B | A[0] = 1 | (A, B, index=1, count=0) |
+|2 | A | B | A[1] = **2**(found)|(A, B, index=2, count=1) |
+|3 | A | B | A[2] = 3|(A, B, index=3, count=1) |
+|4 | A | B | A[3] = **2**(found)|(A, B, index=4, count=2) |
+|5 | A | B | A[4] = 4|(A, B, index=5, count=2) |
+|6 | A | B | A[5] = 4|(A, B, index=6, count=2) |
+|7 | A | B | A[6] = **2**(found)|(A, B, index=7, count=3)
-**Choices**
-- [ ] 0
-- [ ] 2
-- [x] 4
-- [ ] 5
+When **`index reaches 7`**, we **`create array of size=3(count)`**, and **`return ans[3]`**
+`ans = [0, 0, 0]`
+While coming back from recursion, in call number 2, 4, 7, the ans array will get updated
+1. Call Number 2, update ans[0] = 1
+2. Call Number 4, update ans[1] = 3
+3. Call Number 7, update ans[2] = 6
+---
+## All Indices Of Array Pseudo code
-This is ~ log N calls.
-Therefore, time complexity of sum of digits = O(log N) * 1 = O(log N)
+### Pseudo code
----
-### Space Complexity of pow(a,n)
+```java
+int[] recur(int[] A, int B, int index, int count) {
+ if (index == A.length)
+ return new int[count];
-There are total **log2(N)** recursive calls as shown below:
-```
-pow(a,0)
-pow(a,1)
-pow(a,2)
-pow(a,4)
----------------
----------------
----------------
-sumofdigits(a,N/2)
-sumofdigits(a,N)
+ if (A[index] == B){
+ int[] ans = recur(A, B, index + 1, count + 1);
+ ans[count] = idx;
+ }
+ else {
+ int[] ans = recur(A, B, index + 1, count);
+ }
+
+ return ans;
+}
```
-Hence, the total O(log2(N)) space required to execute all the recursive calls.
---
-### Problem 2 Tower of Hanoi
-There are n disks placed on tower A of different sizes.
+## Problem 4 Check palindrome using recursion
+
-**Goal**
-Move all disks from tower A to C using tower B if needed.
+### Problem Statement
+Given a string, write a recursive function to check if it is a palindrome.
-**Constraint**
-- Only 1 disk can be moved at a time.
-- Larger disk can not be placed on a small disk at any step.
+### Example
-Print the movement of disks from A to C in minimum steps.
+Input:
+str = "radar"
-**Example 1**
+Output:
+True
-**Input:** N = 1
+Input:
+str = "area"
- +Output:
+False
-**Explanation:**
-
+Output:
+False
-**Explanation:**
- +### Observation
-**Output:**
-1: A -> C
+To ensure a string is a palindrome, each pair of characters symmetrically positioned around the center must match.
-**Example 2**
-**Input:** N = 2
-
+### Observation
-**Output:**
-1: A -> C
+To ensure a string is a palindrome, each pair of characters symmetrically positioned around the center must match.
-**Example 2**
-**Input:** N = 2
- +Lets keep to pointers, one on the left and another on the right.
-**Explanation:**
-1: A -> B
-
+Lets keep to pointers, one on the left and another on the right.
-**Explanation:**
-1: A -> B
- +
+ -2: A -> C
-
-2: A -> C
- +Here the last checking can be ignored by using (left_pointer < right_pointer).
-1: B -> C
-
+Here the last checking can be ignored by using (left_pointer < right_pointer).
-1: B -> C
- +### Dry Run
-**Output:**
-1: A -> B
-2: A -> C
-1: B -> C
+Lets breakdown the problem into smaller subproblem.
-**Example 3**
-**Input:** N = 3
-
+### Dry Run
-**Output:**
-1: A -> B
-2: A -> C
-1: B -> C
+Lets breakdown the problem into smaller subproblem.
-**Example 3**
-**Input:** N = 3
- +To ensure a string is palindrome, the first and the last character has to be same and the remainging string also has to be palindrome.
-**Explanation:**
-1: A -> C
-2: A -> B
-1: C -> B
+
+To ensure a string is palindrome, the first and the last character has to be same and the remainging string also has to be palindrome.
-**Explanation:**
-1: A -> C
-2: A -> B
-1: C -> B
+ -
- +Here pali(str, left + 1, right - 1) is the recursive step.
-3: A -> C
-
+Here pali(str, left + 1, right - 1) is the recursive step.
-3: A -> C
- +We check the characters recursiving by incrementing the left pointer and decrementing the right pointer.
-1: B -> A
-2: B -> C
-1: A -> C
+
+We check the characters recursiving by incrementing the left pointer and decrementing the right pointer.
-1: B -> A
-2: B -> C
-1: A -> C
+ -
- -**Output:**
-1: A -> C
-2: A -> B
-1: C -> B
-3: A -> C
-1: B -> A
-2: B -> C
-1: A -> C
+When the left and right pointers meets the center, then the recusion has to stop and return True.
-#### n disks
+Since all the characters around the center has a match.
-
-**Output:**
-1: A -> C
-2: A -> B
-1: C -> B
-3: A -> C
-1: B -> A
-2: B -> C
-1: A -> C
+When the left and right pointers meets the center, then the recusion has to stop and return True.
-#### n disks
+Since all the characters around the center has a match.
- +The base case will be
-**Step 1:**
-Move (n-1) disks from A to B
-
+The base case will be
-**Step 1:**
-Move (n-1) disks from A to B
- +```python
+if left >= right:
+ return True
+```
+
+
+### Approach (in short)
+To check if a string is a palindrome using recursion:
+
+- Base Case: If left >= right then return True.
+- Compare the left and right characters of the string.
+- Recursively check if the substring excluding the first and last characters is a palindrome
+
+---
+## Check Palindrome Using Recursion Pseudo Code
-**Step 2:**
-Move n disk to C
-
+```python
+if left >= right:
+ return True
+```
+
+
+### Approach (in short)
+To check if a string is a palindrome using recursion:
+
+- Base Case: If left >= right then return True.
+- Compare the left and right characters of the string.
+- Recursively check if the substring excluding the first and last characters is a palindrome
+
+---
+## Check Palindrome Using Recursion Pseudo Code
-**Step 2:**
-Move n disk to C
- -**Step 3:**
-Move (n-1) disks from B to C
+### Pseudocode
+
+```python
+function isPalindrome(str, left, right):
+ if left >= right:
+ return True
+ if str[left] != str[right]:
+ return False
+ return isPalindrome(str, left+1, right-1)
+```
-
-**Step 3:**
-Move (n-1) disks from B to C
+### Pseudocode
+
+```python
+function isPalindrome(str, left, right):
+ if left >= right:
+ return True
+ if str[left] != str[right]:
+ return False
+ return isPalindrome(str, left+1, right-1)
+```
- +### Complexity Analysis
+Time Complexity: O(n), where n is the length of the string.
-#### Pseudocode
+---
+
+
+### Question
+What is the output of the following code for N = 3?
```cpp
- src temp dest
-void TOH(int n, A, B, C){
- 1. if(n == 0)
- return;
- 2. TOH(n - 1, A, C, B); // move n-1 disks A->B
- 3. print(n : A -> C); // moving n disk A->C
- 4. TOH(n - 1, B, A, C); // move n-1 disks B->C
+void solve(int N){
+ if(N == 0)
+ return;
+ print(N);
+ solve(N-1);
+ print(N);
}
```
-#### Dry Run
-**n = 3**
-
+### Choices
+
+- [x] 3 2 1 1 2 3
+- [ ] 3 2 1 0
+- [ ] 1 2 3 3 2 1
+- [ ] 1 2 3
+
+
+### Explanation
-
+### Complexity Analysis
+Time Complexity: O(n), where n is the length of the string.
-#### Pseudocode
+---
+
+
+### Question
+What is the output of the following code for N = 3?
```cpp
- src temp dest
-void TOH(int n, A, B, C){
- 1. if(n == 0)
- return;
- 2. TOH(n - 1, A, C, B); // move n-1 disks A->B
- 3. print(n : A -> C); // moving n disk A->C
- 4. TOH(n - 1, B, A, C); // move n-1 disks B->C
+void solve(int N){
+ if(N == 0)
+ return;
+ print(N);
+ solve(N-1);
+ print(N);
}
```
-#### Dry Run
-**n = 3**
-
+### Choices
+
+- [x] 3 2 1 1 2 3
+- [ ] 3 2 1 0
+- [ ] 1 2 3 3 2 1
+- [ ] 1 2 3
+
+
+### Explanation
- +First we start at N=3, print(3)
+go to N=2, print(2)
+go to N=1, print(1)
+go to N=0, return
+come back to N=1, print(1)
+come back to N=2, print(2)
+come back to N=3, print(3)
+
+Hence the output is 3 2 1 1 2 3
+
+---
+
+
+### Question
+What is the output of the following code for N = -3?
+```cpp
+void solve(int N){
+ if(N == 0)
+ return;
+ print(N);
+ solve(N-1);
+}
+```
-**Output:**
-1: A -> C
-2: A -> B
-1: C -> B
-3: A -> C
-1: B -> A
-2: B -> C
-1: A -> C
+### Choices
-#### Time Complexity
-It can be observed in terms of number of steps taken for N
-
+First we start at N=3, print(3)
+go to N=2, print(2)
+go to N=1, print(1)
+go to N=0, return
+come back to N=1, print(1)
+come back to N=2, print(2)
+come back to N=3, print(3)
+
+Hence the output is 3 2 1 1 2 3
+
+---
+
+
+### Question
+What is the output of the following code for N = -3?
+```cpp
+void solve(int N){
+ if(N == 0)
+ return;
+ print(N);
+ solve(N-1);
+}
+```
-**Output:**
-1: A -> C
-2: A -> B
-1: C -> B
-3: A -> C
-1: B -> A
-2: B -> C
-1: A -> C
+### Choices
-#### Time Complexity
-It can be observed in terms of number of steps taken for N
- +- [ ] -3 -2 -1
+- [ ] 3 2 1
+- [x] Error; Stack Overflow
+- [ ] 1 2 3
-#### Space Complexity
-
+- [ ] -3 -2 -1
+- [ ] 3 2 1
+- [x] Error; Stack Overflow
+- [ ] 1 2 3
-#### Space Complexity
- +### Explanation
+In this question we will never reach 0, and get stack overflow.
+At first solve(-3) is called, then it will print -3
+call for solve(-4), then it will print -4
+call for solve(-5), in this way, it will keep making calls infinitely, as we will not reach zero, hence stack overflow error occurs.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md b/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md
index e3887c9..db357ea 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md
@@ -1,6 +1,7 @@
# Searching 1: Binary Search on Array
----
+
+## Introduction to Searching
### Introduction to Searching - Story
@@ -9,52 +10,55 @@
* When you go to the police, you tell them what to search for—the target—and where to search—the search space.
* It is easy to look for a word in the dictionary as compared to searching for a word in a book or newspaper. This is because along with the target element, we also have defined search space(alphabetical order).
* In the Phone book as well, we have names sorted in the contacts list, so it's easier to find a person's number.
-* **Search space** - The area where we know the result exists and we search there only
-* **Target** - The item we are looking for
-* **Condition** - Some condition to discard some part of the search space repeatedly to make it smaller and finally reach the result.
-* **Binary Search** - divide the search space into two parts and repeatedly keep on neglecting one-half of the search space.
+ * **Search space** - The area where we know the result exists and we search there only
+ * **Target** - The item we are looking for
+ * **Condition** - Some condition to discard some part of the search space repeatedly to make it smaller and finally reach the result.
+ * **Binary Search** - divide the search space into two parts and repeatedly keep on neglecting one-half of the search space.
---
+
### Question
In binary search, at each step, the search range is typically:
-**Choices**
+### Choices
- [x] Halved
- [ ] Tripled
- [ ] Doubled
- [ ] Reduced by one
---
-## Binary Search
+## Search element K
+
+### Problem Statement
-### Binary Search Question
-Given a sorted array with distinct elements, search the index of an element **k**, if k is not present return -1.
+Given a sorted array with distinct elements, search the index of an element **k**, if k is not present, return -1.
arr[] =
| 3 | 6 | 9 | 12 | 14 | 19 | 20 | 23 | 25 | 27 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
-#### Brute Force Approach - Linear Search
-* We can traverse the array and compare each element with the target element. This is done until we find the target element or all the elements of the array are compared. This method is called linear search and the time complexity in the worst case is **O(N)** where **N** is the number of elements in the array.
-* We can perform the same operation with less number of comparisons and with better time complexity using Binary Search as the array is sorted.
-#### Binary Search Approach
-* Binary search has three elements,
- * **Search space -** array
- * **target -** we are given a target element to be found from the array
- * **condition ->**
- * array is sorted, say I am at some random position, if I compare the current element with the target element.
- * If `current_element > target_element`, I can discard all the element appearing before current element and the target_element as they will always be smaller than current element.
- * Similarly, if the `current_element < target_element`, the target element and the elements appearing after it can be discareded.
- * We have all the three elements and thus, binary search can be easily applied to it.
-* Let us take the middle index.
-* if `arr[mid] == k`, i.e. we found the target, we return the index of the target.
-* if `arr[mid] < k` i.e. the target exists on the right side of the array so the left half is of no use and we can move to the right.
-* Similarly, if `arr[mid] > k` i.e. the target exists on the left, and the right half can be discarded.
+
+### Brute Force Approach - Linear Search
+* We can use a linear search to compare each element in the array with the target until it's found, which has a worst-case time complexity of O(N).
+* If the array is sorted, we can use Binary Search for faster results with fewer comparisons.
+
+
+
+### Binary Search Approach
+
+**Search space:** The array
+
+**Target:** The element we want to find in the array.
+
+**Condition:**
+* If the array is sorted, we can use the current element’s value to determine which part of the array to search.
+* If the current element is greater than the target, we can ignore all elements before it since they will also be greater than the target.
+* If the current element is smaller than the target, we can ignore all elements after it since they will be smaller.
+### Explanation
+In this question we will never reach 0, and get stack overflow.
+At first solve(-3) is called, then it will print -3
+call for solve(-4), then it will print -4
+call for solve(-5), in this way, it will keep making calls infinitely, as we will not reach zero, hence stack overflow error occurs.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md b/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md
index e3887c9..db357ea 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Searching 1 Binary Search on Array.md
@@ -1,6 +1,7 @@
# Searching 1: Binary Search on Array
----
+
+## Introduction to Searching
### Introduction to Searching - Story
@@ -9,52 +10,55 @@
* When you go to the police, you tell them what to search for—the target—and where to search—the search space.
* It is easy to look for a word in the dictionary as compared to searching for a word in a book or newspaper. This is because along with the target element, we also have defined search space(alphabetical order).
* In the Phone book as well, we have names sorted in the contacts list, so it's easier to find a person's number.
-* **Search space** - The area where we know the result exists and we search there only
-* **Target** - The item we are looking for
-* **Condition** - Some condition to discard some part of the search space repeatedly to make it smaller and finally reach the result.
-* **Binary Search** - divide the search space into two parts and repeatedly keep on neglecting one-half of the search space.
+ * **Search space** - The area where we know the result exists and we search there only
+ * **Target** - The item we are looking for
+ * **Condition** - Some condition to discard some part of the search space repeatedly to make it smaller and finally reach the result.
+ * **Binary Search** - divide the search space into two parts and repeatedly keep on neglecting one-half of the search space.
---
+
### Question
In binary search, at each step, the search range is typically:
-**Choices**
+### Choices
- [x] Halved
- [ ] Tripled
- [ ] Doubled
- [ ] Reduced by one
---
-## Binary Search
+## Search element K
+
+### Problem Statement
-### Binary Search Question
-Given a sorted array with distinct elements, search the index of an element **k**, if k is not present return -1.
+Given a sorted array with distinct elements, search the index of an element **k**, if k is not present, return -1.
arr[] =
| 3 | 6 | 9 | 12 | 14 | 19 | 20 | 23 | 25 | 27 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
-#### Brute Force Approach - Linear Search
-* We can traverse the array and compare each element with the target element. This is done until we find the target element or all the elements of the array are compared. This method is called linear search and the time complexity in the worst case is **O(N)** where **N** is the number of elements in the array.
-* We can perform the same operation with less number of comparisons and with better time complexity using Binary Search as the array is sorted.
-#### Binary Search Approach
-* Binary search has three elements,
- * **Search space -** array
- * **target -** we are given a target element to be found from the array
- * **condition ->**
- * array is sorted, say I am at some random position, if I compare the current element with the target element.
- * If `current_element > target_element`, I can discard all the element appearing before current element and the target_element as they will always be smaller than current element.
- * Similarly, if the `current_element < target_element`, the target element and the elements appearing after it can be discareded.
- * We have all the three elements and thus, binary search can be easily applied to it.
-* Let us take the middle index.
-* if `arr[mid] == k`, i.e. we found the target, we return the index of the target.
-* if `arr[mid] < k` i.e. the target exists on the right side of the array so the left half is of no use and we can move to the right.
-* Similarly, if `arr[mid] > k` i.e. the target exists on the left, and the right half can be discarded.
+
+### Brute Force Approach - Linear Search
+* We can use a linear search to compare each element in the array with the target until it's found, which has a worst-case time complexity of O(N).
+* If the array is sorted, we can use Binary Search for faster results with fewer comparisons.
+
+
+
+### Binary Search Approach
+
+**Search space:** The array
+
+**Target:** The element we want to find in the array.
+
+**Condition:**
+* If the array is sorted, we can use the current element’s value to determine which part of the array to search.
+* If the current element is greater than the target, we can ignore all elements before it since they will also be greater than the target.
+* If the current element is smaller than the target, we can ignore all elements after it since they will be smaller.
 -#### Dry Run
+### Dry Run
Let us dry run binary search for the array:
@@ -91,85 +95,72 @@ Let us dry run binary search for the array:
-#### Binary Search Pseudo Code
+### Binary Search Pseudo Code
```javascript
-int search(int arr[], int N, int k) {
- lo = 0, hi = N - 1;
- while (lo <= hi) {
- mid = lo + (hi + lo) / 2;
- if (arr[mid] == k) {
- return mid;
- } else if (arr[mid] < k) {
- lo = mid + 1;
- } else {
- hi = mid - 1;
+int search(int arr[], int N, int k){
+ lo = 0, hi = N - 1;
+ while(lo <= hi){
+ mid = lo + (hi + lo) / 2;
+ if(arr[mid] == k) {
+ return mid;
+ }else if(arr[mid] < k){
+ lo = mid + 1;
+ }else{
+ hi = mid - 1;
+ }
}
- }
- return -1;
+ return -1;
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(log N)
**Space Complexity:** O(1)
---
+
### Question
If the element 'k' is found in a sorted array, what will be the time complexity of binary search?
-**Choices**
+### Choices
- [ ] O(1)
- [x] O(log n)
- [ ] O(n)
- [ ] O(n^2)
---
-### Best Practices - Binary Search
-
-
-* Some write the formula of mid calculation as
-#### Dry Run
+### Dry Run
Let us dry run binary search for the array:
@@ -91,85 +95,72 @@ Let us dry run binary search for the array:
-#### Binary Search Pseudo Code
+### Binary Search Pseudo Code
```javascript
-int search(int arr[], int N, int k) {
- lo = 0, hi = N - 1;
- while (lo <= hi) {
- mid = lo + (hi + lo) / 2;
- if (arr[mid] == k) {
- return mid;
- } else if (arr[mid] < k) {
- lo = mid + 1;
- } else {
- hi = mid - 1;
+int search(int arr[], int N, int k){
+ lo = 0, hi = N - 1;
+ while(lo <= hi){
+ mid = lo + (hi + lo) / 2;
+ if(arr[mid] == k) {
+ return mid;
+ }else if(arr[mid] < k){
+ lo = mid + 1;
+ }else{
+ hi = mid - 1;
+ }
}
- }
- return -1;
+ return -1;
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(log N)
**Space Complexity:** O(1)
---
+
### Question
If the element 'k' is found in a sorted array, what will be the time complexity of binary search?
-**Choices**
+### Choices
- [ ] O(1)
- [x] O(log n)
- [ ] O(n)
- [ ] O(n^2)
---
-### Best Practices - Binary Search
-
-
-* Some write the formula of mid calculation as  but it is incorrect, as in some cases it may lead to overflow.
-* e.g, Let us assume that maximum number stored by a particular data type is `100` (It's Integer.Max_Int but just to make maths easy, assuming its 100), and the number of elements in the array is `100` for which last index will be `99` for zero indexing and thus, is in the limit.
-* There is the posibility that the target element is at the position `98` and value of `low = 98` and `high = 99`. When we calculate `mid` for this scenario, the `high` and the `low` are in limits but while calculating the mid
but it is incorrect, as in some cases it may lead to overflow.
-* e.g, Let us assume that maximum number stored by a particular data type is `100` (It's Integer.Max_Int but just to make maths easy, assuming its 100), and the number of elements in the array is `100` for which last index will be `99` for zero indexing and thus, is in the limit.
-* There is the posibility that the target element is at the position `98` and value of `low = 98` and `high = 99`. When we calculate `mid` for this scenario, the `high` and the `low` are in limits but while calculating the mid  first the sum `197` will be calculated and stored. This will cause the overflow as the limit of the variable is `100` only(assumption).
-* This may result in incorrect or negative value.
-* Whereas, when we write
first the sum `197` will be calculated and stored. This will cause the overflow as the limit of the variable is `100` only(assumption).
-* This may result in incorrect or negative value.
-* Whereas, when we write  we will get
we will get  which even in the worst case be `99` and will not overflow.
-
-
-
which even in the worst case be `99` and will not overflow.
-
-
- -
----
-### Identify 2024's First Email
+## Identify 2024's First Email
All emails in your mailbox are sorted chronologically. Can you find the first mail that you received in 2024?
---
-### Binary Search Problems - Find first occurrence
+## Binary Search Problems - Find first occurrence
+
+### Problem Statement
Given a sorted array of N elements, find the first occurrence of the target element.
arr[] =
| -5 | -5 | -3 | 0 | 0 | 1 | 1 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 8 | 10 | 10 | 15 | 15 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
-For `5` first occurence is at index `7` so we have to return `7`.
-* Brute force approach is linear search.
-* Now the array is sorted so using binary search we can find at least one of the occurences of the given target element.
-* The challenge is to **find the first occurence**. What we know about the first occurence is that it is always going to be the current position or in the left.
-* Now in left, we can do linear search but in worst it will take about O(N) time complexity.
-* What we have got is the potential answer, it can or cannot be final anser.
-* We can store the current position in a variable, in case it is the first occurence. Next, we can apply binary search in the left side of the array.
-* The only change we are required to make is to not stop if we find the target element instead keep looking in the left side of the array until `low > high`.
-* If the `mid == target` store mid, go left.
-* else if `mid > target` go right.
-* else go left.
+For the number 5, the first occurrence is at index 7, so we return 7.
+* A brute-force way to find this is with a linear search.
+* Since the array is sorted, we can use binary search to find an occurrence of the target.
+* The challenge is to find the first occurrence. The first occurrence will be at the current position or to the left of it.
+* Instead of using linear search on the left, which can be slow, we can modify the binary search.
+* Store the current position if it matches the target, then continue searching to the left.
+ * If mid == target, store the mid index and go left.
+ * If mid > target, go left.
+ * Otherwise, go right.
-
-
----
-### Identify 2024's First Email
+## Identify 2024's First Email
All emails in your mailbox are sorted chronologically. Can you find the first mail that you received in 2024?
---
-### Binary Search Problems - Find first occurrence
+## Binary Search Problems - Find first occurrence
+
+### Problem Statement
Given a sorted array of N elements, find the first occurrence of the target element.
arr[] =
| -5 | -5 | -3 | 0 | 0 | 1 | 1 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 8 | 10 | 10 | 15 | 15 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
-For `5` first occurence is at index `7` so we have to return `7`.
-* Brute force approach is linear search.
-* Now the array is sorted so using binary search we can find at least one of the occurences of the given target element.
-* The challenge is to **find the first occurence**. What we know about the first occurence is that it is always going to be the current position or in the left.
-* Now in left, we can do linear search but in worst it will take about O(N) time complexity.
-* What we have got is the potential answer, it can or cannot be final anser.
-* We can store the current position in a variable, in case it is the first occurence. Next, we can apply binary search in the left side of the array.
-* The only change we are required to make is to not stop if we find the target element instead keep looking in the left side of the array until `low > high`.
-* If the `mid == target` store mid, go left.
-* else if `mid > target` go right.
-* else go left.
+For the number 5, the first occurrence is at index 7, so we return 7.
+* A brute-force way to find this is with a linear search.
+* Since the array is sorted, we can use binary search to find an occurrence of the target.
+* The challenge is to find the first occurrence. The first occurrence will be at the current position or to the left of it.
+* Instead of using linear search on the left, which can be slow, we can modify the binary search.
+* Store the current position if it matches the target, then continue searching to the left.
+ * If mid == target, store the mid index and go left.
+ * If mid > target, go left.
+ * Otherwise, go right.
- -#### Dry run for the example
+### Dry run for the example
-#### Dry run for the example
+### Dry run for the example
 @@ -207,11 +198,12 @@ For `5` first occurence is at index `7` so we have to return `7`.
* break;
---
+
### Question
When searching for the first occurrence of an element in a sorted array, what should you do if the current element matches the target 'k'?
-**Choices**
+### Choices
- [ ] Return the current index
- [ ] Continue searching in the right subarray
- [x] Continue searching in the left subarray
@@ -219,45 +211,42 @@ When searching for the first occurrence of an element in a sorted array, what sh
---
+
### Question
What is the time complexity of finding the first occurrence of an element in a sorted array using binary search?
-**Choices**
+### Choices
- [x] O(log n)
- [ ] O(n)
- [ ] O(1)
- [ ] O(n^2)
----
-#### Complexity
+### Complexity
**Time Complexity:** O(logn) (Everytime you are discarding the search space by half).
**Space Complexity:** O(1)
-#### Follow up question
+### Homework
* Try for the last occurence
---
-### Find the unique element
+## Find the unique element
-**Question**
+
+### Question
Every element occurs twice except for 1, find the unique element.
**Note:** Duplicate elements are adjacent to each other but the array is not sorted.
**Example:**
@@ -207,11 +198,12 @@ For `5` first occurence is at index `7` so we have to return `7`.
* break;
---
+
### Question
When searching for the first occurrence of an element in a sorted array, what should you do if the current element matches the target 'k'?
-**Choices**
+### Choices
- [ ] Return the current index
- [ ] Continue searching in the right subarray
- [x] Continue searching in the left subarray
@@ -219,45 +211,42 @@ When searching for the first occurrence of an element in a sorted array, what sh
---
+
### Question
What is the time complexity of finding the first occurrence of an element in a sorted array using binary search?
-**Choices**
+### Choices
- [x] O(log n)
- [ ] O(n)
- [ ] O(1)
- [ ] O(n^2)
----
-#### Complexity
+### Complexity
**Time Complexity:** O(logn) (Everytime you are discarding the search space by half).
**Space Complexity:** O(1)
-#### Follow up question
+### Homework
* Try for the last occurence
---
-### Find the unique element
+## Find the unique element
-**Question**
+
+### Question
Every element occurs twice except for 1, find the unique element.
**Note:** Duplicate elements are adjacent to each other but the array is not sorted.
**Example:**
 -:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
+### Brute Force Approach
* The brute force approach can be comparing A[i] with A[i+1]. If `(A[i]!=A[i+1])`, then `A[i]` is the unique element.
-#### Optimal Approach
+### Optimal Approach
* Can we apply Binary Search ?
* Say we land at mid, how to know current element is the answer? => We can check element at its right and at its left. If both are different, then `mid` is the ans.
* If `A[mid]` is not the answer, then how to decide in which direction shall we move?
@@ -275,7 +264,7 @@ Please take some time to think about the solution approach on your own before re
* 3 is unique.
* First occurrence of 7 and 6 is at index even and after 3, first occurrences of elements, 8, 1, 9 is at odd index.
-#### Steps for applying Binary Search
+### Steps for applying Binary Search
* Land at mid, if `A[mid] != A[mid-1] && A[mid] != A[mid+1]`, then `A[mid]` is the answer.
* NOTE: To avoid accessing invalid indices, above conditions shall be modified as follows-
* `mid == 0 || A[mid] != A[mid-1]`
@@ -284,7 +273,7 @@ Please take some time to think about the solution approach on your own before re
* If index is even, then unique element must be present on right.
* Else, on left.
-#### Dry Run for An Example
+### Dry Run for An Example
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
@@ -328,84 +317,46 @@ For the above array,
* `arr[mid] != arr[mid + 1]` -> mid is the **unique element.** We will terminate the loop.
-#### Pseudo Code
+### Pseudo Code
```cpp
-int findUnique(int arr[], int N) {
-
- lo = 0, hi = N - 1;
-
- // binary search
- while (lo <= hi) {
- mid = lo + (hi - lo) / 2;
-
- if ((mid == 0 || arr[mid] != arr[mid - 1]) && (mid == N - 1 || arr[mid] != arr[mid + 1])) { //checking mid is unique
- return A[mid];
- } else if (mid == 0 || arr[mid] == arr[mid - 1]) { //at first occurrence
- if (mid % 2 == 0) lo = mid + 2;
- else hi = mid - 1;
- } else { //at second occurrence
- if (mid % 2 == 0) hi = mid - 2;
- else lo = mid + 1;
+int findUnique(int arr[], int N){
+
+ lo = 0, hi = N - 1;
+
+ // binary search
+ while(lo <= hi){
+ mid = lo + (hi - lo) / 2;
+
+ if((mid == 0 || arr[mid] != arr[mid - 1]) && (mid == N-1 || arr[mid] != arr[mid + 1])){ //checking mid is unique
+ return A[mid];
+ }
+ else if(mid == 0 || arr[mid] == arr[mid - 1]){ //at first occurrence
+ if(mid % 2 == 0) lo = mid+2;
+ else hi = mid-1;
+ }
+ else { //at second occurrence
+ if(mid % 2 == 0) hi = mid-2;
+ else lo = mid+1;
+ }
}
- }
}
```
-#### Complexities
+### Complexities
**Time Complexity:** O(log(N)
**Space Complexity:** O(1)
---
-### Increasing Decreasing Array
-
-Given an increasing decreasing array with distinct elements. Find max element.
-
-**Examples**
-
-arr[] = {1, 3, 5, 2}
-In the above array `5` is the max value.
-arr[] = {1, 3, 5, 10, 15, 12, 6}
-In the given example max element is `15`
-
-The increasing decreasing array will look something like this:
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
+### Brute Force Approach
* The brute force approach can be comparing A[i] with A[i+1]. If `(A[i]!=A[i+1])`, then `A[i]` is the unique element.
-#### Optimal Approach
+### Optimal Approach
* Can we apply Binary Search ?
* Say we land at mid, how to know current element is the answer? => We can check element at its right and at its left. If both are different, then `mid` is the ans.
* If `A[mid]` is not the answer, then how to decide in which direction shall we move?
@@ -275,7 +264,7 @@ Please take some time to think about the solution approach on your own before re
* 3 is unique.
* First occurrence of 7 and 6 is at index even and after 3, first occurrences of elements, 8, 1, 9 is at odd index.
-#### Steps for applying Binary Search
+### Steps for applying Binary Search
* Land at mid, if `A[mid] != A[mid-1] && A[mid] != A[mid+1]`, then `A[mid]` is the answer.
* NOTE: To avoid accessing invalid indices, above conditions shall be modified as follows-
* `mid == 0 || A[mid] != A[mid-1]`
@@ -284,7 +273,7 @@ Please take some time to think about the solution approach on your own before re
* If index is even, then unique element must be present on right.
* Else, on left.
-#### Dry Run for An Example
+### Dry Run for An Example
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
@@ -328,84 +317,46 @@ For the above array,
* `arr[mid] != arr[mid + 1]` -> mid is the **unique element.** We will terminate the loop.
-#### Pseudo Code
+### Pseudo Code
```cpp
-int findUnique(int arr[], int N) {
-
- lo = 0, hi = N - 1;
-
- // binary search
- while (lo <= hi) {
- mid = lo + (hi - lo) / 2;
-
- if ((mid == 0 || arr[mid] != arr[mid - 1]) && (mid == N - 1 || arr[mid] != arr[mid + 1])) { //checking mid is unique
- return A[mid];
- } else if (mid == 0 || arr[mid] == arr[mid - 1]) { //at first occurrence
- if (mid % 2 == 0) lo = mid + 2;
- else hi = mid - 1;
- } else { //at second occurrence
- if (mid % 2 == 0) hi = mid - 2;
- else lo = mid + 1;
+int findUnique(int arr[], int N){
+
+ lo = 0, hi = N - 1;
+
+ // binary search
+ while(lo <= hi){
+ mid = lo + (hi - lo) / 2;
+
+ if((mid == 0 || arr[mid] != arr[mid - 1]) && (mid == N-1 || arr[mid] != arr[mid + 1])){ //checking mid is unique
+ return A[mid];
+ }
+ else if(mid == 0 || arr[mid] == arr[mid - 1]){ //at first occurrence
+ if(mid % 2 == 0) lo = mid+2;
+ else hi = mid-1;
+ }
+ else { //at second occurrence
+ if(mid % 2 == 0) hi = mid-2;
+ else lo = mid+1;
+ }
}
- }
}
```
-#### Complexities
+### Complexities
**Time Complexity:** O(log(N)
**Space Complexity:** O(1)
---
-### Increasing Decreasing Array
-
-Given an increasing decreasing array with distinct elements. Find max element.
-
-**Examples**
-
-arr[] = {1, 3, 5, 2}
-In the above array `5` is the max value.
-arr[] = {1, 3, 5, 10, 15, 12, 6}
-In the given example max element is `15`
-
-The increasing decreasing array will look something like this:
- -
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Solution
-* Increasing decreasing arrays are the array that increases first and after reaching its peek it starts decreasing. We are supposed to find the peek or the max element of the array. The increasing side is sorted in ascending order and the decreasing side is sorted in descending order.
-* Brute force approach is a linear search with O(N) time complexity.
-* But as we see the elements are sorted in increasing and then decreasing order, so can we do better than O(N) time complexity?
-* Can we apply **Binary Search**? What do we need ?
- * **Search space** -> array
- * **target** -> peak element
- * **Condition:** ->
- * **Case 1**: if`(arr[mid] > arr[mid - 1] && arr[mid] < arr[mid + 1])` return mid;
- * If immediate left and right are less than current element than we are at peek element.
-
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Solution
-* Increasing decreasing arrays are the array that increases first and after reaching its peek it starts decreasing. We are supposed to find the peek or the max element of the array. The increasing side is sorted in ascending order and the decreasing side is sorted in descending order.
-* Brute force approach is a linear search with O(N) time complexity.
-* But as we see the elements are sorted in increasing and then decreasing order, so can we do better than O(N) time complexity?
-* Can we apply **Binary Search**? What do we need ?
- * **Search space** -> array
- * **target** -> peak element
- * **Condition:** ->
- * **Case 1**: if`(arr[mid] > arr[mid - 1] && arr[mid] < arr[mid + 1])` return mid;
- * If immediate left and right are less than current element than we are at peek element.
- - * **Case 2**: if`(arr[mid] > arr[mid - 1] and arr[mid] < arr[mid + 1])` go right;
- * Implies our mid is at the part of the array where it is still increasing. So the peek will be at the right side of the array.
-
- * **Case 2**: if`(arr[mid] > arr[mid - 1] and arr[mid] < arr[mid + 1])` go right;
- * Implies our mid is at the part of the array where it is still increasing. So the peek will be at the right side of the array.
- - * **Case 3**: go left
- * This infers that mid is at the decreasing side of the array and peek must be at left.
-
- * **Case 3**: go left
- * This infers that mid is at the decreasing side of the array and peek must be at left.
- -
-#### Pseudocode
-
-
-#### Pseudocode
- -
- +## Local Minima in an Array
----
-### Local Minima in an Array
-
+### Question
Given an array of N distinct elements, find any local minima in the array
**Local Minima** - a no. which is smaller than its adjacent neighbors.
-**Examples**
+### Examples
+## Local Minima in an Array
----
-### Local Minima in an Array
-
+### Question
Given an array of N distinct elements, find any local minima in the array
**Local Minima** - a no. which is smaller than its adjacent neighbors.
-**Examples**
+### Examples
 @@ -424,7 +375,7 @@ Given an array of N distinct elements, find any local minima in the array
* This can have multiple local minima
* We have to return any local minima
-#### Solution
+### Solution
* **Case 1:** Current element is smaller than the next and the previous element returns the current element, since this is local minima.
* **Case 2:** If the current element is greater than the previous element and less than the next element.
@@ -435,24 +386,25 @@ Given an array of N distinct elements, find any local minima in the array
* **Case 4:** The current element is greater than the previous as well next element. Then we can go to either the left or to the right, because both will contain atleast one local minima.
@@ -424,7 +375,7 @@ Given an array of N distinct elements, find any local minima in the array
* This can have multiple local minima
* We have to return any local minima
-#### Solution
+### Solution
* **Case 1:** Current element is smaller than the next and the previous element returns the current element, since this is local minima.
* **Case 2:** If the current element is greater than the previous element and less than the next element.
@@ -435,24 +386,25 @@ Given an array of N distinct elements, find any local minima in the array
* **Case 4:** The current element is greater than the previous as well next element. Then we can go to either the left or to the right, because both will contain atleast one local minima.
 -#### Pseudo Code
+### Pseudo Code
```javascript
-int localMinima(int[] A) {
- l = 0, h = n - 1;
- while (l <= h) {
- mid = l + (h - l) / 2;
- if ((mid == 0 || arr[mid] < arr[mid - 1]) && (mid == N - 1 || arr[mid] < arr[mid + 1])) {
- return mid;
- } else if (mid == 0 || arr[mid] < arr[mid - 1]) {
- l = mid + 1;
- } else {
- h = mid - 1;
+int localMinima(int[] A){
+ l = 0, h = n - 1;
+ while(l <= h){
+ mid = l + (h - l) / 2;
+ if((mid==0 || arr[mid] < arr[mid - 1]) && (mid==N-1 || arr[mid] < arr[mid + 1])){
+ return mid;
+ }
+ else if(mid==0 || arr[mid] < arr[mid - 1]){
+ l = mid + 1;
+ }else{
+ h = mid - 1;
+ }
}
- }
}
```
-#### Dry run
+### Dry run
-#### Pseudo Code
+### Pseudo Code
```javascript
-int localMinima(int[] A) {
- l = 0, h = n - 1;
- while (l <= h) {
- mid = l + (h - l) / 2;
- if ((mid == 0 || arr[mid] < arr[mid - 1]) && (mid == N - 1 || arr[mid] < arr[mid + 1])) {
- return mid;
- } else if (mid == 0 || arr[mid] < arr[mid - 1]) {
- l = mid + 1;
- } else {
- h = mid - 1;
+int localMinima(int[] A){
+ l = 0, h = n - 1;
+ while(l <= h){
+ mid = l + (h - l) / 2;
+ if((mid==0 || arr[mid] < arr[mid - 1]) && (mid==N-1 || arr[mid] < arr[mid + 1])){
+ return mid;
+ }
+ else if(mid==0 || arr[mid] < arr[mid - 1]){
+ l = mid + 1;
+ }else{
+ h = mid - 1;
+ }
}
- }
}
```
-#### Dry run
+### Dry run
 @@ -483,6 +435,7 @@ int localMinima(int[] A) {
* Element to the right of mid -> `2 < 7`
* **2 is our local minima.**
-#### Complexities
+### Complexities
* **Time Complexity: O(log(N))**
-* **Space Complexity: O(1)**
\ No newline at end of file
+* **Space Complexity: O(1)**
+
diff --git a/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md b/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md
index 71b3183..400c25a 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md
@@ -1,62 +1,30 @@
# Searching 2: Binary Search Problems
----
-## Understanding Binary Search
+## Another formula for finding mid
-### Introduction:
-We will continue with our second lecture on Binary Search. In our previous session, we explored the fundamental concepts of this efficient searching algorithm. Today, we will dive even deeper into the world of binary search, uncovering advanced techniques and applications that expand its capabilities.
+Sometimes when people try to find the middle point of something (like an array), they use a simple formula:
+**`$mid = (low+high) / 2$`**
+However, this can sometimes cause problems, especially if the numbers are very big. Let me explain with an example:
+
+Imagine we can only handle numbers up to 100, and we have a list of 100 items. The last position in this list is 99. If we want to find something near the end, say between position 98 and 99, adding these numbers together gives us 197. This is a problem because 197 is bigger than 100 and our system can't handle it, which might cause errors or give us a negative number when we try to find the middle.
-In this lecture, we will build upon the foundation laid in the first session. We'll delve into topics such as binary search on rotated arrays, finding square root using binary search etc and addressing various edge cases and challenges that may arise during binary search implementation.
+To avoid this problem, we can use a different way to find the middle:
+**`$mid = low + ( (high-low) / 2 )$`**
+Using our example, this would be, **`$98 + ( (99-98)/2 ) = 98.5$`**, which rounds down safely to 98. This method makes sure we don't go over our limit and keeps everything working smoothly.
-### Pseudocode
-```java
-function binarySearch(array, target):
- left = 0
- right = length(array) - 1
- while left <= right:
- mid = left + (right - left) / 2
- if array[mid] == target:
- return mid
- else if array[mid] < target:
- left = mid + 1
- else:
- right = mid - 1
- return NOT_FOUND
-```
-
-### Use Cases:
-Binary search has numerous applications, including:
-* Searching in databases.
-* Finding an element in a sorted array.
-* Finding an insertion point for a new element in a sorted array.
-* Implementing features like autocomplete in search engines.
-
----
-### Question
-In what scenario does Binary Search become ineffective?
-
-**Choices**
-- [x] When the dataset is unsorted.
-- [ ] When the dataset is extremely large.
-- [ ] When the dataset is sorted in descending order.
-- [ ] When the dataset contains only unique elements.
+
---
-### Problem 1 Searching in Rotated Sorted Arrays
-
-### Introduction:
-We'll explore the fascinating problem of searching in rotated sorted arrays using the Binary Search algorithm. This scenario arises when a previously sorted array has been rotated at an unknown pivot point. We'll discuss how to adapt the Binary Search technique to efficiently find a target element in such arrays.
+## Problem 1 Searching in Rotated Sorted Arrays
### Scenario:
Imagine you have an array that was sorted initially, but someone rotated it at an unknown index. The resulting array is a rotated sorted array. The challenge is to find a specific element in this rotated array without reverting to linear search.
-### Example: Finding an Element in a Rotated Array
-
-Suppose we have the following rotated sorted array:
+**Suppose we have the following rotated sorted array:**
```javascript
Original Sorted Rotated Array: [4, 5, 6, 7, 8, 9, 1, 2, 3]
```
@@ -64,69 +32,32 @@ Let's say we want to find the element 7 within this rotated array using a brute-
### Brute-Force Approach:
-* Initialize a variable target with the value we want to find (e.g., 7).
-* Loop through each element in the array one by one, starting from the first element.
-* Compare the current element with the target:
-* If the current element matches the target, we have found our element, and we can return its index.
-* If the current element does not match the target, continue to the next element.
-* Repeat step 3 until we either find the target or reach the end of the array without finding it.
-
-### Adapting Binary Search:
-While the array is rotated, we can still leverage the divide-and-conquer nature of Binary Search. However, we need to make a few adjustments to handle the rotation.
-
-**Intution:**
-* In a rotated sorted array, elements were initially sorted in ascending order but have been rotated at some point.
-* Let's asusme array contain distinct elements only.
-* The goal is to find a specific target element within this rotated array.
-* The key to binary search in a rotated array is to determine the pivot point, which is where the array rotation occurred.
-* The pivot point is essentially the maximum element in the array.
-* Once you've identified the pivot point, you have split the array into two subarrays, each of which is sorted.
-* Then you can apply individual binary search in both the parts, and find the target element.
-* **Another Idea of Doing it in one Binary Search we'll discuss below**
-* **Partitioning of Rotated Sorted Array:**
- * A rotated sorted array can be visualized as being split into two parts: part 1 and part 2.
- * Crucially, both part 1 and part 2 are sorted individually, but every element in part 1 is greater than those in part 2 due to the rotation.
+* Iterate and get the element. T.C: O(N)
+
+
+### Optimised Approach
+ **`A rotated sorted array can be visualized as being split into two parts: part 1 and part 2.`**
+ > Crucially, both part 1 and part 2 are sorted individually, but every element in part 1 is greater than those in part 2 due to the rotation.
@@ -483,6 +435,7 @@ int localMinima(int[] A) {
* Element to the right of mid -> `2 < 7`
* **2 is our local minima.**
-#### Complexities
+### Complexities
* **Time Complexity: O(log(N))**
-* **Space Complexity: O(1)**
\ No newline at end of file
+* **Space Complexity: O(1)**
+
diff --git a/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md b/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md
index 71b3183..400c25a 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Searching 2 Binary Search Problems.md
@@ -1,62 +1,30 @@
# Searching 2: Binary Search Problems
----
-## Understanding Binary Search
+## Another formula for finding mid
-### Introduction:
-We will continue with our second lecture on Binary Search. In our previous session, we explored the fundamental concepts of this efficient searching algorithm. Today, we will dive even deeper into the world of binary search, uncovering advanced techniques and applications that expand its capabilities.
+Sometimes when people try to find the middle point of something (like an array), they use a simple formula:
+**`$mid = (low+high) / 2$`**
+However, this can sometimes cause problems, especially if the numbers are very big. Let me explain with an example:
+
+Imagine we can only handle numbers up to 100, and we have a list of 100 items. The last position in this list is 99. If we want to find something near the end, say between position 98 and 99, adding these numbers together gives us 197. This is a problem because 197 is bigger than 100 and our system can't handle it, which might cause errors or give us a negative number when we try to find the middle.
-In this lecture, we will build upon the foundation laid in the first session. We'll delve into topics such as binary search on rotated arrays, finding square root using binary search etc and addressing various edge cases and challenges that may arise during binary search implementation.
+To avoid this problem, we can use a different way to find the middle:
+**`$mid = low + ( (high-low) / 2 )$`**
+Using our example, this would be, **`$98 + ( (99-98)/2 ) = 98.5$`**, which rounds down safely to 98. This method makes sure we don't go over our limit and keeps everything working smoothly.
-### Pseudocode
-```java
-function binarySearch(array, target):
- left = 0
- right = length(array) - 1
- while left <= right:
- mid = left + (right - left) / 2
- if array[mid] == target:
- return mid
- else if array[mid] < target:
- left = mid + 1
- else:
- right = mid - 1
- return NOT_FOUND
-```
-
-### Use Cases:
-Binary search has numerous applications, including:
-* Searching in databases.
-* Finding an element in a sorted array.
-* Finding an insertion point for a new element in a sorted array.
-* Implementing features like autocomplete in search engines.
-
----
-### Question
-In what scenario does Binary Search become ineffective?
-
-**Choices**
-- [x] When the dataset is unsorted.
-- [ ] When the dataset is extremely large.
-- [ ] When the dataset is sorted in descending order.
-- [ ] When the dataset contains only unique elements.
+
---
-### Problem 1 Searching in Rotated Sorted Arrays
-
-### Introduction:
-We'll explore the fascinating problem of searching in rotated sorted arrays using the Binary Search algorithm. This scenario arises when a previously sorted array has been rotated at an unknown pivot point. We'll discuss how to adapt the Binary Search technique to efficiently find a target element in such arrays.
+## Problem 1 Searching in Rotated Sorted Arrays
### Scenario:
Imagine you have an array that was sorted initially, but someone rotated it at an unknown index. The resulting array is a rotated sorted array. The challenge is to find a specific element in this rotated array without reverting to linear search.
-### Example: Finding an Element in a Rotated Array
-
-Suppose we have the following rotated sorted array:
+**Suppose we have the following rotated sorted array:**
```javascript
Original Sorted Rotated Array: [4, 5, 6, 7, 8, 9, 1, 2, 3]
```
@@ -64,69 +32,32 @@ Let's say we want to find the element 7 within this rotated array using a brute-
### Brute-Force Approach:
-* Initialize a variable target with the value we want to find (e.g., 7).
-* Loop through each element in the array one by one, starting from the first element.
-* Compare the current element with the target:
-* If the current element matches the target, we have found our element, and we can return its index.
-* If the current element does not match the target, continue to the next element.
-* Repeat step 3 until we either find the target or reach the end of the array without finding it.
-
-### Adapting Binary Search:
-While the array is rotated, we can still leverage the divide-and-conquer nature of Binary Search. However, we need to make a few adjustments to handle the rotation.
-
-**Intution:**
-* In a rotated sorted array, elements were initially sorted in ascending order but have been rotated at some point.
-* Let's asusme array contain distinct elements only.
-* The goal is to find a specific target element within this rotated array.
-* The key to binary search in a rotated array is to determine the pivot point, which is where the array rotation occurred.
-* The pivot point is essentially the maximum element in the array.
-* Once you've identified the pivot point, you have split the array into two subarrays, each of which is sorted.
-* Then you can apply individual binary search in both the parts, and find the target element.
-* **Another Idea of Doing it in one Binary Search we'll discuss below**
-* **Partitioning of Rotated Sorted Array:**
- * A rotated sorted array can be visualized as being split into two parts: part 1 and part 2.
- * Crucially, both part 1 and part 2 are sorted individually, but every element in part 1 is greater than those in part 2 due to the rotation.
+* Iterate and get the element. T.C: O(N)
+
+
+### Optimised Approach
+ **`A rotated sorted array can be visualized as being split into two parts: part 1 and part 2.`**
+ > Crucially, both part 1 and part 2 are sorted individually, but every element in part 1 is greater than those in part 2 due to the rotation.
 -* **Identifying Target's Part**
- * To determine which part the Target belongs to (part 1 or 2), compare it with the 0th element.
- * If the midpoint is greater than (also equals to) the 0th element, then it belongs to part 1. Otherwise, it's in part 2.
-
-* **Identifying Target's Part**
- * To determine which part the Target belongs to (part 1 or 2), compare it with the 0th element.
- * If the midpoint is greater than (also equals to) the 0th element, then it belongs to part 1. Otherwise, it's in part 2.
-  -* **Identifying Midpoint's Part:**
+**`How to identify in which part mid point is present?`**
- * To determine which part the midpoint belongs to (part 1 or 2), compare it with the 0th element.
- * If the midpoint is greater than (also equals to) the 0th element, then it belongs to part 1. Otherwise, it's in part 2.
-* **Midpoint vs Target:**
- * If the midpoint is the equals to the target, you've found it.
- * If not, then check if the target lies in the same part as the midpoint. If yes, both target and midpoint is within the same sorted part, perform a binary search in that part to move your midpoint towards the target.
+> To determine which part the midpoint belongs to (part 1 or 2), compare it with the 0th element.
+> -- If arr[mid] >= arr[0], then it belongs to part 1. Otherwise, it's in part 2.
+
+**`How to identify where is the target ?`**
+> If the midpoint is the equals to the target, you've found it.
+ #### If not, then check if the target lies in the same part as the midpoint.
+ * If yes, both target and midpoint is within the same sorted part, perform a binary search in that part to move your midpoint towards the target.
-* **Identifying Midpoint's Part:**
+**`How to identify in which part mid point is present?`**
- * To determine which part the midpoint belongs to (part 1 or 2), compare it with the 0th element.
- * If the midpoint is greater than (also equals to) the 0th element, then it belongs to part 1. Otherwise, it's in part 2.
-* **Midpoint vs Target:**
- * If the midpoint is the equals to the target, you've found it.
- * If not, then check if the target lies in the same part as the midpoint. If yes, both target and midpoint is within the same sorted part, perform a binary search in that part to move your midpoint towards the target.
+> To determine which part the midpoint belongs to (part 1 or 2), compare it with the 0th element.
+> -- If arr[mid] >= arr[0], then it belongs to part 1. Otherwise, it's in part 2.
+
+**`How to identify where is the target ?`**
+> If the midpoint is the equals to the target, you've found it.
+ #### If not, then check if the target lies in the same part as the midpoint.
+ * If yes, both target and midpoint is within the same sorted part, perform a binary search in that part to move your midpoint towards the target.
 -
* If no, move your search towards the other part, effectively approaching the midpoint towards target.
-
* If no, move your search towards the other part, effectively approaching the midpoint towards target.
 -
-* **Iterative Process:**
- * Continue adjusting your boundaries based on the decisions made in the previous step until you either find the target or exhaust your search space.
+
* **Result:**
* Return the index of the target if found, or -1 if not.
-**Algorithm:**
-* Initialize left to 0 and right to len(nums) - 1.
-* While left is less than or equal to right, do the following:
-* Calculate the middle index mid as left + (right - left)/2.
-* If nums[mid] is equal to the target, return mid as the index of the target.
-* Check if the target is less than nums[0] (indicating it's on part 2):
-* If target < nums[0], check if nums[mid] is greater than or equal to nums[0]:
-* If true, update left to mid + 1 to search the right half.
-* If false, update right to mid - 1 based on target's relation to nums[mid].
-* If the target is greater than or equal to nums[0] (indicating it's on the left side of the pivot):
-* If target >= nums[0], check if nums[mid] is less than nums[0]:
-* If true, update right to mid - 1 to search the left half.
-* If false, update left to mid + 1 based on target's relation to nums[mid].
-* Repeat steps 2-6 until left is less than or equal to right.
-* If the loop exits without finding the target, return -1 to indicate the target is not in the array.
-
### Example:
**Scenario:**
@@ -147,9 +78,10 @@ Consider the rotated sorted array **[4, 5, 6, 7, 0, 1, 2]** and our target is 0.
**We found the target 0 at index 5.**
---
-### Searching in Rotated Sorted Arrays Pseudocode
+### Searching in Rotated Sorted Arrays
-#### Pseudocode:
+
+### Pseudocode:
```cpp
function searchRotatedArray(nums, target):
@@ -182,7 +114,7 @@ function searchRotatedArray(nums, target):
return -1
```
-#### Complexity Analysis:
+### Complexity Analysis:
The time complexity of this modified Binary Search algorithm is still O(log n), making it efficient even in rotated sorted arrays.
**Reason**:
* **Divide and Conquer:**
-
-* **Iterative Process:**
- * Continue adjusting your boundaries based on the decisions made in the previous step until you either find the target or exhaust your search space.
+
* **Result:**
* Return the index of the target if found, or -1 if not.
-**Algorithm:**
-* Initialize left to 0 and right to len(nums) - 1.
-* While left is less than or equal to right, do the following:
-* Calculate the middle index mid as left + (right - left)/2.
-* If nums[mid] is equal to the target, return mid as the index of the target.
-* Check if the target is less than nums[0] (indicating it's on part 2):
-* If target < nums[0], check if nums[mid] is greater than or equal to nums[0]:
-* If true, update left to mid + 1 to search the right half.
-* If false, update right to mid - 1 based on target's relation to nums[mid].
-* If the target is greater than or equal to nums[0] (indicating it's on the left side of the pivot):
-* If target >= nums[0], check if nums[mid] is less than nums[0]:
-* If true, update right to mid - 1 to search the left half.
-* If false, update left to mid + 1 based on target's relation to nums[mid].
-* Repeat steps 2-6 until left is less than or equal to right.
-* If the loop exits without finding the target, return -1 to indicate the target is not in the array.
-
### Example:
**Scenario:**
@@ -147,9 +78,10 @@ Consider the rotated sorted array **[4, 5, 6, 7, 0, 1, 2]** and our target is 0.
**We found the target 0 at index 5.**
---
-### Searching in Rotated Sorted Arrays Pseudocode
+### Searching in Rotated Sorted Arrays
-#### Pseudocode:
+
+### Pseudocode:
```cpp
function searchRotatedArray(nums, target):
@@ -182,7 +114,7 @@ function searchRotatedArray(nums, target):
return -1
```
-#### Complexity Analysis:
+### Complexity Analysis:
The time complexity of this modified Binary Search algorithm is still O(log n), making it efficient even in rotated sorted arrays.
**Reason**:
* **Divide and Conquer:**The algorithm works by repeatedly dividing the search space in half. In each step, it either eliminates half of the remaining elements or finds the target element. This is a characteristic of binary search, which has a time complexity of O(log N). @@ -190,42 +122,25 @@ The time complexity of this modified Binary Search algorithm is still O(log n), * **No Need to Examine All Elements:**
Unlike linear search, which would require examining all N elements in the worst case, binary search significantly reduces the number of elements that need to be considered, leading to a logarithmic time complexity. --- -### Question -In the problem of searching for a target element in a rotated sorted array, what advantage does Binary Search offer over Linear Search? -**Choices** -- [ ] Binary Search doesn't require any comparisons. -- [ ] Binary Search works faster on unsorted arrays. -- [x] Binary Search divides the search space in half with each step. -- [ ] Binary Search is always faster than Linear Search. - - - -**Explanation:** -Binary Search offers a significant advantage over Linear Search when searching in a rotated sorted array. With each step, Binary Search efficiently narrows down the search interval by dividing it in half, greatly reducing the number of elements under consideration. This characteristic leads to a time complexity of O(log n), making Binary Search much faster compared to Linear Search's O(n) time complexity, especially for larger arrays. +### Question +Consider a rotated sorted array of distinct integers. What is the worst-case time complexity of finding a specific target element in this array using binary search? +### Choices +- [ ] O(1) +- [ ] O(n) +- [x] O(log n) +- [ ] O(n log n) --- -### Problem 2 Finding the square root of a number - - -### Introduction: -Now, we'll explore a fascinating application of Binary Search: finding the square root of a number. The square root operation is a fundamental mathematical operation, and we'll see how Binary Search helps us approximate this value with great efficiency. +## Problem 2 Finding the square root of a number ### Motivation: Imagine you're working on a mathematical problem or a scientific simulation that requires the square root of a number. Calculating square roots manually can be time-consuming, and a reliable and fast method is needed. Binary Search provides an elegant way to approximate square roots efficiently. ### Brute-Force Algorithm to Find the Square Root: -* **Input Validation:** If it's negative, return "Undefined" because the square root of a negative number is undefined. -* **Special Cases:** If x is 0 or 1, return x because the square root of 0 or 1 is the number itself. -* **Initialize Guess:** Start with an initial guess of 1. -* Check if the square of the current guess is less than or equal to x. If it is, continue to the next step. If not, exit the loop. -* **Increment Guess:** Increment the guess by 1. -* **Exit Loop:** When the loop exits, it means guess * guess exceeds x. The square root is approximated as guess - 1 because guess at this point is the smallest integer greater than or equal to the square root of x. -* Return Result: Return guess - 1 as the square root of x. - ```cpp function sqrt_with_floor(x): if x < 0: @@ -243,15 +158,10 @@ function sqrt_with_floor(x): return guess - 1 ``` -:::warning -Please take some time to think about the Binary Search approach on your own before reading further..... -::: - ### Binary Search Principle for Square Root: -The Binary Search algorithm can be adapted to find the square root of a number by treating the square root as a search problem. The key idea is to search for a number within a certain range that, when squared, is closest to the target value. We'll repeatedly narrow down this range until we achieve a satisfactory approximation. -Establish a search range: The square root of a non-negative number is always within the range of 0 to the number itself. So, you set up an initial search range as [0, x], where 'x' is the number for which you want to find the square root. +The key idea is to search for a number within a certain range that, when squared, is closest to the target value. We'll repeatedly narrow down this range until we achieve a satisfactory approximation. -**Intution**: +**Intuition**: * **Binary search:** You then start a binary search within this range. The midpoint of the range is calculated, and you compute the square of this midpoint. * **Comparison:** You compare the square of the midpoint to the original number (x). Three cases can arise: * **Exact Match:** If the square of the midpoint is exactly equal to x, you've found a value very close to the square root. @@ -262,7 +172,6 @@ Establish a search range: The square root of a non-negative number is always wit For example:
 -
### Example: Finding Square Root using Binary Search
**Scenario:**
@@ -283,8 +192,9 @@ We want to find the square root of the number 9 using Binary Search.
* We found an exact match! The square root of 9 is 3.
---
-### Finding the square root of a number Pseudocode
-#### Pseudocode:
+## Finding the square root of a number
+
+### Pseudocode:
Here's a simple pseudocode representation of finding the square root using Binary Search:
```cpp
@@ -310,7 +220,6 @@ function findSquareRoot(target):
return result
```
-
### Analysis and Complexity:
In each step of the Binary Search, we compare the square of the middle element with the target value. Depending on the result of this comparison, we adjust the search range. Since Binary Search divides the range in half with each step, the time complexity of this algorithm is O(log n), where n is the value of the target number.
@@ -318,252 +227,178 @@ In each step of the Binary Search, we compare the square of the middle element w
### Use Cases:
Finding the square root using Binary Search has applications in various fields, such as mathematics, engineering, physics, and computer graphics. It's often used when precise square root calculations are required, especially in scenarios where hardware or library-based square root functions are not available.
+
---
-### Question
+## Problem 3 Median of two sorted Arrays
-What advantage does using Binary Search for finding the square root of a number offer over directly calculating the square root?
+## Problem Statement
+Given two sorted arrays A and B of sizes m and n, respectively, your task is to find the **median** of the two sorted arrays.
+The median is the middle value in an ordered list of numbers. If the combined size of the two arrays (i.e., m + n) is odd, the median is the middle element. If the combined size is even, the median is the average of the two middle elements.
-**Choices**
-- [ ] Binary Search has a lower time complexity.
-- [x] Binary Search provides a more precise result.
-- [ ] Binary Search doesn't require any comparisons.
-- [ ] Binary Search can find the square root of any number.
+
----
-### Problem 3 Finding the Ath magical number
-In this problem, we are tasked with finding the a-th magical number that satisfies a specific condition. A magical number, in the context of this problem, is defined as a positive integer that is divisible by either b or c (or both).
-* Magical Number Definition: A magical number is a positive integer that is divisible by either b or c or both. In other words, if a number x is a magical number, it means that x % b == 0 or x % c == 0, or both conditions hold.
-* Task: Our task is to find and return the a-th magical number based on the conditions mentioned above.
-#### Example
-
-
### Example: Finding Square Root using Binary Search
**Scenario:**
@@ -283,8 +192,9 @@ We want to find the square root of the number 9 using Binary Search.
* We found an exact match! The square root of 9 is 3.
---
-### Finding the square root of a number Pseudocode
-#### Pseudocode:
+## Finding the square root of a number
+
+### Pseudocode:
Here's a simple pseudocode representation of finding the square root using Binary Search:
```cpp
@@ -310,7 +220,6 @@ function findSquareRoot(target):
return result
```
-
### Analysis and Complexity:
In each step of the Binary Search, we compare the square of the middle element with the target value. Depending on the result of this comparison, we adjust the search range. Since Binary Search divides the range in half with each step, the time complexity of this algorithm is O(log n), where n is the value of the target number.
@@ -318,252 +227,178 @@ In each step of the Binary Search, we compare the square of the middle element w
### Use Cases:
Finding the square root using Binary Search has applications in various fields, such as mathematics, engineering, physics, and computer graphics. It's often used when precise square root calculations are required, especially in scenarios where hardware or library-based square root functions are not available.
+
---
-### Question
+## Problem 3 Median of two sorted Arrays
-What advantage does using Binary Search for finding the square root of a number offer over directly calculating the square root?
+## Problem Statement
+Given two sorted arrays A and B of sizes m and n, respectively, your task is to find the **median** of the two sorted arrays.
+The median is the middle value in an ordered list of numbers. If the combined size of the two arrays (i.e., m + n) is odd, the median is the middle element. If the combined size is even, the median is the average of the two middle elements.
-**Choices**
-- [ ] Binary Search has a lower time complexity.
-- [x] Binary Search provides a more precise result.
-- [ ] Binary Search doesn't require any comparisons.
-- [ ] Binary Search can find the square root of any number.
+
----
-### Problem 3 Finding the Ath magical number
-In this problem, we are tasked with finding the a-th magical number that satisfies a specific condition. A magical number, in the context of this problem, is defined as a positive integer that is divisible by either b or c (or both).
-* Magical Number Definition: A magical number is a positive integer that is divisible by either b or c or both. In other words, if a number x is a magical number, it means that x % b == 0 or x % c == 0, or both conditions hold.
-* Task: Our task is to find and return the a-th magical number based on the conditions mentioned above.
-#### Example
- +**Example:**
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+A = [1,3,4,7,10,12]
+B = [2,3,6,15]
-#### Brute force
-```cpp
-Function findAMagicalNumberBruteForce(a, b, c):
- number = 1 // Start with the first positive integer
- count = 0 // Initialize the count of magical numbers found
+median = 5
- while count < a:
- if number is divisible by b or c:
- count = count + 1 // Increment the count if it's divisible by either b or c
- number = number + 1
+**Explantation**
- return number - 1 // Subtract 1 because we increased 'number' after finding the a-th magical number
-```
+On merging the two arrays, the resulting array when sorted, would look like [1,2,3,3,4,6,7,10,12,15].
+Hence, the median is (4+6)/2 = 5
-#### Observation
-
-Answer has to be a multiple of either B or C. So, we know we will get answer till A * B or A * C depending on which is smaller. Therefore, our answer range will be between`[1 to A * min(B,C)]`
-
-Example:
-A = 8
-B = 2
-C = 3
-
-A * B = 16
-A * C = 24
-So, our answer will be within range [1 to 16]
-
-**Que: How many multiples of B, C will be within range [1 to x]?** => x/B + x/C - x/LCM(B,C)$
-
-`The LCM of 'b' and 'c' represents the smallest common multiple of 'b' and 'c' such that any number that is divisible by both 'b' and 'c' will be a multiple of their LCM and we will have to subtract it`
-
-Example:
-A = 5
-B = 3
-C = 4
-Range => [1 to 15]
-Multiples
-=> 15/3 + 15/4 - 15/LCM(3,4)
-=> 5 + 3 + 1 = 7 `[3, 4, 6, 8, 9, 12, 15]`
-
-**Que: How to calculate LCM(B,C) ?**
-LCM(B,C) = (B * C) / GCD(B,C) [We know how to calculate GCD!]
-
-
-### Can we apply Binary Search ?
-
-**Search Space** => `[1 to A * min(B,C)]`
-**Target** => Ath Magical Number
-**Condition** =>
-* Say we land at mid.
-* To check mid is magical, we need to know how many magical numbers are there in the range [1, mid].
-* Compare with A: If the count is more than A, it means we need to search in the lower range [low, mid-1].
-* Otherwise, if count is < A, we need to search in higher range
-* If count == A, then we store mid as answer, and go left.
-
+**Example:**
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
+A = [1,3,4,7,10,12]
+B = [2,3,6,15]
-#### Brute force
-```cpp
-Function findAMagicalNumberBruteForce(a, b, c):
- number = 1 // Start with the first positive integer
- count = 0 // Initialize the count of magical numbers found
+median = 5
- while count < a:
- if number is divisible by b or c:
- count = count + 1 // Increment the count if it's divisible by either b or c
- number = number + 1
+**Explantation**
- return number - 1 // Subtract 1 because we increased 'number' after finding the a-th magical number
-```
+On merging the two arrays, the resulting array when sorted, would look like [1,2,3,3,4,6,7,10,12,15].
+Hence, the median is (4+6)/2 = 5
-#### Observation
-
-Answer has to be a multiple of either B or C. So, we know we will get answer till A * B or A * C depending on which is smaller. Therefore, our answer range will be between`[1 to A * min(B,C)]`
-
-Example:
-A = 8
-B = 2
-C = 3
-
-A * B = 16
-A * C = 24
-So, our answer will be within range [1 to 16]
-
-**Que: How many multiples of B, C will be within range [1 to x]?** => x/B + x/C - x/LCM(B,C)$
-
-`The LCM of 'b' and 'c' represents the smallest common multiple of 'b' and 'c' such that any number that is divisible by both 'b' and 'c' will be a multiple of their LCM and we will have to subtract it`
-
-Example:
-A = 5
-B = 3
-C = 4
-Range => [1 to 15]
-Multiples
-=> 15/3 + 15/4 - 15/LCM(3,4)
-=> 5 + 3 + 1 = 7 `[3, 4, 6, 8, 9, 12, 15]`
-
-**Que: How to calculate LCM(B,C) ?**
-LCM(B,C) = (B * C) / GCD(B,C) [We know how to calculate GCD!]
-
-
-### Can we apply Binary Search ?
-
-**Search Space** => `[1 to A * min(B,C)]`
-**Target** => Ath Magical Number
-**Condition** =>
-* Say we land at mid.
-* To check mid is magical, we need to know how many magical numbers are there in the range [1, mid].
-* Compare with A: If the count is more than A, it means we need to search in the lower range [low, mid-1].
-* Otherwise, if count is < A, we need to search in higher range
-* If count == A, then we store mid as answer, and go left.
- -
-
-#### Pseudocode:
-```cpp
-int count(x, B, C) {
- return x/B + x/C - x/LCM(B,C);
-}
-
-int magical(A, B, C) {
- l = 1, h = A * min(B,C)
- while(l <= h) {
- m = l + (h-l)/2;
- if(count(m,B,C) > A) {
- h = m-1;
- }
- else if(count(m,B,C) < A) {
- l = m+1;
- }
- else {
- ans = m;
- h = m-1;
- }
- }
- return ans;
-}
-```
----
-### Question
-What is the time complexity of the binary search approach for finding the a-th magical number in terms of A, B, and C?
-
-**Choices**
-
-- [ ] O(A)
-- [x] O(log A)
-- [ ] O(A * B * C)
-- [ ] O(log(A * B * C))
+### Brute Force Approach
----
-### Problem 4 Finding median of array
-
-**What is Median?**
-The median of an array is the middle element of the array when it is sorted. For arrays with an odd number of elements, the median is the value at the exact center. For arrays with an even number of elements, the median is typically defined as the average of the two middle elements. It's a measure of central tendency and divides the data into two equal halves when sorted.
+The brute force approach to find the median of two sorted arrays involves merging both arrays into a single sorted array, and then finding the median of this merged array.
-### Brute-Force Algorithm to Find the Median of an Array:
+Steps:
+1. Merge the two sorted arrays into one sorted array.
+2. Find the median of the merged array.
-* Sort the given array in ascending order. You can use any sorting algorithm (e.g., bubble sort, insertion sort, quicksort, or mergesort).
-* Calculate the length of the sorted array, denoted as n.
-* If n is odd, return the middle element of the sorted array as the median (e.g., sorted_array[n // 2]).
-* If n is even, calculate the average of the two middle elements and return it as the median (e.g., (sorted_array[n // 2 - 1] + sorted_array[n // 2]) / 2).
+### Implementation for Brute Force
```cpp
-def find_median_brute_force(arr):
- # Step 1: Sort the array
- sorted_array = sorted(arr)
+def findMedianBruteForce(arr1, arr2):
+ merged = []
+ i, j = 0, 0
- # Step 2: Calculate the length of the sorted array
- n = len(sorted_array)
+ while i < len(arr1) and j < len(arr2):
+ if arr1[i] < arr2[j]:
+ merged.append(arr1[i])
+ i += 1
+ else:
+ merged.append(arr2[j])
+ j += 1
- # Step 3: Find the median
- if n % 2 == 1:
- median = sorted_array[n // 2]
- else:
- median = (sorted_array[n // 2 - 1] + sorted_array[n // 2]) / 2.0
+ while i < len(arr1):
+ merged.append(arr1[i])
+ i += 1
- return median
+ while j < len(arr2):
+ merged.append(arr2[j])
+ j += 1
+
+ n = len(merged)
+ if n % 2 == 0:
+ return (merged[n // 2 - 1] + merged[n // 2]) / 2
+ else:
+ return merged[n // 2]
```
-:::warning
-Please take some time to think about the Binary Search approach on your own before reading further.....
-:::
+### Complexity Analysis for Brute Force:
+* **Time Complexity** :
+ Merging Two Arrays: O(m + n) where m and n are the lengths of the two arrays.
+ Finding the Median: O(1).
+ Overall Time Complexity: **0(m+n)**
+* **Space Complexity :**
+ The additional space is required to store the merged array, hence space complexity: **0(m+n)**
-### Binary Search Approach:
-The Binary Search technique can be harnessed to find the median of two sorted arrays by partitioning the arrays in such a way that the elements on the left side are less than or equal to the elements on the right side. The median will be either the middle element in a combined array (for an odd number of total elements) or the average of two middle elements (for an even number of elements).
+### Optimized Approach
-### Example: Finding Median of Two Sorted Arrays
+**Observations:**
-**Scenario**:
-Consider the two sorted arrays: nums1 = [1, 3, 5] and nums2 = [2, 4, 6]. We want to find the median of the combined array.
+1. Whenever we are dealing with sorted arrays, we should atleast once think about Binary Search to reduce Time Complexity.
-**Intuition:**
+
-* **Combined Sorted Array:** To find the median of two sorted arrays, you can think of combining them into a single sorted array. The median of this combined array will be our solution.
-* **Partitioning:** The key idea is to partition both arrays into two parts such that:
- * The elements on the left side are smaller than or equal to the elements on the right side.
- * The partitioning should be done in such a way that we can calculate the median easily.
+2. We know when we finally merge these arrays, we will have half elements on the left of median and half on the right of it. If we fix the number of elements from the first array that we will keep on the left, the number for second array gets fixed
-
-
-
-#### Pseudocode:
-```cpp
-int count(x, B, C) {
- return x/B + x/C - x/LCM(B,C);
-}
-
-int magical(A, B, C) {
- l = 1, h = A * min(B,C)
- while(l <= h) {
- m = l + (h-l)/2;
- if(count(m,B,C) > A) {
- h = m-1;
- }
- else if(count(m,B,C) < A) {
- l = m+1;
- }
- else {
- ans = m;
- h = m-1;
- }
- }
- return ans;
-}
-```
----
-### Question
-What is the time complexity of the binary search approach for finding the a-th magical number in terms of A, B, and C?
-
-**Choices**
-
-- [ ] O(A)
-- [x] O(log A)
-- [ ] O(A * B * C)
-- [ ] O(log(A * B * C))
+### Brute Force Approach
----
-### Problem 4 Finding median of array
-
-**What is Median?**
-The median of an array is the middle element of the array when it is sorted. For arrays with an odd number of elements, the median is the value at the exact center. For arrays with an even number of elements, the median is typically defined as the average of the two middle elements. It's a measure of central tendency and divides the data into two equal halves when sorted.
+The brute force approach to find the median of two sorted arrays involves merging both arrays into a single sorted array, and then finding the median of this merged array.
-### Brute-Force Algorithm to Find the Median of an Array:
+Steps:
+1. Merge the two sorted arrays into one sorted array.
+2. Find the median of the merged array.
-* Sort the given array in ascending order. You can use any sorting algorithm (e.g., bubble sort, insertion sort, quicksort, or mergesort).
-* Calculate the length of the sorted array, denoted as n.
-* If n is odd, return the middle element of the sorted array as the median (e.g., sorted_array[n // 2]).
-* If n is even, calculate the average of the two middle elements and return it as the median (e.g., (sorted_array[n // 2 - 1] + sorted_array[n // 2]) / 2).
+### Implementation for Brute Force
```cpp
-def find_median_brute_force(arr):
- # Step 1: Sort the array
- sorted_array = sorted(arr)
+def findMedianBruteForce(arr1, arr2):
+ merged = []
+ i, j = 0, 0
- # Step 2: Calculate the length of the sorted array
- n = len(sorted_array)
+ while i < len(arr1) and j < len(arr2):
+ if arr1[i] < arr2[j]:
+ merged.append(arr1[i])
+ i += 1
+ else:
+ merged.append(arr2[j])
+ j += 1
- # Step 3: Find the median
- if n % 2 == 1:
- median = sorted_array[n // 2]
- else:
- median = (sorted_array[n // 2 - 1] + sorted_array[n // 2]) / 2.0
+ while i < len(arr1):
+ merged.append(arr1[i])
+ i += 1
- return median
+ while j < len(arr2):
+ merged.append(arr2[j])
+ j += 1
+
+ n = len(merged)
+ if n % 2 == 0:
+ return (merged[n // 2 - 1] + merged[n // 2]) / 2
+ else:
+ return merged[n // 2]
```
-:::warning
-Please take some time to think about the Binary Search approach on your own before reading further.....
-:::
+### Complexity Analysis for Brute Force:
+* **Time Complexity** :
+ Merging Two Arrays: O(m + n) where m and n are the lengths of the two arrays.
+ Finding the Median: O(1).
+ Overall Time Complexity: **0(m+n)**
+* **Space Complexity :**
+ The additional space is required to store the merged array, hence space complexity: **0(m+n)**
-### Binary Search Approach:
-The Binary Search technique can be harnessed to find the median of two sorted arrays by partitioning the arrays in such a way that the elements on the left side are less than or equal to the elements on the right side. The median will be either the middle element in a combined array (for an odd number of total elements) or the average of two middle elements (for an even number of elements).
+### Optimized Approach
-### Example: Finding Median of Two Sorted Arrays
+**Observations:**
-**Scenario**:
-Consider the two sorted arrays: nums1 = [1, 3, 5] and nums2 = [2, 4, 6]. We want to find the median of the combined array.
+1. Whenever we are dealing with sorted arrays, we should atleast once think about Binary Search to reduce Time Complexity.
-**Intuition:**
+
-* **Combined Sorted Array:** To find the median of two sorted arrays, you can think of combining them into a single sorted array. The median of this combined array will be our solution.
-* **Partitioning:** The key idea is to partition both arrays into two parts such that:
- * The elements on the left side are smaller than or equal to the elements on the right side.
- * The partitioning should be done in such a way that we can calculate the median easily.
+2. We know when we finally merge these arrays, we will have half elements on the left of median and half on the right of it. If we fix the number of elements from the first array that we will keep on the left, the number for second array gets fixed
- +
-* **Binary Search:** To achieve this, we can perform a binary search on the smaller array (in this case, nums1). We calculate a partition point in nums1, and then we can calculate the corresponding partition point in nums2.
-
+
-* **Binary Search:** To achieve this, we can perform a binary search on the smaller array (in this case, nums1). We calculate a partition point in nums1, and then we can calculate the corresponding partition point in nums2.
- +**Steps:**
-* **Median Calculation:** Once we have the partitions, we can calculate the maximum element on the left side (max_left) and the minimum element on the right side (min_right) in both arrays. The median will be the average of max_left and min_right.
-
+**Steps:**
-* **Median Calculation:** Once we have the partitions, we can calculate the maximum element on the left side (max_left) and the minimum element on the right side (min_right) in both arrays. The median will be the average of max_left and min_right.
- +1) Assume two arrays, A and B, where A is the smaller one.
+2) Use binary search on the smaller array to partition it and the larger array such that the elements on the left partition are less than or equal to the elements on the right partition. It is sufficient to check the boundary elements to ascertain that.
-* **Handling Even and Odd Lengths:** Depending on whether the total length of the combined array is even or odd, the median calculation varies. If it's even, we average the two values; if it's odd, we take the middle value.
+
+
-**Solution**:
-* We start by calculating the total length of the combined arrays to determine if the median will be even or odd.
-* Then, we use binary search on the smaller array (nums1) to find a partition point that satisfies the conditions mentioned earlier. This ensures that elements on the left are smaller or equal to elements on the right.
-* We calculate max_left and min_right for both arrays based on the partitions.
-* Finally, we calculate the median as the average of max_left and min_right.
-**Binary Search:**
+Lets take a few examples to solidify this step
+
-* Initialize left = 0 and right = len(nums1) = 3.
-* Iteration 1:
-* Calculate partition_nums1 = $(0 + 3) / 2 = 1$.
-* Calculate partition_nums2 = $(6 + 1) / 2 - 1 = 2$.
-* Calculate max_left_nums1 = 1 and max_left_nums2 = 2.
-* Calculate min_right_nums1 = 3 and min_right_nums2 = 4.
-* Since 1 <= 4 and 2 <= 3, we have found the correct partition.
-* Since the total length is even (6), the median is the average of the maximum of left elements and the minimum of right elements, which is $(2 + 3) / 2 = 2.5$.
+If we choose 4 as the number of elements to be on the left from the A, B needs to have 1 element on the left part. We can see that this is not a valid partition as 7 > 3 violates the requirement.
----
+
-#### Pseudocode:
-Here's a simplified pseudocode representation of finding the median of two sorted arrays using Binary Search:
+If we choose 2 elements from A to be on the left, B needs to have 3. Here too 6>4 violates the condition.
+
-```cpp
-function findMedianSortedArrays(nums1, nums2):
- if len(nums1) > len(nums2):
- nums1, nums2 = nums2, nums1
-
- total_length = len(nums1) + len(nums2)
- left = 0
- right = len(nums1)
+For 3 elements from A, our condition is satisified.
- while left <= right:
- partition_nums1 = (left + right) / 2
- partition_nums2 = (total_length + 1) / 2 - partition_nums1
+3) Find the maximum element on the left and the minimum element on the right. The median is calculated based on whether the total number of elements is odd or even.
- max_left_nums1 = float('-inf') if partition_nums1 == 0 else nums1[partition_nums1 - 1]
- max_left_nums2 = float('-inf') if partition_nums2 == 0 else nums2[partition_nums2 - 1]
+**Implementation for Optimized approach**
- min_right_nums1 = float('inf') if partition_nums1 == len(nums1) else nums1[partition_nums1]
- min_right_nums2 = float('inf') if partition_nums2 == len(nums2) else nums2[partition_nums2]
+```cpp
+function findMedianOptimized(arr1, arr2):
+ if length(arr1) > length(arr2):
+ # Ensure arr1 is smaller than arr2
+ swap(arr1, arr2)
+
+ x = length(arr1)
+ y = length(arr2)
+ low = 0
+ high = x
+
+ # Binary search on the smaller array (arr1)
+ while low <= high:
+ partitionX = (low + high) // 2
+ partitionY = (x + y + 1) // 2 - partitionX
+
+ # maxX is the largest element on the left side of arr1
+ if partitionX == 0:
+ maxX = negative infinity
+ else:
+ maxX = arr1[partitionX - 1]
- if max_left_nums1 <= min_right_nums2 and max_left_nums2 <= min_right_nums1:
- if total_length % 2 == 0:
- return (max(max_left_nums1, max_left_nums2) + min(min_right_nums1, min_right_nums2)) / 2
+ # maxY is the largest element on the left side of arr2
+ if partitionY == 0:
+ maxY = negative infinity
+ else:
+ maxY = arr2[partitionY - 1]
+
+ # minX is the smallest element on the right side of arr1
+ if partitionX == x:
+ minX = positive infinity
+ else:
+ minX = arr1[partitionX]
+
+ # minY is the smallest element on the right side of arr2
+ if partitionY == y:
+ minY = positive infinity
+ else:
+ minY = arr2[partitionY]
+
+ # Check if we found the correct partition
+ if maxX <= minY and maxY <= minX:
+ # If total elements are even
+ if (x + y) % 2 == 0:
+ return (max(maxX, maxY) + min(minX, minY)) / 2
+ # If total elements are odd
else:
- return max(max_left_nums1, max_left_nums2)
- elif max_left_nums1 > min_right_nums2:
- right = partition_nums1 - 1
+ return max(maxX, maxY)
+
+ # If maxX > minY, we took too many elements from arr1
+ elif maxX > minY:
+ high = partitionX - 1
+ # If maxY > minX, we took too few elements from arr1
else:
- left = partition_nums1 + 1
+ low = partitionX + 1
+
```
-#### Analysis:
-In each iteration, the algorithm adjusts the partition positions based on the comparison of maximum elements on the left side with minimum elements on the right side of the partitions. The Binary Search nature of this algorithm leads to a time complexity of O(log(min(m, n))), where m and n are the lengths of the two input arrays.
-#### Use Cases:
-The concept of finding the median of two sorted arrays is crucial in various fields, including data analysis, algorithms, and statistics.
+### Complexity Analysis of Optimized Approach:
+* Time Complexity: **O(log(min(m, n)))**.
+* Space Complexity: **O(1)** (no extra space except variables for the binary search).
----
-### Observations
-
-* **Sorted Arrays:** Binary Search excels in sorted arrays, capitalizing on their inherent order to quickly locate elements.
-* **Search Space:** Identify the range within which the solution exists, which guides setting up the initial search range.
-* **Midpoint Element:** The middle element provides insights into the properties of elements in different subranges, aiding decisions in adjusting the search range.
-* **Stopping Condition:** Define conditions under which the search should stop, whether an element is found or the search range becomes empty.
-* **Divide and Conquer:** Binary Search employs a "divide and conquer" strategy, progressively reducing the problem size.
-* **Boundary Handling:** Pay special attention to handling boundary conditions, avoiding index out-of-bounds errors.
-* **Precision & Approximations:** Binary Search can yield approximate solutions by adjusting the search criteria.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md b/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md
index fa33107..43be9aa 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md
@@ -1,8 +1,54 @@
# Searching 3: Binary Search on Answer
+
+### Question
+What modification can be made to binary search to handle duplicate elements in a sorted array when searching for the first occurrence of a target?
+
+### Choices
+- [ ] Stop the search as soon as the target is found.
+- [x] Continue the search in the left subarray even after finding the target.
+- [ ] Switch to linear search after finding the target.
+- [ ] Duplicate elements should be removed before applying binary search.
+
+---
+
+### Question
+In finding square root. What should be done if the squared midpoint is less than the target when finding the square root using binary search?
+
+### Choices
+- [ ] Adjust the search range to the left half
+- [ ] Return the midpoint as the square root
+- [x] Adjust the search range to the right half
+- [ ] Return the target as the square root
+
+---
+
+### Question
+What is the time complexity of using binary search to approximate the square root of a number?
+
+### Choices
+
+- [ ] O(n)
+- [x] O(log n)
+- [ ] O(n log n)
+- [ ] O(1)
+
+---
+
+### Question
+What is the space complexity of a recursive binary search implementation?
+
+### Choices
+- [x] O(log n) due to the call stack.
+- [ ] O(1) as it does not use additional space.
+- [ ] O(n) because it needs space for each element.
+- [ ] O(n log n) due to recursive divisions of the array.
+
---
## Problem 1 Painter's Partition
+
+### Problem Statement
We have to paint all N boards of length [C0, C1, C2, C3 … CN - 1]. There are K painters available and each of them takes 1 units of time to paint 1 unit of the board.
Calculate and return the minimum time required to get the job done.
@@ -10,7 +56,7 @@ Calculate and return the minimum time required to get the job done.
> 1. Two painters cannot share a board to paint. That is to say, a board cannot be painted partially by one painter, and partially by another.
> 2. A painter will only paint contiguous boards. This means a painter paints a continous subarray of boards
-**Example 1**
+### Example 1
Below are some of the possible configurations:
+1) Assume two arrays, A and B, where A is the smaller one.
+2) Use binary search on the smaller array to partition it and the larger array such that the elements on the left partition are less than or equal to the elements on the right partition. It is sufficient to check the boundary elements to ascertain that.
-* **Handling Even and Odd Lengths:** Depending on whether the total length of the combined array is even or odd, the median calculation varies. If it's even, we average the two values; if it's odd, we take the middle value.
+
+
-**Solution**:
-* We start by calculating the total length of the combined arrays to determine if the median will be even or odd.
-* Then, we use binary search on the smaller array (nums1) to find a partition point that satisfies the conditions mentioned earlier. This ensures that elements on the left are smaller or equal to elements on the right.
-* We calculate max_left and min_right for both arrays based on the partitions.
-* Finally, we calculate the median as the average of max_left and min_right.
-**Binary Search:**
+Lets take a few examples to solidify this step
+
-* Initialize left = 0 and right = len(nums1) = 3.
-* Iteration 1:
-* Calculate partition_nums1 = $(0 + 3) / 2 = 1$.
-* Calculate partition_nums2 = $(6 + 1) / 2 - 1 = 2$.
-* Calculate max_left_nums1 = 1 and max_left_nums2 = 2.
-* Calculate min_right_nums1 = 3 and min_right_nums2 = 4.
-* Since 1 <= 4 and 2 <= 3, we have found the correct partition.
-* Since the total length is even (6), the median is the average of the maximum of left elements and the minimum of right elements, which is $(2 + 3) / 2 = 2.5$.
+If we choose 4 as the number of elements to be on the left from the A, B needs to have 1 element on the left part. We can see that this is not a valid partition as 7 > 3 violates the requirement.
----
+
-#### Pseudocode:
-Here's a simplified pseudocode representation of finding the median of two sorted arrays using Binary Search:
+If we choose 2 elements from A to be on the left, B needs to have 3. Here too 6>4 violates the condition.
+
-```cpp
-function findMedianSortedArrays(nums1, nums2):
- if len(nums1) > len(nums2):
- nums1, nums2 = nums2, nums1
-
- total_length = len(nums1) + len(nums2)
- left = 0
- right = len(nums1)
+For 3 elements from A, our condition is satisified.
- while left <= right:
- partition_nums1 = (left + right) / 2
- partition_nums2 = (total_length + 1) / 2 - partition_nums1
+3) Find the maximum element on the left and the minimum element on the right. The median is calculated based on whether the total number of elements is odd or even.
- max_left_nums1 = float('-inf') if partition_nums1 == 0 else nums1[partition_nums1 - 1]
- max_left_nums2 = float('-inf') if partition_nums2 == 0 else nums2[partition_nums2 - 1]
+**Implementation for Optimized approach**
- min_right_nums1 = float('inf') if partition_nums1 == len(nums1) else nums1[partition_nums1]
- min_right_nums2 = float('inf') if partition_nums2 == len(nums2) else nums2[partition_nums2]
+```cpp
+function findMedianOptimized(arr1, arr2):
+ if length(arr1) > length(arr2):
+ # Ensure arr1 is smaller than arr2
+ swap(arr1, arr2)
+
+ x = length(arr1)
+ y = length(arr2)
+ low = 0
+ high = x
+
+ # Binary search on the smaller array (arr1)
+ while low <= high:
+ partitionX = (low + high) // 2
+ partitionY = (x + y + 1) // 2 - partitionX
+
+ # maxX is the largest element on the left side of arr1
+ if partitionX == 0:
+ maxX = negative infinity
+ else:
+ maxX = arr1[partitionX - 1]
- if max_left_nums1 <= min_right_nums2 and max_left_nums2 <= min_right_nums1:
- if total_length % 2 == 0:
- return (max(max_left_nums1, max_left_nums2) + min(min_right_nums1, min_right_nums2)) / 2
+ # maxY is the largest element on the left side of arr2
+ if partitionY == 0:
+ maxY = negative infinity
+ else:
+ maxY = arr2[partitionY - 1]
+
+ # minX is the smallest element on the right side of arr1
+ if partitionX == x:
+ minX = positive infinity
+ else:
+ minX = arr1[partitionX]
+
+ # minY is the smallest element on the right side of arr2
+ if partitionY == y:
+ minY = positive infinity
+ else:
+ minY = arr2[partitionY]
+
+ # Check if we found the correct partition
+ if maxX <= minY and maxY <= minX:
+ # If total elements are even
+ if (x + y) % 2 == 0:
+ return (max(maxX, maxY) + min(minX, minY)) / 2
+ # If total elements are odd
else:
- return max(max_left_nums1, max_left_nums2)
- elif max_left_nums1 > min_right_nums2:
- right = partition_nums1 - 1
+ return max(maxX, maxY)
+
+ # If maxX > minY, we took too many elements from arr1
+ elif maxX > minY:
+ high = partitionX - 1
+ # If maxY > minX, we took too few elements from arr1
else:
- left = partition_nums1 + 1
+ low = partitionX + 1
+
```
-#### Analysis:
-In each iteration, the algorithm adjusts the partition positions based on the comparison of maximum elements on the left side with minimum elements on the right side of the partitions. The Binary Search nature of this algorithm leads to a time complexity of O(log(min(m, n))), where m and n are the lengths of the two input arrays.
-#### Use Cases:
-The concept of finding the median of two sorted arrays is crucial in various fields, including data analysis, algorithms, and statistics.
+### Complexity Analysis of Optimized Approach:
+* Time Complexity: **O(log(min(m, n)))**.
+* Space Complexity: **O(1)** (no extra space except variables for the binary search).
----
-### Observations
-
-* **Sorted Arrays:** Binary Search excels in sorted arrays, capitalizing on their inherent order to quickly locate elements.
-* **Search Space:** Identify the range within which the solution exists, which guides setting up the initial search range.
-* **Midpoint Element:** The middle element provides insights into the properties of elements in different subranges, aiding decisions in adjusting the search range.
-* **Stopping Condition:** Define conditions under which the search should stop, whether an element is found or the search range becomes empty.
-* **Divide and Conquer:** Binary Search employs a "divide and conquer" strategy, progressively reducing the problem size.
-* **Boundary Handling:** Pay special attention to handling boundary conditions, avoiding index out-of-bounds errors.
-* **Precision & Approximations:** Binary Search can yield approximate solutions by adjusting the search criteria.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md b/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md
index fa33107..43be9aa 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Searching 3 Binary Search on Answer.md
@@ -1,8 +1,54 @@
# Searching 3: Binary Search on Answer
+
+### Question
+What modification can be made to binary search to handle duplicate elements in a sorted array when searching for the first occurrence of a target?
+
+### Choices
+- [ ] Stop the search as soon as the target is found.
+- [x] Continue the search in the left subarray even after finding the target.
+- [ ] Switch to linear search after finding the target.
+- [ ] Duplicate elements should be removed before applying binary search.
+
+---
+
+### Question
+In finding square root. What should be done if the squared midpoint is less than the target when finding the square root using binary search?
+
+### Choices
+- [ ] Adjust the search range to the left half
+- [ ] Return the midpoint as the square root
+- [x] Adjust the search range to the right half
+- [ ] Return the target as the square root
+
+---
+
+### Question
+What is the time complexity of using binary search to approximate the square root of a number?
+
+### Choices
+
+- [ ] O(n)
+- [x] O(log n)
+- [ ] O(n log n)
+- [ ] O(1)
+
+---
+
+### Question
+What is the space complexity of a recursive binary search implementation?
+
+### Choices
+- [x] O(log n) due to the call stack.
+- [ ] O(1) as it does not use additional space.
+- [ ] O(n) because it needs space for each element.
+- [ ] O(n log n) due to recursive divisions of the array.
+
---
## Problem 1 Painter's Partition
+
+### Problem Statement
We have to paint all N boards of length [C0, C1, C2, C3 … CN - 1]. There are K painters available and each of them takes 1 units of time to paint 1 unit of the board.
Calculate and return the minimum time required to get the job done.
@@ -10,7 +56,7 @@ Calculate and return the minimum time required to get the job done.
> 1. Two painters cannot share a board to paint. That is to say, a board cannot be painted partially by one painter, and partially by another.
> 2. A painter will only paint contiguous boards. This means a painter paints a continous subarray of boards
-**Example 1**
+### Example 1
Below are some of the possible configurations:
 @@ -22,7 +68,7 @@ Configuration 3: Max is 25
There can be more configurations, but you'll find the 3rd to be the best, hence **`25`** is the answer.
-**Example 2**
+### Example 2
```cpp
A = [10,20,30,40]
K = 2
@@ -36,16 +82,11 @@ Max = 70
Max = 60
-**Output**
+### Output
60
---
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Painter's Partition Greedy Approach
+## Painter's Partition Greedy Approach
* Greedy Approach:- We can just divide the total time by total number of painters.
* One might think it as by dividing the boards among the painters would result in least time per painter
@@ -60,19 +101,20 @@ According to Idea 1 :- $110/2 = 55$
But we see that it is impossible, because we can't divide the boards among two painters with 55 length each.
---
+
### Question
What is the minimum time to get the job done?
A = [1,2,3,4,100] K = 2
-**Choices**
+### Choices
- [ ] 55
- [x] 100
- [ ] 1
- [ ] 110
-**Explanation:**
+### Explanation:
The minimum time required to Finish the job is 100.
The configuration of the boards is as follows
@@ -86,7 +128,7 @@ Among all possible configuration **100** is the minimum time achieved.
---
-### Painter's Partition Binary Search
+## Painter's Partition Binary Search
Lets's look at example below :-
@@ -99,8 +141,8 @@ Color code for each painter:
> P3 -> Blue
> P4 -> Orange
----
-#### Search Space
+### Search Space
+
**Best Case**
Say we have as many painters as the number of boards, in which case each painter can paint one board. The maximum value will be the answer.
**Example:**
@@ -112,22 +154,19 @@ There is ony 1 painter. In this case, sum(array) is the answer.
So, our Search Space will be within range: **[max(array) to sum(array)]**
----
-#### Target
+### Target
The max time to complete the task
----
-#### Condition
+### Condition
* Say we land at mid. How can we decide whether mid is the answer?
* We can check if we can complete the task within mid amount of time at max.
* If yes, then we should save it as the answer and move left to try for a lesser time.
* Else, move right(it means we will need more time to complete the task )
----
-### Painter's Partition Dry Run and Pseudocode
-
+## Painter's Partition Dry Run and Pseudocode
+
`[3, 5, 1, 7, 8, 2, 5, 3, 10, 1, 4, 7, 5, 4, 6]` ans `K = 4`
* Intially the **Lo = 10** and **Hi = 71** (By using above defined criteria for search space) therefore using the above algorithm Mid = $10 + (71 - 10)/2 = 40$ then we check if it is possible to paint all boards in atleast 40 units below is the configuration that satisfy the condition :-
@@ -150,82 +189,98 @@ The max time to complete the task
@@ -22,7 +68,7 @@ Configuration 3: Max is 25
There can be more configurations, but you'll find the 3rd to be the best, hence **`25`** is the answer.
-**Example 2**
+### Example 2
```cpp
A = [10,20,30,40]
K = 2
@@ -36,16 +82,11 @@ Max = 70
Max = 60
-**Output**
+### Output
60
---
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Painter's Partition Greedy Approach
+## Painter's Partition Greedy Approach
* Greedy Approach:- We can just divide the total time by total number of painters.
* One might think it as by dividing the boards among the painters would result in least time per painter
@@ -60,19 +101,20 @@ According to Idea 1 :- $110/2 = 55$
But we see that it is impossible, because we can't divide the boards among two painters with 55 length each.
---
+
### Question
What is the minimum time to get the job done?
A = [1,2,3,4,100] K = 2
-**Choices**
+### Choices
- [ ] 55
- [x] 100
- [ ] 1
- [ ] 110
-**Explanation:**
+### Explanation:
The minimum time required to Finish the job is 100.
The configuration of the boards is as follows
@@ -86,7 +128,7 @@ Among all possible configuration **100** is the minimum time achieved.
---
-### Painter's Partition Binary Search
+## Painter's Partition Binary Search
Lets's look at example below :-
@@ -99,8 +141,8 @@ Color code for each painter:
> P3 -> Blue
> P4 -> Orange
----
-#### Search Space
+### Search Space
+
**Best Case**
Say we have as many painters as the number of boards, in which case each painter can paint one board. The maximum value will be the answer.
**Example:**
@@ -112,22 +154,19 @@ There is ony 1 painter. In this case, sum(array) is the answer.
So, our Search Space will be within range: **[max(array) to sum(array)]**
----
-#### Target
+### Target
The max time to complete the task
----
-#### Condition
+### Condition
* Say we land at mid. How can we decide whether mid is the answer?
* We can check if we can complete the task within mid amount of time at max.
* If yes, then we should save it as the answer and move left to try for a lesser time.
* Else, move right(it means we will need more time to complete the task )
----
-### Painter's Partition Dry Run and Pseudocode
-
+## Painter's Partition Dry Run and Pseudocode
+
`[3, 5, 1, 7, 8, 2, 5, 3, 10, 1, 4, 7, 5, 4, 6]` ans `K = 4`
* Intially the **Lo = 10** and **Hi = 71** (By using above defined criteria for search space) therefore using the above algorithm Mid = $10 + (71 - 10)/2 = 40$ then we check if it is possible to paint all boards in atleast 40 units below is the configuration that satisfy the condition :-
@@ -150,82 +189,98 @@ The max time to complete the task
 -#### Pseudocode
+### Pseudocode
```cpp
// Find minimum painters required for given maximum length (Length that painter can paint)
-paintersNumber(arr[], N, mid, K) {
- res = 0, numPainters = 1;
+paintersNumber(arr[], N, mid, K)
+{
+ res = 0, numPainters = 1;
- for (i = 0; i < N; i++) {
- res += arr[i];
+ for (i -> 0 to N - 1) {
+ res += arr[i];
- if (res > mid) {
- res = arr[i];
- numPainters++;
+ if (res > mid) {
+ res = arr[i];
+ numPainters++;
+ }
}
- }
- //if we have used less than or equal to given number of painters,
- //then the configurations works
- if (numPainters <= K) return true;
- else return false;
+ //if we have used less than or equal to given number of painters,
+ //then the configurations works
+ if(numPainters <= K)return true;
+ else return false;
}
-partition(arr[], N, K) {
- Lo = maxEle(arr, N);
- Hi = sumArr(arr, N);
- while (Lo <= Hi) {
- mid = Lo + (Hi - Lo) / 2;
+partition(arr[], N, K)
+{
+ Lo = maxEle(arr, N);
+ Hi = sumArr(arr, N);
- if (paintersNumber(arr, N, mid, K))
- ans = mid
- Hi = mid - 1;
- else
- Lo = mid + 1;
- }
- return ans;
+ while (Lo <= Hi) {
+ mid = Lo + (Hi - Lo) / 2;
+
+ if (paintersNumber(arr, N, mid, K))
+ ans = mid
+ Hi = mid - 1 ;
+ else
+ Lo = mid + 1;
+ }
+ return ans;
}
```
-#### Complexities
+### Complexities
**Time Complexity:** O(log (sum - max) * N )
**Space Complexity:** O(1)
---
+
### Question
What is the time complexity of the Painters Partition Problem?
-**Choices**
-- [x] O( log(k) * (sum(boards) - max(boards)))
+### Choices
+- [ ] O( log(k) * (sum(boards) - max(boards)))
- [ ] O(k * log(sum(boards) - max(boards)))
-- [ ] O(N * log(sum(boards) - max(boards)))
+- [x] O(N * log(sum(boards) - max(boards)))
- [ ] O(k * log N)
+---
+## Email Response Handlers
+
+### Situation:
+Imagine you are tasked with developing a system for evenly distributing the workload among a team of email response handlers in a customer service department. Each email is assigned a 'complexity score' which represents the estimated time and effort required to address it. The complexity scores are represented as an array, where each element corresponds to a single email.
+### Task
+The goal is to divide the array into K contiguous blocks (where K is the number of email handlers), such that the maximum sum of the complexity scores in any block is minimized. This approach aims to ensure that no single email handler is overwhelmed with high-complexity emails while others have a lighter load.
+
+### Approach
+This problem is same as painter's partition. This is just a real life example.
---
-### Problem 2 Aggresive Cows
+## Problem 2 Aggresive Cows
+
+### Problem Statement
Given N cows & M stalls ,all M stalls are located at the different locations at x-axis, place all the cows such that minimum distance between any two cows is maximized.
> Note :
> 1. There can be only one cow in a stall at a time
> 2. We need to place all cows
-**Testcase 1**
+### Testcase 1
```cpp
stalls = [1, 2, 4, 8, 9]
cows = 3
stall = 5
```
-**Solution**
+### Solution
```cpp
T = 3
```
-**Explaination TestCase 1**
+### Explaination TestCase 1
@@ -241,18 +296,18 @@ T = 3
* If we put cows according to the third configuration then min distance = 1 because of c2 and c3 (shortest distance between any two cows is 1).
* Therefore answer = max(1,3,1) = 3
-**Testcase 2**
+### Testcase 2
```cpp
stalls = [2, 6, 11, 14, 19, 25, 30, 39, 43]
cows = 4
stall = 9
```
-**Solution**
+### Solution
```cpp
T = 12
```
-**Explaination TestCase 2**
+### Explaination TestCase 2
| 2 | 6 | 11 | 14 | 19 | 25 | 30 | 39 | 43 | Min distance |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:------------:|
@@ -267,31 +322,34 @@ T = 12
---
+
+
### Question
What is the objective of the problem described?
-**Choices**
+### Choices
- [ ] Place cows in stalls randomly.
- [ ] Place cows in stalls such that the distance between any two cows is minimized.
- [x] Place cows in stalls such that the minimum distance between any two cows is maximized.
- [ ] Place cows in stalls such that the total distance is minimized.
---
+
+
### Question
What will be the maximum value of the distance between the closest cows in this case?
A: 0, 3, 4, 7, 9, 10
K = 4
-**Choices**
+### Choices
- [ ] 10
- [ ] 4
- [x] 3
- [ ] 2
-
-**Explanation:**
+### Explanation:
The 4 cows are placed in stalls at 0, 3, 7, 10. This is the optimal configuration.
@@ -305,20 +363,14 @@ Thus the maximum result is 3 over all possible configurations.
---
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-### Aggresive Cows Binary Search Approach
+## Aggresive Cows Binary Search Approach
Let's use testcase 2 to get the intuition of the question.
This question is similar to Painter's Partition problem. Instead of minimising the maximum answer, we have to maximise the minimum distance.
-#### Search Space
+### Search Space
* **Worst Case:**
If say there are same cows as the number of stalls, then we place each cow at 1 stall. Then we can find difference between adjacent stalls. The minimum out of them is the answer.
@@ -335,7 +387,7 @@ There are two cows. Then, we can place them at the corner stalls. The distance b
**Search Space:** [1 A[N-1]-A[0]]
-#### Condition
+### Condition
Say we land at mid, now we can check if it is possible to keep cows at a minimum distance of mid.
* If yes, save it and check for farther distance, i.e, move right.
* Else, if keeping at a distance of mid is not possible, then we should try reducing the distance; hence, move left.
@@ -360,7 +412,7 @@ Since we are able to place all cows at a minimum distance of 5, we should save i
---
-### Aggresive Cows Dry Run and Pseudocode
+## Aggresive Cows Dry Run and Pseudocode
Below is the trace of algorithm on above Example :-
@@ -386,56 +438,59 @@ Below is the trace of algorithm on above Example :-
-#### Pseudocode
+### Pseudocode
```cpp
// Find minimum painters required for given maximum length (Length that painter can paint)
-paintersNumber(arr[], N, mid, K) {
- res = 0, numPainters = 1;
+paintersNumber(arr[], N, mid, K)
+{
+ res = 0, numPainters = 1;
- for (i = 0; i < N; i++) {
- res += arr[i];
+ for (i -> 0 to N - 1) {
+ res += arr[i];
- if (res > mid) {
- res = arr[i];
- numPainters++;
+ if (res > mid) {
+ res = arr[i];
+ numPainters++;
+ }
}
- }
- //if we have used less than or equal to given number of painters,
- //then the configurations works
- if (numPainters <= K) return true;
- else return false;
+ //if we have used less than or equal to given number of painters,
+ //then the configurations works
+ if(numPainters <= K)return true;
+ else return false;
}
-partition(arr[], N, K) {
- Lo = maxEle(arr, N);
- Hi = sumArr(arr, N);
- while (Lo <= Hi) {
- mid = Lo + (Hi - Lo) / 2;
+partition(arr[], N, K)
+{
+ Lo = maxEle(arr, N);
+ Hi = sumArr(arr, N);
- if (paintersNumber(arr, N, mid, K))
- ans = mid
- Hi = mid - 1;
- else
- Lo = mid + 1;
- }
- return ans;
+ while (Lo <= Hi) {
+ mid = Lo + (Hi - Lo) / 2;
+
+ if (paintersNumber(arr, N, mid, K))
+ ans = mid
+ Hi = mid - 1 ;
+ else
+ Lo = mid + 1;
+ }
+ return ans;
}
```
-#### Complexities
+### Complexities
**Time Complexity:** O(log (sum - max) * N )
**Space Complexity:** O(1)
---
+
### Question
What is the time complexity of the Painters Partition Problem?
-**Choices**
-- [x] O( log(k) * (sum(boards) - max(boards)))
+### Choices
+- [ ] O( log(k) * (sum(boards) - max(boards)))
- [ ] O(k * log(sum(boards) - max(boards)))
-- [ ] O(N * log(sum(boards) - max(boards)))
+- [x] O(N * log(sum(boards) - max(boards)))
- [ ] O(k * log N)
+---
+## Email Response Handlers
+
+### Situation:
+Imagine you are tasked with developing a system for evenly distributing the workload among a team of email response handlers in a customer service department. Each email is assigned a 'complexity score' which represents the estimated time and effort required to address it. The complexity scores are represented as an array, where each element corresponds to a single email.
+### Task
+The goal is to divide the array into K contiguous blocks (where K is the number of email handlers), such that the maximum sum of the complexity scores in any block is minimized. This approach aims to ensure that no single email handler is overwhelmed with high-complexity emails while others have a lighter load.
+
+### Approach
+This problem is same as painter's partition. This is just a real life example.
---
-### Problem 2 Aggresive Cows
+## Problem 2 Aggresive Cows
+
+### Problem Statement
Given N cows & M stalls ,all M stalls are located at the different locations at x-axis, place all the cows such that minimum distance between any two cows is maximized.
> Note :
> 1. There can be only one cow in a stall at a time
> 2. We need to place all cows
-**Testcase 1**
+### Testcase 1
```cpp
stalls = [1, 2, 4, 8, 9]
cows = 3
stall = 5
```
-**Solution**
+### Solution
```cpp
T = 3
```
-**Explaination TestCase 1**
+### Explaination TestCase 1
@@ -241,18 +296,18 @@ T = 3
* If we put cows according to the third configuration then min distance = 1 because of c2 and c3 (shortest distance between any two cows is 1).
* Therefore answer = max(1,3,1) = 3
-**Testcase 2**
+### Testcase 2
```cpp
stalls = [2, 6, 11, 14, 19, 25, 30, 39, 43]
cows = 4
stall = 9
```
-**Solution**
+### Solution
```cpp
T = 12
```
-**Explaination TestCase 2**
+### Explaination TestCase 2
| 2 | 6 | 11 | 14 | 19 | 25 | 30 | 39 | 43 | Min distance |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:------------:|
@@ -267,31 +322,34 @@ T = 12
---
+
+
### Question
What is the objective of the problem described?
-**Choices**
+### Choices
- [ ] Place cows in stalls randomly.
- [ ] Place cows in stalls such that the distance between any two cows is minimized.
- [x] Place cows in stalls such that the minimum distance between any two cows is maximized.
- [ ] Place cows in stalls such that the total distance is minimized.
---
+
+
### Question
What will be the maximum value of the distance between the closest cows in this case?
A: 0, 3, 4, 7, 9, 10
K = 4
-**Choices**
+### Choices
- [ ] 10
- [ ] 4
- [x] 3
- [ ] 2
-
-**Explanation:**
+### Explanation:
The 4 cows are placed in stalls at 0, 3, 7, 10. This is the optimal configuration.
@@ -305,20 +363,14 @@ Thus the maximum result is 3 over all possible configurations.
---
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-
-### Aggresive Cows Binary Search Approach
+## Aggresive Cows Binary Search Approach
Let's use testcase 2 to get the intuition of the question.
This question is similar to Painter's Partition problem. Instead of minimising the maximum answer, we have to maximise the minimum distance.
-#### Search Space
+### Search Space
* **Worst Case:**
If say there are same cows as the number of stalls, then we place each cow at 1 stall. Then we can find difference between adjacent stalls. The minimum out of them is the answer.
@@ -335,7 +387,7 @@ There are two cows. Then, we can place them at the corner stalls. The distance b
**Search Space:** [1 A[N-1]-A[0]]
-#### Condition
+### Condition
Say we land at mid, now we can check if it is possible to keep cows at a minimum distance of mid.
* If yes, save it and check for farther distance, i.e, move right.
* Else, if keeping at a distance of mid is not possible, then we should try reducing the distance; hence, move left.
@@ -360,7 +412,7 @@ Since we are able to place all cows at a minimum distance of 5, we should save i
---
-### Aggresive Cows Dry Run and Pseudocode
+## Aggresive Cows Dry Run and Pseudocode
Below is the trace of algorithm on above Example :-
@@ -386,56 +438,59 @@ Below is the trace of algorithm on above Example :-
 -#### Pseudocode
+### Pseudocode
```cpp
-bool check(v[], int x, int c) {
- n = v.size();
- count = 1;
- last = 0;
- for (i = 0; i < n; i++) {
- if (v[i] - v[last] >= x) {
- last = i; //cow placed
- count++;
- }
- if (count >= c) {
- return true;
+function check(v[], x, c)
+{
+ n = v.size();
+ count = 1;
+ last = 0;
+ for (i -> 0 to n - 1) {
+ if (v[i] - v[last] >= x) {
+ last = i; //cow placed
+ count++;
+ }
+ if (count >= c) {
+ return true;
+ }
}
- }
- return false;
+ return false;
}
-
+
// Function to find the maximum possible
// minimum distance between the cows
-aggressive_cows(v[], size, cows) {
- int lo = 0;
- for (i = 1; i < n; i++) {
- lo = min(lo, v[i] - v[i - 1]);
- }
- hi = v[n - 1] - v[0];
- ans = -1;
-
- // Applying Binary search
- while (lo <= hi) {
- mid = lo + (hi - lo) / 2;
- if (check(v, mid, cows)) {
- ans = mid;
- lo = mid + 1;
- } else {
- hi = mid - 1;
+aggressive_cows( v[], size , cows)
+{
+ lo = 0;
+ for (i -> 1 to n - 1)
+ {
+ lo = min(lo,v[i] - v[i - 1]);
}
- }
-
- return ans;
+ hi = v[n - 1] - v[0];
+ ans = -1;
+
+ // Applying Binary search
+ while (lo <= hi) {
+ mid = lo + (hi - lo) / 2;
+ if (check(v, mid, cows)) {
+ ans = mid;
+ lo = mid + 1;
+ }
+ else {
+ hi = mid - 1;
+ }
+ }
+
+ return ans;
}
```
---
-### Binary Search Problems Identification
+## Binary Search Problems Identification
* These type of problems generally has following characteristics :-
* There are two or three parameter & constraints
* Requirement is to maximize or minimize the given parameter
* One tricky point is to find search space which is generally the parameter asked to maximize or minimize.
* The problem should be **Monotonic** in nature i.e after one point it is not feasible to solve or vice versa.
-
diff --git a/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md b/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md
index 3c9b5fa..5b9daa6 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md
@@ -1,8 +1,10 @@
-# Count Sort & Merge Sort
+# Sorting 1: Count Sort & Merge Sort
+
----
## Count Sort
+### Problem Statement
+
Find the smallest number that can be formed by rearranging the digits of the given number in an array. Return the smallest number in the form an array.
**Example:**
@@ -12,38 +14,38 @@ Answer: `{1, 2, 2, 3, 4, 6, 7}`
A[ ] = `{4, 2, 7, 3, 9, 0}`
Answer: `{0, 2, 3, 4, 7, 9}`
-#### Observation/Hint
-we can to construct a number using digits. The digits in a number can only `range from 0 to 9`, thus instead of sorting the number which takes `O(N log N)` time, one can leverage this fixed range to derive a faster solution.
+### Observation/Hint
+The digits in a number can only `range from 0 to 9`, thus instead of sorting the number which takes `O(N log N)` time, one can leverage this fixed range to derive a faster solution.
-#### Approach
+### Approach
* **Frequency Count:** Create an `array of size 10` to count the frequency of each digit in the given number.
* Using the frequency array, reconstruct the original array in ascending order.
* This method of sorting based on frequency counting is often called "**`Count Sort`**".
-#### Pseudocode
+### Pseudocode
```cpp
Frequency Array of size 10
F = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-for i -> 0 to(N - 1) {
- F[A[i]]++
+for i -> 0 to (N - 1) {
+ F[A[i]] ++
}
k = 0
-for d -> 0 to 9 { // For each digit
- for i -> 1 to F[d] {
- A[k] = d
- k++
- }
+for d -> 0 to 9 { // For each digit
+ for i -> 1 to F[d] {
+ A[k] = d
+ k++
+ }
}
return A
```
-#### Dry Run
+### Dry Run
* A = `[1, 3, 8, 2, 3, 5, 3, 8, 5, 2, 2, 3]` (Given Array)
* F = `[0, 1, 3, 4, 0, 2, 0, 0, 2, 0]` (Frequency Array)
@@ -51,12 +53,13 @@ return A
1 (once), 2 (three times), 3 (four times), 5 (two times), 8 (two times)
* Resulting A = `[1, 2, 2, 2, 3, 3, 3, 3, 5, 5, 8, 8]`
-#### TC and SC
+### TC and SC
* **Time Complexity:** O(N)
* **Space Complexity:** O(1) (Since the size of the frequency array is constant, regardless of the size of N).
---
-### Count Sort on large values
+## Count Sort on large values
+
### Will Count Sort work if the range of A[i] is more than $10^9$?
@@ -68,63 +71,90 @@ Each integer typically occupies `4 Bytes`.
Storing $10^9$ integers requires 4GB, which is often impractical. An array up to $10^6$ in length is more manageable, needing 4MB.
---
-### Count Sort on Negative Numbers
+## Count Sort on Negative Numbers
+
+
+### Problem Statement
Implement Count Sort for an array containing negative numbers.
-#### Observation/Hint
+### Observation/Hint
Unlike conventional **Count Sort**, which operates on non-negative integers, this variation needs to account for negative numbers. The method involves adjusting indices in the frequency array based on the smallest element in the original array.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach
+### Approach
* **Find Range:** Determine the smallest and largest elements in the array to ascertain the range.
* **Adjust for Negative Numbers:** By adjusting indices in the frequency array based on the smallest element, negative numbers can be accounted for.
-**Example**
+### Example
* Given A = [-2, 3, 8, 3, -2, 3]
* Smallest = -2, Largest = 8
* Range = 11 (8 - (-2) + 1)
-* Frequency array F = [2, 0, 0, 3, 0, 0, 0, 0, 1]
+* Frequency array F = [2, 0, 0, 0, 0, 3, 0, 0, 0, 0, 1]
* 0th index frequency is mapped with -2, 1st index with -1, and so on.
* Reconstructed A using F: -2, -2, 3, 3, 3, 8
-#### Pseudocode
+### Pseudocode
```cpp
//Find smallest and largest elements in A
//Create a frequency array F of size (largest - smallest + 1)
-for i -> 0 to(N - 1) {
- F[A[i] - smallest_element]++
+for i -> 0 to (N - 1) {
+ F[A[i] - smallest_element] ++
}
//Reconstruct array A using F
for each index i in F {
- while F[i] > 0 {
- Append(i + smallest_element) to A
- F[i]--
- }
+ while F[i] > 0 {
+ Append (i + smallest_element) to A
+ F[i]--
+ }
}
```
-#### TC and SC
+### TC and SC
* **Time Complexity (TC):** O(N)
* **Space Complexity (SC):** O(N + Range)
---
-### Merge two sorted arrays
+## Gmail's All Inboxes Feature
+
+### Scenerio
+**Google's Gmail** offers an "***All Inboxes***" feature that allows users to view emails from **multiple email accounts** in one seamless interface. This is particularly useful for users managing personal and professional communications through separate accounts.
+
+The feature ensures that emails from all accounts are merged into a single feed sorted by date and time, facilitating better email management and access.
+
+### Problem
+Develop a function to emulate the "**All Inboxes**" feature of **Gmail**.
+- You are given **two sorted arrays** that represent **timestamps** of emails from two different email accounts. Each element in the array is an email object.
+- Your task is to merge these two arrays into a single list, ensuring that the resulting list is sorted by the **timestamp**, allowing the user to view emails in a **chronological order** from both accounts combined.
+
+### Example
+**Input**:
+
+| ACCOUNT| Email Times |
+| -------- | -------- |
+| A | $[1, 5, 6, 9]$ |
+| B | $[2, 4, 8]$|
+
+**OUTPUT** : $[1, 2, 4, 5, 6, 8, 9]$
+
+### Approach :
+- This is a direct application of **Merge two sorted arrays**.
+- Let's have a deep look into the concept now.
+
+---
+## Merge two sorted arrays
+
Giver an integer array where all odd elements are sorted and all even elements are sorted. Sort the entire array.
A[] = {`2, 5, 4, 8, 11, 13, 10, 15, 21`}
-#### Approach
+### Approach
We can take two separate arrays to keep even(EVEN[]) and odd(ODD[]) elements. Then we can merge them in the original array.
We will keep three pointers here: `a(for original array)`, `e(for even array)` and `o(for odd array)`, all starting at index 0.
@@ -133,61 +163,80 @@ If A[a] is odd, ODD[o]=A[a], o++, a++
If A[a] is even, EVEN[e]=A[a], e++, a++
---
-#### Pseudocode
+## Pseudocode
+
```java
-void merge(A[]) {
- int N = A.length();
- //n1: count of even elements
- //n2: count of odd elements
- int EVEN[n1], ODD[n2];
- int a = 0, e = 0, o = 0;
-
- for (int i = 0; i < N; i++) {
- if (A[a] % 2 == 0) {
- EVEN[e] = A[a];
- e++;
- } else {
- ODD[o] = A[a];
- o++;
+function merge( A[]) {
+ N = A.length();
+
+ //n1: count of even elements
+ //n2: count of odd elements
+ n1 = 0, n2 = 0;
+
+ // Count the number of even and odd elements
+ for (i -> 0 to N - 1) {
+ if (A[i] % 2 == 0)
+ n1++;
+ else
+ n2++;
+ }
+
+ EVEN[n1], ODD[n2];
+ a = 0; // moves over A
+ e = 0; // moves over EVEN
+ o = 0; // moves over ODD
+
+ for(i -> 0 to N - 1) {
+ if(A[a] % 2 == 0) {
+ EVEN[e] = A[a];
+ e++;
+ }
+ else {
+ ODD[o] = A[a];
+ o++;
+ }
+ a++;
+ }
+
+ a = 0; // moves over A
+ e = 0; // moves over EVEN
+ o = 0; // moves over ODD
+
+ // perform actual logic of merging of two sorted arrays
+
+ while (e < n1 && o < n2) {
+ if (EVEN[e] < ODD[o]) {
+ A[a] = EVEN[e];
+ e++;
+ } else {
+ A[a] = ODD[o];
+ o++;
+ }
+ a++;
}
- a++;
- }
-
- a = 0; // moves over A
- e = 0; // moves over EVEN
- o = 0; // moves over ODD
-
- while (e < n1 && o < n2) {
- if (EVEN[e] < ODD[o]) {
- A[a] = EVEN[e];
- e++;
- } else {
- A[a] = ODD[o];
- o++;
+
+ while (e < n1) {
+ A[a] = EVEN[e];
+ e++;
+ a++;
+ }
+
+ while (o < n2) {
+ A[a] = ODD[o];
+ a++;
+ o++;
}
- a++;
- }
-
- while (e < n1) {
- A[a] = EVEN[e];
- e++;
- a++;
- }
-
- while (o < n2) {
- A[a] = ODD[o];
- a++;
- o++;
- }
}
```
---
+
+
### Question
Iteration of merging 2 Arrays?
-**Choices**
+### Choices
- [ ] N ^ 3
- [ ] N ^ 2
- [x] 2 * N
@@ -195,7 +244,8 @@ Iteration of merging 2 Arrays?
---
-### Merge Sort
+## Merge Sort
+
### Example: Sorting Examination Sheets
>A teacher collected the examination sheets of students randomly. Now, she needs to sort those sheets as per roll number of students. As she is smart, instead of sorting it by herself, she divided the sheets into two halves and gave each half to Kishore and Suraj for sorting.
@@ -213,16 +263,16 @@ Iteration of merging 2 Arrays?
>In this way, the sheets are finally sorted.
-**Example: Sorting Numbers**
+## Example: Sorting Numbers
Sort the array, A = {3, 10, 6, 8, 15, 2, 12, 18, 17}
-#### Divide
+### Divide
* The idea is to divide the numbers in two halves and then start merging the sorted arrays from bottom and pass above.
-#### Pseudocode
+### Pseudocode
```cpp
-bool check(v[], int x, int c) {
- n = v.size();
- count = 1;
- last = 0;
- for (i = 0; i < n; i++) {
- if (v[i] - v[last] >= x) {
- last = i; //cow placed
- count++;
- }
- if (count >= c) {
- return true;
+function check(v[], x, c)
+{
+ n = v.size();
+ count = 1;
+ last = 0;
+ for (i -> 0 to n - 1) {
+ if (v[i] - v[last] >= x) {
+ last = i; //cow placed
+ count++;
+ }
+ if (count >= c) {
+ return true;
+ }
}
- }
- return false;
+ return false;
}
-
+
// Function to find the maximum possible
// minimum distance between the cows
-aggressive_cows(v[], size, cows) {
- int lo = 0;
- for (i = 1; i < n; i++) {
- lo = min(lo, v[i] - v[i - 1]);
- }
- hi = v[n - 1] - v[0];
- ans = -1;
-
- // Applying Binary search
- while (lo <= hi) {
- mid = lo + (hi - lo) / 2;
- if (check(v, mid, cows)) {
- ans = mid;
- lo = mid + 1;
- } else {
- hi = mid - 1;
+aggressive_cows( v[], size , cows)
+{
+ lo = 0;
+ for (i -> 1 to n - 1)
+ {
+ lo = min(lo,v[i] - v[i - 1]);
}
- }
-
- return ans;
+ hi = v[n - 1] - v[0];
+ ans = -1;
+
+ // Applying Binary search
+ while (lo <= hi) {
+ mid = lo + (hi - lo) / 2;
+ if (check(v, mid, cows)) {
+ ans = mid;
+ lo = mid + 1;
+ }
+ else {
+ hi = mid - 1;
+ }
+ }
+
+ return ans;
}
```
---
-### Binary Search Problems Identification
+## Binary Search Problems Identification
* These type of problems generally has following characteristics :-
* There are two or three parameter & constraints
* Requirement is to maximize or minimize the given parameter
* One tricky point is to find search space which is generally the parameter asked to maximize or minimize.
* The problem should be **Monotonic** in nature i.e after one point it is not feasible to solve or vice versa.
-
diff --git a/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md b/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md
index 3c9b5fa..5b9daa6 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Sorting 1 Count Sort & Merge Sort.md
@@ -1,8 +1,10 @@
-# Count Sort & Merge Sort
+# Sorting 1: Count Sort & Merge Sort
+
----
## Count Sort
+### Problem Statement
+
Find the smallest number that can be formed by rearranging the digits of the given number in an array. Return the smallest number in the form an array.
**Example:**
@@ -12,38 +14,38 @@ Answer: `{1, 2, 2, 3, 4, 6, 7}`
A[ ] = `{4, 2, 7, 3, 9, 0}`
Answer: `{0, 2, 3, 4, 7, 9}`
-#### Observation/Hint
-we can to construct a number using digits. The digits in a number can only `range from 0 to 9`, thus instead of sorting the number which takes `O(N log N)` time, one can leverage this fixed range to derive a faster solution.
+### Observation/Hint
+The digits in a number can only `range from 0 to 9`, thus instead of sorting the number which takes `O(N log N)` time, one can leverage this fixed range to derive a faster solution.
-#### Approach
+### Approach
* **Frequency Count:** Create an `array of size 10` to count the frequency of each digit in the given number.
* Using the frequency array, reconstruct the original array in ascending order.
* This method of sorting based on frequency counting is often called "**`Count Sort`**".
-#### Pseudocode
+### Pseudocode
```cpp
Frequency Array of size 10
F = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-for i -> 0 to(N - 1) {
- F[A[i]]++
+for i -> 0 to (N - 1) {
+ F[A[i]] ++
}
k = 0
-for d -> 0 to 9 { // For each digit
- for i -> 1 to F[d] {
- A[k] = d
- k++
- }
+for d -> 0 to 9 { // For each digit
+ for i -> 1 to F[d] {
+ A[k] = d
+ k++
+ }
}
return A
```
-#### Dry Run
+### Dry Run
* A = `[1, 3, 8, 2, 3, 5, 3, 8, 5, 2, 2, 3]` (Given Array)
* F = `[0, 1, 3, 4, 0, 2, 0, 0, 2, 0]` (Frequency Array)
@@ -51,12 +53,13 @@ return A
1 (once), 2 (three times), 3 (four times), 5 (two times), 8 (two times)
* Resulting A = `[1, 2, 2, 2, 3, 3, 3, 3, 5, 5, 8, 8]`
-#### TC and SC
+### TC and SC
* **Time Complexity:** O(N)
* **Space Complexity:** O(1) (Since the size of the frequency array is constant, regardless of the size of N).
---
-### Count Sort on large values
+## Count Sort on large values
+
### Will Count Sort work if the range of A[i] is more than $10^9$?
@@ -68,63 +71,90 @@ Each integer typically occupies `4 Bytes`.
Storing $10^9$ integers requires 4GB, which is often impractical. An array up to $10^6$ in length is more manageable, needing 4MB.
---
-### Count Sort on Negative Numbers
+## Count Sort on Negative Numbers
+
+
+### Problem Statement
Implement Count Sort for an array containing negative numbers.
-#### Observation/Hint
+### Observation/Hint
Unlike conventional **Count Sort**, which operates on non-negative integers, this variation needs to account for negative numbers. The method involves adjusting indices in the frequency array based on the smallest element in the original array.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach
+### Approach
* **Find Range:** Determine the smallest and largest elements in the array to ascertain the range.
* **Adjust for Negative Numbers:** By adjusting indices in the frequency array based on the smallest element, negative numbers can be accounted for.
-**Example**
+### Example
* Given A = [-2, 3, 8, 3, -2, 3]
* Smallest = -2, Largest = 8
* Range = 11 (8 - (-2) + 1)
-* Frequency array F = [2, 0, 0, 3, 0, 0, 0, 0, 1]
+* Frequency array F = [2, 0, 0, 0, 0, 3, 0, 0, 0, 0, 1]
* 0th index frequency is mapped with -2, 1st index with -1, and so on.
* Reconstructed A using F: -2, -2, 3, 3, 3, 8
-#### Pseudocode
+### Pseudocode
```cpp
//Find smallest and largest elements in A
//Create a frequency array F of size (largest - smallest + 1)
-for i -> 0 to(N - 1) {
- F[A[i] - smallest_element]++
+for i -> 0 to (N - 1) {
+ F[A[i] - smallest_element] ++
}
//Reconstruct array A using F
for each index i in F {
- while F[i] > 0 {
- Append(i + smallest_element) to A
- F[i]--
- }
+ while F[i] > 0 {
+ Append (i + smallest_element) to A
+ F[i]--
+ }
}
```
-#### TC and SC
+### TC and SC
* **Time Complexity (TC):** O(N)
* **Space Complexity (SC):** O(N + Range)
---
-### Merge two sorted arrays
+## Gmail's All Inboxes Feature
+
+### Scenerio
+**Google's Gmail** offers an "***All Inboxes***" feature that allows users to view emails from **multiple email accounts** in one seamless interface. This is particularly useful for users managing personal and professional communications through separate accounts.
+
+The feature ensures that emails from all accounts are merged into a single feed sorted by date and time, facilitating better email management and access.
+
+### Problem
+Develop a function to emulate the "**All Inboxes**" feature of **Gmail**.
+- You are given **two sorted arrays** that represent **timestamps** of emails from two different email accounts. Each element in the array is an email object.
+- Your task is to merge these two arrays into a single list, ensuring that the resulting list is sorted by the **timestamp**, allowing the user to view emails in a **chronological order** from both accounts combined.
+
+### Example
+**Input**:
+
+| ACCOUNT| Email Times |
+| -------- | -------- |
+| A | $[1, 5, 6, 9]$ |
+| B | $[2, 4, 8]$|
+
+**OUTPUT** : $[1, 2, 4, 5, 6, 8, 9]$
+
+### Approach :
+- This is a direct application of **Merge two sorted arrays**.
+- Let's have a deep look into the concept now.
+
+---
+## Merge two sorted arrays
+
Giver an integer array where all odd elements are sorted and all even elements are sorted. Sort the entire array.
A[] = {`2, 5, 4, 8, 11, 13, 10, 15, 21`}
-#### Approach
+### Approach
We can take two separate arrays to keep even(EVEN[]) and odd(ODD[]) elements. Then we can merge them in the original array.
We will keep three pointers here: `a(for original array)`, `e(for even array)` and `o(for odd array)`, all starting at index 0.
@@ -133,61 +163,80 @@ If A[a] is odd, ODD[o]=A[a], o++, a++
If A[a] is even, EVEN[e]=A[a], e++, a++
---
-#### Pseudocode
+## Pseudocode
+
```java
-void merge(A[]) {
- int N = A.length();
- //n1: count of even elements
- //n2: count of odd elements
- int EVEN[n1], ODD[n2];
- int a = 0, e = 0, o = 0;
-
- for (int i = 0; i < N; i++) {
- if (A[a] % 2 == 0) {
- EVEN[e] = A[a];
- e++;
- } else {
- ODD[o] = A[a];
- o++;
+function merge( A[]) {
+ N = A.length();
+
+ //n1: count of even elements
+ //n2: count of odd elements
+ n1 = 0, n2 = 0;
+
+ // Count the number of even and odd elements
+ for (i -> 0 to N - 1) {
+ if (A[i] % 2 == 0)
+ n1++;
+ else
+ n2++;
+ }
+
+ EVEN[n1], ODD[n2];
+ a = 0; // moves over A
+ e = 0; // moves over EVEN
+ o = 0; // moves over ODD
+
+ for(i -> 0 to N - 1) {
+ if(A[a] % 2 == 0) {
+ EVEN[e] = A[a];
+ e++;
+ }
+ else {
+ ODD[o] = A[a];
+ o++;
+ }
+ a++;
+ }
+
+ a = 0; // moves over A
+ e = 0; // moves over EVEN
+ o = 0; // moves over ODD
+
+ // perform actual logic of merging of two sorted arrays
+
+ while (e < n1 && o < n2) {
+ if (EVEN[e] < ODD[o]) {
+ A[a] = EVEN[e];
+ e++;
+ } else {
+ A[a] = ODD[o];
+ o++;
+ }
+ a++;
}
- a++;
- }
-
- a = 0; // moves over A
- e = 0; // moves over EVEN
- o = 0; // moves over ODD
-
- while (e < n1 && o < n2) {
- if (EVEN[e] < ODD[o]) {
- A[a] = EVEN[e];
- e++;
- } else {
- A[a] = ODD[o];
- o++;
+
+ while (e < n1) {
+ A[a] = EVEN[e];
+ e++;
+ a++;
+ }
+
+ while (o < n2) {
+ A[a] = ODD[o];
+ a++;
+ o++;
}
- a++;
- }
-
- while (e < n1) {
- A[a] = EVEN[e];
- e++;
- a++;
- }
-
- while (o < n2) {
- A[a] = ODD[o];
- a++;
- o++;
- }
}
```
---
+
+
### Question
Iteration of merging 2 Arrays?
-**Choices**
+### Choices
- [ ] N ^ 3
- [ ] N ^ 2
- [x] 2 * N
@@ -195,7 +244,8 @@ Iteration of merging 2 Arrays?
---
-### Merge Sort
+## Merge Sort
+
### Example: Sorting Examination Sheets
>A teacher collected the examination sheets of students randomly. Now, she needs to sort those sheets as per roll number of students. As she is smart, instead of sorting it by herself, she divided the sheets into two halves and gave each half to Kishore and Suraj for sorting.
@@ -213,16 +263,16 @@ Iteration of merging 2 Arrays?
>In this way, the sheets are finally sorted.
-**Example: Sorting Numbers**
+## Example: Sorting Numbers
Sort the array, A = {3, 10, 6, 8, 15, 2, 12, 18, 17}
-#### Divide
+### Divide
* The idea is to divide the numbers in two halves and then start merging the sorted arrays from bottom and pass above.
 -#### Merge
+### Merge
- Merging [3] and [10] as [3, 10]
-#### Merge
+### Merge
- Merging [3] and [10] as [3, 10]
 @@ -254,66 +304,66 @@ In this way, we have finally sorted the array.
*Since we are breaking down the array into multiple subproblems and applying the same idea to merge them, we are using the technique of Recursion.*
-#### Psuedocode
+## Psuedocode
```java
-void merge(A[], l, mid, r) {
- int N = A.length();
- int n1 = mid - l + 1;
- int n2 = r - mid;
-
- int B[n1], C[n2];
-
- int idx = 0;
- for (int i = l; i <= mid; i++) {
- B[idx] = A[i];
- idx++;
- }
-
- idx = 0;
- for (int i = mid + 1; i <= r; i++) {
- C[idx] = A[i];
- idx++;
- }
-
- idx = l;
- i = 0; // moves over A
- j = 0; // moves over B
-
- while (i < n1 && j < n2) {
- if (B[i] <= C[j]) {
- A[idx] = B[i];
- i++;
- } else {
- A[idx] = C[j];
- j++;
+function merge(A[], l, mid, r) {
+ N = A.length();
+ n1 = mid-l+1;
+ n2 = r-mid;
+
+ B[n1], C[n2];
+
+ idx=0;
+ for(i -> l to mid){
+ B[idx] = A[i];
+ idx++;
+ }
+
+ idx=0;
+ for(i -> mid+1 to r){
+ C[idx] = A[i];
+ idx++;
+ }
+
+ idx = l;
+ i = 0; // moves over A
+ j = 0; // moves over B
+
+ while (i < n1 && j < n2) {
+ if (B[i] <= C[j]) {
+ A[idx] = B[i];
+ i++;
+ } else {
+ A[idx] = C[j];
+ j++;
+ }
+ idx++;
+ }
+
+ while (i < n1) {
+ A[idx] = B[i];
+ idx++;
+ i++;
+ }
+
+ while (j < n2) {
+ A[idx] = C[j];
+ idx++;
+ j++;
}
- idx++;
- }
-
- while (i < n1) {
- A[idx] = B[i];
- idx++;
- i++;
- }
-
- while (j < n2) {
- A[idx] = C[j];
- idx++;
- j++;
- }
}
-void mergeSort(int A[], l, r) {
- if (l == r) return; // base case
-
- int mid = (l + r) / 2;
- mergeSort(A, l, mid);
- mergeSort(A, mid + 1, r);
- merge(A, l, mid, r);
+function mergeSort(A[], l, r){
+ if(l == r) return; // base case
+
+ mid = (l + r) / 2;
+ mergeSort (A, l, mid);
+ mergeSort (A, mid + 1, r);
+ merge(A, l, mid, r);
}
```
-#### Complexity Analysis:
+### Complexity Analysis:
If we divide the arrays in two halves, we will have a tree structure as:
@@ -254,66 +304,66 @@ In this way, we have finally sorted the array.
*Since we are breaking down the array into multiple subproblems and applying the same idea to merge them, we are using the technique of Recursion.*
-#### Psuedocode
+## Psuedocode
```java
-void merge(A[], l, mid, r) {
- int N = A.length();
- int n1 = mid - l + 1;
- int n2 = r - mid;
-
- int B[n1], C[n2];
-
- int idx = 0;
- for (int i = l; i <= mid; i++) {
- B[idx] = A[i];
- idx++;
- }
-
- idx = 0;
- for (int i = mid + 1; i <= r; i++) {
- C[idx] = A[i];
- idx++;
- }
-
- idx = l;
- i = 0; // moves over A
- j = 0; // moves over B
-
- while (i < n1 && j < n2) {
- if (B[i] <= C[j]) {
- A[idx] = B[i];
- i++;
- } else {
- A[idx] = C[j];
- j++;
+function merge(A[], l, mid, r) {
+ N = A.length();
+ n1 = mid-l+1;
+ n2 = r-mid;
+
+ B[n1], C[n2];
+
+ idx=0;
+ for(i -> l to mid){
+ B[idx] = A[i];
+ idx++;
+ }
+
+ idx=0;
+ for(i -> mid+1 to r){
+ C[idx] = A[i];
+ idx++;
+ }
+
+ idx = l;
+ i = 0; // moves over A
+ j = 0; // moves over B
+
+ while (i < n1 && j < n2) {
+ if (B[i] <= C[j]) {
+ A[idx] = B[i];
+ i++;
+ } else {
+ A[idx] = C[j];
+ j++;
+ }
+ idx++;
+ }
+
+ while (i < n1) {
+ A[idx] = B[i];
+ idx++;
+ i++;
+ }
+
+ while (j < n2) {
+ A[idx] = C[j];
+ idx++;
+ j++;
}
- idx++;
- }
-
- while (i < n1) {
- A[idx] = B[i];
- idx++;
- i++;
- }
-
- while (j < n2) {
- A[idx] = C[j];
- idx++;
- j++;
- }
}
-void mergeSort(int A[], l, r) {
- if (l == r) return; // base case
-
- int mid = (l + r) / 2;
- mergeSort(A, l, mid);
- mergeSort(A, mid + 1, r);
- merge(A, l, mid, r);
+function mergeSort(A[], l, r){
+ if(l == r) return; // base case
+
+ mid = (l + r) / 2;
+ mergeSort (A, l, mid);
+ mergeSort (A, mid + 1, r);
+ merge(A, l, mid, r);
}
```
-#### Complexity Analysis:
+### Complexity Analysis:
If we divide the arrays in two halves, we will have a tree structure as:
 @@ -321,197 +371,23 @@ If we divide the arrays in two halves, we will have a tree structure as:
The time taken at every level is the time taken by merging the arrays which will be O(N).
Height of Tree / Number of Levels - O(log N)
+At each level, work done is O(N)
-Thus,
-***Time Complexity:* O(N * log(N))**
-
+**Hence, Time Complexity:** O(N * log(N))
**Space Complexity:** O(N)
-
-For recursive stack, we require O(logN) space. And at every level, we are using O(N) space for merging but since we are freeing that as well. We are utilizing O(N) in total merging.
-Thus, space complexity is O(logN) + O(N) = O(N)
+For recursive stack, we require O(logN) space. And at every level, we are using O(N) space for merging but since we are freeing that as well. We are utilizing O(N) in total merging. Thus, space complexity is O(N)
> Merge sort is stable as arrangement of elements is taking place at merge step which is essentially maintaining the relative order of elements.
----
-### Calculate no of pairs such that A[i] > B[j]
-Given two array, A[n] and B[m]; Calculate number of pairs i,j such that A[i] > B[j].
-
-**Example**
-A[3] = `{7, 3, 5}`
-B[3] = `{2, 0, 6}`
-
-**Explanation**
-`(7,2) (7,0) (7,6) (3,2) (3,0) (5,2) (5,0)` (7 pairs)
-
-:::warning
-Please take some time to think about the bruteforce approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
-Take 2 loops and compare the values
-#### TC & SC
-* Time complexity is O(n * m)
-* Space complexity is O(1)
-#### Appoach 2 with Dry Run
+## Stable Sort
-1. Sort both the arrays
-2. Create one array, C[6] for merging both the arrays
-3. Assign pointer P1, P2, P3 to A[0], B[0], C[0] respectively
-4. A[3] = {3, 5, 7} `<-- P1`
-5. B[3] = {0, 2, 6} `<-- P2`
-6. `B[0] < A[0]` means 0 is smaller than every element in A from index 0 onwards; **`count of pairs = 3 (3,0)(5,0)(7,0)`**; C[] ={0}; `P2=1`
-7. `B[1] < A[0]` means 2 is smaller than every element in A from index 0 onwards; **`count of pairs = 6 (3,0)(5,0)(7,0)(3,2)(5,2)(7,2)`**; C[] ={0, 2}; `P2=2`
-8. `B[2] > A[0]` means 6 can't form a pair with 3. We are done with 3, because if 6 can't make a pair, no other element after 6 can make a pair with 3; C[]={0, 2, 3}; `P1=1`
-9. `B[2] > A[1]` means 6 can't form a pair with 5. We are done with 5, because if 6 can't make a pair, no other element after 6 can make a pair with 5; C[]={0, 2, 3, 5}; `P1=2`
-10. `B[2] < A[2]` means 6 is smaller than every element in A from index 2 onwards; **`count of pairs = 7(3,0)(5,0)(7,0)(3,2)(5,2)(7,2)(7,6)`**; C[] ={0, 2, 3, 5, 6}; `P2=3`
-11. B is empty, we can push all elements remaining in A to C; C[] ={0, 2, 3, 5, 6, 7};
-
-
-#### Time Complexity
-O(nlogn + mlogm + m + n)
-
-Here nlogn is the time complexity of sorting A array, mlogm is the time complexity for B array and m+n is the time complexity for merging both the arrays
-
----
-### Inversion Count
-
-Given an a[n], calculate no of pairs [i,j] such that i
@@ -321,197 +371,23 @@ If we divide the arrays in two halves, we will have a tree structure as:
The time taken at every level is the time taken by merging the arrays which will be O(N).
Height of Tree / Number of Levels - O(log N)
+At each level, work done is O(N)
-Thus,
-***Time Complexity:* O(N * log(N))**
-
+**Hence, Time Complexity:** O(N * log(N))
**Space Complexity:** O(N)
-
-For recursive stack, we require O(logN) space. And at every level, we are using O(N) space for merging but since we are freeing that as well. We are utilizing O(N) in total merging.
-Thus, space complexity is O(logN) + O(N) = O(N)
+For recursive stack, we require O(logN) space. And at every level, we are using O(N) space for merging but since we are freeing that as well. We are utilizing O(N) in total merging. Thus, space complexity is O(N)
> Merge sort is stable as arrangement of elements is taking place at merge step which is essentially maintaining the relative order of elements.
----
-### Calculate no of pairs such that A[i] > B[j]
-Given two array, A[n] and B[m]; Calculate number of pairs i,j such that A[i] > B[j].
-
-**Example**
-A[3] = `{7, 3, 5}`
-B[3] = `{2, 0, 6}`
-
-**Explanation**
-`(7,2) (7,0) (7,6) (3,2) (3,0) (5,2) (5,0)` (7 pairs)
-
-:::warning
-Please take some time to think about the bruteforce approach on your own before reading further.....
-:::
-
-#### Brute Force Approach
-Take 2 loops and compare the values
-#### TC & SC
-* Time complexity is O(n * m)
-* Space complexity is O(1)
-#### Appoach 2 with Dry Run
+## Stable Sort
-1. Sort both the arrays
-2. Create one array, C[6] for merging both the arrays
-3. Assign pointer P1, P2, P3 to A[0], B[0], C[0] respectively
-4. A[3] = {3, 5, 7} `<-- P1`
-5. B[3] = {0, 2, 6} `<-- P2`
-6. `B[0] < A[0]` means 0 is smaller than every element in A from index 0 onwards; **`count of pairs = 3 (3,0)(5,0)(7,0)`**; C[] ={0}; `P2=1`
-7. `B[1] < A[0]` means 2 is smaller than every element in A from index 0 onwards; **`count of pairs = 6 (3,0)(5,0)(7,0)(3,2)(5,2)(7,2)`**; C[] ={0, 2}; `P2=2`
-8. `B[2] > A[0]` means 6 can't form a pair with 3. We are done with 3, because if 6 can't make a pair, no other element after 6 can make a pair with 3; C[]={0, 2, 3}; `P1=1`
-9. `B[2] > A[1]` means 6 can't form a pair with 5. We are done with 5, because if 6 can't make a pair, no other element after 6 can make a pair with 5; C[]={0, 2, 3, 5}; `P1=2`
-10. `B[2] < A[2]` means 6 is smaller than every element in A from index 2 onwards; **`count of pairs = 7(3,0)(5,0)(7,0)(3,2)(5,2)(7,2)(7,6)`**; C[] ={0, 2, 3, 5, 6}; `P2=3`
-11. B is empty, we can push all elements remaining in A to C; C[] ={0, 2, 3, 5, 6, 7};
-
-
-#### Time Complexity
-O(nlogn + mlogm + m + n)
-
-Here nlogn is the time complexity of sorting A array, mlogm is the time complexity for B array and m+n is the time complexity for merging both the arrays
-
----
-### Inversion Count
-
-Given an a[n], calculate no of pairs [i,j] such that i -#### Pseudocode
+### Pseudocode
```cpp
partition(A,first,last):
pivotvalue = A[first]
@@ -130,46 +139,47 @@ Now that there are two separate subarrays, we can apply partitioning on both sep
2. **Divide**: Split the problem set, move smaller parts to the left of the pivot and larger items to the right.
3. **Repeat and combine**: Repeat the steps on smaller subarrays and combine the arrays that have previously been sorted.
-#### Dry Run
+### Dry Run
-#### Pseudocode
+### Pseudocode
```cpp
partition(A,first,last):
pivotvalue = A[first]
@@ -130,46 +139,47 @@ Now that there are two separate subarrays, we can apply partitioning on both sep
2. **Divide**: Split the problem set, move smaller parts to the left of the pivot and larger items to the right.
3. **Repeat and combine**: Repeat the steps on smaller subarrays and combine the arrays that have previously been sorted.
-#### Dry Run
+### Dry Run
 -#### Pseudocode
+### Pseudocode
Below is the code for QuickSort
```java
-void quicksort(int[] A, int start, int end) {
- if (start < end) {
- int pivotIndex = partition(A, start, end);
- quicksort(A, start, pivotIndex - 1);
- quicksort(A, pivotIndex + 1, end);
- }
+function quicksort( A[], start, int end) {
+ if (start < end) {
+ pivotIndex = partition(A, start, end);
+ quicksort(A, start, pivotIndex - 1);
+ quicksort(A, pivotIndex + 1, end);
+ }
}
```
---
-### Quick Sort Time Complexity and Space Complexity
+## Quick Sort Time Complexity and Space Complexity
+
-#### Best-Case Time Complexity:
+### Best-Case Time Complexity:
The best-case scenario for QuickSort occurs when the pivot chosen at each step divides the input into approximately equal-sized subarrays.
>
-#### Pseudocode
+### Pseudocode
Below is the code for QuickSort
```java
-void quicksort(int[] A, int start, int end) {
- if (start < end) {
- int pivotIndex = partition(A, start, end);
- quicksort(A, start, pivotIndex - 1);
- quicksort(A, pivotIndex + 1, end);
- }
+function quicksort( A[], start, int end) {
+ if (start < end) {
+ pivotIndex = partition(A, start, end);
+ quicksort(A, start, pivotIndex - 1);
+ quicksort(A, pivotIndex + 1, end);
+ }
}
```
---
-### Quick Sort Time Complexity and Space Complexity
+## Quick Sort Time Complexity and Space Complexity
+
-#### Best-Case Time Complexity:
+### Best-Case Time Complexity:
The best-case scenario for QuickSort occurs when the pivot chosen at each step divides the input into approximately equal-sized subarrays.
>  -#### Worst-Case Time Complexity:
+### Worst-Case Time Complexity:
The worst-case scenario for QuickSort occurs when the pivot chosen at each step is either the smallest or largest element in the remaining unsorted portion of the array. This leads to imbalanced partitions, and the algorithm performs poorly. The worst-case time complexity is $O(N^2)$, which occurs when the input is already sorted in ascending or descending order.
>
-#### Worst-Case Time Complexity:
+### Worst-Case Time Complexity:
The worst-case scenario for QuickSort occurs when the pivot chosen at each step is either the smallest or largest element in the remaining unsorted portion of the array. This leads to imbalanced partitions, and the algorithm performs poorly. The worst-case time complexity is $O(N^2)$, which occurs when the input is already sorted in ascending or descending order.
>  -#### Average-Case Time Complexity
+### Average-Case Time Complexity
There are many ways to avoid the worst case of quicksort, like choosing the element from the middle of the array as pivot, randomly generating a pivot for each subarray, selecting the median of the first, last, and middle element as pivot, etc. By using these methods, we can ensure equal partitioning, on average. Thus, quick sort's average case time complexity is O(NlogN)
-#### Space Complexity
+### Space Complexity
The Space Complexity in quick sort will be because of recursion space. Partition function doesn't take any extra space.
So, space in Quick Sort is only because of Recursion Stack whereas in Merge Sort, the extra space is also taken by Merge Fucntion.
@@ -180,13 +190,13 @@ In worst case, Space is **O(N)** since in recursive tree we have N levels.
In best case, Space is **O(log N)** since there are log N levels.
---
-### Randomised QuickSort
+## Randomised QuickSort
The randomised quicksort is a technique where we randomly pick the pivot element, not necessarily the first and last.
There is a random function available in all the languages, to which we can pass Array and get random index. Now, we can swap random index element with first element and execute our algorithm as it is.
-#### Why picking random element helps?
+### Why picking random element helps?
Randomised quicksort help us to get away with the worst case time complexity.
@@ -206,9 +216,10 @@ This value is very small!!
Hence, using randomised quick sort, we can achieve average case of O(N logN) most of the time.
---
-## Comparator
+### Comparator
+
* In programming, a **comparator** is a function that compares two values and returns a result indicating whether the values are equal, less than, or greater than each other.
* The **comparator** is typically used in sorting algorithms to compare elements in a data structure and arrange them in a specified order.
@@ -229,12 +240,13 @@ For **C++**, following logic is followed.
```
---
-### Problem 2 Sorting based on factors
+## Problem 2 Sorting based on factors
+### Problem Statement
Given an array of size n, sort the data in ascending order of count of factors, if count of factors are equal then sort the elements on the basis of their magnitude.
-**Example 1**
+### Example 1
```plaintext
A[ ] = { 9, 3, 10, 6, 4 }
@@ -245,188 +257,130 @@ Ans = { 3, 4, 9, 6, 10 }
Total number of factors of 3, 4, 9, 6, 10 are 2, 3, 3, 4, 4.
---
+
+
### Question
Given an array A of size n, sort the data in ascending order of count of factors, if count of factors are equal then sort the elements on the basis of their magnitude.
`A = [10, 4, 5, 13, 1]`
-**Choices**
+### Choices
- [ ] [1, 4, 5, 10, 13]
- [x] [1, 5, 13, 4, 10]
- [ ] [13, 10, 4, 5, 1]
- [ ] [1, 4, 5, 13, 10]
-**Explanation:**
+
+---
+
+### Explanation:
Total number of factors of 1, 5, 13, 4, 10 are 1, 2, 2, 3, 4.
---
+## Sorting based on factors Solutions
-### Sorting based on factors Solutions
-
-#### C++
+### C++
```cpp
-int factors(int n) {
- int count = 0;
- int sq = sqrt(n);
-
- // if the number is a perfect square
- if (sq * sq == n)
- count++;
-
- // count all other factors
- for (int i = 1; i < sqrt(n); i++) {
- // if i is a factor then n/i will be
- // another factor. So increment by 2
- if (n % i == 0)
- count += 2;
- }
- return count;
+int factors(int n)
+{
+ int count = 0;
+ int sq = sqrt(n);
+
+ // if the number is a perfect square
+ if (sq * sq == n)
+ count++;
+
+ // count all other factors
+ for (int i=1; i
-#### Average-Case Time Complexity
+### Average-Case Time Complexity
There are many ways to avoid the worst case of quicksort, like choosing the element from the middle of the array as pivot, randomly generating a pivot for each subarray, selecting the median of the first, last, and middle element as pivot, etc. By using these methods, we can ensure equal partitioning, on average. Thus, quick sort's average case time complexity is O(NlogN)
-#### Space Complexity
+### Space Complexity
The Space Complexity in quick sort will be because of recursion space. Partition function doesn't take any extra space.
So, space in Quick Sort is only because of Recursion Stack whereas in Merge Sort, the extra space is also taken by Merge Fucntion.
@@ -180,13 +190,13 @@ In worst case, Space is **O(N)** since in recursive tree we have N levels.
In best case, Space is **O(log N)** since there are log N levels.
---
-### Randomised QuickSort
+## Randomised QuickSort
The randomised quicksort is a technique where we randomly pick the pivot element, not necessarily the first and last.
There is a random function available in all the languages, to which we can pass Array and get random index. Now, we can swap random index element with first element and execute our algorithm as it is.
-#### Why picking random element helps?
+### Why picking random element helps?
Randomised quicksort help us to get away with the worst case time complexity.
@@ -206,9 +216,10 @@ This value is very small!!
Hence, using randomised quick sort, we can achieve average case of O(N logN) most of the time.
---
-## Comparator
+### Comparator
+
* In programming, a **comparator** is a function that compares two values and returns a result indicating whether the values are equal, less than, or greater than each other.
* The **comparator** is typically used in sorting algorithms to compare elements in a data structure and arrange them in a specified order.
@@ -229,12 +240,13 @@ For **C++**, following logic is followed.
```
---
-### Problem 2 Sorting based on factors
+## Problem 2 Sorting based on factors
+### Problem Statement
Given an array of size n, sort the data in ascending order of count of factors, if count of factors are equal then sort the elements on the basis of their magnitude.
-**Example 1**
+### Example 1
```plaintext
A[ ] = { 9, 3, 10, 6, 4 }
@@ -245,188 +257,130 @@ Ans = { 3, 4, 9, 6, 10 }
Total number of factors of 3, 4, 9, 6, 10 are 2, 3, 3, 4, 4.
---
+
+
### Question
Given an array A of size n, sort the data in ascending order of count of factors, if count of factors are equal then sort the elements on the basis of their magnitude.
`A = [10, 4, 5, 13, 1]`
-**Choices**
+### Choices
- [ ] [1, 4, 5, 10, 13]
- [x] [1, 5, 13, 4, 10]
- [ ] [13, 10, 4, 5, 1]
- [ ] [1, 4, 5, 13, 10]
-**Explanation:**
+
+---
+
+### Explanation:
Total number of factors of 1, 5, 13, 4, 10 are 1, 2, 2, 3, 4.
---
+## Sorting based on factors Solutions
-### Sorting based on factors Solutions
-
-#### C++
+### C++
```cpp
-int factors(int n) {
- int count = 0;
- int sq = sqrt(n);
-
- // if the number is a perfect square
- if (sq * sq == n)
- count++;
-
- // count all other factors
- for (int i = 1; i < sqrt(n); i++) {
- // if i is a factor then n/i will be
- // another factor. So increment by 2
- if (n % i == 0)
- count += 2;
- }
- return count;
+int factors(int n)
+{
+ int count = 0;
+ int sq = sqrt(n);
+
+ // if the number is a perfect square
+ if (sq * sq == n)
+ count++;
+
+ // count all other factors
+ for (int i=1; i -
->**Input:** points = [[1,3],[-2,2]], B = 1
-**Output:** [[-2,2]]
-**Explanation:**
-The distance between (1, 3) and the origin is sqrt(10).
-The distance between (-2, 2) and the origin is sqrt(8).
-Since sqrt(8) < sqrt(10), (-2, 2) is closer to the origin.
-We only want the closest B = 1 points from the origin, so the answer is just [[-2,2]].
-
-
-**Example 2:**
-
->**Input:** points = [[3,3],[5,-1],[-2,4]], B = 2
-**Output:** [[3,3],[-2,4]]
-**Explanation:** The answer [[-2,4],[3,3]] would also be accepted.
-
----
-**B Closest Points to Origin Approach**
-
-
-We find the B-th distance by creating an array of distances and then sorting them using custom sorting based on distances from origin or points.
-
-After, we select all the points with distance less than or equal to this K-th distance.
-
-**Logic for Custom Sorting**
-
-Say there are two points, (x1, y1) and (x2, y2),
-The distance of (x1, y1) from origin will be ${sqrt((x1-0)^2 + (y1-0)^2)}$
-The distance of (x2, y2) from origin will be ${sqrt((x2-0)^2 + (y2-0)^2)}$
-
-We can leave root part and just compare $(x1^2 + y1^2) and (x2^2 + y2^2)$
-
-**Below logic works for languages like - Java, Python, JS, ...**
-```cpp
-// Need to arrange in ascending order based on distance
-
-// If first argument needs to be placed before, negative gets returned
-if((x1*x1 + y1*y1) < (x2*x2 + y2*y2))
- return -1;
-// If second argument needs to be placed before, positive gets returned
-else if ((x1*x1 + y1*y1) > (x2*x2 + y2*y2))
- return 1;
-// If both are same, 0 is returned
-else return 0
----------------------------------------------
-// Instead of writing like above, we could have also written
-
-return ((x1*x1 + y1*y1) - (x2*x2 + y2*y2))
-```
-
-#### Below logic works for C++
-```cpp
-// If first argument needs to be placed before, true gets returned
-if ((x1 * x1 + y1 * y1) < (x2 * x2 + y2 * y2))
- return true;
-//Else false is returned
-else return false
-```
-
----
-### Problem 4 Largest Number
+## Problem 3 Largest Number
Given a list of non-negative integers nums, arrange them such that they form the largest number and return it.
@@ -442,7 +396,7 @@ Example 2:
>Input: nums = [3,30,34,5,9]
Output: "9534330"
-#### Idea:
+### Idea:
Should we sort the numbers in descending order and append them ?
@@ -452,30 +406,28 @@ but this doesn't work.
**For example,** sorting the problem example in descending order would produce the number **9534303**, while the correct answer is achieved by putting **3** before **30**.
---
+
+
### Question
Given a list of non-negative integers **nums**, arrange them such that they form the largest number and return it.
nums = [10, 5, 2, 8, 200]
-**Choices**
+### Choices
- [ ] 20010825
- [x] 85220010
- [ ] 88888888
- [ ] 85200210
-**Explanation:**
+### Explanation:
After rearrangeing the nums, [8, 5, 2, 200, 10] will form the largest number as **"85220010"**.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
---
-### Larget Number Approach
+## Largest Number Approach
We shall use **custom sorting**.
Say we pick two numbers **X** and **Y**. Now, we can check if **`X (appends) Y`** > **`Y (appends) X`**, then it means that **Y** should come before **X**.
@@ -484,17 +436,17 @@ For example, let X and Y be 542 and 60. To compare X and Y, we compare 54260 and
Once the array is sorted, the most "signficant" number will be at the front.
-**Edge Case**
+### Edge Case
There is a minor edge case that comes up when the array consists of only
zeroes, so if the most significant number is 0, we can simply return 0. Otherwise, we build a string out of the sorted array and return it.
-**Example**
+### Example
Upon sorting this array - **`[3,30,34,5,9]`**,
we shall get - **`[9, 5, 34, 3, 30]`**
Now, we can simply append the numbers to get - **`9534330`**
-#### Complexity
+### Complexity
**Time complexity :** O(n log n)
Although we are doing extra work in our comparator, it is only by a constant factor. Therefore, the overall runtime is dominated by the complexity of sort, which is O(n log n).
@@ -502,47 +454,49 @@ Although we are doing extra work in our comparator, it is only by a constant fac
Space depends on the type of algorithm used by the sort function internally.
---
-### Larget Number Codes in different langauges
-#### C++
+## Larget Number Codes in different langauges
+
+
+### C++
```cpp
bool compare(int a, int b) {
- return to_string(a) + to_string(b) > to_string(b) + to_string(a);
+ return to_string(a) + to_string(b) > to_string(b) + to_string(a);
}
-string largestNumber(vector < int > & A) {
- sort(A.begin(), A.end(), compare);
- string ans = "";
- for (auto & x: A)
- ans += to_string(x);
- if (ans[0] == '0') return "0";
- return ans;
+string largestNumber(vector
-
->**Input:** points = [[1,3],[-2,2]], B = 1
-**Output:** [[-2,2]]
-**Explanation:**
-The distance between (1, 3) and the origin is sqrt(10).
-The distance between (-2, 2) and the origin is sqrt(8).
-Since sqrt(8) < sqrt(10), (-2, 2) is closer to the origin.
-We only want the closest B = 1 points from the origin, so the answer is just [[-2,2]].
-
-
-**Example 2:**
-
->**Input:** points = [[3,3],[5,-1],[-2,4]], B = 2
-**Output:** [[3,3],[-2,4]]
-**Explanation:** The answer [[-2,4],[3,3]] would also be accepted.
-
----
-**B Closest Points to Origin Approach**
-
-
-We find the B-th distance by creating an array of distances and then sorting them using custom sorting based on distances from origin or points.
-
-After, we select all the points with distance less than or equal to this K-th distance.
-
-**Logic for Custom Sorting**
-
-Say there are two points, (x1, y1) and (x2, y2),
-The distance of (x1, y1) from origin will be ${sqrt((x1-0)^2 + (y1-0)^2)}$
-The distance of (x2, y2) from origin will be ${sqrt((x2-0)^2 + (y2-0)^2)}$
-
-We can leave root part and just compare $(x1^2 + y1^2) and (x2^2 + y2^2)$
-
-**Below logic works for languages like - Java, Python, JS, ...**
-```cpp
-// Need to arrange in ascending order based on distance
-
-// If first argument needs to be placed before, negative gets returned
-if((x1*x1 + y1*y1) < (x2*x2 + y2*y2))
- return -1;
-// If second argument needs to be placed before, positive gets returned
-else if ((x1*x1 + y1*y1) > (x2*x2 + y2*y2))
- return 1;
-// If both are same, 0 is returned
-else return 0
----------------------------------------------
-// Instead of writing like above, we could have also written
-
-return ((x1*x1 + y1*y1) - (x2*x2 + y2*y2))
-```
-
-#### Below logic works for C++
-```cpp
-// If first argument needs to be placed before, true gets returned
-if ((x1 * x1 + y1 * y1) < (x2 * x2 + y2 * y2))
- return true;
-//Else false is returned
-else return false
-```
-
----
-### Problem 4 Largest Number
+## Problem 3 Largest Number
Given a list of non-negative integers nums, arrange them such that they form the largest number and return it.
@@ -442,7 +396,7 @@ Example 2:
>Input: nums = [3,30,34,5,9]
Output: "9534330"
-#### Idea:
+### Idea:
Should we sort the numbers in descending order and append them ?
@@ -452,30 +406,28 @@ but this doesn't work.
**For example,** sorting the problem example in descending order would produce the number **9534303**, while the correct answer is achieved by putting **3** before **30**.
---
+
+
### Question
Given a list of non-negative integers **nums**, arrange them such that they form the largest number and return it.
nums = [10, 5, 2, 8, 200]
-**Choices**
+### Choices
- [ ] 20010825
- [x] 85220010
- [ ] 88888888
- [ ] 85200210
-**Explanation:**
+### Explanation:
After rearrangeing the nums, [8, 5, 2, 200, 10] will form the largest number as **"85220010"**.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
---
-### Larget Number Approach
+## Largest Number Approach
We shall use **custom sorting**.
Say we pick two numbers **X** and **Y**. Now, we can check if **`X (appends) Y`** > **`Y (appends) X`**, then it means that **Y** should come before **X**.
@@ -484,17 +436,17 @@ For example, let X and Y be 542 and 60. To compare X and Y, we compare 54260 and
Once the array is sorted, the most "signficant" number will be at the front.
-**Edge Case**
+### Edge Case
There is a minor edge case that comes up when the array consists of only
zeroes, so if the most significant number is 0, we can simply return 0. Otherwise, we build a string out of the sorted array and return it.
-**Example**
+### Example
Upon sorting this array - **`[3,30,34,5,9]`**,
we shall get - **`[9, 5, 34, 3, 30]`**
Now, we can simply append the numbers to get - **`9534330`**
-#### Complexity
+### Complexity
**Time complexity :** O(n log n)
Although we are doing extra work in our comparator, it is only by a constant factor. Therefore, the overall runtime is dominated by the complexity of sort, which is O(n log n).
@@ -502,47 +454,49 @@ Although we are doing extra work in our comparator, it is only by a constant fac
Space depends on the type of algorithm used by the sort function internally.
---
-### Larget Number Codes in different langauges
-#### C++
+## Larget Number Codes in different langauges
+
+
+### C++
```cpp
bool compare(int a, int b) {
- return to_string(a) + to_string(b) > to_string(b) + to_string(a);
+ return to_string(a) + to_string(b) > to_string(b) + to_string(a);
}
-string largestNumber(vector < int > & A) {
- sort(A.begin(), A.end(), compare);
- string ans = "";
- for (auto & x: A)
- ans += to_string(x);
- if (ans[0] == '0') return "0";
- return ans;
+string largestNumber(vectorImagine a scenario where you have a pile of plates, you can only put a plate on the pile from top also only pick a plate from top. You can't really see the plates underneath the top one without first removing the top plate, which means only the first plate is accessible to you. @@ -23,42 +42,26 @@ Before proceeding to more technical examples, let's start from the real life bas 2. **Undo / Redo Operations**:
In software programs, stacks are commonly used to store the state during Undo and Redo operations. Consider the given example we have performed several calculations here, our first stack stores the current state. As soon as user performs UNDO operation the state is moved to REDO stack so that later it can be restored from there.
 -
-
---
-### Question
-What is the most common application of a stack?
-
-**Choices**
-- [ ] Evaluating arithmetic expressions
-- [ ] Implementing undo/redo functionality
-- [ ] Representing parenthesis in expressions
-- [x] All of the above
-
-
-Answer: All of the above
-
-Explanation: Stacks are versatile data structures that find applications in various domains. They are commonly used in expression evaluation, undo/redo functionality, and representing parenthesis in expressions.
+## Operations on Stack
----
### Operations on Stack
-
These operations are generally used on the stack. The time complexity for all of these operations is constant **O(1)**.
-#### 1. Push
+### 1. Push
Push operation is to insert a new element into the top of stack.
```cpp
push(data)
```
-#### 2. Pop
+### 2. Pop
Pop operation is to remove an element from the top of stack.
```cpp
pop()
```
-#### 3. Peek
+### 3. Peek
Peek means to access the top element of the stack, this operation is also called as **top**.
```cpp
data = peek()
@@ -66,28 +69,33 @@ data = peek()
data = top()
```
-#### 4. isEmpty
+### 4. isEmpty
This operation is used to check whether stack is empty or not. It is an important operation because it allows program to run efficiently by checking conditions of overflow and underflow.
```cpp
isEmpty()
```
+---
+
+
### Question
What is the time complexity of the push and pop operations in a stack?
-**Choices**
+### Choices
- [x] O(1) for both push and pop
- [ ] O(n) for push and O(1) for pop
- [ ] O(1) for push and O(n) for pop
- [ ] O(n) for both push and pop
+### Explanation
Answer: O(1) for both push and pop
Explanation: The push and pop operations in a stack operate on the top element, making them constant time operations. This is because the top element is always accessible regardless of the stack's size.
----
+---
+## Problem 1 Implementation of Stack with Arrays
### Implement Stack using Arrays
* Just try to think what a data structure is, a data structure is nothing but a way to store some data in memory along with some rules to insert/access/modify that data.
@@ -99,18 +107,18 @@ Explanation: The push and pop operations in a stack operate on the top element,
-
-
---
-### Question
-What is the most common application of a stack?
-
-**Choices**
-- [ ] Evaluating arithmetic expressions
-- [ ] Implementing undo/redo functionality
-- [ ] Representing parenthesis in expressions
-- [x] All of the above
-
-
-Answer: All of the above
-
-Explanation: Stacks are versatile data structures that find applications in various domains. They are commonly used in expression evaluation, undo/redo functionality, and representing parenthesis in expressions.
+## Operations on Stack
----
### Operations on Stack
-
These operations are generally used on the stack. The time complexity for all of these operations is constant **O(1)**.
-#### 1. Push
+### 1. Push
Push operation is to insert a new element into the top of stack.
```cpp
push(data)
```
-#### 2. Pop
+### 2. Pop
Pop operation is to remove an element from the top of stack.
```cpp
pop()
```
-#### 3. Peek
+### 3. Peek
Peek means to access the top element of the stack, this operation is also called as **top**.
```cpp
data = peek()
@@ -66,28 +69,33 @@ data = peek()
data = top()
```
-#### 4. isEmpty
+### 4. isEmpty
This operation is used to check whether stack is empty or not. It is an important operation because it allows program to run efficiently by checking conditions of overflow and underflow.
```cpp
isEmpty()
```
+---
+
+
### Question
What is the time complexity of the push and pop operations in a stack?
-**Choices**
+### Choices
- [x] O(1) for both push and pop
- [ ] O(n) for push and O(1) for pop
- [ ] O(1) for push and O(n) for pop
- [ ] O(n) for both push and pop
+### Explanation
Answer: O(1) for both push and pop
Explanation: The push and pop operations in a stack operate on the top element, making them constant time operations. This is because the top element is always accessible regardless of the stack's size.
----
+---
+## Problem 1 Implementation of Stack with Arrays
### Implement Stack using Arrays
* Just try to think what a data structure is, a data structure is nothing but a way to store some data in memory along with some rules to insert/access/modify that data.
@@ -99,18 +107,18 @@ Explanation: The push and pop operations in a stack operate on the top element,
 -#### Pseudocode
+### Pseudocode
```cpp
// Consider an array `A`.
-int A[];
+A[];
// Consider a counter to keep track of stack size and currently used index
-int t = -1;
+t = -1;
```
1. For push operation we can keep pushing data from left to right.
```cpp
-void push(data){
+function push(data){
t++;
A[t] = data;
}
@@ -118,32 +126,52 @@ void push(data){
2. And as we are maintaining a counter we can always access the top element in O(1) by just index access of array.
```cpp
-int top(){
+function top(){
return A[t];
}
```
3. To remove element we can simply decrement our counter. Also we can place some value at that index to denote that it is not part of our data.
```cpp
-void pop(){
+function pop(){
t--;
}
```
4. We are maintaining our counter in such a way that it indicates the size of stack. We can simply perform an equality check on counter to know whether stack is empty.
```cpp
-bool isEmpty(){
+function isEmpty(){
return t == -1;
}
```
+---
+
+
+### Question
+What happens when you try to pop an element from an empty Stack?
+
+### Choices
+- [ ] It returns null
+- [ ] It returns the top element
+- [x] It causes an underflow
+- [ ] It causes an overflow
+
+### Explanation
+
+
+Attempting to pop an element from an empty stack will cause an underflow.
---
-### Overflow and Underflow in stack and it's solution
+## Overflow and Underflow in stack and it's solution
+
+
+
+### Concept of Overflow and Underflow
* Overflow occurs when we try to store new data even when there is no empty space in array. For this we have to introduce a overflow condition before push operation.
```cpp
-void push(x){
+function push(x){
// Whenever our counter reaches to the size of the array
// It means stack is already full
if(t >= A.size())
@@ -156,7 +184,7 @@ void push(x){
* Underflow means when we try to perform pop operation or try to access the element of stack but there are none. Again we have to introduce conditions during pop and top operation.
```cpp
-void pop(){
+function pop(){
if(!isEmpty()) return;
t--;
}
@@ -164,7 +192,7 @@ void pop(){
```cpp
-int top(){
+function top(){
if(!isEmpty()) return -1;
return A[t];
}
@@ -173,20 +201,11 @@ int top(){
### Problem with implementation using Arrays
We have to predefine the size of stack to create array. To overcome this problem we can create a dynamic array which can grow or shrink at runtime according to need.
----
-### Question
-What happens when you try to pop an element from an empty Stack?
-
-**Choices**
-- [ ] It returns null
-- [ ] It returns the top element
-- [x] It causes an underflow
-- [ ] It causes an overflow
-Attempting to pop an element from an empty stack will cause an underflow.
+---
+## Problem 2 Implementation of Stack using Linked List
----
### Implement Stack using Linked List
* We can also implement stack using linked list, similar to the array it also has constant `O(1)` time complexity for all operations.
@@ -196,45 +215,46 @@ Attempting to pop an element from an empty stack will cause an underflow.
-#### Pseudocode
+### Pseudocode
```cpp
// Consider an array `A`.
-int A[];
+A[];
// Consider a counter to keep track of stack size and currently used index
-int t = -1;
+t = -1;
```
1. For push operation we can keep pushing data from left to right.
```cpp
-void push(data){
+function push(data){
t++;
A[t] = data;
}
@@ -118,32 +126,52 @@ void push(data){
2. And as we are maintaining a counter we can always access the top element in O(1) by just index access of array.
```cpp
-int top(){
+function top(){
return A[t];
}
```
3. To remove element we can simply decrement our counter. Also we can place some value at that index to denote that it is not part of our data.
```cpp
-void pop(){
+function pop(){
t--;
}
```
4. We are maintaining our counter in such a way that it indicates the size of stack. We can simply perform an equality check on counter to know whether stack is empty.
```cpp
-bool isEmpty(){
+function isEmpty(){
return t == -1;
}
```
+---
+
+
+### Question
+What happens when you try to pop an element from an empty Stack?
+
+### Choices
+- [ ] It returns null
+- [ ] It returns the top element
+- [x] It causes an underflow
+- [ ] It causes an overflow
+
+### Explanation
+
+
+Attempting to pop an element from an empty stack will cause an underflow.
---
-### Overflow and Underflow in stack and it's solution
+## Overflow and Underflow in stack and it's solution
+
+
+
+### Concept of Overflow and Underflow
* Overflow occurs when we try to store new data even when there is no empty space in array. For this we have to introduce a overflow condition before push operation.
```cpp
-void push(x){
+function push(x){
// Whenever our counter reaches to the size of the array
// It means stack is already full
if(t >= A.size())
@@ -156,7 +184,7 @@ void push(x){
* Underflow means when we try to perform pop operation or try to access the element of stack but there are none. Again we have to introduce conditions during pop and top operation.
```cpp
-void pop(){
+function pop(){
if(!isEmpty()) return;
t--;
}
@@ -164,7 +192,7 @@ void pop(){
```cpp
-int top(){
+function top(){
if(!isEmpty()) return -1;
return A[t];
}
@@ -173,20 +201,11 @@ int top(){
### Problem with implementation using Arrays
We have to predefine the size of stack to create array. To overcome this problem we can create a dynamic array which can grow or shrink at runtime according to need.
----
-### Question
-What happens when you try to pop an element from an empty Stack?
-
-**Choices**
-- [ ] It returns null
-- [ ] It returns the top element
-- [x] It causes an underflow
-- [ ] It causes an overflow
-Attempting to pop an element from an empty stack will cause an underflow.
+---
+## Problem 2 Implementation of Stack using Linked List
----
### Implement Stack using Linked List
* We can also implement stack using linked list, similar to the array it also has constant `O(1)` time complexity for all operations.
@@ -196,45 +215,46 @@ Attempting to pop an element from an empty stack will cause an underflow.
 -#### Pseudocode
+### Pseudocode
1. To push data into stack, just create a node and attach before head.
```cpp
-void push(data) {
- new_node = Create a new Node with 'data'
- new_node.next = head
- head = new_node
- // Increment size
- t++
+function push(data){
+ new_node = Create a new Node with 'data'
+ new_node.next = head
+ head = new_node
+ // Increment size
+ t++
}
```
2. To pop data just remove one node from the beginning of linked list.
```cpp
-void pop() {
- if (!isEmpty()) return;
- head = head.next
- // Decrement size
- t--
+function pop(){
+ if( ! isEmpty()) return;
+ head = head.next
+ // Decrement size
+ t--
}
```
3. To find the data on top just access the head node.
```cpp
-int top() {
- if (!isEmpty()) return -1;
- return head.data;
+function top(){
+ if( ! isEmpty()) return -1;
+ return head.data;
}
```
> Note: While accessing top value in function, We can use another concept to indicate that stack is empty if we are using -1 as value to store in stack.
---
-### Problem 3 Balanced Paranthesis Concept with Implementation
+## Problem 3 Balanced Paranthesis Concept with Implementation
-Check whether the given sequence of parenthesis is valid ?
-#### Explanation of Problem
+### Problem Statement
+Check whether the given sequence of parenthesis is valid ?
+### Explanation
Imagine you have a bunch of different types of brackets, like `{` and `}` (curly brackets), `[` and `]` (square brackets), and `(` and `)` (round brackets).
A valid sequence of these brackets means that for every opening bracket, there is a matching closing bracket. It's like having pairs of shoes; you need a left shoe and a right shoe for each pair. In a valid sequence, you have the same number of left and right brackets, and they are correctly matched.
@@ -249,41 +269,40 @@ In summary, a valid sequence of brackets is like having balanced pairs of bracke
Imagine you are writing a small compiler for your college project and one of the tasks (or say sub-tasks) for the compiler would be to detect if the parenthesis are in place or not.
---
+
### Question
Which of the following expressions is balanced with respect to parentheses?
-**Choices**
+### Choices
- [x] `(a + b) * c`
- [ ] `(a + b)) * c`
-- [ ] `(a + b)(c`
-- [ ] `(a + b)c`
+- [ ] `(a + b) ( c`
+- [ ] `(a + b) c )`
---
-### Balanced Parenthesis Implementation
-#### Idea
+## Balanced Parenthesis Implementation
+
+### Idea
An interesting property about a valid parenthesis expression is that a sub-expression of a valid expression should also be a valid expression. (Not every sub-expression) e.g.
-#### Pseudocode
+### Pseudocode
1. To push data into stack, just create a node and attach before head.
```cpp
-void push(data) {
- new_node = Create a new Node with 'data'
- new_node.next = head
- head = new_node
- // Increment size
- t++
+function push(data){
+ new_node = Create a new Node with 'data'
+ new_node.next = head
+ head = new_node
+ // Increment size
+ t++
}
```
2. To pop data just remove one node from the beginning of linked list.
```cpp
-void pop() {
- if (!isEmpty()) return;
- head = head.next
- // Decrement size
- t--
+function pop(){
+ if( ! isEmpty()) return;
+ head = head.next
+ // Decrement size
+ t--
}
```
3. To find the data on top just access the head node.
```cpp
-int top() {
- if (!isEmpty()) return -1;
- return head.data;
+function top(){
+ if( ! isEmpty()) return -1;
+ return head.data;
}
```
> Note: While accessing top value in function, We can use another concept to indicate that stack is empty if we are using -1 as value to store in stack.
---
-### Problem 3 Balanced Paranthesis Concept with Implementation
+## Problem 3 Balanced Paranthesis Concept with Implementation
-Check whether the given sequence of parenthesis is valid ?
-#### Explanation of Problem
+### Problem Statement
+Check whether the given sequence of parenthesis is valid ?
+### Explanation
Imagine you have a bunch of different types of brackets, like `{` and `}` (curly brackets), `[` and `]` (square brackets), and `(` and `)` (round brackets).
A valid sequence of these brackets means that for every opening bracket, there is a matching closing bracket. It's like having pairs of shoes; you need a left shoe and a right shoe for each pair. In a valid sequence, you have the same number of left and right brackets, and they are correctly matched.
@@ -249,41 +269,40 @@ In summary, a valid sequence of brackets is like having balanced pairs of bracke
Imagine you are writing a small compiler for your college project and one of the tasks (or say sub-tasks) for the compiler would be to detect if the parenthesis are in place or not.
---
+
### Question
Which of the following expressions is balanced with respect to parentheses?
-**Choices**
+### Choices
- [x] `(a + b) * c`
- [ ] `(a + b)) * c`
-- [ ] `(a + b)(c`
-- [ ] `(a + b)c`
+- [ ] `(a + b) ( c`
+- [ ] `(a + b) c )`
---
-### Balanced Parenthesis Implementation
-#### Idea
+## Balanced Parenthesis Implementation
+
+### Idea
An interesting property about a valid parenthesis expression is that a sub-expression of a valid expression should also be a valid expression. (Not every sub-expression) e.g.
 -#### Hint
+### Hint
What if whenever we encounter a matching pair of parenthesis in the expression, we simply remove it from the expression?
The stack data structure can come in handy here in representing this recursive structure of the problem. We can't really process this from the inside out because we don't have an idea about the overall structure. But, the stack can help us process this recursively i.e. from outside to inwards.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+### Approach
* Iterate through the sequence, and whenever you encounter an opening parenthesis, you push it onto the stack.
* When you encounter a closing parenthesis, you pop the top element from the stack and compare it to the current closing parenthesis. If they are of the same type (matching), you continue; otherwise, the sequence is invalid.
Additionally, if you finish iterating through the sequence and the stack is not empty, the sequence is also invalid.
-#### Pseudocode
+### Pseudocode
```cpp
-bool is_valid_parentheses(sequence):
+function is_valid_parentheses(sequence):
// Initialize an empty stack
For each character 'char' in sequence:
@@ -302,7 +321,7 @@ bool is_valid_parentheses(sequence):
Return true
```
-#### Dry Run
+### Dry Run
**Example:** `{()[]}`
-#### Hint
+### Hint
What if whenever we encounter a matching pair of parenthesis in the expression, we simply remove it from the expression?
The stack data structure can come in handy here in representing this recursive structure of the problem. We can't really process this from the inside out because we don't have an idea about the overall structure. But, the stack can help us process this recursively i.e. from outside to inwards.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-#### Approach
+### Approach
* Iterate through the sequence, and whenever you encounter an opening parenthesis, you push it onto the stack.
* When you encounter a closing parenthesis, you pop the top element from the stack and compare it to the current closing parenthesis. If they are of the same type (matching), you continue; otherwise, the sequence is invalid.
Additionally, if you finish iterating through the sequence and the stack is not empty, the sequence is also invalid.
-#### Pseudocode
+### Pseudocode
```cpp
-bool is_valid_parentheses(sequence):
+function is_valid_parentheses(sequence):
// Initialize an empty stack
For each character 'char' in sequence:
@@ -302,7 +321,7 @@ bool is_valid_parentheses(sequence):
Return true
```
-#### Dry Run
+### Dry Run
**Example:** `{()[]}`
 @@ -318,54 +337,38 @@ bool is_valid_parentheses(sequence):
---
-### Problem 4 Remove equal pair of consecutive elements till possible
+## Problem 4 Remove equal pair of consecutive elements till possible
+### Problem Statement
Given a string, remove equal pair of consecutive elements till possible
-**Example**
-Let's say we have a string like `abcddc`, The idea here is to check if there are any consecutive pairs of characters that are the same. In this case, we see `dd` is such a pair. When you find such a pair, you simply remove it from the string, and it becomes `abcc` Then, you repeat the process with the new string, searching for and removing consecutive matching pairs of letters. This cycle continues until there are no more matching pairs left to remove.
+### Example
+String - `abcddc`
+The idea here is to check if there are any consecutive pairs of characters that are the same. In this case, we see `dd` is such a pair. When you find such a pair, you simply remove it from the string, and it becomes `abcc` Then, you repeat the process with the new string, searching for and removing consecutive matching pairs of letters. This cycle continues until there are no more matching pairs left to remove.
In the end the final string would be the solution.
+---
-**Approach**
-This problem can be solved very efficiently by using the concept of stack. The stack will help you keep track of the elements that haven't been canceled out by a matching element.
-```cpp
-string remove_equal_pairs(s):
- Initialize an empty stack
-
- For each character 'char' in s:
- If the stack is not empty and 'char' matches the character at the top of the stack:
- Pop the element from the stack
- Else:
- Push 'char' onto the stack
-
- Initialize an empty string 'result'
-
- While the stack is not empty:
- Pop an element from the stack and prepend it to 'result'
-
- Return 'result'
-```
-#### Complexity
-**Time Complexity:** O(n)
-**Space Complexity:** O(n)
----
### Question
If we remove equal pair of consecutive characters in this string multiple times then what will be the final string: `abbcbbcacx`
-**Choices**
+### Choices
- [ ] empty string
- [ ] ax
- [x] cx
- [ ] x
+---
+## Remove consecutive elements approach
+
+This problem can be solved very efficiently by using the concept of stack. The stack will help you keep track of the elements that haven't been canceled out by a matching element.
-**Explanation:**
+### Explanation:
Let's go through the step-by-step process for the given example: `abbcbbcacx`.
@@ -378,10 +381,32 @@ Let's go through the step-by-step process for the given example: `abbcbbcacx`.
7. The stack now contains only `a`. In the next iteration, encountering `a` leads to a pop operation for the existing `a`. **Stack - []**
8. Towards the end, push `c` and `x` onto the stack. Since there's no more to continue, the final stack **[c, x]**, represents the answer.
+```cpp
+function remove_equal_pairs(s):
+ Initialize an empty stack
+
+ For each character 'char' in s:
+ If the stack is not empty and 'char' matches the character at the top of the stack:
+ Pop the element from the stack
+ Else:
+ Push 'char' onto the stack
+
+ Initialize an empty string 'result'
+
+ While the stack is not empty:
+ Pop an element from the stack and prepend it to 'result'
+
+ Return 'result'
+```
+### Complexity
+**Time Complexity:** O(n)
+**Space Complexity:** O(n)
---
-### Problem 5 Evaluate Postfix Expression
+## Problem 5 Evaluate Postfix Expression
+
+### Problem Statement:
Given a postfix expression, evaluate it.
@@ -392,16 +417,12 @@ Below is an example of postfix expression:
2 + 3 => Postfix => 2 3 +
```
-#### Idea
+### Idea
An operator is present after the operands on which we need to apply that operator, hence stack is perfect data structure for this problem.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
We'll process the expression as follows-
-**Example 1**
+### Example 1
```cpp
[2, 3, +]
```
@@ -410,7 +431,7 @@ We'll process the expression as follows-
3. Then we found '`+`', so we will pop top two operands, i.e 3 & 2 in this case
4. Final result is 2 + 3 = 5
-**Example 2**
+### Example 2
```cpp
[4, 3, 3, *, +, 2, -]
```
@@ -424,17 +445,18 @@ We'll process the expression as follows-
---
+
+
### Question
What is the final answer obtained using the stack-based evaluation algorithm for the expression `[5, 2, *, 3, -]`?
-**Choices**
+### Choices
- [ ] 8
- [ ] 13
- [x] 7
- [ ] 15
-
-**Explanation:**
+### Explanation:
1. Push 5 onto the stack.
`Stack: [5]`
@@ -450,6 +472,8 @@ What is the final answer obtained using the stack-based evaluation algorithm for
---
+
+
### Question
Evaluate the given postfix expression:
@@ -457,14 +481,14 @@ Evaluate the given postfix expression:
3 5 + 2 - 2 5 * -
```
-**Choices**
+### Choices
- [ ] 0
- [ ] 4
- [x] -4
- [ ] 8
-**Explanation:**
+### Explanation:
Let's evaluate the given postfix expression step by step: `3 5 + 2 - 2 5 * -`
@@ -483,10 +507,12 @@ Let's evaluate the given postfix expression step by step: `3 5 + 2 - 2 5 * -`
---
-### Evaluate Postfix Expression Pseudocode
-#### Pseudocode
+## Evaluate Postfix Expression Pseudocode
+
+
+### Pseudocode
```cpp
-int evaluate_postfix(expression):
+function evaluate_postfix(expression):
Initialize an empty stack
For each element 'element' in expression:
@@ -502,6 +528,17 @@ int evaluate_postfix(expression):
Pop and return the result
```
-#### Complexity
+### Complexity
**Time Complexity:** O(n)
**Space Complexity:** O(n)
+
+---
+## Summary of Lecture
+
+### Conclusion
+* Stack is a linear data structure which stores data in LIFO manner.
+* The element which is inserted last will be popped out first.
+* In stack only top element is accessible.
+* All operations of stack are of constant time `O(1)`.
+* Stack is used at several places in real life problems, like postfix evaluation in calculators, valid paranthesis check in code editor.
+* We can implement stack with arrays or dynamic linked list in a conveninent manner.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md b/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md
index 2e23962..1ce586f 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md
@@ -1,12 +1,12 @@
# Stacks 2: Nearest Smaller/Greater Element
----
## Problem 1 Nearest smallest element on left
+### Problem Statement
Given an integer array A, find the index of nearest smallest element on left for all i index in A[].
Formally , for all i find j such that `A[j] < A[i]`, `j < i` and j is maximum.
-**Example:**
+### Example:
A[] = [8, 2, 4, 9, 7, 5, 3, 10]
Answer = [-1, -1, 1, 2, 2, 2, 1, 6]
@@ -25,50 +25,52 @@ For each element in the input array, the output indicates the index of the neare
| 10 | 3 | 6 |
---
+
+
### Question
-Given N array elements, find the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, return -1. (Assume all elements are positive).
+Given N array elements, find the **index** of the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, ans is -1.
A = [4, 6, 10, 11, 7, 8, 3, 5]
-**Choices**
+### Choices
-- [ ] [-1, 4, 6, 10, 4, 7, -1, 3]
-- [ ] [-1, 4, 6, 10, 6, 6, -1, 3]
-- [x] [-1, 4, 6, 10, 6, 7, -1, 3]
+- [ ] [-1, 0, 1, 2, 0, 4, -1, 6]
+- [ ] [-1, 0, 1, 2, 1, 1, -1, 6]
+- [x] [-1, 0, 1, 2, 1, 4, -1, 6]
---
+
+
### Question
-Given N array elements, find the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, return -1. (Assume all elements are positive).
+Given N array elements, find the **index** of the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, ans is -1.
A = [4, 5, 2, 10, 8, 2]
-**Choices**
+### Choices
-- [ ] [4, 4, -1, 2, 2, -1]
-- [x] [-1, 4, -1, 2, 2, -1]
-- [ ] [-1, 4, 4, 2, 2, -1]
-- [ ] [-1, 4, 2, 2, 2, 2]
+- [ ] [0, 0, -1, 2, 2, -1]
+- [x] [-1, 0, -1, 2, 2, -1]
+- [ ] [-1, 0, 0, 2, 2, -1]
+- [ ] [-1, 0, 2, 2, 2, 2]
---
+## Nearest smallest element on left Brute Force
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Nearest smallest element on left Brute Force
For each element in the array, iterate through all the elements to its left.
-#### Pseudocode
+Note: We want the indices in answer array.
+
+### Pseudocode
```java
result[n];
-for (int i = 0; i < n; i++) {
- int nearestSmaller = -1;
+for (i -> 0 to n - 1) {
+ nearestSmaller = -1;
- for (int j = i - 1; j >= 0; j--) {
+ for (j -> i - 1 down to 0) {
if (arr[j] < arr[i]) {
nearestSmaller = j;
break;
@@ -80,49 +82,48 @@ for (int i = 0; i < n; i++) {
return result;
```
-#### Time Complexity
+### Time Complexity
This approach has a time complexity of $O(n^2)$ because for each element, it requires checking all elements to its left. It is inefficient for large input arrays.
---
+
+
### Question
If A = [8, x, x, x, x, 5, x, x, x, x...]
-For any element > 5 can the element 8 become nearest smaller element on left?
+For any element present after 5, can the element 8 become nearest smaller element on left?
-**Choices**
+### Choices
- [ ] Yes
- [x] No
-
-#### Explanation
+### Explanation
Not really since 5 will be the answer for them.
---
-### Nearest Smallest Element Optimized Approach
-#### Observation/Intuition:
+## Nearest Smallest Element Optimized Approach
+
+
+### Observation/Intuition:
+
+To efficiently find the nearest smaller element to the left of each element in an array, you can use a stack. Here’s a simplified explanation:
-When iterating through the array from left to right, we want to find the nearest smaller element on the left for each element efficiently.
-* Using a stack helps us keep track of potential candidates for the nearest smaller element as we move from left to right. The stack stores the indices of elements that have not yet found their nearest smaller element.
-* When we encounter a new element, we check if it is smaller than the element at the top of the stack (the most recent candidate for the nearest smaller element). If it is, we know that the element at the top of the stack cannot be the nearest smaller element for any future elements because the new element is closer and smaller. Therefore, we pop elements from the stack until we find an element that is smaller than the current element or until the stack becomes empty.
-* The popped elements from the stack are assigned as the nearest smaller elements on the left for the corresponding indices.
-* By doing this, we efficiently find the nearest smaller element for each element in the array without the need for nested loops or extensive comparisons, resulting in a linear time complexity of O(n).
+1. **Use a Stack:** As you move from left to right through the array, use a stack to keep track of element indices that haven't yet found their nearest smaller element.
+2. **Compare with Stack's Top:** For each new element, compare it with the element at the top of the stack. If the new element is smaller, it means it's the nearest smaller element for the future elements, making the stack's top element no longer valid.
-#### Optimized Approach:
+3. **Pop the Stack:** Continue popping the stack until you find an element smaller than the current one or the stack is empty. This way, the popped elements are marked as having their nearest smaller element found.
+
+4. **Linear Time Complexity:** This method avoids nested loops and extensive comparisons, allowing you to find each element's nearest smaller neighbor with a linear time complexity, 𝑂(𝑛)
+
+By continuously updating the stack and assigning nearest smaller elements efficiently, this approach streamlines the process, ensuring each element's comparison is handled as you iterate through the array.
-* Create an empty stack to store the indices of elements.
-* Initialize an empty result array with -1 values.
-* Iterate through the input array from left to right.
-* For each element, while the stack is not empty and the element at the current index is less than or equal to the element at the index stored at the top of the stack, pop elements from the stack and update the result array for those popped elements.
-* After the loop, the stack will contain indices of elements that haven't found their nearest smaller element. These elements have no smaller element on the left side.
-* The result array will contain the index of the nearest smaller element for all other elements.
-* Return the result array.
---
-### Nearest Smallest Element Optimized Approach Dry Run
+## Nearest Smallest Element Optimized Approach Dry Run
* Initialize an empty stack and an empty result array of the same length as A filled with -1s.
@@ -140,72 +141,81 @@ When iterating through the array from left to right, we want to find the nearest
| 7 | 10 | NIL | 1, 6 | 3 | 7 |
-**Code:**
+**PseudoCode:**
```java
-for (int i = 0; i < n; i++) {
- // While the stack is not empty and the element at the current index is less than or
- // equal to the element at the index stored at the top of the stack, pop elements from
- // the stack and update the result array.
- while (!stack.isEmpty() && arr[i] <= arr[stack.peek()]) {
- stack.pop();
- }
+for (i -> 0 to n - 1) {
+ // While the stack is not empty and the element at the current index is less than or
+ // equal to the element at the index stored at the top of the stack, pop elements from
+ // the stack and update the result array.
+ while (not Empty(stack) and arr[i] <= arr[stack.top()]) {
+ stack.pop();
+ }
- // If the stack is not empty, the top element's index is the nearest smaller element on the left.
- if (!stack.isEmpty()) {
- result[i] = stack.peek();
- }
+ // If the stack is not empty, the top element's index is the nearest smaller element on the left.
+ if (not Empty(stack)) {
+ result[i] = stack.top();
+ }
- // Push the current index onto the stack.
- stack.push(i);
-}
+ // Push the current index onto the stack.
+ stack.push(i);
+ }
-return result;
+ return result;
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
---
-### Nearest Smallest Element related questions
+## Variation Question 2 Restraunt Hunt
-### Question-2
-For all `i`, find nearest smaller or equal element on left
+A person uses **Google Maps** to find the nearest restaurants and picks one based on its proximity. Unfortunately, after visiting, they realized that the restaurant didn't meet their expectations.
-**ANS:** For this question, we need to change the sign from `<=` to `<` in the above code of the approach in line number 5.
+**Task**
+Let's break it down with a simple example. You have a list of restaurants and their **ratings**. For each restaurant, we're going to find the next restaurant to the **right** on the list that's not just close but also has a **higher rating** than the **current** one. If there's no better option on the list, we'll say there's **none** available.
-### Question-3
+**Problem**
+Given a sequence of restaurants listed on Google Maps with their ratings, create a tool that helps users discover the rating of the next higher-rated restaurant to the right for each listed establishment.
-For all `i`, find nearest greater element on left
+#### Example Input
-**ANS:** For this question, we need to change the sign from `<=` to `>=` in the above code of the approach.
+Ratings[] =
-### Question-4
-For all `i`, find nearest greater or equal element on left.
+| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
+| -| -| -| -| -| -|-|
+| 3 | 2 | 6 | 5 | 8 | 7 |9 |
-**ANS:** For this question, we need to change the sign from `<=` to `>` in the above code of the approach.
+Output -
+Next greater elements' indices are mentioned for each element.
+| 3 | 2 | 6 | 5 | 8 | 7 |9 |
+| -| -| -| -| -| -|-|
+| 2 | 2 | 4 | 4 | 6 | 6 | -1 |
-### Question-5
+### Approach
-For all `i`, find nearest smaller element on right.
+In this problem, **we have to find greater element on right.**
+This is also a variation of above problem only.
+* For this question, we need to iterate from right to left.
+* For an element A[i], while A[i] >= element at top of stack, then keep removing.
+* If at the end stack is not empty, the element at top will be answer for A[i].
-**ANS:** For this question, the for loop iterates through the input array arr in reverse order (from right to left), and it finds the nearest smaller element on the right for each element using a stack.
+### Code
```java
-for (int i = n - 1; i >= 0; i--) {
- // While the stack is not empty and the element at the current index is less than or
- // equal to the element at the index stored at the top of the stack, pop elements from
- // the stack and update the result array.
- while (!stack.isEmpty() && arr[i] <= arr[stack.peek()]) {
+for (i -> n - 1 down to 0) {
+ // While the stack is not empty and the current element is greater than or
+ // equal to the element at top, pop and update the result array.
+ while (not stack.isEmpty() and arr[i] >= arr[stack.to()]) {
stack.pop();
}
- // If the stack is not empty, the top element's index is the nearest smaller element on the right.
- if (!stack.isEmpty()) {
- result[i] = stack.peek();
+ // If the stack is not empty, the top element is the nearest greater element on the right.
+ if (not stack.isEmpty()) {
+ result[i] = stack.top();
}
// Push the current index onto the stack.
@@ -215,29 +225,21 @@ for (int i = n - 1; i >= 0; i--) {
return result;
```
-### Question-6
-For all `i`, find nearest smaller or equal element on right.
-
-**ANS:** For this question, we need to change the sign from `<=` to `>` in the above code of the approach.
-
-### Question - 7
-
-For all `i`, find nearest greater element on right.
-
-**ANS:** For this question, we need to change the sign from `<=` to `>=` in the above code of the approach.
-
-### Question-8
-
-For all `i`, find the nearest greater or equal element on right.
+---
+## Variations of the problem
-**ANS:** For this question, we need to change the sign from `<=` to `>` in the above code of the approach.
+## Try the below problems by yourselves
+### Question 3: For all `i`, find nearest greater element on left
+### Question 4: For all `i`, find nearest smaller element on right.
---
-### Problem 2 Largest Rectangle in histogram
+## Problem 2 Largest Rectangle in histogram
+
+### Problem Statement
Given an integer array A, where
A[i] = height of i-th bar.
@@ -256,24 +258,30 @@ The goal is to find the largest rectangle that can be formed using continuous ba
Sure, here is a brief MCQ based on finding the largest rectangle formed by continuous bars in an integer array representing bar heights:
---
+
+
### Question
Find the area of the largest rectangle formed by continious bars.
bars = [1, 2, 3, 2, 1]
-**Choices**
+### Choices
- [ ] 5
- [ ] 9
- [ ] 7
- [x] 6
- [ ] 3
-**Explanation:**
+### Explanation:
The largest rectangle is formed from [2, 3, 2] whose contribution is [2, 2, 2] thus the area of the largest rectangle is 6.
-#### Largest Rectangle Brute Force
+---
+## Largest rectangle Approach
+
+
+### Largest Rectangle Brute Force
**Brute - Force Approach Pseudo Code:**
@@ -297,11 +305,8 @@ function findMaxRectangleArea(hist):
The brute-force approach involves nested loops and has a time complexity of O(n^2) because it considers all possible combinations of starting and ending points for rectangles.
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
-#### Optimized Approch
+### Optimized Approch
**Mathematical Representation:**
@@ -354,8 +359,10 @@ function findMaxRectangleArea(hist):
* We subtract 1 from the product of `nearest_smaller_right[i]` and `nearest_smaller_left[i]` to account for the width of the rectangle.
---
-### Problem 3 Sum of (Max-Min) of all subarrays
+## Problem 3 Sum of (Max-Min) of all subarrays
+
+### Question
Giver an integer array with distinct integers, for all subarrays find (max-min) and return its sum as the answer.
@@ -377,10 +384,6 @@ The goal is to find the sum of the differences between the maximum and minimum e
The sum of all differences is 0 + 0 + 0 + 3 + 2 + 3 = 8.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
### Sum of (Max-Min) of all subarrays Brute force approach
**Brute-Force Approach Pseudo Code:**
@@ -407,24 +410,26 @@ function sumOfDifferences(arr):
return result
```
-#### Complexity
-**Time Complexity:** O(N * N)
+### Complexity
+**Time Complexity:** O(N^3^)
**Space Complexity:** O(1)
---
+
+
### Question
Giver an integer array, A with distinct integers, for all subarrays find (max-min) and return its sum as the answer.
A = [1, 2, 3]
-**Choices**
+### Choices
- [x] 4
- [ ] 6
- [ ] 5
- [ ] 0
-#### Explanation:
+### Explanation:
The goal is to find the sum of the differences between the maximum and minimum elements for all possible subarrays.
@@ -444,63 +449,105 @@ The sum of all differences is 0 + 0 + 0 + 1 + 1 + 2 = 4.
---
-### Sum of (Max-Min) of all subarrays Optimized approach
+## Sum of (Max-Min) of all subarrays Optimized approach
+
-#### Optimized Approach
+### Optimized Approach
**Intuition:**
-* The contribution technique eliminates redundant calculations by efficiently counting the number of subarrays in which each element can be the maximum or minimum element.
-* By tracking the elements that are greater or smaller than the current element in both directions, we can calculate their contributions to the sum of (max - min) differences without repeatedly considering the same subarrays.
+1. Calculate the contribution of each element being the maximum
+2. Calculate the contribution of each element being the minimum
+3. Calculate the total contribution : contribution = element × (count as max − count as min)
-**Optimized Approach Pseudo code:**
+### Contribution idea
+Let's take example **A** = $[1, 2, 3]$
+
+Now compute the 4 things for each element:
+1. Previous Greater element's index (default value -1)
+2. Next Greater element's index (default value n)
+3. Previous Smaller element's index (default value -1)
+4. Next Smaller element's index (default value n)
+
+| index | prvGreater | nxtGreater | prvSmaller | nxtSmaller |
+|:-----:|:----------:|:----------:|:----------:|:----------:|
+| 0 | -1 | 1 | -1 | 3 |
+| 1 | -1 | 2 | 0 | 3 |
+| 2 | -1 | 3 | 1 | 3 |
-```cpp
-function sumOfDifferences(arr):
- n = length of arr
- left = new array of size n
- right = new array of size n
- max_stack = empty stack
- min_stack = empty stack
- result = 0
- // Initialize left and right arrays
- for i from 0 to n - 1:
- left[i] = (i + 1) * (n - i)
- right[i] = (i + 1) * (i + 1)
+**Contributions :**
- // Calculate left contributions
- for i from 0 to n - 1:
- while (not max_stack.isEmpty() and arr[i] > arr[max_stack.top()]):
- max_stack.pop()
+1. Contribution as Min = $(nxtSmaller - i) * (i - prvSmaller)$
+2. Similarly Contribution as Max = $(nxtGreater - i) * (i - prvGreater)$
+3. Total contribution = (contribution as max - contribution as min)
- if (max_stack.isEmpty()):
- left[i] = (i + 1) * (i + 1)
- else:
- left[i] = (i - max_stack.top()) * (i + 1)
+| index | contribution as Min | contribution as Max | Total Contribution |
+|:-----:|:-------------------:|:-------------------:| ------------------ |
+| 0 | 3 | 1 | -2 |
+| 1 | 2 | 2 | 0 |
+| 2 | 1 | 3 | 2 |
- max_stack.push(i)
+Hence Total Contribution = $A[0] * (-2) + A[1] * (0) + A[2] * (2)$
+= $-2 + 0 + 6$ = $4$
- // Calculate right contributions
- for i from n - 1 to 0:
- while (not min_stack.isEmpty() and arr[i] < arr[min_stack.top()]):
- min_stack.pop()
+**Optimized Approach Pseudo code:**
- if (min_stack.isEmpty()):
- right[i] = (n - i) * (n - i)
- else:
- right[i] = (min_stack.top() - i) * (n - i)
+```cpp
+function subarrayRanges(A):
+ n = size(A)
+ nextGreater = array of size n, initialized to n
+ prevGreater = array of size n, initialized to -1
+ nextSmaller = array of size n, initialized to n
+ prevSmaller = array of size n, initialized to -1
+
+ stack = empty stack
+
+ // Find next greater elements
+ for i from 0 to n-1:
+ while stack is not empty and A[stack.top()] < A[i]:
+ nextGreater[stack.top()] = i
+ stack.pop()
+ stack.push(i)
+
+ clear stack
+
+ // Find previous greater elements
+ for i from n-1 to 0:
+ while stack is not empty and A[stack.top()] <= A[i]:
+ prevGreater[stack.top()] = i
+ stack.pop()
+ stack.push(i)
+
+ clear stack
+
+ // Find next smaller elements
+ for i from 0 to n-1:
+ while stack is not empty and A[stack.top()] > A[i]:
+ nextSmaller[stack.top()] = i
+ stack.pop()
+ stack.push(i)
+
+ clear stack
+
+ // Find previous smaller elements
+ for i from n-1 to 0:
+ while stack is not empty and A[stack.top()] >= A[i]:
+ prevSmaller[stack.top()] = i
+ stack.pop()
+ stack.push(i)
- min_stack.push(i)
+ result = 0
- // Calculate the sum of (max - min) differences
- for i from 0 to n - 1:
- contribution = (right[i] * left[i]) * arr[i]
- result += contribution
+ // Calculate the result based on the contributions
+ for i from 0 to n-1:
+ maxContribution = (i - prevGreater[i]) * (nextGreater[i] - i)
+ minContribution = (i - prevSmaller[i]) * (nextSmaller[i] - i)
+ result += A[i] * (maxContribution - minContribution)
return result
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Topological Sort & Interview Problems.md b/Academy DSA Typed Notes/Advanced/DSA Topological Sort & Interview Problems.md
new file mode 100644
index 0000000..e5bcfdd
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Topological Sort & Interview Problems.md
@@ -0,0 +1,414 @@
+
+# DSA: Topological Sort & Interview Problems
+
+## Possibility of finishing the courses
+
+Given N courses with pre-requisites, we have to check if it is possible to finish all the course ?
+
+### Example:
+
+N = 5
+
+**Pre-requisites**
+1 ---> 2 & 3 [1 is pre-req for 2 and 3]
+2 ---> 3 & 5
+3 ---> 4
+4 ---> 2
+
+
@@ -318,54 +337,38 @@ bool is_valid_parentheses(sequence):
---
-### Problem 4 Remove equal pair of consecutive elements till possible
+## Problem 4 Remove equal pair of consecutive elements till possible
+### Problem Statement
Given a string, remove equal pair of consecutive elements till possible
-**Example**
-Let's say we have a string like `abcddc`, The idea here is to check if there are any consecutive pairs of characters that are the same. In this case, we see `dd` is such a pair. When you find such a pair, you simply remove it from the string, and it becomes `abcc` Then, you repeat the process with the new string, searching for and removing consecutive matching pairs of letters. This cycle continues until there are no more matching pairs left to remove.
+### Example
+String - `abcddc`
+The idea here is to check if there are any consecutive pairs of characters that are the same. In this case, we see `dd` is such a pair. When you find such a pair, you simply remove it from the string, and it becomes `abcc` Then, you repeat the process with the new string, searching for and removing consecutive matching pairs of letters. This cycle continues until there are no more matching pairs left to remove.
In the end the final string would be the solution.
+---
-**Approach**
-This problem can be solved very efficiently by using the concept of stack. The stack will help you keep track of the elements that haven't been canceled out by a matching element.
-```cpp
-string remove_equal_pairs(s):
- Initialize an empty stack
-
- For each character 'char' in s:
- If the stack is not empty and 'char' matches the character at the top of the stack:
- Pop the element from the stack
- Else:
- Push 'char' onto the stack
-
- Initialize an empty string 'result'
-
- While the stack is not empty:
- Pop an element from the stack and prepend it to 'result'
-
- Return 'result'
-```
-#### Complexity
-**Time Complexity:** O(n)
-**Space Complexity:** O(n)
----
### Question
If we remove equal pair of consecutive characters in this string multiple times then what will be the final string: `abbcbbcacx`
-**Choices**
+### Choices
- [ ] empty string
- [ ] ax
- [x] cx
- [ ] x
+---
+## Remove consecutive elements approach
+
+This problem can be solved very efficiently by using the concept of stack. The stack will help you keep track of the elements that haven't been canceled out by a matching element.
-**Explanation:**
+### Explanation:
Let's go through the step-by-step process for the given example: `abbcbbcacx`.
@@ -378,10 +381,32 @@ Let's go through the step-by-step process for the given example: `abbcbbcacx`.
7. The stack now contains only `a`. In the next iteration, encountering `a` leads to a pop operation for the existing `a`. **Stack - []**
8. Towards the end, push `c` and `x` onto the stack. Since there's no more to continue, the final stack **[c, x]**, represents the answer.
+```cpp
+function remove_equal_pairs(s):
+ Initialize an empty stack
+
+ For each character 'char' in s:
+ If the stack is not empty and 'char' matches the character at the top of the stack:
+ Pop the element from the stack
+ Else:
+ Push 'char' onto the stack
+
+ Initialize an empty string 'result'
+
+ While the stack is not empty:
+ Pop an element from the stack and prepend it to 'result'
+
+ Return 'result'
+```
+### Complexity
+**Time Complexity:** O(n)
+**Space Complexity:** O(n)
---
-### Problem 5 Evaluate Postfix Expression
+## Problem 5 Evaluate Postfix Expression
+
+### Problem Statement:
Given a postfix expression, evaluate it.
@@ -392,16 +417,12 @@ Below is an example of postfix expression:
2 + 3 => Postfix => 2 3 +
```
-#### Idea
+### Idea
An operator is present after the operands on which we need to apply that operator, hence stack is perfect data structure for this problem.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
We'll process the expression as follows-
-**Example 1**
+### Example 1
```cpp
[2, 3, +]
```
@@ -410,7 +431,7 @@ We'll process the expression as follows-
3. Then we found '`+`', so we will pop top two operands, i.e 3 & 2 in this case
4. Final result is 2 + 3 = 5
-**Example 2**
+### Example 2
```cpp
[4, 3, 3, *, +, 2, -]
```
@@ -424,17 +445,18 @@ We'll process the expression as follows-
---
+
+
### Question
What is the final answer obtained using the stack-based evaluation algorithm for the expression `[5, 2, *, 3, -]`?
-**Choices**
+### Choices
- [ ] 8
- [ ] 13
- [x] 7
- [ ] 15
-
-**Explanation:**
+### Explanation:
1. Push 5 onto the stack.
`Stack: [5]`
@@ -450,6 +472,8 @@ What is the final answer obtained using the stack-based evaluation algorithm for
---
+
+
### Question
Evaluate the given postfix expression:
@@ -457,14 +481,14 @@ Evaluate the given postfix expression:
3 5 + 2 - 2 5 * -
```
-**Choices**
+### Choices
- [ ] 0
- [ ] 4
- [x] -4
- [ ] 8
-**Explanation:**
+### Explanation:
Let's evaluate the given postfix expression step by step: `3 5 + 2 - 2 5 * -`
@@ -483,10 +507,12 @@ Let's evaluate the given postfix expression step by step: `3 5 + 2 - 2 5 * -`
---
-### Evaluate Postfix Expression Pseudocode
-#### Pseudocode
+## Evaluate Postfix Expression Pseudocode
+
+
+### Pseudocode
```cpp
-int evaluate_postfix(expression):
+function evaluate_postfix(expression):
Initialize an empty stack
For each element 'element' in expression:
@@ -502,6 +528,17 @@ int evaluate_postfix(expression):
Pop and return the result
```
-#### Complexity
+### Complexity
**Time Complexity:** O(n)
**Space Complexity:** O(n)
+
+---
+## Summary of Lecture
+
+### Conclusion
+* Stack is a linear data structure which stores data in LIFO manner.
+* The element which is inserted last will be popped out first.
+* In stack only top element is accessible.
+* All operations of stack are of constant time `O(1)`.
+* Stack is used at several places in real life problems, like postfix evaluation in calculators, valid paranthesis check in code editor.
+* We can implement stack with arrays or dynamic linked list in a conveninent manner.
diff --git a/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md b/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md
index 2e23962..1ce586f 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Stacks 2 Nearest Smaller or Greater Element.md
@@ -1,12 +1,12 @@
# Stacks 2: Nearest Smaller/Greater Element
----
## Problem 1 Nearest smallest element on left
+### Problem Statement
Given an integer array A, find the index of nearest smallest element on left for all i index in A[].
Formally , for all i find j such that `A[j] < A[i]`, `j < i` and j is maximum.
-**Example:**
+### Example:
A[] = [8, 2, 4, 9, 7, 5, 3, 10]
Answer = [-1, -1, 1, 2, 2, 2, 1, 6]
@@ -25,50 +25,52 @@ For each element in the input array, the output indicates the index of the neare
| 10 | 3 | 6 |
---
+
+
### Question
-Given N array elements, find the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, return -1. (Assume all elements are positive).
+Given N array elements, find the **index** of the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, ans is -1.
A = [4, 6, 10, 11, 7, 8, 3, 5]
-**Choices**
+### Choices
-- [ ] [-1, 4, 6, 10, 4, 7, -1, 3]
-- [ ] [-1, 4, 6, 10, 6, 6, -1, 3]
-- [x] [-1, 4, 6, 10, 6, 7, -1, 3]
+- [ ] [-1, 0, 1, 2, 0, 4, -1, 6]
+- [ ] [-1, 0, 1, 2, 1, 1, -1, 6]
+- [x] [-1, 0, 1, 2, 1, 4, -1, 6]
---
+
+
### Question
-Given N array elements, find the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, return -1. (Assume all elements are positive).
+Given N array elements, find the **index** of the nearest smaller element on the left side for all the elements. If there is NO smaller element on left side, ans is -1.
A = [4, 5, 2, 10, 8, 2]
-**Choices**
+### Choices
-- [ ] [4, 4, -1, 2, 2, -1]
-- [x] [-1, 4, -1, 2, 2, -1]
-- [ ] [-1, 4, 4, 2, 2, -1]
-- [ ] [-1, 4, 2, 2, 2, 2]
+- [ ] [0, 0, -1, 2, 2, -1]
+- [x] [-1, 0, -1, 2, 2, -1]
+- [ ] [-1, 0, 0, 2, 2, -1]
+- [ ] [-1, 0, 2, 2, 2, 2]
---
+## Nearest smallest element on left Brute Force
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-### Nearest smallest element on left Brute Force
For each element in the array, iterate through all the elements to its left.
-#### Pseudocode
+Note: We want the indices in answer array.
+
+### Pseudocode
```java
result[n];
-for (int i = 0; i < n; i++) {
- int nearestSmaller = -1;
+for (i -> 0 to n - 1) {
+ nearestSmaller = -1;
- for (int j = i - 1; j >= 0; j--) {
+ for (j -> i - 1 down to 0) {
if (arr[j] < arr[i]) {
nearestSmaller = j;
break;
@@ -80,49 +82,48 @@ for (int i = 0; i < n; i++) {
return result;
```
-#### Time Complexity
+### Time Complexity
This approach has a time complexity of $O(n^2)$ because for each element, it requires checking all elements to its left. It is inefficient for large input arrays.
---
+
+
### Question
If A = [8, x, x, x, x, 5, x, x, x, x...]
-For any element > 5 can the element 8 become nearest smaller element on left?
+For any element present after 5, can the element 8 become nearest smaller element on left?
-**Choices**
+### Choices
- [ ] Yes
- [x] No
-
-#### Explanation
+### Explanation
Not really since 5 will be the answer for them.
---
-### Nearest Smallest Element Optimized Approach
-#### Observation/Intuition:
+## Nearest Smallest Element Optimized Approach
+
+
+### Observation/Intuition:
+
+To efficiently find the nearest smaller element to the left of each element in an array, you can use a stack. Here’s a simplified explanation:
-When iterating through the array from left to right, we want to find the nearest smaller element on the left for each element efficiently.
-* Using a stack helps us keep track of potential candidates for the nearest smaller element as we move from left to right. The stack stores the indices of elements that have not yet found their nearest smaller element.
-* When we encounter a new element, we check if it is smaller than the element at the top of the stack (the most recent candidate for the nearest smaller element). If it is, we know that the element at the top of the stack cannot be the nearest smaller element for any future elements because the new element is closer and smaller. Therefore, we pop elements from the stack until we find an element that is smaller than the current element or until the stack becomes empty.
-* The popped elements from the stack are assigned as the nearest smaller elements on the left for the corresponding indices.
-* By doing this, we efficiently find the nearest smaller element for each element in the array without the need for nested loops or extensive comparisons, resulting in a linear time complexity of O(n).
+1. **Use a Stack:** As you move from left to right through the array, use a stack to keep track of element indices that haven't yet found their nearest smaller element.
+2. **Compare with Stack's Top:** For each new element, compare it with the element at the top of the stack. If the new element is smaller, it means it's the nearest smaller element for the future elements, making the stack's top element no longer valid.
-#### Optimized Approach:
+3. **Pop the Stack:** Continue popping the stack until you find an element smaller than the current one or the stack is empty. This way, the popped elements are marked as having their nearest smaller element found.
+
+4. **Linear Time Complexity:** This method avoids nested loops and extensive comparisons, allowing you to find each element's nearest smaller neighbor with a linear time complexity, 𝑂(𝑛)
+
+By continuously updating the stack and assigning nearest smaller elements efficiently, this approach streamlines the process, ensuring each element's comparison is handled as you iterate through the array.
-* Create an empty stack to store the indices of elements.
-* Initialize an empty result array with -1 values.
-* Iterate through the input array from left to right.
-* For each element, while the stack is not empty and the element at the current index is less than or equal to the element at the index stored at the top of the stack, pop elements from the stack and update the result array for those popped elements.
-* After the loop, the stack will contain indices of elements that haven't found their nearest smaller element. These elements have no smaller element on the left side.
-* The result array will contain the index of the nearest smaller element for all other elements.
-* Return the result array.
---
-### Nearest Smallest Element Optimized Approach Dry Run
+## Nearest Smallest Element Optimized Approach Dry Run
* Initialize an empty stack and an empty result array of the same length as A filled with -1s.
@@ -140,72 +141,81 @@ When iterating through the array from left to right, we want to find the nearest
| 7 | 10 | NIL | 1, 6 | 3 | 7 |
-**Code:**
+**PseudoCode:**
```java
-for (int i = 0; i < n; i++) {
- // While the stack is not empty and the element at the current index is less than or
- // equal to the element at the index stored at the top of the stack, pop elements from
- // the stack and update the result array.
- while (!stack.isEmpty() && arr[i] <= arr[stack.peek()]) {
- stack.pop();
- }
+for (i -> 0 to n - 1) {
+ // While the stack is not empty and the element at the current index is less than or
+ // equal to the element at the index stored at the top of the stack, pop elements from
+ // the stack and update the result array.
+ while (not Empty(stack) and arr[i] <= arr[stack.top()]) {
+ stack.pop();
+ }
- // If the stack is not empty, the top element's index is the nearest smaller element on the left.
- if (!stack.isEmpty()) {
- result[i] = stack.peek();
- }
+ // If the stack is not empty, the top element's index is the nearest smaller element on the left.
+ if (not Empty(stack)) {
+ result[i] = stack.top();
+ }
- // Push the current index onto the stack.
- stack.push(i);
-}
+ // Push the current index onto the stack.
+ stack.push(i);
+ }
-return result;
+ return result;
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
---
-### Nearest Smallest Element related questions
+## Variation Question 2 Restraunt Hunt
-### Question-2
-For all `i`, find nearest smaller or equal element on left
+A person uses **Google Maps** to find the nearest restaurants and picks one based on its proximity. Unfortunately, after visiting, they realized that the restaurant didn't meet their expectations.
-**ANS:** For this question, we need to change the sign from `<=` to `<` in the above code of the approach in line number 5.
+**Task**
+Let's break it down with a simple example. You have a list of restaurants and their **ratings**. For each restaurant, we're going to find the next restaurant to the **right** on the list that's not just close but also has a **higher rating** than the **current** one. If there's no better option on the list, we'll say there's **none** available.
-### Question-3
+**Problem**
+Given a sequence of restaurants listed on Google Maps with their ratings, create a tool that helps users discover the rating of the next higher-rated restaurant to the right for each listed establishment.
-For all `i`, find nearest greater element on left
+#### Example Input
-**ANS:** For this question, we need to change the sign from `<=` to `>=` in the above code of the approach.
+Ratings[] =
-### Question-4
-For all `i`, find nearest greater or equal element on left.
+| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
+| -| -| -| -| -| -|-|
+| 3 | 2 | 6 | 5 | 8 | 7 |9 |
-**ANS:** For this question, we need to change the sign from `<=` to `>` in the above code of the approach.
+Output -
+Next greater elements' indices are mentioned for each element.
+| 3 | 2 | 6 | 5 | 8 | 7 |9 |
+| -| -| -| -| -| -|-|
+| 2 | 2 | 4 | 4 | 6 | 6 | -1 |
-### Question-5
+### Approach
-For all `i`, find nearest smaller element on right.
+In this problem, **we have to find greater element on right.**
+This is also a variation of above problem only.
+* For this question, we need to iterate from right to left.
+* For an element A[i], while A[i] >= element at top of stack, then keep removing.
+* If at the end stack is not empty, the element at top will be answer for A[i].
-**ANS:** For this question, the for loop iterates through the input array arr in reverse order (from right to left), and it finds the nearest smaller element on the right for each element using a stack.
+### Code
```java
-for (int i = n - 1; i >= 0; i--) {
- // While the stack is not empty and the element at the current index is less than or
- // equal to the element at the index stored at the top of the stack, pop elements from
- // the stack and update the result array.
- while (!stack.isEmpty() && arr[i] <= arr[stack.peek()]) {
+for (i -> n - 1 down to 0) {
+ // While the stack is not empty and the current element is greater than or
+ // equal to the element at top, pop and update the result array.
+ while (not stack.isEmpty() and arr[i] >= arr[stack.to()]) {
stack.pop();
}
- // If the stack is not empty, the top element's index is the nearest smaller element on the right.
- if (!stack.isEmpty()) {
- result[i] = stack.peek();
+ // If the stack is not empty, the top element is the nearest greater element on the right.
+ if (not stack.isEmpty()) {
+ result[i] = stack.top();
}
// Push the current index onto the stack.
@@ -215,29 +225,21 @@ for (int i = n - 1; i >= 0; i--) {
return result;
```
-### Question-6
-For all `i`, find nearest smaller or equal element on right.
-
-**ANS:** For this question, we need to change the sign from `<=` to `>` in the above code of the approach.
-
-### Question - 7
-
-For all `i`, find nearest greater element on right.
-
-**ANS:** For this question, we need to change the sign from `<=` to `>=` in the above code of the approach.
-
-### Question-8
-
-For all `i`, find the nearest greater or equal element on right.
+---
+## Variations of the problem
-**ANS:** For this question, we need to change the sign from `<=` to `>` in the above code of the approach.
+## Try the below problems by yourselves
+### Question 3: For all `i`, find nearest greater element on left
+### Question 4: For all `i`, find nearest smaller element on right.
---
-### Problem 2 Largest Rectangle in histogram
+## Problem 2 Largest Rectangle in histogram
+
+### Problem Statement
Given an integer array A, where
A[i] = height of i-th bar.
@@ -256,24 +258,30 @@ The goal is to find the largest rectangle that can be formed using continuous ba
Sure, here is a brief MCQ based on finding the largest rectangle formed by continuous bars in an integer array representing bar heights:
---
+
+
### Question
Find the area of the largest rectangle formed by continious bars.
bars = [1, 2, 3, 2, 1]
-**Choices**
+### Choices
- [ ] 5
- [ ] 9
- [ ] 7
- [x] 6
- [ ] 3
-**Explanation:**
+### Explanation:
The largest rectangle is formed from [2, 3, 2] whose contribution is [2, 2, 2] thus the area of the largest rectangle is 6.
-#### Largest Rectangle Brute Force
+---
+## Largest rectangle Approach
+
+
+### Largest Rectangle Brute Force
**Brute - Force Approach Pseudo Code:**
@@ -297,11 +305,8 @@ function findMaxRectangleArea(hist):
The brute-force approach involves nested loops and has a time complexity of O(n^2) because it considers all possible combinations of starting and ending points for rectangles.
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
-#### Optimized Approch
+### Optimized Approch
**Mathematical Representation:**
@@ -354,8 +359,10 @@ function findMaxRectangleArea(hist):
* We subtract 1 from the product of `nearest_smaller_right[i]` and `nearest_smaller_left[i]` to account for the width of the rectangle.
---
-### Problem 3 Sum of (Max-Min) of all subarrays
+## Problem 3 Sum of (Max-Min) of all subarrays
+
+### Question
Giver an integer array with distinct integers, for all subarrays find (max-min) and return its sum as the answer.
@@ -377,10 +384,6 @@ The goal is to find the sum of the differences between the maximum and minimum e
The sum of all differences is 0 + 0 + 0 + 3 + 2 + 3 = 8.
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
### Sum of (Max-Min) of all subarrays Brute force approach
**Brute-Force Approach Pseudo Code:**
@@ -407,24 +410,26 @@ function sumOfDifferences(arr):
return result
```
-#### Complexity
-**Time Complexity:** O(N * N)
+### Complexity
+**Time Complexity:** O(N^3^)
**Space Complexity:** O(1)
---
+
+
### Question
Giver an integer array, A with distinct integers, for all subarrays find (max-min) and return its sum as the answer.
A = [1, 2, 3]
-**Choices**
+### Choices
- [x] 4
- [ ] 6
- [ ] 5
- [ ] 0
-#### Explanation:
+### Explanation:
The goal is to find the sum of the differences between the maximum and minimum elements for all possible subarrays.
@@ -444,63 +449,105 @@ The sum of all differences is 0 + 0 + 0 + 1 + 1 + 2 = 4.
---
-### Sum of (Max-Min) of all subarrays Optimized approach
+## Sum of (Max-Min) of all subarrays Optimized approach
+
-#### Optimized Approach
+### Optimized Approach
**Intuition:**
-* The contribution technique eliminates redundant calculations by efficiently counting the number of subarrays in which each element can be the maximum or minimum element.
-* By tracking the elements that are greater or smaller than the current element in both directions, we can calculate their contributions to the sum of (max - min) differences without repeatedly considering the same subarrays.
+1. Calculate the contribution of each element being the maximum
+2. Calculate the contribution of each element being the minimum
+3. Calculate the total contribution : contribution = element × (count as max − count as min)
-**Optimized Approach Pseudo code:**
+### Contribution idea
+Let's take example **A** = $[1, 2, 3]$
+
+Now compute the 4 things for each element:
+1. Previous Greater element's index (default value -1)
+2. Next Greater element's index (default value n)
+3. Previous Smaller element's index (default value -1)
+4. Next Smaller element's index (default value n)
+
+| index | prvGreater | nxtGreater | prvSmaller | nxtSmaller |
+|:-----:|:----------:|:----------:|:----------:|:----------:|
+| 0 | -1 | 1 | -1 | 3 |
+| 1 | -1 | 2 | 0 | 3 |
+| 2 | -1 | 3 | 1 | 3 |
-```cpp
-function sumOfDifferences(arr):
- n = length of arr
- left = new array of size n
- right = new array of size n
- max_stack = empty stack
- min_stack = empty stack
- result = 0
- // Initialize left and right arrays
- for i from 0 to n - 1:
- left[i] = (i + 1) * (n - i)
- right[i] = (i + 1) * (i + 1)
+**Contributions :**
- // Calculate left contributions
- for i from 0 to n - 1:
- while (not max_stack.isEmpty() and arr[i] > arr[max_stack.top()]):
- max_stack.pop()
+1. Contribution as Min = $(nxtSmaller - i) * (i - prvSmaller)$
+2. Similarly Contribution as Max = $(nxtGreater - i) * (i - prvGreater)$
+3. Total contribution = (contribution as max - contribution as min)
- if (max_stack.isEmpty()):
- left[i] = (i + 1) * (i + 1)
- else:
- left[i] = (i - max_stack.top()) * (i + 1)
+| index | contribution as Min | contribution as Max | Total Contribution |
+|:-----:|:-------------------:|:-------------------:| ------------------ |
+| 0 | 3 | 1 | -2 |
+| 1 | 2 | 2 | 0 |
+| 2 | 1 | 3 | 2 |
- max_stack.push(i)
+Hence Total Contribution = $A[0] * (-2) + A[1] * (0) + A[2] * (2)$
+= $-2 + 0 + 6$ = $4$
- // Calculate right contributions
- for i from n - 1 to 0:
- while (not min_stack.isEmpty() and arr[i] < arr[min_stack.top()]):
- min_stack.pop()
+**Optimized Approach Pseudo code:**
- if (min_stack.isEmpty()):
- right[i] = (n - i) * (n - i)
- else:
- right[i] = (min_stack.top() - i) * (n - i)
+```cpp
+function subarrayRanges(A):
+ n = size(A)
+ nextGreater = array of size n, initialized to n
+ prevGreater = array of size n, initialized to -1
+ nextSmaller = array of size n, initialized to n
+ prevSmaller = array of size n, initialized to -1
+
+ stack = empty stack
+
+ // Find next greater elements
+ for i from 0 to n-1:
+ while stack is not empty and A[stack.top()] < A[i]:
+ nextGreater[stack.top()] = i
+ stack.pop()
+ stack.push(i)
+
+ clear stack
+
+ // Find previous greater elements
+ for i from n-1 to 0:
+ while stack is not empty and A[stack.top()] <= A[i]:
+ prevGreater[stack.top()] = i
+ stack.pop()
+ stack.push(i)
+
+ clear stack
+
+ // Find next smaller elements
+ for i from 0 to n-1:
+ while stack is not empty and A[stack.top()] > A[i]:
+ nextSmaller[stack.top()] = i
+ stack.pop()
+ stack.push(i)
+
+ clear stack
+
+ // Find previous smaller elements
+ for i from n-1 to 0:
+ while stack is not empty and A[stack.top()] >= A[i]:
+ prevSmaller[stack.top()] = i
+ stack.pop()
+ stack.push(i)
- min_stack.push(i)
+ result = 0
- // Calculate the sum of (max - min) differences
- for i from 0 to n - 1:
- contribution = (right[i] * left[i]) * arr[i]
- result += contribution
+ // Calculate the result based on the contributions
+ for i from 0 to n-1:
+ maxContribution = (i - prevGreater[i]) * (nextGreater[i] - i)
+ minContribution = (i - prevSmaller[i]) * (nextSmaller[i] - i)
+ result += A[i] * (maxContribution - minContribution)
return result
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Topological Sort & Interview Problems.md b/Academy DSA Typed Notes/Advanced/DSA Topological Sort & Interview Problems.md
new file mode 100644
index 0000000..e5bcfdd
--- /dev/null
+++ b/Academy DSA Typed Notes/Advanced/DSA Topological Sort & Interview Problems.md
@@ -0,0 +1,414 @@
+
+# DSA: Topological Sort & Interview Problems
+
+## Possibility of finishing the courses
+
+Given N courses with pre-requisites, we have to check if it is possible to finish all the course ?
+
+### Example:
+
+N = 5
+
+**Pre-requisites**
+1 ---> 2 & 3 [1 is pre-req for 2 and 3]
+2 ---> 3 & 5
+3 ---> 4
+4 ---> 2
+
+ +
+The pre-req information is represented in above directed graph.
+
+
+### Explanantion:
+
+**Que:** Which course shall we complete first?
+The one having no pre-requisites. (say 1)
+
+
+
+The pre-req information is represented in above directed graph.
+
+
+### Explanantion:
+
+**Que:** Which course shall we complete first?
+The one having no pre-requisites. (say 1)
+
+ +
+Next, which one shall we pick ?
+
+We can't pick any course because of the dependencies. Hence, it means we can't finish courses in above example.
+
+The reason is there's a cycle!
+Have you heard of the term deadlock ? [*For experience we need job, for job we need experience like scenario :p* ]
+
+**Conclusion:** If it's a cyclic graph, answer will always be false, else true.
+
+**Observation:** To solve the problem, we need directed acyclic graph!
+
+### Possibility of finishing courses approach
+
+**Example:**
+
+
+
+Next, which one shall we pick ?
+
+We can't pick any course because of the dependencies. Hence, it means we can't finish courses in above example.
+
+The reason is there's a cycle!
+Have you heard of the term deadlock ? [*For experience we need job, for job we need experience like scenario :p* ]
+
+**Conclusion:** If it's a cyclic graph, answer will always be false, else true.
+
+**Observation:** To solve the problem, we need directed acyclic graph!
+
+### Possibility of finishing courses approach
+
+**Example:**
+
+ +
+Pick ? 1 [not dependant on any other course]
+Next Pick ? 2
+Next Pick ? 3
+Next Pick ? 4
+Next Pick ? 5
+
+**Order:**
+1 2 3 4 5
+
+The above order is known as topological sort/ topological order.
+
+**Que:** For one graph, can we have only one topological order?
+
+
+
+Pick ? 1 [not dependant on any other course]
+Next Pick ? 2
+Next Pick ? 3
+Next Pick ? 4
+Next Pick ? 5
+
+**Order:**
+1 2 3 4 5
+
+The above order is known as topological sort/ topological order.
+
+**Que:** For one graph, can we have only one topological order?
+
+ +
+Is the order 1 2 3 4 5 valid ? YES!
+What about 1 3 2 4 5 ? YES!
+What about 1 3 4 2 5 ? YES!
+
+Hence, it is possible that we have multiple topological order for a given graph.
+
+### Definition
+
+**Topological sort** is a linear ordering of the vertices (nodes) in a directed acyclic graph (DAG) such that for every directed edge (u, v), vertex u comes before vertex v in the ordering. In other words, it arranges the nodes in such a way that if there is a directed edge from node A to node B, then node A comes before node B in the sorted order.
+
+### Topological Sort
+
+Let's find topological ordering of below graph!
+
+
+
+Is the order 1 2 3 4 5 valid ? YES!
+What about 1 3 2 4 5 ? YES!
+What about 1 3 4 2 5 ? YES!
+
+Hence, it is possible that we have multiple topological order for a given graph.
+
+### Definition
+
+**Topological sort** is a linear ordering of the vertices (nodes) in a directed acyclic graph (DAG) such that for every directed edge (u, v), vertex u comes before vertex v in the ordering. In other words, it arranges the nodes in such a way that if there is a directed edge from node A to node B, then node A comes before node B in the sorted order.
+
+### Topological Sort
+
+Let's find topological ordering of below graph!
+
+ +
+**Indegree:** The count of incoming nodes is known as indegree of a node.
+
+For above graph, the indegrees will be as follows -
+
+
+
+**Indegree:** The count of incoming nodes is known as indegree of a node.
+
+For above graph, the indegrees will be as follows -
+
+ +
+### Next Steps
+* Insert all the nodes with indegree=0 in a queue
+* Dequeue an element from the queue and update the indegree for all the neighbours, if the indegree for any nbr becomes 0 add that node in the queue.
+
+
+
+### Approach:
+* Create an array to store indegrees, initially set all values to zero.
+* Iterate through each node in the graph using a loop.
+* For each node, traverse its outgoing edges by iterating through its adjacency list.
+* For each neighboring node in the adjacency list, increment its indegree count by one.
+* Continue the loop until you've processed all nodes in the graph.
+* The array now contains the indegree of each node, where the value at index i represents the indegree of node i.
+
+### Example:
+
+
+
+### Next Steps
+* Insert all the nodes with indegree=0 in a queue
+* Dequeue an element from the queue and update the indegree for all the neighbours, if the indegree for any nbr becomes 0 add that node in the queue.
+
+
+
+### Approach:
+* Create an array to store indegrees, initially set all values to zero.
+* Iterate through each node in the graph using a loop.
+* For each node, traverse its outgoing edges by iterating through its adjacency list.
+* For each neighboring node in the adjacency list, increment its indegree count by one.
+* Continue the loop until you've processed all nodes in the graph.
+* The array now contains the indegree of each node, where the value at index i represents the indegree of node i.
+
+### Example:
+
+ +
+In the above photo we can refer the indegree of each of the nodes is written in green.
+
+### Pseudocode:
+
+```java
+in_degree[N], i,
+for(i -> 0 to n - 1)
+ in_degree[i] = 0;
+
+for(i -> 0 to n - 1)
+{
+ for(each neighbour in adj[i])
+ {
+ in_degree[i] += 1;
+ }
+}
+```
+### Complexity
+**Time Complexity:** O(N + E)
+**Space Complexity:** O(N)
+
+## Topological Sort (Right to Left)
+### Topological Sort
+
+In a right-to-left topological order, you start from the "rightmost" vertex (i.e., a vertex with no outgoing edges) and proceed leftward. This approach can be useful in certain situations and can be thought of as a reverse topological ordering.
+
+Here's how you can approach it:
+
+### Approach:
+* Identify a vertex with no outgoing edges (in-degree = 0). If there are multiple such vertices, you can choose any of them.
+* Remove that vertex from the graph along with all its outgoing edges. This removal may affect the in-degrees of other vertices.
+* Repeat steps 1 and 2 until all vertices are removed from the graph. The order in which you remove the vertices constitutes the right-to-left topological order.
+
+### Example/Dry-Run:
+```java
+A -> B -> C
+| |
+v v
+D E
+```
+To find the right-to-left topological order:
+
+* Start with a vertex with no outgoing edges. In this case, you can start with vertex C.
+* Remove vertex C and its outgoing edge. The graph becomes:
+```java
+A -> B
+|
+v
+D E
+```
+Now, you can choose either B or E, both of which have no outgoing edges. Let's choose B and remove it:
+```java
+A
+|
+v
+D E
+```
+* Continue with the remaining vertices. Choose A next:
+```java
+|
+v
+D E
+```
+* Finally, remove D and E:
+```java
+|
+v
+| |
+```
+The order in which you removed the vertices is a right-to-left topological order: C, B, A, D, E.
+
+### Pseudocode
+```java
+function topologicalSortRightToLeft(graph):
+ // Function to perform DFS and record nodes in the order they are finished
+ function dfs(node):
+ mark node as visited
+ for each neighbor in graph[node]:
+ if neighbor is not visited:
+ dfs(neighbor)
+ append node to order list
+
+ create an empty order list
+ initialize a visited array with False for all nodes
+
+ for each node in the graph:
+ if node is not visited:
+ dfs(node)
+
+ reverse the order list
+
+ return the reversed order list as the topological order (right-to-left)
+```
+
+### Complexity
+**Time Complexity:** O(V+E)
+**Space Complexity:** O(V)
+
+---
+
+
+### Question
+Which of the following is correct topological order for this graph?
+
+
+
+In the above photo we can refer the indegree of each of the nodes is written in green.
+
+### Pseudocode:
+
+```java
+in_degree[N], i,
+for(i -> 0 to n - 1)
+ in_degree[i] = 0;
+
+for(i -> 0 to n - 1)
+{
+ for(each neighbour in adj[i])
+ {
+ in_degree[i] += 1;
+ }
+}
+```
+### Complexity
+**Time Complexity:** O(N + E)
+**Space Complexity:** O(N)
+
+## Topological Sort (Right to Left)
+### Topological Sort
+
+In a right-to-left topological order, you start from the "rightmost" vertex (i.e., a vertex with no outgoing edges) and proceed leftward. This approach can be useful in certain situations and can be thought of as a reverse topological ordering.
+
+Here's how you can approach it:
+
+### Approach:
+* Identify a vertex with no outgoing edges (in-degree = 0). If there are multiple such vertices, you can choose any of them.
+* Remove that vertex from the graph along with all its outgoing edges. This removal may affect the in-degrees of other vertices.
+* Repeat steps 1 and 2 until all vertices are removed from the graph. The order in which you remove the vertices constitutes the right-to-left topological order.
+
+### Example/Dry-Run:
+```java
+A -> B -> C
+| |
+v v
+D E
+```
+To find the right-to-left topological order:
+
+* Start with a vertex with no outgoing edges. In this case, you can start with vertex C.
+* Remove vertex C and its outgoing edge. The graph becomes:
+```java
+A -> B
+|
+v
+D E
+```
+Now, you can choose either B or E, both of which have no outgoing edges. Let's choose B and remove it:
+```java
+A
+|
+v
+D E
+```
+* Continue with the remaining vertices. Choose A next:
+```java
+|
+v
+D E
+```
+* Finally, remove D and E:
+```java
+|
+v
+| |
+```
+The order in which you removed the vertices is a right-to-left topological order: C, B, A, D, E.
+
+### Pseudocode
+```java
+function topologicalSortRightToLeft(graph):
+ // Function to perform DFS and record nodes in the order they are finished
+ function dfs(node):
+ mark node as visited
+ for each neighbor in graph[node]:
+ if neighbor is not visited:
+ dfs(neighbor)
+ append node to order list
+
+ create an empty order list
+ initialize a visited array with False for all nodes
+
+ for each node in the graph:
+ if node is not visited:
+ dfs(node)
+
+ reverse the order list
+
+ return the reversed order list as the topological order (right-to-left)
+```
+
+### Complexity
+**Time Complexity:** O(V+E)
+**Space Complexity:** O(V)
+
+---
+
+
+### Question
+Which of the following is correct topological order for this graph?
+
+ +
+### Choices
+- [x] TD,TA,TC,TB
+- [ ] TA,TD,TC,TB
+- [ ] TC,TA,TD,TB
+
+---
+
+to add
+
+---
+title: In-Degree of Node
+description:
+duration: 900
+card_type: cue_card
+---
+
+## Problem 2 Minimum Jumps to Reach End
+### Description:
+You are given a 0-indexed array of integers arr of length n. You are initially positioned at arr[0].
+
+Each element arr[i] represents the maximum length of a forward jump from index i. In other words, if you are at arr[i], you can jump to any arr[i + j] where:
+* 0 <= j <= arr[i]
+* i + j < n
+
+Return the minimum number of jumps to reach arr[n - 1]. The test cases are generated such that you can reach arr[n - 1].
+
+### Example
+#### Example 1
+**Input**: arr = [2,3,1,1,4]
+**Output**: 2
+**Explanation**: The minimum number of jumps to reach the last index is 2. Jump 1 step from index 0 to 1, then 3 steps to the last index.
+
+#### Example 2
+**Input**: arr = [2,3,0,1,4]
+**Output**: 2
+
+
+### Slower Approach
+
+- Initialize an array to store the minimum number of jumps required to reach each index in the input array.
+- Start with the assumption that the minimum number of jumps required to reach the first index is 0.
+- Iterate through each index of the array.
+- For each index i, iterate through all the indices before i.
+- Check if it's possible to reach index i from index j (where j < i) by ensuring the current index is within the reachable range of j.
+ - If it's possible to reach index i from index j, update the minimum number of jumps required to reach index i.
+- Once all indices are processed, the last element of the jumps array will hold the minimum number of jumps required to reach the end of the array.
+
+### Code
+```java
+
+function minJumps(arr[], n) {
+ // jumps[n-1] will hold the result
+ jumps[] = integer array of size n;
+
+ // if first element is 0, end cannot be reached
+ if (n == 0 || arr[0] == 0)
+ return infinity;
+
+ jumps[0] = 0;
+
+ // Find the minimum number of jumps to reach arr[i]
+ // from arr[0], and assign this value to jumps[i]
+ for (i -> 1 to n - 1) {
+ jumps[i] = infinity;
+ for (j -> 0 to i - 1) {
+ if (i <= j + arr[j] && jumps[j] != infinity) {
+ jumps[i] = min(jumps[i], jumps[j] + 1);
+ break;
+ }
+ }
+ }
+ return jumps[n - 1];
+}
+
+```
+
+### Complexity Analysis
+**Time complexity**: O(N$^2$)
+
+**Space complexity**: O(N$^2$)
+
+## Optimised Approach Minimum jumps to reach end
+
+### Observation
+How can we calculate for each index what's the farthest index we can jump to ? And can we do it in O(N) ?
+
+The answer is Yes !!
+
+### Optimized Approach
+1. **Preprocess the Array:**
+* We iterate through the array starting from the second element.
+* For each element $arr[i]$, we update it to be the maximum value between $arr[i] + i$ and $arr[i - 1]$.
+* $arr[i] + i$ represents the farthest index we can reach from index i using the value at $arr[i]$.
+* $arr[i - 1]$ represents the farthest index reachable from any of the previous indices.
+* This preprocessing step ensures that $arr[i]$ holds the farthest reachable index from the start up to the current index **i**.
+
+2. **Calculate the Minimum Jumps:**
+While currentIndex is not at the last index (n - 1), we perform the following:
+* Increment the jumps counter as we are making a jump.
+* Update currentIndex to the value of $arr[currentIndex]$, which represents the farthest index we can reach from currentIndex.
+* This loop continues until we reach or pass the last index of the array.
+
+### Pseudocode
+```java
+function jump(arr, n) {
+ if (n <= 1) return 0;
+
+ for (i -> 1 to n - 1) {
+ arr[i] = max(arr[i] + i, arr[i - 1]);
+ }
+
+ currentIndex = 0;
+ jumps = 0;
+
+ while (currentIndex < n) {
+ ++jumps;
+ currentIndex = arr[currentIndex];
+ }
+
+ return jumps;
+}
+
+```
+
+### Complexity Analysis
+**Time complexity**: O(N)
+
+**Space complexity**: O(1)
+
+
+---
+## Problem 4 Maximum Profit from Stock Prices
+
+### Problem Statement
+Given an array A where the i-th element represents the price of a stock on day i, the objective is to find the maximum profit. We're allowed to complete as many transactions as desired, but engaging in multiple transactions simultaneously is not allowed.
+
+### Approach
+Let's start with some key observations:
+
+**Note 1**: It's never beneficial to buy a stock and sell it at a loss. This intuitive insight guides our decision-making process.
+
+**Note 2**: If the stock price on day i is less than the price on day i+1, it's always advantageous to buy on day i and sell on day i+1.
+
+Now, let's delve into the rationale behind Note 2:
+
+**Proof**: If the price on day i+1 is higher than the price on day i, buying on day i and selling on day i+1 ensures a profit. If we didn't sell on day i+1 and waited for day i+2 to sell, the profit would still be the same. Thus, it's optimal to sell whenever there's a price increase.
+
+### DP-Based Solution
+Now, let's transition to a dynamic programming solution based on the following recurrence relation:
+
+Let Dp[i] represent the maximum profit you can gain in the region (i, i+1, ..., n).
+
+**Recurrence Relation**: `Dp[i] = max(Dp[i+1], -A[i] + max(A[j] + Dp[j] for j > i))`
+
+Here, Dp[i] considers either continuing with the profit from the next day (Dp[i+1]) or selling on day i and adding the profit from subsequent days.
+
+#### Base Cases
+
+When i is the last day (i == n-1), Dp[i] = 0 since there are no more future days.
+When i is not the last day, Dp[i] needs to be computed using the recurrence relation.
+
+#### Direction of Computation
+
+We start computing Dp[i] from the last day and move towards the first day.
+
+#### Code
+```cpp
+function max_profit(list A) {
+ n = A.size;
+ declare dp array of size n filled with 0;
+
+ for (i -> n - 2 down to 0) {
+ dp[i] = dp[i + 1];
+
+ for (j -> i + 1 to n - 1) {
+ if (j + 1 < n) {
+ dp[i] = max(dp[i], -A[i] + A[j] + dp[j + 1]);
+ } else {
+ dp[i] = max(dp[i], -A[i] + A[j]);
+ }
+ }
+ }
+
+ return dp[0];
+}
+```
+
+
+### Optimized Code
+The provided code snippet in C++ contains this observation-based solution. It iterates through the array, checks for price increases, and accumulates the profits accordingly.
+```cpp
+function maxProfit(list A) {
+ total = 0, sz = A.size;
+
+ for (i -> 0 to sz - 2) {
+ if (A[i + 1] > A[i])
+ total += A[i + 1] - A[i];
+ }
+ return total;
+}
+```
+
+**Time Complexity** : O(|A|)
+**Space Complexity** : O(1)
+
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md b/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md
index 2e1c599..1f5bc47 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md
@@ -1,7 +1,33 @@
# Trees 1: Structure & Traversal
+## Revision Quizzes
+
+### Question
+Which of the following scenarios is an example of a queue?
+
+
+### Choices
+
+- [ ] A stack of books
+- [ ] Undo operation in a text editor
+- [x] People standing in line at a ticket counter
+- [ ] A recursive function call stack
+
+---
+
+
+### Question
+Which of the following is a more efficient strategy for implementing a queue using a linked list?
+
+### Choices
+- [ ] Insert at head and delete at head.
+- [ ] Insert at head and delete at tail.
+- [ ] Insert and delete at tail.
+- [x] Insert at tail and delete at head.
+
---
-## What is a tree
+
+## What is a tree?
Till now, we have seen data structures such as Arrays, Linked Lists, Stacks, Queues... They are **Linear Data Structure** which means we can access them in sequencial order.
@@ -46,9 +72,9 @@ CEO (Chief Executive Officer)
As we know that every tree has roots which are below the leaves but in the computer science the case is different the roots are at the top and leaves below it.
---
-## Tree naming
+### Tree naming
-Example
+### Example
```sql
1
/ \
@@ -60,7 +86,7 @@ Example
```
* **Node**: An element in a tree that contains data and may have child nodes connected to it. 1, 2, 3, 4, 5, 6, 7, 8.
-
+
+### Choices
+- [x] TD,TA,TC,TB
+- [ ] TA,TD,TC,TB
+- [ ] TC,TA,TD,TB
+
+---
+
+to add
+
+---
+title: In-Degree of Node
+description:
+duration: 900
+card_type: cue_card
+---
+
+## Problem 2 Minimum Jumps to Reach End
+### Description:
+You are given a 0-indexed array of integers arr of length n. You are initially positioned at arr[0].
+
+Each element arr[i] represents the maximum length of a forward jump from index i. In other words, if you are at arr[i], you can jump to any arr[i + j] where:
+* 0 <= j <= arr[i]
+* i + j < n
+
+Return the minimum number of jumps to reach arr[n - 1]. The test cases are generated such that you can reach arr[n - 1].
+
+### Example
+#### Example 1
+**Input**: arr = [2,3,1,1,4]
+**Output**: 2
+**Explanation**: The minimum number of jumps to reach the last index is 2. Jump 1 step from index 0 to 1, then 3 steps to the last index.
+
+#### Example 2
+**Input**: arr = [2,3,0,1,4]
+**Output**: 2
+
+
+### Slower Approach
+
+- Initialize an array to store the minimum number of jumps required to reach each index in the input array.
+- Start with the assumption that the minimum number of jumps required to reach the first index is 0.
+- Iterate through each index of the array.
+- For each index i, iterate through all the indices before i.
+- Check if it's possible to reach index i from index j (where j < i) by ensuring the current index is within the reachable range of j.
+ - If it's possible to reach index i from index j, update the minimum number of jumps required to reach index i.
+- Once all indices are processed, the last element of the jumps array will hold the minimum number of jumps required to reach the end of the array.
+
+### Code
+```java
+
+function minJumps(arr[], n) {
+ // jumps[n-1] will hold the result
+ jumps[] = integer array of size n;
+
+ // if first element is 0, end cannot be reached
+ if (n == 0 || arr[0] == 0)
+ return infinity;
+
+ jumps[0] = 0;
+
+ // Find the minimum number of jumps to reach arr[i]
+ // from arr[0], and assign this value to jumps[i]
+ for (i -> 1 to n - 1) {
+ jumps[i] = infinity;
+ for (j -> 0 to i - 1) {
+ if (i <= j + arr[j] && jumps[j] != infinity) {
+ jumps[i] = min(jumps[i], jumps[j] + 1);
+ break;
+ }
+ }
+ }
+ return jumps[n - 1];
+}
+
+```
+
+### Complexity Analysis
+**Time complexity**: O(N$^2$)
+
+**Space complexity**: O(N$^2$)
+
+## Optimised Approach Minimum jumps to reach end
+
+### Observation
+How can we calculate for each index what's the farthest index we can jump to ? And can we do it in O(N) ?
+
+The answer is Yes !!
+
+### Optimized Approach
+1. **Preprocess the Array:**
+* We iterate through the array starting from the second element.
+* For each element $arr[i]$, we update it to be the maximum value between $arr[i] + i$ and $arr[i - 1]$.
+* $arr[i] + i$ represents the farthest index we can reach from index i using the value at $arr[i]$.
+* $arr[i - 1]$ represents the farthest index reachable from any of the previous indices.
+* This preprocessing step ensures that $arr[i]$ holds the farthest reachable index from the start up to the current index **i**.
+
+2. **Calculate the Minimum Jumps:**
+While currentIndex is not at the last index (n - 1), we perform the following:
+* Increment the jumps counter as we are making a jump.
+* Update currentIndex to the value of $arr[currentIndex]$, which represents the farthest index we can reach from currentIndex.
+* This loop continues until we reach or pass the last index of the array.
+
+### Pseudocode
+```java
+function jump(arr, n) {
+ if (n <= 1) return 0;
+
+ for (i -> 1 to n - 1) {
+ arr[i] = max(arr[i] + i, arr[i - 1]);
+ }
+
+ currentIndex = 0;
+ jumps = 0;
+
+ while (currentIndex < n) {
+ ++jumps;
+ currentIndex = arr[currentIndex];
+ }
+
+ return jumps;
+}
+
+```
+
+### Complexity Analysis
+**Time complexity**: O(N)
+
+**Space complexity**: O(1)
+
+
+---
+## Problem 4 Maximum Profit from Stock Prices
+
+### Problem Statement
+Given an array A where the i-th element represents the price of a stock on day i, the objective is to find the maximum profit. We're allowed to complete as many transactions as desired, but engaging in multiple transactions simultaneously is not allowed.
+
+### Approach
+Let's start with some key observations:
+
+**Note 1**: It's never beneficial to buy a stock and sell it at a loss. This intuitive insight guides our decision-making process.
+
+**Note 2**: If the stock price on day i is less than the price on day i+1, it's always advantageous to buy on day i and sell on day i+1.
+
+Now, let's delve into the rationale behind Note 2:
+
+**Proof**: If the price on day i+1 is higher than the price on day i, buying on day i and selling on day i+1 ensures a profit. If we didn't sell on day i+1 and waited for day i+2 to sell, the profit would still be the same. Thus, it's optimal to sell whenever there's a price increase.
+
+### DP-Based Solution
+Now, let's transition to a dynamic programming solution based on the following recurrence relation:
+
+Let Dp[i] represent the maximum profit you can gain in the region (i, i+1, ..., n).
+
+**Recurrence Relation**: `Dp[i] = max(Dp[i+1], -A[i] + max(A[j] + Dp[j] for j > i))`
+
+Here, Dp[i] considers either continuing with the profit from the next day (Dp[i+1]) or selling on day i and adding the profit from subsequent days.
+
+#### Base Cases
+
+When i is the last day (i == n-1), Dp[i] = 0 since there are no more future days.
+When i is not the last day, Dp[i] needs to be computed using the recurrence relation.
+
+#### Direction of Computation
+
+We start computing Dp[i] from the last day and move towards the first day.
+
+#### Code
+```cpp
+function max_profit(list A) {
+ n = A.size;
+ declare dp array of size n filled with 0;
+
+ for (i -> n - 2 down to 0) {
+ dp[i] = dp[i + 1];
+
+ for (j -> i + 1 to n - 1) {
+ if (j + 1 < n) {
+ dp[i] = max(dp[i], -A[i] + A[j] + dp[j + 1]);
+ } else {
+ dp[i] = max(dp[i], -A[i] + A[j]);
+ }
+ }
+ }
+
+ return dp[0];
+}
+```
+
+
+### Optimized Code
+The provided code snippet in C++ contains this observation-based solution. It iterates through the array, checks for price increases, and accumulates the profits accordingly.
+```cpp
+function maxProfit(list A) {
+ total = 0, sz = A.size;
+
+ for (i -> 0 to sz - 2) {
+ if (A[i + 1] > A[i])
+ total += A[i + 1] - A[i];
+ }
+ return total;
+}
+```
+
+**Time Complexity** : O(|A|)
+**Space Complexity** : O(1)
+
+
+---
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md b/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md
index 2e1c599..1f5bc47 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 1 Structure & Traversal.md
@@ -1,7 +1,33 @@
# Trees 1: Structure & Traversal
+## Revision Quizzes
+
+### Question
+Which of the following scenarios is an example of a queue?
+
+
+### Choices
+
+- [ ] A stack of books
+- [ ] Undo operation in a text editor
+- [x] People standing in line at a ticket counter
+- [ ] A recursive function call stack
+
+---
+
+
+### Question
+Which of the following is a more efficient strategy for implementing a queue using a linked list?
+
+### Choices
+- [ ] Insert at head and delete at head.
+- [ ] Insert at head and delete at tail.
+- [ ] Insert and delete at tail.
+- [x] Insert at tail and delete at head.
+
---
-## What is a tree
+
+## What is a tree?
Till now, we have seen data structures such as Arrays, Linked Lists, Stacks, Queues... They are **Linear Data Structure** which means we can access them in sequencial order.
@@ -46,9 +72,9 @@ CEO (Chief Executive Officer)
As we know that every tree has roots which are below the leaves but in the computer science the case is different the roots are at the top and leaves below it.
---
-## Tree naming
+### Tree naming
-Example
+### Example
```sql
1
/ \
@@ -60,7 +86,7 @@ Example
```
* **Node**: An element in a tree that contains data and may have child nodes connected to it. 1, 2, 3, 4, 5, 6, 7, 8.
- +
+) * **Root**:
* **Root**:The topmost node in a tree from which all other nodes descend. It has no parent. Node 1 is the root. @@ -76,38 +102,43 @@ Example --- + + ### Question Can a leaf node also be a subtree? -**Choices** +### Choices - [x] YES - [ ] NO - [ ] Can't say - -**Explanation:** +### Explanation: Yes, a leaf node can also be considered a subtree. A subtree is a portion of a tree structure that is itself a tree. --- + + ### Question Do all nodes have a parent node? -**Choices** +### Choices - [ ] YES - [x] NO - [ ] Can't say -**Explanation:** + +### Explanation: In a tree data structure, all nodes except for the root node have a parent node. --- -### Levels of a tree +### Levels of a Tree + ```sql 1 Level 0 / \ @@ -122,18 +153,20 @@ In this example: * **Level 2:** Nodes 4 and 5 are at level 2. --- + + ### Question What is the height of the leaf node in any tree? -**Choices** +### Choices - [x] 0 - [ ] 1 - [ ] 2 - [ ] 3 -**Explanation** +### Explanation The height of a leaf node in any tree, including a binary tree, is 0. This is because the height of a node is defined as the length of the longest path from that node to a leaf node, and a leaf node is a node that doesn't have any children. Since there are no edges to traverse from a leaf node to a leaf node, the length of the path is 0. @@ -153,7 +186,8 @@ A type of tree in which each node can have at most two children i.e, either 0, 1 ``` --- -### Traversals in a Tree +## Traversals in a Tree + ### How can we traverse a Tree ? @@ -180,7 +214,7 @@ Names are given w.r.t the position of the root node. > There are more techniques for traversing a tree that'll be covered in next set of sessions. -#### Pre-order +### Pre-order Pre-order traversal is a depth-first traversal technique used to visit all nodes of a binary tree in a specific order. In pre-order traversal, you start from the root node and follow these steps for each node: 1. Visit the current node. 2. Traverse the left subtree (recursively). @@ -188,7 +222,7 @@ Pre-order traversal is a depth-first traversal technique used to visit all nodes **This traversal order ensures that the root node is visited before its children and the left subtree is explored before the right subtree.** -**Example:** +### Example: ```sql 10 / \ @@ -198,18 +232,19 @@ Pre-order traversal is a depth-first traversal technique used to visit all nodes ``` Pre-order traversal sequence: 10, 5, 3, 8, 15, 12, 18 -#### Pseudocode +### Pseudocode ```cpp -void preorder(root) { - if (root == null) +function preorder(root) +{ + if(root == null) return; - - print(root.data); //node - preorder(root.left); //left - preorder(root.right) //right + + print(root.data);//node + preorder(root.left);//left + preorder(root.right)//right } ``` -#### In-order traversal +### In-order traversal In-order traversal is another depth-first traversal technique used to visit all nodes of a binary tree, but in a specific order. In in-order traversal, you follow these steps for each node: 1. Traverse the left subtree (recursively). @@ -228,18 +263,19 @@ Here's an example of in-order traversal on a binary tree: ``` In-order traversal sequence: 3, 5, 8, 10, 12, 15, 18 -#### Pseudocode +### Pseudocode ```cpp -void inorder(root) { - if (root == null) +function inorder(root) +{ + if(root == null) return; - - inorder(root.left); //left - print(root.data); //node - inorder(root.right) //right + + inorder(root.left);//left + print(root.data);//node + inorder(root.right)//right } ``` -#### Post-order Traversal +### Post-order Traversal Post-order traversal is another depth-first traversal technique used to visit all nodes of a binary tree, but in a specific order. In post-order traversal, you follow these steps for each node: 1. Traverse the left subtree (recursively). @@ -248,7 +284,7 @@ Post-order traversal is another depth-first traversal technique used to visit al **This traversal order ensures that nodes are visited from the bottom up, starting from the leaf nodes and moving towards the root node.** -**Example** +### Example ```cpp 10 / \ @@ -258,10 +294,11 @@ Post-order traversal is another depth-first traversal technique used to visit al ``` Post-order traversal sequence: 3, 8, 5, 12, 18, 15, 10 -#### Pseudocode: +### Pseudocode: ```cpp -void postorder(root) { - if (root = null) return; +function postorder(root) +{ + if(root = null ) return; postorder(root.left) left postorder(root.right) right print(root.data) Node @@ -269,6 +306,8 @@ void postorder(root) { ``` --- + + ### Question What is the inorder traversal sequence of the below tree? ```cpp @@ -278,21 +317,22 @@ What is the inorder traversal sequence of the below tree? / / \ 3 5 6 ``` -**Choices** +### Choices - [ ] [1, 2, 3, 4, 5, 6] - [x] [3, 2, 1, 5, 4, 6] - [ ] [3, 2, 1, 4, 5, 6] - [ ] [4, 5, 6, 1, 2, 3] - -**Explanation** +### Explanation The inorder traversal sequence is [3, 2, 1, 5, 4, 6]. + --- -### Iterative Inorder traversal +## Iterative Inorder traversal + ### Approach: @@ -308,7 +348,7 @@ Let's say we have the following binary tree as an example: / \ 4 5 ``` -#### Dry-Run: +### Dry-Run: * Start at the root node (1). * Push 1 onto the stack and move left to node 2. * Push 2 onto the stack and move left to node 4. @@ -320,202 +360,231 @@ Let's say we have the following binary tree as an example: * The stack is empty, and all nodes have been visited. * So, the iterative Inorder traversal of the tree is 4, 2, 5, 1, 3. -#### Need of recursion/stack: +### Need of recursion/stack: In inorder traversal of a binary tree, you need a data structure like a stack or recursion because you need to keep track of the order in which you visit the nodes of the tree. The reason for using these techniques is to handle the backtracking that's inherent in traversing a binary tree in inorder fashion. In a binary tree's inorder traversal, you visit nodes in a specific order: left, current, right. You use a stack or recursion to remember where you left off in the tree when moving between nodes, ensuring you visit nodes in the correct order and navigate through the tree efficiently. This backtracking is essential for proper traversal. -#### Pseudocode: +### Pseudocode: ```cpp cur = root; -while (cur != null || st.isempty()) { - if (cur != null) { +while(cur != null || st.isempty()) +{ + if(cur != null) + { st.push(curr) cur = cur.left; - } else { + } + else{ cur = st.pop(); print(cur.data) cur = cur.right } } ``` +* **TC -** O(N) +* **SC -** O(N) -#### Complexity -**Time Complexity:** O(N) -**Space Complexity:** O(N) --- +## Equal Tree Partition -### Construct binary tree from inorder and post order - -Constructing a binary tree from its inorder and postorder traversals involves a recursive process. Here's a brief explanation with an example: - +### Problem Statement : +Given the root of a binary tree, return ***true*** if the tree can be split into two non-empty subtrees with equal sums, or ***false*** otherwise. +### Example 1 +```cpp +Input: + 5 + / \ + 3 7 + / \ / \ + 4 2 6 1 -#### Brute-Force Approach - +Output: True +``` +### Explanation: -* Generate all possible permutations of the given inorder traversal. -* For each permutation, check if it forms a valid binary tree when combined with the given postorder traversal. -* Return the first valid binary tree found. +```cpp +Part 1 :- + + 5 + / + 3 + / \ +4 2 -**Example:** -Inorder: [4, 2, 7, 5, 1, 3, 6] -Postorder: [4, 7, 5, 2, 6, 3, 1] +Sum: 14 +``` -#### Dry-Run: -* Identify the root: In the postorder traversal, the last element is 1, which is the root of the binary tree. -* Split into left and right subtrees: In the inorder traversal, find the position of the root element (1). Elements to the left of this position represent the left subtree, and elements to the right represent the right subtree. -* Recurse on left subtree: For the left subtree, the root is 2 (found in postorder traversal). Split the left subtree's inorder and postorder traversals, and repeat the process. -* Recurse on right subtree: For the right subtree, the root is 3 (found in postorder traversal). Split the right subtree's inorder and postorder traversals, and repeat the process. -* Continue the recursion: Repeat steps 3 and 4 for each subtree until the entire binary tree is constructed. +```cpp +Part 2 :- + 7 + / \ + 6 1 -#### Pseudocode: +Sum: 14 +``` +### Example 2 ```cpp -function buildTreeBruteForce(inorder, postorder): - for each permutation of inorder: - if formsValidBinaryTree(permutation, postorder): - return constructBinaryTree(permutation, postorder) - return null +Input: + 5 + / \ + 8 9 + / \ + 2 3 + +Output: false ``` +### Explanation: +There is no way to split the course into two parts with equal sums. -#### Complexity -**Time Complexity:** O(N! * N) -**Space Complexity:** O(N) --- -:::warning -Please take some time to think about the optimised approach on your own before reading further..... -::: -### Most-Optimised Approach: +### Question +Check whether the given tree can be split into two non-empty subtrees with equal sums or not. -* The last element in the postorder traversal is the root of the binary tree. -* Find the root element in the inorder traversal to determine the left and right subtrees. -* Recursively repeat the process for the left and right subtrees. +```cpp + 5 + / \ + 10 10 + / \ + 20 3 + / + 8 +``` + +### Choices +- [x] Yes, It is possible. +- [ ] It is impossible. -
 -Now as we can see in the above image let us understand this with the help of a dry/run:
+### Explanation:
-#### Dry-Run/Example:
-inorder={4,2,7,5,1,3,6} and postorder={4,7,5,2,6,3,1}
+Yes It is possible to split the tree into two non-empty subtrees with sum 28.
-1. The last element in the postorder traversal is 1, which is the root of the binary tree.
+Sub-Tree 1:
+```cpp
+ 5
+ / \
+ 10 10
+ \
+ 3
-Binary Tree:
-```plaintext
-1
```
-2. Find 1 in the inorder traversal to split it into left and right subtrees. The elements to the left are the left subtree, and the elements to the right are the right subtree.
+Sub-Tree 2:
```cpp
-Inorder: [4,2,7,5,1,3,6]
-Postorder: [4,7,5,2,6,3,1]
+ 20
+ /
+ 8
```
-Left Subtree (Inorder: [4,2,7,5], Postorder: [4,7,5,2]):
-```cpp
- 1
- /
-2
- \
- 5
- / \
-4 7
-```
-Right Subtree (Inorder: [3,6], Postorder: [6,3]):
+---
+## Equal Tree Partition Solution
-```cpp
-6
- \
- 3
-```
-3. Repeat the process for the left and right subtrees:
-For the left subtree:
-* The last element in the postorder traversal is 2, which is the root of the left subtree.
-* Find 2 in the inorder traversal to split it into left and right subtrees.
-* Left Subtree (Inorder: [4], Postorder: [4]):
-```cpp
- 2
- /
-4
-```
-Right Subtree (Inorder: [7,5], Postorder: [7,5]):
-```cpp
- 5
- /
-7
-```
-For the right subtree:
+### Solution
-* The last element in the postorder traversal is 3, which is the root of the right subtree.
-* Find 3 in the inorder traversal to split it into left and right subtrees.
-* Left Subtree (Inorder: [6], Postorder: [6]):
-```cpp
- 3
- \
- 6
-```
+1. **Total Sum Check**:
+If the total sum of all nodes in the binary tree is odd, it is impossible to divide the tree into two subtrees with equal sums. This is because the sum of two equal values is always even, and if the total sum is odd, it cannot be divided equally into two parts.
+2. **Subtree Sum Check**:
+If we can find a subtree in the binary tree with a sum equal to half of the total sum, we can split the tree into two equal partitions by removing the edge leading to the root of that subtree. This means that we don't necessarily need to compare sums of all possible subtrees, but we can look for a single subtree that meets the subtree sum check condition.
-The final binary tree would look like this:
+### Pseudocode
```cpp
- 1
- / \
- 2 3
- / \ \
- 4 5 6
- /
- 7
-```
+function sum(TreeNode root) {
+ if (!root) {
+ return 0;
+ }
+ return sum(root.left) + sum(root.right) + root.val;
+}
----
-### Question
-The inorder traversal sequence `[4, 2, 5, 1, 6, 3]` and the postorder traversal sequence `[4, 5, 2, 6, 3, 1]`. What is the root of the binary tree?
+function hasSubtreeWithHalfSum(TreeNode root, int totalSum) {
+ if (!root) {
+ return false;
+ }
+
+ int leftSum = sum(root.left);
+ int rightSum = sum(root.right);
-**Choices**
-- [x] 1
-- [ ] 2
-- [ ] 3
-- [ ] 4
+ if ((leftSum == totalSum / 2 || rightSum == totalSum / 2) || hasSubtreeWithHalfSum(root.left, totalSum) || hasSubtreeWithHalfSum(root.right, totalSum)) {
+ return true;
+ }
+ return false;
+}
-**Explanation:**
+function isEqualTreePartition(TreeNode root) {
+ if (!root) {
+ return false; // An empty tree cannot be partitioned
+ }
+
+ int totalSum = sum(root);
-In postorder traversal, the last element is always the root of the tree, so here, 1 is the root.
+ if (totalSum % 2 == 1) {
+ return false; // If the total sum is odd, partition is not possible
+ }
+
+ return hasSubtreeWithHalfSum(root, totalSum);
+}
+```
+### Complexity
+**Time Complexity:** O(N)
+**Space Complexity:** O(H)
---
-### Construct binary tree Pseudocode
-#### Pseudocode:
-* rootIndex is the index of the root value in the inorder array.
-* rootIndex + 1 represents the start of the right subtree in the arrays.
-* end represents the end of the right subtree in the arrays.
-* start represents the start of the left subtree in the arrays.
-* rootIndex - 1 represents the end of the left subtree in the arrays.
-```cpp
-function buildTree(inorder, postorder):
- if postorder is empty:
- return null
+## Path Sum
+
+### Problem Statement
+Given a binary tree and an integer k, determine if there exists a root-to-leaf path in the tree such that adding up all the node values along the path equals k.
+
+Example:
+```cpp
+
+Input:
+ Binary Tree:
+ 5
+ / \
+ 4 8
+ / / \
+ 11 13 4
+ / \ \
+ 7 2 1
+
+ k = 22
+
+Output: true
+```
+Explanation:
- // The last element in postorder is the root of the current subtree
- rootValue = postorder.last
- root = new TreeNode(rootValue)
+In the given binary tree, there exists a root-to-leaf path 5 -> 4 -> 11 -> 2 with a sum of 5 + 4 + 11 + 2 = 22, which equals k. Therefore, the function should return true.
- // Find the index of the rootValue in inorder to split it into left and right subtrees
- rootIndex = indexOf(inorder, rootValue)
+### Solution:
+* To solve this problem,we first check if the current node is a leaf node (having no left and right children) and if the current value equals k. If both conditions are met, it returns true, indicating that a valid path is found.
+* If not, it recursively checks the left and right subtrees with a reduced sum (k - root->val).
+* It returns true if there's a path in either the left or right subtree, indicating that a valid path is found.
- // Recursive call for right subtree
- root.right = buildTree(subarray(inorder, rootIndex + 1, end), subarray(postorder, rootIndex, end - 1))
-
- // Recursive call for left subtree
- root.left = buildTree(subarray(inorder, start, rootIndex - 1), subarray(postorder, start, rootIndex - 1))
- return root
+### Pseudocode
+```cpp
+function hasPathSum(Node root, k) {
+ if (!root) {
+ return false; // No path if the tree is empty
+ }
+
+ if (!root.left and !root.right) {
+ return (k == root.val);
+ }
+
+ return hasPathSum(root.left, k - root.val) || hasPathSum(root.right, k - root.val);
+}
+
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+**Space Complexity:** O(H)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md b/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md
index 2a5f69e..b580435 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md
@@ -1,12 +1,14 @@
# Advanced DSA : Trees 2: Views & Types
----
-## Level Order Traversal
+
+## Problem 1 Level order traversal
+
+### Level Order Traversal
Input: 1, 2, 3, 5, 8, 10, 13, 6, 9, 7, 4, 12, 11.
The diagram for the following nodes will be:
-
-Now as we can see in the above image let us understand this with the help of a dry/run:
+### Explanation:
-#### Dry-Run/Example:
-inorder={4,2,7,5,1,3,6} and postorder={4,7,5,2,6,3,1}
+Yes It is possible to split the tree into two non-empty subtrees with sum 28.
-1. The last element in the postorder traversal is 1, which is the root of the binary tree.
+Sub-Tree 1:
+```cpp
+ 5
+ / \
+ 10 10
+ \
+ 3
-Binary Tree:
-```plaintext
-1
```
-2. Find 1 in the inorder traversal to split it into left and right subtrees. The elements to the left are the left subtree, and the elements to the right are the right subtree.
+Sub-Tree 2:
```cpp
-Inorder: [4,2,7,5,1,3,6]
-Postorder: [4,7,5,2,6,3,1]
+ 20
+ /
+ 8
```
-Left Subtree (Inorder: [4,2,7,5], Postorder: [4,7,5,2]):
-```cpp
- 1
- /
-2
- \
- 5
- / \
-4 7
-```
-Right Subtree (Inorder: [3,6], Postorder: [6,3]):
+---
+## Equal Tree Partition Solution
-```cpp
-6
- \
- 3
-```
-3. Repeat the process for the left and right subtrees:
-For the left subtree:
-* The last element in the postorder traversal is 2, which is the root of the left subtree.
-* Find 2 in the inorder traversal to split it into left and right subtrees.
-* Left Subtree (Inorder: [4], Postorder: [4]):
-```cpp
- 2
- /
-4
-```
-Right Subtree (Inorder: [7,5], Postorder: [7,5]):
-```cpp
- 5
- /
-7
-```
-For the right subtree:
+### Solution
-* The last element in the postorder traversal is 3, which is the root of the right subtree.
-* Find 3 in the inorder traversal to split it into left and right subtrees.
-* Left Subtree (Inorder: [6], Postorder: [6]):
-```cpp
- 3
- \
- 6
-```
+1. **Total Sum Check**:
+If the total sum of all nodes in the binary tree is odd, it is impossible to divide the tree into two subtrees with equal sums. This is because the sum of two equal values is always even, and if the total sum is odd, it cannot be divided equally into two parts.
+2. **Subtree Sum Check**:
+If we can find a subtree in the binary tree with a sum equal to half of the total sum, we can split the tree into two equal partitions by removing the edge leading to the root of that subtree. This means that we don't necessarily need to compare sums of all possible subtrees, but we can look for a single subtree that meets the subtree sum check condition.
-The final binary tree would look like this:
+### Pseudocode
```cpp
- 1
- / \
- 2 3
- / \ \
- 4 5 6
- /
- 7
-```
+function sum(TreeNode root) {
+ if (!root) {
+ return 0;
+ }
+ return sum(root.left) + sum(root.right) + root.val;
+}
----
-### Question
-The inorder traversal sequence `[4, 2, 5, 1, 6, 3]` and the postorder traversal sequence `[4, 5, 2, 6, 3, 1]`. What is the root of the binary tree?
+function hasSubtreeWithHalfSum(TreeNode root, int totalSum) {
+ if (!root) {
+ return false;
+ }
+
+ int leftSum = sum(root.left);
+ int rightSum = sum(root.right);
-**Choices**
-- [x] 1
-- [ ] 2
-- [ ] 3
-- [ ] 4
+ if ((leftSum == totalSum / 2 || rightSum == totalSum / 2) || hasSubtreeWithHalfSum(root.left, totalSum) || hasSubtreeWithHalfSum(root.right, totalSum)) {
+ return true;
+ }
+ return false;
+}
-**Explanation:**
+function isEqualTreePartition(TreeNode root) {
+ if (!root) {
+ return false; // An empty tree cannot be partitioned
+ }
+
+ int totalSum = sum(root);
-In postorder traversal, the last element is always the root of the tree, so here, 1 is the root.
+ if (totalSum % 2 == 1) {
+ return false; // If the total sum is odd, partition is not possible
+ }
+
+ return hasSubtreeWithHalfSum(root, totalSum);
+}
+```
+### Complexity
+**Time Complexity:** O(N)
+**Space Complexity:** O(H)
---
-### Construct binary tree Pseudocode
-#### Pseudocode:
-* rootIndex is the index of the root value in the inorder array.
-* rootIndex + 1 represents the start of the right subtree in the arrays.
-* end represents the end of the right subtree in the arrays.
-* start represents the start of the left subtree in the arrays.
-* rootIndex - 1 represents the end of the left subtree in the arrays.
-```cpp
-function buildTree(inorder, postorder):
- if postorder is empty:
- return null
+## Path Sum
+
+### Problem Statement
+Given a binary tree and an integer k, determine if there exists a root-to-leaf path in the tree such that adding up all the node values along the path equals k.
+
+Example:
+```cpp
+
+Input:
+ Binary Tree:
+ 5
+ / \
+ 4 8
+ / / \
+ 11 13 4
+ / \ \
+ 7 2 1
+
+ k = 22
+
+Output: true
+```
+Explanation:
- // The last element in postorder is the root of the current subtree
- rootValue = postorder.last
- root = new TreeNode(rootValue)
+In the given binary tree, there exists a root-to-leaf path 5 -> 4 -> 11 -> 2 with a sum of 5 + 4 + 11 + 2 = 22, which equals k. Therefore, the function should return true.
- // Find the index of the rootValue in inorder to split it into left and right subtrees
- rootIndex = indexOf(inorder, rootValue)
+### Solution:
+* To solve this problem,we first check if the current node is a leaf node (having no left and right children) and if the current value equals k. If both conditions are met, it returns true, indicating that a valid path is found.
+* If not, it recursively checks the left and right subtrees with a reduced sum (k - root->val).
+* It returns true if there's a path in either the left or right subtree, indicating that a valid path is found.
- // Recursive call for right subtree
- root.right = buildTree(subarray(inorder, rootIndex + 1, end), subarray(postorder, rootIndex, end - 1))
-
- // Recursive call for left subtree
- root.left = buildTree(subarray(inorder, start, rootIndex - 1), subarray(postorder, start, rootIndex - 1))
- return root
+### Pseudocode
+```cpp
+function hasPathSum(Node root, k) {
+ if (!root) {
+ return false; // No path if the tree is empty
+ }
+
+ if (!root.left and !root.right) {
+ return (k == root.val);
+ }
+
+ return hasPathSum(root.left, k - root.val) || hasPathSum(root.right, k - root.val);
+}
+
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
-**Space Complexity:** O(N)
+**Space Complexity:** O(H)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md b/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md
index 2a5f69e..b580435 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 2 Views & Types.md
@@ -1,12 +1,14 @@
# Advanced DSA : Trees 2: Views & Types
----
-## Level Order Traversal
+
+## Problem 1 Level order traversal
+
+### Level Order Traversal
Input: 1, 2, 3, 5, 8, 10, 13, 6, 9, 7, 4, 12, 11.
The diagram for the following nodes will be:
- +
```cpp
@@ -19,41 +21,48 @@ The diagram for the following nodes will be:
---
+
+
+
### Question
Will the last level node always be a leaf node?
-**Choices**
+### Choices
- [x] YES
- [ ] NO
- [ ] Cant say
+### Explanation
-**Explanation**
+In a binary tree, the last level nodes are typically the leaf nodes. A leaf node is defined as a node that does not have any children. Since the last level of a binary tree is the lowest level, the nodes at this level do not have any child nodes, making them leaf nodes.
-Yes, in the context of a binary tree's right view, the last level node will always be a leaf node. This is because the right view of a binary tree focuses on the rightmost nodes at each level as seen from a top-down view.
+Thus, the correct answer is "YES" because in a well-formed binary tree, the nodes at the last level will always be leaf nodes, as they cannot have any children further down the tree.
---
+
+
+
### Question
Which traversal is best to print the nodes from top to bottom?
-**Choices**
+### Choices
- [x] Level order traversal
- [ ] Pre order
- [ ] post order
-**Explanation:**
+### Explanation:
When you want to print nodes from top to bottom, the level-order traversal, also known as Breadth-First Search (BFS), is the best choice. Level-order traversal ensures that nodes at the same level are processed before moving to the next level. This results in a top-to-bottom exploration of the tree.
---
-### Level order traversal Observations
+## Level order traversal Observations
-#### Observations:
+### Observations:
* Level order traversal visits nodes level by level, starting from the root.
* It uses a queue to keep track of the nodes to be processed.
* Nodes at the same level are processed before moving on to the next level.
@@ -61,24 +70,26 @@ When you want to print nodes from top to bottom, the level-order traversal, also
Since this will be done level by level hence we will be requiring a queue data structure to solve this problem:
-
+
```cpp
@@ -19,41 +21,48 @@ The diagram for the following nodes will be:
---
+
+
+
### Question
Will the last level node always be a leaf node?
-**Choices**
+### Choices
- [x] YES
- [ ] NO
- [ ] Cant say
+### Explanation
-**Explanation**
+In a binary tree, the last level nodes are typically the leaf nodes. A leaf node is defined as a node that does not have any children. Since the last level of a binary tree is the lowest level, the nodes at this level do not have any child nodes, making them leaf nodes.
-Yes, in the context of a binary tree's right view, the last level node will always be a leaf node. This is because the right view of a binary tree focuses on the rightmost nodes at each level as seen from a top-down view.
+Thus, the correct answer is "YES" because in a well-formed binary tree, the nodes at the last level will always be leaf nodes, as they cannot have any children further down the tree.
---
+
+
+
### Question
Which traversal is best to print the nodes from top to bottom?
-**Choices**
+### Choices
- [x] Level order traversal
- [ ] Pre order
- [ ] post order
-**Explanation:**
+### Explanation:
When you want to print nodes from top to bottom, the level-order traversal, also known as Breadth-First Search (BFS), is the best choice. Level-order traversal ensures that nodes at the same level are processed before moving to the next level. This results in a top-to-bottom exploration of the tree.
---
-### Level order traversal Observations
+## Level order traversal Observations
-#### Observations:
+### Observations:
* Level order traversal visits nodes level by level, starting from the root.
* It uses a queue to keep track of the nodes to be processed.
* Nodes at the same level are processed before moving on to the next level.
@@ -61,24 +70,26 @@ When you want to print nodes from top to bottom, the level-order traversal, also
Since this will be done level by level hence we will be requiring a queue data structure to solve this problem:
- +
After the whole process the queue data strucutre will look somewhat like this:
-
+
After the whole process the queue data strucutre will look somewhat like this:
- +
Like this(in theabove example) it will be done for all of the nodes.
Let us see the pseudocde to solve the problem in printing in one line only:
-#### Pseudocode:
+### Pseudocode:
```cpp
-q.enqueue(root) {
- while (!q.eempty()) {
+q.enqueue(root)
+{
+ while(not q.empty())
+ {
x = q.dequeue()
print(x.data)
- if (x.left != null) q.enqueue(x.left)
- if (x.right != null) q.enqueue(x.right)
+ if(x.left != null) q.enqueue(x.left)
+ if(x.right != null) q.enqueue(x.right)
}
}
```
@@ -92,11 +103,11 @@ Each level will be printed in seperate line:
```
-#### Observations:
+### Observations:
* Level order traversal prints nodes at the same depth before moving to the next level, ensuring that nodes on the same level are printed on separate lines.
-#### Approach:
+### Approach:
1. Start with the root node and enqueue it.
2. Initialize last as the root.
3. While the queue is not empty:
@@ -104,7 +115,7 @@ Each level will be printed in seperate line:
* Enqueue its children (if any).
* If the dequeued node is the same as last, print a newline and update last.
-#### Dry-Run:
+### Dry-Run:
```cpp
1
/ \
@@ -132,17 +143,20 @@ Each level will be printed in seperate line:
Let us see the pseudocode to solve the problem in printing in **seperate** line only:
-#### Pseudocode:
+### Pseudocode:
```cpp
-q.enqueue(root) {
+q.enqueue(root)
+{
last = root;
- while (!q.empty()) {
+ while(!q.empty())
+ {
x.dequeue()
print(x.data)
- if (x.left != null) q.enqueue(x.left)
- if (x.right != null) q.enqueue(x.right)
- if (x == last && !q.empty()) {
+ if(x.left != null) q.enqueue(x.left)
+ if(x.right != null) q.enqueue(x.right)
+ if(x == last && !q.empty())
+ {
print("\n");
last = q.rear();
}
@@ -150,14 +164,16 @@ q.enqueue(root) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
---
-### Problem 2 Right and left view
+## Problem 2 Right and left view
+### Print right view of a binary tree:
+
### Example:
Let us see an example below:
```cpp
@@ -190,7 +206,7 @@ Print right view of the given binary tree,
9 10
```
-**Choices**
+### Choices
- [ ] [1, 3, 6, 7]
- [ ] [1, 3, 6, 8, 9]
- [ ] [1, 3, 6, 7, 8, 9, 10]
@@ -199,14 +215,15 @@ Print right view of the given binary tree,
---
-### Right view Observations
+## Right view Observations
+
-#### Observations/Idea
+### Observations/Idea
* The idea behind obtaining the right view of a binary tree is to perform a level-order traversal, and for each level, identify and print the rightmost node. This process ensures that we capture the rightmost nodes at each level, giving us the right view of the binary tree. We can obtain the right-view of the tree using a breadth-first level-order traversal with a queue and a loop.
-#### Approach:
+### Approach:
1. Initialize an empty queue for level order traversal and enqueue the root node.
2. While the queue is not empty, do the following:
* Get the number of nodes at the current level (levelSize) by checking the queue's size.
@@ -217,17 +234,19 @@ Print right view of the given binary tree,
Let us see the pseudocode to solve the problem:
-#### Pseudocode:
+### Pseudocode:
```cpp
q.enqueue(root)
last = root;
-while (!q.empty(1)) {
+while(!q.empty(1))
+{
x = q.dequeue()
- if (x.left != null) q.enqueue(x.left)
- if (x.right != null) q.enqueue(x.right)
- if (x == last) {
+ if(x.left != null) q.enqueue(x.left)
+ if(x.right != null) q.enqueue(x.right)
+ if(x == last) {
print(x.data)
- if (!q.empty()) {
+ if(!q.empty())
+ {
print("\n");
last = q.rear();
}
@@ -236,201 +255,12 @@ while (!q.empty(1)) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(M)
---
-### Vertical Order traversal
-
-**Examples:**
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- / \ / \
- 4 5 6 7
- / \
- 8 9
-```
-Vertical order traversal of this tree would yield the following output:
-```cpp
-Vertical Line 1: 4
-Vertical Line 2: 2, 8
-Vertical Line 3: 1, 5, 6
-Vertical Line 4: 3, 9
-Vertical Line 5: 7
-```
-
-We need to print the vertical lines from top to bottom.
-
-
----
-### Question
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- \ \
- 5 6
- / \
- 8 7
- / \
- 9 10
-```
-
-Pick the vertical order traversal of the given Binary Tree.
-
-**Choices**
-- [x] [2, 1, 5, 9, 3, 8, 6, 10, 7]
-- [ ] [1, 2, 5, 3, 6, 8 ,9, 10, 7]
-- [ ] [1, 2, 3, 5, 6, 8, 7, 9, 10]
-- [ ] [1, 5, 2, 3, 6, 10, 8, 7, 9]
-
-**Explanation:**
-
-Vertical order traversal of this tree would yield the following output:
-```cpp
-Vertical Line 1: 2
-Vertical Line 2: 1, 5, 9
-Vertical Line 3: 3, 8
-Vertical Line 4: 6, 10
-Vertical Line 5: 7
-```
-
-
----
-### Vertical Order traversal Observations
-#### Observation:
-* Vertical order traversal of a binary tree prints nodes column by column, with nodes in the same column printed together.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-These are the steps to Print vertical order traversal:
-#### Approach:
-* Assign horizontal distances to nodes (root gets distance 0, left decreases by 1, right increases by 1).
-* Create a map/hash table where keys are distances and values are lists of node values.
-* Update the map while traversing: append node values to corresponding distance lists.
-* After traversal, print the values from the map in ascending order of distances.
-
-
----
-### Vertical Order traversal Pseudocode
-#### Pseudocode
-
-Let us see the pseudocode to solve this:
-```cpp
-procedure levelOrderTraversal(root)
- if root is null
- return
-
- Create a queue
- Enqueue root
-
- while queue is not empty
- currentNode = dequeue a node from the queue
- print currentNode's value
-
- if currentNode has left child
- enqueue left child
- end if
-
- if currentNode has right child
- enqueue right child
- end if
- end while
-end procedure
-```
-
----
-### Problem 4 Top View
-
-**Example:**
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- / \ / \
- 4 5 6 7
-```
-The top view of this tree would be [4, 2, 1, 3, 7].
-
-
----
-### Question
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- \ \
- 5 6
- / \
- 8 9
-```
-
-What is the top view of the given binary tree.
-
-**Choices**
-- [ ] [5, 2, 1, 3, 6, 9]
-- [ ] [8, 5, 2, 1, 3, 6, 9]
-- [ ] [2, 1, 5, 3, 8, 6, 9]
-- [x] [2, 1, 3, 6, 9]
-
-
-**Explanation:**
-
-The Top view of the Given Binary tree is [2, 1, 3, 6, 9].
-
-
----
-### Top View Observations
-
-#### Observations:
-* Assign Horizontal Distances: Nodes are assigned horizontal distances, with the root at distance 0, left children decreasing by 1, and right children increasing by 1. This helps identify the nodes in the top view efficiently.
-
-#### Approach:
-For this we need to follow these steps:
-* Traverse the binary tree.
-* Maintain a map of horizontal distances and corresponding nodes.
-* Only store the first node encountered at each unique distance.
-* Print the stored nodes in ascending order of distances to get the top view.
-
-#### Pseudocode:
-```cpp
-procedure topView(root)
- if root is null
- return
-
- Create an empty map
-
- Queue: enqueue (root, horizontal distance 0)
-
- while queue is not empty
- (currentNode, currentDistance) = dequeue a node
-
- if currentDistance is not in the map
- add currentDistance and currentNode's value to map
-
- enqueue (currentNode's left child, currentDistance - 1) if left child exists
- enqueue (currentNode's right child, currentDistance + 1) if right child exists
-
- Print values in map sorted by keys
-end procedure
-
-```
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(W)
-
----
-### Types of binary tree
+## Types of binary tree
@@ -464,27 +294,30 @@ Diagram:
---
+
+
+
### Question
Perfect Binary Trees are also:
-**Choices**
+### Choices
- [ ] Proper binary tree
- [ ] Complete binary tree
- [x] both
- [ ] none
-
-**Explanation:**
+### Explanation:
A perfect binary tree is a specialized case of both a proper binary tree and a complete binary tree, where all internal nodes have two children, all leaf nodes are at the same level, and all levels are completely filled.
---
-### Problem 5 : Check height balanced tree
+## Problem 3 Check height balanced tree
+
### Definition
For all nodes if(`height_ofleftchild-height_ofrightchild`) <= 1
-**Example:**
+### Example:
```cpp
1
/ \
@@ -496,18 +329,14 @@ For all nodes if(`height_ofleftchild-height_ofrightchild`) <= 1
```
This tree is not height-balanced because the left subtree of node 2 has a height of 3, while the right subtree of node 2 has a height of 0, and the difference is greater than 1.
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
-
### Brute Force
-#### Approach
+### Approach
* For each node in the binary tree, calculate the height of its left and right subtrees.
* Check if the absolute difference between the heights of the left and right subtrees for each node is less than or equal to 1.
* If step 2 is true for all nodes in the tree, the tree is height-balanced.
-#### Pseudocode:
+### Pseudocode:
```cpp
// Helper function to calculate the height of a tree
function calculateHeight(root):
@@ -538,32 +367,35 @@ result = isHeightBalanced(root)
> NOTE: For a null node: **height = -1**
-#### Complexity
+### Complexity
**Time Complexity:** $O(N^2)$
**Space Complexity:** O(N)
---
+
+
### Question
Which traversal is best to use when finding the height of the tree?
-**Choices**
+### Choices
- [ ] Level order
- [ ] Inorder
- [x] postorder
- [ ] preorder
-**Explanation:**
+### Explanation:
Postorder traversal works best for calculating the height of a tree because it considers the height of subtrees before calculating the height of parent nodes, which mirrors the hierarchical nature of tree height calculation.
---
-### Check height balanced tree Optimised Approach
+## Check height balanced tree Optimised Approach
-#### Observation/Idea:
+
+### Observation/Idea:
* To solve the problem of determining whether a binary tree is height-balanced we can consider using a recursive approach where you calculate the height of left and right subtrees and check their balance condition at each step. Keep track of a boolean flag to indicate whether the tree is still balanced.
-#### Approach:
+### Approach:
* We use a helper function height(root) to calculate the height of each subtree starting from the root.
* In the height function:
* If the root is null (i.e., an empty subtree), we return -1 to indicate a height of -1.
@@ -574,7 +406,7 @@ Postorder traversal works best for calculating the height of a tree because it c
* If, at any point, the ishb flag becomes false, we know that the tree is not height-balanced, and we can stop further calculations.
* After the traversal is complete, if the ishb flag is still true, the tree is height-balanced.
-#### Example:
+### Example:
```cpp
1
/ \
@@ -584,18 +416,190 @@ Postorder traversal works best for calculating the height of a tree because it c
```
This tree is height-balanced because the height of the left and right subtrees of every node differs by at most 1.
-#### Pseudocode
+### Pseudocode
```cpp
-int height(root, ishb) {
- if (root == null) return -1;
+function height(root, ishb)
+{
+ if(root == null) return -1;
l = height(root.left)
r = height(root.right)
- if (abs(l - r) > 1) ishb = false;
+ if( absolute(l - r) > 1) ishb = false;
return max(l, r) + 1
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(log N)
+---
+## Problem 4 Construct binary tree
+
+
+### Construct binary tree from inorder and post order
+
+Constructing a binary tree from its inorder and postorder traversals involves a recursive process. Here's a brief explanation with an example:
+
+### Brute-Force Approach
+
+### Approach:
+
+* Generate all possible permutations of the given inorder traversal.
+* For each permutation, check if it forms a valid binary tree when combined with the given postorder traversal.
+* Return the first valid binary tree found.
+
+### Example:
+Inorder: [4, 2, 7, 5, 1, 3, 6]
+Postorder: [4, 7, 5, 2, 6, 3, 1]
+
+### Dry-Run:
+* Identify the root: In the postorder traversal, the last element is 1, which is the root of the binary tree.
+* Split into left and right subtrees: In the inorder traversal, find the position of the root element (1). Elements to the left of this position represent the left subtree, and elements to the right represent the right subtree.
+* Recurse on left subtree: For the left subtree, the root is 2 (found in postorder traversal). Split the left subtree's inorder and postorder traversals, and repeat the process.
+* Recurse on right subtree: For the right subtree, the root is 3 (found in postorder traversal). Split the right subtree's inorder and postorder traversals, and repeat the process.
+* Continue the recursion: Repeat steps 3 and 4 for each subtree until the entire binary tree is constructed.
+
+
+### Pseudocode:
+```cpp
+function buildTreeBruteForce(inorder, postorder):
+ for each permutation of inorder:
+ if formsValidBinaryTree(permutation, postorder):
+ return constructBinaryTree(permutation, postorder)
+ return null
+```
+* **TC-** O(N! * N)
+* **SC-** O(N)
+
+---
+## Construct binary tree Most Optimised Approach
+
+### Most-Optimised Approach:
+
+* The last element in the postorder traversal is the root of the binary tree.
+* Find the root element in the inorder traversal to determine the left and right subtrees.
+* Recursively repeat the process for the left and right subtrees.
+
+
+
+Now as we can see in the above image let us understand this with the help of a dry/run:
+### Dry-Run/Example:
+inorder={4,2,7,5,1,3,6} and postorder={4,7,5,2,6,3,1}
+
+1. The last element in the postorder traversal is 1, which is the root of the binary tree.
+
+Binary Tree:
+```plaintext
+1
+```
+2. Find 1 in the inorder traversal to split it into left and right subtrees. The elements to the left are the left subtree, and the elements to the right are the right subtree.
+
+```cpp
+Inorder: [4,2,7,5,1,3,6]
+Postorder: [4,7,5,2,6,3,1]
+```
+
+Left Subtree (Inorder: [4,2,7,5], Postorder: [4,7,5,2]):
+
+```cpp
+ 1
+ /
+2
+ \
+ 5
+ / \
+4 7
+```
+Right Subtree (Inorder: [3,6], Postorder: [6,3]):
+
+```cpp
+6
+ \
+ 3
+```
+3. Repeat the process for the left and right subtrees:
+
+For the left subtree:
+* The last element in the postorder traversal is 2, which is the root of the left subtree.
+* Find 2 in the inorder traversal to split it into left and right subtrees.
+* Left Subtree (Inorder: [4], Postorder: [4]):
+```cpp
+ 2
+ /
+4
+```
+Right Subtree (Inorder: [7,5], Postorder: [7,5]):
+```cpp
+ 5
+ /
+7
+```
+For the right subtree:
+
+* The last element in the postorder traversal is 3, which is the root of the right subtree.
+* Find 3 in the inorder traversal to split it into left and right subtrees.
+* Left Subtree (Inorder: [6], Postorder: [6]):
+```cpp
+ 3
+ \
+ 6
+```
+
+The final binary tree would look like this:
+```cpp
+ 1
+ / \
+ 2 3
+ / \ \
+ 4 5 6
+ /
+ 7
+```
+
+---
+
+### Question
+The inorder traversal sequence `[4, 2, 5, 1, 6, 3]` and the postorder traversal sequence `[4, 5, 2, 6, 3, 1]`. What is the root of the binary tree?
+
+### Choices
+- [x] 1
+- [ ] 2
+- [ ] 3
+- [ ] 4
+
+### Explanation:
+
+In postorder traversal, the last element is always the root of the tree, so here, 1 is the root.
+
+---
+## Construct binary tree Pseudocode
+
+### Pseudocode:
+* rootIndex is the index of the root value in the inorder array.
+* rootIndex + 1 represents the start of the right subtree in the arrays.
+* end represents the end of the right subtree in the arrays.
+* start represents the start of the left subtree in the arrays.
+* rootIndex - 1 represents the end of the left subtree in the arrays.
+```cpp
+function buildTree(inorder, postorder):
+ if postorder is empty:
+ return null
+
+ // The last element in postorder is the root of the current subtree
+ rootValue = postorder.last
+ root = new TreeNode(rootValue)
+
+ // Find the index of the rootValue in inorder to split it into left and right subtrees
+ rootIndex = indexOf(inorder, rootValue)
+
+ // Recursive call for right subtree
+ root.right = buildTree(subarray(inorder, rootIndex + 1, end), subarray(postorder, rootIndex, end - 1))
+
+ // Recursive call for left subtree
+ root.left = buildTree(subarray(inorder, start, rootIndex - 1), subarray(postorder, start, rootIndex - 1))
+
+ return root
+```
+
+**TC-O(N)
+SC-O(N)**
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md b/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md
index 543a0ca..6024627 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md
@@ -1,6 +1,7 @@
# Advanced DSA : Trees 3: BST
----
+
+
## Binary Search Tree
Binary search tree is searching data in an organized dataset using divide and conquer.
@@ -20,21 +21,23 @@ Example of a binary search tree:
```
---
+
+
+
### Question
What is a Binary Search Tree (BST)?
-**Choices**
+### Choices
- [ ] A tree with only two nodes
- [ ] A tree where the left child of a node has a value <= the node, and the right child has a value > the node
- [x] A tree where for a node x, everything on the left has data <= x and on the right > x.
- [ ] A tree that has height log N.
-
-
---
-### Problem 1 Searching in Binary Search Tree
+## Problem 1 Searching in Binary Search Tree
+### Searching
Searching in a Binary Search Tree (BST) involves utilizing the property that values in the left subtree are smaller and values in the right subtree are larger than the current node's value. This property allows for efficient search operations.
Here's an example using the BST diagram from earlier:
```cpp
@@ -52,6 +55,8 @@ Here's an example using the BST diagram from earlier:
* The value 6 matches the current node's value, so the search is successful.
---
+
+
### Question
What is the number of nodes you need to visit to find the number `1` in the following BST?
@@ -63,22 +68,22 @@ What is the number of nodes you need to visit to find the number `1` in the foll
1 4 6 9
```
-**Choices**
+### Choices
- [ ] 2
- [x] 3
- [ ] 4
- [ ] 1
-**Explanation**
+### Explanation
First node: 5. From 5 you move left.
Second node: 3. From 3 you move left, again.
Third node: 1. You finally get 1.
---
-### Searching in Binary Search Tree Pseudo Code
+## Searching in Binary Search Tree Pseudo Code
-#### Pseudo Code
+### Pseudo Code
```cpp
function search(root, target):
if root is None:
@@ -96,8 +101,7 @@ function search(root, target):
---
-### Problem 2 Insertion in Binary Search Tree
-
+## Problem 2 Insertion in Binary Search Tree
### Insertion in BST:
Inserting a new value into a Binary Search Tree (BST) involves maintaining the property that values in the left subtree are smaller and values in the right subtree are larger than the current node's value.
@@ -129,7 +133,7 @@ The updated tree after insertion:
7
```
-#### Pseudocode:
+### Pseudocode:
```cpp
function insert(root, value):
if root is null:
@@ -144,34 +148,31 @@ function insert(root, value):
```
---
+
+
### Question
Where does the node with the smallest value resides in a BST?
-**Choices**
+### Choices
- [x] We keep on going left and we get the smallest one.
- [ ] Depends on the tree.
- [ ] We keep on going right and we get the smallest one.
- [ ] The root node.
-
For every node, we need to go to its left, that's the only way we can reach the smallest one.
---
-### Problem 3 Find smallest in Binary Search Tree
+## Problem 3 Find smallest in Binary Search Tree
+### Problem Statement
Find smallest in Binary Search Tree
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-**Approach**
+### Approach
The left most node in the tree, will be the smallest.
-**Example:**
+### Example:
Suppose we have the following BST:
```cpp
5
@@ -187,28 +188,29 @@ To find the smallest element:
* Continue moving to the left child until you reach a node with no left child.
* The node with no left child is the smallest element in the BST. In this case, it's the node with the value 2.
* So, in this example, the smallest element in the BST is 2.
-
-#### Pseudocode
+### Pseudocode
```cpp
-temp = root // not null
-while (temp.left != null) {
- temp = temp.left
+temp = root// not null
+while(temp.left != null)
+{
+ temp = temp.left
}
return temp.data;
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(1)
---
-### Problem 4 Find largest in Binary Search Tree
-#### Approach
+## Problem 4 Find largest in Binary Search Tree
+
+### Approach
The right most node in the tree, will be the largest.
-**Example:**
+### Example:
Suppose we have the following BST:
```cpp
5
@@ -224,24 +226,27 @@ Suppose we have the following BST:
* The node with no right child is the largest element in the BST. In this case, it's the node with the value 9.
* So, in this example, the largest element in the BST is 9.
-#### Pseudocode
+### Pseudocode
```cpp
-temp = root // not null
-while (temp.right != null) {
- temp = temp.right
+temp = root// not null
+while(temp.right != null)
+{
+ temp = temp.right
}
return temp.data;
```
---
-### Problem 5 Deletion in Binary Search Tree
+## Problem 5 Deletion in Binary Search Tree
+
+### Deletion in Binary Search Tree
Deleting a node from a Binary Search Tree (BST) involves maintaining the BST property while handling various cases depending on the node's structure. Here's how the deletion process works:
* Find the Node to Delete: Start at the root and traverse the tree to find the node you want to delete. Remember to keep track of the parent node as well.
-#### Case 1: Node with No Children (Leaf Node)
+### Case 1: Node with No Children (Leaf Node)
In this case, we have a node with no children (a leaf node). Deleting it is straightforward; we simply remove it from the tree.
**Example:**
@@ -261,7 +266,7 @@ After deleting the node with the value 7, the tree becomes:
/ / \
3 12 18
```
-#### Case 2: Node with One Child
+### Case 2: Node with One Child
In this case, the node to be deleted has only one child. To delete it, we replace the node with its child.
**Example:**
@@ -283,7 +288,7 @@ After deleting the node with the value 5, we replace it with its child (3):
```
-#### Case 3: Node with Two Children
+### Case 3: Node with Two Children
In this case, the node to be deleted has two children. To delete it, we find either the in-order predecessor or successor and replace the node's value with the value of the predecessor or successor. Then, we recursively delete the predecessor or successor.
**Example:**
@@ -310,25 +315,57 @@ To delete the node with value 10, we can either choose its in-order predecessor
```
These are the three main cases for deleting a node in a Binary Search Tree (BST).
-#### Pseudo Code
+### Pseudo Code
Here's the pseudo code with each of the cases mentioned.
-
+
Like this(in theabove example) it will be done for all of the nodes.
Let us see the pseudocde to solve the problem in printing in one line only:
-#### Pseudocode:
+### Pseudocode:
```cpp
-q.enqueue(root) {
- while (!q.eempty()) {
+q.enqueue(root)
+{
+ while(not q.empty())
+ {
x = q.dequeue()
print(x.data)
- if (x.left != null) q.enqueue(x.left)
- if (x.right != null) q.enqueue(x.right)
+ if(x.left != null) q.enqueue(x.left)
+ if(x.right != null) q.enqueue(x.right)
}
}
```
@@ -92,11 +103,11 @@ Each level will be printed in seperate line:
```
-#### Observations:
+### Observations:
* Level order traversal prints nodes at the same depth before moving to the next level, ensuring that nodes on the same level are printed on separate lines.
-#### Approach:
+### Approach:
1. Start with the root node and enqueue it.
2. Initialize last as the root.
3. While the queue is not empty:
@@ -104,7 +115,7 @@ Each level will be printed in seperate line:
* Enqueue its children (if any).
* If the dequeued node is the same as last, print a newline and update last.
-#### Dry-Run:
+### Dry-Run:
```cpp
1
/ \
@@ -132,17 +143,20 @@ Each level will be printed in seperate line:
Let us see the pseudocode to solve the problem in printing in **seperate** line only:
-#### Pseudocode:
+### Pseudocode:
```cpp
-q.enqueue(root) {
+q.enqueue(root)
+{
last = root;
- while (!q.empty()) {
+ while(!q.empty())
+ {
x.dequeue()
print(x.data)
- if (x.left != null) q.enqueue(x.left)
- if (x.right != null) q.enqueue(x.right)
- if (x == last && !q.empty()) {
+ if(x.left != null) q.enqueue(x.left)
+ if(x.right != null) q.enqueue(x.right)
+ if(x == last && !q.empty())
+ {
print("\n");
last = q.rear();
}
@@ -150,14 +164,16 @@ q.enqueue(root) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(N)
---
-### Problem 2 Right and left view
+## Problem 2 Right and left view
+### Print right view of a binary tree:
+
### Example:
Let us see an example below:
```cpp
@@ -190,7 +206,7 @@ Print right view of the given binary tree,
9 10
```
-**Choices**
+### Choices
- [ ] [1, 3, 6, 7]
- [ ] [1, 3, 6, 8, 9]
- [ ] [1, 3, 6, 7, 8, 9, 10]
@@ -199,14 +215,15 @@ Print right view of the given binary tree,
---
-### Right view Observations
+## Right view Observations
+
-#### Observations/Idea
+### Observations/Idea
* The idea behind obtaining the right view of a binary tree is to perform a level-order traversal, and for each level, identify and print the rightmost node. This process ensures that we capture the rightmost nodes at each level, giving us the right view of the binary tree. We can obtain the right-view of the tree using a breadth-first level-order traversal with a queue and a loop.
-#### Approach:
+### Approach:
1. Initialize an empty queue for level order traversal and enqueue the root node.
2. While the queue is not empty, do the following:
* Get the number of nodes at the current level (levelSize) by checking the queue's size.
@@ -217,17 +234,19 @@ Print right view of the given binary tree,
Let us see the pseudocode to solve the problem:
-#### Pseudocode:
+### Pseudocode:
```cpp
q.enqueue(root)
last = root;
-while (!q.empty(1)) {
+while(!q.empty(1))
+{
x = q.dequeue()
- if (x.left != null) q.enqueue(x.left)
- if (x.right != null) q.enqueue(x.right)
- if (x == last) {
+ if(x.left != null) q.enqueue(x.left)
+ if(x.right != null) q.enqueue(x.right)
+ if(x == last) {
print(x.data)
- if (!q.empty()) {
+ if(!q.empty())
+ {
print("\n");
last = q.rear();
}
@@ -236,201 +255,12 @@ while (!q.empty(1)) {
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(M)
---
-### Vertical Order traversal
-
-**Examples:**
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- / \ / \
- 4 5 6 7
- / \
- 8 9
-```
-Vertical order traversal of this tree would yield the following output:
-```cpp
-Vertical Line 1: 4
-Vertical Line 2: 2, 8
-Vertical Line 3: 1, 5, 6
-Vertical Line 4: 3, 9
-Vertical Line 5: 7
-```
-
-We need to print the vertical lines from top to bottom.
-
-
----
-### Question
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- \ \
- 5 6
- / \
- 8 7
- / \
- 9 10
-```
-
-Pick the vertical order traversal of the given Binary Tree.
-
-**Choices**
-- [x] [2, 1, 5, 9, 3, 8, 6, 10, 7]
-- [ ] [1, 2, 5, 3, 6, 8 ,9, 10, 7]
-- [ ] [1, 2, 3, 5, 6, 8, 7, 9, 10]
-- [ ] [1, 5, 2, 3, 6, 10, 8, 7, 9]
-
-**Explanation:**
-
-Vertical order traversal of this tree would yield the following output:
-```cpp
-Vertical Line 1: 2
-Vertical Line 2: 1, 5, 9
-Vertical Line 3: 3, 8
-Vertical Line 4: 6, 10
-Vertical Line 5: 7
-```
-
-
----
-### Vertical Order traversal Observations
-#### Observation:
-* Vertical order traversal of a binary tree prints nodes column by column, with nodes in the same column printed together.
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-These are the steps to Print vertical order traversal:
-#### Approach:
-* Assign horizontal distances to nodes (root gets distance 0, left decreases by 1, right increases by 1).
-* Create a map/hash table where keys are distances and values are lists of node values.
-* Update the map while traversing: append node values to corresponding distance lists.
-* After traversal, print the values from the map in ascending order of distances.
-
-
----
-### Vertical Order traversal Pseudocode
-#### Pseudocode
-
-Let us see the pseudocode to solve this:
-```cpp
-procedure levelOrderTraversal(root)
- if root is null
- return
-
- Create a queue
- Enqueue root
-
- while queue is not empty
- currentNode = dequeue a node from the queue
- print currentNode's value
-
- if currentNode has left child
- enqueue left child
- end if
-
- if currentNode has right child
- enqueue right child
- end if
- end while
-end procedure
-```
-
----
-### Problem 4 Top View
-
-**Example:**
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- / \ / \
- 4 5 6 7
-```
-The top view of this tree would be [4, 2, 1, 3, 7].
-
-
----
-### Question
-Consider the following binary tree:
-```cpp
- 1
- / \
- 2 3
- \ \
- 5 6
- / \
- 8 9
-```
-
-What is the top view of the given binary tree.
-
-**Choices**
-- [ ] [5, 2, 1, 3, 6, 9]
-- [ ] [8, 5, 2, 1, 3, 6, 9]
-- [ ] [2, 1, 5, 3, 8, 6, 9]
-- [x] [2, 1, 3, 6, 9]
-
-
-**Explanation:**
-
-The Top view of the Given Binary tree is [2, 1, 3, 6, 9].
-
-
----
-### Top View Observations
-
-#### Observations:
-* Assign Horizontal Distances: Nodes are assigned horizontal distances, with the root at distance 0, left children decreasing by 1, and right children increasing by 1. This helps identify the nodes in the top view efficiently.
-
-#### Approach:
-For this we need to follow these steps:
-* Traverse the binary tree.
-* Maintain a map of horizontal distances and corresponding nodes.
-* Only store the first node encountered at each unique distance.
-* Print the stored nodes in ascending order of distances to get the top view.
-
-#### Pseudocode:
-```cpp
-procedure topView(root)
- if root is null
- return
-
- Create an empty map
-
- Queue: enqueue (root, horizontal distance 0)
-
- while queue is not empty
- (currentNode, currentDistance) = dequeue a node
-
- if currentDistance is not in the map
- add currentDistance and currentNode's value to map
-
- enqueue (currentNode's left child, currentDistance - 1) if left child exists
- enqueue (currentNode's right child, currentDistance + 1) if right child exists
-
- Print values in map sorted by keys
-end procedure
-
-```
-
-#### Complexity
-**Time Complexity:** O(N)
-**Space Complexity:** O(W)
-
----
-### Types of binary tree
+## Types of binary tree
@@ -464,27 +294,30 @@ Diagram:
---
+
+
+
### Question
Perfect Binary Trees are also:
-**Choices**
+### Choices
- [ ] Proper binary tree
- [ ] Complete binary tree
- [x] both
- [ ] none
-
-**Explanation:**
+### Explanation:
A perfect binary tree is a specialized case of both a proper binary tree and a complete binary tree, where all internal nodes have two children, all leaf nodes are at the same level, and all levels are completely filled.
---
-### Problem 5 : Check height balanced tree
+## Problem 3 Check height balanced tree
+
### Definition
For all nodes if(`height_ofleftchild-height_ofrightchild`) <= 1
-**Example:**
+### Example:
```cpp
1
/ \
@@ -496,18 +329,14 @@ For all nodes if(`height_ofleftchild-height_ofrightchild`) <= 1
```
This tree is not height-balanced because the left subtree of node 2 has a height of 3, while the right subtree of node 2 has a height of 0, and the difference is greater than 1.
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
-
### Brute Force
-#### Approach
+### Approach
* For each node in the binary tree, calculate the height of its left and right subtrees.
* Check if the absolute difference between the heights of the left and right subtrees for each node is less than or equal to 1.
* If step 2 is true for all nodes in the tree, the tree is height-balanced.
-#### Pseudocode:
+### Pseudocode:
```cpp
// Helper function to calculate the height of a tree
function calculateHeight(root):
@@ -538,32 +367,35 @@ result = isHeightBalanced(root)
> NOTE: For a null node: **height = -1**
-#### Complexity
+### Complexity
**Time Complexity:** $O(N^2)$
**Space Complexity:** O(N)
---
+
+
### Question
Which traversal is best to use when finding the height of the tree?
-**Choices**
+### Choices
- [ ] Level order
- [ ] Inorder
- [x] postorder
- [ ] preorder
-**Explanation:**
+### Explanation:
Postorder traversal works best for calculating the height of a tree because it considers the height of subtrees before calculating the height of parent nodes, which mirrors the hierarchical nature of tree height calculation.
---
-### Check height balanced tree Optimised Approach
+## Check height balanced tree Optimised Approach
-#### Observation/Idea:
+
+### Observation/Idea:
* To solve the problem of determining whether a binary tree is height-balanced we can consider using a recursive approach where you calculate the height of left and right subtrees and check their balance condition at each step. Keep track of a boolean flag to indicate whether the tree is still balanced.
-#### Approach:
+### Approach:
* We use a helper function height(root) to calculate the height of each subtree starting from the root.
* In the height function:
* If the root is null (i.e., an empty subtree), we return -1 to indicate a height of -1.
@@ -574,7 +406,7 @@ Postorder traversal works best for calculating the height of a tree because it c
* If, at any point, the ishb flag becomes false, we know that the tree is not height-balanced, and we can stop further calculations.
* After the traversal is complete, if the ishb flag is still true, the tree is height-balanced.
-#### Example:
+### Example:
```cpp
1
/ \
@@ -584,18 +416,190 @@ Postorder traversal works best for calculating the height of a tree because it c
```
This tree is height-balanced because the height of the left and right subtrees of every node differs by at most 1.
-#### Pseudocode
+### Pseudocode
```cpp
-int height(root, ishb) {
- if (root == null) return -1;
+function height(root, ishb)
+{
+ if(root == null) return -1;
l = height(root.left)
r = height(root.right)
- if (abs(l - r) > 1) ishb = false;
+ if( absolute(l - r) > 1) ishb = false;
return max(l, r) + 1
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(log N)
+---
+## Problem 4 Construct binary tree
+
+
+### Construct binary tree from inorder and post order
+
+Constructing a binary tree from its inorder and postorder traversals involves a recursive process. Here's a brief explanation with an example:
+
+### Brute-Force Approach
+
+### Approach:
+
+* Generate all possible permutations of the given inorder traversal.
+* For each permutation, check if it forms a valid binary tree when combined with the given postorder traversal.
+* Return the first valid binary tree found.
+
+### Example:
+Inorder: [4, 2, 7, 5, 1, 3, 6]
+Postorder: [4, 7, 5, 2, 6, 3, 1]
+
+### Dry-Run:
+* Identify the root: In the postorder traversal, the last element is 1, which is the root of the binary tree.
+* Split into left and right subtrees: In the inorder traversal, find the position of the root element (1). Elements to the left of this position represent the left subtree, and elements to the right represent the right subtree.
+* Recurse on left subtree: For the left subtree, the root is 2 (found in postorder traversal). Split the left subtree's inorder and postorder traversals, and repeat the process.
+* Recurse on right subtree: For the right subtree, the root is 3 (found in postorder traversal). Split the right subtree's inorder and postorder traversals, and repeat the process.
+* Continue the recursion: Repeat steps 3 and 4 for each subtree until the entire binary tree is constructed.
+
+
+### Pseudocode:
+```cpp
+function buildTreeBruteForce(inorder, postorder):
+ for each permutation of inorder:
+ if formsValidBinaryTree(permutation, postorder):
+ return constructBinaryTree(permutation, postorder)
+ return null
+```
+* **TC-** O(N! * N)
+* **SC-** O(N)
+
+---
+## Construct binary tree Most Optimised Approach
+
+### Most-Optimised Approach:
+
+* The last element in the postorder traversal is the root of the binary tree.
+* Find the root element in the inorder traversal to determine the left and right subtrees.
+* Recursively repeat the process for the left and right subtrees.
+
+
+
+Now as we can see in the above image let us understand this with the help of a dry/run:
+### Dry-Run/Example:
+inorder={4,2,7,5,1,3,6} and postorder={4,7,5,2,6,3,1}
+
+1. The last element in the postorder traversal is 1, which is the root of the binary tree.
+
+Binary Tree:
+```plaintext
+1
+```
+2. Find 1 in the inorder traversal to split it into left and right subtrees. The elements to the left are the left subtree, and the elements to the right are the right subtree.
+
+```cpp
+Inorder: [4,2,7,5,1,3,6]
+Postorder: [4,7,5,2,6,3,1]
+```
+
+Left Subtree (Inorder: [4,2,7,5], Postorder: [4,7,5,2]):
+
+```cpp
+ 1
+ /
+2
+ \
+ 5
+ / \
+4 7
+```
+Right Subtree (Inorder: [3,6], Postorder: [6,3]):
+
+```cpp
+6
+ \
+ 3
+```
+3. Repeat the process for the left and right subtrees:
+
+For the left subtree:
+* The last element in the postorder traversal is 2, which is the root of the left subtree.
+* Find 2 in the inorder traversal to split it into left and right subtrees.
+* Left Subtree (Inorder: [4], Postorder: [4]):
+```cpp
+ 2
+ /
+4
+```
+Right Subtree (Inorder: [7,5], Postorder: [7,5]):
+```cpp
+ 5
+ /
+7
+```
+For the right subtree:
+
+* The last element in the postorder traversal is 3, which is the root of the right subtree.
+* Find 3 in the inorder traversal to split it into left and right subtrees.
+* Left Subtree (Inorder: [6], Postorder: [6]):
+```cpp
+ 3
+ \
+ 6
+```
+
+The final binary tree would look like this:
+```cpp
+ 1
+ / \
+ 2 3
+ / \ \
+ 4 5 6
+ /
+ 7
+```
+
+---
+
+### Question
+The inorder traversal sequence `[4, 2, 5, 1, 6, 3]` and the postorder traversal sequence `[4, 5, 2, 6, 3, 1]`. What is the root of the binary tree?
+
+### Choices
+- [x] 1
+- [ ] 2
+- [ ] 3
+- [ ] 4
+
+### Explanation:
+
+In postorder traversal, the last element is always the root of the tree, so here, 1 is the root.
+
+---
+## Construct binary tree Pseudocode
+
+### Pseudocode:
+* rootIndex is the index of the root value in the inorder array.
+* rootIndex + 1 represents the start of the right subtree in the arrays.
+* end represents the end of the right subtree in the arrays.
+* start represents the start of the left subtree in the arrays.
+* rootIndex - 1 represents the end of the left subtree in the arrays.
+```cpp
+function buildTree(inorder, postorder):
+ if postorder is empty:
+ return null
+
+ // The last element in postorder is the root of the current subtree
+ rootValue = postorder.last
+ root = new TreeNode(rootValue)
+
+ // Find the index of the rootValue in inorder to split it into left and right subtrees
+ rootIndex = indexOf(inorder, rootValue)
+
+ // Recursive call for right subtree
+ root.right = buildTree(subarray(inorder, rootIndex + 1, end), subarray(postorder, rootIndex, end - 1))
+
+ // Recursive call for left subtree
+ root.left = buildTree(subarray(inorder, start, rootIndex - 1), subarray(postorder, start, rootIndex - 1))
+
+ return root
+```
+
+**TC-O(N)
+SC-O(N)**
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md b/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md
index 543a0ca..6024627 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 3 BST.md
@@ -1,6 +1,7 @@
# Advanced DSA : Trees 3: BST
----
+
+
## Binary Search Tree
Binary search tree is searching data in an organized dataset using divide and conquer.
@@ -20,21 +21,23 @@ Example of a binary search tree:
```
---
+
+
+
### Question
What is a Binary Search Tree (BST)?
-**Choices**
+### Choices
- [ ] A tree with only two nodes
- [ ] A tree where the left child of a node has a value <= the node, and the right child has a value > the node
- [x] A tree where for a node x, everything on the left has data <= x and on the right > x.
- [ ] A tree that has height log N.
-
-
---
-### Problem 1 Searching in Binary Search Tree
+## Problem 1 Searching in Binary Search Tree
+### Searching
Searching in a Binary Search Tree (BST) involves utilizing the property that values in the left subtree are smaller and values in the right subtree are larger than the current node's value. This property allows for efficient search operations.
Here's an example using the BST diagram from earlier:
```cpp
@@ -52,6 +55,8 @@ Here's an example using the BST diagram from earlier:
* The value 6 matches the current node's value, so the search is successful.
---
+
+
### Question
What is the number of nodes you need to visit to find the number `1` in the following BST?
@@ -63,22 +68,22 @@ What is the number of nodes you need to visit to find the number `1` in the foll
1 4 6 9
```
-**Choices**
+### Choices
- [ ] 2
- [x] 3
- [ ] 4
- [ ] 1
-**Explanation**
+### Explanation
First node: 5. From 5 you move left.
Second node: 3. From 3 you move left, again.
Third node: 1. You finally get 1.
---
-### Searching in Binary Search Tree Pseudo Code
+## Searching in Binary Search Tree Pseudo Code
-#### Pseudo Code
+### Pseudo Code
```cpp
function search(root, target):
if root is None:
@@ -96,8 +101,7 @@ function search(root, target):
---
-### Problem 2 Insertion in Binary Search Tree
-
+## Problem 2 Insertion in Binary Search Tree
### Insertion in BST:
Inserting a new value into a Binary Search Tree (BST) involves maintaining the property that values in the left subtree are smaller and values in the right subtree are larger than the current node's value.
@@ -129,7 +133,7 @@ The updated tree after insertion:
7
```
-#### Pseudocode:
+### Pseudocode:
```cpp
function insert(root, value):
if root is null:
@@ -144,34 +148,31 @@ function insert(root, value):
```
---
+
+
### Question
Where does the node with the smallest value resides in a BST?
-**Choices**
+### Choices
- [x] We keep on going left and we get the smallest one.
- [ ] Depends on the tree.
- [ ] We keep on going right and we get the smallest one.
- [ ] The root node.
-
For every node, we need to go to its left, that's the only way we can reach the smallest one.
---
-### Problem 3 Find smallest in Binary Search Tree
+## Problem 3 Find smallest in Binary Search Tree
+### Problem Statement
Find smallest in Binary Search Tree
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-**Approach**
+### Approach
The left most node in the tree, will be the smallest.
-**Example:**
+### Example:
Suppose we have the following BST:
```cpp
5
@@ -187,28 +188,29 @@ To find the smallest element:
* Continue moving to the left child until you reach a node with no left child.
* The node with no left child is the smallest element in the BST. In this case, it's the node with the value 2.
* So, in this example, the smallest element in the BST is 2.
-
-#### Pseudocode
+### Pseudocode
```cpp
-temp = root // not null
-while (temp.left != null) {
- temp = temp.left
+temp = root// not null
+while(temp.left != null)
+{
+ temp = temp.left
}
return temp.data;
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(1)
---
-### Problem 4 Find largest in Binary Search Tree
-#### Approach
+## Problem 4 Find largest in Binary Search Tree
+
+### Approach
The right most node in the tree, will be the largest.
-**Example:**
+### Example:
Suppose we have the following BST:
```cpp
5
@@ -224,24 +226,27 @@ Suppose we have the following BST:
* The node with no right child is the largest element in the BST. In this case, it's the node with the value 9.
* So, in this example, the largest element in the BST is 9.
-#### Pseudocode
+### Pseudocode
```cpp
-temp = root // not null
-while (temp.right != null) {
- temp = temp.right
+temp = root// not null
+while(temp.right != null)
+{
+ temp = temp.right
}
return temp.data;
```
---
-### Problem 5 Deletion in Binary Search Tree
+## Problem 5 Deletion in Binary Search Tree
+
+### Deletion in Binary Search Tree
Deleting a node from a Binary Search Tree (BST) involves maintaining the BST property while handling various cases depending on the node's structure. Here's how the deletion process works:
* Find the Node to Delete: Start at the root and traverse the tree to find the node you want to delete. Remember to keep track of the parent node as well.
-#### Case 1: Node with No Children (Leaf Node)
+### Case 1: Node with No Children (Leaf Node)
In this case, we have a node with no children (a leaf node). Deleting it is straightforward; we simply remove it from the tree.
**Example:**
@@ -261,7 +266,7 @@ After deleting the node with the value 7, the tree becomes:
/ / \
3 12 18
```
-#### Case 2: Node with One Child
+### Case 2: Node with One Child
In this case, the node to be deleted has only one child. To delete it, we replace the node with its child.
**Example:**
@@ -283,7 +288,7 @@ After deleting the node with the value 5, we replace it with its child (3):
```
-#### Case 3: Node with Two Children
+### Case 3: Node with Two Children
In this case, the node to be deleted has two children. To delete it, we find either the in-order predecessor or successor and replace the node's value with the value of the predecessor or successor. Then, we recursively delete the predecessor or successor.
**Example:**
@@ -310,25 +315,57 @@ To delete the node with value 10, we can either choose its in-order predecessor
```
These are the three main cases for deleting a node in a Binary Search Tree (BST).
-#### Pseudo Code
+### Pseudo Code
Here's the pseudo code with each of the cases mentioned.
- +
+
+```cpp
+Node delete(Node root, int K){
+ if(root == NULL) return NULL;
+
+ if(root.data == K){
+ if(root.left == NULL && root.right == NULL)
+ return NULL;
+ if(root.left || root.right){
+ if(root.left == NULL) return root.right;
+ if(root.right == NULL) return root.left;
+ }
+
+ Node temp = root.left;
+ while(temp.right != NULL){
+ temp = temp.right;
+ }
+ root.data = temp.data;
+ root.left = delete(root.left, temp.data);
+ return root;
+ }
+ else if(root.left > K){
+ root.left = delete(root.left, K);
+ }
+ else{
+ root.right = delete(root.right, K);
+ }
+}
+```
+
+---
+
### Question
What is the purpose of balancing a Binary Search Tree?
-
-**Choices**
+### Choices
- [ ] To make it visually appealing
- [ ] To ensure all nodes have the same value
- [x] To maintain efficient search, insert, and delete operations
- [ ] Balancing is not necessary in a Binary Search Tree
-
---
-### Problem 6 Construct a binary search tree
+## Problem 6 Construct a binary search tree
+
+### Construct BST from sorted array of unique elements:
-#### Approach:
+### Approach:
* Find the middle element of the sorted array.
* Create a new node with this middle element as the root of the tree.
* Recursively repeat steps 1 and 2 for the left and right halves of the array, making the middle element of each subarray the root of its respective subtree.
@@ -336,7 +373,7 @@ What is the purpose of balancing a Binary Search Tree?
* The final tree will be a valid BST with the given sorted array as its inorder traversal.
* Here's an example construction of a BST using the values 8, 3, 10, 1, 6, 14, 4, 7, and 13:
-#### Example:
+### Example:
* Sorted Array - 1, 3, 4, 6, 7, 8, 10, 13, 14
* Create the root node with value 8.
* Insert 3: Move to the left child of the root (value 3).
@@ -359,7 +396,7 @@ The constructed BST:
```
-#### Pseudocode:
+### Pseudocode:
```cpp
function insert(root, value):
@@ -380,12 +417,15 @@ for each value in values:
root = insert(root, value)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(logn)
---
-### Problem 7 Check if a binary tree is a binary search tree
+## Problem 7 Check if a binary tree is a binary search tree
+
+
+### Check if a binary tree is a binary search tree
To check if a binary tree is a binary search tree (BST), you can perform an inorder traversal of the tree and ensure that the values encountered during the traversal are in ascending order. Here's how you can do it:
@@ -394,7 +434,7 @@ To check if a binary tree is a binary search tree (BST), you can perform an inor
+
+
+```cpp
+Node delete(Node root, int K){
+ if(root == NULL) return NULL;
+
+ if(root.data == K){
+ if(root.left == NULL && root.right == NULL)
+ return NULL;
+ if(root.left || root.right){
+ if(root.left == NULL) return root.right;
+ if(root.right == NULL) return root.left;
+ }
+
+ Node temp = root.left;
+ while(temp.right != NULL){
+ temp = temp.right;
+ }
+ root.data = temp.data;
+ root.left = delete(root.left, temp.data);
+ return root;
+ }
+ else if(root.left > K){
+ root.left = delete(root.left, K);
+ }
+ else{
+ root.right = delete(root.right, K);
+ }
+}
+```
+
+---
+
### Question
What is the purpose of balancing a Binary Search Tree?
-
-**Choices**
+### Choices
- [ ] To make it visually appealing
- [ ] To ensure all nodes have the same value
- [x] To maintain efficient search, insert, and delete operations
- [ ] Balancing is not necessary in a Binary Search Tree
-
---
-### Problem 6 Construct a binary search tree
+## Problem 6 Construct a binary search tree
+
+### Construct BST from sorted array of unique elements:
-#### Approach:
+### Approach:
* Find the middle element of the sorted array.
* Create a new node with this middle element as the root of the tree.
* Recursively repeat steps 1 and 2 for the left and right halves of the array, making the middle element of each subarray the root of its respective subtree.
@@ -336,7 +373,7 @@ What is the purpose of balancing a Binary Search Tree?
* The final tree will be a valid BST with the given sorted array as its inorder traversal.
* Here's an example construction of a BST using the values 8, 3, 10, 1, 6, 14, 4, 7, and 13:
-#### Example:
+### Example:
* Sorted Array - 1, 3, 4, 6, 7, 8, 10, 13, 14
* Create the root node with value 8.
* Insert 3: Move to the left child of the root (value 3).
@@ -359,7 +396,7 @@ The constructed BST:
```
-#### Pseudocode:
+### Pseudocode:
```cpp
function insert(root, value):
@@ -380,12 +417,15 @@ for each value in values:
root = insert(root, value)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
**Space Complexity:** O(logn)
---
-### Problem 7 Check if a binary tree is a binary search tree
+## Problem 7 Check if a binary tree is a binary search tree
+
+
+### Check if a binary tree is a binary search tree
To check if a binary tree is a binary search tree (BST), you can perform an inorder traversal of the tree and ensure that the values encountered during the traversal are in ascending order. Here's how you can do it:
@@ -394,7 +434,7 @@ To check if a binary tree is a binary search tree (BST), you can perform an inor
 -#### Approach:
+### Approach:
* Perform an inorder traversal of the binary tree.
* During the traversal, keep track of the previously visited node's value.
* At each step, compare the current node's value with the previously visited node's value.
@@ -403,7 +443,7 @@ To check if a binary tree is a binary search tree (BST), you can perform an inor
-**Example:**
+### Example:
Suppose we have the following binary tree:
```cpp
4
@@ -423,6 +463,8 @@ Suppose we have the following binary tree:
* Since there's a violation, the tree is not a BST.
---
+
+
### Question
Check where the given binary tree is a Binary Search Tree.
@@ -434,22 +476,21 @@ Check where the given binary tree is a Binary Search Tree.
1 3 4 7
```
-**Choices**
+### Choices
- [ ] Yes, It is a Binary Search Tree
- [x] No, It is not a Binary Search Tree
- [ ] May be
- [ ] Not sure
-**Explanation:**
+---
+
+### Explanation:
No, It is not a Binary Search Tree.
The node with the value 4 should not be on the right sub of the root node, since the root is 5, the node has to be placed on left subtree.
----
-
-
### Pseudocode:
```cpp
function isBST(root):
@@ -479,6 +520,6 @@ function isBST(root):
return inorderTraversal(root)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
-**Space Complexity:** O(N)
\ No newline at end of file
+**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md b/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md
index 5ff3a70..c594e52 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md
@@ -1,220 +1,147 @@
# Advanced DSA : Trees 4: LCA
+
+## Agenda
+
+1. Kth smallest element in BST
+2. Node to Root Path in a given Tree
+3. LCA in Binary Tree
+4. LCA in Binary Search Tree
+
+
---
-## Understanding Binary Trees and Binary Search Trees
+## Problem 1 Finding the kth Smallest Element in a Binary Search Tree
+
+
+### Problem Statement
+
+Given a Binary Search Tree and a positive integer k, find the kth smallest element in the BST.
-### Binary Trees
+### Approach 1
-A Binary Tree is a hierarchical data structure composed of nodes, where each node has at most two children: a left child and a right child. The top node is called the root, and nodes without children are called leaves.
+We can use inorder traversal and store elements in an array, then return (k-1)th element.
+**T.C:** O(N)
+**S.C:** O(N)
-### Binary Search Trees (BSTs)
+### Approach 2
+The **`Inorder Traversal`** of a BST visits the nodes in ascending order. Therefore, by performing an inorder traversal and keeping track of the count of visited nodes, we can identify the kth smallest element when the count matches k. Basically instead of storing elements, we can just keep the track of count.
+**T.C:** O(N)
+**S.C:** O(Height)
-A Binary Search Tree is a type of binary tree with an additional property: for each node, all nodes in its left subtree have values smaller than the node's value, and all nodes in its right subtree have values greater than the node's value.
+```cpp
+count = 0;
+result = -infinity;
+function inorderTraversal(Node node, k) {
+ if (node == null) {
+ return;
+ }
+
+ // Traverse the left subtree
+ inorderTraversal(node.left, k);
+
+ // Increment count for each node visited
+ count++;
+
+ // If count equals k, we've found the kth smallest element
+ if (count == k) {
+ result = node.val;
+ return; // Stop the traversal
+ }
+
+ // Only proceed to the right subtree if we haven't found the kth smallest element
+ if (result == -infinity) {
+ inorderTraversal(node.right, k);
+ }
+}
+
+//Once "inorderTraversal" function completes, "result" variable shall hold the answer.
+```
---
-### Problem 1 Finding the kth Smallest Element in a Binary Search Tree
+## Problem 2 Morris Traversal
-Given a Binary Search Tree and a positive integer k, the problem is to find the kth smallest element in the BST.
+### Introduction:
+Morris Traversal is a clever method used to walk through binary trees without needing extra memory structures like stacks or queues. This technique not only saves memory but also provides an interesting way to explore trees.
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
+### Idea:
-### In-Order Traversal storing elements in array(Brute Force):
+Morris Traversal works by making use of the empty spaces in the tree's structure to create temporary links between nodes. This process threads the tree, allowing traversal without relying on recursion or additional memory.
-#### Algorithm
-1. Initialize a binary search tree (BST) as root.
-2. Iterate through the elements of the array and insert each element into the BST.
-3. Perform an in-order traversal of the BST to collect the elements in sorted order.
-4. Access the Kth element from the sorted elements list.
-5. Return the Kth element as the Kth smallest element.
-#### Pseudocode:
-```java
-// Define a TreeNode structure
-Struct TreeNode:
- val
- left
- right
+### In-Order Morris Traversal Dry Run:
-// Function to find the Kth smallest element in a BST
-Function findKthSmallestElement(arr, k):
- If arr is empty:
- Return None // Array is empty, no elements to find
+Lets take an Example and understand the traversal better.
- Root = null // Initialize the root of the binary search tree
+To Perform Inorder traversal, We need to visit **Left-Data-Right**
- // Step 1: Create a binary search tree (BST) from the array
- For each element in arr:
- Root = insert(Root, element)
+
- SortedElements = [] // Initialize an empty list to store sorted elements
+The root 6 has no left child, So `print 6`, then move towards the right child.
- // Step 2: Perform an in-order traversal of the BST
- InorderTraversal(Root, SortedElements)
+From node 8, it has no left child, So `print 8`, then move to the right child.
- // Step 3: Return the Kth element from the sorted elements list
- If 1 <= k <= length(SortedElements):
- Return SortedElements[k - 1] // Subtract 1 because indices are 0-based
- Else:
- Return None // Handle the case when k is out of bounds
+On 29, there is a left child. So the left subtree needs to be visited before 29.
-// Function to insert a value into a BST
-Function insert(root, value):
- If root is null:
- Return TreeNode(value) // Create a new node with the given value
+> The Problem here is "If we go to the left node, do we have a way to come to 29 ?"
- If value < root.val:
- root.left = insert(root.left, value) // Insert into the left subtree
- Else:
- root.right = insert(root.right, value) // Insert into the right subtree
+ > During recursion, we recusively call the function, once the function call is over, then we will move back to the root, using the stack memory.
+> While print 6 and moving to 8, We know that, we dont need to visit 6 again, But on 29, we need to come back.
- Return root
+So we need to secure a way to come back.
-// Function to perform an in-order traversal of the BST
-Function InorderTraversal(root, result):
- If root is null:
- Return
+Now focus on this particular tree alone, and find the last node to be visited during the In-order traversal.
- // Step 4: Perform an in-order traversal recursively
- InorderTraversal(root.left, result)
- Append root.val to result
- InorderTraversal(root.right, result)
+
-// Example usage:
-Elements = [12, 3, 7, 15, 9, 20]
-K = 3 // Find the 3rd smallest element
-Result = findKthSmallestElement(Elements, K)
+That is 25. So, Before moving to 20, we will secure a way, from 25 to the current node 29, like the below.
-If Result is not null:
- Output "The Kth smallest element is: " + Result
-Else:
- Output "Invalid value of K: " + K
+
-```
+After making the connecting, move to 20.
-#### In-Order Traversal Approach(Count Method):
-The in-order traversal of a BST visits the nodes in ascending order. Therefore, by performing an in-order traversal and keeping track of the count of visited nodes, we can identify the kth smallest element when the count matches k.
+Now, 20 has a left child. So before printing 20, need to visit the left node.
-#### Example: Finding the 3rd Smallest Element in a BST
+
-**BST:**
-```java
- 4
- / \
- 2 6
- / \ / \
-1 3 5 7
-```
+> Lets ask the same question here as well, "If we go to the left node, do we have a way to come to 20 ?"
+> No, So lets do the same process, Connect the Last node of the inorder traversal to the current node like the below
-**Scenario:**
-We want to find the 3rd smallest element in the given BST.
+
-**Solution:**
-* Perform an in-order traversal of the BST:
-* In-order traversal: 1, 2, 3, 4, 5, 6, 7
-* The 3rd smallest element is 3.
+The same process for the node 5 as well.
+
-#### Pseudocode:
-Here's a simplified pseudocode representation of finding the kth smallest element using in-order traversal:
-```java
-function findKthSmallest(root, k):
- count = 0
- stack = []
- while stack or root:
- while root:
- stack.append(root)
- root = root.left
-
- root = stack.pop()
- count += 1
-
- if count == k:
- return root.val
-
- root = root.right
-```
+On node 9, there is no left child, `print 9` then move to right child.
+On node 10, there is no left child, `print 10` then move to right child.
-#### Analysis:
+On node 13, there is no left child, `print 13` then move to right child.
-The in-order traversal visits every node once, making the time complexity of this algorithm $O(n)$, where n is the number of nodes in the BST. The space complexity is $O(h)$, where h is the height of the BST, due to the stack used for traversal.
+> Here is the main catch, Visually we can see that we are visiting 5 for the second time, But how do we realise programically ?
+lets do the same process, and see how it works,
----
-### Problem 2 Morris Traversal
-
-#### Morris Traversal Approach:
-Morris Traversal takes advantage of unused null pointers in the tree structure to link nodes temporarily, effectively threading the tree. By doing so, it enables us to traverse the tree in a specific order without requiring a stack or recursion.
-
-#### In-Order Morris Traversal:
-
-* Start at the root.
-* Initialize the current node as the root.
-* While the current node is not null:
- * If the current node's left child is null, print the current node's value and move to the right child.
- * If the current node's left child is not null:
- * Find the rightmost node in the left subtree.
- * Make the current node the right child of the rightmost node.
- * Move to the left child of the current node.
-* Repeat the process until the current node becomes null.
-
-#### Pre-Order Morris Traversal:
-
-* Start at the root.
-* Initialize the current node as the root.
-* While the current node is not null:
- * Print the current node's value.
- * If the current node's left child is null, move to the right child.
- * If the current node's left child is not null:
- * Find the rightmost node in the left subtree.
- * Make the current node the right child of the rightmost node.
- * Move to the left child of the current node.
-* Repeat the process until the current node becomes null.
-
-
-**Example:**
-```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-We will carefully go through each step:
+> 5 has left child, so need to visit its left child, before printing 5. need to secure a path from the last node of the inorder traversal of the left subtree.
+> Here is the main thing we can notice, when trying to make a connection, there is connection which is already established.
-- **Step 1: Start at the root node, which is 1.**
- 1. Initialize current pointer as current = 1.
+`This is how, we can figure out the left subtree is already visited`
-- **Step 2: At node 1:**
- 1. Check if the left subtree of the current node is null.
- 2. Since the left subtree of 1 is not null, find the rightmost node in the left subtree. This is node 5.
- 3. Create a thread (temporary link) from 5 to the current node (1): 5 -> 1.
- 4. Update the current node to its left child: current = 2.
+> After this, we will break the connection which we used to come back.
-- **Step 3: At node 2:**
- 1. Check if the left subtree of the current node is null.
- 2. The left subtree of 2 is not null, so find the rightmost node in the left subtree of 2, which is 5.
- 3. Remove the thread from 5 to 1 (undoing the link created earlier).
- 4. Print the current node's value, which is 2.
- 5. Move to the right child of the current node: current = 3
+
-- **Step 4: At node 3:**
- 1. Check if the left subtree of the current node is null.
- 2. The left subtree of 3 is null, so print the current node's value, which is 3.
- 3. Move to the right child of the current node (null): current = None.
+The same process goes for the rest of the nodes as well!
-- **Step 5:** Since the current node is now None, we've reached the end of the traversal.
- 1. The Morris Inorder Traversal of the binary tree 1 -> 2 -> 4 -> 5 -> 3 allows us to visit all the nodes in ascending order without using additional data structures or modifying the tree's structure. It's an efficient way to perform an inorder traversal.
+
-#### Pseudocode Example (In-Order):
+### Pseudocode:
```java
function morrisInOrderTraversal(root):
@@ -237,152 +164,55 @@ function morrisInOrderTraversal(root):
```
-#### Analysis:
+### Analysis:
Morris Traversal eliminates the need for an explicit stack, leading to a constant space complexity of $O(1)$. The time complexity for traversing the entire tree remains $O(n)$, where n is the number of nodes.
---
+
+
### Question
What is the primary advantage of Morris Traversal for binary trees?
-
-**Choices**
+### Choices
- [ ] It uses an auxiliary stack to save memory.
-- [ ] It guarantees the fastest traversal among all traversal methods.
- [ ] It allows for traversal in reverse order (right-to-left).
- [x] It achieves memory-efficient traversal without using additional data structures.
-
---
-### Problem 3 Finding an element
+## We are all connected
-#### Approach:
-Finding an element in a binary tree involves traversing the tree in a systematic way to search for the desired value. We'll focus on a common approach known as depth-first search (DFS), which includes pre-order, in-order, and post-order traversal methods.
+### Problem Statement
+It is said that we all **humans** are related through some **common ancestor** at some point of time. Assume that a person can have **0, 1 or 2** **children** **only**.
-#### Algorithm:
-1. Start at the root node of the binary tree.
-2. If the root node is null (indicating an empty tree), return False (element not found).
-3. Check if the value of the current node matches the target value:
-4. If they are equal, return True (element found).
-5. Recursively search for the target element in the left subtree by calling the function with the left child node.
-6. Recursively search for the target element in the right subtree by calling the function with the right child node.
-7. If the element is found in either the left or right subtree (or both), return True.
-8. If the element is not found in either subtree, return False.
+Given the Binary tree **A** representing the family tree, discover the earliest common family member who connects two given people **B and C** in a family tree.
-#### Example:
+### Example
```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-**Dry Run:**
-1. Start at the root (1).
-2. Check if it matches the target (3) - No.
-3. Move to the left child (2).
-4. Check if it matches the target (3) - No.
-5. Move to the left child (4).
-6. Check if it matches the target (3) - No.
-7. Move to the right child (null).
-8. Move back to 4's parent (2).
-9. Move to the right child (5).
-10. Check if it matches the target (3) - No.
-11. Move to the left child (null).
-12. Move back to 5's parent (2).
-13. Move back to 2's parent (1).
-14. Check if it matches the target (3) - Yes, found!
-15. Finish the search.
-
-#### Pseudocode Example:
-
-```java
-function findElement(root, target)
- if root is null
- return False // Element not found in an empty tree
-
- if root.value is equal to target
- return True // Element found at the current node
-
- // Recursively search in the left subtree
- found_in_left = findElement(root.left, target)
-
- // Recursively search in the right subtree
- found_in_right = findElement(root.right, target)
-
- // Return True if found in either left or right subtree
- return found_in_left OR found_in_right
+ Ram
+ / \
+ Shyam Bob
+ / \ \
+Dholu Bholu Satish
+
+-> Find LCA of Dholu and Bob
+-> Answer = Ram
```
-
-#### Analysis:
-The time complexity of finding an element in a binary tree using DFS depends on the height of the tree. In the worst case, it's O(n), where n is the number of nodes in the tree. The space complexity is determined by the depth of the recursion stack.
-
-
----
-### Problem 4 Path from root to node in Binary Tree
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach:
-To find the path from the root to a specific node, we'll leverage depth-first search (DFS), a versatile traversal method that includes pre-order, in-order, and post-order traversal techniques.
-
-#### DFS Pre-Order Traversal for Finding Path:
-
-1. Initialize an empty list path to store the path.
-2. Define a recursive function findPath(root, target, path):
-3. If root is null, return False.
-4. If root matches the target, append it to path and return True.
-5. Recursively call findPath on the left subtree and right subtree.
-6. If either subtree returns True, append root to path and return True.
-7. Start the search from the root node by calling findPath(root, target, path).
-8. If the search returns True, reverse the path list to get the path from root to target.
-9. Return the reversed path.
-
-#### Pseudocode Example (DFS Pre-Order):
-
-```java
-function findPath(root, target):
- if root is null:
- return false // Element not found in an empty tree
-
- if root.value == target:
- list.add(root) // Add the current node to the list (path found)
- return true; // Element found
-
- res = findPath(root -> left, target) OR findPath(root -> right, target)
-
- if res == true:
- list.add(root) // Add the current node to the list (part of the path)
-
- return res;
-
-// Reverse the list to get the answer (the path from root to target)
-
-```
-#### Analysis:
-The time complexity of finding the path from the root to a node using DFS depends on the height of the tree. In the worst case, it's O(n), where n is the number of nodes in the tree. The space complexity is determined by the depth of the recursion stack and the length of the path.
+### Simplified Problem
+Let's simplify the problem where we are only working with numbers and let's formally define the problem statement.
---
-### Question
-What is the primary benefit of using depth-first search (DFS) for finding the path from the root to a specific node in a Binary Tree?
+## Problem 3 LCA
-**Choices**
-- [ ] DFS guarantees the shortest path between the root and the target node.
-- [ ] DFS ensures that the tree remains balanced during traversal.
-- [ ] DFS enables efficient path finding with a time complexity of O(log n).
-- [x] DFS allows us to explore the structure of the tree while tracking visited nodes.
----
-### Problem 5 finding the Lowest Common Ancestor (LCA) of two nodes
+The LCA is a crucial concept with applications in genealogy research, network routing, and more. Let's explore the intricacies of finding the LCA in a binary tree.
-#### Approach:
+### Approach:
To find the LCA of two nodes in a binary tree, we'll utilize a recursive approach that capitalizes on the tree's structure. The LCA is the deepest node that has one of the nodes in its left subtree and the other node in its right subtree.
-#### Recursive Algorithm for LCA:
+### Recursive Algorithm for LCA:
* Start at the root of the binary tree.
* If the root is null or matches either of the target nodes, return the root as the LCA.
@@ -392,7 +222,7 @@ To find the LCA of two nodes in a binary tree, we'll utilize a recursive approac
* If both target nodes are found in the same subtree, continue the search in that subtree.
-**Example**:
+### Example:
```java
1
/ \
@@ -418,7 +248,7 @@ To find the LCA of two nodes in a binary tree, we'll utilize a recursive approac
13. Return node 2 as the Lowest Common Ancestor (LCA).
-#### Pseudocode Example:
+### Pseudocode Example:
```java
function findLCA(root, node1, node2):
@@ -438,16 +268,20 @@ function findLCA(root, node1, node2):
return right_lca # LCA found in the right subtree
```
-#### Analysis:
+### Analysis:
The time complexity of finding the LCA in a binary tree using this recursive approach is O(n), where n is the number of nodes in the tree. The space complexity is determined by the depth of the recursion stack.
---
-### Problem 6 Lowest Common Ancestor (LCA) in a Binary Search Tree (BST)
+## Problem 4 Lowest Common Ancestor (LCA) in a Binary Search Tree (BST)
+
+
+### Introduction:
+Hello, everyone! Today, we're going to explore a specialized case of finding the Lowest Common Ancestor (LCA) in a data structure known as a Binary Search Tree (BST). The LCA operation is essential for understanding relationships between nodes in a tree, and in a BST, it becomes even more efficient due to the inherent properties of the structure. Let's dive into the process of finding the LCA in a BST.
-#### Approach:
+### Approach:
To find the LCA of two nodes in a Binary Search Tree, we'll utilize the properties of BSTs that make traversal and comparison more efficient.
-#### Algorithm for Finding LCA in a BST:
+### Algorithm for Finding LCA in a BST:
* Start at the root of the BST.
* Compare the values of the root node, node1, and node2.
@@ -456,7 +290,7 @@ To find the LCA of two nodes in a Binary Search Tree, we'll utilize the properti
* If one node is smaller and the other is larger than the root's value, or if either node matches the root's value, the root is the LCA.
* Repeat steps 2-5 in the chosen subtree until the LCA is found.
-#### Example: Finding LCA in a Binary Search Tree
+### Example: Finding LCA in a Binary Search Tree
**BST:**
```java
@@ -487,7 +321,7 @@ Let's find the LCA of nodes 4 and 7 in this BST:
4. The current node (6) is the LCA of nodes 4 and 7.
5. So, in this example, the LCA of nodes 4 and 7 in the BST is node 6.
-#### Pseudocode Example:
+### Pseudocode Example:
```java
function findLCA(root, node1, node2):
@@ -508,219 +342,5 @@ function findLCA(root, node1, node2):
return null // If no LCA is found (unlikely in a valid BST)
```
-#### Analysis:
+### Analysis:
The time complexity of finding the LCA in a BST is O(h), where h is the height of the BST. In a balanced BST, the height is log(n), making the LCA operation highly efficient. The space complexity is determined by the depth of the recursion stack.
-
-
----
-### Problem 7 In-time and Out-time of Binary Tree
-
-
-#### Approach:
-The Interval Assignment technique involves three main steps: DFS traversal, interval assignment, and construction of the rooted tree.
-
-:::warning
-Please take some time to think about the further solution approach on your own before reading further.....
-:::
-
-#### DFS Traversal and Interval Assignment:
-
-* Start a DFS traversal of the tree from any chosen starting node.
-* As nodes are visited, assign start times when a node is entered and finish times when the traversal returns from that node. These times define intervals for each node.
-#### Constructing the Rooted Tree:
-
-1. From the DFS traversal, we have a collection of intervals (start and finish times) for each node.
-2. Choose the node with the smallest start time as the root of the rooted tree.
-3. For each remaining node:
- 1. Find the node with the largest start time that is still smaller than the current node's finish time. This node becomes the parent of the current node in the rooted tree.
- 2. Repeat this process for all nodes.
-
----
-### Question
-What is the significance of in-time and out-time values in DFS traversal?
-
-**Choices**
-- [ ] They indicate the number of times each node is visited during the traversal.
-- [ ] They represent the depth of each node in the tree.
-- [x] They help create hierarchical visualizations of trees.
-- [ ] They are used to determine the balance of the tree.
-
-
-
-**Example:**
-```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-1. We initialize the global time variable to 1.
-2. We traverse the tree using Depth-First Search (DFS):
-3. Starting at Node 1:
-4. In-Time for Node 1 is recorded as 1.
-5. We recursively visit the left child, Node 2.
-6. At Node 2:
-7. In-Time for Node 2 is recorded as 2.
-8. We recursively visit the left child, Node 4.
-9. At Node 4:
-10. In-Time for Node 4 is recorded as 3.
-11. Since Node 4 has no further children, we record its Out-Time as 5.
-12. Now, we return to Node 2:
-13. We recursively visit the right child, Node 5.
-14. At Node 5:
-15. In-Time for Node 5 is recorded as 8.
-16. Since Node 5 has no further children, we record its Out-Time as 10
-17. We return to Node 2 and record its Out-Time as 11.
-18. We return to Node 1 and recursively visit its right child, Node 3.
-19. At Node 3:
-20. In-Time for Node 3 is recorded as 12.
-21. We recursively visit its right child, but it's null.
-22. We record the Out-Time for Node 3 as 14.
-23. Finally, we return to Node 1 and record its Out-Time as 15.
-
-**The in-time and out-time values are now calculated:**
-* Node 1 - In-Time: 1, Out-Time: 15
-* Node 2 - In-Time: 2, Out-Time: 11
-* Node 3 - In-Time: 12, Out-Time: 14
-* Node 4 - In-Time: 3, Out-Time: 5
-* Node 5 - In-Time: 8, Out-Time: 10
-
-#### Pseudocode
-```java
-function calculateInTimeOutTime(root):
- global time // A global variable to keep track of time
-
- // Initialize arrays to store in-time and out-time for each node
- inTime = [0] * (2 * n) // Assuming 'n' is the number of nodes in the tree
- outTime = [0] * (2 * n)
-
- // Helper function for DFS traversal
- function dfs(node):
- nonlocal time
-
- // Record the in-time for the current node and increment time
- inTime[node] = time
- time = time + 1
-
- // Recursively visit left child (if exists)
- if node.left is not null:
- dfs(node.left)
-
- // Recursively visit right child (if exists)
- if node.right is not null:
- dfs(node.right)
-
- // Record the out-time for the current node and increment time
- outTime[node] = time
- time = time + 1
-
- // Start DFS traversal from the root
- dfs(root)
-
-```
-
-
----
-### Problem 8 For multiple queries find LCA(x,y)
-
-#### Algorithm:
-1. Calculate In-Time and Out-Time for Each Node:
-2. First, calculate the in-time and out-time for each node in the binary tree as explained in a previous response.
-3. Answer LCA Queries:
-4. To find the LCA of multiple pairs of nodes (x, y):
-5. For each LCA query (x, y):
-6. Check if inTime[x] is less than or equal to inTime[y] and outTime[x] is greater than or equal to outTime[y]. If true, it means that node x is an ancestor of node y.
-7. Check if inTime[y] is less than or equal to inTime[x] and outTime[y] is greater than or equal to outTime[x]. If true, it means that node y is an ancestor of node x.
-8. If neither of the above conditions is met, it means that x and y have different ancestors.
-9. In such cases, move up the tree from the deeper node until you find a node that is at the same level as the shallower node. This node will be their LCA.
-
-#### Example
-```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-And we'll find the Lowest Common Ancestor (LCA) for a few pairs of nodes (x, y) using the in-time and out-time approach.
-
-* **Step 1: Calculate In-Time and Out-Time**
-#### Approach:
+### Approach:
* Perform an inorder traversal of the binary tree.
* During the traversal, keep track of the previously visited node's value.
* At each step, compare the current node's value with the previously visited node's value.
@@ -403,7 +443,7 @@ To check if a binary tree is a binary search tree (BST), you can perform an inor
-**Example:**
+### Example:
Suppose we have the following binary tree:
```cpp
4
@@ -423,6 +463,8 @@ Suppose we have the following binary tree:
* Since there's a violation, the tree is not a BST.
---
+
+
### Question
Check where the given binary tree is a Binary Search Tree.
@@ -434,22 +476,21 @@ Check where the given binary tree is a Binary Search Tree.
1 3 4 7
```
-**Choices**
+### Choices
- [ ] Yes, It is a Binary Search Tree
- [x] No, It is not a Binary Search Tree
- [ ] May be
- [ ] Not sure
-**Explanation:**
+---
+
+### Explanation:
No, It is not a Binary Search Tree.
The node with the value 4 should not be on the right sub of the root node, since the root is 5, the node has to be placed on left subtree.
----
-
-
### Pseudocode:
```cpp
function isBST(root):
@@ -479,6 +520,6 @@ function isBST(root):
return inorderTraversal(root)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N)
-**Space Complexity:** O(N)
\ No newline at end of file
+**Space Complexity:** O(N)
diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md b/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md
index 5ff3a70..c594e52 100644
--- a/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md
+++ b/Academy DSA Typed Notes/Advanced/DSA Trees 4 LCA + Morris Inorder Traversal.md
@@ -1,220 +1,147 @@
# Advanced DSA : Trees 4: LCA
+
+## Agenda
+
+1. Kth smallest element in BST
+2. Node to Root Path in a given Tree
+3. LCA in Binary Tree
+4. LCA in Binary Search Tree
+
+
---
-## Understanding Binary Trees and Binary Search Trees
+## Problem 1 Finding the kth Smallest Element in a Binary Search Tree
+
+
+### Problem Statement
+
+Given a Binary Search Tree and a positive integer k, find the kth smallest element in the BST.
-### Binary Trees
+### Approach 1
-A Binary Tree is a hierarchical data structure composed of nodes, where each node has at most two children: a left child and a right child. The top node is called the root, and nodes without children are called leaves.
+We can use inorder traversal and store elements in an array, then return (k-1)th element.
+**T.C:** O(N)
+**S.C:** O(N)
-### Binary Search Trees (BSTs)
+### Approach 2
+The **`Inorder Traversal`** of a BST visits the nodes in ascending order. Therefore, by performing an inorder traversal and keeping track of the count of visited nodes, we can identify the kth smallest element when the count matches k. Basically instead of storing elements, we can just keep the track of count.
+**T.C:** O(N)
+**S.C:** O(Height)
-A Binary Search Tree is a type of binary tree with an additional property: for each node, all nodes in its left subtree have values smaller than the node's value, and all nodes in its right subtree have values greater than the node's value.
+```cpp
+count = 0;
+result = -infinity;
+function inorderTraversal(Node node, k) {
+ if (node == null) {
+ return;
+ }
+
+ // Traverse the left subtree
+ inorderTraversal(node.left, k);
+
+ // Increment count for each node visited
+ count++;
+
+ // If count equals k, we've found the kth smallest element
+ if (count == k) {
+ result = node.val;
+ return; // Stop the traversal
+ }
+
+ // Only proceed to the right subtree if we haven't found the kth smallest element
+ if (result == -infinity) {
+ inorderTraversal(node.right, k);
+ }
+}
+
+//Once "inorderTraversal" function completes, "result" variable shall hold the answer.
+```
---
-### Problem 1 Finding the kth Smallest Element in a Binary Search Tree
+## Problem 2 Morris Traversal
-Given a Binary Search Tree and a positive integer k, the problem is to find the kth smallest element in the BST.
+### Introduction:
+Morris Traversal is a clever method used to walk through binary trees without needing extra memory structures like stacks or queues. This technique not only saves memory but also provides an interesting way to explore trees.
-:::warning
-Please take some time to think about the brute force approach on your own before reading further.....
-:::
+### Idea:
-### In-Order Traversal storing elements in array(Brute Force):
+Morris Traversal works by making use of the empty spaces in the tree's structure to create temporary links between nodes. This process threads the tree, allowing traversal without relying on recursion or additional memory.
-#### Algorithm
-1. Initialize a binary search tree (BST) as root.
-2. Iterate through the elements of the array and insert each element into the BST.
-3. Perform an in-order traversal of the BST to collect the elements in sorted order.
-4. Access the Kth element from the sorted elements list.
-5. Return the Kth element as the Kth smallest element.
-#### Pseudocode:
-```java
-// Define a TreeNode structure
-Struct TreeNode:
- val
- left
- right
+### In-Order Morris Traversal Dry Run:
-// Function to find the Kth smallest element in a BST
-Function findKthSmallestElement(arr, k):
- If arr is empty:
- Return None // Array is empty, no elements to find
+Lets take an Example and understand the traversal better.
- Root = null // Initialize the root of the binary search tree
+To Perform Inorder traversal, We need to visit **Left-Data-Right**
- // Step 1: Create a binary search tree (BST) from the array
- For each element in arr:
- Root = insert(Root, element)
+
- SortedElements = [] // Initialize an empty list to store sorted elements
+The root 6 has no left child, So `print 6`, then move towards the right child.
- // Step 2: Perform an in-order traversal of the BST
- InorderTraversal(Root, SortedElements)
+From node 8, it has no left child, So `print 8`, then move to the right child.
- // Step 3: Return the Kth element from the sorted elements list
- If 1 <= k <= length(SortedElements):
- Return SortedElements[k - 1] // Subtract 1 because indices are 0-based
- Else:
- Return None // Handle the case when k is out of bounds
+On 29, there is a left child. So the left subtree needs to be visited before 29.
-// Function to insert a value into a BST
-Function insert(root, value):
- If root is null:
- Return TreeNode(value) // Create a new node with the given value
+> The Problem here is "If we go to the left node, do we have a way to come to 29 ?"
- If value < root.val:
- root.left = insert(root.left, value) // Insert into the left subtree
- Else:
- root.right = insert(root.right, value) // Insert into the right subtree
+ > During recursion, we recusively call the function, once the function call is over, then we will move back to the root, using the stack memory.
+> While print 6 and moving to 8, We know that, we dont need to visit 6 again, But on 29, we need to come back.
- Return root
+So we need to secure a way to come back.
-// Function to perform an in-order traversal of the BST
-Function InorderTraversal(root, result):
- If root is null:
- Return
+Now focus on this particular tree alone, and find the last node to be visited during the In-order traversal.
- // Step 4: Perform an in-order traversal recursively
- InorderTraversal(root.left, result)
- Append root.val to result
- InorderTraversal(root.right, result)
+
-// Example usage:
-Elements = [12, 3, 7, 15, 9, 20]
-K = 3 // Find the 3rd smallest element
-Result = findKthSmallestElement(Elements, K)
+That is 25. So, Before moving to 20, we will secure a way, from 25 to the current node 29, like the below.
-If Result is not null:
- Output "The Kth smallest element is: " + Result
-Else:
- Output "Invalid value of K: " + K
+
-```
+After making the connecting, move to 20.
-#### In-Order Traversal Approach(Count Method):
-The in-order traversal of a BST visits the nodes in ascending order. Therefore, by performing an in-order traversal and keeping track of the count of visited nodes, we can identify the kth smallest element when the count matches k.
+Now, 20 has a left child. So before printing 20, need to visit the left node.
-#### Example: Finding the 3rd Smallest Element in a BST
+
-**BST:**
-```java
- 4
- / \
- 2 6
- / \ / \
-1 3 5 7
-```
+> Lets ask the same question here as well, "If we go to the left node, do we have a way to come to 20 ?"
+> No, So lets do the same process, Connect the Last node of the inorder traversal to the current node like the below
-**Scenario:**
-We want to find the 3rd smallest element in the given BST.
+
-**Solution:**
-* Perform an in-order traversal of the BST:
-* In-order traversal: 1, 2, 3, 4, 5, 6, 7
-* The 3rd smallest element is 3.
+The same process for the node 5 as well.
+
-#### Pseudocode:
-Here's a simplified pseudocode representation of finding the kth smallest element using in-order traversal:
-```java
-function findKthSmallest(root, k):
- count = 0
- stack = []
- while stack or root:
- while root:
- stack.append(root)
- root = root.left
-
- root = stack.pop()
- count += 1
-
- if count == k:
- return root.val
-
- root = root.right
-```
+On node 9, there is no left child, `print 9` then move to right child.
+On node 10, there is no left child, `print 10` then move to right child.
-#### Analysis:
+On node 13, there is no left child, `print 13` then move to right child.
-The in-order traversal visits every node once, making the time complexity of this algorithm $O(n)$, where n is the number of nodes in the BST. The space complexity is $O(h)$, where h is the height of the BST, due to the stack used for traversal.
+> Here is the main catch, Visually we can see that we are visiting 5 for the second time, But how do we realise programically ?
+lets do the same process, and see how it works,
----
-### Problem 2 Morris Traversal
-
-#### Morris Traversal Approach:
-Morris Traversal takes advantage of unused null pointers in the tree structure to link nodes temporarily, effectively threading the tree. By doing so, it enables us to traverse the tree in a specific order without requiring a stack or recursion.
-
-#### In-Order Morris Traversal:
-
-* Start at the root.
-* Initialize the current node as the root.
-* While the current node is not null:
- * If the current node's left child is null, print the current node's value and move to the right child.
- * If the current node's left child is not null:
- * Find the rightmost node in the left subtree.
- * Make the current node the right child of the rightmost node.
- * Move to the left child of the current node.
-* Repeat the process until the current node becomes null.
-
-#### Pre-Order Morris Traversal:
-
-* Start at the root.
-* Initialize the current node as the root.
-* While the current node is not null:
- * Print the current node's value.
- * If the current node's left child is null, move to the right child.
- * If the current node's left child is not null:
- * Find the rightmost node in the left subtree.
- * Make the current node the right child of the rightmost node.
- * Move to the left child of the current node.
-* Repeat the process until the current node becomes null.
-
-
-**Example:**
-```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-We will carefully go through each step:
+> 5 has left child, so need to visit its left child, before printing 5. need to secure a path from the last node of the inorder traversal of the left subtree.
+> Here is the main thing we can notice, when trying to make a connection, there is connection which is already established.
-- **Step 1: Start at the root node, which is 1.**
- 1. Initialize current pointer as current = 1.
+`This is how, we can figure out the left subtree is already visited`
-- **Step 2: At node 1:**
- 1. Check if the left subtree of the current node is null.
- 2. Since the left subtree of 1 is not null, find the rightmost node in the left subtree. This is node 5.
- 3. Create a thread (temporary link) from 5 to the current node (1): 5 -> 1.
- 4. Update the current node to its left child: current = 2.
+> After this, we will break the connection which we used to come back.
-- **Step 3: At node 2:**
- 1. Check if the left subtree of the current node is null.
- 2. The left subtree of 2 is not null, so find the rightmost node in the left subtree of 2, which is 5.
- 3. Remove the thread from 5 to 1 (undoing the link created earlier).
- 4. Print the current node's value, which is 2.
- 5. Move to the right child of the current node: current = 3
+
-- **Step 4: At node 3:**
- 1. Check if the left subtree of the current node is null.
- 2. The left subtree of 3 is null, so print the current node's value, which is 3.
- 3. Move to the right child of the current node (null): current = None.
+The same process goes for the rest of the nodes as well!
-- **Step 5:** Since the current node is now None, we've reached the end of the traversal.
- 1. The Morris Inorder Traversal of the binary tree 1 -> 2 -> 4 -> 5 -> 3 allows us to visit all the nodes in ascending order without using additional data structures or modifying the tree's structure. It's an efficient way to perform an inorder traversal.
+
-#### Pseudocode Example (In-Order):
+### Pseudocode:
```java
function morrisInOrderTraversal(root):
@@ -237,152 +164,55 @@ function morrisInOrderTraversal(root):
```
-#### Analysis:
+### Analysis:
Morris Traversal eliminates the need for an explicit stack, leading to a constant space complexity of $O(1)$. The time complexity for traversing the entire tree remains $O(n)$, where n is the number of nodes.
---
+
+
### Question
What is the primary advantage of Morris Traversal for binary trees?
-
-**Choices**
+### Choices
- [ ] It uses an auxiliary stack to save memory.
-- [ ] It guarantees the fastest traversal among all traversal methods.
- [ ] It allows for traversal in reverse order (right-to-left).
- [x] It achieves memory-efficient traversal without using additional data structures.
-
---
-### Problem 3 Finding an element
+## We are all connected
-#### Approach:
-Finding an element in a binary tree involves traversing the tree in a systematic way to search for the desired value. We'll focus on a common approach known as depth-first search (DFS), which includes pre-order, in-order, and post-order traversal methods.
+### Problem Statement
+It is said that we all **humans** are related through some **common ancestor** at some point of time. Assume that a person can have **0, 1 or 2** **children** **only**.
-#### Algorithm:
-1. Start at the root node of the binary tree.
-2. If the root node is null (indicating an empty tree), return False (element not found).
-3. Check if the value of the current node matches the target value:
-4. If they are equal, return True (element found).
-5. Recursively search for the target element in the left subtree by calling the function with the left child node.
-6. Recursively search for the target element in the right subtree by calling the function with the right child node.
-7. If the element is found in either the left or right subtree (or both), return True.
-8. If the element is not found in either subtree, return False.
+Given the Binary tree **A** representing the family tree, discover the earliest common family member who connects two given people **B and C** in a family tree.
-#### Example:
+### Example
```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-**Dry Run:**
-1. Start at the root (1).
-2. Check if it matches the target (3) - No.
-3. Move to the left child (2).
-4. Check if it matches the target (3) - No.
-5. Move to the left child (4).
-6. Check if it matches the target (3) - No.
-7. Move to the right child (null).
-8. Move back to 4's parent (2).
-9. Move to the right child (5).
-10. Check if it matches the target (3) - No.
-11. Move to the left child (null).
-12. Move back to 5's parent (2).
-13. Move back to 2's parent (1).
-14. Check if it matches the target (3) - Yes, found!
-15. Finish the search.
-
-#### Pseudocode Example:
-
-```java
-function findElement(root, target)
- if root is null
- return False // Element not found in an empty tree
-
- if root.value is equal to target
- return True // Element found at the current node
-
- // Recursively search in the left subtree
- found_in_left = findElement(root.left, target)
-
- // Recursively search in the right subtree
- found_in_right = findElement(root.right, target)
-
- // Return True if found in either left or right subtree
- return found_in_left OR found_in_right
+ Ram
+ / \
+ Shyam Bob
+ / \ \
+Dholu Bholu Satish
+
+-> Find LCA of Dholu and Bob
+-> Answer = Ram
```
-
-#### Analysis:
-The time complexity of finding an element in a binary tree using DFS depends on the height of the tree. In the worst case, it's O(n), where n is the number of nodes in the tree. The space complexity is determined by the depth of the recursion stack.
-
-
----
-### Problem 4 Path from root to node in Binary Tree
-
-:::warning
-Please take some time to think about the solution approach on your own before reading further.....
-:::
-
-#### Approach:
-To find the path from the root to a specific node, we'll leverage depth-first search (DFS), a versatile traversal method that includes pre-order, in-order, and post-order traversal techniques.
-
-#### DFS Pre-Order Traversal for Finding Path:
-
-1. Initialize an empty list path to store the path.
-2. Define a recursive function findPath(root, target, path):
-3. If root is null, return False.
-4. If root matches the target, append it to path and return True.
-5. Recursively call findPath on the left subtree and right subtree.
-6. If either subtree returns True, append root to path and return True.
-7. Start the search from the root node by calling findPath(root, target, path).
-8. If the search returns True, reverse the path list to get the path from root to target.
-9. Return the reversed path.
-
-#### Pseudocode Example (DFS Pre-Order):
-
-```java
-function findPath(root, target):
- if root is null:
- return false // Element not found in an empty tree
-
- if root.value == target:
- list.add(root) // Add the current node to the list (path found)
- return true; // Element found
-
- res = findPath(root -> left, target) OR findPath(root -> right, target)
-
- if res == true:
- list.add(root) // Add the current node to the list (part of the path)
-
- return res;
-
-// Reverse the list to get the answer (the path from root to target)
-
-```
-#### Analysis:
-The time complexity of finding the path from the root to a node using DFS depends on the height of the tree. In the worst case, it's O(n), where n is the number of nodes in the tree. The space complexity is determined by the depth of the recursion stack and the length of the path.
+### Simplified Problem
+Let's simplify the problem where we are only working with numbers and let's formally define the problem statement.
---
-### Question
-What is the primary benefit of using depth-first search (DFS) for finding the path from the root to a specific node in a Binary Tree?
+## Problem 3 LCA
-**Choices**
-- [ ] DFS guarantees the shortest path between the root and the target node.
-- [ ] DFS ensures that the tree remains balanced during traversal.
-- [ ] DFS enables efficient path finding with a time complexity of O(log n).
-- [x] DFS allows us to explore the structure of the tree while tracking visited nodes.
----
-### Problem 5 finding the Lowest Common Ancestor (LCA) of two nodes
+The LCA is a crucial concept with applications in genealogy research, network routing, and more. Let's explore the intricacies of finding the LCA in a binary tree.
-#### Approach:
+### Approach:
To find the LCA of two nodes in a binary tree, we'll utilize a recursive approach that capitalizes on the tree's structure. The LCA is the deepest node that has one of the nodes in its left subtree and the other node in its right subtree.
-#### Recursive Algorithm for LCA:
+### Recursive Algorithm for LCA:
* Start at the root of the binary tree.
* If the root is null or matches either of the target nodes, return the root as the LCA.
@@ -392,7 +222,7 @@ To find the LCA of two nodes in a binary tree, we'll utilize a recursive approac
* If both target nodes are found in the same subtree, continue the search in that subtree.
-**Example**:
+### Example:
```java
1
/ \
@@ -418,7 +248,7 @@ To find the LCA of two nodes in a binary tree, we'll utilize a recursive approac
13. Return node 2 as the Lowest Common Ancestor (LCA).
-#### Pseudocode Example:
+### Pseudocode Example:
```java
function findLCA(root, node1, node2):
@@ -438,16 +268,20 @@ function findLCA(root, node1, node2):
return right_lca # LCA found in the right subtree
```
-#### Analysis:
+### Analysis:
The time complexity of finding the LCA in a binary tree using this recursive approach is O(n), where n is the number of nodes in the tree. The space complexity is determined by the depth of the recursion stack.
---
-### Problem 6 Lowest Common Ancestor (LCA) in a Binary Search Tree (BST)
+## Problem 4 Lowest Common Ancestor (LCA) in a Binary Search Tree (BST)
+
+
+### Introduction:
+Hello, everyone! Today, we're going to explore a specialized case of finding the Lowest Common Ancestor (LCA) in a data structure known as a Binary Search Tree (BST). The LCA operation is essential for understanding relationships between nodes in a tree, and in a BST, it becomes even more efficient due to the inherent properties of the structure. Let's dive into the process of finding the LCA in a BST.
-#### Approach:
+### Approach:
To find the LCA of two nodes in a Binary Search Tree, we'll utilize the properties of BSTs that make traversal and comparison more efficient.
-#### Algorithm for Finding LCA in a BST:
+### Algorithm for Finding LCA in a BST:
* Start at the root of the BST.
* Compare the values of the root node, node1, and node2.
@@ -456,7 +290,7 @@ To find the LCA of two nodes in a Binary Search Tree, we'll utilize the properti
* If one node is smaller and the other is larger than the root's value, or if either node matches the root's value, the root is the LCA.
* Repeat steps 2-5 in the chosen subtree until the LCA is found.
-#### Example: Finding LCA in a Binary Search Tree
+### Example: Finding LCA in a Binary Search Tree
**BST:**
```java
@@ -487,7 +321,7 @@ Let's find the LCA of nodes 4 and 7 in this BST:
4. The current node (6) is the LCA of nodes 4 and 7.
5. So, in this example, the LCA of nodes 4 and 7 in the BST is node 6.
-#### Pseudocode Example:
+### Pseudocode Example:
```java
function findLCA(root, node1, node2):
@@ -508,219 +342,5 @@ function findLCA(root, node1, node2):
return null // If no LCA is found (unlikely in a valid BST)
```
-#### Analysis:
+### Analysis:
The time complexity of finding the LCA in a BST is O(h), where h is the height of the BST. In a balanced BST, the height is log(n), making the LCA operation highly efficient. The space complexity is determined by the depth of the recursion stack.
-
-
----
-### Problem 7 In-time and Out-time of Binary Tree
-
-
-#### Approach:
-The Interval Assignment technique involves three main steps: DFS traversal, interval assignment, and construction of the rooted tree.
-
-:::warning
-Please take some time to think about the further solution approach on your own before reading further.....
-:::
-
-#### DFS Traversal and Interval Assignment:
-
-* Start a DFS traversal of the tree from any chosen starting node.
-* As nodes are visited, assign start times when a node is entered and finish times when the traversal returns from that node. These times define intervals for each node.
-#### Constructing the Rooted Tree:
-
-1. From the DFS traversal, we have a collection of intervals (start and finish times) for each node.
-2. Choose the node with the smallest start time as the root of the rooted tree.
-3. For each remaining node:
- 1. Find the node with the largest start time that is still smaller than the current node's finish time. This node becomes the parent of the current node in the rooted tree.
- 2. Repeat this process for all nodes.
-
----
-### Question
-What is the significance of in-time and out-time values in DFS traversal?
-
-**Choices**
-- [ ] They indicate the number of times each node is visited during the traversal.
-- [ ] They represent the depth of each node in the tree.
-- [x] They help create hierarchical visualizations of trees.
-- [ ] They are used to determine the balance of the tree.
-
-
-
-**Example:**
-```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-1. We initialize the global time variable to 1.
-2. We traverse the tree using Depth-First Search (DFS):
-3. Starting at Node 1:
-4. In-Time for Node 1 is recorded as 1.
-5. We recursively visit the left child, Node 2.
-6. At Node 2:
-7. In-Time for Node 2 is recorded as 2.
-8. We recursively visit the left child, Node 4.
-9. At Node 4:
-10. In-Time for Node 4 is recorded as 3.
-11. Since Node 4 has no further children, we record its Out-Time as 5.
-12. Now, we return to Node 2:
-13. We recursively visit the right child, Node 5.
-14. At Node 5:
-15. In-Time for Node 5 is recorded as 8.
-16. Since Node 5 has no further children, we record its Out-Time as 10
-17. We return to Node 2 and record its Out-Time as 11.
-18. We return to Node 1 and recursively visit its right child, Node 3.
-19. At Node 3:
-20. In-Time for Node 3 is recorded as 12.
-21. We recursively visit its right child, but it's null.
-22. We record the Out-Time for Node 3 as 14.
-23. Finally, we return to Node 1 and record its Out-Time as 15.
-
-**The in-time and out-time values are now calculated:**
-* Node 1 - In-Time: 1, Out-Time: 15
-* Node 2 - In-Time: 2, Out-Time: 11
-* Node 3 - In-Time: 12, Out-Time: 14
-* Node 4 - In-Time: 3, Out-Time: 5
-* Node 5 - In-Time: 8, Out-Time: 10
-
-#### Pseudocode
-```java
-function calculateInTimeOutTime(root):
- global time // A global variable to keep track of time
-
- // Initialize arrays to store in-time and out-time for each node
- inTime = [0] * (2 * n) // Assuming 'n' is the number of nodes in the tree
- outTime = [0] * (2 * n)
-
- // Helper function for DFS traversal
- function dfs(node):
- nonlocal time
-
- // Record the in-time for the current node and increment time
- inTime[node] = time
- time = time + 1
-
- // Recursively visit left child (if exists)
- if node.left is not null:
- dfs(node.left)
-
- // Recursively visit right child (if exists)
- if node.right is not null:
- dfs(node.right)
-
- // Record the out-time for the current node and increment time
- outTime[node] = time
- time = time + 1
-
- // Start DFS traversal from the root
- dfs(root)
-
-```
-
-
----
-### Problem 8 For multiple queries find LCA(x,y)
-
-#### Algorithm:
-1. Calculate In-Time and Out-Time for Each Node:
-2. First, calculate the in-time and out-time for each node in the binary tree as explained in a previous response.
-3. Answer LCA Queries:
-4. To find the LCA of multiple pairs of nodes (x, y):
-5. For each LCA query (x, y):
-6. Check if inTime[x] is less than or equal to inTime[y] and outTime[x] is greater than or equal to outTime[y]. If true, it means that node x is an ancestor of node y.
-7. Check if inTime[y] is less than or equal to inTime[x] and outTime[y] is greater than or equal to outTime[x]. If true, it means that node y is an ancestor of node x.
-8. If neither of the above conditions is met, it means that x and y have different ancestors.
-9. In such cases, move up the tree from the deeper node until you find a node that is at the same level as the shallower node. This node will be their LCA.
-
-#### Example
-```java
- 1
- / \
- 2 3
- / \
- 4 5
-```
-And we'll find the Lowest Common Ancestor (LCA) for a few pairs of nodes (x, y) using the in-time and out-time approach.
-
-* **Step 1: Calculate In-Time and Out-Time** We've already calculated the in-time and out-time values for this tree as follows: - 1. Node 1 - In-Time: 1, Out-Time: 10 - 2. Node 2 - In-Time: 2, Out-Time: 7 - 3. Node 3 - In-Time: 8, Out-Time: 9 - 4. Node 4 - In-Time: 3, Out-Time: 4 - 5. Node 5 - In-Time: 5, Out-Time: 6 - -* **Step 2: Find LCA for Pairs** - * Find LCA(4, 5): - * Check in-time and out-time: - * In-Time(4) <= In-Time(5) and Out-Time(4) >= Out-Time(5) is true. - * So, LCA(4, 5) is 4. - * Find LCA(2, 3): - * Check in-time and out-time: - * In-Time(2) <= In-Time(3) and Out-Time(2) >= Out-Time(3) is false. - * Now, bring both nodes to the same depth: - * Move 2 up once: 2 is now at the same depth as 3. - * Continue moving both nodes up: - * LCA(2, 3) is 1. - * Find LCA(4, 3): - * Check in-time and out-time: - * In-Time(4) <= In-Time(3) and Out-Time(4) >= Out-Time(3) is false. - * Now, bring both nodes to the same depth: - * Move 4 up once: 4 is now at the same depth as 3. - * Continue moving both nodes up: - * LCA(4, 3) is 1. - * Find LCA(5, 2): - * Check in-time and out-time: - * In-Time(5) <= In-Time(2) and Out-Time(5) >= Out-Time(2) is false. - * Now, bring both nodes to the same depth: - * Move 5 up once: 5 is now at the same depth as 2. - * Continue moving both nodes up: - * LCA(5, 2) is 1. - -#### Pseudocode: -```java -function findLCA(x, y): - if inTime[x] <= inTime[y] and outTime[x] >= outTime[y]: - return x # x is an ancestor of y - - if inTime[y] <= inTime[x] and outTime[y] >= outTime[x]: - return y # y is an ancestor of x - - # Move x and y up the tree to the same depth - while depth[x] > depth[y]: - x = parent[x] - - while depth[y] > depth[x]: - y = parent[y] - - # Move x and y up simultaneously until they meet at the LCA - while x != y: - x = parent[x] - y = parent[y] - - return x # LCA found -``` - ---- -### Question -What is the primary purpose of constructing a rooted tree using the start and finish times obtained during the DFS traversal? - -**Choices** -- [ ] To optimize the tree structure for faster traversal. -- [ ] To visualize the tree with nodes arranged in increasing order. -- [x] To efficiently represent the hierarchy and relationships within the tree. -- [ ] To eliminate the need for recursion in tree traversal. - ---- -### Observations - -* **In-Order Traversal:**
It visits Binary Search Tree (BST) nodes in ascending order, enabling efficient kth smallest element retrieval. -* **Morris Traversal:**
An efficient memory-saving tree traversal method with O(1) space complexity. -* **Path from Root:**
DFS traversal is used to find the path from the root to a node, with space complexity tied to recursion depth. -* **Lowest Common Ancestor (LCA) in Tree:**
LCA is found through recursion with O(n) time complexity and stack space. -* **In-Time & Out-Time:**
These values in DFS help create hierarchical visualizations of trees. -* **Interval Assignment Visualization:**
Provides a visual hierarchy for analyzing complex structures in various fields. -* **Finding LCA for Multiple Queries:**
LCA retrieval for multiple pairs involves adjusting node depths until they meet. - diff --git a/Academy DSA Typed Notes/Advanced/DSA Trees 5 Problems on Trees.md b/Academy DSA Typed Notes/Advanced/DSA Trees 5 Problems on Trees.md index b942262..967da51 100644 --- a/Academy DSA Typed Notes/Advanced/DSA Trees 5 Problems on Trees.md +++ b/Academy DSA Typed Notes/Advanced/DSA Trees 5 Problems on Trees.md @@ -1,259 +1,12 @@ # Advanced DSA : Trees 5: Problems on Trees ---- -## Problem 1 Invert Binary Tree - -Given the root node of a binary tree, write a function to invert the tree. - -**Example** -Original Binary Tree : -```plaintext - 1 - / \ - 2 3 - / \ - 4 5 -``` -After Inverting the Binary Tree : -```plaintext - 1 - / \ - 3 2 - / \ - 5 4 -``` ---- -### Question -Select the correct inverted binary tree for this given tree: - -``` - 4 - / \ - 2 7 - / \ \ -1 3 9 -``` -**Choices** - -- [ ] **Option 1:** - -``` - 4 - / \ - 7 2 - / \ / -9 3 1 -``` - -- [ ] **Option 2:** - -``` - 4 - / \ - 7 2 - \ / \ - 3 1 9 -``` - -- [ ] **Option 3:** - -``` - 4 - / \ - 2 7 - \ / \ - 1 9 3 -``` - -- [x] **Option 4:** - -``` - 4 - / \ - 7 2 - / \ / -9 1 3 -``` - -:::warning -Please take some time to think about the solution approach on your own before reading further..... -::: - -**Solution** -To solve this problem,we can recursively invert the binary tree by swapping the left and right subtrees for each node. - -```cpp -void invertTree(TreeNode * root) { - if (root == nullptr) { - return; // Return if the root is null - } - - // Use a temporary variable to swap left and right subtrees - TreeNode * temp = root -> left; - root -> left = root -> right; - root -> right = temp; - - // Recursively invert the left and right subtrees - invertTree(root -> left); - invertTree(root -> right); -} - -``` - -#### Complexity -**Time Complexity:** O(N) -**Space Complexity:** O(H) - ---- -### Problem 2 Equal Tree Partition - -Given the root of a binary tree, return ***true*** if the tree can be split into two non-empty subtrees with equal sums, or ***false*** otherwise. - -**Example 1** -```cpp -Input: - 5 - / \ - 10 10 - / \ - 2 3 - -Output: True -``` - -**Explanation:** - -```cpp - 5 - / - 10 - -Sum: 15 -``` - -```cpp - 10 - / \ - 2 3 - -Sum: 15 -``` -**Example 2** -```cpp -Input: - 1 - / \ - 2 10 - / \ - 2 15 -Output: false - -``` -**Explanation:** -There is no way to split the tree into two subtrees with equal sums. - - ---- -### Question -Check whether the given tree can be split into two non-empty subtrees with equal sums or not. - -```cpp - 5 - / \ - 10 10 - / \ - 20 3 - / - 8 -``` - -**Choices** -- [x] Yes, It is possible. -- [ ] It is impossible. - - -**Explanation:** - -Yes It is possible to split the tree into two non-empty subtrees with sum 28. - -Sub-Tree 1: -```cpp - 5 - / \ - 10 10 - \ - 3 - -``` - -Sub-Tree 2: -```cpp - 20 - / - 8 -``` - -:::warning -Please take some time to think about the solution approach on your own before reading further..... -::: - -**Solution** - -1. **Total Sum Check**: -If the total sum of all nodes in the binary tree is odd, it is impossible to divide the tree into two subtrees with equal sums. This is because the sum of two equal values is always even, and if the total sum is odd, it cannot be divided equally into two parts. -2. **Subtree Sum Check**: -If we can find a subtree in the binary tree with a sum equal to half of the total sum, we can split the tree into two equal partitions by removing the edge leading to the root of that subtree. This means that we don't necessarily need to compare sums of all possible subtrees, but we can look for a single subtree that meets the subtree sum check condition. - -#### Pseudocode -```cpp -int sum(TreeNode * root) { - if (!root) { - return 0; - } - return sum(root -> left) + sum(root -> right) + root -> val; -} - -bool hasSubtreeWithHalfSum(TreeNode * root, int totalSum) { - if (!root) { - return false; - } - - int leftSum = sum(root -> left); - int rightSum = sum(root -> right); - - if ((leftSum == totalSum / 2 || rightSum == totalSum / 2) || hasSubtreeWithHalfSum(root -> left, totalSum) || hasSubtreeWithHalfSum(root -> right, totalSum)) { - return true; - } - - return false; -} - -bool isEqualTreePartition(TreeNode * root) { - if (!root) { - return false; // An empty tree cannot be partitioned - } - - int totalSum = sum(root); - - if (totalSum % 2 == 1) { - return false; // If the total sum is odd, partition is not possible - } - - return hasSubtreeWithHalfSum(root, totalSum); -} -``` - -#### Complexity -**Time Complexity:** O(N) -**Space Complexity:** O(H) - ---- -### Problem 3 Next Pointer in Binary Tree +## Problem 1 Next Pointer in Binary Tree +### Problem Statement Given a perfect binary tree initially with all next pointers set to nullptr, modify the tree in-place to connect each node's next pointer to the next node in the same level from left to right, following an in-order traversal. -**Example** +### Example ```cpp Input: 1 @@ -271,11 +24,9 @@ Output : ``` -:::warning -Please take some time to think about the bruteforce approach on your own before reading further..... -::: -#### Brute force solution + +### Brute force solution **Level order Traversal** : 1. We check if the binary tree is empty; if so, we return the root since there's nothing to connect. 2. A queue is created for level order traversal, initialized with the root node. @@ -289,52 +40,52 @@ Please take some time to think about the bruteforce approach on your own before 7. Finally, the function returns the modified root of the binary tree, which now has next pointers connecting nodes at the same level, except for the last node in each level, whose next pointer remains nullptr. -#### Pseudocode : +### Pseudocode : ```cpp -Node * connect(Node * root) { - // Check if the tree is empty - if (root is null) { - return null; - } +function connect(Node root) { + // Check if the tree is empty + if (root is null) { + return null; + } + + // Create a queue and enqueue the root + queue
 @@ -519,7 +533,7 @@ Amount of water stored between any two walls `A[i]` and `A[j]` = `min(A[i], A[j]
> **Note:** height = `min(A[i], A[j])`, as water can be stored upto minimum height of the wall, and width = `(j - i)`, i.e., the difference between the position of walls.
-#### Brute Force Apporach:
+### Brute Force Apporach:
*Choose all the pair of walls, calculate the amount of water stored between them and find the maximum.*
- **Time Complexity:**
@@ -529,20 +543,22 @@ O(1), as no additional space is required.
---
+
+
### Question
What is the water trapped between 2 walls at index L and R.
Array A gives the heights of buildings
Chose the correct answer
-**Choices**
+### Choices
- [x] (R - L) * min(A[L], A[r])
- [ ] (R - L)* max(A[L], A[r])
- [ ] (R - L + 1) * min(A[L], A[r])
- [ ] (R - L + 1) * max(A[L], A[r])
-**Explanation:**
+### Explanation:
The answer is **(R - L) * min(A[L], A[r])**.
@@ -553,12 +569,7 @@ width = (R - L).
---
-
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
-
-### Container with most Water Two Pointer Approach
+## Container with most Water Two Pointer Approach
- Since `area = height * width`. To achieve the maximum area, we should find the maximum values for height and width.
@@ -623,18 +634,18 @@ A[] =
After this, moving any of i or j will yield width as 0. Hence, we stop the execution and final ans is 24.
-#### Pseudocode:
+### Pseudocode:
```java
i = 0, j = n - 1;
while (i < j) {
- area = min(A[i], A[j]) * (j - 1);
- if (A[i] < A[j]) {
- i++;
- } else if (A[i] > A[j]) {
- j--;
- } else {
- i++, j--; // Doesn't matter if we move only i or j or both
- }
+ area = min(A[i], A[j]) * (j - 1);
+ if (A[i] < A[j]) {
+ i++;
+ } else if (A[i] > A[j]) {
+ j--;
+ } else {
+ i++, j--; // Doesn't matter if we move only i or j or both
+ }
}
return area;
```
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 1 One Dimentional.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 1 One Dimentional.md
new file mode 100644
index 0000000..caf6205
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 1 One Dimentional.md
@@ -0,0 +1,461 @@
+# DP 1: One Dimensional
+
+---
+title: Mock Interview awareness
+description:
+duration: 600
+card_type: cue_card
+---
+
+
+**`Introduction:`** Greetings to everyone as we embark on the final module of our DSA curriculum before the first mock interview.
+**`Appreciation:`** A big thank you to all for your consistent efforts throughout this journey.
+**`Motivation:`** It’s time for one last push to excel in the DSA module. We’re facing the challenging yet rewarding topic of Dynamic Programming (DP).
+**`Content Overview:`** We will explore optimizing recursive calls and delve into knapsack problems. These skills are crucial not just for the mock interview but also for real-world job interviews.
+**`Encouragement:`** Let’s make the most of this final phase in our DSA journey. I encourage everyone to actively participate and ask questions.
+**`Team Spirit:`** Together, we will master DP and turn it into a strong asset in our skillset.
+
+
+
+---
+title: Fibonacci Series
+description: Introduction to fibonacci Series
+duration: 300
+card_type: cue_card
+---
+
+### fibonacci Series
+`0 1 1 2 3 5 8 13 21 ...`
+
+### fibonacci Expresion
+* `fib(n) = fib(n-1) + fib(n-2)`
+* base case for the fibonacci expression -> `fib(0) = 0; fib(1) = 1`
+
+### Psuedocode
+```java
+int fib(n){
+ if(n <= 1) return n;
+ return fib(n - 1) + (n - 2);
+}
+```
+> Time complexity for the above code : **O(2^N)**
+> Space Complexity for the above code : **O(N)**
+
+---
+title: Problem 1 Fibonacci Series
+description: Solving Fibonacci Series using Dynamic Programming
+duration: 900
+card_type: cue_card
+---
+
+### Properties of Dynamic Programming
+* **Optimal Substructure** - i.e. solving a problem by solving smaller subproblems
+* **Overlapping Subproblems** - solving some subproblems multiple times
+
+### Solution for Dynamic Programming
+* Store the information about already solved sub-problem and use it
+
+
+### Psuedocode of Fibonacci series using dynamic Programming
+```java=
+int f[N + 1] // intialize it with -1
+
+int fib(n){
+ if(N <= 1) return n;
+
+ // if already solved, don't repeat
+ if(f[N] != -1) return f[N];
+
+ // store it
+ f[N] = fib(n - 1) + (n - 2);
+ return f[N];
+}
+```
+**Two main operations performed in the above code of dynamic programming:**
+* If we have already solved a problem just return the solution, don't repeat the step
+* If not solved, solve and store the solution
+
+### Dry Run
+
+
+
+We're going to figure out what **`fib(5)`** is using a method called recursion, and we'll keep track of our answers in an array. Here's how it works, step by step:
+
+* **Starting Point:**
+We want to find out what fib(5) is. Our array, where we store our results, starts with -1 in every spot because we haven't calculated anything yet.
+
+* **Breaking it Down:**
+To get fib(5), we first need to know fib(4) and fib(3).
+
+* **Going Deeper:**
+For fib(4), we need fib(3) and fib(2). And for fib(3) (the one we saw earlier), we also need fib(2) and fib(1).
+
+* **Even Deeper:**
+To find fib(2), we look at fib(1) and fib(0).
+
+* **Simple Answers:**
+Now, fib(1) and fib(0) are easy; they are 1 and 0. We use these to find out fib(2), which is 1 (0 + 1). Store it before moving forward.
+
+* **Building Up:**
+We keep using these small answers to find the bigger ones. If we already know an answer (like fib(2)), we don't have to calculate it again; we just use the answer from our array.
+
+By the end, we'll have the answer to fib(5), and all the smaller fib numbers stored in our array!
+
+### Time and Space Complexity
+
+**Time Complexity for the above code is O(N)** and **space complexity is O(N)**. Thus, we were able to reduce the time complexity from O(2^N) to O(N) using dynamic programing
+
+---
+title: Dynamic Programming Types
+description: Bottom up Approach
+duration: 900
+card_type: cue_card
+---
+
+### Types of DP Solution:
+*Dynamic programming solution can be of two types*:
+* **`Top-Down`** [Also know as **Memoization**]
+ * It is a recursive solution
+ * We start with the biggest problem and keep on breaking it till we reach the base case.
+ * Then store answers of already evaluated problems.
+
+* **`Bottom-Up`**
+ * It is an iterative solution
+ * We start with the smallest problem, solve it and store its result.
+ * Then we keep on moving to the bigger problems and use the already calculated results from sub-problems.
+
+
+### Bottom Up Approach for Fibonacci series
+### Psuedocode
+```java
+int fib[N + 1];
+
+fib[0] = 0;
+fib[1] = 1;
+
+for(i = 2, i <= N; i++){
+ fib[i] = fib[i - 1] + fib[i - 2];
+}
+```
+
+### Complexity
+**Time Complexity:** O(N)
+**Space Complexity:** O(N)
+> Through this approach we were able to eliminate recursive stack.
+
+### Further optimising the Space Complexity
+
+If seen closely, the above approach can be optimised by using just simple variables instead of an array. In this way, we can further optimize the space.
+
+### Pseudocode
+```java
+int a = 0; int b = 1;
+int c;
+for(int i = 2; i <= N; i++){
+ c = a + b;
+ a = b;
+ b = c;
+}
+```
+> In the above code we were able to optimize the space complexity to O(1).
+
+---
+title: Quiz 1
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+What is the purpose of memoization in dynamic programming?
+# Choices
+
+- [ ] To minimize the space complexity of the algorithm
+- [x] To store and reuse solutions to subproblems
+- [ ] To calculate results of all calls
+- [ ] To improve the readability of the code
+
+---
+title: Quiz 2
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+Which approach is considered as an iterative process?
+# Choices
+- [ ] Top-down approach
+- [x] Bottom-up approach
+- [ ] Both are iterative
+- [ ] Neither is iterative
+
+
+---
+title: Problem 2 Climbing Staircase
+description: Question 2 (No. of ways to reach Nth stair)
+duration: 900
+card_type: cue_card
+---
+
+
+### Problem Statement
+*Calculate the number of ways to reach the Nth stair. You can take 1 step at a time or 2 steps at a time.*
+
+
+
+**`CASE 1: (number of stairs = 1)`**
+{1}
+
@@ -519,7 +533,7 @@ Amount of water stored between any two walls `A[i]` and `A[j]` = `min(A[i], A[j]
> **Note:** height = `min(A[i], A[j])`, as water can be stored upto minimum height of the wall, and width = `(j - i)`, i.e., the difference between the position of walls.
-#### Brute Force Apporach:
+### Brute Force Apporach:
*Choose all the pair of walls, calculate the amount of water stored between them and find the maximum.*
- **Time Complexity:**
@@ -529,20 +543,22 @@ O(1), as no additional space is required.
---
+
+
### Question
What is the water trapped between 2 walls at index L and R.
Array A gives the heights of buildings
Chose the correct answer
-**Choices**
+### Choices
- [x] (R - L) * min(A[L], A[r])
- [ ] (R - L)* max(A[L], A[r])
- [ ] (R - L + 1) * min(A[L], A[r])
- [ ] (R - L + 1) * max(A[L], A[r])
-**Explanation:**
+### Explanation:
The answer is **(R - L) * min(A[L], A[r])**.
@@ -553,12 +569,7 @@ width = (R - L).
---
-
-:::warning
-Please take some time to think about the optimised approach on your own before reading further.....
-:::
-
-### Container with most Water Two Pointer Approach
+## Container with most Water Two Pointer Approach
- Since `area = height * width`. To achieve the maximum area, we should find the maximum values for height and width.
@@ -623,18 +634,18 @@ A[] =
After this, moving any of i or j will yield width as 0. Hence, we stop the execution and final ans is 24.
-#### Pseudocode:
+### Pseudocode:
```java
i = 0, j = n - 1;
while (i < j) {
- area = min(A[i], A[j]) * (j - 1);
- if (A[i] < A[j]) {
- i++;
- } else if (A[i] > A[j]) {
- j--;
- } else {
- i++, j--; // Doesn't matter if we move only i or j or both
- }
+ area = min(A[i], A[j]) * (j - 1);
+ if (A[i] < A[j]) {
+ i++;
+ } else if (A[i] > A[j]) {
+ j--;
+ } else {
+ i++, j--; // Doesn't matter if we move only i or j or both
+ }
}
return area;
```
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 1 One Dimentional.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 1 One Dimentional.md
new file mode 100644
index 0000000..caf6205
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 1 One Dimentional.md
@@ -0,0 +1,461 @@
+# DP 1: One Dimensional
+
+---
+title: Mock Interview awareness
+description:
+duration: 600
+card_type: cue_card
+---
+
+
+**`Introduction:`** Greetings to everyone as we embark on the final module of our DSA curriculum before the first mock interview.
+**`Appreciation:`** A big thank you to all for your consistent efforts throughout this journey.
+**`Motivation:`** It’s time for one last push to excel in the DSA module. We’re facing the challenging yet rewarding topic of Dynamic Programming (DP).
+**`Content Overview:`** We will explore optimizing recursive calls and delve into knapsack problems. These skills are crucial not just for the mock interview but also for real-world job interviews.
+**`Encouragement:`** Let’s make the most of this final phase in our DSA journey. I encourage everyone to actively participate and ask questions.
+**`Team Spirit:`** Together, we will master DP and turn it into a strong asset in our skillset.
+
+
+
+---
+title: Fibonacci Series
+description: Introduction to fibonacci Series
+duration: 300
+card_type: cue_card
+---
+
+### fibonacci Series
+`0 1 1 2 3 5 8 13 21 ...`
+
+### fibonacci Expresion
+* `fib(n) = fib(n-1) + fib(n-2)`
+* base case for the fibonacci expression -> `fib(0) = 0; fib(1) = 1`
+
+### Psuedocode
+```java
+int fib(n){
+ if(n <= 1) return n;
+ return fib(n - 1) + (n - 2);
+}
+```
+> Time complexity for the above code : **O(2^N)**
+> Space Complexity for the above code : **O(N)**
+
+---
+title: Problem 1 Fibonacci Series
+description: Solving Fibonacci Series using Dynamic Programming
+duration: 900
+card_type: cue_card
+---
+
+### Properties of Dynamic Programming
+* **Optimal Substructure** - i.e. solving a problem by solving smaller subproblems
+* **Overlapping Subproblems** - solving some subproblems multiple times
+
+### Solution for Dynamic Programming
+* Store the information about already solved sub-problem and use it
+
+
+### Psuedocode of Fibonacci series using dynamic Programming
+```java=
+int f[N + 1] // intialize it with -1
+
+int fib(n){
+ if(N <= 1) return n;
+
+ // if already solved, don't repeat
+ if(f[N] != -1) return f[N];
+
+ // store it
+ f[N] = fib(n - 1) + (n - 2);
+ return f[N];
+}
+```
+**Two main operations performed in the above code of dynamic programming:**
+* If we have already solved a problem just return the solution, don't repeat the step
+* If not solved, solve and store the solution
+
+### Dry Run
+
+
+
+We're going to figure out what **`fib(5)`** is using a method called recursion, and we'll keep track of our answers in an array. Here's how it works, step by step:
+
+* **Starting Point:**
+We want to find out what fib(5) is. Our array, where we store our results, starts with -1 in every spot because we haven't calculated anything yet.
+
+* **Breaking it Down:**
+To get fib(5), we first need to know fib(4) and fib(3).
+
+* **Going Deeper:**
+For fib(4), we need fib(3) and fib(2). And for fib(3) (the one we saw earlier), we also need fib(2) and fib(1).
+
+* **Even Deeper:**
+To find fib(2), we look at fib(1) and fib(0).
+
+* **Simple Answers:**
+Now, fib(1) and fib(0) are easy; they are 1 and 0. We use these to find out fib(2), which is 1 (0 + 1). Store it before moving forward.
+
+* **Building Up:**
+We keep using these small answers to find the bigger ones. If we already know an answer (like fib(2)), we don't have to calculate it again; we just use the answer from our array.
+
+By the end, we'll have the answer to fib(5), and all the smaller fib numbers stored in our array!
+
+### Time and Space Complexity
+
+**Time Complexity for the above code is O(N)** and **space complexity is O(N)**. Thus, we were able to reduce the time complexity from O(2^N) to O(N) using dynamic programing
+
+---
+title: Dynamic Programming Types
+description: Bottom up Approach
+duration: 900
+card_type: cue_card
+---
+
+### Types of DP Solution:
+*Dynamic programming solution can be of two types*:
+* **`Top-Down`** [Also know as **Memoization**]
+ * It is a recursive solution
+ * We start with the biggest problem and keep on breaking it till we reach the base case.
+ * Then store answers of already evaluated problems.
+
+* **`Bottom-Up`**
+ * It is an iterative solution
+ * We start with the smallest problem, solve it and store its result.
+ * Then we keep on moving to the bigger problems and use the already calculated results from sub-problems.
+
+
+### Bottom Up Approach for Fibonacci series
+### Psuedocode
+```java
+int fib[N + 1];
+
+fib[0] = 0;
+fib[1] = 1;
+
+for(i = 2, i <= N; i++){
+ fib[i] = fib[i - 1] + fib[i - 2];
+}
+```
+
+### Complexity
+**Time Complexity:** O(N)
+**Space Complexity:** O(N)
+> Through this approach we were able to eliminate recursive stack.
+
+### Further optimising the Space Complexity
+
+If seen closely, the above approach can be optimised by using just simple variables instead of an array. In this way, we can further optimize the space.
+
+### Pseudocode
+```java
+int a = 0; int b = 1;
+int c;
+for(int i = 2; i <= N; i++){
+ c = a + b;
+ a = b;
+ b = c;
+}
+```
+> In the above code we were able to optimize the space complexity to O(1).
+
+---
+title: Quiz 1
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+What is the purpose of memoization in dynamic programming?
+# Choices
+
+- [ ] To minimize the space complexity of the algorithm
+- [x] To store and reuse solutions to subproblems
+- [ ] To calculate results of all calls
+- [ ] To improve the readability of the code
+
+---
+title: Quiz 2
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+Which approach is considered as an iterative process?
+# Choices
+- [ ] Top-down approach
+- [x] Bottom-up approach
+- [ ] Both are iterative
+- [ ] Neither is iterative
+
+
+---
+title: Problem 2 Climbing Staircase
+description: Question 2 (No. of ways to reach Nth stair)
+duration: 900
+card_type: cue_card
+---
+
+
+### Problem Statement
+*Calculate the number of ways to reach the Nth stair. You can take 1 step at a time or 2 steps at a time.*
+
+
+
+**`CASE 1: (number of stairs = 1)`**
+{1}
+ +
+
+
+Number of ways to reach first stair : 1 (as shown in fig)
+
+
+**`CASE 2: (number of stairs = 2)`**
+
+{1, 1}
+{2}
+
+
+
+
+
+Number of ways to reach first stair : 1 (as shown in fig)
+
+
+**`CASE 2: (number of stairs = 2)`**
+
+{1, 1}
+{2}
+
+ +
+Number of ways to reach two stairs : 2 (as shown in fig)
+
+**`CASE 3: (number of stairs = 3)`**
+
+{1, 2}
+{1, 1, 1}
+{2, 1}
+
+
+
+Number of ways to reach two stairs : 2 (as shown in fig)
+
+**`CASE 3: (number of stairs = 3)`**
+
+{1, 2}
+{1, 1, 1}
+{2, 1}
+
+ +
+Number of ways to reach two stairs : 3 (as shown in fig)
+
+**`CASE 4: (number of stairs = 4)`**
+{1, 1, 2}
+{2, 2}
+{1, 2, 1}
+{1, 1, 1, 1}
+{2, 1, 1}
+
+
+
+---
+title: Quiz 3
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+In Stairs Problems, the result for N=4
+# Choices
+- [ ] 4
+- [x] 5
+- [ ] 6
+- [ ] 7
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+To reach 1st staircase : 1 way
+To reach 2nd staircase : 2 ways
+To reach 3rd staircase : 3 ways
+To reach 4th staircase : 5 ways
+
+---
+title: Problem 2 Climbing Staircase Approach
+description: Question 2 (No. of ways to reach Nth stair)
+duration: 900
+card_type: cue_card
+---
+
+### Approach
+
+We can come to 4th stair from 2nd and 3rd step.
+* If I get to know #steps to reach stair 3, we can take length 1 step and reach stair 4.
+* Similarly, if I get to know #steps to reach stair 2, we can take length 2 step and reach stair 4.
+
+
+
+Number of ways to reach two stairs : 3 (as shown in fig)
+
+**`CASE 4: (number of stairs = 4)`**
+{1, 1, 2}
+{2, 2}
+{1, 2, 1}
+{1, 1, 1, 1}
+{2, 1, 1}
+
+
+
+---
+title: Quiz 3
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+In Stairs Problems, the result for N=4
+# Choices
+- [ ] 4
+- [x] 5
+- [ ] 6
+- [ ] 7
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+To reach 1st staircase : 1 way
+To reach 2nd staircase : 2 ways
+To reach 3rd staircase : 3 ways
+To reach 4th staircase : 5 ways
+
+---
+title: Problem 2 Climbing Staircase Approach
+description: Question 2 (No. of ways to reach Nth stair)
+duration: 900
+card_type: cue_card
+---
+
+### Approach
+
+We can come to 4th stair from 2nd and 3rd step.
+* If I get to know #steps to reach stair 3, we can take length 1 step and reach stair 4.
+* Similarly, if I get to know #steps to reach stair 2, we can take length 2 step and reach stair 4.
+
+ +
+
+
+ +
+
+
+ +
+* Number of ways we can reach to the nth step is either by (n - 1) or (n - 2).
+* Answer will be summation of number of ways to reach (n - 1)th step + number of ways to reach (n - 2)th step
+
+We can see that the above has been deduced to fibonacii expression
+
+---
+title: Problem 3 Get Minimum Squares
+description: Minimum number of perfect squares required to get sum = N
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+*Find minimum number of perfect squares required to get sum = N. (duplicate squares are allowed)*
+
+*example 1 --> N = 6*
+
+sum 6 can be obtained by the addition of following squares:
+* `1^2+1^2+1^2+1^2+1^2+1^2`
+* `1^2+1^2+2^2` --> minimum number of squares is 3 in this case
+
+*example 2 --> N = 10*
+
+sum 10 can be obtained by the addition of following squares:
+* `1^2+1^2+..... 10 times`
+* `2^2 + 1^2..... 6 times`
+* `2^2 + 2^2 + 1^2 + 1^2`
+* `3^2 + 1^2 `--> minimum number of squares is 2 in this case
+
+*example 3 --> N = 9*
+
+sum 10 can be obtained by the addition of following squares:
+* `1^2+1^2+..... 9 times`
+* `2^2 + 1^2..... 5 times`
+* `2^2 + 2^2 + 1^2 `
+* `3^2` --> minimum number of squares is 1 in this case
+
+
+---
+title: Quiz 4
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+What is the minimum number of perfect squares required to get sum = 5. (duplicate squares are allowed)
+
+# Choices
+- [ ] 5
+- [ ] 1
+- [x] 2
+- [ ] 3
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+sum 5 can be obtained by the addition of following squares:
+* `1^2 + 1^2 + 1^2 + 1^2 + 1^2`
+* `2^2 + 1^2` --> minimum number of squares is 2 in this case
+
+
+---
+title: Get Minimum Squares Approach
+description: Minimum number of perfect squares required to get sum = N
+duration: 900
+card_type: cue_card
+---
+
+
+
+### Approach 1
+* Can we simply do **`N - (nearest perfect square)`** ?
+
+ * Verifying approach 1 with example N=12
+ * 12-9 (closest square) = 3
+ * 3-1 = 2
+ * 2-1 = 1
+ * 1-1 = 0
+ * We are using 4 perfect squares, whereas the minimum number of square is 3 (2^2 + 2^2 +2^2) so approach 1 is not useful in this case
+
+### Brute Force Approach
+* Try every possible way to form the sum using brute force to solve a example N = 12
+
+
+The above image shows all possiblities to achieve 12.
+
+Now, to get minimum sum of 12 we will find minimum square of 11 or minimum square of 8 or minimum square of 3 + 1.
+
+The above is a recursive problem where we can see overalapping subproblems, like for N=7.
+
+### Dynamic Programming Approach
+Here optimal structure has been obtained as well as overlapping subproblems
+
+So, we can say that
+`square(i) = 1 + min{ squares(i - x^2) for all x^2 <= i} `and base case is square[0] = 0
+
+### Psuedocode
+```java
+int dp[N + 1]; //initialise (-1)
+int psquares(int N, int dp[]){
+if(n == 0) return 0;
+if(dp[N] != -1) return dp[N];
+ans = int - max;
+for(x = 1; x * x <= N; x++){
+ans = min(ans, psquares(N - x^2)); // dp
+}
+dp[N] = 1 + ans;
+return dp[N];
+}
+```
+Time complexity for the above code is O(N(sqrt(N))) and space complexity is O(N).
+
+---
+title: ATM Minimum Note Dispenser
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem :
+**RBI** wants to reduce **paper usage** for money. Imagine you need to withdraw a specific amount of money from an ATM. The ATMs should be programmed to give you the least number of notes possible.
+
+The available notes in the ATM are **₹50, ₹30, and ₹5**. Your task is to figure out the **minimum number of notes** the ATM should give you for any amount of money you request, ensuring the ATM dispenses the exact amount you asked for.
+
+### Common Mistake :
+#### Greedy will fail...
+A greedy algorithm would start by taking the **largest denomination** note available and using as many of those as possible, then move to the next largest denomination, and continue in this way until the exact amount is dispensed.
+
+For example say you want ₹65, here the greedy approach would select **one** ₹50 note and **three** ₹5 notes, totaling **four** notes.
+
+However, the optimal solution is **two** ₹30 notes and **one** ₹5 note, totaling only **three** notes.
+
+
+
+### Intuition
+This is somewhat similar to the previous problem. Can we solve it too using Dynamic Programming ?
+
+### Dynamic Programming Approach
+Let's define the dynamic programming solution :
+
+- Let `DP[i] represent the minimum number of notes required to make sum N`
+- Initially `DP[i] = infinity`, and `DP[0] = 0`
+- Transition : `DP[i] = min(DP[i - 50], DP[i - 30], DP[i - 5])`
+
+### Psuedocode
+```java
+int dp[N + 1]; //initialise (-1)
+
+int minNotes(int N, int dp[]){
+ if(n == 0) return 0;
+ if(n < 0) return infinity ;
+ if(dp[N] != -1) return dp[N];
+ ans = infinity;
+
+ ans = min(ans, psquares(N - 50));
+ ans = min(ans, psquares(N - 30));
+ ans = min(ans, psquares(N - 5));
+
+ dp[N] = 1 + ans;
+ return dp[N];
+}
+```
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 2 Two Dimentional.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 2 Two Dimentional.md
new file mode 100644
index 0000000..0d2a8e7
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 2 Two Dimentional.md
@@ -0,0 +1,859 @@
+# DP 2: Two Dimensional
+
+---
+title: Data Backup Scheduler
+description:
+duration: 900
+card_type: cue_card
+---
+
+**Problem Statement:**
+You're the network administrator at a large company where daily data backups are crucial. Each backup affects the network differently, measured by a "load score" that reflects its impact on network performance.
+
+The challenge is to schedule these backups over a period of N days to ensure the network remains stable and efficient during business hours. The goal is to achieve the highest possible total load score, which indicates the significance of the data backed up, while ensuring that backups are not scheduled on consecutive days.
+
+Here’s an example of how you might approach this over any number of days, say N=10 days, with the following load scores:
+
+**Day 1:** **`Load score = 45`**
+**Day 2:** **`Load score = 55`**
+**Day 3:** **`Load score = 40`**
+**Day 4:** **`Load score = 65`**
+**Day 5:** **`Load score = 60`**
+**Day 6:** **`Load score = 35`**
+**Day 7:** **`Load score = 75`**
+**Day 8:** **`Load score = 50`**
+**Day 9:** **`Load score = 80`**
+**Day 10:** **`Load score = 70`**
+
+Select days - **`1, 3, 5, 7, 9`** to get max score of **`300`**.
+
+---
+title: Problem 1 Maximum Subsequence Sum
+description: Two Dimensional
+duration: 900
+card_type: cue_card
+---
+
+### Simplified Problem Statement
+
+#### The problem can be broken down to be said as :
+Find maximum subsequence sum from a given array, where selecting adjacent element is not allowed.
+
+### Examples
+Example 1: ar[] = {5, 4, 8}
+Output 1: 13. Since out of all possible non adjacent element subsequences, the subsequence (5, 8) will yield maximum sum. So the student should be absent on first and third day.
+
+Example 2: ar[] = {9, 4, 10, 12}
+Output 2: 21 (The student should be absent on days with 9 hours and 12 hours)
+
+
+---
+title: Quiz 1
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+Find maximum subsequence sum from `[10, 20, 30, 40]`, where selecting adjacent element is not allowed.
+
+# Choices
+- [ ] 70
+- [x] 60
+- [ ] 100
+- [ ] 50
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Maximum Subsequence is 60. Since, Out of all possible non adjacent element subsequences, the subsequence (20, 40) will yield maximum sum of 60.
+
+
+---
+title: Maximum Subsequence Sum Brute Force Approach
+description: Maximum Subsequence Sum Dynamic Programming Approach Top Down
+duration: 900
+card_type: cue_card
+---
+
+
+### Brute Force Approach
+- Consider all the valid subsequences **`(this a backtracking step)`**.
+- For creating subsequences, for every element we can make a choice, whether to select it or reject it.
+- Say, we start from right most element. If we keep it, then (n - 1)th element can't be considered, so jump to (n - 2)th. If we don't, then (n - 1)th element can be considered. So on...
+
+
+
+
+
+The above image shows tree which has all the choices of selection. Here we can see that the choices are overlapping.
+
+Moreover, as the problem can be broken into smaller problems and has overlapping sub problems, we can use **dynamic programming**.
+
+
+---
+title: Maximum Subsequence Sum Top Down Approach
+description: Maximum Subsequence Sum Dynamic Programming Approach Top Down
+duration: 900
+card_type: cue_card
+---
+
+### Top Down Approach
+So for **maxSum(i)** there are two options:
+* either we can select element present at index i
+ * if we select that element we will include its value ie ar[i] and the recursive call will be **maxSum(i-2)**
+* or we cannot select the element present at index i
+ * so in this case we will not include its value and will make recursive call which is **maxSum(i-1)**
+
+`dp[i] = stores the maximum value that can be obtained by selecting 0 to ith toy.`
+
+The maximum of the choice we make will give us the final answer
+
+### Psuedocode
+
+```cpp
+int dp[N] //initialize it with negative infinity
+
+// i will be initialised with N-1, i.e we start with the last element
+int maxSum(int []arr, i, dp[N]){
+ if(i < 0){
+ return 0
+ }
+ if(dp[i] != -infinity) {
+ return dp[i]
+ }
+ //Don't consider the ith element, in this case we can consider (i-1)th element
+ f1 = maxSum(arr, i - 1, dp);
+
+ //Consider the ith element, in this case we can't consider (i-1)th element, so we jump to (i-2)th element
+ f2 = arr[i] + maxSum(arr, i - 2, dp);
+
+ ans = max(f1, f2)
+
+ dp[i] = ans;
+
+ return ans
+}
+```
+
+### Time & Space Complexity
+
+**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
+**Space complexity:** O(N), because of dp array of size N.
+
+
+---
+title: Maximum Subsequence Sum Bottom Up Approach
+description: Two Dimensional
+duration: 900
+card_type: cue_card
+---
+
+### Problem 1
+**`dp[i] is defined as the maximum subsequence sum from [0 - i] provided no adjacent elements are selected`**
+
+arr = {9, 4, 13, 24}
+
+We can start from arr[0] and we have two choices: either we can select arr[0] or reject.
+* If we select it, the maximum value we can acheive is arr[0] = 9
+* If we reject it, the value which we will get is 0
+* So, we will store arr[0] in dp[0]
+
+* Now, we will look at arr[0] and arr[1] to find the maximum
+ * As arr[0] > arr[1], we will store arr[0] in dp[1]
+* Similary we will repeat the above steps to fill dp[].
+
+
+### Psuedocode
+
+```cpp
+dp[N]
+for(i = 0; i < N; i++){
+ dp[i] = max(dp[i - 1], arr[i] + dp[i - 2])
+}
+return dp[N - 1]
+```
+
+
+### Time & Space Complexity
+**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
+**Space complexity:** O(N), because of dp array of size N.
+
+---
+title: Problem 2 Count Unique Paths
+description: Total number of ways to reach from top left to bottom right cell in the matrix
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+Given mat[n][m], find total number of ways from (0,0) to (n - 1, m - 1). We can move 1 step in horizontal direction or 1 step in vertical direction.
+
+
+
+
+### Example
+
+
+
+
+> `h` represents movement in horizontal direction and `v` represents movement in vertical direction
+
+**Ans:** 6
+
+
+
+---
+title: Quiz 2
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+Find the total number of ways to go from (0, 0) to (1, 2)
+
+| o | | |
+|---|---|---|
+| | | **o** |
+
+
+# Choices
+- [ ] 1
+- [ ] 2
+- [x] 3
+- [ ] 4
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The 2D matrix dp is
+
+| | 0 | 1 | 2 |
+|---|---|---|---|
+| 0 | 1 | 1 | 1 |
+| 1 | 1 | 2 | 3 |
+
+From here, the number of ways to go from (0, 0) to (1, 2) is 3.
+
+
+---
+title: Count Unique Paths Brute Force Approach
+description: Total number of ways to reach from top left to bottom right cell in the matrix
+duration: 900
+card_type: cue_card
+---
+
+
+### Brute Force Appoarch
+**Backtracking**, i.e., start from (0, 0) and try all possible scenarios to reach (n - 1, m - 1)
+
+### Observation
+Can we break it into subproblems?
+- We can reach (n - 1, m - 1) in one step (by moving vertically) from (n - 2, m - 1)
+- We can reach (n - 1, m - 1) in one step (by moving horizontally) (n - 1, m - 2)
+
+
+
+* Number of ways we can reach to the nth step is either by (n - 1) or (n - 2).
+* Answer will be summation of number of ways to reach (n - 1)th step + number of ways to reach (n - 2)th step
+
+We can see that the above has been deduced to fibonacii expression
+
+---
+title: Problem 3 Get Minimum Squares
+description: Minimum number of perfect squares required to get sum = N
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+*Find minimum number of perfect squares required to get sum = N. (duplicate squares are allowed)*
+
+*example 1 --> N = 6*
+
+sum 6 can be obtained by the addition of following squares:
+* `1^2+1^2+1^2+1^2+1^2+1^2`
+* `1^2+1^2+2^2` --> minimum number of squares is 3 in this case
+
+*example 2 --> N = 10*
+
+sum 10 can be obtained by the addition of following squares:
+* `1^2+1^2+..... 10 times`
+* `2^2 + 1^2..... 6 times`
+* `2^2 + 2^2 + 1^2 + 1^2`
+* `3^2 + 1^2 `--> minimum number of squares is 2 in this case
+
+*example 3 --> N = 9*
+
+sum 10 can be obtained by the addition of following squares:
+* `1^2+1^2+..... 9 times`
+* `2^2 + 1^2..... 5 times`
+* `2^2 + 2^2 + 1^2 `
+* `3^2` --> minimum number of squares is 1 in this case
+
+
+---
+title: Quiz 4
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+What is the minimum number of perfect squares required to get sum = 5. (duplicate squares are allowed)
+
+# Choices
+- [ ] 5
+- [ ] 1
+- [x] 2
+- [ ] 3
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+sum 5 can be obtained by the addition of following squares:
+* `1^2 + 1^2 + 1^2 + 1^2 + 1^2`
+* `2^2 + 1^2` --> minimum number of squares is 2 in this case
+
+
+---
+title: Get Minimum Squares Approach
+description: Minimum number of perfect squares required to get sum = N
+duration: 900
+card_type: cue_card
+---
+
+
+
+### Approach 1
+* Can we simply do **`N - (nearest perfect square)`** ?
+
+ * Verifying approach 1 with example N=12
+ * 12-9 (closest square) = 3
+ * 3-1 = 2
+ * 2-1 = 1
+ * 1-1 = 0
+ * We are using 4 perfect squares, whereas the minimum number of square is 3 (2^2 + 2^2 +2^2) so approach 1 is not useful in this case
+
+### Brute Force Approach
+* Try every possible way to form the sum using brute force to solve a example N = 12
+
+
+The above image shows all possiblities to achieve 12.
+
+Now, to get minimum sum of 12 we will find minimum square of 11 or minimum square of 8 or minimum square of 3 + 1.
+
+The above is a recursive problem where we can see overalapping subproblems, like for N=7.
+
+### Dynamic Programming Approach
+Here optimal structure has been obtained as well as overlapping subproblems
+
+So, we can say that
+`square(i) = 1 + min{ squares(i - x^2) for all x^2 <= i} `and base case is square[0] = 0
+
+### Psuedocode
+```java
+int dp[N + 1]; //initialise (-1)
+int psquares(int N, int dp[]){
+if(n == 0) return 0;
+if(dp[N] != -1) return dp[N];
+ans = int - max;
+for(x = 1; x * x <= N; x++){
+ans = min(ans, psquares(N - x^2)); // dp
+}
+dp[N] = 1 + ans;
+return dp[N];
+}
+```
+Time complexity for the above code is O(N(sqrt(N))) and space complexity is O(N).
+
+---
+title: ATM Minimum Note Dispenser
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem :
+**RBI** wants to reduce **paper usage** for money. Imagine you need to withdraw a specific amount of money from an ATM. The ATMs should be programmed to give you the least number of notes possible.
+
+The available notes in the ATM are **₹50, ₹30, and ₹5**. Your task is to figure out the **minimum number of notes** the ATM should give you for any amount of money you request, ensuring the ATM dispenses the exact amount you asked for.
+
+### Common Mistake :
+#### Greedy will fail...
+A greedy algorithm would start by taking the **largest denomination** note available and using as many of those as possible, then move to the next largest denomination, and continue in this way until the exact amount is dispensed.
+
+For example say you want ₹65, here the greedy approach would select **one** ₹50 note and **three** ₹5 notes, totaling **four** notes.
+
+However, the optimal solution is **two** ₹30 notes and **one** ₹5 note, totaling only **three** notes.
+
+
+
+### Intuition
+This is somewhat similar to the previous problem. Can we solve it too using Dynamic Programming ?
+
+### Dynamic Programming Approach
+Let's define the dynamic programming solution :
+
+- Let `DP[i] represent the minimum number of notes required to make sum N`
+- Initially `DP[i] = infinity`, and `DP[0] = 0`
+- Transition : `DP[i] = min(DP[i - 50], DP[i - 30], DP[i - 5])`
+
+### Psuedocode
+```java
+int dp[N + 1]; //initialise (-1)
+
+int minNotes(int N, int dp[]){
+ if(n == 0) return 0;
+ if(n < 0) return infinity ;
+ if(dp[N] != -1) return dp[N];
+ ans = infinity;
+
+ ans = min(ans, psquares(N - 50));
+ ans = min(ans, psquares(N - 30));
+ ans = min(ans, psquares(N - 5));
+
+ dp[N] = 1 + ans;
+ return dp[N];
+}
+```
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 2 Two Dimentional.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 2 Two Dimentional.md
new file mode 100644
index 0000000..0d2a8e7
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 2 Two Dimentional.md
@@ -0,0 +1,859 @@
+# DP 2: Two Dimensional
+
+---
+title: Data Backup Scheduler
+description:
+duration: 900
+card_type: cue_card
+---
+
+**Problem Statement:**
+You're the network administrator at a large company where daily data backups are crucial. Each backup affects the network differently, measured by a "load score" that reflects its impact on network performance.
+
+The challenge is to schedule these backups over a period of N days to ensure the network remains stable and efficient during business hours. The goal is to achieve the highest possible total load score, which indicates the significance of the data backed up, while ensuring that backups are not scheduled on consecutive days.
+
+Here’s an example of how you might approach this over any number of days, say N=10 days, with the following load scores:
+
+**Day 1:** **`Load score = 45`**
+**Day 2:** **`Load score = 55`**
+**Day 3:** **`Load score = 40`**
+**Day 4:** **`Load score = 65`**
+**Day 5:** **`Load score = 60`**
+**Day 6:** **`Load score = 35`**
+**Day 7:** **`Load score = 75`**
+**Day 8:** **`Load score = 50`**
+**Day 9:** **`Load score = 80`**
+**Day 10:** **`Load score = 70`**
+
+Select days - **`1, 3, 5, 7, 9`** to get max score of **`300`**.
+
+---
+title: Problem 1 Maximum Subsequence Sum
+description: Two Dimensional
+duration: 900
+card_type: cue_card
+---
+
+### Simplified Problem Statement
+
+#### The problem can be broken down to be said as :
+Find maximum subsequence sum from a given array, where selecting adjacent element is not allowed.
+
+### Examples
+Example 1: ar[] = {5, 4, 8}
+Output 1: 13. Since out of all possible non adjacent element subsequences, the subsequence (5, 8) will yield maximum sum. So the student should be absent on first and third day.
+
+Example 2: ar[] = {9, 4, 10, 12}
+Output 2: 21 (The student should be absent on days with 9 hours and 12 hours)
+
+
+---
+title: Quiz 1
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+Find maximum subsequence sum from `[10, 20, 30, 40]`, where selecting adjacent element is not allowed.
+
+# Choices
+- [ ] 70
+- [x] 60
+- [ ] 100
+- [ ] 50
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Maximum Subsequence is 60. Since, Out of all possible non adjacent element subsequences, the subsequence (20, 40) will yield maximum sum of 60.
+
+
+---
+title: Maximum Subsequence Sum Brute Force Approach
+description: Maximum Subsequence Sum Dynamic Programming Approach Top Down
+duration: 900
+card_type: cue_card
+---
+
+
+### Brute Force Approach
+- Consider all the valid subsequences **`(this a backtracking step)`**.
+- For creating subsequences, for every element we can make a choice, whether to select it or reject it.
+- Say, we start from right most element. If we keep it, then (n - 1)th element can't be considered, so jump to (n - 2)th. If we don't, then (n - 1)th element can be considered. So on...
+
+
+
+
+
+The above image shows tree which has all the choices of selection. Here we can see that the choices are overlapping.
+
+Moreover, as the problem can be broken into smaller problems and has overlapping sub problems, we can use **dynamic programming**.
+
+
+---
+title: Maximum Subsequence Sum Top Down Approach
+description: Maximum Subsequence Sum Dynamic Programming Approach Top Down
+duration: 900
+card_type: cue_card
+---
+
+### Top Down Approach
+So for **maxSum(i)** there are two options:
+* either we can select element present at index i
+ * if we select that element we will include its value ie ar[i] and the recursive call will be **maxSum(i-2)**
+* or we cannot select the element present at index i
+ * so in this case we will not include its value and will make recursive call which is **maxSum(i-1)**
+
+`dp[i] = stores the maximum value that can be obtained by selecting 0 to ith toy.`
+
+The maximum of the choice we make will give us the final answer
+
+### Psuedocode
+
+```cpp
+int dp[N] //initialize it with negative infinity
+
+// i will be initialised with N-1, i.e we start with the last element
+int maxSum(int []arr, i, dp[N]){
+ if(i < 0){
+ return 0
+ }
+ if(dp[i] != -infinity) {
+ return dp[i]
+ }
+ //Don't consider the ith element, in this case we can consider (i-1)th element
+ f1 = maxSum(arr, i - 1, dp);
+
+ //Consider the ith element, in this case we can't consider (i-1)th element, so we jump to (i-2)th element
+ f2 = arr[i] + maxSum(arr, i - 2, dp);
+
+ ans = max(f1, f2)
+
+ dp[i] = ans;
+
+ return ans
+}
+```
+
+### Time & Space Complexity
+
+**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
+**Space complexity:** O(N), because of dp array of size N.
+
+
+---
+title: Maximum Subsequence Sum Bottom Up Approach
+description: Two Dimensional
+duration: 900
+card_type: cue_card
+---
+
+### Problem 1
+**`dp[i] is defined as the maximum subsequence sum from [0 - i] provided no adjacent elements are selected`**
+
+arr = {9, 4, 13, 24}
+
+We can start from arr[0] and we have two choices: either we can select arr[0] or reject.
+* If we select it, the maximum value we can acheive is arr[0] = 9
+* If we reject it, the value which we will get is 0
+* So, we will store arr[0] in dp[0]
+
+* Now, we will look at arr[0] and arr[1] to find the maximum
+ * As arr[0] > arr[1], we will store arr[0] in dp[1]
+* Similary we will repeat the above steps to fill dp[].
+
+
+### Psuedocode
+
+```cpp
+dp[N]
+for(i = 0; i < N; i++){
+ dp[i] = max(dp[i - 1], arr[i] + dp[i - 2])
+}
+return dp[N - 1]
+```
+
+
+### Time & Space Complexity
+**Time complexity:** O(N). As we are filling the DP array of size N linearly, it would take O(N) time.
+**Space complexity:** O(N), because of dp array of size N.
+
+---
+title: Problem 2 Count Unique Paths
+description: Total number of ways to reach from top left to bottom right cell in the matrix
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+Given mat[n][m], find total number of ways from (0,0) to (n - 1, m - 1). We can move 1 step in horizontal direction or 1 step in vertical direction.
+
+
+
+
+### Example
+
+
+
+
+> `h` represents movement in horizontal direction and `v` represents movement in vertical direction
+
+**Ans:** 6
+
+
+
+---
+title: Quiz 2
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+Find the total number of ways to go from (0, 0) to (1, 2)
+
+| o | | |
+|---|---|---|
+| | | **o** |
+
+
+# Choices
+- [ ] 1
+- [ ] 2
+- [x] 3
+- [ ] 4
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The 2D matrix dp is
+
+| | 0 | 1 | 2 |
+|---|---|---|---|
+| 0 | 1 | 1 | 1 |
+| 1 | 1 | 2 | 3 |
+
+From here, the number of ways to go from (0, 0) to (1, 2) is 3.
+
+
+---
+title: Count Unique Paths Brute Force Approach
+description: Total number of ways to reach from top left to bottom right cell in the matrix
+duration: 900
+card_type: cue_card
+---
+
+
+### Brute Force Appoarch
+**Backtracking**, i.e., start from (0, 0) and try all possible scenarios to reach (n - 1, m - 1)
+
+### Observation
+Can we break it into subproblems?
+- We can reach (n - 1, m - 1) in one step (by moving vertically) from (n - 2, m - 1)
+- We can reach (n - 1, m - 1) in one step (by moving horizontally) (n - 1, m - 2)
+
+ +
+
+
+### Recursive Relation
+
+**ways(i, j) = ways(i - 1, j) + ways(i, j - 1)**
+
+### Base Condition
+- When i == 0, we have only one path to reach at the end, i.e., by moving vertically.
+- Similary, when j == 0, we have only one path to reach at the end, i.e., by moving horizontally.
+
+Therefore, **ways(0, j) = ways(i, 0) = 1**
+
+### Pseudocode:
+```java
+int ways(i, j) {
+ if (i == 0 || j == 0) {
+ return 1;
+ }
+ return ways(i - 1, j) + ways(i, j - 1);
+}
+```
+
+Time Complexity: O(2 ^ (N * M)), as at every step we have two options, and there are total of N * M cells.
+
+
+---
+title: Count Unique Paths Optimization
+description: Optimization using DP
+duration: 900
+card_type: cue_card
+---
+
+### Optimization using DP
+
+We can see the **optimal substructure** in this problem as it can be defined in terms of smaller subproblems.
+
+**Are there overlapping subproblems as well?**
+
+
+
+
+
+### Recursive Relation
+
+**ways(i, j) = ways(i - 1, j) + ways(i, j - 1)**
+
+### Base Condition
+- When i == 0, we have only one path to reach at the end, i.e., by moving vertically.
+- Similary, when j == 0, we have only one path to reach at the end, i.e., by moving horizontally.
+
+Therefore, **ways(0, j) = ways(i, 0) = 1**
+
+### Pseudocode:
+```java
+int ways(i, j) {
+ if (i == 0 || j == 0) {
+ return 1;
+ }
+ return ways(i - 1, j) + ways(i, j - 1);
+}
+```
+
+Time Complexity: O(2 ^ (N * M)), as at every step we have two options, and there are total of N * M cells.
+
+
+---
+title: Count Unique Paths Optimization
+description: Optimization using DP
+duration: 900
+card_type: cue_card
+---
+
+### Optimization using DP
+
+We can see the **optimal substructure** in this problem as it can be defined in terms of smaller subproblems.
+
+**Are there overlapping subproblems as well?**
+
+ +
+
+We can see that, `(i - 1, j - 1)` are the overlapping subproblems.
+
+***Since there is optimal substructure and overlapping subproblems, DP can be easily applied.***
+
+*Which type of array should be used?*
+Since two args (i and j) are varying in above method, 2-d storage is needed of size N x M.
+
+### Top Down Approach
+
+**`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`**
+
+### Pseudocode
+```java
+int dp[N][M]; // initialized with -1
+int ways(i, j) {
+ if (i == 0 || j == 0) {
+ return 1;
+ }
+
+ if (dp[i][j] != -1) {
+ return dp[i][j];
+ }
+ ans = ways(i - 1, j, dp) + ways(i, j - 1, dp);
+ dp[i][j] = ans;
+ return ans;
+}
+```
+### Complexity
+**Time Complexity:** O(N * M), as we are filling a matrix of size N * M.
+**Space Complexity:** O(N * M), as we have used dp matrix of size N * M.
+
+> *In how many ways can we reach (0, 0) starting from (0, 0)?*
+>
+> If you say 0, that means there is no way to reach (0, 0) or (0, 0) is unreachable. Hence, to reach (0, 0) from (0, 0), there is 1 way and not 0.
+
+### Bottom Up Approach:
+Consider a 2D matrix `dp` of size N * M.
+`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`
+
+In bottom up approach, we start from the smallest problem which is (0, 0) in this case.
+- No. of ways to move (0, 0) from (0, 0) = ways(0, 0) = 1
+- Similarly, ways(0, 1) = ways(0, 2) = . . . = 1
+- Also, ways(1, 0) = ways(2, 0) = . . . = 1
+- Now, ways(1, 1) = ways(1, 0) + ways(0, 1) = 2
+- Similarly, ways(1, 2) = ways(1, 1) + ways(0, 2) = 3, and so on.
+
+
+
+### Pseudocode
+```java
+dp[N][M];
+// Initialize `dp` row - 0 and col - 0 with 1.
+for (i = 1; i <= N; i++) {
+ for (j = 1; j <= M; j++) {
+ dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
+ }
+}
+return dp[N - 1][M - 1];
+```
+
+Time Complexity: O(N * M)
+Space Complexity: O(N * M)
+
+
+### Can we further optimize the space complexity?
+
+- The answer of every row is dependent upon its previous row.
+- So, essentially, we require two rows at a time - (1) current row (2) previous row. Thus, the space can be optimized to use just two 1-D arrays.
+
+
+---
+title: Problem 3 Total number of ways to go to bottom right corner from top left corner
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+
+Find the total number of ways to go to bottom right corner (N - 1, M - 1) from top left corner (0, 0) where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
+We can either traverse one step down or one step right.
+
+
+
+
+### Solution
+
+
+
+| 1 | 1 | 1 | 1 |
+| - | - | - | - |
+| 1 | 0 | 1 | 0 |
+| 0 | 0 | 1 | 1 |
+| 0 | 0 | 1 | 2 |
+| 0 | 0 | 1 | 3 |
+
+There are 3 ways, to reach from (0, 0) to (N - 1, M - 1).
+
+
+> The given problem is just a variation of above problem. Only advancement is that if cell value has 0, then there is no way to reach the bottom right cell.
+
+### Pseudocode (Recursive Approach)
+
+```cpp
+if (mat[i][j] != 0) {
+ ways[i][j] = ways(i - 1, j) + ways(i, j - 1);
+} else {
+ ways[i][j] = 0;
+}
+```
+
+Similar base condition can be added to top-down and bottom-up approach to optimize it using DP.
+
+
+---
+title: Quiz 3
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+How many unique paths in the grid from (0, 0) to (2, 2) ?
+
+| 1 | 1 | 1 |
+|-------|-------|-------|
+| **0** | **0** | **0** |
+| **1** | **1** | **1** |
+
+where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
+
+# Choices
+- [x] 0
+- [ ] 1
+- [ ] 2
+- [ ] 3
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+On the Grid, Row 1 is completely blocked. So there is no path from (0, 0) to (2, 2).
+
+Thus, the Total number of unique paths is 0.
+
+---
+title: Problem 4 Dungeons and Princess
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+
+Find the minimum health level of the prince to start with to save the princess, where the negative numbers denote a dragon and positive numbers denote red bull.
+
+Redbull will increase the health whereas the dragons will decrease the health.
+
+The prince can move either in horizontal right direction or vertical down direction.
+If health level <= 0, it means prince is dead.
+
+
+
+
+### Observation
+One might argue to solve it by finding the path with minimum sum or maximum sum.
+
+Let's check does it even work or not?
+
+### Using path with minimum sum(fails)
+- For the above matrix, the path with minimum sum is -3 -> -6 -> -15 -> -7 -> 5 -> -3 -> -4, which yields sum as 33. So, minimum health level should be (3 + 6 + 15 + 7) + 1 = 32, right?
+- No because if we start with **health 4** and follow the path -3 -> 2 -> 4 -> -5 -> 6 -> -2 -> -4, we can definitely reach the princess with lesser initial health.
+- Thus, finding the path with minimum sum doesn't work/
+
+### Using path with maximum sum(fails)
+
+
+
+
+- For the above matrix, the path with maximum sum is -2 -> -8 -> 100 -> 1, which yields sum as 91. So, minimum health level should be (2 + 8) + 1 = 11, right?
+- No because if we start with **health 7** and follow the path -2 -> -1 -> -3 -> 1, we can definitely reach the princess with lesser initial health.
+- Similarly, finding the path with maximum sum doesn't work.
+
+> NOTE:
+> Finding the path with maximum or minimum sum is a greedy approach, which doesn't work for this problem.
+
+### How to approach the problem then?
+Let's start with finding the smallest problem.
+
+***Where does smallest problem lie?* (0, 0) ?*** **NO**
+
+The smallest problem lies at **`(M - 1, N - 1)`**, because we need to find the minimum health to finally enter that cell to save the princess.
+
+***Now, what should be the minimum health to enter a cell?***
+
+Suppose the cell(M - 1, N - 1) has value -4, then to enter the cell needed is: minimum_health + (-4) > 0 => minimum_health + (-4) = 1 => minimum_health = 5
+
+
+
+
+There are two ways to enter the cell:
+**(1)** via TOP **(2)** via LEFT.
+***Which one to choose?***
+
+We know, to enter the cell with value -4, the minimum health should be 5. Therefore, if we want to enter from top cell with value -2, then x + (-2) = 5; x = 7, where 'x' is minimum health to enter top cell.
+
+Similary, y + (-3) = 5; y = 8.
+
+
+
+Hence, we should choose minimum of these and enter the cell via top.
+
+**What is the minimum health required to enter a cell (i, j) which has two options to move ahead?**
+
+
+
+
+
+
+
+
+> If the minimum health evaluates to negative, we should consider 1 in place of that as with any health <= 0, the prince will die.
+
+Let's fill the matrix using the same approach.
+
+
+
+
+
+Here, `dp[i][j]` = min health with which prince should take the entry at (i, j) so that he can save the princess.
+
+---
+title: Quiz 4
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+What is the Time Complexity to find minimum cost path from (0,0) to (r-1, c-1)?
+
+# Choices
+- [ ] O(max(r, c))
+- [ ] O(c )
+- [x] O(r * c)
+- [ ] O(r + c)
+
+
+---
+title: Dungeons and Princess Algorithm and Pseudocode
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Algorithm
+```java
+arr[i][j] + x = min(dp[i + 1][j], dp[i][j + 1])
+x = min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]
+```
+
+Since `x` should be > 0
+
+```java
+x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j])
+```
+
+### Pseudocode:
+```java
+declare dp[N][M];
+if (arr[N - 1][M - 1] > 0) {
+ dp[N - 1][M - 1] = 1;
+} else {
+ dp[N - 1][M - 1] = 1 + abs(arr[N - 1][M - 1]);
+}
+
+// Fill the last column and last row
+
+for (i = N - 2; i >= 0; i--) {
+ for (j = M - 2; j >= 0; j--) {
+ x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]);
+ dp[i][j] = x;
+ }
+}
+
+return dp[0][0];
+```
+
+### Complexity
+**Time Complexity:** O(N * M)
+**Space Complexity:** O(N * M)
+
+
+---
+title: Catalan Numbers
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Catalan Numbers
+
+The Catalan numbers form a sequence of natural numbers that have numerous applications in combinatorial mathematics. Each number in the sequence is a solution to a variety of counting problems. The Nth Catalan number, denoted as Cn, can be used to determine:
+
+* The number of correct combinations of N pairs of parentheses.
+* The number of distinct binary search trees with N nodes, etc.
+
+Here is the sequence,
+```
+C0 = 1
+C1 = 1
+C2 = C0 * C1 + C1 * C0 = 2
+C3 = C0 * C2 + C1 * C1 + C2 * C0 = 5
+C4 = C0 * C3 + C1 * C2 + C2 * C1 + C3 * C0 = 14
+C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0 = 42
+```
+
+### Formula
+
+
+
+
+
+
+### Psuedo Code
+
+```cpp
+int C[N + 1];
+
+C[0] = 1;
+C[1] = 1;
+
+for(int i = 2; i <= N; i++)
+{
+ for(int j = 0; j < i; j++)
+ {
+ C[i] += C[j] * C[N - 1 - j];
+ }
+}
+```
+
+### Complexity
+
+**Time Complexity:** O(N^2^)
+**Space Complexity:** O(N)
+
+Now, Let's look into a problem, which can be solved by finding the **Nth catalan number**.
+
+
+---
+title: Problem 5 Total Number of Unique BSTs
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+
+You are given a number N, Count Total number of Unique Binary Search Trees, that can be formed using N distinct numbers.
+
+### Example
+
+**Input:**
+N = 3
+
+**Output:**
+5
+
+**Explanation:**
+
+The Unique binary Search Trees are
+```
+ 30 10 30 10 20
+ / \ / \ / \
+ 10 20 20 30 10 30
+ \ \ / /
+ 20 30 10 20
+```
+
+---
+title: Quiz 5
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Count Total number of Unique Binary Search Trees, that can be formed using 2 distinct numbers
+
+# Choices
+- [ ] 1
+- [x] 2
+- [ ] 5
+- [ ] 4
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Let's take 2 distinct numbers as [10, 20]
+
+The possible BSTs are
+```
+ 20 10
+ / \
+ 10 20
+```
+---
+title: Total Number of Unique BSTs Dryrun
+description:
+duration: 900
+card_type: cue_card
+---
+
+Let's take N = 5, the numbers are [10, 20, 30, 40, 50].
+
+Let's keep each number as the root! one by one.
+
+**10 as root**
+```
+ 10
+ \
+ \
+ \
+ 20, 30, 40, 50
+```
+
+Here we notice that, 20, 30, 40 and 50 will be present on right side of 10. With these 4 nodes, we can create further BSTs, let's denote by C4
+
+Also on the right side, there is no elements. So denoting by C0.
+
+With `10 as root, the total number of BSTs => C0 * C1`
+
+
+**20 as root**
+```
+ 20
+ / \
+ / \
+ / \
+ 10 30, 40, 50
+```
+
+There are 1 element on the left side and 3 elements on the right side.
+
+`20 as root => C1 * C3`
+
+
+**30 as root**
+```
+ 30
+ / \
+ / \
+ / \
+ 10, 20 40, 50
+```
+
+
+There are 2 element on the left side and 2 elements on the right side.
+
+
+`30 as root => C2 * C2`
+
+
+**40 as root**
+```
+ 40
+ / \
+ / \
+ / \
+ 10, 20, 30 50
+```
+
+
+There are 3 element on the left side and 1 elements on the right side.
+
+
+`40 as root => C0 * C1`
+
+**50 as root**
+```
+ 50
+ /
+ /
+ /
+ 10, 20, 30, 40
+```
+
+There are 4 element on the left side and 1 elements on the right side.
+
+
+`10 as root => C4 * C0`
+
+C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0
+
+which is 42.
+
+### Solution
+
+The Solution for finding the total number of Unique BSTs is the **Nth Catalan Number**.
+
+---
+title: Total Number of Unique BSTs Pseudo Code
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Psuedo Code
+
+The pseudo code is same as the Catalan Number Psuedo code.
+
+```cpp
+function findTotalUniqueBSTs(int N){
+ int C[N + 1];
+
+ C[0] = 1;
+ C[1] = 1;
+
+ for(int i = 2; i <= N; i++)
+ {
+ for(int j = 0; j < i; j++)
+ {
+ C[i] += C[j] * C[N - 1 - j];
+ }
+ }
+
+ return C[N];
+}
+```
+
+### Complexity
+
+**Time Complexity:** O(N^2^)
+**Space Complexity:** O(N)
+
+
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 3 Knapsack.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 3 Knapsack.md
new file mode 100644
index 0000000..a6b7a08
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 3 Knapsack.md
@@ -0,0 +1,365 @@
+# DP 3: Knapsack
+
+---
+title: Knapsack
+description: Knapsack Introduction
+duration: 300
+card_type: cue_card
+---
+
+
+### Knapsack Problem
+
+Given N objects with their values Vi profit/loss their weight Wi. A bag is given with capacity W that can be used to carry some objects such that the total sum of object weights W and sum of profit in the bag is maximized or sum of loss in the bag is minimized.
+
+We will try Knapsack when these combinations are given:
+* number of objects will be N
+* every object will have 2 attributes namingly value and weight
+* and capacity will be given
+
+---
+title: Problem 1 Fractional Knapsack
+description: Fractional Knapsack
+duration: 1050
+card_type: cue_card
+---
+### Problem Statement
+Given N cakes with their happiness and weight. Find maximum total happiness that can be kept in a bag with capacity = W (cakes can be divided)
+
+### Example:
+N = 5; W = 40
+Happiness of the 5 cakes = [3, 8, 10, 2, 5]
+Weight of the 5 cakes = [10, 4, 20, 8, 15]
+Goal - happiness should be maximum possible and the total sum of weights should be <= 40.
+
+### Approach
+
+**`Since we can divide the objects, hence they can be picked based on their value per unit weight.`**
+
+**`For per unit weight, below are the happiness values:`**
+* Cake 1: `happiness = 0.3`;
+* Cake 2: `happiness = 2`;
+* Cake 3: `happiness = 0.5`;
+* Cake 4: `happiness = 0.25`;
+* Cake 5: `happiness = 0.33`;
+
+
+
+
+### Solution
+
+**`Arrange the cakes in descending order with respect to happiness/weight and start picking the element`**
+* Select the 2nd cake (happiness = 2), reducing capacity to 36(40-4).
+* Choose the 3rd cake (happiness = 0.5), further reducing capacity to 16(36-20).
+* Opt for the 5th cake (happiness = 0.33), leaving a capacity of 1(16-15).
+* Take a part of the 1st cake (happiness = 0.3), using up the remaining capacity.
+* Total happiness achieved: 23.3 (8 + 10 + 5 + 0.3).
+
+**Time complexity** of the above solution is O(Nlog(N)) because it requires sorting with respect to `happiness/weight`.
+
+**Space complexity** of the above solution is O(1).*
+
+### Pseudo Code
+```cpp=
+public class Solution {
+ class Items {
+ double cost;
+ int weight, value, ind;
+ Items(int weight, int value, double cost){
+ this.weight = weight;
+ this.value = value;
+ this.cost = cost;
+ }
+ }
+
+ public int solve(int[] A, int[] B, int C) {
+ Items[] iVal = new Items[A.length];
+ for (int i = 0; i < A.length; i++) {
+ double cost = (A[i]*1.0) / B[i];
+ iVal[i] = new Items(B[i], A[i], cost);
+ }
+ Arrays.sort(iVal, new Comparator
+
+### Dry Run of Brute Force Apporach
+
+
+
+In the above figure each element is taken and its selection is determined based on happiness and weight.
+
+> Here we can notice optimal sub structure as well as overlapping sub problems.
+> *Thus we can use dynamic progamming in this case*
+
+If index and capacity can define one unique state total number of unique states are `O(N * (W + 1))` which is `O(N * W)`, as index will go from 0 to N - 1 and weight will go from 0 to W.
+
+```cpp
+dp[N][W] = max happiness (considering N objects and capacity W)
+```
+
+
+
+
+We can see that, `(i - 1, j - 1)` are the overlapping subproblems.
+
+***Since there is optimal substructure and overlapping subproblems, DP can be easily applied.***
+
+*Which type of array should be used?*
+Since two args (i and j) are varying in above method, 2-d storage is needed of size N x M.
+
+### Top Down Approach
+
+**`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`**
+
+### Pseudocode
+```java
+int dp[N][M]; // initialized with -1
+int ways(i, j) {
+ if (i == 0 || j == 0) {
+ return 1;
+ }
+
+ if (dp[i][j] != -1) {
+ return dp[i][j];
+ }
+ ans = ways(i - 1, j, dp) + ways(i, j - 1, dp);
+ dp[i][j] = ans;
+ return ans;
+}
+```
+### Complexity
+**Time Complexity:** O(N * M), as we are filling a matrix of size N * M.
+**Space Complexity:** O(N * M), as we have used dp matrix of size N * M.
+
+> *In how many ways can we reach (0, 0) starting from (0, 0)?*
+>
+> If you say 0, that means there is no way to reach (0, 0) or (0, 0) is unreachable. Hence, to reach (0, 0) from (0, 0), there is 1 way and not 0.
+
+### Bottom Up Approach:
+Consider a 2D matrix `dp` of size N * M.
+`dp[i][j] = It is defined as the total ways to reach from 0,0 to i,j`
+
+In bottom up approach, we start from the smallest problem which is (0, 0) in this case.
+- No. of ways to move (0, 0) from (0, 0) = ways(0, 0) = 1
+- Similarly, ways(0, 1) = ways(0, 2) = . . . = 1
+- Also, ways(1, 0) = ways(2, 0) = . . . = 1
+- Now, ways(1, 1) = ways(1, 0) + ways(0, 1) = 2
+- Similarly, ways(1, 2) = ways(1, 1) + ways(0, 2) = 3, and so on.
+
+
+
+### Pseudocode
+```java
+dp[N][M];
+// Initialize `dp` row - 0 and col - 0 with 1.
+for (i = 1; i <= N; i++) {
+ for (j = 1; j <= M; j++) {
+ dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
+ }
+}
+return dp[N - 1][M - 1];
+```
+
+Time Complexity: O(N * M)
+Space Complexity: O(N * M)
+
+
+### Can we further optimize the space complexity?
+
+- The answer of every row is dependent upon its previous row.
+- So, essentially, we require two rows at a time - (1) current row (2) previous row. Thus, the space can be optimized to use just two 1-D arrays.
+
+
+---
+title: Problem 3 Total number of ways to go to bottom right corner from top left corner
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+
+Find the total number of ways to go to bottom right corner (N - 1, M - 1) from top left corner (0, 0) where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
+We can either traverse one step down or one step right.
+
+
+
+
+### Solution
+
+
+
+| 1 | 1 | 1 | 1 |
+| - | - | - | - |
+| 1 | 0 | 1 | 0 |
+| 0 | 0 | 1 | 1 |
+| 0 | 0 | 1 | 2 |
+| 0 | 0 | 1 | 3 |
+
+There are 3 ways, to reach from (0, 0) to (N - 1, M - 1).
+
+
+> The given problem is just a variation of above problem. Only advancement is that if cell value has 0, then there is no way to reach the bottom right cell.
+
+### Pseudocode (Recursive Approach)
+
+```cpp
+if (mat[i][j] != 0) {
+ ways[i][j] = ways(i - 1, j) + ways(i, j - 1);
+} else {
+ ways[i][j] = 0;
+}
+```
+
+Similar base condition can be added to top-down and bottom-up approach to optimize it using DP.
+
+
+---
+title: Quiz 3
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+How many unique paths in the grid from (0, 0) to (2, 2) ?
+
+| 1 | 1 | 1 |
+|-------|-------|-------|
+| **0** | **0** | **0** |
+| **1** | **1** | **1** |
+
+where cell with value 1 and 0 represents non-blocked and blocked cell respectively.
+
+# Choices
+- [x] 0
+- [ ] 1
+- [ ] 2
+- [ ] 3
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+On the Grid, Row 1 is completely blocked. So there is no path from (0, 0) to (2, 2).
+
+Thus, the Total number of unique paths is 0.
+
+---
+title: Problem 4 Dungeons and Princess
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+
+Find the minimum health level of the prince to start with to save the princess, where the negative numbers denote a dragon and positive numbers denote red bull.
+
+Redbull will increase the health whereas the dragons will decrease the health.
+
+The prince can move either in horizontal right direction or vertical down direction.
+If health level <= 0, it means prince is dead.
+
+
+
+
+### Observation
+One might argue to solve it by finding the path with minimum sum or maximum sum.
+
+Let's check does it even work or not?
+
+### Using path with minimum sum(fails)
+- For the above matrix, the path with minimum sum is -3 -> -6 -> -15 -> -7 -> 5 -> -3 -> -4, which yields sum as 33. So, minimum health level should be (3 + 6 + 15 + 7) + 1 = 32, right?
+- No because if we start with **health 4** and follow the path -3 -> 2 -> 4 -> -5 -> 6 -> -2 -> -4, we can definitely reach the princess with lesser initial health.
+- Thus, finding the path with minimum sum doesn't work/
+
+### Using path with maximum sum(fails)
+
+
+
+
+- For the above matrix, the path with maximum sum is -2 -> -8 -> 100 -> 1, which yields sum as 91. So, minimum health level should be (2 + 8) + 1 = 11, right?
+- No because if we start with **health 7** and follow the path -2 -> -1 -> -3 -> 1, we can definitely reach the princess with lesser initial health.
+- Similarly, finding the path with maximum sum doesn't work.
+
+> NOTE:
+> Finding the path with maximum or minimum sum is a greedy approach, which doesn't work for this problem.
+
+### How to approach the problem then?
+Let's start with finding the smallest problem.
+
+***Where does smallest problem lie?* (0, 0) ?*** **NO**
+
+The smallest problem lies at **`(M - 1, N - 1)`**, because we need to find the minimum health to finally enter that cell to save the princess.
+
+***Now, what should be the minimum health to enter a cell?***
+
+Suppose the cell(M - 1, N - 1) has value -4, then to enter the cell needed is: minimum_health + (-4) > 0 => minimum_health + (-4) = 1 => minimum_health = 5
+
+
+
+
+There are two ways to enter the cell:
+**(1)** via TOP **(2)** via LEFT.
+***Which one to choose?***
+
+We know, to enter the cell with value -4, the minimum health should be 5. Therefore, if we want to enter from top cell with value -2, then x + (-2) = 5; x = 7, where 'x' is minimum health to enter top cell.
+
+Similary, y + (-3) = 5; y = 8.
+
+
+
+Hence, we should choose minimum of these and enter the cell via top.
+
+**What is the minimum health required to enter a cell (i, j) which has two options to move ahead?**
+
+
+
+
+
+
+
+
+> If the minimum health evaluates to negative, we should consider 1 in place of that as with any health <= 0, the prince will die.
+
+Let's fill the matrix using the same approach.
+
+
+
+
+
+Here, `dp[i][j]` = min health with which prince should take the entry at (i, j) so that he can save the princess.
+
+---
+title: Quiz 4
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+What is the Time Complexity to find minimum cost path from (0,0) to (r-1, c-1)?
+
+# Choices
+- [ ] O(max(r, c))
+- [ ] O(c )
+- [x] O(r * c)
+- [ ] O(r + c)
+
+
+---
+title: Dungeons and Princess Algorithm and Pseudocode
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Algorithm
+```java
+arr[i][j] + x = min(dp[i + 1][j], dp[i][j + 1])
+x = min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]
+```
+
+Since `x` should be > 0
+
+```java
+x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j])
+```
+
+### Pseudocode:
+```java
+declare dp[N][M];
+if (arr[N - 1][M - 1] > 0) {
+ dp[N - 1][M - 1] = 1;
+} else {
+ dp[N - 1][M - 1] = 1 + abs(arr[N - 1][M - 1]);
+}
+
+// Fill the last column and last row
+
+for (i = N - 2; i >= 0; i--) {
+ for (j = M - 2; j >= 0; j--) {
+ x = max(1, min(dp[i + 1][j], dp[i][j + 1]) - arr[i][j]);
+ dp[i][j] = x;
+ }
+}
+
+return dp[0][0];
+```
+
+### Complexity
+**Time Complexity:** O(N * M)
+**Space Complexity:** O(N * M)
+
+
+---
+title: Catalan Numbers
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Catalan Numbers
+
+The Catalan numbers form a sequence of natural numbers that have numerous applications in combinatorial mathematics. Each number in the sequence is a solution to a variety of counting problems. The Nth Catalan number, denoted as Cn, can be used to determine:
+
+* The number of correct combinations of N pairs of parentheses.
+* The number of distinct binary search trees with N nodes, etc.
+
+Here is the sequence,
+```
+C0 = 1
+C1 = 1
+C2 = C0 * C1 + C1 * C0 = 2
+C3 = C0 * C2 + C1 * C1 + C2 * C0 = 5
+C4 = C0 * C3 + C1 * C2 + C2 * C1 + C3 * C0 = 14
+C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0 = 42
+```
+
+### Formula
+
+
+
+
+
+
+### Psuedo Code
+
+```cpp
+int C[N + 1];
+
+C[0] = 1;
+C[1] = 1;
+
+for(int i = 2; i <= N; i++)
+{
+ for(int j = 0; j < i; j++)
+ {
+ C[i] += C[j] * C[N - 1 - j];
+ }
+}
+```
+
+### Complexity
+
+**Time Complexity:** O(N^2^)
+**Space Complexity:** O(N)
+
+Now, Let's look into a problem, which can be solved by finding the **Nth catalan number**.
+
+
+---
+title: Problem 5 Total Number of Unique BSTs
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+
+You are given a number N, Count Total number of Unique Binary Search Trees, that can be formed using N distinct numbers.
+
+### Example
+
+**Input:**
+N = 3
+
+**Output:**
+5
+
+**Explanation:**
+
+The Unique binary Search Trees are
+```
+ 30 10 30 10 20
+ / \ / \ / \
+ 10 20 20 30 10 30
+ \ \ / /
+ 20 30 10 20
+```
+
+---
+title: Quiz 5
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Count Total number of Unique Binary Search Trees, that can be formed using 2 distinct numbers
+
+# Choices
+- [ ] 1
+- [x] 2
+- [ ] 5
+- [ ] 4
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Let's take 2 distinct numbers as [10, 20]
+
+The possible BSTs are
+```
+ 20 10
+ / \
+ 10 20
+```
+---
+title: Total Number of Unique BSTs Dryrun
+description:
+duration: 900
+card_type: cue_card
+---
+
+Let's take N = 5, the numbers are [10, 20, 30, 40, 50].
+
+Let's keep each number as the root! one by one.
+
+**10 as root**
+```
+ 10
+ \
+ \
+ \
+ 20, 30, 40, 50
+```
+
+Here we notice that, 20, 30, 40 and 50 will be present on right side of 10. With these 4 nodes, we can create further BSTs, let's denote by C4
+
+Also on the right side, there is no elements. So denoting by C0.
+
+With `10 as root, the total number of BSTs => C0 * C1`
+
+
+**20 as root**
+```
+ 20
+ / \
+ / \
+ / \
+ 10 30, 40, 50
+```
+
+There are 1 element on the left side and 3 elements on the right side.
+
+`20 as root => C1 * C3`
+
+
+**30 as root**
+```
+ 30
+ / \
+ / \
+ / \
+ 10, 20 40, 50
+```
+
+
+There are 2 element on the left side and 2 elements on the right side.
+
+
+`30 as root => C2 * C2`
+
+
+**40 as root**
+```
+ 40
+ / \
+ / \
+ / \
+ 10, 20, 30 50
+```
+
+
+There are 3 element on the left side and 1 elements on the right side.
+
+
+`40 as root => C0 * C1`
+
+**50 as root**
+```
+ 50
+ /
+ /
+ /
+ 10, 20, 30, 40
+```
+
+There are 4 element on the left side and 1 elements on the right side.
+
+
+`10 as root => C4 * C0`
+
+C5 = C0 * C4 + C1 * C3 + C2 * C2 + C3 * C1 + C4 * C0
+
+which is 42.
+
+### Solution
+
+The Solution for finding the total number of Unique BSTs is the **Nth Catalan Number**.
+
+---
+title: Total Number of Unique BSTs Pseudo Code
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Psuedo Code
+
+The pseudo code is same as the Catalan Number Psuedo code.
+
+```cpp
+function findTotalUniqueBSTs(int N){
+ int C[N + 1];
+
+ C[0] = 1;
+ C[1] = 1;
+
+ for(int i = 2; i <= N; i++)
+ {
+ for(int j = 0; j < i; j++)
+ {
+ C[i] += C[j] * C[N - 1 - j];
+ }
+ }
+
+ return C[N];
+}
+```
+
+### Complexity
+
+**Time Complexity:** O(N^2^)
+**Space Complexity:** O(N)
+
+
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 3 Knapsack.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 3 Knapsack.md
new file mode 100644
index 0000000..a6b7a08
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 3 Knapsack.md
@@ -0,0 +1,365 @@
+# DP 3: Knapsack
+
+---
+title: Knapsack
+description: Knapsack Introduction
+duration: 300
+card_type: cue_card
+---
+
+
+### Knapsack Problem
+
+Given N objects with their values Vi profit/loss their weight Wi. A bag is given with capacity W that can be used to carry some objects such that the total sum of object weights W and sum of profit in the bag is maximized or sum of loss in the bag is minimized.
+
+We will try Knapsack when these combinations are given:
+* number of objects will be N
+* every object will have 2 attributes namingly value and weight
+* and capacity will be given
+
+---
+title: Problem 1 Fractional Knapsack
+description: Fractional Knapsack
+duration: 1050
+card_type: cue_card
+---
+### Problem Statement
+Given N cakes with their happiness and weight. Find maximum total happiness that can be kept in a bag with capacity = W (cakes can be divided)
+
+### Example:
+N = 5; W = 40
+Happiness of the 5 cakes = [3, 8, 10, 2, 5]
+Weight of the 5 cakes = [10, 4, 20, 8, 15]
+Goal - happiness should be maximum possible and the total sum of weights should be <= 40.
+
+### Approach
+
+**`Since we can divide the objects, hence they can be picked based on their value per unit weight.`**
+
+**`For per unit weight, below are the happiness values:`**
+* Cake 1: `happiness = 0.3`;
+* Cake 2: `happiness = 2`;
+* Cake 3: `happiness = 0.5`;
+* Cake 4: `happiness = 0.25`;
+* Cake 5: `happiness = 0.33`;
+
+
+
+
+### Solution
+
+**`Arrange the cakes in descending order with respect to happiness/weight and start picking the element`**
+* Select the 2nd cake (happiness = 2), reducing capacity to 36(40-4).
+* Choose the 3rd cake (happiness = 0.5), further reducing capacity to 16(36-20).
+* Opt for the 5th cake (happiness = 0.33), leaving a capacity of 1(16-15).
+* Take a part of the 1st cake (happiness = 0.3), using up the remaining capacity.
+* Total happiness achieved: 23.3 (8 + 10 + 5 + 0.3).
+
+**Time complexity** of the above solution is O(Nlog(N)) because it requires sorting with respect to `happiness/weight`.
+
+**Space complexity** of the above solution is O(1).*
+
+### Pseudo Code
+```cpp=
+public class Solution {
+ class Items {
+ double cost;
+ int weight, value, ind;
+ Items(int weight, int value, double cost){
+ this.weight = weight;
+ this.value = value;
+ this.cost = cost;
+ }
+ }
+
+ public int solve(int[] A, int[] B, int C) {
+ Items[] iVal = new Items[A.length];
+ for (int i = 0; i < A.length; i++) {
+ double cost = (A[i]*1.0) / B[i];
+ iVal[i] = new Items(B[i], A[i], cost);
+ }
+ Arrays.sort(iVal, new Comparator
+
+### Dry Run of Brute Force Apporach
+
+
+
+In the above figure each element is taken and its selection is determined based on happiness and weight.
+
+> Here we can notice optimal sub structure as well as overlapping sub problems.
+> *Thus we can use dynamic progamming in this case*
+
+If index and capacity can define one unique state total number of unique states are `O(N * (W + 1))` which is `O(N * W)`, as index will go from 0 to N - 1 and weight will go from 0 to W.
+
+```cpp
+dp[N][W] = max happiness (considering N objects and capacity W)
+```
+
+ +
+> Here taking N = i and W = j, we have two choices either to select dp[i][j] or to reject it. On selecting it will result into` h[i] + dp[i - 1][j - wt[i]]`(h[i]=happiness of i) and on rejecting it will be `dp[i - 1][j]`.
+
+### Base Case
+* for all j when i = 0, dp[0][j] = 0
+* for all i when j = 0, dp[i][0] = 0
+
+### Psuedocode
+
+```java
+//for all i,j dp[i][j]=0
+for(i --> 1 to N){ // 1based index for input
+ for(j--> 1 to W){
+ if(wt[i] <= j){
+ dp[i][j] = max(dp[i - 1][j], h[i] + dp(i - 1)(j - wt[i]))
+ }else{
+ dp[i][j] = dp[i - 1][j]
+ }
+ }
+ }
+return dp[N][w]
+}
+```
+
+
+The dimensions should be (N + 1) * (W + 1) as the final answer would be at dp[N][W]
+
+### Dry run
+taking the N = 4 and W = 7
+Happiness of the 4 toys = [4, 1, 5, 7]
+Weight of the 4 toys = [3, 2, 4, 5]
+
+
+
+> Here taking N = i and W = j, we have two choices either to select dp[i][j] or to reject it. On selecting it will result into` h[i] + dp[i - 1][j - wt[i]]`(h[i]=happiness of i) and on rejecting it will be `dp[i - 1][j]`.
+
+### Base Case
+* for all j when i = 0, dp[0][j] = 0
+* for all i when j = 0, dp[i][0] = 0
+
+### Psuedocode
+
+```java
+//for all i,j dp[i][j]=0
+for(i --> 1 to N){ // 1based index for input
+ for(j--> 1 to W){
+ if(wt[i] <= j){
+ dp[i][j] = max(dp[i - 1][j], h[i] + dp(i - 1)(j - wt[i]))
+ }else{
+ dp[i][j] = dp[i - 1][j]
+ }
+ }
+ }
+return dp[N][w]
+}
+```
+
+
+The dimensions should be (N + 1) * (W + 1) as the final answer would be at dp[N][W]
+
+### Dry run
+taking the N = 4 and W = 7
+Happiness of the 4 toys = [4, 1, 5, 7]
+Weight of the 4 toys = [3, 2, 4, 5]
+
+ +
+* Initially, we filled the `dp` matrix with zeros. Now, we will fill every position one by one.
+ - At i = 1, j = 1
+ wt[i] = wt[1] = 3
+ since wt[i] > j, dp[i][j] = dp[i - 1][j] => dp[1][1] = dp[0][1] = 0
+* At i = 1, j = 2
+ wt[i] = wt[1] = 3
+ since wt[i] > j, dp[i][j] = dp[i - 1][j] => dp[1][2] = dp[0][2] = 0
+* At i = 1, j = 3
+ wt[i] = wt[1] = 3
+ since wt[i] <= j, dp[i][j] = max(dp[i - 1][j], h[i] + dp[i - 1][j - wt[i]])
+ => dp[1][3] = max(dp[0][2], h[1] + dp[0][0]) = max(0, 4 + 0) = 4
+
+Similary we wil follow the above to fill the entire table.
+
+> Time complexity for the above code is O(N * W)
+
+> Space Complexity for the above code is O(N * W), we can furture optimize space complexity by using 2 rows. So the space complexity is O(2W) which can be written as O(W).
+
+---
+title: Problem 3 Unbounded Knapsack
+description: Unbounded Knapsack
+duration: 1050
+card_type: cue_card
+---
+
+## Unbounded Knapsack or 0-N Knapsack
+* objects cannot be divided
+* same object can be selected multiple times
+
+### Question
+
+Given N toys with their happiness and weight. Find more total happiness that can be kept in a bag with capacity W. Division of toys are not allowed and infinite toys are available.
+
+### Example
+
+N = 3; W = 8
+Happiness of the 3 toys = [2, 3, 5]
+Weight of the 3 toys = [3, 4, 7]
+
+*In this case we will select second index toy 2 times. Happiness we will be 6 and weight will be 8.*
+
+Now here as we do not have any limitation on which toy to buy index will not matter, only capacity will matter.
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+We have Weight Capacity of 100
+- Values = [1, 30]
+- Weights = [1, 50]
+
+What is the maximum value you can have?
+
+# Choices
+- [ ] 0
+- [x] 100
+- [ ] 60
+- [ ] 80
+
+
+---
+title: Quiz 2 Explanation
+description:
+duration: 60
+card_type: cue_card
+---
+
+### Explanation
+There are many ways to fill knapsack.
+
+- 2 instances of 50 unit weight item.
+- 100 instances of 1 unit weight item.
+- 1 instance of 50 unit weight item and 50
+ instances of 1 unit weight items.
+
+We get maximum value with option 2, i.e **100**
+
+
+---
+title: Unbounded Knapsack Dry Run
+description:
+duration: 1050
+card_type: cue_card
+---
+
+
+### Dry Run for Brute Force Appoarch
+
+
+
+Step 1:
+* if we select toy with index 1, capacity left will be `8 - wt of toy 1 = 8 - 3 = 5`. And the happiness will be `h = 2`
+* Similarily if we select toy with index 2, capacity left will be `8 - wt of toy 2 = 8 - 4 = 4`. And the happiness will be `h = 3`
+* if we select toy with index 3, capacity left will be `8 - wt of toy 3 = 8 - 7 = 1`. And the happiness will be `h = 5`
+
+Step 2:
+After buying toy 1
+* Now if we buy toy 1, capacity will reduce to 2 and happiness will become 4
+* Similary if we buy toy 2, capacity will reduce to 1 and happiness will become 5
+* We cannot buy toy 3 as the capacity will be exceeded.
+
+
+We will follow similar steps to find all the possiblity.
+
+> We will pick the toy with maximum happiness that is 6 in this case after selecting toy 2 firstly and then selecting toy 2 again.
+
+Here we can notice optimal sub structure as well as overlapping sub problems. Thus we can apply dynamic programming.
+
+* Unqiue states here will be` W + 1 = O(W)` because the capacity can be from 0 to W
+
+Base case for the above question:
+* if capacity is 0, happiness is 0. So, `dp[0] = 0`
+
+Equation `dp[i] = max(h[i] + dp[i - wt[j]])` for all toys j
+
+### Psuedocode
+```java
+for all i, dp[0] = 0
+for (i --> 1 to W){
+ for(j --> 1 to N){
+ if(wt[j] <= i)
+ dp[i] = max(h[i] + dp[i - wt[j]])
+ }
+} return dp[W]
+```
+
+### Complexity
+**Time Complexity:** O(N * W)
+**Space Complexity:** O(W)
+
+
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 4 Applications of Knapsack.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 4 Applications of Knapsack.md
new file mode 100644
index 0000000..e66caf5
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 4 Applications of Knapsack.md
@@ -0,0 +1,353 @@
+# DSA: DP 4: Applications of Knapsack
+
+---
+title: Agenda of the lecture
+description: What will be covered in the topic?
+duration: 180
+card_type: cue_card
+---
+
+### Agenda
+- Introduction to the knapsack and DP
+- 4 problems from basic to advanced related to Dynamic Programming.
+
+So let's start.
+
+---
+title: Quiz 1
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+Time Complexity of the unbounded 0-1 knapsack problem?
+- W : capacity of knapsack
+- N : no. of elements
+- K : Max weight of any item
+- P : max value of any item
+
+# Choices
+Chose the correct answer
+- [x] O(NW)
+- [ ] O(NK)
+- [ ] O(NP)
+- [ ] O(WK)
+- [ ] O(WP)
+- [ ] O(KP)
+
+
+---
+title: Quiz 1 Explanation
+description:
+duration: 30
+card_type: cue_card
+---
+
+### Explanation
+For every node, we need to go to its left, that's the only way we can reach the smallest one.
+
+---
+title: Introduction to the knapsack and DP
+description: This section explains dynamic programming using examples.
+duration: 180
+card_type: cue_card
+---
+
+### What Is Dynamic Programming?
+In the context of dynamic programming, the ``knapsack problem`` refers to a classic optimization problem that can be solved using dynamic programming techniques.
+
+### Example
+Suppose we are working on solving the fibonacci series problesm, then we can break it into step by step as follows:
+
+
+
+Let us now solve some questions related to dynamic programming.
+
+---
+title: Problem 1 Cut the rod for maximum profit
+description: A rod is to be cut into pieces and we have to get the maximum profit out of it
+duration: 1700
+card_type: cue_card
+---
+
+### Problem Statement
+A rod of length `N` and an array `A` of length `N` is given. The elements (`i`) of the array contain the length of the rod (1-based indexing). Find the maximum values that can be obtained by cutting the rod into some pieces and selling them.
+
+### Example
+Suppose we have the length on `N = 5` and we have to divide it then the division can be done as:
+
+
+
+Now, we can see that $9$ is the maximum value that we can get.
+
+### Solution
+A naive approach to solving this problem would involve considering all possible combinations of cutting the rod into pieces and calculating the total value for each combination. This can be achieved using recursion and backtracking, where for each possible cut, the value of the cut piece is added to the recursively calculated value of the remaining part of the rod. The maximum value obtained among all combinations is the desired result.
+
+### Our Approach
+As we can visualize from the example, there is an overlapping subproblem and an optimal sub-structure. So, we should opt for the DP approach.
+
+> **Note**: We can observe three things here:
+ 1. The maximum capacity is the length of the order.
+ 2. `A[i]` is storing the length of the piece of the rod.
+ 3. The sum of the length of each piece must be less than or equal to ``N``
+The general observation that we can get here from these three things is that it is a knapsack problem.
+
+---
+title: Quiz 2
+description: Type of the above problem.
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+The cutting rod question is:
+
+# Choices
+- [ ] Fractional Knapsack
+- [ ] `0-1` Knapsack
+- [x] Unbounded Knapsack (or `0-N` Knapsack)
+
+---
+title: Cut the rod for maximum profit Approach
+description:
+duration: 1700
+card_type: cue_card
+---
+
+### Approach
+- First, define the state of the dp i.e. `dp[i]`, it will be the maximum value that can be received by the rod of length `i`.
+- The base case will be 0 in the case when the length of the rod is 0. This means `dp[0] = 0`.
+
+We will loop over the array, and then calculate the maximum profit, and finally store the maximum profit in the current dp state.
+
+Let us now see the pseudo-code for the problem.
+### Pseudocode
+```cpp
+for all values of i: dp[i] = 0
+
+for (i = 1 to N) // length of rod to sell = i
+{
+ for (j = 1 to i)
+ {
+ dp[i] = max(dp[i], A[j] + dp[i - j])
+ }
+}
+return dp[N]
+```
+
+### Time and Space Complexity
+- **Time Complexity**: $O(N^2)$, as we are traversing the N-length array using nested for loops (Simply, we can also say that the capacity is `N` and the length of the array is also `N`).
+- **Space Complexity**: `O(N)`, as we are using an extra dp array to store the current state of profit.
+
+> **Note for the instructor**: We can do a dry run for better clarity.
+
+---
+title: Problem 2 Count the number of ways using coins (ordered selection)
+description: Count the number of ways of getting a sum using coins, each coin can be selected multiple times.
+duration: 950
+card_type: cue_card
+---
+
+### Problem Statement
+In how many ways can the sum be equal to ``N`` by using coins given in the array? One coin can be used multiple times.
+
+### Example
+There are 2 ways to solve this problem
+a. **Ordered selection of coin**
+
+Let us create the set of numbers that cummulate the value of `N`.
+
+
+
+So, we can see that we have the value we get is $6$.
+
+Now, let's look at the selection tree of the coin selection. We can divide the number by selecting the choices of subraction.
+
+
+
+
+### Solution - Ordered Selection of Coin
+The naive approach to solving this problem involves using a recursive approach with backtracking. For each coin value in the array, subtract it from the target sum N, and recursively find the number of ways to form the remaining sum using the same coin set. Repeat this process for all coins and sum up the results.
+
+### Approach
+As we can observe from the examples above, we have to calculate the number of ways of selection, it is similar to the unbounded knapsack problem (as one coin can be selected multiple times).
+
+---
+title: Quiz 3
+description: Number of ways of getting the sum 0.
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the number of ways to get `sum = 0`
+
+# Choices
+- [ ] 0
+- [x] 1
+- [ ] 2
+- [ ] Undefined
+
+---
+title: Count the number of ways using coins Pseudocode
+description:
+duration: 950
+card_type: cue_card
+---
+
+### Pseudocode
+```cpp
+for all values of i: dp[i] = 0
+dp[0] = 1
+
+for (i = 1 to N)
+{
+ for (j = 1 to (A.length - 1))
+ {
+ if (A[j] <= i)
+ {
+ dp[i] += dp[i - A[j]]
+ }
+ }
+}
+
+return dp[N]
+```
+
+
+### Time and Space Complexity
+- **Time Complexity**: $O(N * (length~ of ~the ~array))$.
+- **Space Complexity**: $O(N)$.
+
+---
+title: Problem 3 Count the number of ways using coins (un-ordered selection)
+description: Count the number of ways of getting a sum using coins, the coins cannot be selected multiple times.
+duration: 1400
+card_type: cue_card
+---
+
+### Problem Statement
+
+Given a set of coins and a target sum, find the number of ways to make the target sum using the coins, where each coin can only be used once.
+
+### Example
+
+Suppose we have a situation same as the last one.
+N = 5 and coins we have [3, 1, 4].
+
+So here we have 3 possible ways.
+
+Now, let us try to arrage the coins to get the desired value.
+
+
+
+* Initially, we filled the `dp` matrix with zeros. Now, we will fill every position one by one.
+ - At i = 1, j = 1
+ wt[i] = wt[1] = 3
+ since wt[i] > j, dp[i][j] = dp[i - 1][j] => dp[1][1] = dp[0][1] = 0
+* At i = 1, j = 2
+ wt[i] = wt[1] = 3
+ since wt[i] > j, dp[i][j] = dp[i - 1][j] => dp[1][2] = dp[0][2] = 0
+* At i = 1, j = 3
+ wt[i] = wt[1] = 3
+ since wt[i] <= j, dp[i][j] = max(dp[i - 1][j], h[i] + dp[i - 1][j - wt[i]])
+ => dp[1][3] = max(dp[0][2], h[1] + dp[0][0]) = max(0, 4 + 0) = 4
+
+Similary we wil follow the above to fill the entire table.
+
+> Time complexity for the above code is O(N * W)
+
+> Space Complexity for the above code is O(N * W), we can furture optimize space complexity by using 2 rows. So the space complexity is O(2W) which can be written as O(W).
+
+---
+title: Problem 3 Unbounded Knapsack
+description: Unbounded Knapsack
+duration: 1050
+card_type: cue_card
+---
+
+## Unbounded Knapsack or 0-N Knapsack
+* objects cannot be divided
+* same object can be selected multiple times
+
+### Question
+
+Given N toys with their happiness and weight. Find more total happiness that can be kept in a bag with capacity W. Division of toys are not allowed and infinite toys are available.
+
+### Example
+
+N = 3; W = 8
+Happiness of the 3 toys = [2, 3, 5]
+Weight of the 3 toys = [3, 4, 7]
+
+*In this case we will select second index toy 2 times. Happiness we will be 6 and weight will be 8.*
+
+Now here as we do not have any limitation on which toy to buy index will not matter, only capacity will matter.
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+We have Weight Capacity of 100
+- Values = [1, 30]
+- Weights = [1, 50]
+
+What is the maximum value you can have?
+
+# Choices
+- [ ] 0
+- [x] 100
+- [ ] 60
+- [ ] 80
+
+
+---
+title: Quiz 2 Explanation
+description:
+duration: 60
+card_type: cue_card
+---
+
+### Explanation
+There are many ways to fill knapsack.
+
+- 2 instances of 50 unit weight item.
+- 100 instances of 1 unit weight item.
+- 1 instance of 50 unit weight item and 50
+ instances of 1 unit weight items.
+
+We get maximum value with option 2, i.e **100**
+
+
+---
+title: Unbounded Knapsack Dry Run
+description:
+duration: 1050
+card_type: cue_card
+---
+
+
+### Dry Run for Brute Force Appoarch
+
+
+
+Step 1:
+* if we select toy with index 1, capacity left will be `8 - wt of toy 1 = 8 - 3 = 5`. And the happiness will be `h = 2`
+* Similarily if we select toy with index 2, capacity left will be `8 - wt of toy 2 = 8 - 4 = 4`. And the happiness will be `h = 3`
+* if we select toy with index 3, capacity left will be `8 - wt of toy 3 = 8 - 7 = 1`. And the happiness will be `h = 5`
+
+Step 2:
+After buying toy 1
+* Now if we buy toy 1, capacity will reduce to 2 and happiness will become 4
+* Similary if we buy toy 2, capacity will reduce to 1 and happiness will become 5
+* We cannot buy toy 3 as the capacity will be exceeded.
+
+
+We will follow similar steps to find all the possiblity.
+
+> We will pick the toy with maximum happiness that is 6 in this case after selecting toy 2 firstly and then selecting toy 2 again.
+
+Here we can notice optimal sub structure as well as overlapping sub problems. Thus we can apply dynamic programming.
+
+* Unqiue states here will be` W + 1 = O(W)` because the capacity can be from 0 to W
+
+Base case for the above question:
+* if capacity is 0, happiness is 0. So, `dp[0] = 0`
+
+Equation `dp[i] = max(h[i] + dp[i - wt[j]])` for all toys j
+
+### Psuedocode
+```java
+for all i, dp[0] = 0
+for (i --> 1 to W){
+ for(j --> 1 to N){
+ if(wt[j] <= i)
+ dp[i] = max(h[i] + dp[i - wt[j]])
+ }
+} return dp[W]
+```
+
+### Complexity
+**Time Complexity:** O(N * W)
+**Space Complexity:** O(W)
+
+
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA DP 4 Applications of Knapsack.md b/Academy DSA Typed Notes/DSA 4.2/DSA DP 4 Applications of Knapsack.md
new file mode 100644
index 0000000..e66caf5
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA DP 4 Applications of Knapsack.md
@@ -0,0 +1,353 @@
+# DSA: DP 4: Applications of Knapsack
+
+---
+title: Agenda of the lecture
+description: What will be covered in the topic?
+duration: 180
+card_type: cue_card
+---
+
+### Agenda
+- Introduction to the knapsack and DP
+- 4 problems from basic to advanced related to Dynamic Programming.
+
+So let's start.
+
+---
+title: Quiz 1
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+Time Complexity of the unbounded 0-1 knapsack problem?
+- W : capacity of knapsack
+- N : no. of elements
+- K : Max weight of any item
+- P : max value of any item
+
+# Choices
+Chose the correct answer
+- [x] O(NW)
+- [ ] O(NK)
+- [ ] O(NP)
+- [ ] O(WK)
+- [ ] O(WP)
+- [ ] O(KP)
+
+
+---
+title: Quiz 1 Explanation
+description:
+duration: 30
+card_type: cue_card
+---
+
+### Explanation
+For every node, we need to go to its left, that's the only way we can reach the smallest one.
+
+---
+title: Introduction to the knapsack and DP
+description: This section explains dynamic programming using examples.
+duration: 180
+card_type: cue_card
+---
+
+### What Is Dynamic Programming?
+In the context of dynamic programming, the ``knapsack problem`` refers to a classic optimization problem that can be solved using dynamic programming techniques.
+
+### Example
+Suppose we are working on solving the fibonacci series problesm, then we can break it into step by step as follows:
+
+
+
+Let us now solve some questions related to dynamic programming.
+
+---
+title: Problem 1 Cut the rod for maximum profit
+description: A rod is to be cut into pieces and we have to get the maximum profit out of it
+duration: 1700
+card_type: cue_card
+---
+
+### Problem Statement
+A rod of length `N` and an array `A` of length `N` is given. The elements (`i`) of the array contain the length of the rod (1-based indexing). Find the maximum values that can be obtained by cutting the rod into some pieces and selling them.
+
+### Example
+Suppose we have the length on `N = 5` and we have to divide it then the division can be done as:
+
+
+
+Now, we can see that $9$ is the maximum value that we can get.
+
+### Solution
+A naive approach to solving this problem would involve considering all possible combinations of cutting the rod into pieces and calculating the total value for each combination. This can be achieved using recursion and backtracking, where for each possible cut, the value of the cut piece is added to the recursively calculated value of the remaining part of the rod. The maximum value obtained among all combinations is the desired result.
+
+### Our Approach
+As we can visualize from the example, there is an overlapping subproblem and an optimal sub-structure. So, we should opt for the DP approach.
+
+> **Note**: We can observe three things here:
+ 1. The maximum capacity is the length of the order.
+ 2. `A[i]` is storing the length of the piece of the rod.
+ 3. The sum of the length of each piece must be less than or equal to ``N``
+The general observation that we can get here from these three things is that it is a knapsack problem.
+
+---
+title: Quiz 2
+description: Type of the above problem.
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+The cutting rod question is:
+
+# Choices
+- [ ] Fractional Knapsack
+- [ ] `0-1` Knapsack
+- [x] Unbounded Knapsack (or `0-N` Knapsack)
+
+---
+title: Cut the rod for maximum profit Approach
+description:
+duration: 1700
+card_type: cue_card
+---
+
+### Approach
+- First, define the state of the dp i.e. `dp[i]`, it will be the maximum value that can be received by the rod of length `i`.
+- The base case will be 0 in the case when the length of the rod is 0. This means `dp[0] = 0`.
+
+We will loop over the array, and then calculate the maximum profit, and finally store the maximum profit in the current dp state.
+
+Let us now see the pseudo-code for the problem.
+### Pseudocode
+```cpp
+for all values of i: dp[i] = 0
+
+for (i = 1 to N) // length of rod to sell = i
+{
+ for (j = 1 to i)
+ {
+ dp[i] = max(dp[i], A[j] + dp[i - j])
+ }
+}
+return dp[N]
+```
+
+### Time and Space Complexity
+- **Time Complexity**: $O(N^2)$, as we are traversing the N-length array using nested for loops (Simply, we can also say that the capacity is `N` and the length of the array is also `N`).
+- **Space Complexity**: `O(N)`, as we are using an extra dp array to store the current state of profit.
+
+> **Note for the instructor**: We can do a dry run for better clarity.
+
+---
+title: Problem 2 Count the number of ways using coins (ordered selection)
+description: Count the number of ways of getting a sum using coins, each coin can be selected multiple times.
+duration: 950
+card_type: cue_card
+---
+
+### Problem Statement
+In how many ways can the sum be equal to ``N`` by using coins given in the array? One coin can be used multiple times.
+
+### Example
+There are 2 ways to solve this problem
+a. **Ordered selection of coin**
+
+Let us create the set of numbers that cummulate the value of `N`.
+
+
+
+So, we can see that we have the value we get is $6$.
+
+Now, let's look at the selection tree of the coin selection. We can divide the number by selecting the choices of subraction.
+
+
+
+
+### Solution - Ordered Selection of Coin
+The naive approach to solving this problem involves using a recursive approach with backtracking. For each coin value in the array, subtract it from the target sum N, and recursively find the number of ways to form the remaining sum using the same coin set. Repeat this process for all coins and sum up the results.
+
+### Approach
+As we can observe from the examples above, we have to calculate the number of ways of selection, it is similar to the unbounded knapsack problem (as one coin can be selected multiple times).
+
+---
+title: Quiz 3
+description: Number of ways of getting the sum 0.
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the number of ways to get `sum = 0`
+
+# Choices
+- [ ] 0
+- [x] 1
+- [ ] 2
+- [ ] Undefined
+
+---
+title: Count the number of ways using coins Pseudocode
+description:
+duration: 950
+card_type: cue_card
+---
+
+### Pseudocode
+```cpp
+for all values of i: dp[i] = 0
+dp[0] = 1
+
+for (i = 1 to N)
+{
+ for (j = 1 to (A.length - 1))
+ {
+ if (A[j] <= i)
+ {
+ dp[i] += dp[i - A[j]]
+ }
+ }
+}
+
+return dp[N]
+```
+
+
+### Time and Space Complexity
+- **Time Complexity**: $O(N * (length~ of ~the ~array))$.
+- **Space Complexity**: $O(N)$.
+
+---
+title: Problem 3 Count the number of ways using coins (un-ordered selection)
+description: Count the number of ways of getting a sum using coins, the coins cannot be selected multiple times.
+duration: 1400
+card_type: cue_card
+---
+
+### Problem Statement
+
+Given a set of coins and a target sum, find the number of ways to make the target sum using the coins, where each coin can only be used once.
+
+### Example
+
+Suppose we have a situation same as the last one.
+N = 5 and coins we have [3, 1, 4].
+
+So here we have 3 possible ways.
+
+Now, let us try to arrage the coins to get the desired value.
+
+ +
+So, what we can observe out of it is:
+- The current state of dp, i.e. `dp[i]` is to select the number of ways to get the sum equal to i by selecting coins from L to R in the array.
+
+### Solution: Un-ordered Selection of Coin
+How we can solve it:
+- Initialize an array dp with all values set to 0. This array will be used to store the number of ways to make change for each possible sum from 0 to N.
+- Set the initial value of `dp[0]` to 1. This step indicates that there is one way to make change for an amount of 0, which is by not using any coins.
+- Iterate through the different coin denominations represented by the array A. This loop will consider each coin one by one.
+- For each coin denomination `A[j]`, iterate through the possible sums from 1 to N. This loop will consider each sum value from 1 to N and calculate the number of ways to make change for that sum.
+- Inside the inner loop, check if the current coin denomination `A[j]` is less than or equal to the current sum `i`. If it is, then it's possible to use this coin to make change for the current sum.
+- If the condition is met, update the `dp` array for the current sum i by adding the number of ways to make change for the remaining amount (`i - A[j]`). This is where dynamic programming comes into play, as you are building up the solutions for larger sums based on the solutions for smaller sums.
+- After both loops complete, the `dp[N]` value will represent the number of ways to make change for the desired amount N using the given coin denominations.
+- Finally, return the value stored in `dp[N]`.
+
+
+### Pseudocode
+```cpp
+for all values of i:dp[i] = 0
+dp[0] = 1
+
+for (j = 0 to (A.length - 1)) // coins
+{
+ for (i = 1 to N) // sum
+ {
+ if (A[j] <= i)
+ {
+ dp[i] += dp[i - A[j]]
+ }
+ }
+}
+
+return dp[N]
+```
+
+
+### Time and Space Complexity
+- **Time Complexity**: $O(N * (length~ of~ the~ array))$.
+- **Space Complexity**: `O(N)`.
+
+> **Note for the instructor**: We can do a dry run for better clarity.
+
+
+---
+title: Problem 4 Extended 0-1 Knapsack Problem
+description: Solution problem - Calculate the maximum happiness.
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+We are given `N` toys with their happiness and weight. Find max total happiness that can be kept in a bag with the capacity `W`. Here, we cannot divide the toys.
+
+The constraints are:
+$- 1 <= N <= 500$
+$- 1 <= h[i] <= 50$
+$- 1 <= wt[i] <= 10^9$
+$- 1 <= W <= 10^9$
+
+
+---
+title: Quiz 4
+description:
+duration: 60
+card_type: quiz_card
+---
+
+
+# Question
+What is the MAX value we can get for these items i.e. (weight, value) pairs in 0-1 knapsack of capacity W = 8.
+Items = [(3, 12), (6, 20), (5, 15), (2, 6), (4, 10)]
+
+Chose the correct answer
+
+
+# Choices
+- [x] 27
+- [ ] 28
+- [ ] 29
+- [ ] 30
+
+
+---
+title: Quiz 4 Explanation
+description:
+duration: 30
+card_type: cue_card
+---
+
+### Explanation
+
+Simple 0-1 Knapsack, after trying all combinations 27 is the highest value we can have inside the knapsack.
+
+---
+title: Extended 0-1 Knapsack Problem Approach and Explanation
+description:
+duration: 850
+card_type: cue_card
+---
+### Approach and Calculations
+
+
+
+The normal approach to solve this problem would involve using a recursive or iterative algorithm to consider all possible combinations of toys and select the one with the maximum happiness that doesn't exceed the weight limit. However, due to the constraints provided (N up to 500, `wt[i]` up to $10^9$, ``W`` up to $10^9$), this approach would be extremely slow and inefficient.
+
+By employing dynamic programming, we can optimize the solution significantly. The DP approach allows us to break down the problem into subproblems and store the results of these subproblems in a table to avoid redundant calculations. In this case, we can use a 2-D DP table where `dp[i][w]` represents the maximum happiness that can be achieved with the first `i` toys and a weight constraint of `w`.
+
+DP offers a much faster solution, as it reduces the time complexity from exponential to polynomial time, making it suitable for large inputs like those in the given constraints. Therefore, opting for a DP approach is essential to meet the time and pace constraints of this problem.
+
+> **Note for the instructor**: Assist the students with the calculations of the dp array so that they can get to know why the original knapsack solution (discussed in the last video) will lead to **``TLE``** and give them homework.
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 1 Introduction, DFS & Cycle Detection.md b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
new file mode 100644
index 0000000..6839731
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
@@ -0,0 +1,658 @@
+# Graphs 1: Introduction with BFS & DFS
+
+---
+title: How to Approach Mock Interview
+description:
+duration: 600
+card_type: cue_card
+---
+
+Hey Everyone,
+We will be starting our last DSA topic before the mock Interview. Before starting this topic I want to make sure that everyone is informed about the Mandatory Skill Evaluation contest and Mock Interviews .
+We will be having the contest in our last class which will consist of the entire DSA curriculum.This contest will be of 2.5 hrs .Following the contest, we'll hold a discussion the next day to review the contest and discuss our approaches to mock interviews.
+
+To help you prepare, I'm sharing the DSA toolkit with all of you. - ***https://bit.ly/48wVeRS***
+
+
+Let’s give our best and make sure we clear the contest as well as Mock Interview ASAP.
+
+---
+title: Graphs Introduction
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Introduction
+
+**Graph**: It is a collection of nodes and edges.
+
+Some real life examples of Graph -
+1. Network of computers
+2. A Website
+3. Google Maps
+4. Social Media
+
+
+
+So, what we can observe out of it is:
+- The current state of dp, i.e. `dp[i]` is to select the number of ways to get the sum equal to i by selecting coins from L to R in the array.
+
+### Solution: Un-ordered Selection of Coin
+How we can solve it:
+- Initialize an array dp with all values set to 0. This array will be used to store the number of ways to make change for each possible sum from 0 to N.
+- Set the initial value of `dp[0]` to 1. This step indicates that there is one way to make change for an amount of 0, which is by not using any coins.
+- Iterate through the different coin denominations represented by the array A. This loop will consider each coin one by one.
+- For each coin denomination `A[j]`, iterate through the possible sums from 1 to N. This loop will consider each sum value from 1 to N and calculate the number of ways to make change for that sum.
+- Inside the inner loop, check if the current coin denomination `A[j]` is less than or equal to the current sum `i`. If it is, then it's possible to use this coin to make change for the current sum.
+- If the condition is met, update the `dp` array for the current sum i by adding the number of ways to make change for the remaining amount (`i - A[j]`). This is where dynamic programming comes into play, as you are building up the solutions for larger sums based on the solutions for smaller sums.
+- After both loops complete, the `dp[N]` value will represent the number of ways to make change for the desired amount N using the given coin denominations.
+- Finally, return the value stored in `dp[N]`.
+
+
+### Pseudocode
+```cpp
+for all values of i:dp[i] = 0
+dp[0] = 1
+
+for (j = 0 to (A.length - 1)) // coins
+{
+ for (i = 1 to N) // sum
+ {
+ if (A[j] <= i)
+ {
+ dp[i] += dp[i - A[j]]
+ }
+ }
+}
+
+return dp[N]
+```
+
+
+### Time and Space Complexity
+- **Time Complexity**: $O(N * (length~ of~ the~ array))$.
+- **Space Complexity**: `O(N)`.
+
+> **Note for the instructor**: We can do a dry run for better clarity.
+
+
+---
+title: Problem 4 Extended 0-1 Knapsack Problem
+description: Solution problem - Calculate the maximum happiness.
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+We are given `N` toys with their happiness and weight. Find max total happiness that can be kept in a bag with the capacity `W`. Here, we cannot divide the toys.
+
+The constraints are:
+$- 1 <= N <= 500$
+$- 1 <= h[i] <= 50$
+$- 1 <= wt[i] <= 10^9$
+$- 1 <= W <= 10^9$
+
+
+---
+title: Quiz 4
+description:
+duration: 60
+card_type: quiz_card
+---
+
+
+# Question
+What is the MAX value we can get for these items i.e. (weight, value) pairs in 0-1 knapsack of capacity W = 8.
+Items = [(3, 12), (6, 20), (5, 15), (2, 6), (4, 10)]
+
+Chose the correct answer
+
+
+# Choices
+- [x] 27
+- [ ] 28
+- [ ] 29
+- [ ] 30
+
+
+---
+title: Quiz 4 Explanation
+description:
+duration: 30
+card_type: cue_card
+---
+
+### Explanation
+
+Simple 0-1 Knapsack, after trying all combinations 27 is the highest value we can have inside the knapsack.
+
+---
+title: Extended 0-1 Knapsack Problem Approach and Explanation
+description:
+duration: 850
+card_type: cue_card
+---
+### Approach and Calculations
+
+
+
+The normal approach to solve this problem would involve using a recursive or iterative algorithm to consider all possible combinations of toys and select the one with the maximum happiness that doesn't exceed the weight limit. However, due to the constraints provided (N up to 500, `wt[i]` up to $10^9$, ``W`` up to $10^9$), this approach would be extremely slow and inefficient.
+
+By employing dynamic programming, we can optimize the solution significantly. The DP approach allows us to break down the problem into subproblems and store the results of these subproblems in a table to avoid redundant calculations. In this case, we can use a 2-D DP table where `dp[i][w]` represents the maximum happiness that can be achieved with the first `i` toys and a weight constraint of `w`.
+
+DP offers a much faster solution, as it reduces the time complexity from exponential to polynomial time, making it suitable for large inputs like those in the given constraints. Therefore, opting for a DP approach is essential to meet the time and pace constraints of this problem.
+
+> **Note for the instructor**: Assist the students with the calculations of the dp array so that they can get to know why the original knapsack solution (discussed in the last video) will lead to **``TLE``** and give them homework.
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 1 Introduction, DFS & Cycle Detection.md b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
new file mode 100644
index 0000000..6839731
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 1 Introduction, DFS & Cycle Detection.md
@@ -0,0 +1,658 @@
+# Graphs 1: Introduction with BFS & DFS
+
+---
+title: How to Approach Mock Interview
+description:
+duration: 600
+card_type: cue_card
+---
+
+Hey Everyone,
+We will be starting our last DSA topic before the mock Interview. Before starting this topic I want to make sure that everyone is informed about the Mandatory Skill Evaluation contest and Mock Interviews .
+We will be having the contest in our last class which will consist of the entire DSA curriculum.This contest will be of 2.5 hrs .Following the contest, we'll hold a discussion the next day to review the contest and discuss our approaches to mock interviews.
+
+To help you prepare, I'm sharing the DSA toolkit with all of you. - ***https://bit.ly/48wVeRS***
+
+
+Let’s give our best and make sure we clear the contest as well as Mock Interview ASAP.
+
+---
+title: Graphs Introduction
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Introduction
+
+**Graph**: It is a collection of nodes and edges.
+
+Some real life examples of Graph -
+1. Network of computers
+2. A Website
+3. Google Maps
+4. Social Media
+
+ +
+
+
+ +
+
+
+
+---
+title: Types of Graph
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Cyclic Graph
+
+A cyclic graph contains at least one cycle, which is a closed path that returns to the same vertex.
+Diagram:
+```javascript
+A -- B
+| |
+| |
+D -- C
+```
+
+### Acyclic Graph
+An acyclic graph has no cycles, meaning there are no closed paths in the graph.
+Diagram:
+```javascript
+A -- B
+| |
+D C
+```
+
+### Directed Graph (Digraph)
+In a directed graph, edges have a direction, indicating one-way relationships between vertices.
+Diagram:
+```javascript
+A --> B
+| |
+v v
+D --> C
+```
+
+### Undirected Graph
+In an undirected graph, edges have no direction, representing symmetric relationships between vertices.
+Diagram:
+```javascript
+A -- B
+| |
+| |
+D -- C
+```
+
+### Connected Graph
+A connected graph has a path between every pair of vertices, ensuring no isolated vertices.
+Diagram
+```javascript
+A -- B
+|
+D -- C
+```
+
+### Disconnected Graph
+A disconnected graph has at least two disconnected components, meaning there is no path between them.
+Diagram:
+```javascript
+A -- B C -- D
+| |
+E -- F G -- H
+```
+
+### Weighted Graph
+In a weighted graph, edges have associated weights or costs, often used to represent distances, costs, or other metrics.
+Diagram (Undirected with Weights):
+```javascript
+A -2- B
+| |
+1 3
+| |
+D -4- C
+```
+
+### Unweighted Graph
+An unweighted graph has no associated weights on its edges.
+Diagram (Undirected Unweighted):
+```javascript
+A -- B
+|
+D -- C
+```
+
+### Degree of a Vertex
+The degree of a vertex is the number of edges incident to it.
+Diagram:
+```javascript
+ B
+ |
+A--C--D
+```
+
+### Outdegree of a Vertex
+The outdegree of a vertex in a directed graph is the number of edges leaving that vertex.
+Diagram:
+```javascript
+A --> B
+| |
+v v
+D --> C
+```
+
+### Simple Graph
+A simple graph has no self-loops or multiple edges between the same pair of vertices.
+Diagram:
+```javascript
+A -- B
+|
+D -- C
+```
+
+
+
+---
+title: How to store a graph
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Graph:
+
+
+
+
+
+
+---
+title: Types of Graph
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Cyclic Graph
+
+A cyclic graph contains at least one cycle, which is a closed path that returns to the same vertex.
+Diagram:
+```javascript
+A -- B
+| |
+| |
+D -- C
+```
+
+### Acyclic Graph
+An acyclic graph has no cycles, meaning there are no closed paths in the graph.
+Diagram:
+```javascript
+A -- B
+| |
+D C
+```
+
+### Directed Graph (Digraph)
+In a directed graph, edges have a direction, indicating one-way relationships between vertices.
+Diagram:
+```javascript
+A --> B
+| |
+v v
+D --> C
+```
+
+### Undirected Graph
+In an undirected graph, edges have no direction, representing symmetric relationships between vertices.
+Diagram:
+```javascript
+A -- B
+| |
+| |
+D -- C
+```
+
+### Connected Graph
+A connected graph has a path between every pair of vertices, ensuring no isolated vertices.
+Diagram
+```javascript
+A -- B
+|
+D -- C
+```
+
+### Disconnected Graph
+A disconnected graph has at least two disconnected components, meaning there is no path between them.
+Diagram:
+```javascript
+A -- B C -- D
+| |
+E -- F G -- H
+```
+
+### Weighted Graph
+In a weighted graph, edges have associated weights or costs, often used to represent distances, costs, or other metrics.
+Diagram (Undirected with Weights):
+```javascript
+A -2- B
+| |
+1 3
+| |
+D -4- C
+```
+
+### Unweighted Graph
+An unweighted graph has no associated weights on its edges.
+Diagram (Undirected Unweighted):
+```javascript
+A -- B
+|
+D -- C
+```
+
+### Degree of a Vertex
+The degree of a vertex is the number of edges incident to it.
+Diagram:
+```javascript
+ B
+ |
+A--C--D
+```
+
+### Outdegree of a Vertex
+The outdegree of a vertex in a directed graph is the number of edges leaving that vertex.
+Diagram:
+```javascript
+A --> B
+| |
+v v
+D --> C
+```
+
+### Simple Graph
+A simple graph has no self-loops or multiple edges between the same pair of vertices.
+Diagram:
+```javascript
+A -- B
+|
+D -- C
+```
+
+
+
+---
+title: How to store a graph
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Graph:
+
+ +
+### Adjacency Matrix:
+All the edges in above graph has equal weights.
+In adjacency matrix, `mat[i][j] = 1`, if there is an edge between them else it will be 0.
+
+
+
+### Adjacency Matrix:
+All the edges in above graph has equal weights.
+In adjacency matrix, `mat[i][j] = 1`, if there is an edge between them else it will be 0.
+
+ +
+
+
+#### Pseudocode:
+
+```cpp
+int N, M
+int mat[N+1][M+1] = {0}
+
+for(int i=0; i < A.size(); i++) {
+ u = A[i][0];
+ v = A[i][1];
+
+ mat[u][v] = 1
+ mat[v][u] = 1
+}
+```
+
+Note: In case of weighted graph, we store weights in the matrix.
+
+**Advantage:** Easy to update new edges.
+
+**Disadvantage:** Space wastage because of also leaving space for non-exitent edges.
+Moreover,
+If N<=10^5, it won't be possible to create matrix of size 10^10.
+It is possible only if N <= 10^3
+
+
+**Space Complexity:** O(N^2^)
+
+### 2. Adjacency List:
+
+An adjacency list is a common way to represent a graph in computer science. It's used to describe which nodes (or vertices) in the graph are connected to each other. Here's how it works:
+
+#### Graph:
+
+
+
+#### Adjacency List:
+
+Stores the list of nodes connected corresponding to every node.
+
+
+
+
+#### Pseudocode:
+
+```cpp
+int N, M
+int mat[N+1][M+1] = {0}
+
+for(int i=0; i < A.size(); i++) {
+ u = A[i][0];
+ v = A[i][1];
+
+ mat[u][v] = 1
+ mat[v][u] = 1
+}
+```
+
+Note: In case of weighted graph, we store weights in the matrix.
+
+**Advantage:** Easy to update new edges.
+
+**Disadvantage:** Space wastage because of also leaving space for non-exitent edges.
+Moreover,
+If N<=10^5, it won't be possible to create matrix of size 10^10.
+It is possible only if N <= 10^3
+
+
+**Space Complexity:** O(N^2^)
+
+### 2. Adjacency List:
+
+An adjacency list is a common way to represent a graph in computer science. It's used to describe which nodes (or vertices) in the graph are connected to each other. Here's how it works:
+
+#### Graph:
+
+
+
+#### Adjacency List:
+
+Stores the list of nodes connected corresponding to every node.
+ +
+We can create map of
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Time Complexity for DFS?
+
+# Choices
+- [x] O(V + E)
+- [ ] O(V)
+- [ ] O(2E)
+
+---
+title: Quiz 2 Explanation
+description:
+duration: 300
+card_type: cue_card
+---
+
+
+### Explanation:
+
+The time complexity of the DFS algorithm is O(V + E), where V is the number of vertices (nodes) in the graph, and E is the number of edges. This is because, in the worst case, the algorithm visits each vertex once and each edge once.
+
+**Space Complexity:** O(V)
+
+
+---
+title: Problem 1 Detecting Cycles in a Directed Graph
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+Check if given graph has a cycle?
+
+### Examples
+
+1)
+
+
+2)
+
+
+
+
+[**Students may say:**] Apply DFS and if we come accross a visited node, then there's a cycle
+**Counter Example:** It is not true, because we can come to a visited node via some other path
+For eg, in Example 2, start at 0 -> 1 -> 3, now we can't go anywhere, backtrack to 1->2, then via 2 we'll find 3 which is already visited but there's no cycle in the graph.
+
+
+### Approach
+
+Apply DFS, if a node in current path is encountered again, it means cycle is present!
+With this, we will have to keep track of the path.
+
+Example 1:
+
+
+>Say we start at 0 -> 1 -> 3
+path[] = {0, 1, 3}
+Now, while coming back from 3, we can remove the 3 from path array.
+path[] = {0, 1}
+Now, 0 -> 1 -> 2 -> 3
+path[] = {0, 1, 2, 3} ***[Here, we came back to 3, but via different path, which is not an issue for us]***
+
+Example 2:
+
+
+> Say we start at 0 -> 1 -> 2 -> 3
+path[] = {0, 1, 2, 3}
+Now, from 3, we come back to 1.
+path[] = {0, 1, 2, 3, 1} ***[But 1 is already a part of that path, which means cycle is present]***
+
+### Pseudocode
+
+```javascript
+list
+
+In this case we can see that our answer is 5.
+
+**Que: Do we need adjacency list ?**
+Ans: No, since the information is already present in form of matrix which can be utilised as it is.
+
+### Approach:
+
+**Set a Counter:** Start with a counter at zero for tracking island count.
+
+**Scan the Grid:** Go through each cell in the grid.
+
+**Search for Islands:** When you find a land cell ('1'), use either BFS or DFS to explore all connected land cells.
+
+**Mark Visited Cells:** Change each visited '1' to '0' during the search to avoid recounting.
+
+**Count Each Island:** Increase the counter by 1 for every complete search that identifies a new island.
+
+**Finish the Search:** Continue until all grid cells are checked.
+
+**Result:** The counter will indicate the total number of islands.
+
+
+---
+title: Number of Islands Dry Run and Pseudocode
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Dry-Run:
+```java
+[
+ ['1', '1', '0', '0', '0'],
+ ['1', '1', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+
+* Initialize variable islands = 0.
+* Start iterating through the grid:
+* At grid[0][0], we find '1'. Increment islands to 1 and call visitIsland(grid, 0, 0).
+* visitIsland will mark all connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+
+
+```cpp-
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '1', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue iterating through the grid:
+* At grid[2][2], we find '1'. Increment islands to 2 and call visitIsland(grid, 2, 2).
+* visitIsland will mark connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+```java
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue the iteration.
+* At grid[3][3], we find '1'. Increment islands to 3 and call visitIsland(grid, 3, 3).
+
+We can visit only 4 coordinates, considering them to be i, j; it means we can visit **(i,j-1), (i-1, j), (i, j+1), (i+1, j)**
+
+
+
+### Pseudocode
+
+
+
+
+
+
+
+---
+title: LinkedIN - Maximising the Reach
+description:
+duration: 300
+card_type: cue_card
+---
+
+## Problem
+In the LinkedIn ecosystem, understanding the structure of professional networks is crucial for both users and the platform itself.
+
+A new feature is being developed to visualize the network of a user in terms of "**clusters**". These clusters represent groups of LinkedIn users who are all connected to each other, either directly or through mutual connections, but do not have connections to users outside their cluster. This visualization aims to help users to increase their **Reach**.
+
+### Problem Statement
+Given **A** denoting the total number of people and matrix B of size Mx2, denoting the bidirectional connections between LinkeIN users, and an Integer C denoting the user ID of each connection joins two users by their user IDs, the target person, find out the number of connections that this person should make in order to connect with all the networks.
+
+### Intuition :-
+We need to find out the number of clusters except the cluster containing person with ID C.
+
+
+### Approach :-
+Let's calculate the total number of clusters, the final answer will be (Total number of clusters - 1)
+
+### Implementation :-
+Let's implement this idea using DFS traversal, we want to count the number of connected components in the given graph.
+Don't forget that some nodes might be isolated and not connected to any other node, so don't miss them out.
+
+### Code:
+
+We'll take a visited array to mark the visited nodes, and increment the answer when a node is unvisited.
+
+```java
+public class Solution {
+
+ private ArrayList
@@ -102,8 +124,13 @@ In the beginning, we need to push all source node at once and apply exact BFS,th
* **SC -** O(N+E)
---
-### Rotten Oranges
+title: Rotten Oranges
+description:
+duration: 2000
+card_type: cue_card
+---
+#### Problem
There is given a matrix and there are 3 values where 0 means empty cell, 1 means fresh orange present and 2 means rotten orange prsent, we need to find the time when all oranges will become rotten.
**Note:** If not possible, return - 1.
@@ -130,7 +157,7 @@ public class RottingOranges {
public int orangesRotting(int[][] grid) {
int rowCount = grid.length;
int colCount = grid[0].length;
- Queue< int[] > queue = new LinkedList< >();
+ Queue
In the above photo we can refer the indegree of each of the nodes is written in green.
-#### Pseudocode:
+### Pseudocode:
+
```java
-in [N], i, in [i] = 0;
-for (i = 0; i < n; i++) {
- for (nbr: adj[i]) {
- ibr[i] += 1;
+in_degree[N], i,
+for(i = 0; i < n; i++)
+ in_degree[i] = 0;
+
+for(i = 0; i < n; i++)
+{
+ for(neighbour : adj[i])
+ {
+ in_degree[i] += 1;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N + E)
**Space Complexity:** 0(N)
---
-### Topological Sort (Right to Left)
-
+title: Topological Sort (Right to Left)
+description:
+duration: 900
+card_type: cue_card
+---
+### Topological Sort
In a right-to-left topological order, you start from the "rightmost" vertex (i.e., a vertex with no outgoing edges) and proceed leftward. This approach can be useful in certain situations and can be thought of as a reverse topological ordering.
Here's how you can approach it:
-#### Approach:
+### Approach:
* Identify a vertex with no outgoing edges (in-degree = 0). If there are multiple such vertices, you can choose any of them.
* Remove that vertex from the graph along with all its outgoing edges. This removal may affect the in-degrees of other vertices.
* Repeat steps 1 and 2 until all vertices are removed from the graph. The order in which you remove the vertices constitutes the right-to-left topological order.
-#### Example/Dry-Run:
+### Example/Dry-Run:
```java
A -> B -> C
| |
@@ -351,7 +429,7 @@ v
```
The order in which you removed the vertices is a right-to-left topological order: C, B, A, D, E.
-#### Pseudocode
+### Pseudocode
```java
function topologicalSortRightToLeft(graph):
// Function to perform DFS and record nodes in the order they are finished
@@ -374,24 +452,35 @@ function topologicalSortRightToLeft(graph):
return the reversed order list as the topological order (right-to-left)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(V+E)
**Space Complexity:** O(V)
---
-### Question
+title: Quiz 2
+description:
+duration: 90
+card_type: quiz_card
+---
+
+# Question
Which of the following is correct topological order for this graph?
-**Choices**
+# Choices
- [x] TD,TA,TC,TB
- [ ] TA,TD,TC,TB
- [ ] TC,TA,TD,TB
---
-### Another approach to BFS
+title: Why BFS leads to shortest path
+description:
+duration: 900
+card_type: cue_card
+---
+### Question
Find the minimum number of edges to reach v starting from u in undirected simple graph.
@@ -400,7 +489,7 @@ Find the minimum number of edges to reach v starting from u in undirected simple
+
+We can create map of
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Time Complexity for DFS?
+
+# Choices
+- [x] O(V + E)
+- [ ] O(V)
+- [ ] O(2E)
+
+---
+title: Quiz 2 Explanation
+description:
+duration: 300
+card_type: cue_card
+---
+
+
+### Explanation:
+
+The time complexity of the DFS algorithm is O(V + E), where V is the number of vertices (nodes) in the graph, and E is the number of edges. This is because, in the worst case, the algorithm visits each vertex once and each edge once.
+
+**Space Complexity:** O(V)
+
+
+---
+title: Problem 1 Detecting Cycles in a Directed Graph
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+Check if given graph has a cycle?
+
+### Examples
+
+1)
+
+
+2)
+
+
+
+
+[**Students may say:**] Apply DFS and if we come accross a visited node, then there's a cycle
+**Counter Example:** It is not true, because we can come to a visited node via some other path
+For eg, in Example 2, start at 0 -> 1 -> 3, now we can't go anywhere, backtrack to 1->2, then via 2 we'll find 3 which is already visited but there's no cycle in the graph.
+
+
+### Approach
+
+Apply DFS, if a node in current path is encountered again, it means cycle is present!
+With this, we will have to keep track of the path.
+
+Example 1:
+
+
+>Say we start at 0 -> 1 -> 3
+path[] = {0, 1, 3}
+Now, while coming back from 3, we can remove the 3 from path array.
+path[] = {0, 1}
+Now, 0 -> 1 -> 2 -> 3
+path[] = {0, 1, 2, 3} ***[Here, we came back to 3, but via different path, which is not an issue for us]***
+
+Example 2:
+
+
+> Say we start at 0 -> 1 -> 2 -> 3
+path[] = {0, 1, 2, 3}
+Now, from 3, we come back to 1.
+path[] = {0, 1, 2, 3, 1} ***[But 1 is already a part of that path, which means cycle is present]***
+
+### Pseudocode
+
+```javascript
+list
+
+In this case we can see that our answer is 5.
+
+**Que: Do we need adjacency list ?**
+Ans: No, since the information is already present in form of matrix which can be utilised as it is.
+
+### Approach:
+
+**Set a Counter:** Start with a counter at zero for tracking island count.
+
+**Scan the Grid:** Go through each cell in the grid.
+
+**Search for Islands:** When you find a land cell ('1'), use either BFS or DFS to explore all connected land cells.
+
+**Mark Visited Cells:** Change each visited '1' to '0' during the search to avoid recounting.
+
+**Count Each Island:** Increase the counter by 1 for every complete search that identifies a new island.
+
+**Finish the Search:** Continue until all grid cells are checked.
+
+**Result:** The counter will indicate the total number of islands.
+
+
+---
+title: Number of Islands Dry Run and Pseudocode
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Dry-Run:
+```java
+[
+ ['1', '1', '0', '0', '0'],
+ ['1', '1', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+
+* Initialize variable islands = 0.
+* Start iterating through the grid:
+* At grid[0][0], we find '1'. Increment islands to 1 and call visitIsland(grid, 0, 0).
+* visitIsland will mark all connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+
+
+```cpp-
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '1', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue iterating through the grid:
+* At grid[2][2], we find '1'. Increment islands to 2 and call visitIsland(grid, 2, 2).
+* visitIsland will mark connected land cells as '0', and we explore the neighboring cells recursively. After this, the grid becomes:
+```java
+[
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '0', '0'],
+ ['0', '0', '0', '1', '1']
+]
+```
+* Continue the iteration.
+* At grid[3][3], we find '1'. Increment islands to 3 and call visitIsland(grid, 3, 3).
+
+We can visit only 4 coordinates, considering them to be i, j; it means we can visit **(i,j-1), (i-1, j), (i, j+1), (i+1, j)**
+
+
+
+### Pseudocode
+
+
+
+
+
+
+
+---
+title: LinkedIN - Maximising the Reach
+description:
+duration: 300
+card_type: cue_card
+---
+
+## Problem
+In the LinkedIn ecosystem, understanding the structure of professional networks is crucial for both users and the platform itself.
+
+A new feature is being developed to visualize the network of a user in terms of "**clusters**". These clusters represent groups of LinkedIn users who are all connected to each other, either directly or through mutual connections, but do not have connections to users outside their cluster. This visualization aims to help users to increase their **Reach**.
+
+### Problem Statement
+Given **A** denoting the total number of people and matrix B of size Mx2, denoting the bidirectional connections between LinkeIN users, and an Integer C denoting the user ID of each connection joins two users by their user IDs, the target person, find out the number of connections that this person should make in order to connect with all the networks.
+
+### Intuition :-
+We need to find out the number of clusters except the cluster containing person with ID C.
+
+
+### Approach :-
+Let's calculate the total number of clusters, the final answer will be (Total number of clusters - 1)
+
+### Implementation :-
+Let's implement this idea using DFS traversal, we want to count the number of connected components in the given graph.
+Don't forget that some nodes might be isolated and not connected to any other node, so don't miss them out.
+
+### Code:
+
+We'll take a visited array to mark the visited nodes, and increment the answer when a node is unvisited.
+
+```java
+public class Solution {
+
+ private ArrayList
@@ -102,8 +124,13 @@ In the beginning, we need to push all source node at once and apply exact BFS,th
* **SC -** O(N+E)
---
-### Rotten Oranges
+title: Rotten Oranges
+description:
+duration: 2000
+card_type: cue_card
+---
+#### Problem
There is given a matrix and there are 3 values where 0 means empty cell, 1 means fresh orange present and 2 means rotten orange prsent, we need to find the time when all oranges will become rotten.
**Note:** If not possible, return - 1.
@@ -130,7 +157,7 @@ public class RottingOranges {
public int orangesRotting(int[][] grid) {
int rowCount = grid.length;
int colCount = grid[0].length;
- Queue< int[] > queue = new LinkedList< >();
+ Queue
In the above photo we can refer the indegree of each of the nodes is written in green.
-#### Pseudocode:
+### Pseudocode:
+
```java
-in [N], i, in [i] = 0;
-for (i = 0; i < n; i++) {
- for (nbr: adj[i]) {
- ibr[i] += 1;
+in_degree[N], i,
+for(i = 0; i < n; i++)
+ in_degree[i] = 0;
+
+for(i = 0; i < n; i++)
+{
+ for(neighbour : adj[i])
+ {
+ in_degree[i] += 1;
}
}
```
-#### Complexity
+### Complexity
**Time Complexity:** O(N + E)
**Space Complexity:** 0(N)
---
-### Topological Sort (Right to Left)
-
+title: Topological Sort (Right to Left)
+description:
+duration: 900
+card_type: cue_card
+---
+### Topological Sort
In a right-to-left topological order, you start from the "rightmost" vertex (i.e., a vertex with no outgoing edges) and proceed leftward. This approach can be useful in certain situations and can be thought of as a reverse topological ordering.
Here's how you can approach it:
-#### Approach:
+### Approach:
* Identify a vertex with no outgoing edges (in-degree = 0). If there are multiple such vertices, you can choose any of them.
* Remove that vertex from the graph along with all its outgoing edges. This removal may affect the in-degrees of other vertices.
* Repeat steps 1 and 2 until all vertices are removed from the graph. The order in which you remove the vertices constitutes the right-to-left topological order.
-#### Example/Dry-Run:
+### Example/Dry-Run:
```java
A -> B -> C
| |
@@ -351,7 +429,7 @@ v
```
The order in which you removed the vertices is a right-to-left topological order: C, B, A, D, E.
-#### Pseudocode
+### Pseudocode
```java
function topologicalSortRightToLeft(graph):
// Function to perform DFS and record nodes in the order they are finished
@@ -374,24 +452,35 @@ function topologicalSortRightToLeft(graph):
return the reversed order list as the topological order (right-to-left)
```
-#### Complexity
+### Complexity
**Time Complexity:** O(V+E)
**Space Complexity:** O(V)
---
-### Question
+title: Quiz 2
+description:
+duration: 90
+card_type: quiz_card
+---
+
+# Question
Which of the following is correct topological order for this graph?
-**Choices**
+# Choices
- [x] TD,TA,TC,TB
- [ ] TA,TD,TC,TB
- [ ] TC,TA,TD,TB
---
-### Another approach to BFS
+title: Why BFS leads to shortest path
+description:
+duration: 900
+card_type: cue_card
+---
+### Question
Find the minimum number of edges to reach v starting from u in undirected simple graph.
@@ -400,7 +489,7 @@ Find the minimum number of edges to reach v starting from u in undirected simple
) -#### Approach
+### Approach
Imagine you're playing a game where you have to find the quickest way from point A (vertex u) to point B (vertex v) in a giant maze. This is similar to using Breadth-First Search (BFS) in a graph.
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
new file mode 100644
index 0000000..f8e3cc4
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
@@ -0,0 +1,575 @@
+# Graphs 3: MST & Dijkstra
+
+---
+title: Agenda of the lecture
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Agenda of the lecture:
+
+* Challenges in Flipkart's Logistics and Delivery Operations
+* Prim's Algorithm
+* Djikstra's Algorithm
+
+---
+title: Challenges in Flipkarts Logistics and Delivery
+description:
+duration: 900
+card_type: cue_card
+---
+
+**Scenario:**
+Suppose Flipkart has N local distribution centers spread across a large metropolitan city. These centers need to be interconnected for efficient movement of goods. However, building and maintaining roads between these centers is costly. Flipkart's goal is to minimize these costs while ensuring every center is connected and operational.
+
+**Goal:** You are given number of centers and possible connections that can be made with their cost. Find minimum cost of constructing roads between centers such that it is possible to travel from one center to any other via roads.
+
+
+
+### Explanation
+
+**Example:**
+
+
-#### Approach
+### Approach
Imagine you're playing a game where you have to find the quickest way from point A (vertex u) to point B (vertex v) in a giant maze. This is similar to using Breadth-First Search (BFS) in a graph.
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
new file mode 100644
index 0000000..f8e3cc4
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Graphs 3 MST (Prims Algo.) & Dijkstra Algo.md
@@ -0,0 +1,575 @@
+# Graphs 3: MST & Dijkstra
+
+---
+title: Agenda of the lecture
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Agenda of the lecture:
+
+* Challenges in Flipkart's Logistics and Delivery Operations
+* Prim's Algorithm
+* Djikstra's Algorithm
+
+---
+title: Challenges in Flipkarts Logistics and Delivery
+description:
+duration: 900
+card_type: cue_card
+---
+
+**Scenario:**
+Suppose Flipkart has N local distribution centers spread across a large metropolitan city. These centers need to be interconnected for efficient movement of goods. However, building and maintaining roads between these centers is costly. Flipkart's goal is to minimize these costs while ensuring every center is connected and operational.
+
+**Goal:** You are given number of centers and possible connections that can be made with their cost. Find minimum cost of constructing roads between centers such that it is possible to travel from one center to any other via roads.
+
+
+
+### Explanation
+
+**Example:**
+
+ +
+
+
+**Output:**
+
+
+
+
+
+**Output:**
+
+ +
+
+### Idea:
+
+To achieve the lowest cost in our scenario, consider these key points:
+
+1. **Aim for Fewer roads:** Minimizing the number of roads directly leads to reduced costs.
+
+2. **Opt for a Tree Structure:** Why a tree? Well, in the world of data structures, a tree uniquely stands out when it comes to minimal connections. For any given N nodes, a tree is the only structure that connects all nodes with exactly N - 1 edges. This is precisely what we need - the bare minimum of edges to connect all points, ensuring the lowest possible number of roads.
+
+
+**Another Example:**
+
+
+
+
+### Idea:
+
+To achieve the lowest cost in our scenario, consider these key points:
+
+1. **Aim for Fewer roads:** Minimizing the number of roads directly leads to reduced costs.
+
+2. **Opt for a Tree Structure:** Why a tree? Well, in the world of data structures, a tree uniquely stands out when it comes to minimal connections. For any given N nodes, a tree is the only structure that connects all nodes with exactly N - 1 edges. This is precisely what we need - the bare minimum of edges to connect all points, ensuring the lowest possible number of roads.
+
+
+**Another Example:**
+
+ +
+The end goal is that all centers should be connected.
+
+**Possible Solutions -**
+
+
+
+The end goal is that all centers should be connected.
+
+**Possible Solutions -**
+
+ +
+Here first is better because the sum of all edge weights is minimum.
+
+The tree which spans (covers) all the vertices with the minimum number of edges needed to connect them is known as **Spanning Tree**.
+
+### Minimum Spanning Tree
+
+The minimum spanning tree has all the properties of a spanning tree with an added constraint of having the minimum possible weights among all possible spanning trees.
+
+**Uniqueness of MST:** If all edge weights are unique, there's only one MST. If some weights are the same, multiple MSTs can exist.
+
+**Algorithms for MST:** Kruskal's and Prim's algorithms are used to find MSTs. The MST found can vary based on the choices made for edges with equal weights. Both algorithms solve for same problem having same time and space complexities.
+
+*Note: We'll cover Prim's in today's session, Kruskal shall be covered in DSA 4.2*
+
+### Solution to Flipkart's problem
+
+**Application of MST:**
+* **Identify All Possible Connections:** First, identify all the possible routes that can connect these N centers. Imagine this as a network where each center is a node, and each possible road between two centers is an edge.
+
+* **Assign Costs:** Assign a cost to each potential road, based on factors like distance, traffic, or construction expenses. In real-life terms, shorter and more straightforward routes would generally cost less.
+
+* **Create the MST:** Now, apply the MST algorithm (like Kruskal's or Prim's). The algorithm will select routes that connect all the centers with the least total cost, without forming any loops or cycles.
+
+* **Outcome:** The result is a network of roads connecting all centers with the shortest total length or the lowest cost.
+
+---
+title: Prims Algorithm
+description:
+duration: 900
+card_type: cue_card
+---
+
+Let's consider the below **Graph:**
+
+
+
+Here first is better because the sum of all edge weights is minimum.
+
+The tree which spans (covers) all the vertices with the minimum number of edges needed to connect them is known as **Spanning Tree**.
+
+### Minimum Spanning Tree
+
+The minimum spanning tree has all the properties of a spanning tree with an added constraint of having the minimum possible weights among all possible spanning trees.
+
+**Uniqueness of MST:** If all edge weights are unique, there's only one MST. If some weights are the same, multiple MSTs can exist.
+
+**Algorithms for MST:** Kruskal's and Prim's algorithms are used to find MSTs. The MST found can vary based on the choices made for edges with equal weights. Both algorithms solve for same problem having same time and space complexities.
+
+*Note: We'll cover Prim's in today's session, Kruskal shall be covered in DSA 4.2*
+
+### Solution to Flipkart's problem
+
+**Application of MST:**
+* **Identify All Possible Connections:** First, identify all the possible routes that can connect these N centers. Imagine this as a network where each center is a node, and each possible road between two centers is an edge.
+
+* **Assign Costs:** Assign a cost to each potential road, based on factors like distance, traffic, or construction expenses. In real-life terms, shorter and more straightforward routes would generally cost less.
+
+* **Create the MST:** Now, apply the MST algorithm (like Kruskal's or Prim's). The algorithm will select routes that connect all the centers with the least total cost, without forming any loops or cycles.
+
+* **Outcome:** The result is a network of roads connecting all centers with the shortest total length or the lowest cost.
+
+---
+title: Prims Algorithm
+description:
+duration: 900
+card_type: cue_card
+---
+
+Let's consider the below **Graph:**
+
+ +
+Say we start with **vertex 5**, now we can choose an edge originating out of 5.
+
+
+
+Say we start with **vertex 5**, now we can choose an edge originating out of 5.
+
+ +
+*Which one should we choose?*
+The one with minimum weight.
+
+We choose 5 ---- 3 with weight 2
+
+
+
+*Which one should we choose?*
+The one with minimum weight.
+
+We choose 5 ---- 3 with weight 2
+
+ +
+Now, after this, since 5 and 3 are part of the MST, we shall choose a min weighted edge originated from either 3 or 5. That edge should connect to a vertex which hasn't been visited yet.
+
+
+
+Now, after this, since 5 and 3 are part of the MST, we shall choose a min weighted edge originated from either 3 or 5. That edge should connect to a vertex which hasn't been visited yet.
+
+ +
+We choose 5 ---- 4 with weight 3
+
+
+
+---
+title: Quiz 1
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the next node, we need to visit ?
+
+
+
+
+# Choices
+- [ ] 3
+- [x] 2
+- [ ] 1
+- [ ] 6
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The next we need to visit is **2**.
+
+We choose 4 ----> 2 with weight 3, This is the smallest weight node among all possible edges of 3, 4, and 5.
+
+---
+title: Prims Algorithm Continued
+description:
+duration: 300
+card_type: cue_card
+---
+
+Now, same process follows i.e, we can select a min weighted edge originating from 3, 4, or 5 such that it should connect to a vertex that hasn't been visited yet.
+
+
+**After completing the entire process, we shall have below MST.**
+
+
+
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the most suitable data structure for implementing Prim's algorithm?
+
+# Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Heap
+- [ ] Stack
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Prim's algorithm typically uses a Heap (min-heap) to efficiently select the minimum-weight edge at each step of the algorithm. Min Heaps allow for constant time access to the minimum element, making them well-suited for this purpose.
+
+---
+title: Prims Algorithm Execution
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Execution
+
+Say we have a black box(we'll name it later)
+
+Now, say we start with 5. From 5, via weight 3 we can visit 4, via weight 5 we can visit 6, via weight 2 we can visit 3.
+
+We'll information as - (weight, vertex)
+
+
+
+We choose 5 ---- 4 with weight 3
+
+
+
+---
+title: Quiz 1
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the next node, we need to visit ?
+
+
+
+
+# Choices
+- [ ] 3
+- [x] 2
+- [ ] 1
+- [ ] 6
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The next we need to visit is **2**.
+
+We choose 4 ----> 2 with weight 3, This is the smallest weight node among all possible edges of 3, 4, and 5.
+
+---
+title: Prims Algorithm Continued
+description:
+duration: 300
+card_type: cue_card
+---
+
+Now, same process follows i.e, we can select a min weighted edge originating from 3, 4, or 5 such that it should connect to a vertex that hasn't been visited yet.
+
+
+**After completing the entire process, we shall have below MST.**
+
+
+
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the most suitable data structure for implementing Prim's algorithm?
+
+# Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Heap
+- [ ] Stack
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Prim's algorithm typically uses a Heap (min-heap) to efficiently select the minimum-weight edge at each step of the algorithm. Min Heaps allow for constant time access to the minimum element, making them well-suited for this purpose.
+
+---
+title: Prims Algorithm Execution
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Execution
+
+Say we have a black box(we'll name it later)
+
+Now, say we start with 5. From 5, via weight 3 we can visit 4, via weight 5 we can visit 6, via weight 2 we can visit 3.
+
+We'll information as - (weight, vertex)
+
+ +
+From this, we'll get vertex reachable via min weight, which data structure can be helpful ?
+**MIN HEAPS**
+
+Now, we remove (2, 3) from heaps and connect 3 to 5.
+
+From 3, the nodes that are reachable will be pushed to the heap.
+*We'll insert only those vertices which haven't been visited yet.*
+
+
+
+From this, we'll get vertex reachable via min weight, which data structure can be helpful ?
+**MIN HEAPS**
+
+Now, we remove (2, 3) from heaps and connect 3 to 5.
+
+From 3, the nodes that are reachable will be pushed to the heap.
+*We'll insert only those vertices which haven't been visited yet.*
+
+ +
+Select the minimum weighted -> (3, 4)
+
+Now, this shall continue.
+
+
+### Pseudocode
+
+```java
+while (!heap.isEmpty()) {
+
+ Pair p = heap.getMin();
+
+ if (vis[v] == true)
+ continue;
+
+ // Add the vertex to the MST and accumulate the weight
+ vis[v] = true;
+ ans += p.first
+
+ // Now, you can optionally iterate through the adjacent vertices of 'v' and update the heap with new edges
+ for ((u, w) in adj[v]) {
+
+ if (!vis[u]) {
+ // Add the unvisited neighbor edges to the heap
+ heap.add({w, u});
+ }
+ }
+}
+```
+
+### Complexity
+**Time Complexity:** O(E * logE)
+**Space Complexity:** O(V + E)
+
+---
+title: Dijkstras Algorithm
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Question
+
+There are N cities in a country, you are living in city-1. Find minimum distance to reach every other city from city-1.
+
+We need to return the answer in the form of array
+
+### Example
+
+**Input Graph:**
+
+
+**Output:**
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+### Result Array
+
+Lets say d is the Resultant Array,
+
+`d[i] says that the minimum distance from the source node to the ith vertex`
+
+### Dry Run
+Lets take the above example and Dry Run it.
+
+
+
+
+Lets set the starting point as **1**. So we need to find the Shortest to all the other vertexes from 1.
+
+
+Initally the distance array, d will be set to ∞.
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+We know that, from 1 -> 1 is always 0.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 1 into the min-heap, which is used to pick the minimum weighted node.
+
+The elements of the min heap is in the form **(weight, vertex)**.
+
+min heap = `[ (7,2) (8, 3) ]`
+
+**(7, 2) Picked**
+
+Pick the minimum weighted one, which is **(7, 2)**. So we can say that, from **1 -> 2**, the minimum path is 7. Updating in the distance array as well.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 2 into the min-heap, by adding the current weight + adjacent weight.
+i.e., (cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_3)
+(cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_4)
+
+Before adding the adjacent vertex in the min heap, check whether it is good enought to add it.
+
+Here the adjacent elements of 2 is 1, 3, 4. We notice that, there is no point in visiting 1, by **1 -> 2 -> 1** for the cost of **14**. Already we know that, 1 can be visited in **0 cost** by checking on the d (distance array). So in this case, we **dont insert in our min heap**.
+
+
+
+Adding the remaining two pairs in the min heap.
+
+min heap = `[ (8, 3) (10, 3) (13, 4)]`
+
+
+**(8, 3) Picked**
+Picking the minimum (8, 3) and updating the distance array.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+After adding the adjacent vertexes of 3,
+
+(16, 1) is not inserted, Since there is already a cost exist.
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+
+---
+title: Quiz 3
+description:
+duration: 120
+card_type: quiz_card
+---
+
+# Question
+
+The current states are,
+
+Given Graph
+
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| distance array (d) | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+What would be the next step, which is going to take place?
+
+# Choices
+- [ ] Pick (10, 3) and Update the distance array at 3rd vertex as 10
+- [x] Pick (10, 3) and Dont update the distance array
+- [ ] Pick (13, 4) and Update the distance array at 4th vertex as 13
+- [ ] Pick (12, 4) and Dont update the distance array
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The current step is to **Pick (10, 3) and Dont update the distance array**. Since we have noticed that, On the distance array, vertex 3 can be visited at cost 8, which is obviously lesser than 10. So no need to update the array.
+
+After Picking (10, 3), the further steps are processed.
+
+---
+title: Dijkstras Algorithm Dry Run continued
+description:
+duration: 900
+card_type: cue_card
+---
+
+**(10, 3) is Picked**
+
+But 3 can be visited by 8 cost already. So, No changes.
+
+min heap = `[ (13, 4) (11, 5) (12, 4)]`
+
+**(11, 5) is Picked**
+
+Updating the distance array
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | 11 | ∞ | ∞ |
+
+Inserting the adjacent vertexes of 5,
+
+min heap = `[ (13, 4) (12, 4) (13, 4) (16, 6) (13, 7)]`
+
+The pairs, (14, 3) is not inserted, since there is already minimum cost exist in the distance array.
+
+**(12, 4) is Picked**
+
+Updating the distance array
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | ∞ |
+
+Inserting adjacent of 4,
+
+min heap = `[ (13, 4) (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+The other possible pairs are not inserted, since it has the minimum cost already.
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (16, 6) (13, 7) (17, 6)]`
+
+**(13, 7) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7) (15, 6)]`
+
+**(15, 6) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7)]`
+
+
+**(16, 6) is Picked**
+
+No changes
+
+min heap = `[(17, 6) (18, 7)]`
+
+**(17, 6) is Picked**
+
+No changes
+
+min heap = `[(18, 7)]`
+
+**(18, 6) is Picked**
+
+No changes
+
+min heap = `[]`
+
+Thus the min heap is Emptied.
+
+The distance array is,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+
+### Pseudo code
+```java
+ while (!hp.isEmpty()) {
+ Pair rp = hp.poll(); // Extract the minimum element
+
+ int d = rp.first; // Distance
+ int u = rp.second; // City
+
+ // Skip if this distance is greater than the known distance
+ if (d > dist[u]) {
+ continue;
+ }
+
+ // Explore neighbors of u and update distances
+ for (/* Loop through neighbors */) {
+ int v = /* Neighbor city */;
+ int w = /* Weight to reach v from u */;
+
+ // Calculate the new distance via u
+ int new_dist = dist[u] + w;
+
+ // If the new distance is shorter, update dist and add to heap
+ if (new_dist < dist[v]) {
+ dist[v] = new_dist;
+ hp.add(new Pair(new_dist, v));
+ }
+ }
+ }
+ }
+```
+
+* The time complexity of the Dijkstra's algorithm implementation with a min-heap of pairs is $O((E + V) * log(V))$, where E is the number of edges, V is the number of vertices (cities), and log(V) represents the complexity of heap operations.
+* The space complexity of this implementation is O(V + E), where V is the space used to store the dist array (minimum distances) for all cities, and E is the space used to represent the graph (adjacency list).
+
+### Can Dijkstra's algorithm work on negative wieghts?
+
+Dijkstra's algorithm is not suitable for graphs with negative edge weights as it assumes non-negative weights to guarantee correct results. Negative weights can lead to unexpected behavior and incorrect shortest path calculations.
+
+---
+title: Quiz 4
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Is Dijkstra's algorithm is commonly used for finding the Minimum Spanning Tree ?
+
+# Choices
+- [ ] Yes
+- [x] No
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Dijkstra's Algorithms is for finding the Single source shortest path algorithm
+
+---
+title: Contest Information
+description:
+duration: 900
+card_type: cue_card
+---
+
+We have an upcoming contest based on **Full DSA module** please keep revising all the topics.
+
+Please share the following with learners -
+1. Revision material
+https://hackmd.io/dVt8WSoPRcqbu5y5hgOEcg
+
+2. How to access the contest?
+https://www.loom.com/share/5a47836051384f8fa3ffb32c3c9d5e7f?sid=ff500645-0cb5-498a-aebc-29997f6745f9
+
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Greedy.md b/Academy DSA Typed Notes/DSA 4.2/DSA Greedy.md
new file mode 100644
index 0000000..18b410b
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Greedy.md
@@ -0,0 +1,960 @@
+# Advanced DSA: Greedy
+
+---
+title: Introduction on Greedy
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Greedy
+The greedy approach deals with maximizing our profit and minimizing our loss.
+
+
+
+**Example 1:**
+Suppose we want to buy an iPhone, and the price of an iPhone at Amazon is 1.3 lakhs, the price at Paytm at 1.2 lakhs and the price at Flipkart is 1.25 lakhs.
+So we will buy an iPhone from Paytm as it has a minimum price.
+Here we are considering only one factor i.e. the amount of an iphone.
+
+**Example 2:**
+
+Suppose we want to switch a company and we have three offer letters. The first company is given a 22 LPA offer, the second company is given a 25 LPA, and the third company is given a 28 LPA offer.
+
+So we are going to select 28 LPA offer company. Here we are again considering the money factor, we are not considering the factors:
+- Job is remote
+- Work culture
+- Timings
+- Growth
+
+But if 25 LPA company has other facilities better than 28 LPA offer company. 25 LPA company has flexible working hours, provides remote job and good work culture. Then we are going to choose 25 LPA offer company.
+
+If we involve only one factor then selection will become easier and if multiple factors are involved then the decision becomes a bit difficult.
+
+In this lecture, we are going to do questions which involve multiple factors.
+
+
+---
+title: Problem 1 Flipkart's Challenge in Effective Inventory Management
+description:
+duration: 600
+card_type: cue_card
+---
+
+In the recent expansion into grocery delivery, Flipkart faces a crucial challenge in effective inventory management. Each grocery item on the platform carries its own expiration date and profit margin, represented by arrays A[i] (expiration date for the ith item) and B[i] (profit margin for the ith item). To mitigate potential losses due to expiring items, Flipkart is seeking a strategic solution. The objective is to identify a method to strategically promote certain items, ensuring they are sold before their expiration date, thereby maximizing overall profit. Can you assist Flipkart in developing an innovative approach to optimize their grocery inventory and enhance profitability?
+
+
+**A[i] -> expiration time for ith item**
+**B[i] -> profit gained by ith item**
+
+Time starts with **T = 0**, and it takes 1 unit of time to sell one item and the item **can only be sold if T < A[i].**
+
+Sell items such that the sum of the **profit by items is maximized.**
+
+### Example
+
+**`A[] = [3 1 3 2 3]`**
+**`B[] = [6 5 3 1 9]`**
+**`index: 0 1 2 3 4`**
+
+
+### Idea 1 - Pick the highest profit item first
+
+
+- We will first sell the item with the highest profit.
+
+Initially T = 0
+
+- We have the maximum profit item at index 4, so will sell it and increment T by 1.
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 4 | 9 |
+
+- Now the item at index 1 can't be sold as A[1] <= T. So we can not sell it.
+
+
+- Now we will sell the item at 0 index.
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 4 | 9 |
+| 2 | 0 | 6 |
+
+
+
+- Now the item at index 3 can't be sold as A[3] <= T. So we can not sell it.
+
+
+- Now we will sell the item at 2 index.
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 4 | 9 |
+| 2 | 0 | 6 |
+| 3 | 2 | 3 |
+
+So we have a total profit: 18.
+
+:bulb: **`But we can have a better answer than this answer. Let us try one more combination of selling items.`**
+
+**`A[] = [3 1 3 2 3]`**
+**`B[] = [6 5 3 1 9]`**
+**`index: 0 1 2 3 4`**
+
+Initially T = 0
+
+- We have sold the item at index 1 and increment T by 1.
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 1 | 5 |
+
+- Now we have sold the item at index 4 and again increment T by 1.
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 1 | 5 |
+| 2 | 4 | 9 |
+
+- Now the item at index 3 can't be sold as A[3] <= T. So we can not sell it.
+
+
+- Now have sold the item at 0 index.
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 1 | 5 |
+| 2 | 4 | 9 |
+| 3 | 0 | 6 |
+
+
+- Now the item at index 2 can't be sold as A[2] <= T. So we can not sell it
+
+
+So we have a total profit 20.
+
+Here we are getting the total profit greater than the total profit of the previously sold combination of items.
+
+And we can achieve maximum profit 20.
+
+**The greedy approach is selecting the path by greedy approach, in greedy we will select one path based on some conditions by assuming that this path will give us the solution.**
+
+
+
+
+---
+title: Quiz 1
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the maximum profit we can achieve if we have two items with expiration time in A and profit in B:
+
+A = [1, 2]
+B = [3, 1500]
+
+# Choices
+
+- [ ] 3
+- [ ] 1500
+- [x] 1503
+- [ ] 0
+
+
+
+---
+title: Quiz Explanation
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Explanation
+
+A = [1, 2]
+B = [3, 1500]
+
+
+
+Initially T = 0
+
+- We have selected the item at index 9 and incremented T by 1.
+
+
+|T|Item Index|Profit|
+|-|-|-|
+|1|0|3|
+
+- Now we have selected the item at index 1 and again increment T by 1.
+
+
+|T|Item Index|Profit|
+|-|-|-|
+|1|0|3|
+|2|1|1500|
+
+So we have a total profit 1503.
+
+
+---
+title: Effective Inventory Management Solution
+description:
+duration: 1800
+card_type: cue_card
+---
+
+### Solution - Effective Inventory Management
+
+- Pick the highest profit item first approach is not giving us the maximum profit, so it will not work. We have to think of another approach.
+
+### Idea: Sell Everything
+
+Our approach is always towards selling all the items so that we can achieve maximum profit.
+ So our approach is to first sell the item with the minimum end time.
+
+ For this, we have to sort the expiration time in ascending order.
+
+**Example:**
+
+A[] = [1, 3, 3, 3, 5, 5, 5, 8]
+B[] = [5, 2, 7, 1, 4, 3, 8, 1]
+
+
+Initially T = 0
+
+- We can sell an item available at index 0, as A[0] = 1, and T < A[0]
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+
+- We can sell an item available at index 1, as A[1] = 3, and T < A[1]
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+
+- We can sell a item available at index 2, as A[2] = 3, and T < A[2]
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+| 3 | 2 | 7 |
+
+- But we can not sell the item available at index 3, as A[3] = 3, and A[3] <= T, here the profit of the item at index 3 is 1, so we ignore it easily as it has very little profit.
+
+- We can sell a item available at index 4, as A[4] = 5, and T < A[4].
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+| 3 | 2 | 7 |
+| 4 | 4 | 4 |
+
+- We can sell a item available at index 5, as A[5] = 5, and T < A[5].
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+| 3 | 2 | 7 |
+| 4 | 4 | 4 |
+| 5 | 5 | 3 |
+
+- But we can not sell the item available at index 6, as A[6] = 5, and A[6] <= T. But we can say that we must have to select this item to get the maximum profit as it has the larger profit. But we are rejecting it.
+- To select the item available at index 6, we have to remove one of the previously selected items.
+- So we want to discard the item with the minimum profit among all the selected items.
+
+
+| T | Item Index | Profit |
+|:-----:|:---------:|:------:|
+| 1 | 0 | 5 |
+| ~~2~~ | ~~1~~ | ~~2~~ |
+| 3 | 2 | 7 |
+| 4 | 4 | 4 |
+| 5 | 5 | 3 |
+| 5 | 6 | 8 |
+
+
+
+- We can sell item available at index 7, as A[7] = 8, and T < A[7].
+
+
+|T|Item Index|Profit|
+|-|-|-|
+|1|0|5|
+|~~2~~|~~1~~|~~2~~|
+|3|2|7|
+|4|4|4|
+|5|5|3|
+|5|6|8|
+|6|7|1|
+
+
+So we have a total profit 28.
+
+
+**`At any point, if we weren't able to choose a item as T >= A[i] and realize we made a wrong choice before, we will get rid of the item with least profit we previously picked and choose the current one instead.`**
+
+
+### Approach
+
+The solution to this question is just like the team selection. We have to select the strongest player, if we have any player who is stronger than the player in our team, then we will remove the weaker player from the team and add that player to our team.
+
+***`[Ask Learners] Which data structure should we select ?`***
+**`MIN HEAP!`**
+
+### Example: Solving using min-heap
+
+| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+| -- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
+|A[ ]| 1 | 3 | 3 | 3 | 5 | 5 | 5 | 8 |
+|B[ ]| 5 | 2 | 7 | 1 | 4 | 3 | 8 | 1 |
+
+
+**Solution**
+
+Initially **T = 0** and we have a empty min-heap.
+
+
+
+Select the minimum weighted -> (3, 4)
+
+Now, this shall continue.
+
+
+### Pseudocode
+
+```java
+while (!heap.isEmpty()) {
+
+ Pair p = heap.getMin();
+
+ if (vis[v] == true)
+ continue;
+
+ // Add the vertex to the MST and accumulate the weight
+ vis[v] = true;
+ ans += p.first
+
+ // Now, you can optionally iterate through the adjacent vertices of 'v' and update the heap with new edges
+ for ((u, w) in adj[v]) {
+
+ if (!vis[u]) {
+ // Add the unvisited neighbor edges to the heap
+ heap.add({w, u});
+ }
+ }
+}
+```
+
+### Complexity
+**Time Complexity:** O(E * logE)
+**Space Complexity:** O(V + E)
+
+---
+title: Dijkstras Algorithm
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Question
+
+There are N cities in a country, you are living in city-1. Find minimum distance to reach every other city from city-1.
+
+We need to return the answer in the form of array
+
+### Example
+
+**Input Graph:**
+
+
+**Output:**
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+### Result Array
+
+Lets say d is the Resultant Array,
+
+`d[i] says that the minimum distance from the source node to the ith vertex`
+
+### Dry Run
+Lets take the above example and Dry Run it.
+
+
+
+
+Lets set the starting point as **1**. So we need to find the Shortest to all the other vertexes from 1.
+
+
+Initally the distance array, d will be set to ∞.
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+We know that, from 1 -> 1 is always 0.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 1 into the min-heap, which is used to pick the minimum weighted node.
+
+The elements of the min heap is in the form **(weight, vertex)**.
+
+min heap = `[ (7,2) (8, 3) ]`
+
+**(7, 2) Picked**
+
+Pick the minimum weighted one, which is **(7, 2)**. So we can say that, from **1 -> 2**, the minimum path is 7. Updating in the distance array as well.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | ∞ | ∞ | ∞ | ∞ | ∞ |
+
+Lets add the adjacent vertexes of 2 into the min-heap, by adding the current weight + adjacent weight.
+i.e., (cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_3)
+(cost_to_reachfrom_1_to_2 + cost_to_reachfrom_2_to_4)
+
+Before adding the adjacent vertex in the min heap, check whether it is good enought to add it.
+
+Here the adjacent elements of 2 is 1, 3, 4. We notice that, there is no point in visiting 1, by **1 -> 2 -> 1** for the cost of **14**. Already we know that, 1 can be visited in **0 cost** by checking on the d (distance array). So in this case, we **dont insert in our min heap**.
+
+
+
+Adding the remaining two pairs in the min heap.
+
+min heap = `[ (8, 3) (10, 3) (13, 4)]`
+
+
+**(8, 3) Picked**
+Picking the minimum (8, 3) and updating the distance array.
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+After adding the adjacent vertexes of 3,
+
+(16, 1) is not inserted, Since there is already a cost exist.
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+
+---
+title: Quiz 3
+description:
+duration: 120
+card_type: quiz_card
+---
+
+# Question
+
+The current states are,
+
+Given Graph
+
+
+min heap = `[ (10, 3) (13, 4) (11, 5) (12, 4)]`
+
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| distance array (d) | 0 | 7 | 8 | ∞ | ∞ | ∞ | ∞ |
+
+What would be the next step, which is going to take place?
+
+# Choices
+- [ ] Pick (10, 3) and Update the distance array at 3rd vertex as 10
+- [x] Pick (10, 3) and Dont update the distance array
+- [ ] Pick (13, 4) and Update the distance array at 4th vertex as 13
+- [ ] Pick (12, 4) and Dont update the distance array
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The current step is to **Pick (10, 3) and Dont update the distance array**. Since we have noticed that, On the distance array, vertex 3 can be visited at cost 8, which is obviously lesser than 10. So no need to update the array.
+
+After Picking (10, 3), the further steps are processed.
+
+---
+title: Dijkstras Algorithm Dry Run continued
+description:
+duration: 900
+card_type: cue_card
+---
+
+**(10, 3) is Picked**
+
+But 3 can be visited by 8 cost already. So, No changes.
+
+min heap = `[ (13, 4) (11, 5) (12, 4)]`
+
+**(11, 5) is Picked**
+
+Updating the distance array
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | ∞ | 11 | ∞ | ∞ |
+
+Inserting the adjacent vertexes of 5,
+
+min heap = `[ (13, 4) (12, 4) (13, 4) (16, 6) (13, 7)]`
+
+The pairs, (14, 3) is not inserted, since there is already minimum cost exist in the distance array.
+
+**(12, 4) is Picked**
+
+Updating the distance array
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | ∞ |
+
+Inserting adjacent of 4,
+
+min heap = `[ (13, 4) (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+The other possible pairs are not inserted, since it has the minimum cost already.
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (13, 4) (16, 6) (13, 7) (17, 6)]`
+
+**(13, 4) is Picked**
+
+4 is on Already minimum cost
+
+min heap = `[ (16, 6) (13, 7) (17, 6)]`
+
+**(13, 7) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | ∞ | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7) (15, 6)]`
+
+**(15, 6) is Picked**
+
+Updaing the distance array,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+min heap = `[(16, 6) (17, 6) (18, 7)]`
+
+
+**(16, 6) is Picked**
+
+No changes
+
+min heap = `[(17, 6) (18, 7)]`
+
+**(17, 6) is Picked**
+
+No changes
+
+min heap = `[(18, 7)]`
+
+**(18, 6) is Picked**
+
+No changes
+
+min heap = `[]`
+
+Thus the min heap is Emptied.
+
+The distance array is,
+
+| | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+|---|---|---|---|---|---|---|---|
+| d | 0 | 7 | 8 | 12 | 11 | 15 | 13 |
+
+
+
+### Pseudo code
+```java
+ while (!hp.isEmpty()) {
+ Pair rp = hp.poll(); // Extract the minimum element
+
+ int d = rp.first; // Distance
+ int u = rp.second; // City
+
+ // Skip if this distance is greater than the known distance
+ if (d > dist[u]) {
+ continue;
+ }
+
+ // Explore neighbors of u and update distances
+ for (/* Loop through neighbors */) {
+ int v = /* Neighbor city */;
+ int w = /* Weight to reach v from u */;
+
+ // Calculate the new distance via u
+ int new_dist = dist[u] + w;
+
+ // If the new distance is shorter, update dist and add to heap
+ if (new_dist < dist[v]) {
+ dist[v] = new_dist;
+ hp.add(new Pair(new_dist, v));
+ }
+ }
+ }
+ }
+```
+
+* The time complexity of the Dijkstra's algorithm implementation with a min-heap of pairs is $O((E + V) * log(V))$, where E is the number of edges, V is the number of vertices (cities), and log(V) represents the complexity of heap operations.
+* The space complexity of this implementation is O(V + E), where V is the space used to store the dist array (minimum distances) for all cities, and E is the space used to represent the graph (adjacency list).
+
+### Can Dijkstra's algorithm work on negative wieghts?
+
+Dijkstra's algorithm is not suitable for graphs with negative edge weights as it assumes non-negative weights to guarantee correct results. Negative weights can lead to unexpected behavior and incorrect shortest path calculations.
+
+---
+title: Quiz 4
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Is Dijkstra's algorithm is commonly used for finding the Minimum Spanning Tree ?
+
+# Choices
+- [ ] Yes
+- [x] No
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Dijkstra's Algorithms is for finding the Single source shortest path algorithm
+
+---
+title: Contest Information
+description:
+duration: 900
+card_type: cue_card
+---
+
+We have an upcoming contest based on **Full DSA module** please keep revising all the topics.
+
+Please share the following with learners -
+1. Revision material
+https://hackmd.io/dVt8WSoPRcqbu5y5hgOEcg
+
+2. How to access the contest?
+https://www.loom.com/share/5a47836051384f8fa3ffb32c3c9d5e7f?sid=ff500645-0cb5-498a-aebc-29997f6745f9
+
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Greedy.md b/Academy DSA Typed Notes/DSA 4.2/DSA Greedy.md
new file mode 100644
index 0000000..18b410b
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Greedy.md
@@ -0,0 +1,960 @@
+# Advanced DSA: Greedy
+
+---
+title: Introduction on Greedy
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Greedy
+The greedy approach deals with maximizing our profit and minimizing our loss.
+
+
+
+**Example 1:**
+Suppose we want to buy an iPhone, and the price of an iPhone at Amazon is 1.3 lakhs, the price at Paytm at 1.2 lakhs and the price at Flipkart is 1.25 lakhs.
+So we will buy an iPhone from Paytm as it has a minimum price.
+Here we are considering only one factor i.e. the amount of an iphone.
+
+**Example 2:**
+
+Suppose we want to switch a company and we have three offer letters. The first company is given a 22 LPA offer, the second company is given a 25 LPA, and the third company is given a 28 LPA offer.
+
+So we are going to select 28 LPA offer company. Here we are again considering the money factor, we are not considering the factors:
+- Job is remote
+- Work culture
+- Timings
+- Growth
+
+But if 25 LPA company has other facilities better than 28 LPA offer company. 25 LPA company has flexible working hours, provides remote job and good work culture. Then we are going to choose 25 LPA offer company.
+
+If we involve only one factor then selection will become easier and if multiple factors are involved then the decision becomes a bit difficult.
+
+In this lecture, we are going to do questions which involve multiple factors.
+
+
+---
+title: Problem 1 Flipkart's Challenge in Effective Inventory Management
+description:
+duration: 600
+card_type: cue_card
+---
+
+In the recent expansion into grocery delivery, Flipkart faces a crucial challenge in effective inventory management. Each grocery item on the platform carries its own expiration date and profit margin, represented by arrays A[i] (expiration date for the ith item) and B[i] (profit margin for the ith item). To mitigate potential losses due to expiring items, Flipkart is seeking a strategic solution. The objective is to identify a method to strategically promote certain items, ensuring they are sold before their expiration date, thereby maximizing overall profit. Can you assist Flipkart in developing an innovative approach to optimize their grocery inventory and enhance profitability?
+
+
+**A[i] -> expiration time for ith item**
+**B[i] -> profit gained by ith item**
+
+Time starts with **T = 0**, and it takes 1 unit of time to sell one item and the item **can only be sold if T < A[i].**
+
+Sell items such that the sum of the **profit by items is maximized.**
+
+### Example
+
+**`A[] = [3 1 3 2 3]`**
+**`B[] = [6 5 3 1 9]`**
+**`index: 0 1 2 3 4`**
+
+
+### Idea 1 - Pick the highest profit item first
+
+
+- We will first sell the item with the highest profit.
+
+Initially T = 0
+
+- We have the maximum profit item at index 4, so will sell it and increment T by 1.
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 4 | 9 |
+
+- Now the item at index 1 can't be sold as A[1] <= T. So we can not sell it.
+
+
+- Now we will sell the item at 0 index.
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 4 | 9 |
+| 2 | 0 | 6 |
+
+
+
+- Now the item at index 3 can't be sold as A[3] <= T. So we can not sell it.
+
+
+- Now we will sell the item at 2 index.
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 4 | 9 |
+| 2 | 0 | 6 |
+| 3 | 2 | 3 |
+
+So we have a total profit: 18.
+
+:bulb: **`But we can have a better answer than this answer. Let us try one more combination of selling items.`**
+
+**`A[] = [3 1 3 2 3]`**
+**`B[] = [6 5 3 1 9]`**
+**`index: 0 1 2 3 4`**
+
+Initially T = 0
+
+- We have sold the item at index 1 and increment T by 1.
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 1 | 5 |
+
+- Now we have sold the item at index 4 and again increment T by 1.
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 1 | 5 |
+| 2 | 4 | 9 |
+
+- Now the item at index 3 can't be sold as A[3] <= T. So we can not sell it.
+
+
+- Now have sold the item at 0 index.
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 1 | 5 |
+| 2 | 4 | 9 |
+| 3 | 0 | 6 |
+
+
+- Now the item at index 2 can't be sold as A[2] <= T. So we can not sell it
+
+
+So we have a total profit 20.
+
+Here we are getting the total profit greater than the total profit of the previously sold combination of items.
+
+And we can achieve maximum profit 20.
+
+**The greedy approach is selecting the path by greedy approach, in greedy we will select one path based on some conditions by assuming that this path will give us the solution.**
+
+
+
+
+---
+title: Quiz 1
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the maximum profit we can achieve if we have two items with expiration time in A and profit in B:
+
+A = [1, 2]
+B = [3, 1500]
+
+# Choices
+
+- [ ] 3
+- [ ] 1500
+- [x] 1503
+- [ ] 0
+
+
+
+---
+title: Quiz Explanation
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Explanation
+
+A = [1, 2]
+B = [3, 1500]
+
+
+
+Initially T = 0
+
+- We have selected the item at index 9 and incremented T by 1.
+
+
+|T|Item Index|Profit|
+|-|-|-|
+|1|0|3|
+
+- Now we have selected the item at index 1 and again increment T by 1.
+
+
+|T|Item Index|Profit|
+|-|-|-|
+|1|0|3|
+|2|1|1500|
+
+So we have a total profit 1503.
+
+
+---
+title: Effective Inventory Management Solution
+description:
+duration: 1800
+card_type: cue_card
+---
+
+### Solution - Effective Inventory Management
+
+- Pick the highest profit item first approach is not giving us the maximum profit, so it will not work. We have to think of another approach.
+
+### Idea: Sell Everything
+
+Our approach is always towards selling all the items so that we can achieve maximum profit.
+ So our approach is to first sell the item with the minimum end time.
+
+ For this, we have to sort the expiration time in ascending order.
+
+**Example:**
+
+A[] = [1, 3, 3, 3, 5, 5, 5, 8]
+B[] = [5, 2, 7, 1, 4, 3, 8, 1]
+
+
+Initially T = 0
+
+- We can sell an item available at index 0, as A[0] = 1, and T < A[0]
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+
+- We can sell an item available at index 1, as A[1] = 3, and T < A[1]
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+
+- We can sell a item available at index 2, as A[2] = 3, and T < A[2]
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+| 3 | 2 | 7 |
+
+- But we can not sell the item available at index 3, as A[3] = 3, and A[3] <= T, here the profit of the item at index 3 is 1, so we ignore it easily as it has very little profit.
+
+- We can sell a item available at index 4, as A[4] = 5, and T < A[4].
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+| 3 | 2 | 7 |
+| 4 | 4 | 4 |
+
+- We can sell a item available at index 5, as A[5] = 5, and T < A[5].
+
+
+| T | Item Index | Profit |
+|:---:|:---------:|:------:|
+| 1 | 0 | 5 |
+| 2 | 1 | 2 |
+| 3 | 2 | 7 |
+| 4 | 4 | 4 |
+| 5 | 5 | 3 |
+
+- But we can not sell the item available at index 6, as A[6] = 5, and A[6] <= T. But we can say that we must have to select this item to get the maximum profit as it has the larger profit. But we are rejecting it.
+- To select the item available at index 6, we have to remove one of the previously selected items.
+- So we want to discard the item with the minimum profit among all the selected items.
+
+
+| T | Item Index | Profit |
+|:-----:|:---------:|:------:|
+| 1 | 0 | 5 |
+| ~~2~~ | ~~1~~ | ~~2~~ |
+| 3 | 2 | 7 |
+| 4 | 4 | 4 |
+| 5 | 5 | 3 |
+| 5 | 6 | 8 |
+
+
+
+- We can sell item available at index 7, as A[7] = 8, and T < A[7].
+
+
+|T|Item Index|Profit|
+|-|-|-|
+|1|0|5|
+|~~2~~|~~1~~|~~2~~|
+|3|2|7|
+|4|4|4|
+|5|5|3|
+|5|6|8|
+|6|7|1|
+
+
+So we have a total profit 28.
+
+
+**`At any point, if we weren't able to choose a item as T >= A[i] and realize we made a wrong choice before, we will get rid of the item with least profit we previously picked and choose the current one instead.`**
+
+
+### Approach
+
+The solution to this question is just like the team selection. We have to select the strongest player, if we have any player who is stronger than the player in our team, then we will remove the weaker player from the team and add that player to our team.
+
+***`[Ask Learners] Which data structure should we select ?`***
+**`MIN HEAP!`**
+
+### Example: Solving using min-heap
+
+| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+| -- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
+|A[ ]| 1 | 3 | 3 | 3 | 5 | 5 | 5 | 8 |
+|B[ ]| 5 | 2 | 7 | 1 | 4 | 3 | 8 | 1 |
+
+
+**Solution**
+
+Initially **T = 0** and we have a empty min-heap.
+
+ +
+All the items are sorted in the ascending order of expiration time.
+
+- We can sell a item available at index 0, as A[0] = 1, so here T < A[0], so we will sell the item available at index 0 and add its profit in min-heap.
+
+**T = 1**
+
+
+
+All the items are sorted in the ascending order of expiration time.
+
+- We can sell a item available at index 0, as A[0] = 1, so here T < A[0], so we will sell the item available at index 0 and add its profit in min-heap.
+
+**T = 1**
+
+ +
+- We can sell a item available at index 1, as A[1] = 3, so here T < A[1], so we will sell the item available at index 1 and add its profit in min-heap.
+
+**T = 2**
+
+
+
+- We can sell a item available at index 1, as A[1] = 3, so here T < A[1], so we will sell the item available at index 1 and add its profit in min-heap.
+
+**T = 2**
+
+ +
+- We can sell a item available at index 2, as A[2] = 3, so here T < A[2], so we will sell the item available at index 2 and add its profit in min-heap.
+
+**T = 3**
+
+
+
+
+- We can sell a item available at index 2, as A[2] = 3, so here T < A[2], so we will sell the item available at index 2 and add its profit in min-heap.
+
+**T = 3**
+
+
+ +
+- But we can not sell the item available at index 3, as A[3] = 3, and A[3] <= T. Now we will check if we have taken any incorrect steps in the past.
+- We check if we have any items in the heap with profit less than 1. So we have 2 minimum profit in the heap but 2 > 1, so it proves all our past decisions are correct. So we will skip the item available at index 3.
+
+
+- We can sell a item available at index 4, as A[4] = 5, and T < A[4] and add its profit in min-heap.
+
+**T = 4**
+
+
+
+- But we can not sell the item available at index 3, as A[3] = 3, and A[3] <= T. Now we will check if we have taken any incorrect steps in the past.
+- We check if we have any items in the heap with profit less than 1. So we have 2 minimum profit in the heap but 2 > 1, so it proves all our past decisions are correct. So we will skip the item available at index 3.
+
+
+- We can sell a item available at index 4, as A[4] = 5, and T < A[4] and add its profit in min-heap.
+
+**T = 4**
+
+ +
+- We can sell a item available at index 5, as A[5] = 5, so here T < A[5] and add its profit in min-heap.
+
+
+**T = 5**
+
+
+
+- We can sell a item available at index 5, as A[5] = 5, so here T < A[5] and add its profit in min-heap.
+
+
+**T = 5**
+
+ +
+- But we can not sell the item available at index 6, as A[6] = 5, and A[6] <= T. Now we will check if we have made any incorrect decisions in the past.
+- We have minimum profit 2 in the heap, so remove it from the heap and add the profit of the item available at index 6 in the heap.
+
+**T = 5**
+
+
+
+- But we can not sell the item available at index 6, as A[6] = 5, and A[6] <= T. Now we will check if we have made any incorrect decisions in the past.
+- We have minimum profit 2 in the heap, so remove it from the heap and add the profit of the item available at index 6 in the heap.
+
+**T = 5**
+
+ +
+
+- We can sell a item available at index 7, as A[7] = 8, so here T < A[7], so we will sell the item available at index 7 and add its profit in min-heap.
+
+
+**T = 6**
+
+
+
+
+- We can sell a item available at index 7, as A[7] = 8, so here T < A[7], so we will sell the item available at index 7 and add its profit in min-heap.
+
+
+**T = 6**
+
+ +
+- Now we can find the answer by removing one-by-one elements from the heap and adding them to the answer.
+
+So we have final answer = $1 + 3 + 4 + 5 + 7 + 8 = 28$
+
+
+### PseudoCode
+```cpp
+1. Sort them in increasing order of time.
+2. Minheap heap:
+ T = 0
+ for( i = 0 ; i < N ; i++ ){
+ if(T < A[i]){
+ heap.insert(B[i])
+ T++
+ }
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin()
+ heap.insert(B[i])
+ }
+ }
+ }
+3. Remove all elements from the heap and add them to get the answer.
+```
+
+---
+title: Quiz 2
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+
+What is the time and space complexity of this question?
+
+# Choices
+
+- [ ] TC: O(N), SC: O(N)
+- [x] TC: O(NlogN), SC: O(N)
+- [ ] TC: O(N$^2$), SC: O(N)
+- [ ] TC: O(N$^2$) , SC: O(N$^2$)
+
+
+---
+title: Effective Inventory Management Complexity
+description:
+duration: 300
+card_type: cue_card
+---
+
+**Time Complexity**
+
+```cpp
+1. Sort them in increasing order of time. ---> NlogN
+2. Minheap heap:
+ T = 0
+ for( i = 0 ; i < N ; i++ ){ ---> N
+ if(T < A[i]){
+ heap.insert(B[i]) ---> logN
+ T++
+ }
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin() ---> logN
+ heap.insert(B[i]) ---> logN
+ }
+ }
+ }
+3. Remove all elements from the heap and add them to get the answer.
+```
+
+So overall time complexity = O(NlogN) + O(NlogN)
+
+- **Time Complexity: O(NlogN)**
+- **Space Complexity: O(N)**
+
+
+---
+title: Problem 2 Candy Distribution
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Problem Description
+
+There are N students with their marks. The teacher has to give them candies such that
+a) Every student should have at least one candy
+b) Students with more marks than any of his/her neighbours have more candies than them.
+
+Find minimum candies to distribute.
+
+
+### Example
+**Input:** [1, 5, 2, 1]
+**Explanation:** First we will give 1 candy to all students.
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|1|1|1|
+
+Index 1 student has marks greater than their neighbours. So it must have candies greater than his neighbors.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|~~1~~ 2 |1|1|
+
+Index 2 student has marks greater than its right neighbour. So it must have candies greater than his right neighbour.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|~~1~~ 2 |~~1~~ 2 |1|
+
+Now index 1 student again has marks greater than both neighbors but its candies are not greater than its right neighbor's candies. So it must have candies greater than his both neighbors.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|~~1~~ ~~2~~ 3 |~~1~~ 2 |1|
+
+Now all the conditions of the question are satisfied, so total 7 candies are required to be distributed among students.
+
+**Output:** 7
+
+
+---
+title: Quiz 3
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+
+What is the minimum number of candies teacher has to use if the marks are: [4, 4, 4, 4, 4]
+
+# Choices
+
+- [ ] 1
+- [x] 5
+- [ ] 10
+- [ ] 20
+
+
+---
+title: Quiz Explanation
+description:
+duration: 60
+card_type: cue_card
+---
+
+### Explanation
+
+[4, 4, 4, 4, 4]
+
+First, we will give 1 candy to all students.
+|index|0|1|2|3|4|
+|-|-|-|-|-|-|
+|marks|4|4|4|4|4|
+|candy|1|1|1|1|1|
+
+Now any student does not have marks greater than its neighbors. So our candy distribution is perfect.
+
+**So total 5 candies are required.**
+
+
+
+---
+title: Candy Distribution Example
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Example
+
+**Input:** [8, 10, 6, 2]
+
+
+
+First, we will give 1 candy to all students.
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|8|10|6|2|
+|candy|1|1|1|1|
+
+- Now student at index 2 has marks greater than its right neighbor, so it receive 2 candies.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|8|10|6|2|
+|candy|1|1|~~1~~ 2|1|
+
+- Student at index 1 has marks greater than both neighbours, so it must candies greater than both neighbours. So it receives 3 candies.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|8|10|6|2|
+|candy|1|~~1~~ 3|~~1~~ 2|1|
+
+So total 7 candies are required.
+
+**Output:** 7
+
+
+---
+title: Quiz 4
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the minimum number of candies the teacher has to use if the marks are: [1, 6, 3, 1, 10, 12, 20, 5, 2]
+
+# Choices
+
+- [ ] 15
+- [x] 19
+- [ ] 21
+- [ ] 20
+
+
+---
+title: Quiz Explanation
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Explanation
+
+[1, 6, 3, 1, 10, 12, 20, 5, 2]
+
+First, we will give 1 candy to all students.
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
+
+First, let us consider the left nighbor of all the indexes.
+
+- Now a student at index 1 has marks greater than its left neighbour, so it should receive at least 2 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | --- | --- | --- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
+
+- Now student at index 2, and 3 does not have marks greater than their left neighbour.
+
+- Student at index 4 has marks greater than its left neighbour, so it should receive at least 2 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | --- | --- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | 1 | 1 | 1 | 1 |
+
+- Student at index 5 has marks greater than its left neighbour, so it should receive at least 3 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | ------- | --- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | ~~1~~ 3 | 1 | 1 | 1 |
+
+- Student at index 6 has marks greater than its left neighbour, so it should receive at least 4 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | ------- | ------- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | ~~1~~ 3 | ~~1~~ 4 | 1 | 1 |
+
+- Student at index 7 and index 8 does not have marks greater than their left neighbour.
+
+Now let us consider the right neighbour.
+
+
+- Student at index 7 has marks greater than its right neighbour, so it should receive at least 2 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | ------- | ------- | ------- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | ~~1~~ 3 | ~~1~~ 4 | ~~1~~ 2 | 1 |
+
+- Student at index 6 has marks greater than its right neighbour, so it should receive at least 3 candies but it has 4 candies already which is greater than its right neighbour candies, so it is fine.
+
+- Student at index 5, 4 and 3 do not have marks greater than their right neighbour.
+
+- Student at index 2 has marks greater than its right neighbour. So it receives at least 2 candies.
+
+
+|index|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|-|
+|marks|1|6|3|1|10|12|20|5|2|
+|candy|1|~~1~~ 2|~~1~~ 2|1|~~1~~ 2|~~1~~ 3|~~1~~ 4|~~1~~ 2|1|
+
+- Student at index 1 has marks greater than its right neighbour. So it receives at least 3 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------------- | ------- | --- | ------- | ------- | ------- | ------- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ ~~2~~ 3 | ~~1~~ 2 | 1 | ~~1~~ 2 | ~~1~~ 3 | ~~1~~ 4 | ~~1~~ 2 | 1 |
+
+- Student at index 0 does not have marks greater than its right neighbour.
+
+So a total 19 candies are required.
+
+**Output:** 19
+
+
+---
+title: Candy Distribution Solution
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Candy Distribution - Solution
+
+**Step 1:** Assign 1 candy to all the students.
+**Step 2:** For all the values of i, consider its left neighbour, if(A[i] > A[i - 1]) then C[i] > C[i - 1], means candy of ith index should be greater than (i-1)th index candy, so we will follow the greedy approach as we want to distribute a minimum number of candies, so we do `C[i] = C[i - 1] + 1`
+
+```cpp
+if(A[i] > A[i - 1]){
+ C[i] = C[i - 1] + 1
+}
+```
+
+**Step 3:** For all the values of i, consider its right neighbour, if(A[i] > A[i+1]) then C[i] > C[i + 1], means candy of ith index should be greater than (i+1)th index candy, so first we check it has candies greater than his right neighbour or not if not then we will follow the greedy approach as we want to distribute a minimum number of candies, then we do `C[i] = C[i + 1] + 1`
+
+```cpp
+if(A[i] > A[i + 1]){
+ if(C[i] < C[i + 1] + 1)
+ C[i] = C[i + 1] + 1
+}
+```
+
+### PsuedoCode
+```cpp=
+int C[N];
+for all i, C[i] = 1
+for( i = 1 ; i < N ; i++){
+ if(arr[i] > arr[i - 1]){
+ C[i] = C[i - 1] + 1
+ }
+}
+for( i = N - 2 ; i >= 0 ; i--){
+ if(arr[i] > arr[i + 1] && C[i] < C[i + 1] + 1 ){
+ C[i] = C[i + 1] + 1
+ }
+}
+
+ans = sum of all values in C[]
+```
+### Complexity
+
+- **Time Complexity:** O(N)
+- **Space Complexity:** O(N)
+
+
+---
+title: Problem 3 Maximum jobs
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Maximum jobs
+
+Given N jobs with their start and end times. Find the maximum number of jobs that can be completed if only one job can be done at a time.
+
+### Example
+
+
+
+**Answer:** 5
+
+We will select the jobs that are not overlapping:
+- We select job `9 am - 11 am`, then we can not select `10 am - 1 pm` and `10 am - 2 pm`
+- Then we select jobs `3 pm - 4 pm` and `4 pm - 6 pm`
+- Then we select job `4 pm - 8 pm` and `8 pm - 10 pm` but we do not select job `7 pm - 9 pm`
+
+
+
+
+
+
+### Approach
+We have to select the job in such a way that the start time of a currently selected job is greater than or equal to the end time of the previous job.
+
+`S[i] >= E[i - 1]`
+
+
+---
+title: Quiz 5
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the maximum number of jobs one person can do if only one job at a time is allowed, the start times and end times of jobs are:
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+# Choices
+
+- [ ] 2
+- [x] 3
+- [ ] 4
+- [ ] 5
+
+
+---
+title: Quiz Explanation
+description:
+duration: 120
+card_type: cue_card
+---
+
+### Explanation
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+
+
+We will pick jobs `1 - 2`, `5 - 10` and `12 - 20`. So we can pick total three jobs.
+
+
+
+
+---
+title: Maximum jobs Solution
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Maximum jobs - Solution
+
+The first idea towards a solution is to first pick a job with minimum duration.
+
+### Idea 1 - Greedy based on duration
+Pick the job in the ascending order of the minimum duration. Let us take an example:
+
+
+
+In this case, if we select the minimum duration job first, then we will select the job `10 - 13`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `10 - 13`, then we can select both other jobs, which means we can select two jobs.
+
+
+
+
+So selecting a job in the ascending order of the duration will not always give us the maximum number of jobs.
+
+
+### Idea 2 - Greedy based on start time
+Pick the job in the ascending order of the start time. Let us take an example:
+
+
+
+
+
+
+In this case, if we select the minimum start time job first, then we will select the job `2 - 20`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `2 - 20`, then we can select both other jobs, which means we can select two jobs.
+
+
+
+So selecting a job in the ascending order of the start time will not always give us the maximum number of jobs.
+
+### Observation
+We have to take a combination of the above approaches means we have to start early with the minimum duration job.
+
+start early + minimum duration
+
+A combination of both is nothing but simply means ending early.
+
+start early + minimum duration = end early
+
+### Solution
+We have to be greedy based on the end time, so we have to select jobs in the ascending order of end times.
+
+**Example:**
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+Sort these jobs based on the end time.
+
+
+S = [1, 5, 8, 7, 13, 12]
+E = [2, 10, 10, 11, 19, 20]
+
+Initially ans = 0.
+
+| Index | 0 | 1 | 2 | 3 | 4 | 5 |
+|:----------:| --- | --- | --- |:---:|:---:|:---:|
+| Start time | 1 | 5 | 8 | 7 | 13 | 12 |
+| end time | 2 | 10 | 10 | 11 | 19 | 20 |
+
+
+- We will start with the first job, which has an end time 2 but now the start time of any next job must be greater than the end time of this job.
+
+
+**So we need to keep track of the last end time.**
+
+Till now lastEndTime = 2
+ans+=1, ans = 1
+
+- Now the job at index 1 has start time = 5, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 10
+ans+=1, ans = 2
+- Now the job at index 2 has start time = 8, lastEndTime > start time, so we can not select this job.
+- Now the job at index 3 has start time = 7, lastEndTime > start time, so we can not select this job.
+- Now the job at index 4 has start time = 13, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 19
+ans+=1, ans = 3
+- Now the job at index 5 has start time = 20, lastEndTime > start time, so we can not select this job.
+
+**Answer:** 3
+
+### PseudoCode
+```cpp
+1. Sort on the basis of end-time
+2. ans = 1, lastEndTime = E[0]
+ for( i = 1 ; i < N ; i++){
+ if(S[i] >= lastEndTime){
+ ans++;
+ lastEndTime = E[i];
+ }
+ }
+3. return ans;
+```
+
+### Complexity
+
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(N)
+
+---
+title: Contest Information
+description:
+duration: 900
+card_type: cue_card
+---
+
+We have completed **Greedy** topic, which is part of our upcoming contest, please solve atleast assignment problems of this topic.
+
+Our upcoming contest syllabus is completed now, topics are : **Trees, Heaps & Greedy**
+
+Please share the follwoing with learners -
+1. Revision material
+https://hackmd.io/@scaler-topics-main/By3KctjdT
+
+2. How to access the contest?
+https://www.loom.com/share/5a47836051384f8fa3ffb32c3c9d5e7f?sid=ff500645-0cb5-498a-aebc-29997f6745f9
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 1 Introduction.md b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 1 Introduction.md
new file mode 100644
index 0000000..5607bb5
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 1 Introduction.md
@@ -0,0 +1,639 @@
+# Advanced DSA: Heaps 1: Introduction
+
+---
+title: Problem 1 Connecting the ropes
+description:
+duration: 1800
+card_type: cue_card
+---
+
+### Problem Description
+We are given an array that represents the size of different ropes. In a single operation, you can connect two ropes. Cost of connecting two ropes is sum of the length of ropes you are connecting. Find the minimum cost of connecting all the ropes.
+
+**`To illustrate:`**
+
+### Example 1:
+
+int A[] = {2, 5, 3, 2, 6}
+
+
+
+### Example 2:
+
+**`Initial Ropes: [2, 5, 6, 3]`**
+
+Connect 2 and 5 (Cost = 2 + 5 = 7)
+Total Cost: 7
+New Ropes: [7, 6, 3]
+Next Step: [7, 6, 3]
+
+Connect 7 and 6 (Cost = 7 + 6 = 13)
+Total Cost: 7 + 13 = 20
+New Ropes: [13, 3]
+Final Step: [13, 3]
+
+Connect 13 and 3 (Cost = 13 + 3 = 16)
+Total Cost: 20 + 16 = 36
+Final Rope: [16]
+
+This is one of the options for finding the cost of connecting all ropes, but we need to find the minimum cost of connecting all the ropes.
+
+
+### Observation
+Say, we have 3 ropes, **`x < y < z`**
+Which 2 ropes should we connect first ?
+
+| Case | 1 | 2 |3|
+| --------| -------- | -------- |--|
+| Step 1 | x+y | x+z |y+z|
+| Step 2 | (x+y) + z | (x+z) + y |(y+z) + x|
+
+Comparing case 1 and 2, y and z are different, now since y < z, we can say cost of 1 < cost of 2.
+
+
+Comparing case 2 and 3, x and y are different, now since x < y, we can say cost of 2 < cost of 3.
+
+**`Conclusion:`** Connecting smaller length ropes gives us lesser cost.
+
+### Process:
+
+**`Initial Setup:`** Start with an array of rope lengths, e.g., [2, 2, 3, 5, 6]. First, sort the array.
+
+**`Combining Ropes:`**
+
+- Continuously pick the two smallest ropes.
+- Combine these ropes, adding their lengths to find the cost.
+- Insert the combined rope back into the array at its correct position in sorted array.
+- Repeat until only one rope remains.
+
+We are basically applying **`insertion sort`**.
+
+**`Example Steps:`**
+
+- Combine ropes 2 and 2 (cost = 4). New array: [3, 4, 5, 6]. Total cost: 4.
+- Combine ropes 3 and 4 (cost = 7). New array: [5, 6, 7]. Total cost: 11.
+- Combine ropes 5 and 6 (cost = 11). New array: [7, 11]. Total cost: 22.
+- Combine ropes 7 and 11 (cost = 18). Final rope: 18. Total cost: 40.
+
+
+### Complexity
+**Time Complexity:** O(N^2^)
+**Space Complexity:** O(1)
+
+---
+title: Quiz 1
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the minimum cost of connecting all the ropes for the array [1, 2, 3, 4]?
+
+# Choices
+- [x] 19
+- [ ] 20
+- [ ] 10
+- [ ] 0
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+**Always pick two of the smallest ropes and combine them.**
+
+After combining the two smallest ropes at every step, we need to sort an array again to get the two minimum-length ropes.
+
+1, 2, 3, 4; cost = 3
+3, 3, 4; sort: 3, 3, 4; cost = 6
+6, 4; sort: 4, 6; cost = 10
+
+Final Length: 10
+Total Cost = (3 + 6 + 10) = 19
+
+
+---
+title: Connecting the ropes optimisation
+description:
+duration: 1800
+card_type: cue_card
+---
+
+Heaps efficiently perform the necessary operations:
+
+- Insertion of elements in **`O(log n)`** time.
+- Extraction of the minimum element in **`O(log n)`** time.
+
+**`NOTE: We'll understand how we can achive the above complexities, for now assume heap to be a black box solving the above requirements for us in lesser time.`**
+
+Heap returns the min or max value depending upon it is a min heap or max heap.
+
+Say, for above problem, we use a min heap. At every step, it will give us the 2 small length ropes. Please note below steps for solving above problem.
+
+
+
+### Time & Space Complexity
+For every operation, we are removing 2 elements and inserting one back, hence it is 3 * log N. For N operations, **`the time complexity will be O(N * log N)`**
+
+**`Space Complexity is O(N)`**
+
+---
+title: Heap Data Structure
+description: Introduction to the heap data structure
+duration: 1800
+card_type: cue_card
+---
+
+### Heap Data Structure
+The heap data structure is a binary tree with two special properties.
+- First property is based on structure.
+ - **Complete Binary Tree:** All levels are completely filled. The last level can be the exception but is should also be filled from left to right.
+- Second property is based on the order of elements.
+ - **Heap Order Property:** In the case of max heap, the value of the parent is greater than the value of the children. And in the case of min heap, the value of the parent is less than the value of the children.
+
+
+### Examples
+
+**`Example 1:`**
+
+
+
+- Now we can find the answer by removing one-by-one elements from the heap and adding them to the answer.
+
+So we have final answer = $1 + 3 + 4 + 5 + 7 + 8 = 28$
+
+
+### PseudoCode
+```cpp
+1. Sort them in increasing order of time.
+2. Minheap heap:
+ T = 0
+ for( i = 0 ; i < N ; i++ ){
+ if(T < A[i]){
+ heap.insert(B[i])
+ T++
+ }
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin()
+ heap.insert(B[i])
+ }
+ }
+ }
+3. Remove all elements from the heap and add them to get the answer.
+```
+
+---
+title: Quiz 2
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+
+What is the time and space complexity of this question?
+
+# Choices
+
+- [ ] TC: O(N), SC: O(N)
+- [x] TC: O(NlogN), SC: O(N)
+- [ ] TC: O(N$^2$), SC: O(N)
+- [ ] TC: O(N$^2$) , SC: O(N$^2$)
+
+
+---
+title: Effective Inventory Management Complexity
+description:
+duration: 300
+card_type: cue_card
+---
+
+**Time Complexity**
+
+```cpp
+1. Sort them in increasing order of time. ---> NlogN
+2. Minheap heap:
+ T = 0
+ for( i = 0 ; i < N ; i++ ){ ---> N
+ if(T < A[i]){
+ heap.insert(B[i]) ---> logN
+ T++
+ }
+ else{
+ if(B[i] <= root of heap) -> ignore
+ {
+
+ }
+ else{
+ extractMin() ---> logN
+ heap.insert(B[i]) ---> logN
+ }
+ }
+ }
+3. Remove all elements from the heap and add them to get the answer.
+```
+
+So overall time complexity = O(NlogN) + O(NlogN)
+
+- **Time Complexity: O(NlogN)**
+- **Space Complexity: O(N)**
+
+
+---
+title: Problem 2 Candy Distribution
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Problem Description
+
+There are N students with their marks. The teacher has to give them candies such that
+a) Every student should have at least one candy
+b) Students with more marks than any of his/her neighbours have more candies than them.
+
+Find minimum candies to distribute.
+
+
+### Example
+**Input:** [1, 5, 2, 1]
+**Explanation:** First we will give 1 candy to all students.
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|1|1|1|
+
+Index 1 student has marks greater than their neighbours. So it must have candies greater than his neighbors.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|~~1~~ 2 |1|1|
+
+Index 2 student has marks greater than its right neighbour. So it must have candies greater than his right neighbour.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|~~1~~ 2 |~~1~~ 2 |1|
+
+Now index 1 student again has marks greater than both neighbors but its candies are not greater than its right neighbor's candies. So it must have candies greater than his both neighbors.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|1|5|2|1|
+|candy|1|~~1~~ ~~2~~ 3 |~~1~~ 2 |1|
+
+Now all the conditions of the question are satisfied, so total 7 candies are required to be distributed among students.
+
+**Output:** 7
+
+
+---
+title: Quiz 3
+description:
+duration: 30
+card_type: quiz_card
+---
+
+# Question
+
+What is the minimum number of candies teacher has to use if the marks are: [4, 4, 4, 4, 4]
+
+# Choices
+
+- [ ] 1
+- [x] 5
+- [ ] 10
+- [ ] 20
+
+
+---
+title: Quiz Explanation
+description:
+duration: 60
+card_type: cue_card
+---
+
+### Explanation
+
+[4, 4, 4, 4, 4]
+
+First, we will give 1 candy to all students.
+|index|0|1|2|3|4|
+|-|-|-|-|-|-|
+|marks|4|4|4|4|4|
+|candy|1|1|1|1|1|
+
+Now any student does not have marks greater than its neighbors. So our candy distribution is perfect.
+
+**So total 5 candies are required.**
+
+
+
+---
+title: Candy Distribution Example
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Example
+
+**Input:** [8, 10, 6, 2]
+
+
+
+First, we will give 1 candy to all students.
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|8|10|6|2|
+|candy|1|1|1|1|
+
+- Now student at index 2 has marks greater than its right neighbor, so it receive 2 candies.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|8|10|6|2|
+|candy|1|1|~~1~~ 2|1|
+
+- Student at index 1 has marks greater than both neighbours, so it must candies greater than both neighbours. So it receives 3 candies.
+
+|index|0|1|2|3|
+|-|-|-|-|-|
+|marks|8|10|6|2|
+|candy|1|~~1~~ 3|~~1~~ 2|1|
+
+So total 7 candies are required.
+
+**Output:** 7
+
+
+---
+title: Quiz 4
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the minimum number of candies the teacher has to use if the marks are: [1, 6, 3, 1, 10, 12, 20, 5, 2]
+
+# Choices
+
+- [ ] 15
+- [x] 19
+- [ ] 21
+- [ ] 20
+
+
+---
+title: Quiz Explanation
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Explanation
+
+[1, 6, 3, 1, 10, 12, 20, 5, 2]
+
+First, we will give 1 candy to all students.
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
+
+First, let us consider the left nighbor of all the indexes.
+
+- Now a student at index 1 has marks greater than its left neighbour, so it should receive at least 2 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | --- | --- | --- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
+
+- Now student at index 2, and 3 does not have marks greater than their left neighbour.
+
+- Student at index 4 has marks greater than its left neighbour, so it should receive at least 2 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | --- | --- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | 1 | 1 | 1 | 1 |
+
+- Student at index 5 has marks greater than its left neighbour, so it should receive at least 3 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | ------- | --- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | ~~1~~ 3 | 1 | 1 | 1 |
+
+- Student at index 6 has marks greater than its left neighbour, so it should receive at least 4 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | ------- | ------- | --- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | ~~1~~ 3 | ~~1~~ 4 | 1 | 1 |
+
+- Student at index 7 and index 8 does not have marks greater than their left neighbour.
+
+Now let us consider the right neighbour.
+
+
+- Student at index 7 has marks greater than its right neighbour, so it should receive at least 2 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------- | --- | --- | ------- | ------- | ------- | ------- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ 2 | 1 | 1 | ~~1~~ 2 | ~~1~~ 3 | ~~1~~ 4 | ~~1~~ 2 | 1 |
+
+- Student at index 6 has marks greater than its right neighbour, so it should receive at least 3 candies but it has 4 candies already which is greater than its right neighbour candies, so it is fine.
+
+- Student at index 5, 4 and 3 do not have marks greater than their right neighbour.
+
+- Student at index 2 has marks greater than its right neighbour. So it receives at least 2 candies.
+
+
+|index|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|-|
+|marks|1|6|3|1|10|12|20|5|2|
+|candy|1|~~1~~ 2|~~1~~ 2|1|~~1~~ 2|~~1~~ 3|~~1~~ 4|~~1~~ 2|1|
+
+- Student at index 1 has marks greater than its right neighbour. So it receives at least 3 candies.
+
+| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+|:-----:| --- | ------------- | ------- | --- | ------- | ------- | ------- | ------- | --- |
+| marks | 1 | 6 | 3 | 1 | 10 | 12 | 20 | 5 | 2 |
+| candy | 1 | ~~1~~ ~~2~~ 3 | ~~1~~ 2 | 1 | ~~1~~ 2 | ~~1~~ 3 | ~~1~~ 4 | ~~1~~ 2 | 1 |
+
+- Student at index 0 does not have marks greater than its right neighbour.
+
+So a total 19 candies are required.
+
+**Output:** 19
+
+
+---
+title: Candy Distribution Solution
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Candy Distribution - Solution
+
+**Step 1:** Assign 1 candy to all the students.
+**Step 2:** For all the values of i, consider its left neighbour, if(A[i] > A[i - 1]) then C[i] > C[i - 1], means candy of ith index should be greater than (i-1)th index candy, so we will follow the greedy approach as we want to distribute a minimum number of candies, so we do `C[i] = C[i - 1] + 1`
+
+```cpp
+if(A[i] > A[i - 1]){
+ C[i] = C[i - 1] + 1
+}
+```
+
+**Step 3:** For all the values of i, consider its right neighbour, if(A[i] > A[i+1]) then C[i] > C[i + 1], means candy of ith index should be greater than (i+1)th index candy, so first we check it has candies greater than his right neighbour or not if not then we will follow the greedy approach as we want to distribute a minimum number of candies, then we do `C[i] = C[i + 1] + 1`
+
+```cpp
+if(A[i] > A[i + 1]){
+ if(C[i] < C[i + 1] + 1)
+ C[i] = C[i + 1] + 1
+}
+```
+
+### PsuedoCode
+```cpp=
+int C[N];
+for all i, C[i] = 1
+for( i = 1 ; i < N ; i++){
+ if(arr[i] > arr[i - 1]){
+ C[i] = C[i - 1] + 1
+ }
+}
+for( i = N - 2 ; i >= 0 ; i--){
+ if(arr[i] > arr[i + 1] && C[i] < C[i + 1] + 1 ){
+ C[i] = C[i + 1] + 1
+ }
+}
+
+ans = sum of all values in C[]
+```
+### Complexity
+
+- **Time Complexity:** O(N)
+- **Space Complexity:** O(N)
+
+
+---
+title: Problem 3 Maximum jobs
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Maximum jobs
+
+Given N jobs with their start and end times. Find the maximum number of jobs that can be completed if only one job can be done at a time.
+
+### Example
+
+
+
+**Answer:** 5
+
+We will select the jobs that are not overlapping:
+- We select job `9 am - 11 am`, then we can not select `10 am - 1 pm` and `10 am - 2 pm`
+- Then we select jobs `3 pm - 4 pm` and `4 pm - 6 pm`
+- Then we select job `4 pm - 8 pm` and `8 pm - 10 pm` but we do not select job `7 pm - 9 pm`
+
+
+
+
+
+
+### Approach
+We have to select the job in such a way that the start time of a currently selected job is greater than or equal to the end time of the previous job.
+
+`S[i] >= E[i - 1]`
+
+
+---
+title: Quiz 5
+description:
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the maximum number of jobs one person can do if only one job at a time is allowed, the start times and end times of jobs are:
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+# Choices
+
+- [ ] 2
+- [x] 3
+- [ ] 4
+- [ ] 5
+
+
+---
+title: Quiz Explanation
+description:
+duration: 120
+card_type: cue_card
+---
+
+### Explanation
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+
+
+We will pick jobs `1 - 2`, `5 - 10` and `12 - 20`. So we can pick total three jobs.
+
+
+
+
+---
+title: Maximum jobs Solution
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Maximum jobs - Solution
+
+The first idea towards a solution is to first pick a job with minimum duration.
+
+### Idea 1 - Greedy based on duration
+Pick the job in the ascending order of the minimum duration. Let us take an example:
+
+
+
+In this case, if we select the minimum duration job first, then we will select the job `10 - 13`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `10 - 13`, then we can select both other jobs, which means we can select two jobs.
+
+
+
+
+So selecting a job in the ascending order of the duration will not always give us the maximum number of jobs.
+
+
+### Idea 2 - Greedy based on start time
+Pick the job in the ascending order of the start time. Let us take an example:
+
+
+
+
+
+
+In this case, if we select the minimum start time job first, then we will select the job `2 - 20`, then we can not select any other job because both overlap with it.
+
+But if we have not selected `2 - 20`, then we can select both other jobs, which means we can select two jobs.
+
+
+
+So selecting a job in the ascending order of the start time will not always give us the maximum number of jobs.
+
+### Observation
+We have to take a combination of the above approaches means we have to start early with the minimum duration job.
+
+start early + minimum duration
+
+A combination of both is nothing but simply means ending early.
+
+start early + minimum duration = end early
+
+### Solution
+We have to be greedy based on the end time, so we have to select jobs in the ascending order of end times.
+
+**Example:**
+
+S = [1, 5, 8, 7, 12, 13]
+E = [2, 10, 10, 11, 20, 19]
+
+Sort these jobs based on the end time.
+
+
+S = [1, 5, 8, 7, 13, 12]
+E = [2, 10, 10, 11, 19, 20]
+
+Initially ans = 0.
+
+| Index | 0 | 1 | 2 | 3 | 4 | 5 |
+|:----------:| --- | --- | --- |:---:|:---:|:---:|
+| Start time | 1 | 5 | 8 | 7 | 13 | 12 |
+| end time | 2 | 10 | 10 | 11 | 19 | 20 |
+
+
+- We will start with the first job, which has an end time 2 but now the start time of any next job must be greater than the end time of this job.
+
+
+**So we need to keep track of the last end time.**
+
+Till now lastEndTime = 2
+ans+=1, ans = 1
+
+- Now the job at index 1 has start time = 5, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 10
+ans+=1, ans = 2
+- Now the job at index 2 has start time = 8, lastEndTime > start time, so we can not select this job.
+- Now the job at index 3 has start time = 7, lastEndTime > start time, so we can not select this job.
+- Now the job at index 4 has start time = 13, lastEndTime <= start time, so can select this job and lastEndTime will be updated to the end time of the current job and the answer is incremented by 1.
+lastEndTime = 19
+ans+=1, ans = 3
+- Now the job at index 5 has start time = 20, lastEndTime > start time, so we can not select this job.
+
+**Answer:** 3
+
+### PseudoCode
+```cpp
+1. Sort on the basis of end-time
+2. ans = 1, lastEndTime = E[0]
+ for( i = 1 ; i < N ; i++){
+ if(S[i] >= lastEndTime){
+ ans++;
+ lastEndTime = E[i];
+ }
+ }
+3. return ans;
+```
+
+### Complexity
+
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(N)
+
+---
+title: Contest Information
+description:
+duration: 900
+card_type: cue_card
+---
+
+We have completed **Greedy** topic, which is part of our upcoming contest, please solve atleast assignment problems of this topic.
+
+Our upcoming contest syllabus is completed now, topics are : **Trees, Heaps & Greedy**
+
+Please share the follwoing with learners -
+1. Revision material
+https://hackmd.io/@scaler-topics-main/By3KctjdT
+
+2. How to access the contest?
+https://www.loom.com/share/5a47836051384f8fa3ffb32c3c9d5e7f?sid=ff500645-0cb5-498a-aebc-29997f6745f9
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 1 Introduction.md b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 1 Introduction.md
new file mode 100644
index 0000000..5607bb5
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 1 Introduction.md
@@ -0,0 +1,639 @@
+# Advanced DSA: Heaps 1: Introduction
+
+---
+title: Problem 1 Connecting the ropes
+description:
+duration: 1800
+card_type: cue_card
+---
+
+### Problem Description
+We are given an array that represents the size of different ropes. In a single operation, you can connect two ropes. Cost of connecting two ropes is sum of the length of ropes you are connecting. Find the minimum cost of connecting all the ropes.
+
+**`To illustrate:`**
+
+### Example 1:
+
+int A[] = {2, 5, 3, 2, 6}
+
+
+
+### Example 2:
+
+**`Initial Ropes: [2, 5, 6, 3]`**
+
+Connect 2 and 5 (Cost = 2 + 5 = 7)
+Total Cost: 7
+New Ropes: [7, 6, 3]
+Next Step: [7, 6, 3]
+
+Connect 7 and 6 (Cost = 7 + 6 = 13)
+Total Cost: 7 + 13 = 20
+New Ropes: [13, 3]
+Final Step: [13, 3]
+
+Connect 13 and 3 (Cost = 13 + 3 = 16)
+Total Cost: 20 + 16 = 36
+Final Rope: [16]
+
+This is one of the options for finding the cost of connecting all ropes, but we need to find the minimum cost of connecting all the ropes.
+
+
+### Observation
+Say, we have 3 ropes, **`x < y < z`**
+Which 2 ropes should we connect first ?
+
+| Case | 1 | 2 |3|
+| --------| -------- | -------- |--|
+| Step 1 | x+y | x+z |y+z|
+| Step 2 | (x+y) + z | (x+z) + y |(y+z) + x|
+
+Comparing case 1 and 2, y and z are different, now since y < z, we can say cost of 1 < cost of 2.
+
+
+Comparing case 2 and 3, x and y are different, now since x < y, we can say cost of 2 < cost of 3.
+
+**`Conclusion:`** Connecting smaller length ropes gives us lesser cost.
+
+### Process:
+
+**`Initial Setup:`** Start with an array of rope lengths, e.g., [2, 2, 3, 5, 6]. First, sort the array.
+
+**`Combining Ropes:`**
+
+- Continuously pick the two smallest ropes.
+- Combine these ropes, adding their lengths to find the cost.
+- Insert the combined rope back into the array at its correct position in sorted array.
+- Repeat until only one rope remains.
+
+We are basically applying **`insertion sort`**.
+
+**`Example Steps:`**
+
+- Combine ropes 2 and 2 (cost = 4). New array: [3, 4, 5, 6]. Total cost: 4.
+- Combine ropes 3 and 4 (cost = 7). New array: [5, 6, 7]. Total cost: 11.
+- Combine ropes 5 and 6 (cost = 11). New array: [7, 11]. Total cost: 22.
+- Combine ropes 7 and 11 (cost = 18). Final rope: 18. Total cost: 40.
+
+
+### Complexity
+**Time Complexity:** O(N^2^)
+**Space Complexity:** O(1)
+
+---
+title: Quiz 1
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the minimum cost of connecting all the ropes for the array [1, 2, 3, 4]?
+
+# Choices
+- [x] 19
+- [ ] 20
+- [ ] 10
+- [ ] 0
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+**Always pick two of the smallest ropes and combine them.**
+
+After combining the two smallest ropes at every step, we need to sort an array again to get the two minimum-length ropes.
+
+1, 2, 3, 4; cost = 3
+3, 3, 4; sort: 3, 3, 4; cost = 6
+6, 4; sort: 4, 6; cost = 10
+
+Final Length: 10
+Total Cost = (3 + 6 + 10) = 19
+
+
+---
+title: Connecting the ropes optimisation
+description:
+duration: 1800
+card_type: cue_card
+---
+
+Heaps efficiently perform the necessary operations:
+
+- Insertion of elements in **`O(log n)`** time.
+- Extraction of the minimum element in **`O(log n)`** time.
+
+**`NOTE: We'll understand how we can achive the above complexities, for now assume heap to be a black box solving the above requirements for us in lesser time.`**
+
+Heap returns the min or max value depending upon it is a min heap or max heap.
+
+Say, for above problem, we use a min heap. At every step, it will give us the 2 small length ropes. Please note below steps for solving above problem.
+
+
+
+### Time & Space Complexity
+For every operation, we are removing 2 elements and inserting one back, hence it is 3 * log N. For N operations, **`the time complexity will be O(N * log N)`**
+
+**`Space Complexity is O(N)`**
+
+---
+title: Heap Data Structure
+description: Introduction to the heap data structure
+duration: 1800
+card_type: cue_card
+---
+
+### Heap Data Structure
+The heap data structure is a binary tree with two special properties.
+- First property is based on structure.
+ - **Complete Binary Tree:** All levels are completely filled. The last level can be the exception but is should also be filled from left to right.
+- Second property is based on the order of elements.
+ - **Heap Order Property:** In the case of max heap, the value of the parent is greater than the value of the children. And in the case of min heap, the value of the parent is less than the value of the children.
+
+
+### Examples
+
+**`Example 1:`**
+
+ +
+- This is the complete binary tree as all the levels are filled and the last level is filled from left to right.
+- Heap Order Property is also valid at every point in the tree, as 5 is less than 12 and 20, 12 is less than 25 and 13, 20 is less than 24 and 22, 25 is less than 35 and 34.
+- Hence, it is a **min-heap**
+
+
+**`Example 2:`**
+
+
+
+- This is the complete binary tree as all the levels are filled and the last level is filled from left to right.
+- Heap Order Property is also valid at every point in the tree, as 5 is less than 12 and 20, 12 is less than 25 and 13, 20 is less than 24 and 22, 25 is less than 35 and 34.
+- Hence, it is a **min-heap**
+
+
+**`Example 2:`**
+
+ +
+- This is the complete binary tree as all the levels are filled and the last level is filled from left to right.
+- Heap Order Property is also valid at every point in the tree, as 58 is greater than 39 and 26, 39 is greater than 34 and 12, 26 is greater than 3 and 9, 34 is greater than 16 and 1.
+- Hence, it is a **max-heap.**
+
+---
+title: Array Implementation of Trees(Complete Binary Tree)
+description:
+duration: 1800
+card_type: cue_card
+---
+
+
+
+- We shall store elements in the array in level order wise.
+- Such an array representation of tree is only possible if it is a complete binary tree.
+
+
+
+- This is the complete binary tree as all the levels are filled and the last level is filled from left to right.
+- Heap Order Property is also valid at every point in the tree, as 58 is greater than 39 and 26, 39 is greater than 34 and 12, 26 is greater than 3 and 9, 34 is greater than 16 and 1.
+- Hence, it is a **max-heap.**
+
+---
+title: Array Implementation of Trees(Complete Binary Tree)
+description:
+duration: 1800
+card_type: cue_card
+---
+
+
+
+- We shall store elements in the array in level order wise.
+- Such an array representation of tree is only possible if it is a complete binary tree.
+
+ +
+- Index 0 has its children at index 1 and 2
+- Index 1 has its children at index 3 and 4
+- Index 2 has its children at index 5 and 6
+- Index 3 has its children at index 7 and 8
+
+**`For the particular node stored at the i index, the left child is at (i * 2 + 1 ) and the right child is at (i * 2 + 2 )`**.
+
+**`For any node i, its parent is at (i-1)/2.`**
+
+
+
+---
+title: Insertion in min heap
+description:
+duration: 1800
+card_type: cue_card
+---
+
+
+
+|0|1|2|3|4|5|6|7|
+|-|-|-|-|-|-|-|-|
+|5|12|20|25|13|24|22|35|
+
+
+### Example 1: Insert 10
+
+In an array, if we will insert 10 at index 8, then our array becomes,
+
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|12|20|25|13|24|22|35|10|
+
+
+
+And the tree becomes,
+
+
+
+- Index 0 has its children at index 1 and 2
+- Index 1 has its children at index 3 and 4
+- Index 2 has its children at index 5 and 6
+- Index 3 has its children at index 7 and 8
+
+**`For the particular node stored at the i index, the left child is at (i * 2 + 1 ) and the right child is at (i * 2 + 2 )`**.
+
+**`For any node i, its parent is at (i-1)/2.`**
+
+
+
+---
+title: Insertion in min heap
+description:
+duration: 1800
+card_type: cue_card
+---
+
+
+
+|0|1|2|3|4|5|6|7|
+|-|-|-|-|-|-|-|-|
+|5|12|20|25|13|24|22|35|
+
+
+### Example 1: Insert 10
+
+In an array, if we will insert 10 at index 8, then our array becomes,
+
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|12|20|25|13|24|22|35|10|
+
+
+
+And the tree becomes,
+
+ +
+Now tree satisfies the complete binary tree property but the tree does not satisfy the min-heap property, as here 25 > 10.
+
+In this case, we shall start with the inserted node and compare the parent with the child and keep swapping until the property is satisfied.
+
+Let us assume the node inserted at index `i` and the index of its parent is `pi`.
+```cpp
+if(arr[pi] > arr[i]) swap
+```
+
+> i = 8
+pi = (8-1)/2 = 3
+Since, (arr[3] > arr[8]) swap
+
+
+
+Now tree satisfies the complete binary tree property but the tree does not satisfy the min-heap property, as here 25 > 10.
+
+In this case, we shall start with the inserted node and compare the parent with the child and keep swapping until the property is satisfied.
+
+Let us assume the node inserted at index `i` and the index of its parent is `pi`.
+```cpp
+if(arr[pi] > arr[i]) swap
+```
+
+> i = 8
+pi = (8-1)/2 = 3
+Since, (arr[3] > arr[8]) swap
+
+ +
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|12|20|10|13|24|22|35|25|
+
+
+
+Now again we need to confirm whether the heap order property is satisfied or not by checking with its parent again.
+
+> i = 3
+pi = (3-1)/2 = 1
+Since, (arr[1] > arr[3]) swap
+
+
+
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|12|20|10|13|24|22|35|25|
+
+
+
+Now again we need to confirm whether the heap order property is satisfied or not by checking with its parent again.
+
+> i = 3
+pi = (3-1)/2 = 1
+Since, (arr[1] > arr[3]) swap
+
+ +
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|10|20|12|13|24|22|35|25|
+
+Now again we need to confirm whether the heap order property is satisfied or not by checking with its parent again.
+
+> i = 1
+pi = (3-1)/2 = 0
+Since, (arr[0] < arr[1]) no need to swap
+
+STOP
+
+Now this tree satisfies the min-heap order property.
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|10|20|12|13|24|22|35|25|
+
+
+
+### Example 2: Insert 3
+
+First insert 3 at index 9.
+
+|0|1|2|3|4|5|6|7|8|9|
+|-|-|-|-|-|-|-|-|-|-|
+|5|10|20|12|13|24|22|35|25|3|
+
+- Compare index 9 and parent index ((9-1)/2)= 4 value, as arr[4] > arr[9], swap.
+- Now again compare index 4 and , parent index((4-1)/2)=1 arr[1]>arr[4], swap again.
+- Now again compare index 1 and , parent index((1-1)/2)=0 arr[0]>arr[1], swap again.
+- Now zero index does not have any parent so stop.
+
+
+
+
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|10|20|12|13|24|22|35|25|
+
+Now again we need to confirm whether the heap order property is satisfied or not by checking with its parent again.
+
+> i = 1
+pi = (3-1)/2 = 0
+Since, (arr[0] < arr[1]) no need to swap
+
+STOP
+
+Now this tree satisfies the min-heap order property.
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|5|10|20|12|13|24|22|35|25|
+
+
+
+### Example 2: Insert 3
+
+First insert 3 at index 9.
+
+|0|1|2|3|4|5|6|7|8|9|
+|-|-|-|-|-|-|-|-|-|-|
+|5|10|20|12|13|24|22|35|25|3|
+
+- Compare index 9 and parent index ((9-1)/2)= 4 value, as arr[4] > arr[9], swap.
+- Now again compare index 4 and , parent index((4-1)/2)=1 arr[1]>arr[4], swap again.
+- Now again compare index 1 and , parent index((1-1)/2)=0 arr[0]>arr[1], swap again.
+- Now zero index does not have any parent so stop.
+
+
+ +
+|0|1|2|3|4|5|6|7|8|9|
+|-|-|-|-|-|-|-|-|-|-|
+|3|5|20|12|10|24|22|35|25|13|
+
+
+**`NOTE: The maximum swap we can perform for any element to be inserted is equal to the height of the tree.`**
+
+---
+title: Quiz 2
+description: Complexity of inserting an element in the heap
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+
+Time Complexity of inserting an element in a heap having n nodes?
+
+# Choices
+
+- [ ] O(1)
+- [x] O(log n)
+- [ ] O(sqrt n)
+- [ ] O(n)
+
+
+---
+title: Inserting in min heap pseudocode
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Pseudocode
+```cpp
+heap[];
+heap.insert(val); // inserting at last
+i = heap.size - 1;
+while(i>0){
+ pi = (i-1)/2;
+ if(heap[pi] > heap[i]){
+ swap(heap,pi,i);
+ i=pi;
+ }
+ else
+ {
+ break;
+ }
+}
+```
+
+### Complexity
+**Time Complexity:** O(height of tree) = O(logN)
+
+
+---
+title: Extract Min
+description:
+duration: 1800
+card_type: cue_card
+---
+
+**`Min Heap -`**
+
+
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|2|4|5|11|6|7|8|20|12|
+
+
+In this tree, we have a minimum element at the root. First we swap the first and last elements, then remove the last index element of an array virtually, i.e. consider your array from index 0 to N-2.
+
+
+
+
+
+But the tree is not satisfying the heap-order property. To regain this heap-order property, first check 12, 4 and 5, the minimum is 4, so swap 12 with 4.
+
+
+
+|0|1|2|3|4|5|6|7|8|9|
+|-|-|-|-|-|-|-|-|-|-|
+|3|5|20|12|10|24|22|35|25|13|
+
+
+**`NOTE: The maximum swap we can perform for any element to be inserted is equal to the height of the tree.`**
+
+---
+title: Quiz 2
+description: Complexity of inserting an element in the heap
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+
+Time Complexity of inserting an element in a heap having n nodes?
+
+# Choices
+
+- [ ] O(1)
+- [x] O(log n)
+- [ ] O(sqrt n)
+- [ ] O(n)
+
+
+---
+title: Inserting in min heap pseudocode
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Pseudocode
+```cpp
+heap[];
+heap.insert(val); // inserting at last
+i = heap.size - 1;
+while(i>0){
+ pi = (i-1)/2;
+ if(heap[pi] > heap[i]){
+ swap(heap,pi,i);
+ i=pi;
+ }
+ else
+ {
+ break;
+ }
+}
+```
+
+### Complexity
+**Time Complexity:** O(height of tree) = O(logN)
+
+
+---
+title: Extract Min
+description:
+duration: 1800
+card_type: cue_card
+---
+
+**`Min Heap -`**
+
+
+|0|1|2|3|4|5|6|7|8|
+|-|-|-|-|-|-|-|-|-|
+|2|4|5|11|6|7|8|20|12|
+
+
+In this tree, we have a minimum element at the root. First we swap the first and last elements, then remove the last index element of an array virtually, i.e. consider your array from index 0 to N-2.
+
+
+
+
+
+But the tree is not satisfying the heap-order property. To regain this heap-order property, first check 12, 4 and 5, the minimum is 4, so swap 12 with 4.
+
+ +
+- Now check the index 1(12) value, it greater than index 3(11) and index 4(6), so we need to swap this value with the minimum of left and right child i.e. 6.
+
+
+
+- Now check the index 1(12) value, it greater than index 3(11) and index 4(6), so we need to swap this value with the minimum of left and right child i.e. 6.
+
+ +
+- Now index 4(12) does not have any child, so we will stop here. **`Now the heap-order property is regained.`**
+
+
+
+**`NOTE to Instructor: Perform extract-min again for more clarity on above tree.`**
+
+
+### Pseudocode
+```cpp
+swap(heap, 0, heap-size()-1)
+heap.remove(heap.size()-1)
+heapify(heap[], 0);
+
+void heapify(heap[], i ) {
+ while (2i+1 < N) { //need to handle the edge case when left child is there but not the right child
+ x = min (heap [i], heap [2i+1], heap [2i+2])
+
+ if (x == heap[i]) {
+ break
+ }
+ else if (x == heap[2i+1]){
+ swap (heap, i, 2i+1)
+ i = 2i+1
+ }
+ else{
+ swap (heap, i, 2i+2)
+ i = 2i+2
+ }
+ }
+}
+```
+
+
+### Complexity
+**Time Complexity:** O(log N)
+
+
+---
+title: Build a heap
+description:
+duration: 1800
+card_type: cue_card
+---
+
+### Build a heap
+
+We have an array of values, we want to make a heap of it.
+**`[5, 13, -2, 11, 27, 31, 0, 19]`**
+
+### Idea 1
+Sort the array.
+[-2, 0, 5, 11, 13, 19, 27, 31]
+
+Looking at the tree below, we can see this is a heap.
+
+
+
+- Now index 4(12) does not have any child, so we will stop here. **`Now the heap-order property is regained.`**
+
+
+
+**`NOTE to Instructor: Perform extract-min again for more clarity on above tree.`**
+
+
+### Pseudocode
+```cpp
+swap(heap, 0, heap-size()-1)
+heap.remove(heap.size()-1)
+heapify(heap[], 0);
+
+void heapify(heap[], i ) {
+ while (2i+1 < N) { //need to handle the edge case when left child is there but not the right child
+ x = min (heap [i], heap [2i+1], heap [2i+2])
+
+ if (x == heap[i]) {
+ break
+ }
+ else if (x == heap[2i+1]){
+ swap (heap, i, 2i+1)
+ i = 2i+1
+ }
+ else{
+ swap (heap, i, 2i+2)
+ i = 2i+2
+ }
+ }
+}
+```
+
+
+### Complexity
+**Time Complexity:** O(log N)
+
+
+---
+title: Build a heap
+description:
+duration: 1800
+card_type: cue_card
+---
+
+### Build a heap
+
+We have an array of values, we want to make a heap of it.
+**`[5, 13, -2, 11, 27, 31, 0, 19]`**
+
+### Idea 1
+Sort the array.
+[-2, 0, 5, 11, 13, 19, 27, 31]
+
+Looking at the tree below, we can see this is a heap.
+
+ +
+
+**`Time Complexity: O(N * logN)`**
+
+
+### Idea 2
+Call insert(arr[i]) for every element of an array.
+
+**Explanation:**
+When insert(val) is called, at every insert we shall make sure heap property is being satisfied.
+
+It will take N * logN, as for each element, we will take O(log N) as heapify shall be called.
+
+**`Time Complexity:O(N * logN)`**
+
+---
+title: Build a heap Idea 3
+description: Idea to build the heap in linear time
+duration: 1800
+card_type: cue_card
+---
+
+### Idea to build in linear time
+
+We have an array
+**`[7, 3, 5, 1, 6, 8, 10, 2, 13, 14, -2]`**
+
+We can represent this array in the form of a tree.
+
+
+
+
+**`Time Complexity: O(N * logN)`**
+
+
+### Idea 2
+Call insert(arr[i]) for every element of an array.
+
+**Explanation:**
+When insert(val) is called, at every insert we shall make sure heap property is being satisfied.
+
+It will take N * logN, as for each element, we will take O(log N) as heapify shall be called.
+
+**`Time Complexity:O(N * logN)`**
+
+---
+title: Build a heap Idea 3
+description: Idea to build the heap in linear time
+duration: 1800
+card_type: cue_card
+---
+
+### Idea to build in linear time
+
+We have an array
+**`[7, 3, 5, 1, 6, 8, 10, 2, 13, 14, -2]`**
+
+We can represent this array in the form of a tree.
+
+ +
+- In the above tree, the heap-order property is automatically valid for the leaf node, hence no need to heapify them.
+- Rather, we shall start with the first non-leaf node.
+- The first non-leaf is nothing but the parent of the last leaf node of the tree and the index of the last node is $n-1$, so the index of the first non-leaf is $((n-1-1)/2)=((n-2)/2)=(n/2)-1$.
+- We will call heapify() starting from for $(n/2)-1$ index to index 0.
+
+```cpp=
+for(int i = (n/2)-1; i >= 0 ;i--){
+ heapify(heap[], i);
+}
+```
+
+
+- Firstly it will call for i = 4(6), `heapfiy(heap[], 4)`, minimum of 6, 14, -2 is -2 so 6 and -2 will be swapped.
+
+
+- In the above tree, the heap-order property is automatically valid for the leaf node, hence no need to heapify them.
+- Rather, we shall start with the first non-leaf node.
+- The first non-leaf is nothing but the parent of the last leaf node of the tree and the index of the last node is $n-1$, so the index of the first non-leaf is $((n-1-1)/2)=((n-2)/2)=(n/2)-1$.
+- We will call heapify() starting from for $(n/2)-1$ index to index 0.
+
+```cpp=
+for(int i = (n/2)-1; i >= 0 ;i--){
+ heapify(heap[], i);
+}
+```
+
+
+- Firstly it will call for i = 4(6), `heapfiy(heap[], 4)`, minimum of 6, 14, -2 is -2 so 6 and -2 will be swapped.
+ +
+ - Now 6 does not have any children so we will stop here.
+
+- Call heapify for i = 3(1), now we will check minimum of 1, 2, 13 is 1, so here min-heap property is already satisfied.
+
+- Call heapify for i = 2(5), minimum of 5, 8, 10 is 5 and it is at index 2, so here min-heap property is already satisfied.
+
+- Call heapify for i = 1, minimum of 3, 1, -2 is -2 and so swap.
+
+
+ - Now 6 does not have any children so we will stop here.
+
+- Call heapify for i = 3(1), now we will check minimum of 1, 2, 13 is 1, so here min-heap property is already satisfied.
+
+- Call heapify for i = 2(5), minimum of 5, 8, 10 is 5 and it is at index 2, so here min-heap property is already satisfied.
+
+- Call heapify for i = 1, minimum of 3, 1, -2 is -2 and so swap.
+ +
+ - Now we will again check for 3, and 3 is less than 14 and 6, so here heap-order property is valid here.
+
+- Call heapify for i = 0, here also heap-order property is not satisfied as -2 is less than 7, so swap.
+
+
+ - Now we will again check for 3, and 3 is less than 14 and 6, so here heap-order property is valid here.
+
+- Call heapify for i = 0, here also heap-order property is not satisfied as -2 is less than 7, so swap.
+ +
+ - Now again check for 7, here minimum of 7, 1 and 3 is 1, so again swap it.
+
+
+ - Now again check for 7, here minimum of 7, 1 and 3 is 1, so again swap it.
+ +
+
+ - Now again check for minimum of 7, 2 and 13 is 2, so again swap it.
+
+
+
+ - Now again check for minimum of 7, 2 and 13 is 2, so again swap it.
+ +
+- Now 7 does not have any child so stop here.
+- Now all the nodes has valid heap-order property.
+
+
+### Time Complexity
+
+
+
+Total Number of elements in tree = N
+Elements at last level = N/2
+
+
+
+- Now 7 does not have any child so stop here.
+- Now all the nodes has valid heap-order property.
+
+
+### Time Complexity
+
+
+
+Total Number of elements in tree = N
+Elements at last level = N/2
+
+ +
+- We are not calling heapify() for the last level(leaf node), So for the leaf node, total swaps are 0.
+- For the last second level, we have N/4 nodes and at maximum, there can be 1 swap for these nodes i.e. with the last level.
+- And maximum swaps for N/8 level nodes 2.
+- Similar, for the root node, maximum swaps can be equal to the height of the tree.
+
+
+
+- We are not calling heapify() for the last level(leaf node), So for the leaf node, total swaps are 0.
+- For the last second level, we have N/4 nodes and at maximum, there can be 1 swap for these nodes i.e. with the last level.
+- And maximum swaps for N/8 level nodes 2.
+- Similar, for the root node, maximum swaps can be equal to the height of the tree.
+
+ +
+
+
+
+
+ +
+Here it is an Arithmetic Geometric progression. We need to find the sum of
+
+
+Here it is an Arithmetic Geometric progression. We need to find the sum of
+ +
+Multiply both sides by 1/2
+
+
+Multiply both sides by 1/2
+ +
+Now subtract the above two equations
+
+
+
+Now subtract the above two equations
+
+ +
+Here we are using the formula of the sum of GP.
+
+And put the value of the sum in this equation
+
+
+Here we are using the formula of the sum of GP.
+
+And put the value of the sum in this equation
+ +
+Then
+(N/2) * 2
+Here both will cancel out with each other and so our overall time complexity for building a heap is **O(N)**
+
+---
+title: Quiz 3
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the time complexity for building a heap with N nodes?
+
+# Choices
+- [ ] O(1)
+- [ ] O(N$^2$)
+- [x] O(N)
+- [ ] O(logN)
+
+
+
+---
+title: Problem 2 Merge N sorted arrays
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Merge N-sorted arrays
+a - [2, 3, 11, 15, 20]
+b - [1, 5, 7, 9]
+c - [0, 2, 4]
+d - [3, 4, 5, 6, 7, 8]
+e - [-2, 5, 10, 20]
+
+We have to merge these sorted arrays.
+
+### Idea
+- If we want to merge two sorted arrays then we need two pointers.
+- If we want to merge three sorted arrays then we need three pointers.
+- If we want to merge N sorted arrays then we need N pointers, in which complexity becomes very high and we need to keep track of N pointers.
+
+---
+title: Quiz 4
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+For merging N sorted arrays, which data structure would be the most efficient for this task ?
+
+# Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Min-Heap
+- [ ] Hash Table
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+A Min-Heap is an efficient data structure choice. The Min-Heap ensures that the smallest element among all the elements in the arrays is always at the front. This allows for constant-time access to the minimum element, making it efficient to extract and merge elements in sorted order.
+
+---
+title: Merge N sorted arrays Solution
+description:
+duration: 300
+card_type: cue_card
+---
+
+
+### Optimized Solution
+- First, we need to compare the 0th index element of every array.
+- Now we use heap here.
+- We will add an index 0 element of every array in the heap, in the form of element value, array number and Index of the element in particular.
+
+
+
+Now take the minimum element and insert it in the resultant array,
+
+- Now insert the next element of the list for which the minimum element is selected, like first, we have taken the fourth list element, so now insert the next element of the fourth list.
+
+
+
+- Now again extract-min() from the heap and insert the next element of that list to which the minimum element belongs.
+- And keep repeating this until we have done with all the elements.
+
+### Time Complexity
+**Time Complexity:** (XlogN)
+Here X is a total number of elements of all arrays.
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 2 Problems.md b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 2 Problems.md
new file mode 100644
index 0000000..6f6eb7b
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 2 Problems.md
@@ -0,0 +1,707 @@
+# Advanced DSA: Heaps 2: Problems
+
+---
+title: Today's content
+description:
+duration: 60
+card_type: cue_card
+---
+
+### Todays Content
+- Heap Sort
+- Kth largest element
+- Sort nearly sorted array
+- Median of stream of integer
+
+
+---
+title: Problem 1 Sort an Array
+description: Sort an array using heap sort
+duration: 120
+card_type: cue_card
+---
+
+### Problem Statement
+We want to sort an array in increasing order using a heap.
+
+**`[Ask Students: How can we do so ?]`**
+
+
+### Idea
+We can use min-heap, and we need to call `extract-min()`/`remove(`) repeatedly many times, `extract-min()` will every time give the minimum element among all the available elements.
+1. Build a min-heap.
+2. `extract-min()` and store the returned value in the `ans` array until all the elements are not deleted.
+
+
+---
+title: Quiz 1
+description: time Complexity to convert an array to a heap
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+
+What is the time Complexity to convert an array to a heap?
+
+# Choices
+
+- [ ] O(1)
+- [ ] O(log n)
+- [x] O(n)
+- [ ] O(nlog(n))
+
+
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Root element in a heap is ?
+
+# Choices
+- [ ] min element of the array
+- [ ] max element of the array
+- [x] either min or max depending upon whether it is min or max heap
+- [ ] random element of the array
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Either min or max depending upon whether it is min or max heap. Min-Heap has minimum element at the root node, where as Max-Heap has maximum element at the root node.
+
+
+
+---
+title: Sort an Array Complexity and Solution Approach
+description: Sort an array using heap sort continued
+duration: 900
+card_type: cue_card
+---
+
+### Complexity of sorting an array using heap
+1. Build a min-heap -> **Complexity:** `O(n)`
+2. `extract-min()` and store the returned value in the `ans` array until all the elements are not deleted.
+3. Complexity of `extract-min()` is `O(logn)` and we are calling `N` times, so the overall complexity is `O(NlogN)`.
+
+### Complexity
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(N), as we are using another array for building the heap.
+
+### Can we optimize the space complexity?
+
+**`Hint: Try to solve by using `max-heap`.`**
+
+- Let us take an example of `max-heap`
+
+>
+
+- Create an array for this max-heap.
+
+>
+
+- Say, we extract an element, which element will we get? The Maximum!
+Now, the maximum element can be swapped with the last index. This way, maximum element will come at its correct position in sorted array.
+
+>
+
+- Now we will virtually remove the last element, which means we consider an array till the second last element of an array.
+
+- Now, since the tree is not satisfying the heap order property, so we will call `heapify()` for index 0.
+
+- So when we call `heapify()`, firstly 3 is swapped with 13(maximum of 13 and 10).
+
+>
+
+- Now again 3 is swapped with 7.
+
+>
+
+- Now 3 is the maximum among 3, 2 and 1. Hence, no further swaps are needed.
+Now we have an array,
+
+>
+
+- As we know now a maximum of all available elements is present at root, call `extract-max()`, swap maximum element with the last index element(index 8) and then we will call heapify for the value 1.
+
+>
+
+- 1 is swapped with 10, then swapped with 8, after that 1 will reach to its correct position.
+
+>
+
+- Again extract the maximum and swap it with the last(7th) index element. Then call Heapify for it.
+
+In this way, repeat these steps we completed with all the elements of the tree.
+
+
+---
+title: Sort an Array PseudoCode
+description: Pseudo code for Sort an array using heap sort
+duration: 600
+card_type: cue_card
+---
+
+### PseudoCode
+```cpp=
+Build max-heap ---> TC:O(N)
+j = N - 1;
+while(j > 0){
+ swap(A[0], A[j]);
+ j--;
+ heapify(0, arr[], j)
+}
+```
+
+### Complexity
+
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(1), we are not taking an extra array, we are converting the max heap into sorted array.
+
+
+### Is heap sort an in-place sorting algorithm?
+**Answer:** Yes it is in-place as we are sorting an array using heap sort in constant time in the above question.
+
+### Is heap sort a stable sorting algorithm?
+**Answer:** No heap sort is not stable.
+**Explanation:** Heap sort is not stable because operations in the heap can change the relative order of equivalent keys.
+
+---
+title: Problem 2 kth Largest Element
+description: Find a kth largest element in an array
+duration: 300
+card_type: cue_card
+---
+
+### Problem Statement
+Given arr[N], find the kth largest element.
+
+
+### Example
+**Input:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
+
+
+**Output:**
+7
+
+**Explanation:**
+In the above array,
+- First largest element = 9
+- Second largest element = 8
+- Third largest element = 7
+
+We need to return the third largest element.
+
+
+---
+title: Quiz 3
+description: Find kth largest element in an array
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the 5th largest element of an array `[1, 2, 3, 4, 5]`?
+
+# Choices
+
+- [ ] 5
+- [ ] 3
+- [x] 1
+- [ ] 2
+
+
+---
+title: Quiz 3 Explanation
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Explanation
+In the above array,
+- First largest element = 5
+- Second largest element = 4
+- Third largest element = 3
+- Fourth largest element = 2
+- Fifth largest element = 1
+
+We need to return the fifth largest element.
+
+
+---
+title: kth Largest Element solution approach
+description: Solution for the kth largest element problem
+duration: 600
+card_type: cue_card
+---
+
+### :bulb: Idea 1(by sorting)
+Sort an array and simply return arr[N-K].
+
+**Example:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
+
+**Solution**
+Sort an array, [1, 2, 4, 5, 7, 8, 9]
+Now return arr[N-K] element i.e. arr[7-3] = arr[4] = 7
+
+**Time Complexity:** O(NlogN), **Space Complexity:** O(1).
+
+### :bulb: Idea 2(Using binary search)
+
+We can find the kth largest element by applying binary search just like we have used in the kth smallest element.
+**Time Complexity:** O(Nlog(max-min))
+
+### :bulb: Idea 3(Using heap sort)
+
+1. Build a max-heap.
+2. Call extract-max() k-1 times to remove K-1 elements(for first largest we need zero removals, for second largest we need 1 removal, in this way for kth largest we need k-1 removals)
+
+### Complexity
+**Time Complexity:** O(N + KlogN)
+**Space Complexity:** O(1)
+
+---
+title: kth Largest Element Using min-heap
+description:
+duration: 1200
+card_type: cue_card
+---
+
+### :bulb: Idea 4(Using min-heap)
+
+Let us take an example, we want to create a cricket team of 4 batsmen and we have 8 batsmen i.e. b1, b2, b3, b4, b5, b6, b7 and b8, and every batsman is given only 1 over and everyone tries to achieve maximum run in that over.
+
+Firstly, 4 batsmen played and scored
+|b1|b2|b3|b4|
+|-|-|-|-|
+|12|8|4|6|
+
+We have recently incorporated four batsmen into our team with respective scores of **`12, 8, 4, and 6`**. When batsman **`B5 joins, scoring 7`**, we opt to replace the player with the lowest score to maintain team quality. Since we use a min heap to track scores, we **`remove the batsman with a score of 4 and include B5`**, updating our heap to **[12, 8, 7, 6]**.
+
+Later, batsman **`B6 arrives, earning 3 runs`**. However, his score **`doesn't surpass our team's minimum`**, so he isn't added. Then, batsman **`B7 steps in, scoring a notable 10 runs`**. Outperforming our lowest score, **`B7's addition leads us to drop the current minimum`** scorer and update the heap to **[12, 8, 7, 10]**.
+
+Following this, batsman **`B8 enters with a score of 9`**. Exceeding the lowest score in our lineup, we **`incorporate B8 by removing the now lowest scorer`**, refining our heap to **[12, 8, 9, 10]**.
+
+Thus, in this dynamic team selection process, the minimum element in our heap represents the fourth-highest score among our players.
+
+### Example:
+To find the 3rd largest element in an array using a min-heap of size 3:
+
+Given array: **`arr = [8, 5, 1, 2, 4, 9, 7] and k=3`**.
+
+- Initialize an empty min-heap.
+- Add the first three elements of the array to the heap: [8, 5, 1].
+- Iterate over the remaining elements. If an element is greater than the heap's minimum, remove the minimum and insert the new element.
+- After processing elements 2, 4, 9, and 7, the heap evolves as follows:
+ - [8, 5, 2] (after adding 2)
+ - [8, 5, 4] (after adding 4)
+ - [8, 5, 9] (after adding 9)
+ - [8, 7, 9] (after adding 7)
+- The 3rd largest element is the minimum in the heap: 7.
+
+### PseudoCode
+```cpp=
+Build min-heap with first k elements. -> O(K)
+Iterate on the remaining elements. -> (N-K)
+ for every element, check
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ }
+ans = getMin()
+```
+
+### Complexity
+- **Time Complexity:** O(K+(N-K)logK)
+- **Space Complexity:** O(K)
+
+:bulb: What should we use for finding k-th smallest?
+- A max-heap of size K.
+
+
+---
+title: Problem 2 kth Largest Element for all windows
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+Find the kth largest element for all the windows of an array starting from 0 index.
+
+### Example
+**Input:**
+arr[] = `[10, 18, 7, 5, 16, 19, 3]`
+k = 3
+
+
+**Solution:**
+
+- We need atleast 3 elements in a window, so we will consider first window from index 0 to k-1, we have elements in that `[10, 18, 7]`; third largest is 7, ans=`[7]`.
+- Window 0 to 3 `[10, 18, 7, 5]`,third largest = 7, ans=`[7, 7]`.
+- Window 0 to 4 `[10, 18, 7, 5, 16]`,third largest = 10, ans=`[7, 7, 10]`.
+- Window 0 to 5 `[10, 18, 7, 5, 16, 19]`,third largest = 16, ans=`[7, 7, 10, 16]`.
+- Window 0 to 6 `[10, 18, 7, 5, 16, 19, 3]`,third largest = 16, ans=`[7, 7, 10, 16, 16]`.
+
+---
+title: Quiz 4
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Find the kth largest element for all the windows of an array starting from 0 index.
+
+arr[] = `[5, 4, 1, 6, 7]`
+k = 2
+
+# Choices
+- [x] [4, 4, 5, 6]
+- [ ] [6, 6, 6, 6]
+- [ ] [5, 4, 1, 6]
+- [ ] [4, 1, 6, 7]
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+To find the second largest element in each window of a given size in an array:
+
+- Start with the first window (from index 0 to k-1). For example, in [5, 4], the second largest is 4. Answer array starts as [4].
+- Shift the window one element at a time and find the second largest in each new window.
+ - Window [5, 4, 1] gives second largest 4. Answer array becomes [4, 4].
+ - Window [5, 4, 1, 6] gives second largest 5. Answer array becomes [4, 4, 5].
+ - Window [5, 4, 1, 6, 7] gives second largest 6. Answer array becomes [4, 4, 5, 6].
+
+---
+title: kth Largest Element for all windows Idea
+description:
+duration: 900
+card_type: cue_card
+---
+To find the k-largest elements in an array using a min-heap:
+
+- **Initialize Min-Heap**: Start with a min-heap and add the first k elements from the array to it.
+- **Compare and Update**: For each remaining array element, if it's larger than the heap's minimum, replace the minimum with this element.
+- **Track Minimums**: After each update, record the heap's minimum. This shows the evolving k-th largest element.
+
+### Pseudocode
+```java
+Build min-heap with first K elements. -> O(K)
+ans.add(extractMin())
+
+Iterate on the remaining elements. -> (N-K)
+ for every element, check {
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ ans.add(extractMin())
+ }
+ }
+```
+
+---
+title: Problem 3 Sort the nearly sorted array
+description:
+duration: 1200
+card_type: cue_card
+---
+
+### Problem Statement
+Given a nearly sorted array. You need to sort the array.
+
+> Nearly sorted array definition - Every element is shifted away from its correct position by at most k-steps.
+
+### Example
+Sorted array can be `[11, 13, 20, 22, 31, 45, 48, 50, 60]`
+We are given,
+**Input:**
+arr[] = `[13, 22, 31, 45, 11, 20, 48, 60, 50]`
+k = 4
+
+Every element is not more than 4 distance away from its position.
+
+### :bulb: Idea 1(Sorting)
+Sort an Array
+**Time Complexity:** O(NlogN)
+
+### :bulb: Idea 2
+
+An element can be shifted by at most k steps, so the **`element at index 0 can only be shifted till index (k)`**, so the **`minimum element lies from index 0 to k`**.
+- So we need to choose a minimum of first k+1 elements.
+- We will take a min-heap of size k+1.
+- Add first k+1 elements into a heap, heap = `[13, 22, 31, 45, 11]`.
+- extractMin()(heap = `[13, 22, 31, 45]`) will give a first element of a sorted array, ans = `[11]`, now add the next element from an input array, into a heap, heap = `[13, 22, 31, 45, 20]`.
+- Again extractMin(), it will give a second of a sorted array, ans = `[11, 13]`, again add the next element of the input array, again extractMin(), in this way do until we reach the last index, and then remove minimum element from array one-by-one and add it to ans array.
+
+
+### PseudoCode
+```cpp
+1. build min-heap with the first (k + 1) elements.
+2. for(i = k + 1 ; i < N ; i ++){
+ extractMin(); -> put it into ans[] array
+ insert( arr[i] )
+ }
+ while(minHeap is not empty){
+ extractMin() -> put it into ans[] array
+ }
+3. return ans;
+```
+
+### Compexity
+**Time Complexity:** O(K + N.logK)
+**Space Complexity:** O(K)
+
+
+---
+title: Flipkart's Delivery Time Estimation Challenge
+description:
+duration: 120
+card_type: cue_card
+---
+
+*Flipkart is currently dealing with the difficulty of precisely estimating and displaying the expected delivery time for orders to a specific pin code.*
+
+*The existing method relies on historical delivery time data for that pin code, using the median value as the expected delivery time.*
+
+*As the order history expands with new entries, Flipkart aims to enhance this process by dynamically updating the expected delivery time whenever a new delivery time is added. The objective is to find the expected delivery time after each new element is incorporated into the list of delivery times.*
+
+**End Goal:** With every addition of new delivery time, requirement is to find the median value.
+
+**Why Median ?**
+The median is calculated because it provides a more robust measure of the expected delivery time
+
+The median is less sensitive to outliers or extreme values than the mean. In the context of delivery times, this is crucial because occasional delays or unusually fast deliveries (outliers) can skew the mean significantly, leading to inaccurate estimations.
+
+---
+title: Problem 4 Find the median
+description:
+duration: 120
+card_type: cue_card
+---
+
+### Problem Statement
+Given an infinite stream of integers. Find the median of the current set of elements
+
+>### Median
+>Median is the Middle element in a sorted array.
+
+>The median of [1, 2, 5, 4, 3, 6]
+First, we need to sort an array [1, 2, 3, 4, 5, 6]
+We have two middle values as the size of the array is even i.e. 3, 4.
+So to find the median, we need to take the average of both middle values, median = (3+4)/2 = 3.5
+
+---
+title: Quiz 5
+description: Median of the given array
+duration: 60
+card_type: quiz_card
+---
+
+
+# Question
+
+The median of [1, 2, 4, 3]
+
+# Choices
+
+- [ ] 2
+- [ ] 4
+- [ ] 3
+- [x] 2.5
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The median of [1, 2, 4, 3]
+First, we need to sort an array [1, 2, 3, 4]
+We have two middle values as the size of the array is even i.e. 2, 3.
+So to find the median, we need to take the average of both middle values,
+
+Median = (2+3)/2 = 2.5
+
+
+
+---
+title: Find the median Brute Force Approach
+description:
+duration: 600
+card_type: cue_card
+---
+
+
+### Understanding the question
+We have an infinite stream of elements.
+1. First we have one element.
+6, then median = 6.
+2. Next element if 3
+6, 3, then median = 4.5
+3. 6, 3, 8, then median = 6
+4. 6, 3, 8, 11, then median = 7
+5. 6, 3, 8, 11, 10 then median = 8
+
+
+### Brute Force Idea
+For every incoming value, include the value and sort an array. Find the middle point/average of 2 middle points.
+**Time Complexity:** O(N^2^logN)
+
+
+---
+title: Find the median solution approach
+description:
+duration: 1200
+card_type: cue_card
+---
+
+### Idea(Using Insertion Sort)
+Every time find the correct position of the upcoming element i.e. Insertion Sort
+
+**Time Complexity:** O(N^2^)
+
+### Idea(Using heap)
+
+To find the median in an array by dividing it into two parts - one with smaller elements and the other with larger elements:
+
+Consider an array, **`for example, [6, 3, 8, 11]`**. We divide it such that **`6, 3 are on the smaller side`** and **`8, 11 on the larger side`**, as shown in the image:
+
+
+To find the median:
+
+- If both sides have an equal number of elements, take the average of the largest element on the smaller side and the smallest element on the larger side.
+- If the sizes are unequal, choose the largest element from the smaller side if it's larger, or the smallest from the larger side otherwise.
+
+**The key is to use two heaps:** a min-heap for the larger elements and a max-heap for the smaller elements. This approach maintains a balanced partition of the array for efficient median calculation.
+
+### Example
+arr = [6, 3, 8, 11, 20, 2, 10, 8, 13, 50, _ _ _ ]
+
+Take two heaps, min-heap and max-heap
+
+
+Smaller side elements are stored in max-heap and Greater side elements are stored in min-heap
+
+
+1. First element is 6, simply add it in max-heap
+
+**The median is 6.**
+
+
+2. Second element is 3; compare with h1.getMax(), if 3<6 then it must be included in h1.
+
+but now both the heaps do not have half-half elements. Remove the maximum element from max-heap and insert it into h2.
+
+Now we have an equal number of elements in both heaps, so the median is the average of the largest value of h1 and the smallest value of h2.
+**Median is 4.5**
+
+
+3. Next element is 8.
+Compare it with h1.getMax(), 8>3 so 8 will go to h2.
+
+size(h2) is greater by 1
+**Median is 6**
+
+
+4. Next element is 11.
+Compare it with h1.getMax(), 11>3 so 11 will go to h2.
+
+But now both heap does not have nearly half elements.
+So remove the minimum element and add it to h1.
+
+**Median is average of 6,8 = (6+8)/2 = 7**
+
+
+5. Next element is 20.
+Compare it with h1.getMax(), 20>6 so 20 will go to h2.
+
+size(h2) is greater by 1
+**The median is 8.**
+
+In this way we will do for all the elements of an array, and find the median at every step, we need to take care that the |h1.size()-h2.size()|<=1.
+
+After adding all the medians in an array, we will get an answer: [6, 4.5, 6, 7, 8, 7, 8, 8, 8, _ _ _ ]
+
+
+---
+title: Find the median pseudocode
+description:
+duration: 600
+card_type: cue_card
+---
+
+### PseudoCode
+```cpp
+ h1, h2
+ h1.insert(arr[0])
+ print(arr[0])
+ for(int i = 1 ; i < N ; i++){
+ if(arr[i] > h1.getMax()){
+ h2.insert(arr[i]);
+ }
+ else{
+ h1.insert(arr[i]);
+ }
+ diff = |h1.size() - h2.size()|
+ if(diff > 1){
+ if(h1.size() > h2.size()) {
+ h2.insert(h1.getMax());
+ }
+ else {
+ h1.insert(h2.getMin());
+ }
+ }
+ if(h1.size() > h2.size()){
+ print(h1.getMax());
+ }
+ else if(h2.size() > h1.size()){
+ print(h2.getMin())
+ }
+ else{
+ print((h1.getMax() + h2.getMin()) / 2.0);
+ }
+ }
+```
+
+### Complexity
+
+**Time Complexity:** O(NlogN)
+**Space Complexity:** O(N)
+
+---
+title: Contest Information
+description:
+duration: 900
+card_type: cue_card
+---
+
+Next contest syllabus includes - **"Trees, Heaps and Greedy"**. We are already done with **Trees** and **Heaps**, kindly make sure we are done with their problems at the earliest.
+
+If you haven't done any yet, then make sure we are atleast done with assignments.
diff --git a/Non-DSA Notes/Backend Project Java Notes/AWS Elastic Beanstalk (EBS), Amazon RDS, Environment Variables, and Product Service Deployment.md b/Non-DSA Notes/Backend Project Java Notes/AWS Elastic Beanstalk (EBS), Amazon RDS, Environment Variables, and Product Service Deployment.md
new file mode 100644
index 0000000..1b2d722
--- /dev/null
+++ b/Non-DSA Notes/Backend Project Java Notes/AWS Elastic Beanstalk (EBS), Amazon RDS, Environment Variables, and Product Service Deployment.md
@@ -0,0 +1,215 @@
+## Topics to be Covered
+
+- **Elastic Beanstalk (EBS)**
+- **Amazon Relational Database Service (RDS)**
+- **Environment Variablesuct Service Deployment**
+
+---
+
+## Elastic Beanstalk (EBS)
+
+### Overview of EC2 and the Need for EBS
+
+EC2 instances are virtual servers in the AWS cloud. EC2 provides the raw compute power needed to run applications, but managing these instances, especially as your application grows, can become complex. Tasks such as load balancing, scaling, and handling failures require constant attention.
+
+This is where **Elastic Beanstalk (EBS)** comes into play. EBS is an orchestration service that abstracts the complexities of deploying and managing applications by automatically handling infrastructure provisioning, load balancing, scaling, and application health monitoring.
+
+### How EBS Simplifies Application Management
+
+EBS acts as a manager for your application deployment. It orchestrates various AWS services to ensure your application remains available and performs optimally with minimal manual intervention. The main features of EBS include:
+
+- **Server Management:** EBS automatically manages the number of servers (EC2 instances) needed based on the current load. It can add or remove instances as needed.
+- **Load Balancing:** EBS integrates with an Elastic Load Balancer (ELB), which distributes incoming traffic across multiple EC2 instances. This ensures that your application can handle varying amounts of traffic without downtime. The client only needs to know the IP address of the load balancer, which simplifies the networking aspect.
+- **Application Deployment:** EBS takes care of deploying your application code to the servers, managing the deployment process and handling any necessary updates.
+
+### Practical Example: Deploying a Java Application
+
+To illustrate how EBS works, let's consider deploying a Java-based application called "Product Service." Java is a compiled language, meaning the source code needs to be compiled into bytecode before it can be executed. This bytecode is typically packaged into a `.jar` (Java ARchive) file.
+
+#### Step 1: Compiling the Java Code
+First, we compile our Java code to generate the `.jar` file. This file is the deployable artifact that contains all the classes and resources needed to run the application.
+
+- **Visual Aid:**
+ - **Compilation Process:** 
+ - **Generated `.jar` File:** 
+
+**Instructor Note:** Discuss the significance of the `.jar` file, including how it's named and structured.
+
+#### Step 2: Running the `.jar` File
+Once the `.jar` file is generated, it can be executed on any machine with the Java Runtime Environment (JRE) installed. The command to run the `.jar` file is:
+
+```bash
+java -jar name-of-jar.jar
+```
+
+### What EBS Manages Behind the Scenes
+
+When deploying this application using EBS, the service takes over several critical tasks:
+
+- **Server Scaling:** EBS determines when to add or remove EC2 instances based on traffic patterns.
+- **Load Balancing:** It routes incoming requests through a load balancer to the appropriate EC2 instance.
+- **Monitoring and Logging:** EBS monitors the health of your application and logs any issues, providing you with real-time feedback.
+
+This orchestration significantly reduces the workload for developers and operators, allowing them to focus on developing new features rather than managing infrastructure.
+
+---
+
+## Amazon RDS (Relational Database Service)
+
+### Introduction to RDS
+
+Amazon RDS (Relational Database Service) is a managed database service that simplifies the setup, operation, and scaling of relational databases in the cloud. RDS handles routine database tasks such as provisioning, patching, backup, recovery, and scaling, allowing you to focus on your application rather than database management.
+
+### Why Use RDS?
+
+Managing a database involves several time-consuming tasks, including:
+
+- **Installation and Setup:** Configuring the database software on a server.
+- **Backups and Recovery:** Ensuring that data is regularly backed up and can be restored in case of failure.
+- **Patching and Updates:** Keeping the database software up to date with the latest patches.
+- **Scaling:** Adjusting the database's capacity to handle increasing loads.
+
+RDS automates all these tasks, offering a fully managed experience where you only need to specify the type and size of the database, and RDS handles the rest.
+
+### Deploying a Database with RDS
+
+To integrate our product service with a database, we'll use Amazon RDS to deploy a MySQL database.
+
+#### Step 1: Creating the Database
+Using the AWS Management Console, we can create a new RDS instance by specifying the database engine, version, and instance size. We also have the option to enable features such as **auto-scaling** to automatically adjust the database's capacity based on demand.
+
+- **Visual Aid:**
+ - **RDS Creation Interface:** 
+ - **Auto-Scaling Configuration:** 
+
+**Instructor Note:** Walk through the process of creating an RDS instance, highlighting options like maintenance settings and disk encryption for added security.
+
+#### Step 2: Configuring Database Access
+Security is a critical aspect of database management. With RDS, you can configure the database to accept connections only from specific EC2 instances, ensuring that unauthorized access is prevented even if credentials are compromised.
+
+- **Security Configuration:** Specify that only the servers within your VPC (Virtual Private Cloud) can access the database. This adds an extra layer of security.
+
+#### Step 3: Connecting to the Database from a Spring Application
+After the database is set up, we need to connect it to our Java application. This is done by updating the `application.properties` file with the database URL and credentials.
+
+```java
+spring.datasource.url=jdbc:mysql://localhost:3306/productservicedecmwfeve
+spring.datasource.username=${PRODUCT_SERVICE_DATABASE_USERNAME}
+spring.datasource.password=${PRODUCT_SERVICE_DATABASE_PASSWORD}
+```
+
+By using environment variables (as we'll discuss next), we can avoid hardcoding sensitive information directly into the application code.
+
+---
+
+## Environment Variables
+
+### Importance of Environment Variables
+
+Environment variables are key-value pairs stored at the operating system level that applications can use to retrieve configuration information. This method of configuration management offers several advantages, particularly in terms of security and flexibility.
+
+#### Security Benefits
+Hardcoding sensitive information such as database URLs, usernames, and passwords directly into your application's source code is a risky practice. If the code is ever compromised, these credentials could be exposed to attackers. By using environment variables, sensitive information is stored separately from the code, reducing the risk of exposure.
+
+#### Flexibility in Different Environments
+Applications often need to run in different environments, such as development, testing, and production. Each environment may require different configuration settings, such as database URLs or API keys. By using environment variables, you can easily change the configuration based on the environment without modifying the code.
+
+### Example Configuration in `application.properties`
+
+Here is an example of how environment variables can be used in a Spring application to configure database access and other settings:
+
+```java
+spring.datasource.url=${PRODUCT_SERVICE_DATABASE_URL}
+spring.datasource.username=${PRODUCT_SERVICE_DATABASE_USERNAME}
+spring.datasource.password=${PRODUCT_SERVICE_DATABASE_PASSWORD}
+spring.security.oauth2.resourceserver.jwt.issuer-uri=${USER_SERVICE_URL}
+```
+
+In this setup:
+- The actual values for `PRODUCT_SERVICE_DATABASE_URL`, `PRODUCT_SERVICE_DATABASE_USERNAME`, and `PRODUCT_SERVICE_DATABASE_PASSWORD` are stored as environment variables.
+- The application retrieves these values at runtime, ensuring that sensitive information is not exposed in the source code.
+
+This approach not only enhances security but also makes it easier to manage different configurations for different environments.
+
+---
+
+## Product Service Deployment
+
+### Preparing for Deployment
+
+Now that we have our `.jar` file ready and our database deployed on RDS, we can proceed with deploying the Product Service using Elastic Beanstalk.
+
+#### Step 1: Create the Elastic Beanstalk Environment
+
+1. **Choosing the Environment Type:**
+ - Elastic Beanstalk supports multiple environment types, such as single-instance or load-balanced environments. For our service, we may choose a load-balanced environment to handle high traffic.
+
+ - **Visual Aid:**
+ - **Environment Selection:** 
+
+2. **Uploading the Application Code:**
+ - Upload the compiled `.jar` file to Elastic Beanstalk. EBS will handle the deployment process, including creating EC2 instances and configuring the necessary resources.
+
+#### Step 2: Configuring Permissions and Roles
+
+EBS relies on other AWS services to function, such as EC2 for running the application and RDS for database connectivity. To interact with these services securely, EBS requires specific permissions, which are granted through **service roles**.
+
+- **Creating a Service Role:**
+ - A service role is an IAM role that grants permissions to AWS services so they can interact with other AWS resources. In this case, we need to create
+
+ a service role that allows EBS to manage EC2 instances, access the RDS database, and configure the load balancer.
+
+- **Assigning the Service Role to EBS:**
+ - Once the service role is created and the necessary permissions are granted, it is assigned to the EBS environment.
+
+- **Visual Aid:**
+ - **Service Role Configuration:** 
+
+
+
+#### Step 3: Configuring Auto-Scaling and Monitoring
+
+EBS provides several advanced features for managing the scalability and health of your application:
+
+- **Auto-Scaling Groups:**
+ - Auto-scaling ensures that your application can handle varying levels of traffic by automatically adjusting the number of EC2 instances. For example, you can set a policy to add more instances if CPU utilization exceeds 70% and reduce instances if it drops below 40%.
+
+- **Visual Aid:**
+ - **Auto-Scaling Example:** 
+
+- **Monitoring:**
+ - EBS continuously monitors the health of your application and the underlying infrastructure. It provides detailed logs and metrics that help you identify and resolve issues quickly.
+
+#### Step 4: Configuring Listener Ports
+
+The load balancer in EBS routes incoming traffic to the appropriate EC2 instances. The configuration of listener ports is crucial to ensure that the traffic is correctly directed:
+
+- **Listener Port Configuration:**
+ - Typically, the load balancer listens on port 80 (HTTP) or 443 (HTTPS). However, the application may run on a different port (e.g., 8283). EBS allows you to map the incoming traffic on port 80 to the application's port.
+
+- **Visual Aid:**
+ - **Listener Ports Configuration:** 
+
+#### Step 5: Deployment Strategies
+
+Elastic Beanstalk offers several deployment strategies, including:
+
+- **All-at-once:** Deploys the new version of the application to all instances simultaneously.
+- **Rolling Updates:** Deploys the new version gradually, ensuring that some instances remain operational during the deployment.
+
+Choose the strategy that best suits your application's needs.
+
+#### Step 6: Setting Environment Variables
+
+Finally, configure any necessary environment variables at the OS level within the EBS environment. This ensures that sensitive information, such as database credentials, is securely managed.
+
+- **Visual Aid:**
+ - **Environment Variables Configuration:** 
+
+### Monitoring the Deployment Process
+
+Once the deployment starts, EBS provides real-time feedback on the progress and any events that occur during the process. This includes the creation of resources, status updates, and any errors that might arise.
+
+- **Visual Aid:**
+ - **Deployment Events:** 
+
diff --git a/Non-DSA Notes/Backend Project Java Notes/AWS III.md b/Non-DSA Notes/Backend Project Java Notes/AWS III.md
new file mode 100644
index 0000000..7a711c9
--- /dev/null
+++ b/Non-DSA Notes/Backend Project Java Notes/AWS III.md
@@ -0,0 +1,199 @@
+## Topics to be covered
+
+
+1. **User Service Deployment**
+2. **Virtual Private Cloud (VPC) and Security Groups**
+3. **Health Status Monitoring**
+4. **Deploying on Custom Domains**
+
+---
+
+## User Service Deployment
+
+### Steps for Deployment:
+
+1. **Deploy the Database**:
+ - Begin by setting up the database that the user service will utilize. This involves configuring a relational database, such as MySQL or PostgreSQL, within AWS RDS (Relational Database Service). Ensure the database is correctly provisioned with appropriate settings, including instance type, storage capacity, and backup configurations.
+
+2. **Update Application Properties**:
+ - The next step is to modify the `application.properties` file of the user-service to point to the newly deployed database. This file should include the database URL, username, password, and any additional settings required by the service.
+ - Once updated, create a Java Archive (JAR) package of the user-service. This package will include all necessary libraries, resources, and metadata required for deployment.
+
+3. **Create a New Elastic Beanstalk Service (EBS) Environment**:
+ - Set up a new environment in Elastic Beanstalk specifically for the user-service. Elastic Beanstalk automates the deployment, scaling, and management of applications, making it an ideal platform for our service.
+ - Ensure that the environment is configured with the correct platform, such as a Java SE or Tomcat environment, depending on your application.
+
+4. **Configure Elastic Beanstalk**:
+ - Adjust key configurations within Elastic Beanstalk. This includes setting environment variables, configuring load balancers, and defining autoscaling rules.
+ - Pay particular attention to security settings, such as setting up HTTPS for secure communication and managing IAM roles to control access to AWS resources.
+
+5. **Deploy the User Service**:
+ - Finally, deploy the user-service JAR package to Elastic Beanstalk. Once deployed, Elastic Beanstalk will automatically handle the provisioning of resources, including EC2 instances, and will manage the deployment process.
+
+### Post Deployment Actions:
+
+- **Update the Product Service**:
+ - After successfully deploying the user-service, it's crucial to integrate it with the product service. Update the `application.properties` file of the product service to include the URL of the user-service. This ensures that the product service can authenticate and authorize requests via the user-service.
+
+- **Re-deploy the Product Service**:
+ - With the updated configurations, re-deploy the product service to Elastic Beanstalk. This ensures that both services are correctly linked and operational.
+
+```java
+logging.level.org.springframework.web=TRACE
+spring.jpa.hibernate.ddl-auto=validate
+spring.datasource.url=${PRODUCT_SERVICE_DATABASE_URL}
+spring.datasource.username=${PRODUCT_SERVICE_DATABASE_USERNAME}
+spring.datasource.password=${PRODUCT_SERVICE_DATABASE_PASSWORD}
+spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
+spring.jpa.show-sql=true
+spring.security.oauth2.resourceserver.jwt.issuer-uri=${USER_SERVICE_URL}
+logging.level.org.springframework.security.*=TRACE
+logging.level.org.springframework.web.*=TRACE
+server.port=8283
+```
+
+- **Final Outcome**: Both the user-service and product-service should now be fully deployed and functional. This interconnected deployment is a fundamental step in building a robust, microservices-based architecture.
+
+
+
+---
+
+## Virtual Private Cloud (VPC) and Security Groups
+
+### Introduction:
+As our applications grow in complexity, securing the infrastructure becomes increasingly critical. In this section, we will explore how AWS Virtual Private Cloud (VPC) and Security Groups can be used to enhance security by isolating resources and controlling traffic.
+
+### Application Architecture Overview:
+The architecture of our application consists of multiple interconnected services, each with its own database and functionality. These services must be protected from unauthorized access while allowing legitimate communication between them.
+
+
+
+### Security Challenges:
+
+- **Unrestricted Database Access**:
+ - Currently, if someone outside the network has the correct credentials (username, password, and URL), they can access the database directly. This presents a significant security risk, as databases often contain sensitive information.
+
+- **Example Scenario**:
+ - Suppose you attempt to connect to the database using an external tool like IntelliJ. Without proper restrictions, such access is possible, highlighting the need for enhanced security.
+
+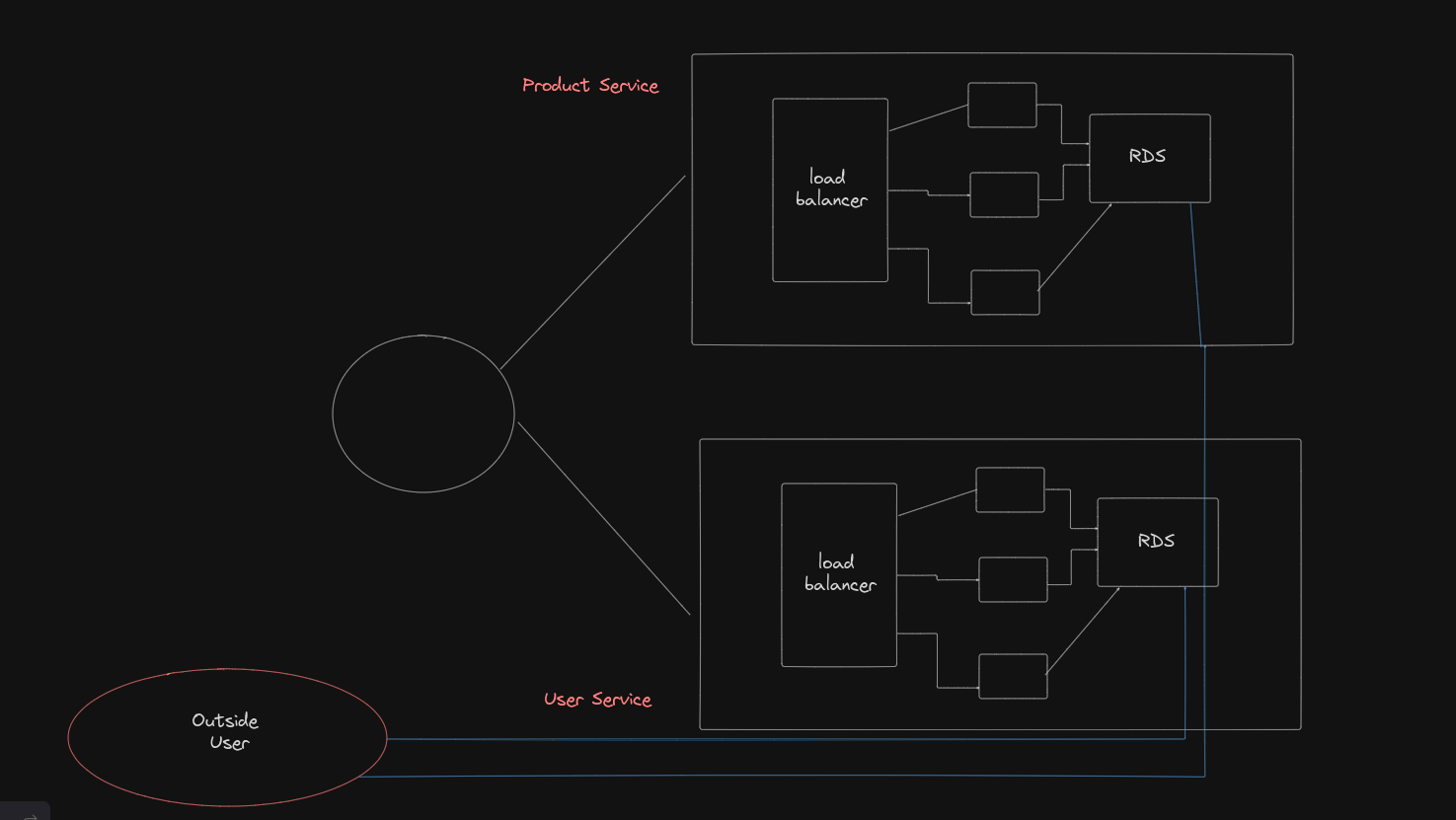
+
+### Solution - Implementing Virtual Private Cloud (VPC):
+
+- **VPC Overview**:
+ - AWS provides a Virtual Private Cloud (VPC) as a means of isolating resources within a virtual network that is logically separated from other AWS customers. By placing services within a VPC, you can control who has access to these services and ensure that only authorized traffic is allowed.
+
+- **Practical Example**:
+ - Imagine AWS as a large city with numerous buildings (services). By creating a VPC, you are essentially constructing a gated community within this city, where only residents (services within the VPC) can interact with each other. External entities must go through strict checkpoints (security groups) to gain access.
+
+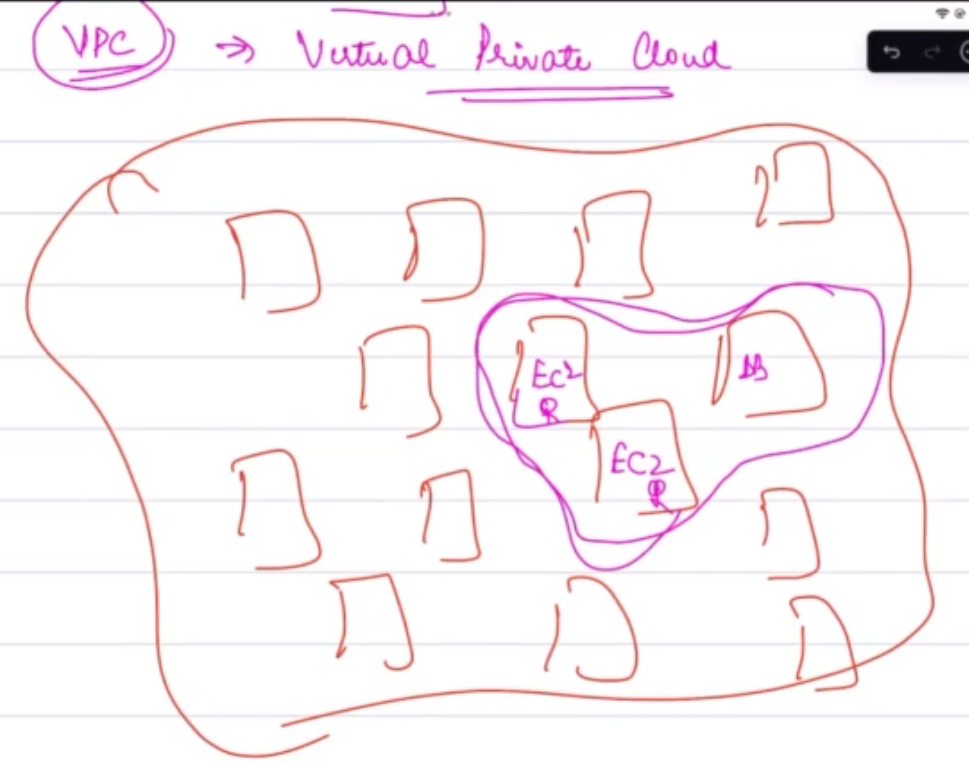
+
+### Enhancing Security with Security Groups:
+
+- **Security Groups**:
+ - Security Groups act as virtual firewalls for your EC2 instances or other AWS resources within a VPC. They consist of a set of rules that define which incoming and outgoing traffic is allowed.
+
+- **Best Practices**:
+ - While AWS provides default security groups, it is recommended to create custom security groups tailored to the specific needs of each service. This avoids potential security issues where changes to a default security group could inadvertently affect multiple services.
+
+- **Example**: Consider our application’s architecture, where the authentication service and the product service each have their own databases. By creating specific security groups, we can ensure that only the authentication service can access its database and similarly for the product service.
+
+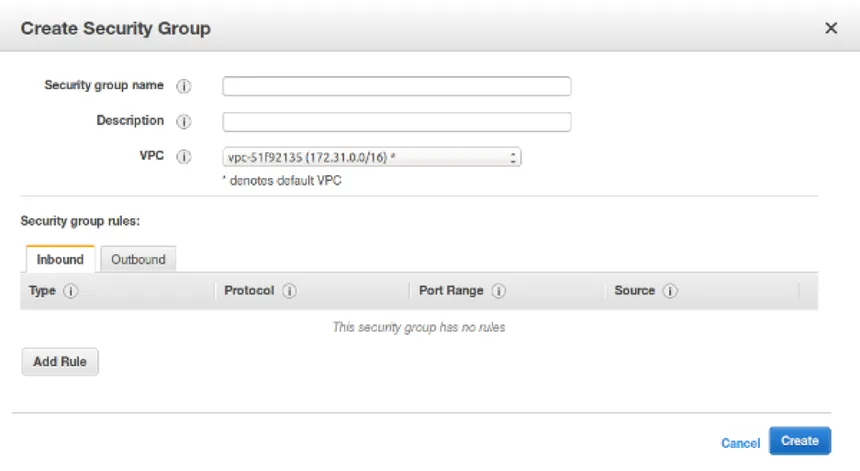
+
+- **Inbound and Outbound Rules**:
+ - **Inbound Rules**: These rules specify which sources (e.g., IP addresses or other services) can send requests to your service.
+ - **Outbound Rules**: These rules determine where your service can send requests, such as to other databases or services within the VPC.
+
+### Application and Testing:
+
+- **Applying Security Groups**:
+ - After setting up the appropriate security groups, apply them to your EC2 instances or other AWS resources. This ensures that only authorized traffic is permitted, greatly enhancing the security of your application.
+
+- **Validation**:
+ - Once the security groups are applied, test the application to confirm that unauthorized external tools (such as IntelliJ) can no longer connect directly to the database. This demonstrates the effectiveness of the security measures.
+
+
+
+---
+
+## Health Status
+
+### Introduction:
+Ensuring the stability of services during updates is critical in a production environment. In this section, we’ll discuss how to implement health status checks in AWS Elastic Beanstalk to monitor the health of services during and after deployment.
+
+### Rolling Deployment Overview:
+
+- **Rolling Deployment Process**:
+ - When deploying an update to a service, AWS Elastic Beanstalk uses a rolling deployment strategy. This strategy involves gradually updating instances behind a load balancer to ensure minimal downtime. The steps include:
+ 1. The load balancer takes one server offline.
+ 2. The new version of the service is deployed on that server.
+ 3. The server is checked to ensure it is functioning correctly.
+ 4. The server is brought back online and reconnected to the load balancer.
+
+
+### Health Status Checks:
+
+- **Purpose**:
+ - Health status checks are automated tests that Elastic Beanstalk uses to verify that a server is healthy after an update. These checks are critical to prevent issues like service outages or degraded performance.
+
+- **Configuration**:
+ - Elastic Beanstalk allows you to configure health checks by specifying a URL endpoint that it should monitor. The health check continuously sends HTTP requests to this endpoint and expects a 200 status code as a sign of success.
+
+- **Example**:
+ - You can configure the health check to send a request every 5 seconds to the root path (`/`) and expect a 200 status code. If this condition is met five times in a row, the server is considered healthy, and the deployment can proceed.
+
+
+
+- **Detailed Example**:
+ - Suppose the health check configuration is set as follows:
+ - **Path**: `/`
+ - **Interval**: 5 seconds
+ - **Timeout**: 5 seconds
+ - **Healthy Threshold**: 5 times
+
+ This configuration instructs Elastic Beanstalk to ensure the service responds with a 200 status code at the specified intervals before declaring the server healthy.
+
+For better clarity you can refer to the documanetation [Spring Boot Actuator ](https://spring.io/guides/gs/actuator-service) .
+
+---
+
+## Deploy on Custom Domains
+
+### Introduction:
+Using a custom domain name for your services not only improves branding but also makes it easier for users to access and remember your service URLs. In this section, we’ll walk through the process of setting up a custom domain for your AWS-deployed services.
+
+### Steps to Deploy on Custom Domains:
+
+1. **Obtain a Domain Name**:
+ - If you don’t already have a domain name, you can obtain one through various domain registrars. The GitHub Student Developer Pack offers a free domain name for one year through services like **namecheap.com**, **name.com**, or **get.tech**.
+
+2. **Domain Name Settings**:
+ - Once you have your domain, you can manage its settings through the registrar’s website. This includes configuring DNS records, which direct traffic from your domain to specific servers or services.
+
+3. **Configure AWS Route 53**:
+ - AWS Route 53 is a scalable DNS web service designed to route end-user requests to AWS applications efficiently. To use your custom domain with AWS, you need to create a hosted zone in Route 53 and add your domain name to it.
+
+
+
+4. **Set Up Name Servers**:
+ - After setting up Route 53, you will receive name server addresses. These need to be configured in your domain registrar’s settings to ensure that your domain points to the AWS-hosted services.
+
+5. **Understanding Routing Policies**:
+ - Route 53 offers several routing policies to manage how traffic is directed:
+ - **Simple Routing**: Directs traffic to a single resource without health checks.
+ - **Failover Routing**: Routes traffic to a primary resource, and if it fails, to a secondary resource.
+ - **Geolocation Routing**: Routes traffic based on the geographic location of the user.
+ - **Geoproximity Routing**: Routes traffic based on the geographic location of resources and optionally shifts traffic from one resource to another.
+ - **Latency Routing**: Routes traffic to the resource with the lowest latency for the user.
+ - **Multivalue Answer Routing**: Returns multiple IP addresses for a DNS query, with optional health checks.
+ - **Weighted Routing**: Distributes traffic across multiple resources based on specified weights.
+
+6. **Choosing a Routing Policy**:
+ - Depending on your specific use case, select a routing policy that best suits your needs. For example, if your service is global, **Geolocation Routing** can help ensure that users are directed to the nearest server to reduce latency.
+
+7. **Assigning a Domain Name**:
+ - Once your routing policy is in place, assign a specific subdomain to your service. For instance, if your domain is `naman.dev`, you could assign `product.naman.dev` to your product service. This makes the service accessible through the custom domain.
+
+8. **Testing the Configuration**:
+ - After the configuration is complete, test the domain by accessing it through a web browser. Ensure that the service responds correctly and that the domain name is properly routed to the AWS service.
+
diff --git a/Non-DSA Notes/Backend Project Java Notes/Auth - 3: Implementing User Service.md b/Non-DSA Notes/Backend Project Java Notes/Auth - 3: Implementing User Service.md
new file mode 100644
index 0000000..39dbc6f
--- /dev/null
+++ b/Non-DSA Notes/Backend Project Java Notes/Auth - 3: Implementing User Service.md
@@ -0,0 +1,292 @@
+## Topics to be covered
+
+* Implementation of User Service
+
+---
+
+## Implementing Signup Functionality
+
+### Overview of Signup
+
+The **signup** functionality is a critical component of any user service, where new users can register by providing their details, such as email, password, and name. Here, we’ll implement the signup functionality by ensuring that the user's password is securely stored in the database.
+
+**Security** is the key concern in signup implementations, especially how passwords are handled. Instead of storing plain-text passwords, we use a **password hashing algorithm** called `bcrypt`, which transforms the plain password into an irreversible hash. This way, even if someone gains access to the database, they cannot retrieve the original passwords.
+
+
+### Step-by-Step Implementation
+
+1. **Implement `bcrypt` Password Encoder**:
+ - Use the `bcrypt` hashing algorithm to encode passwords before saving them to the database. This provides security by ensuring that even if the database is compromised, the passwords cannot be easily decoded.
+
+ **Why `bcrypt`?**
+ - It is a widely used hashing function designed specifically for hashing passwords, offering features like a salt to defend against rainbow table attacks and a configurable work factor to adjust the computational cost.
+
+2. **Allow All Requests Temporarily**:
+ - In the `SecurityConfiguration` class, temporarily allow all incoming HTTP requests. This step is necessary during development and testing to simplify access without authentication.
+
+3. **Resolve CORS Issues**:
+ - Ensure Cross-Origin Resource Sharing (CORS) policies are configured to allow requests from tools like Postman. CORS restrictions might prevent external clients from accessing resources, so removing these restrictions aids testing.
+
+4. **Testing with Postman**:
+ - Use Postman to make a `POST` request to the signup API endpoint. Postman allows us to send HTTP requests with a JSON body containing the user's email, password, and name, and observe the response.
+
+5. **Use `bcrypt` with Different Key Values**:
+ - Experiment with `bcrypt` by using different key values to explore how password encryption changes and observe the resulting hashed passwords.
+
+### Code Implementation
+
+The signup feature is implemented using two main components: a controller to handle incoming HTTP requests and a service that contains the business logic.
+
+#### Controllers Code (Signup)
+The controller manages the HTTP request for user signup and forwards it to the service layer for processing.
+```java
+@PostMapping("/signup")
+public UserDto signUp(@RequestBody SignUpRequestDto request) {
+ // Extract email, password, and name from the request object
+ String email = request.getEmail();
+ String password = request.getPassword();
+ String name = request.getName();
+
+ // Pass the extracted values to the signUp method in the service layer
+ return UserDto.from(userService.signUp(name, email, password));
+}
+```
+
+- **Explanation**:
+ - The `@PostMapping("/signup")` annotation maps this method to a POST HTTP request for the `/signup` endpoint.
+ - `@RequestBody` indicates that the request body contains JSON data (user's email, password, and name) that will be deserialized into a `SignUpRequestDto` object.
+ - The signup request data is passed to the service layer for processing.
+ - The response is converted into a `UserDto` object, which is then returned to the client.
+
+#### Service Code (Signup)
+The service handles the logic of storing the new user in the database after hashing their password.
+```java
+public User signUp(String fullName, String email, String password) {
+ // Create a new User object and set its attributes
+ User u = new User();
+ u.setEmail(email);
+ u.setName(fullName);
+
+ // Hash the user's password using bcrypt before saving it to the database
+ u.setHashedPassword(bCryptPasswordEncoder.encode(password));
+
+ // Save the user object to the database and return the saved user
+ User user = userRepository.save(u);
+ return user;
+}
+```
+
+- **Explanation**:
+ - A new `User` object is created, and its `email`, `name`, and `hashedPassword` attributes are set.
+ - The `password` is hashed using the `bCryptPasswordEncoder.encode()` method before being stored in the `hashedPassword` field.
+ - The `userRepository.save(u)` method saves the new user to the database and returns the saved user object.
+
+For more details on the structure of DTOs (Data Transfer Objects) and the complete project code, refer to the [GitHub repository](https://github.com/Naman-Bhalla/userservicemwfeve).
+
+---
+
+## Implementing Login Functionality
+
+### Overview of Login
+
+Login functionality allows users to authenticate themselves by providing their registered email and password. To ensure security, we verify the password against the stored hashed password using `bcrypt`. On successful authentication, the system generates a token that can be used to authenticate future requests.
+
+### Key Steps for Login
+
+1. **Find the User by Email**:
+ - When a login request is made, the system first searches for the user in the database using the provided email address.
+
+2. **Verify the Password**:
+ - If the user is found, the next step is to compare the provided password with the stored hashed password using the `bcryptPasswordEncoder.matches()` method. This method returns `true` if the passwords match, ensuring that the user has provided the correct password.
+
+3. **Generate a Token**:
+ - Once the password is verified, a new token is generated. This token will be used to authenticate future requests made by the user. For now, we can generate a simple random string, but later we will replace this with a JWT token for better security and functionality.
+
+### Code Implementation
+
+#### Controllers Code (Login)
+The controller handles the incoming login request and delegates it to the service.
+```java
+@PostMapping("/login")
+public Token login(@RequestBody LoginRequestDto request) {
+ // Pass email and password from the request to the login service method
+ return userService.login(request.getEmail(), request.getPassword());
+}
+```
+
+- **Explanation**:
+ - Similar to the signup process, `@PostMapping("/login")` maps this method to handle POST requests at the `/login` endpoint.
+ - The email and password are extracted from the `LoginRequestDto` object and passed to the service for validation.
+
+#### Service Code (Login)
+The service handles the login logic by checking the credentials and generating a token if the login is successful.
+```java
+public Token login(String email, String password) {
+ // Find the user by email in the database
+ Optional
+
+Then
+(N/2) * 2
+Here both will cancel out with each other and so our overall time complexity for building a heap is **O(N)**
+
+---
+title: Quiz 3
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+What is the time complexity for building a heap with N nodes?
+
+# Choices
+- [ ] O(1)
+- [ ] O(N$^2$)
+- [x] O(N)
+- [ ] O(logN)
+
+
+
+---
+title: Problem 2 Merge N sorted arrays
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Merge N-sorted arrays
+a - [2, 3, 11, 15, 20]
+b - [1, 5, 7, 9]
+c - [0, 2, 4]
+d - [3, 4, 5, 6, 7, 8]
+e - [-2, 5, 10, 20]
+
+We have to merge these sorted arrays.
+
+### Idea
+- If we want to merge two sorted arrays then we need two pointers.
+- If we want to merge three sorted arrays then we need three pointers.
+- If we want to merge N sorted arrays then we need N pointers, in which complexity becomes very high and we need to keep track of N pointers.
+
+---
+title: Quiz 4
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+For merging N sorted arrays, which data structure would be the most efficient for this task ?
+
+# Choices
+- [ ] Linked List
+- [ ] Array
+- [x] Min-Heap
+- [ ] Hash Table
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+A Min-Heap is an efficient data structure choice. The Min-Heap ensures that the smallest element among all the elements in the arrays is always at the front. This allows for constant-time access to the minimum element, making it efficient to extract and merge elements in sorted order.
+
+---
+title: Merge N sorted arrays Solution
+description:
+duration: 300
+card_type: cue_card
+---
+
+
+### Optimized Solution
+- First, we need to compare the 0th index element of every array.
+- Now we use heap here.
+- We will add an index 0 element of every array in the heap, in the form of element value, array number and Index of the element in particular.
+
+
+
+Now take the minimum element and insert it in the resultant array,
+
+- Now insert the next element of the list for which the minimum element is selected, like first, we have taken the fourth list element, so now insert the next element of the fourth list.
+
+
+
+- Now again extract-min() from the heap and insert the next element of that list to which the minimum element belongs.
+- And keep repeating this until we have done with all the elements.
+
+### Time Complexity
+**Time Complexity:** (XlogN)
+Here X is a total number of elements of all arrays.
\ No newline at end of file
diff --git a/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 2 Problems.md b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 2 Problems.md
new file mode 100644
index 0000000..6f6eb7b
--- /dev/null
+++ b/Academy DSA Typed Notes/DSA 4.2/DSA Heaps 2 Problems.md
@@ -0,0 +1,707 @@
+# Advanced DSA: Heaps 2: Problems
+
+---
+title: Today's content
+description:
+duration: 60
+card_type: cue_card
+---
+
+### Todays Content
+- Heap Sort
+- Kth largest element
+- Sort nearly sorted array
+- Median of stream of integer
+
+
+---
+title: Problem 1 Sort an Array
+description: Sort an array using heap sort
+duration: 120
+card_type: cue_card
+---
+
+### Problem Statement
+We want to sort an array in increasing order using a heap.
+
+**`[Ask Students: How can we do so ?]`**
+
+
+### Idea
+We can use min-heap, and we need to call `extract-min()`/`remove(`) repeatedly many times, `extract-min()` will every time give the minimum element among all the available elements.
+1. Build a min-heap.
+2. `extract-min()` and store the returned value in the `ans` array until all the elements are not deleted.
+
+
+---
+title: Quiz 1
+description: time Complexity to convert an array to a heap
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+
+What is the time Complexity to convert an array to a heap?
+
+# Choices
+
+- [ ] O(1)
+- [ ] O(log n)
+- [x] O(n)
+- [ ] O(nlog(n))
+
+
+
+---
+title: Quiz 2
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Root element in a heap is ?
+
+# Choices
+- [ ] min element of the array
+- [ ] max element of the array
+- [x] either min or max depending upon whether it is min or max heap
+- [ ] random element of the array
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+Either min or max depending upon whether it is min or max heap. Min-Heap has minimum element at the root node, where as Max-Heap has maximum element at the root node.
+
+
+
+---
+title: Sort an Array Complexity and Solution Approach
+description: Sort an array using heap sort continued
+duration: 900
+card_type: cue_card
+---
+
+### Complexity of sorting an array using heap
+1. Build a min-heap -> **Complexity:** `O(n)`
+2. `extract-min()` and store the returned value in the `ans` array until all the elements are not deleted.
+3. Complexity of `extract-min()` is `O(logn)` and we are calling `N` times, so the overall complexity is `O(NlogN)`.
+
+### Complexity
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(N), as we are using another array for building the heap.
+
+### Can we optimize the space complexity?
+
+**`Hint: Try to solve by using `max-heap`.`**
+
+- Let us take an example of `max-heap`
+
+>
+
+- Create an array for this max-heap.
+
+>
+
+- Say, we extract an element, which element will we get? The Maximum!
+Now, the maximum element can be swapped with the last index. This way, maximum element will come at its correct position in sorted array.
+
+>
+
+- Now we will virtually remove the last element, which means we consider an array till the second last element of an array.
+
+- Now, since the tree is not satisfying the heap order property, so we will call `heapify()` for index 0.
+
+- So when we call `heapify()`, firstly 3 is swapped with 13(maximum of 13 and 10).
+
+>
+
+- Now again 3 is swapped with 7.
+
+>
+
+- Now 3 is the maximum among 3, 2 and 1. Hence, no further swaps are needed.
+Now we have an array,
+
+>
+
+- As we know now a maximum of all available elements is present at root, call `extract-max()`, swap maximum element with the last index element(index 8) and then we will call heapify for the value 1.
+
+>
+
+- 1 is swapped with 10, then swapped with 8, after that 1 will reach to its correct position.
+
+>
+
+- Again extract the maximum and swap it with the last(7th) index element. Then call Heapify for it.
+
+In this way, repeat these steps we completed with all the elements of the tree.
+
+
+---
+title: Sort an Array PseudoCode
+description: Pseudo code for Sort an array using heap sort
+duration: 600
+card_type: cue_card
+---
+
+### PseudoCode
+```cpp=
+Build max-heap ---> TC:O(N)
+j = N - 1;
+while(j > 0){
+ swap(A[0], A[j]);
+ j--;
+ heapify(0, arr[], j)
+}
+```
+
+### Complexity
+
+- **Time Complexity:** O(NlogN)
+- **Space Complexity:** O(1), we are not taking an extra array, we are converting the max heap into sorted array.
+
+
+### Is heap sort an in-place sorting algorithm?
+**Answer:** Yes it is in-place as we are sorting an array using heap sort in constant time in the above question.
+
+### Is heap sort a stable sorting algorithm?
+**Answer:** No heap sort is not stable.
+**Explanation:** Heap sort is not stable because operations in the heap can change the relative order of equivalent keys.
+
+---
+title: Problem 2 kth Largest Element
+description: Find a kth largest element in an array
+duration: 300
+card_type: cue_card
+---
+
+### Problem Statement
+Given arr[N], find the kth largest element.
+
+
+### Example
+**Input:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
+
+
+**Output:**
+7
+
+**Explanation:**
+In the above array,
+- First largest element = 9
+- Second largest element = 8
+- Third largest element = 7
+
+We need to return the third largest element.
+
+
+---
+title: Quiz 3
+description: Find kth largest element in an array
+duration: 60
+card_type: quiz_card
+---
+
+# Question
+
+What is the 5th largest element of an array `[1, 2, 3, 4, 5]`?
+
+# Choices
+
+- [ ] 5
+- [ ] 3
+- [x] 1
+- [ ] 2
+
+
+---
+title: Quiz 3 Explanation
+description:
+duration: 300
+card_type: cue_card
+---
+
+### Explanation
+In the above array,
+- First largest element = 5
+- Second largest element = 4
+- Third largest element = 3
+- Fourth largest element = 2
+- Fifth largest element = 1
+
+We need to return the fifth largest element.
+
+
+---
+title: kth Largest Element solution approach
+description: Solution for the kth largest element problem
+duration: 600
+card_type: cue_card
+---
+
+### :bulb: Idea 1(by sorting)
+Sort an array and simply return arr[N-K].
+
+**Example:**
+arr[] = [8, 5, 1, 2, 4, 9, 7]
+k = 3
+
+**Solution**
+Sort an array, [1, 2, 4, 5, 7, 8, 9]
+Now return arr[N-K] element i.e. arr[7-3] = arr[4] = 7
+
+**Time Complexity:** O(NlogN), **Space Complexity:** O(1).
+
+### :bulb: Idea 2(Using binary search)
+
+We can find the kth largest element by applying binary search just like we have used in the kth smallest element.
+**Time Complexity:** O(Nlog(max-min))
+
+### :bulb: Idea 3(Using heap sort)
+
+1. Build a max-heap.
+2. Call extract-max() k-1 times to remove K-1 elements(for first largest we need zero removals, for second largest we need 1 removal, in this way for kth largest we need k-1 removals)
+
+### Complexity
+**Time Complexity:** O(N + KlogN)
+**Space Complexity:** O(1)
+
+---
+title: kth Largest Element Using min-heap
+description:
+duration: 1200
+card_type: cue_card
+---
+
+### :bulb: Idea 4(Using min-heap)
+
+Let us take an example, we want to create a cricket team of 4 batsmen and we have 8 batsmen i.e. b1, b2, b3, b4, b5, b6, b7 and b8, and every batsman is given only 1 over and everyone tries to achieve maximum run in that over.
+
+Firstly, 4 batsmen played and scored
+|b1|b2|b3|b4|
+|-|-|-|-|
+|12|8|4|6|
+
+We have recently incorporated four batsmen into our team with respective scores of **`12, 8, 4, and 6`**. When batsman **`B5 joins, scoring 7`**, we opt to replace the player with the lowest score to maintain team quality. Since we use a min heap to track scores, we **`remove the batsman with a score of 4 and include B5`**, updating our heap to **[12, 8, 7, 6]**.
+
+Later, batsman **`B6 arrives, earning 3 runs`**. However, his score **`doesn't surpass our team's minimum`**, so he isn't added. Then, batsman **`B7 steps in, scoring a notable 10 runs`**. Outperforming our lowest score, **`B7's addition leads us to drop the current minimum`** scorer and update the heap to **[12, 8, 7, 10]**.
+
+Following this, batsman **`B8 enters with a score of 9`**. Exceeding the lowest score in our lineup, we **`incorporate B8 by removing the now lowest scorer`**, refining our heap to **[12, 8, 9, 10]**.
+
+Thus, in this dynamic team selection process, the minimum element in our heap represents the fourth-highest score among our players.
+
+### Example:
+To find the 3rd largest element in an array using a min-heap of size 3:
+
+Given array: **`arr = [8, 5, 1, 2, 4, 9, 7] and k=3`**.
+
+- Initialize an empty min-heap.
+- Add the first three elements of the array to the heap: [8, 5, 1].
+- Iterate over the remaining elements. If an element is greater than the heap's minimum, remove the minimum and insert the new element.
+- After processing elements 2, 4, 9, and 7, the heap evolves as follows:
+ - [8, 5, 2] (after adding 2)
+ - [8, 5, 4] (after adding 4)
+ - [8, 5, 9] (after adding 9)
+ - [8, 7, 9] (after adding 7)
+- The 3rd largest element is the minimum in the heap: 7.
+
+### PseudoCode
+```cpp=
+Build min-heap with first k elements. -> O(K)
+Iterate on the remaining elements. -> (N-K)
+ for every element, check
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ }
+ans = getMin()
+```
+
+### Complexity
+- **Time Complexity:** O(K+(N-K)logK)
+- **Space Complexity:** O(K)
+
+:bulb: What should we use for finding k-th smallest?
+- A max-heap of size K.
+
+
+---
+title: Problem 2 kth Largest Element for all windows
+description:
+duration: 900
+card_type: cue_card
+---
+
+### Problem Statement
+Find the kth largest element for all the windows of an array starting from 0 index.
+
+### Example
+**Input:**
+arr[] = `[10, 18, 7, 5, 16, 19, 3]`
+k = 3
+
+
+**Solution:**
+
+- We need atleast 3 elements in a window, so we will consider first window from index 0 to k-1, we have elements in that `[10, 18, 7]`; third largest is 7, ans=`[7]`.
+- Window 0 to 3 `[10, 18, 7, 5]`,third largest = 7, ans=`[7, 7]`.
+- Window 0 to 4 `[10, 18, 7, 5, 16]`,third largest = 10, ans=`[7, 7, 10]`.
+- Window 0 to 5 `[10, 18, 7, 5, 16, 19]`,third largest = 16, ans=`[7, 7, 10, 16]`.
+- Window 0 to 6 `[10, 18, 7, 5, 16, 19, 3]`,third largest = 16, ans=`[7, 7, 10, 16, 16]`.
+
+---
+title: Quiz 4
+description:
+duration: 45
+card_type: quiz_card
+---
+
+# Question
+Find the kth largest element for all the windows of an array starting from 0 index.
+
+arr[] = `[5, 4, 1, 6, 7]`
+k = 2
+
+# Choices
+- [x] [4, 4, 5, 6]
+- [ ] [6, 6, 6, 6]
+- [ ] [5, 4, 1, 6]
+- [ ] [4, 1, 6, 7]
+
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+To find the second largest element in each window of a given size in an array:
+
+- Start with the first window (from index 0 to k-1). For example, in [5, 4], the second largest is 4. Answer array starts as [4].
+- Shift the window one element at a time and find the second largest in each new window.
+ - Window [5, 4, 1] gives second largest 4. Answer array becomes [4, 4].
+ - Window [5, 4, 1, 6] gives second largest 5. Answer array becomes [4, 4, 5].
+ - Window [5, 4, 1, 6, 7] gives second largest 6. Answer array becomes [4, 4, 5, 6].
+
+---
+title: kth Largest Element for all windows Idea
+description:
+duration: 900
+card_type: cue_card
+---
+To find the k-largest elements in an array using a min-heap:
+
+- **Initialize Min-Heap**: Start with a min-heap and add the first k elements from the array to it.
+- **Compare and Update**: For each remaining array element, if it's larger than the heap's minimum, replace the minimum with this element.
+- **Track Minimums**: After each update, record the heap's minimum. This shows the evolving k-th largest element.
+
+### Pseudocode
+```java
+Build min-heap with first K elements. -> O(K)
+ans.add(extractMin())
+
+Iterate on the remaining elements. -> (N-K)
+ for every element, check {
+ if(curr element > min element in heap){
+ extractMin()
+ insert(current element)
+ ans.add(extractMin())
+ }
+ }
+```
+
+---
+title: Problem 3 Sort the nearly sorted array
+description:
+duration: 1200
+card_type: cue_card
+---
+
+### Problem Statement
+Given a nearly sorted array. You need to sort the array.
+
+> Nearly sorted array definition - Every element is shifted away from its correct position by at most k-steps.
+
+### Example
+Sorted array can be `[11, 13, 20, 22, 31, 45, 48, 50, 60]`
+We are given,
+**Input:**
+arr[] = `[13, 22, 31, 45, 11, 20, 48, 60, 50]`
+k = 4
+
+Every element is not more than 4 distance away from its position.
+
+### :bulb: Idea 1(Sorting)
+Sort an Array
+**Time Complexity:** O(NlogN)
+
+### :bulb: Idea 2
+
+An element can be shifted by at most k steps, so the **`element at index 0 can only be shifted till index (k)`**, so the **`minimum element lies from index 0 to k`**.
+- So we need to choose a minimum of first k+1 elements.
+- We will take a min-heap of size k+1.
+- Add first k+1 elements into a heap, heap = `[13, 22, 31, 45, 11]`.
+- extractMin()(heap = `[13, 22, 31, 45]`) will give a first element of a sorted array, ans = `[11]`, now add the next element from an input array, into a heap, heap = `[13, 22, 31, 45, 20]`.
+- Again extractMin(), it will give a second of a sorted array, ans = `[11, 13]`, again add the next element of the input array, again extractMin(), in this way do until we reach the last index, and then remove minimum element from array one-by-one and add it to ans array.
+
+
+### PseudoCode
+```cpp
+1. build min-heap with the first (k + 1) elements.
+2. for(i = k + 1 ; i < N ; i ++){
+ extractMin(); -> put it into ans[] array
+ insert( arr[i] )
+ }
+ while(minHeap is not empty){
+ extractMin() -> put it into ans[] array
+ }
+3. return ans;
+```
+
+### Compexity
+**Time Complexity:** O(K + N.logK)
+**Space Complexity:** O(K)
+
+
+---
+title: Flipkart's Delivery Time Estimation Challenge
+description:
+duration: 120
+card_type: cue_card
+---
+
+*Flipkart is currently dealing with the difficulty of precisely estimating and displaying the expected delivery time for orders to a specific pin code.*
+
+*The existing method relies on historical delivery time data for that pin code, using the median value as the expected delivery time.*
+
+*As the order history expands with new entries, Flipkart aims to enhance this process by dynamically updating the expected delivery time whenever a new delivery time is added. The objective is to find the expected delivery time after each new element is incorporated into the list of delivery times.*
+
+**End Goal:** With every addition of new delivery time, requirement is to find the median value.
+
+**Why Median ?**
+The median is calculated because it provides a more robust measure of the expected delivery time
+
+The median is less sensitive to outliers or extreme values than the mean. In the context of delivery times, this is crucial because occasional delays or unusually fast deliveries (outliers) can skew the mean significantly, leading to inaccurate estimations.
+
+---
+title: Problem 4 Find the median
+description:
+duration: 120
+card_type: cue_card
+---
+
+### Problem Statement
+Given an infinite stream of integers. Find the median of the current set of elements
+
+>### Median
+>Median is the Middle element in a sorted array.
+
+>The median of [1, 2, 5, 4, 3, 6]
+First, we need to sort an array [1, 2, 3, 4, 5, 6]
+We have two middle values as the size of the array is even i.e. 3, 4.
+So to find the median, we need to take the average of both middle values, median = (3+4)/2 = 3.5
+
+---
+title: Quiz 5
+description: Median of the given array
+duration: 60
+card_type: quiz_card
+---
+
+
+# Question
+
+The median of [1, 2, 4, 3]
+
+# Choices
+
+- [ ] 2
+- [ ] 4
+- [ ] 3
+- [x] 2.5
+
+---
+title: Quiz Explanation
+description:
+duration: 180
+card_type: cue_card
+---
+
+### Explanation:
+
+The median of [1, 2, 4, 3]
+First, we need to sort an array [1, 2, 3, 4]
+We have two middle values as the size of the array is even i.e. 2, 3.
+So to find the median, we need to take the average of both middle values,
+
+Median = (2+3)/2 = 2.5
+
+
+
+---
+title: Find the median Brute Force Approach
+description:
+duration: 600
+card_type: cue_card
+---
+
+
+### Understanding the question
+We have an infinite stream of elements.
+1. First we have one element.
+6, then median = 6.
+2. Next element if 3
+6, 3, then median = 4.5
+3. 6, 3, 8, then median = 6
+4. 6, 3, 8, 11, then median = 7
+5. 6, 3, 8, 11, 10 then median = 8
+
+
+### Brute Force Idea
+For every incoming value, include the value and sort an array. Find the middle point/average of 2 middle points.
+**Time Complexity:** O(N^2^logN)
+
+
+---
+title: Find the median solution approach
+description:
+duration: 1200
+card_type: cue_card
+---
+
+### Idea(Using Insertion Sort)
+Every time find the correct position of the upcoming element i.e. Insertion Sort
+
+**Time Complexity:** O(N^2^)
+
+### Idea(Using heap)
+
+To find the median in an array by dividing it into two parts - one with smaller elements and the other with larger elements:
+
+Consider an array, **`for example, [6, 3, 8, 11]`**. We divide it such that **`6, 3 are on the smaller side`** and **`8, 11 on the larger side`**, as shown in the image:
+
+
+To find the median:
+
+- If both sides have an equal number of elements, take the average of the largest element on the smaller side and the smallest element on the larger side.
+- If the sizes are unequal, choose the largest element from the smaller side if it's larger, or the smallest from the larger side otherwise.
+
+**The key is to use two heaps:** a min-heap for the larger elements and a max-heap for the smaller elements. This approach maintains a balanced partition of the array for efficient median calculation.
+
+### Example
+arr = [6, 3, 8, 11, 20, 2, 10, 8, 13, 50, _ _ _ ]
+
+Take two heaps, min-heap and max-heap
+
+
+Smaller side elements are stored in max-heap and Greater side elements are stored in min-heap
+
+
+1. First element is 6, simply add it in max-heap
+
+**The median is 6.**
+
+
+2. Second element is 3; compare with h1.getMax(), if 3<6 then it must be included in h1.
+
+but now both the heaps do not have half-half elements. Remove the maximum element from max-heap and insert it into h2.
+
+Now we have an equal number of elements in both heaps, so the median is the average of the largest value of h1 and the smallest value of h2.
+**Median is 4.5**
+
+
+3. Next element is 8.
+Compare it with h1.getMax(), 8>3 so 8 will go to h2.
+
+size(h2) is greater by 1
+**Median is 6**
+
+
+4. Next element is 11.
+Compare it with h1.getMax(), 11>3 so 11 will go to h2.
+
+But now both heap does not have nearly half elements.
+So remove the minimum element and add it to h1.
+
+**Median is average of 6,8 = (6+8)/2 = 7**
+
+
+5. Next element is 20.
+Compare it with h1.getMax(), 20>6 so 20 will go to h2.
+
+size(h2) is greater by 1
+**The median is 8.**
+
+In this way we will do for all the elements of an array, and find the median at every step, we need to take care that the |h1.size()-h2.size()|<=1.
+
+After adding all the medians in an array, we will get an answer: [6, 4.5, 6, 7, 8, 7, 8, 8, 8, _ _ _ ]
+
+
+---
+title: Find the median pseudocode
+description:
+duration: 600
+card_type: cue_card
+---
+
+### PseudoCode
+```cpp
+ h1, h2
+ h1.insert(arr[0])
+ print(arr[0])
+ for(int i = 1 ; i < N ; i++){
+ if(arr[i] > h1.getMax()){
+ h2.insert(arr[i]);
+ }
+ else{
+ h1.insert(arr[i]);
+ }
+ diff = |h1.size() - h2.size()|
+ if(diff > 1){
+ if(h1.size() > h2.size()) {
+ h2.insert(h1.getMax());
+ }
+ else {
+ h1.insert(h2.getMin());
+ }
+ }
+ if(h1.size() > h2.size()){
+ print(h1.getMax());
+ }
+ else if(h2.size() > h1.size()){
+ print(h2.getMin())
+ }
+ else{
+ print((h1.getMax() + h2.getMin()) / 2.0);
+ }
+ }
+```
+
+### Complexity
+
+**Time Complexity:** O(NlogN)
+**Space Complexity:** O(N)
+
+---
+title: Contest Information
+description:
+duration: 900
+card_type: cue_card
+---
+
+Next contest syllabus includes - **"Trees, Heaps and Greedy"**. We are already done with **Trees** and **Heaps**, kindly make sure we are done with their problems at the earliest.
+
+If you haven't done any yet, then make sure we are atleast done with assignments.
diff --git a/Non-DSA Notes/Backend Project Java Notes/AWS Elastic Beanstalk (EBS), Amazon RDS, Environment Variables, and Product Service Deployment.md b/Non-DSA Notes/Backend Project Java Notes/AWS Elastic Beanstalk (EBS), Amazon RDS, Environment Variables, and Product Service Deployment.md
new file mode 100644
index 0000000..1b2d722
--- /dev/null
+++ b/Non-DSA Notes/Backend Project Java Notes/AWS Elastic Beanstalk (EBS), Amazon RDS, Environment Variables, and Product Service Deployment.md
@@ -0,0 +1,215 @@
+## Topics to be Covered
+
+- **Elastic Beanstalk (EBS)**
+- **Amazon Relational Database Service (RDS)**
+- **Environment Variablesuct Service Deployment**
+
+---
+
+## Elastic Beanstalk (EBS)
+
+### Overview of EC2 and the Need for EBS
+
+EC2 instances are virtual servers in the AWS cloud. EC2 provides the raw compute power needed to run applications, but managing these instances, especially as your application grows, can become complex. Tasks such as load balancing, scaling, and handling failures require constant attention.
+
+This is where **Elastic Beanstalk (EBS)** comes into play. EBS is an orchestration service that abstracts the complexities of deploying and managing applications by automatically handling infrastructure provisioning, load balancing, scaling, and application health monitoring.
+
+### How EBS Simplifies Application Management
+
+EBS acts as a manager for your application deployment. It orchestrates various AWS services to ensure your application remains available and performs optimally with minimal manual intervention. The main features of EBS include:
+
+- **Server Management:** EBS automatically manages the number of servers (EC2 instances) needed based on the current load. It can add or remove instances as needed.
+- **Load Balancing:** EBS integrates with an Elastic Load Balancer (ELB), which distributes incoming traffic across multiple EC2 instances. This ensures that your application can handle varying amounts of traffic without downtime. The client only needs to know the IP address of the load balancer, which simplifies the networking aspect.
+- **Application Deployment:** EBS takes care of deploying your application code to the servers, managing the deployment process and handling any necessary updates.
+
+### Practical Example: Deploying a Java Application
+
+To illustrate how EBS works, let's consider deploying a Java-based application called "Product Service." Java is a compiled language, meaning the source code needs to be compiled into bytecode before it can be executed. This bytecode is typically packaged into a `.jar` (Java ARchive) file.
+
+#### Step 1: Compiling the Java Code
+First, we compile our Java code to generate the `.jar` file. This file is the deployable artifact that contains all the classes and resources needed to run the application.
+
+- **Visual Aid:**
+ - **Compilation Process:** 
+ - **Generated `.jar` File:** 
+
+**Instructor Note:** Discuss the significance of the `.jar` file, including how it's named and structured.
+
+#### Step 2: Running the `.jar` File
+Once the `.jar` file is generated, it can be executed on any machine with the Java Runtime Environment (JRE) installed. The command to run the `.jar` file is:
+
+```bash
+java -jar name-of-jar.jar
+```
+
+### What EBS Manages Behind the Scenes
+
+When deploying this application using EBS, the service takes over several critical tasks:
+
+- **Server Scaling:** EBS determines when to add or remove EC2 instances based on traffic patterns.
+- **Load Balancing:** It routes incoming requests through a load balancer to the appropriate EC2 instance.
+- **Monitoring and Logging:** EBS monitors the health of your application and logs any issues, providing you with real-time feedback.
+
+This orchestration significantly reduces the workload for developers and operators, allowing them to focus on developing new features rather than managing infrastructure.
+
+---
+
+## Amazon RDS (Relational Database Service)
+
+### Introduction to RDS
+
+Amazon RDS (Relational Database Service) is a managed database service that simplifies the setup, operation, and scaling of relational databases in the cloud. RDS handles routine database tasks such as provisioning, patching, backup, recovery, and scaling, allowing you to focus on your application rather than database management.
+
+### Why Use RDS?
+
+Managing a database involves several time-consuming tasks, including:
+
+- **Installation and Setup:** Configuring the database software on a server.
+- **Backups and Recovery:** Ensuring that data is regularly backed up and can be restored in case of failure.
+- **Patching and Updates:** Keeping the database software up to date with the latest patches.
+- **Scaling:** Adjusting the database's capacity to handle increasing loads.
+
+RDS automates all these tasks, offering a fully managed experience where you only need to specify the type and size of the database, and RDS handles the rest.
+
+### Deploying a Database with RDS
+
+To integrate our product service with a database, we'll use Amazon RDS to deploy a MySQL database.
+
+#### Step 1: Creating the Database
+Using the AWS Management Console, we can create a new RDS instance by specifying the database engine, version, and instance size. We also have the option to enable features such as **auto-scaling** to automatically adjust the database's capacity based on demand.
+
+- **Visual Aid:**
+ - **RDS Creation Interface:** 
+ - **Auto-Scaling Configuration:** 
+
+**Instructor Note:** Walk through the process of creating an RDS instance, highlighting options like maintenance settings and disk encryption for added security.
+
+#### Step 2: Configuring Database Access
+Security is a critical aspect of database management. With RDS, you can configure the database to accept connections only from specific EC2 instances, ensuring that unauthorized access is prevented even if credentials are compromised.
+
+- **Security Configuration:** Specify that only the servers within your VPC (Virtual Private Cloud) can access the database. This adds an extra layer of security.
+
+#### Step 3: Connecting to the Database from a Spring Application
+After the database is set up, we need to connect it to our Java application. This is done by updating the `application.properties` file with the database URL and credentials.
+
+```java
+spring.datasource.url=jdbc:mysql://localhost:3306/productservicedecmwfeve
+spring.datasource.username=${PRODUCT_SERVICE_DATABASE_USERNAME}
+spring.datasource.password=${PRODUCT_SERVICE_DATABASE_PASSWORD}
+```
+
+By using environment variables (as we'll discuss next), we can avoid hardcoding sensitive information directly into the application code.
+
+---
+
+## Environment Variables
+
+### Importance of Environment Variables
+
+Environment variables are key-value pairs stored at the operating system level that applications can use to retrieve configuration information. This method of configuration management offers several advantages, particularly in terms of security and flexibility.
+
+#### Security Benefits
+Hardcoding sensitive information such as database URLs, usernames, and passwords directly into your application's source code is a risky practice. If the code is ever compromised, these credentials could be exposed to attackers. By using environment variables, sensitive information is stored separately from the code, reducing the risk of exposure.
+
+#### Flexibility in Different Environments
+Applications often need to run in different environments, such as development, testing, and production. Each environment may require different configuration settings, such as database URLs or API keys. By using environment variables, you can easily change the configuration based on the environment without modifying the code.
+
+### Example Configuration in `application.properties`
+
+Here is an example of how environment variables can be used in a Spring application to configure database access and other settings:
+
+```java
+spring.datasource.url=${PRODUCT_SERVICE_DATABASE_URL}
+spring.datasource.username=${PRODUCT_SERVICE_DATABASE_USERNAME}
+spring.datasource.password=${PRODUCT_SERVICE_DATABASE_PASSWORD}
+spring.security.oauth2.resourceserver.jwt.issuer-uri=${USER_SERVICE_URL}
+```
+
+In this setup:
+- The actual values for `PRODUCT_SERVICE_DATABASE_URL`, `PRODUCT_SERVICE_DATABASE_USERNAME`, and `PRODUCT_SERVICE_DATABASE_PASSWORD` are stored as environment variables.
+- The application retrieves these values at runtime, ensuring that sensitive information is not exposed in the source code.
+
+This approach not only enhances security but also makes it easier to manage different configurations for different environments.
+
+---
+
+## Product Service Deployment
+
+### Preparing for Deployment
+
+Now that we have our `.jar` file ready and our database deployed on RDS, we can proceed with deploying the Product Service using Elastic Beanstalk.
+
+#### Step 1: Create the Elastic Beanstalk Environment
+
+1. **Choosing the Environment Type:**
+ - Elastic Beanstalk supports multiple environment types, such as single-instance or load-balanced environments. For our service, we may choose a load-balanced environment to handle high traffic.
+
+ - **Visual Aid:**
+ - **Environment Selection:** 
+
+2. **Uploading the Application Code:**
+ - Upload the compiled `.jar` file to Elastic Beanstalk. EBS will handle the deployment process, including creating EC2 instances and configuring the necessary resources.
+
+#### Step 2: Configuring Permissions and Roles
+
+EBS relies on other AWS services to function, such as EC2 for running the application and RDS for database connectivity. To interact with these services securely, EBS requires specific permissions, which are granted through **service roles**.
+
+- **Creating a Service Role:**
+ - A service role is an IAM role that grants permissions to AWS services so they can interact with other AWS resources. In this case, we need to create
+
+ a service role that allows EBS to manage EC2 instances, access the RDS database, and configure the load balancer.
+
+- **Assigning the Service Role to EBS:**
+ - Once the service role is created and the necessary permissions are granted, it is assigned to the EBS environment.
+
+- **Visual Aid:**
+ - **Service Role Configuration:** 
+
+
+
+#### Step 3: Configuring Auto-Scaling and Monitoring
+
+EBS provides several advanced features for managing the scalability and health of your application:
+
+- **Auto-Scaling Groups:**
+ - Auto-scaling ensures that your application can handle varying levels of traffic by automatically adjusting the number of EC2 instances. For example, you can set a policy to add more instances if CPU utilization exceeds 70% and reduce instances if it drops below 40%.
+
+- **Visual Aid:**
+ - **Auto-Scaling Example:** 
+
+- **Monitoring:**
+ - EBS continuously monitors the health of your application and the underlying infrastructure. It provides detailed logs and metrics that help you identify and resolve issues quickly.
+
+#### Step 4: Configuring Listener Ports
+
+The load balancer in EBS routes incoming traffic to the appropriate EC2 instances. The configuration of listener ports is crucial to ensure that the traffic is correctly directed:
+
+- **Listener Port Configuration:**
+ - Typically, the load balancer listens on port 80 (HTTP) or 443 (HTTPS). However, the application may run on a different port (e.g., 8283). EBS allows you to map the incoming traffic on port 80 to the application's port.
+
+- **Visual Aid:**
+ - **Listener Ports Configuration:** 
+
+#### Step 5: Deployment Strategies
+
+Elastic Beanstalk offers several deployment strategies, including:
+
+- **All-at-once:** Deploys the new version of the application to all instances simultaneously.
+- **Rolling Updates:** Deploys the new version gradually, ensuring that some instances remain operational during the deployment.
+
+Choose the strategy that best suits your application's needs.
+
+#### Step 6: Setting Environment Variables
+
+Finally, configure any necessary environment variables at the OS level within the EBS environment. This ensures that sensitive information, such as database credentials, is securely managed.
+
+- **Visual Aid:**
+ - **Environment Variables Configuration:** 
+
+### Monitoring the Deployment Process
+
+Once the deployment starts, EBS provides real-time feedback on the progress and any events that occur during the process. This includes the creation of resources, status updates, and any errors that might arise.
+
+- **Visual Aid:**
+ - **Deployment Events:** 
+
diff --git a/Non-DSA Notes/Backend Project Java Notes/AWS III.md b/Non-DSA Notes/Backend Project Java Notes/AWS III.md
new file mode 100644
index 0000000..7a711c9
--- /dev/null
+++ b/Non-DSA Notes/Backend Project Java Notes/AWS III.md
@@ -0,0 +1,199 @@
+## Topics to be covered
+
+
+1. **User Service Deployment**
+2. **Virtual Private Cloud (VPC) and Security Groups**
+3. **Health Status Monitoring**
+4. **Deploying on Custom Domains**
+
+---
+
+## User Service Deployment
+
+### Steps for Deployment:
+
+1. **Deploy the Database**:
+ - Begin by setting up the database that the user service will utilize. This involves configuring a relational database, such as MySQL or PostgreSQL, within AWS RDS (Relational Database Service). Ensure the database is correctly provisioned with appropriate settings, including instance type, storage capacity, and backup configurations.
+
+2. **Update Application Properties**:
+ - The next step is to modify the `application.properties` file of the user-service to point to the newly deployed database. This file should include the database URL, username, password, and any additional settings required by the service.
+ - Once updated, create a Java Archive (JAR) package of the user-service. This package will include all necessary libraries, resources, and metadata required for deployment.
+
+3. **Create a New Elastic Beanstalk Service (EBS) Environment**:
+ - Set up a new environment in Elastic Beanstalk specifically for the user-service. Elastic Beanstalk automates the deployment, scaling, and management of applications, making it an ideal platform for our service.
+ - Ensure that the environment is configured with the correct platform, such as a Java SE or Tomcat environment, depending on your application.
+
+4. **Configure Elastic Beanstalk**:
+ - Adjust key configurations within Elastic Beanstalk. This includes setting environment variables, configuring load balancers, and defining autoscaling rules.
+ - Pay particular attention to security settings, such as setting up HTTPS for secure communication and managing IAM roles to control access to AWS resources.
+
+5. **Deploy the User Service**:
+ - Finally, deploy the user-service JAR package to Elastic Beanstalk. Once deployed, Elastic Beanstalk will automatically handle the provisioning of resources, including EC2 instances, and will manage the deployment process.
+
+### Post Deployment Actions:
+
+- **Update the Product Service**:
+ - After successfully deploying the user-service, it's crucial to integrate it with the product service. Update the `application.properties` file of the product service to include the URL of the user-service. This ensures that the product service can authenticate and authorize requests via the user-service.
+
+- **Re-deploy the Product Service**:
+ - With the updated configurations, re-deploy the product service to Elastic Beanstalk. This ensures that both services are correctly linked and operational.
+
+```java
+logging.level.org.springframework.web=TRACE
+spring.jpa.hibernate.ddl-auto=validate
+spring.datasource.url=${PRODUCT_SERVICE_DATABASE_URL}
+spring.datasource.username=${PRODUCT_SERVICE_DATABASE_USERNAME}
+spring.datasource.password=${PRODUCT_SERVICE_DATABASE_PASSWORD}
+spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
+spring.jpa.show-sql=true
+spring.security.oauth2.resourceserver.jwt.issuer-uri=${USER_SERVICE_URL}
+logging.level.org.springframework.security.*=TRACE
+logging.level.org.springframework.web.*=TRACE
+server.port=8283
+```
+
+- **Final Outcome**: Both the user-service and product-service should now be fully deployed and functional. This interconnected deployment is a fundamental step in building a robust, microservices-based architecture.
+
+
+
+---
+
+## Virtual Private Cloud (VPC) and Security Groups
+
+### Introduction:
+As our applications grow in complexity, securing the infrastructure becomes increasingly critical. In this section, we will explore how AWS Virtual Private Cloud (VPC) and Security Groups can be used to enhance security by isolating resources and controlling traffic.
+
+### Application Architecture Overview:
+The architecture of our application consists of multiple interconnected services, each with its own database and functionality. These services must be protected from unauthorized access while allowing legitimate communication between them.
+
+
+
+### Security Challenges:
+
+- **Unrestricted Database Access**:
+ - Currently, if someone outside the network has the correct credentials (username, password, and URL), they can access the database directly. This presents a significant security risk, as databases often contain sensitive information.
+
+- **Example Scenario**:
+ - Suppose you attempt to connect to the database using an external tool like IntelliJ. Without proper restrictions, such access is possible, highlighting the need for enhanced security.
+
+
+
+### Solution - Implementing Virtual Private Cloud (VPC):
+
+- **VPC Overview**:
+ - AWS provides a Virtual Private Cloud (VPC) as a means of isolating resources within a virtual network that is logically separated from other AWS customers. By placing services within a VPC, you can control who has access to these services and ensure that only authorized traffic is allowed.
+
+- **Practical Example**:
+ - Imagine AWS as a large city with numerous buildings (services). By creating a VPC, you are essentially constructing a gated community within this city, where only residents (services within the VPC) can interact with each other. External entities must go through strict checkpoints (security groups) to gain access.
+
+
+
+### Enhancing Security with Security Groups:
+
+- **Security Groups**:
+ - Security Groups act as virtual firewalls for your EC2 instances or other AWS resources within a VPC. They consist of a set of rules that define which incoming and outgoing traffic is allowed.
+
+- **Best Practices**:
+ - While AWS provides default security groups, it is recommended to create custom security groups tailored to the specific needs of each service. This avoids potential security issues where changes to a default security group could inadvertently affect multiple services.
+
+- **Example**: Consider our application’s architecture, where the authentication service and the product service each have their own databases. By creating specific security groups, we can ensure that only the authentication service can access its database and similarly for the product service.
+
+
+
+- **Inbound and Outbound Rules**:
+ - **Inbound Rules**: These rules specify which sources (e.g., IP addresses or other services) can send requests to your service.
+ - **Outbound Rules**: These rules determine where your service can send requests, such as to other databases or services within the VPC.
+
+### Application and Testing:
+
+- **Applying Security Groups**:
+ - After setting up the appropriate security groups, apply them to your EC2 instances or other AWS resources. This ensures that only authorized traffic is permitted, greatly enhancing the security of your application.
+
+- **Validation**:
+ - Once the security groups are applied, test the application to confirm that unauthorized external tools (such as IntelliJ) can no longer connect directly to the database. This demonstrates the effectiveness of the security measures.
+
+
+
+---
+
+## Health Status
+
+### Introduction:
+Ensuring the stability of services during updates is critical in a production environment. In this section, we’ll discuss how to implement health status checks in AWS Elastic Beanstalk to monitor the health of services during and after deployment.
+
+### Rolling Deployment Overview:
+
+- **Rolling Deployment Process**:
+ - When deploying an update to a service, AWS Elastic Beanstalk uses a rolling deployment strategy. This strategy involves gradually updating instances behind a load balancer to ensure minimal downtime. The steps include:
+ 1. The load balancer takes one server offline.
+ 2. The new version of the service is deployed on that server.
+ 3. The server is checked to ensure it is functioning correctly.
+ 4. The server is brought back online and reconnected to the load balancer.
+
+
+### Health Status Checks:
+
+- **Purpose**:
+ - Health status checks are automated tests that Elastic Beanstalk uses to verify that a server is healthy after an update. These checks are critical to prevent issues like service outages or degraded performance.
+
+- **Configuration**:
+ - Elastic Beanstalk allows you to configure health checks by specifying a URL endpoint that it should monitor. The health check continuously sends HTTP requests to this endpoint and expects a 200 status code as a sign of success.
+
+- **Example**:
+ - You can configure the health check to send a request every 5 seconds to the root path (`/`) and expect a 200 status code. If this condition is met five times in a row, the server is considered healthy, and the deployment can proceed.
+
+
+
+- **Detailed Example**:
+ - Suppose the health check configuration is set as follows:
+ - **Path**: `/`
+ - **Interval**: 5 seconds
+ - **Timeout**: 5 seconds
+ - **Healthy Threshold**: 5 times
+
+ This configuration instructs Elastic Beanstalk to ensure the service responds with a 200 status code at the specified intervals before declaring the server healthy.
+
+For better clarity you can refer to the documanetation [Spring Boot Actuator ](https://spring.io/guides/gs/actuator-service) .
+
+---
+
+## Deploy on Custom Domains
+
+### Introduction:
+Using a custom domain name for your services not only improves branding but also makes it easier for users to access and remember your service URLs. In this section, we’ll walk through the process of setting up a custom domain for your AWS-deployed services.
+
+### Steps to Deploy on Custom Domains:
+
+1. **Obtain a Domain Name**:
+ - If you don’t already have a domain name, you can obtain one through various domain registrars. The GitHub Student Developer Pack offers a free domain name for one year through services like **namecheap.com**, **name.com**, or **get.tech**.
+
+2. **Domain Name Settings**:
+ - Once you have your domain, you can manage its settings through the registrar’s website. This includes configuring DNS records, which direct traffic from your domain to specific servers or services.
+
+3. **Configure AWS Route 53**:
+ - AWS Route 53 is a scalable DNS web service designed to route end-user requests to AWS applications efficiently. To use your custom domain with AWS, you need to create a hosted zone in Route 53 and add your domain name to it.
+
+
+
+4. **Set Up Name Servers**:
+ - After setting up Route 53, you will receive name server addresses. These need to be configured in your domain registrar’s settings to ensure that your domain points to the AWS-hosted services.
+
+5. **Understanding Routing Policies**:
+ - Route 53 offers several routing policies to manage how traffic is directed:
+ - **Simple Routing**: Directs traffic to a single resource without health checks.
+ - **Failover Routing**: Routes traffic to a primary resource, and if it fails, to a secondary resource.
+ - **Geolocation Routing**: Routes traffic based on the geographic location of the user.
+ - **Geoproximity Routing**: Routes traffic based on the geographic location of resources and optionally shifts traffic from one resource to another.
+ - **Latency Routing**: Routes traffic to the resource with the lowest latency for the user.
+ - **Multivalue Answer Routing**: Returns multiple IP addresses for a DNS query, with optional health checks.
+ - **Weighted Routing**: Distributes traffic across multiple resources based on specified weights.
+
+6. **Choosing a Routing Policy**:
+ - Depending on your specific use case, select a routing policy that best suits your needs. For example, if your service is global, **Geolocation Routing** can help ensure that users are directed to the nearest server to reduce latency.
+
+7. **Assigning a Domain Name**:
+ - Once your routing policy is in place, assign a specific subdomain to your service. For instance, if your domain is `naman.dev`, you could assign `product.naman.dev` to your product service. This makes the service accessible through the custom domain.
+
+8. **Testing the Configuration**:
+ - After the configuration is complete, test the domain by accessing it through a web browser. Ensure that the service responds correctly and that the domain name is properly routed to the AWS service.
+
diff --git a/Non-DSA Notes/Backend Project Java Notes/Auth - 3: Implementing User Service.md b/Non-DSA Notes/Backend Project Java Notes/Auth - 3: Implementing User Service.md
new file mode 100644
index 0000000..39dbc6f
--- /dev/null
+++ b/Non-DSA Notes/Backend Project Java Notes/Auth - 3: Implementing User Service.md
@@ -0,0 +1,292 @@
+## Topics to be covered
+
+* Implementation of User Service
+
+---
+
+## Implementing Signup Functionality
+
+### Overview of Signup
+
+The **signup** functionality is a critical component of any user service, where new users can register by providing their details, such as email, password, and name. Here, we’ll implement the signup functionality by ensuring that the user's password is securely stored in the database.
+
+**Security** is the key concern in signup implementations, especially how passwords are handled. Instead of storing plain-text passwords, we use a **password hashing algorithm** called `bcrypt`, which transforms the plain password into an irreversible hash. This way, even if someone gains access to the database, they cannot retrieve the original passwords.
+
+
+### Step-by-Step Implementation
+
+1. **Implement `bcrypt` Password Encoder**:
+ - Use the `bcrypt` hashing algorithm to encode passwords before saving them to the database. This provides security by ensuring that even if the database is compromised, the passwords cannot be easily decoded.
+
+ **Why `bcrypt`?**
+ - It is a widely used hashing function designed specifically for hashing passwords, offering features like a salt to defend against rainbow table attacks and a configurable work factor to adjust the computational cost.
+
+2. **Allow All Requests Temporarily**:
+ - In the `SecurityConfiguration` class, temporarily allow all incoming HTTP requests. This step is necessary during development and testing to simplify access without authentication.
+
+3. **Resolve CORS Issues**:
+ - Ensure Cross-Origin Resource Sharing (CORS) policies are configured to allow requests from tools like Postman. CORS restrictions might prevent external clients from accessing resources, so removing these restrictions aids testing.
+
+4. **Testing with Postman**:
+ - Use Postman to make a `POST` request to the signup API endpoint. Postman allows us to send HTTP requests with a JSON body containing the user's email, password, and name, and observe the response.
+
+5. **Use `bcrypt` with Different Key Values**:
+ - Experiment with `bcrypt` by using different key values to explore how password encryption changes and observe the resulting hashed passwords.
+
+### Code Implementation
+
+The signup feature is implemented using two main components: a controller to handle incoming HTTP requests and a service that contains the business logic.
+
+#### Controllers Code (Signup)
+The controller manages the HTTP request for user signup and forwards it to the service layer for processing.
+```java
+@PostMapping("/signup")
+public UserDto signUp(@RequestBody SignUpRequestDto request) {
+ // Extract email, password, and name from the request object
+ String email = request.getEmail();
+ String password = request.getPassword();
+ String name = request.getName();
+
+ // Pass the extracted values to the signUp method in the service layer
+ return UserDto.from(userService.signUp(name, email, password));
+}
+```
+
+- **Explanation**:
+ - The `@PostMapping("/signup")` annotation maps this method to a POST HTTP request for the `/signup` endpoint.
+ - `@RequestBody` indicates that the request body contains JSON data (user's email, password, and name) that will be deserialized into a `SignUpRequestDto` object.
+ - The signup request data is passed to the service layer for processing.
+ - The response is converted into a `UserDto` object, which is then returned to the client.
+
+#### Service Code (Signup)
+The service handles the logic of storing the new user in the database after hashing their password.
+```java
+public User signUp(String fullName, String email, String password) {
+ // Create a new User object and set its attributes
+ User u = new User();
+ u.setEmail(email);
+ u.setName(fullName);
+
+ // Hash the user's password using bcrypt before saving it to the database
+ u.setHashedPassword(bCryptPasswordEncoder.encode(password));
+
+ // Save the user object to the database and return the saved user
+ User user = userRepository.save(u);
+ return user;
+}
+```
+
+- **Explanation**:
+ - A new `User` object is created, and its `email`, `name`, and `hashedPassword` attributes are set.
+ - The `password` is hashed using the `bCryptPasswordEncoder.encode()` method before being stored in the `hashedPassword` field.
+ - The `userRepository.save(u)` method saves the new user to the database and returns the saved user object.
+
+For more details on the structure of DTOs (Data Transfer Objects) and the complete project code, refer to the [GitHub repository](https://github.com/Naman-Bhalla/userservicemwfeve).
+
+---
+
+## Implementing Login Functionality
+
+### Overview of Login
+
+Login functionality allows users to authenticate themselves by providing their registered email and password. To ensure security, we verify the password against the stored hashed password using `bcrypt`. On successful authentication, the system generates a token that can be used to authenticate future requests.
+
+### Key Steps for Login
+
+1. **Find the User by Email**:
+ - When a login request is made, the system first searches for the user in the database using the provided email address.
+
+2. **Verify the Password**:
+ - If the user is found, the next step is to compare the provided password with the stored hashed password using the `bcryptPasswordEncoder.matches()` method. This method returns `true` if the passwords match, ensuring that the user has provided the correct password.
+
+3. **Generate a Token**:
+ - Once the password is verified, a new token is generated. This token will be used to authenticate future requests made by the user. For now, we can generate a simple random string, but later we will replace this with a JWT token for better security and functionality.
+
+### Code Implementation
+
+#### Controllers Code (Login)
+The controller handles the incoming login request and delegates it to the service.
+```java
+@PostMapping("/login")
+public Token login(@RequestBody LoginRequestDto request) {
+ // Pass email and password from the request to the login service method
+ return userService.login(request.getEmail(), request.getPassword());
+}
+```
+
+- **Explanation**:
+ - Similar to the signup process, `@PostMapping("/login")` maps this method to handle POST requests at the `/login` endpoint.
+ - The email and password are extracted from the `LoginRequestDto` object and passed to the service for validation.
+
+#### Service Code (Login)
+The service handles the login logic by checking the credentials and generating a token if the login is successful.
+```java
+public Token login(String email, String password) {
+ // Find the user by email in the database
+ OptionalHello, world !
+ + +``` + +### Structure your code +#### Div +Div elements are often used to structure and style sections of a web page, making it easier to apply CSS styles or JavaScript functionality to specific groups of content. + +#### Code: + +```html + + + +
+
+
+
+```
+#### Output
+
+
+
+#### Section
+Sections are used to structure the content of a web page into logical parts, such as chapters, articles, or different sections of a document.
+
+#### Code:
+```html
+
+
+
+ Welcome to Scalar Topics
++ We're glad you're here +
+Section Title
+This is a section of content.
+ +` typically being the main title and ``, ``, and so on used for subsections. They help improve the accessibility and readability of content.
+
+#### Code:
+
+```html
+Main Heading
+Subheading
+Sub-subheading
+```
+
+#### Output
+
+
+
+#### Anchor tags
+Anchor tags are used to link to other web pages or resources, both within the same website or externally to other websites.
+
+#### Code:
+```html
+
+
+
+ Basic HTML
+
+
+
+ Learn autoboxing - in - java
+
+
+
+
+```
+#### Output
+
+
+
+#### Image tags
+Image tags are used to display graphics, photographs, icons, or any other visual content on a webpage. The alt attribute provides alternative text for accessibility and SEO purposes.
+
+#### Code:
+```html
+
+
+
+ Basic HTML
+
+
+  +
+
+```
+#### Output
+
+
+#### Buttons
+Button elements are used to create clickable elements that can trigger actions when clicked, such as submitting a form or triggering JavaScript functions.
+
+#### Code:
+```html
+
+```
+#### Output
+
+
+
diff --git a/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md b/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md
new file mode 100644
index 0000000..aab5b84
--- /dev/null
+++ b/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md
@@ -0,0 +1,244 @@
+## List
+
+In HTML you can structure your content in a more readable and organized manner using lists. There are two types of lists such as
+1. Ordered lists `
+
+
+```
+#### Output
+
+
+#### Buttons
+Button elements are used to create clickable elements that can trigger actions when clicked, such as submitting a form or triggering JavaScript functions.
+
+#### Code:
+```html
+
+```
+#### Output
+
+
+
diff --git a/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md b/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md
new file mode 100644
index 0000000..aab5b84
--- /dev/null
+++ b/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md
@@ -0,0 +1,244 @@
+## List
+
+In HTML you can structure your content in a more readable and organized manner using lists. There are two types of lists such as
+1. Ordered lists `` and,
+2. Unordered lists ``
+
+## 1. Ordered List
+An ordered list is used to create a list of items that have a specific sequence or order. Each item in an ordered list is typically numbered, and the numbers usually increment in a sequential manner.
+Each list item is defined with the `- ` (list item) element, this will be more clear further in this article.
+
+An ordered list can store content in two ways as well:
+1. Non-alphabetically ordered
+2. Alphabetically ordered
+
+#### 1.1 Ordered List
+In the following code you can clearly see that the output generated is not structured alphabetically but listed in an orderely fashion
+
+#### Pseudocode
+
+```html
+
+
+
+
List Examples
+
+
+
+ - Banana
+ - Apple
+ - Strawberry
+
+
+
+```
+#### Output:
+
+
+### 1.2. Alphabetical Ordered List
+In order to structure list in alphabetical fashion we can use `type = "A"` between `` tags
+#### Pseudocode
+```html
+
+
+
+ Alphabetical Ordered List
+
+
+ Alphabetical Ordered List Example
+
+
+ - Banana
+ - Apple
+ - Strawberry
+
+
+
+
+```
+**Output:**
+
+
+### 2. Unordered List
+Use `` tags for displaying a list with the help of symbols/shapes. In this case we're considering shapes.
+#### Pseudocode
+```html
+
+
+
+ List Examples
+
+
+
+ - Banana
+ - Apple
+ - Strawberry
+
+
+```
+#### Output:
+
+
+
+## Tables in HTML
+
+We gnerally tables are used to organize and display data in a structured format. Tables consist of rows and columns, where each cell is capable of storing data in form of text, images, links, or other HTML elements. But in-order to create tables in HTML one needs to be familiar with certain tags and attributes used such as:
+1. ``: tag represents a table cell that contains data
+3. ``: tag represents a table row
+4. `` : tag represents a table header and is used to label columns or provide additional information about the data
+5. ``: tag is used to group the header content in a table. It typically contains one or more `` elements with `` elements inside.
+6. ` `: tag groups the body content of the table.
+7. ``: tag is used to provide a title or caption for the table. It is placed immediately after the opening `` tag.
+8. **border attribute**: is used to specify the thickness of the border around the table and its cells.
+
+
+#### Pseudocode
+```html
+
+
+
+ List Examples
+
+
+
+ Student's Marksheet
+
+ Student
+ Roll No.
+ Marks
+
+
+
+ 1
+ 2016911
+ 98
+
+
+ 2
+ 2015911
+ 78
+
+
+
+
+
+```
+#### Output:
+
+
+
+## HTML Forms
+
+Just like any other forms are used to collect information, in context of HTML it collects user input on a web page. They allow users to enter data, make selections, and submit that information to a server for processing. HTML forms are created using a combination of form-related tags and input elements such as
+1. `
`, and so on used for subsections. They help improve the accessibility and readability of content.
+
+#### Code:
+
+```html
+Main Heading
+Subheading
+Sub-subheading
+```
+
+#### Output
+
+
+
+#### Anchor tags
+Anchor tags are used to link to other web pages or resources, both within the same website or externally to other websites.
+
+#### Code:
+```html
+
+
+
+ Basic HTML
+
+
+
+ Learn autoboxing - in - java
+
+
+
+
+```
+#### Output
+
+
+
+#### Image tags
+Image tags are used to display graphics, photographs, icons, or any other visual content on a webpage. The alt attribute provides alternative text for accessibility and SEO purposes.
+
+#### Code:
+```html
+
+
+
+ Basic HTML
+
+
+
+
+
+```
+#### Output
+
+
+#### Buttons
+Button elements are used to create clickable elements that can trigger actions when clicked, such as submitting a form or triggering JavaScript functions.
+
+#### Code:
+```html
+
+```
+#### Output
+
+
+
diff --git a/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md b/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md
new file mode 100644
index 0000000..aab5b84
--- /dev/null
+++ b/Non-DSA Notes/FullStack-LLD/LLD-1 (HTML/CSS)/2_HTML (Lists , Tables and Forms).md
@@ -0,0 +1,244 @@
+## List
+
+In HTML you can structure your content in a more readable and organized manner using lists. There are two types of lists such as
+1. Ordered lists `` and,
+2. Unordered lists ``
+
+## 1. Ordered List
+An ordered list is used to create a list of items that have a specific sequence or order. Each item in an ordered list is typically numbered, and the numbers usually increment in a sequential manner.
+Each list item is defined with the `- ` (list item) element, this will be more clear further in this article.
+
+An ordered list can store content in two ways as well:
+1. Non-alphabetically ordered
+2. Alphabetically ordered
+
+#### 1.1 Ordered List
+In the following code you can clearly see that the output generated is not structured alphabetically but listed in an orderely fashion
+
+#### Pseudocode
+
+```html
+
+
+
+
List Examples
+
+
+
+ - Banana
+ - Apple
+ - Strawberry
+
+
+
+```
+#### Output:
+
+
+### 1.2. Alphabetical Ordered List
+In order to structure list in alphabetical fashion we can use `type = "A"` between `` tags
+#### Pseudocode
+```html
+
+
+
+ Alphabetical Ordered List
+
+
+ Alphabetical Ordered List Example
+
+
+ - Banana
+ - Apple
+ - Strawberry
+
+
+
+
+```
+**Output:**
+
+
+### 2. Unordered List
+Use `` tags for displaying a list with the help of symbols/shapes. In this case we're considering shapes.
+#### Pseudocode
+```html
+
+
+
+ List Examples
+
+
+
+ - Banana
+ - Apple
+ - Strawberry
+
+
+```
+#### Output:
+
+
+
+## Tables in HTML
+
+We gnerally tables are used to organize and display data in a structured format. Tables consist of rows and columns, where each cell is capable of storing data in form of text, images, links, or other HTML elements. But in-order to create tables in HTML one needs to be familiar with certain tags and attributes used such as:
+1. ``: tag represents a table cell that contains data
+3. ``: tag represents a table row
+4. `` : tag represents a table header and is used to label columns or provide additional information about the data
+5. ``: tag is used to group the header content in a table. It typically contains one or more `` elements with `` elements inside.
+6. ` `: tag groups the body content of the table.
+7. ``: tag is used to provide a title or caption for the table. It is placed immediately after the opening `` tag.
+8. **border attribute**: is used to specify the thickness of the border around the table and its cells.
+
+
+#### Pseudocode
+```html
+
+
+
+ List Examples
+
+
+
+ Student's Marksheet
+
+ Student
+ Roll No.
+ Marks
+
+
+
+ 1
+ 2016911
+ 98
+
+
+ 2
+ 2015911
+ 78
+
+
+
+
+
+```
+#### Output:
+
+
+
+## HTML Forms
+
+Just like any other forms are used to collect information, in context of HTML it collects user input on a web page. They allow users to enter data, make selections, and submit that information to a server for processing. HTML forms are created using a combination of form-related tags and input elements such as
+1. `
- `
+
+## 1. Ordered List
+An ordered list is used to create a list of items that have a specific sequence or order. Each item in an ordered list is typically numbered, and the numbers usually increment in a sequential manner.
+Each list item is defined with the `
- ` (list item) element, this will be more clear further in this article.
+
+An ordered list can store content in two ways as well:
+1. Non-alphabetically ordered
+2. Alphabetically ordered
+
+#### 1.1 Ordered List
+In the following code you can clearly see that the output generated is not structured alphabetically but listed in an orderely fashion
+
+#### Pseudocode
+
+```html
+
+
+
+
List Examples + + +-
+
- Banana +
- Apple +
- Strawberry +
- ` tags
+#### Pseudocode
+```html
+
+
+
+
- Banana +
- Apple +
- Strawberry +
- Banana +
- Apple +
- Strawberry +
Alphabetical Ordered List + + +Alphabetical Ordered List Example
+ +-
+
- ` tags for displaying a list with the help of symbols/shapes. In this case we're considering shapes.
+#### Pseudocode
+```html
+
+
+
+
List Examples + + +-
+
`: tag represents a table row +4. ` `: tag groups the body content of the table. +7. `` : tag represents a table header and is used to label columns or provide additional information about the data +5. ``: tag is used to group the header content in a table. It typically contains one or more ` ` elements with ` ` elements inside. +6. ` `: tag is used to provide a title or caption for the table. It is placed immediately after the opening ` ` tag. +8. **border attribute**: is used to specify the thickness of the border around the table and its cells. + + +#### Pseudocode +```html + + + +
List Examples + + ++
+ + +``` +#### Output: + + + +## HTML Forms + +Just like any other forms are used to collect information, in context of HTML it collects user input on a web page. They allow users to enter data, make selections, and submit that information to a server for processing. HTML forms are created using a combination of form-related tags and input elements such as +1. `Student's Marksheet + +Student +Roll No. +Marks + + ++ +1 +2016911 +98 ++ + +2 +2015911 +78 +